
Hola Habr! La descripción del funcionamiento del interior de una gran plataforma de pago continuará lógicamente con una descripción de cómo funcionan exactamente todos estos componentes en el mundo real en hardware físico. En esta publicación, me refiero a cómo y dónde están ubicadas las aplicaciones de la plataforma, cómo les llega el tráfico del mundo exterior, y también describiré el esquema de un rack estándar para nosotros con equipos ubicados en cualquiera de nuestros centros de datos.
Enfoques y limitaciones

Uno de los primeros requisitos que formulamos antes del desarrollo de la plataforma suena como "la capacidad de escalar recursos informáticos lineales para garantizar el procesamiento de cualquier cantidad de transacciones".
Los enfoques clásicos de los sistemas de pago utilizados por los participantes en el mercado implican la presencia de un techo, aunque bastante alto según las declaraciones. Por lo general, suena así: "nuestro procesamiento puede aceptar 1000 transacciones por segundo".
Este enfoque no se ajusta a nuestros objetivos comerciales y arquitectura. No queremos tener ningún límite. De hecho, sería extraño escuchar de Yandex o Google la declaración "podemos procesar 1 millón de búsquedas por segundo". La plataforma debe procesar tantas solicitudes como necesite la empresa en este momento debido a la arquitectura, que permite, en pocas palabras, enviar a un trabajador de TI con un grupo de servidores, que instalará en bastidores, se conectará al conmutador y se irá. Y el orquestador de la plataforma desplegará copias de las instancias de aplicaciones comerciales a nuevas capacidades, como resultado de lo cual obtendremos el aumento de RPS que necesitamos.
El segundo requisito importante es garantizar la alta disponibilidad de los servicios prestados. Sería divertido, pero no demasiado útil, crear una plataforma de pago que pueda aceptar un número infinito de pagos en / dev / null.
Quizás la forma más efectiva de lograr una alta disponibilidad es duplicar las entidades que prestan servicio al servicio muchas veces para que la falla de cualquier número razonable de aplicaciones, equipos o centros de datos no afecte la disponibilidad general de la plataforma.
La duplicación múltiple de aplicaciones requiere una gran cantidad de servidores físicos y equipos de red relacionados. Este hierro cuesta dinero, cuya cantidad tenemos, por supuesto, no podemos permitirnos comprar una gran cantidad de hierro costoso. Por lo tanto, la plataforma está diseñada de tal manera que se acomoda fácilmente y se siente bien en una gran cantidad de hierro económico y no demasiado potente, o incluso en una nube pública.
El uso de servidores que no son los más fuertes en términos de potencia informática tiene sus ventajas: su falla no tiene un efecto crítico en el estado general del sistema en su conjunto. Imagínese lo que es mejor: si un servidor de marca caro, grande y súper confiable se incendia, ejecutando un DBMS de acuerdo con el esquema maestro-esclavo (y de acuerdo con la ley de Murphy, ciertamente se quemará y en la noche del 31 de diciembre) o un par de servidores en un grupo de 30 nodos que se ejecutan de acuerdo con masterless diagrama?
En base a esta lógica, decidimos no crear otro punto de falla masivo en forma de una matriz de discos centralizada. El clúster Ceph nos proporciona dispositivos de bloque comunes, que se implementan hiperconvergentes en los mismos servidores, pero con una infraestructura de red separada.
Por lo tanto, lógicamente llegamos al esquema general de un rack universal con recursos informáticos en forma de servidores económicos y poco potentes en el centro de datos. Si necesitamos más recursos, terminamos cualquier rack gratuito con servidores o colocamos otro, preferiblemente más cerca.

Bueno, al final, es simplemente hermoso. Cuando se instala una cantidad clara del mismo hierro en los bastidores, esto le permite resolver problemas con la calidad de la instalación de la granja de alambres, le permite deshacerse de los nidos de golondrinas y el peligro de enredarse en los cables, dejando caer el procesamiento. Un bien desde el punto de vista de la ingeniería, el sistema debe ser hermoso en todas partes, tanto desde el interior en forma de código como desde el exterior en forma de servidores y hardware de red. Un sistema hermoso funciona mejor y de manera más confiable, tuve suficientes ejemplos para verificar esto desde mi propia experiencia.
Por favor, no piense que somos delincuentes o que el negocio se ve afectado por la financiación. Desarrollar y mantener una plataforma distribuida es en realidad un placer muy costoso. De hecho, esto es aún más costoso que poseer un sistema clásico, construido, condicionalmente, en un potente hardware de marca con Oracle / MSSQL, servidores de aplicaciones y otros enlaces.
Nuestro enfoque vale la pena con una alta confiabilidad, capacidades de escalado horizontal muy flexibles, falta de un límite en la cantidad de pagos por segundo, y no importa cuán extraño suene, muy divertido para el equipo de TI. Para mí, el nivel de placer de los desarrolladores y desarrolladores del sistema que crean no es menos importante que el tiempo de desarrollo previsto, la cantidad y la calidad de las características implementadas.
Infraestructura del servidor

Lógicamente, nuestras capacidades de servidor se pueden dividir en dos clases principales: servidores para hipervisores, para los cuales la densidad de núcleos de CPU y RAM por unidad es importante, y servidores de almacenamiento, donde el énfasis principal está en la cantidad de espacio en disco por unidad, y CPU y RAM ya están seleccionados para número de discos
Por el momento, nuestro servidor clásico para potencia informática se ve así:
- CPU 2xXeon E5-2630;
- 128G RAM;
- 3xSATA SSD (grupo de SSD Ceph);
- 1xNVMe SSD (dm-cache).
Servidor para almacenar estados:
- CPU 1xXeon E5-2630;
- 12-16 HDD;
- 2 SSD para block.db;
- 32G de RAM.
Infraestructura de red
En la elección del hardware de red, nuestro enfoque es algo diferente. Todavía usamos conmutadores de marca para cambiar y enrutar entre vlan-s, ahora es Cisco SG500X-48 y Cisco Nexus C5020 en SAN.
Físicamente, cada servidor está conectado a la red por 4 puertos físicos:
- 2x1GbE: red de gestión y RPC entre aplicaciones;
- 2x10GbE: red para almacenamiento.
Las interfaces dentro de las máquinas se combinan mediante enlaces, luego el tráfico etiquetado diverge de acuerdo con la vlan deseada.
Quizás este es el único lugar en nuestra infraestructura donde puede ver la etiqueta de un vendedor famoso. Porque para el enrutamiento, el filtrado de la red y la inspección del tráfico utilizamos hosts Linux. No compramos enrutadores especializados. Todo lo que necesitamos lo configuramos en servidores que ejecutan Gentoo (iptables para filtrado, BIRD para enrutamiento dinámico, Suricata como IDS / IPS, Wallarm como WAF).
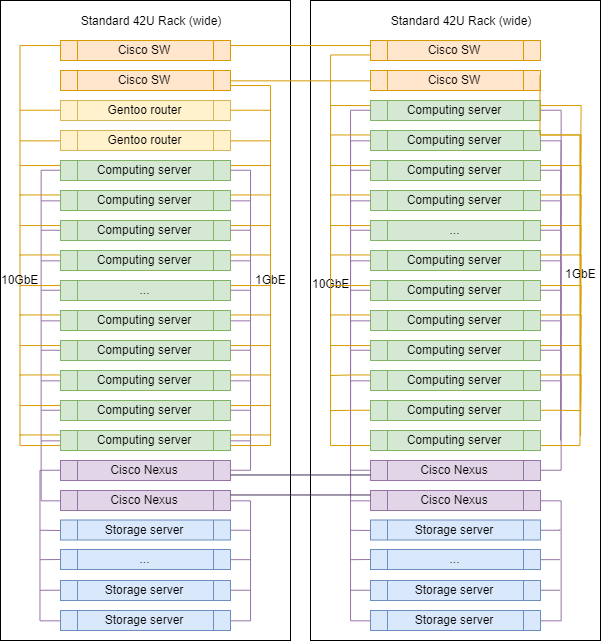
Bastidor típico en DC
Al escalar, los racks en DC prácticamente no difieren entre sí, excepto para los enrutadores de enlace ascendente, que están instalados en uno de ellos.
Las proporciones exactas de los servidores de diferentes clases pueden variar, pero en general, la lógica se conserva: hay más servidores para la informática que servidores para almacenar datos.
Bloquear dispositivos y compartir recursos
Tratemos de poner todo junto. Imagine que necesitamos colocar varios de nuestros microservicios en la infraestructura, para mayor claridad, estos serán microservicios que deben comunicarse entre sí a través de RPC y uno de ellos es Machinegun, que almacena el estado en el clúster Riak, así como algunos servicios auxiliares, como como los nodos ES y Consul.
Un diseño típico se vería así:
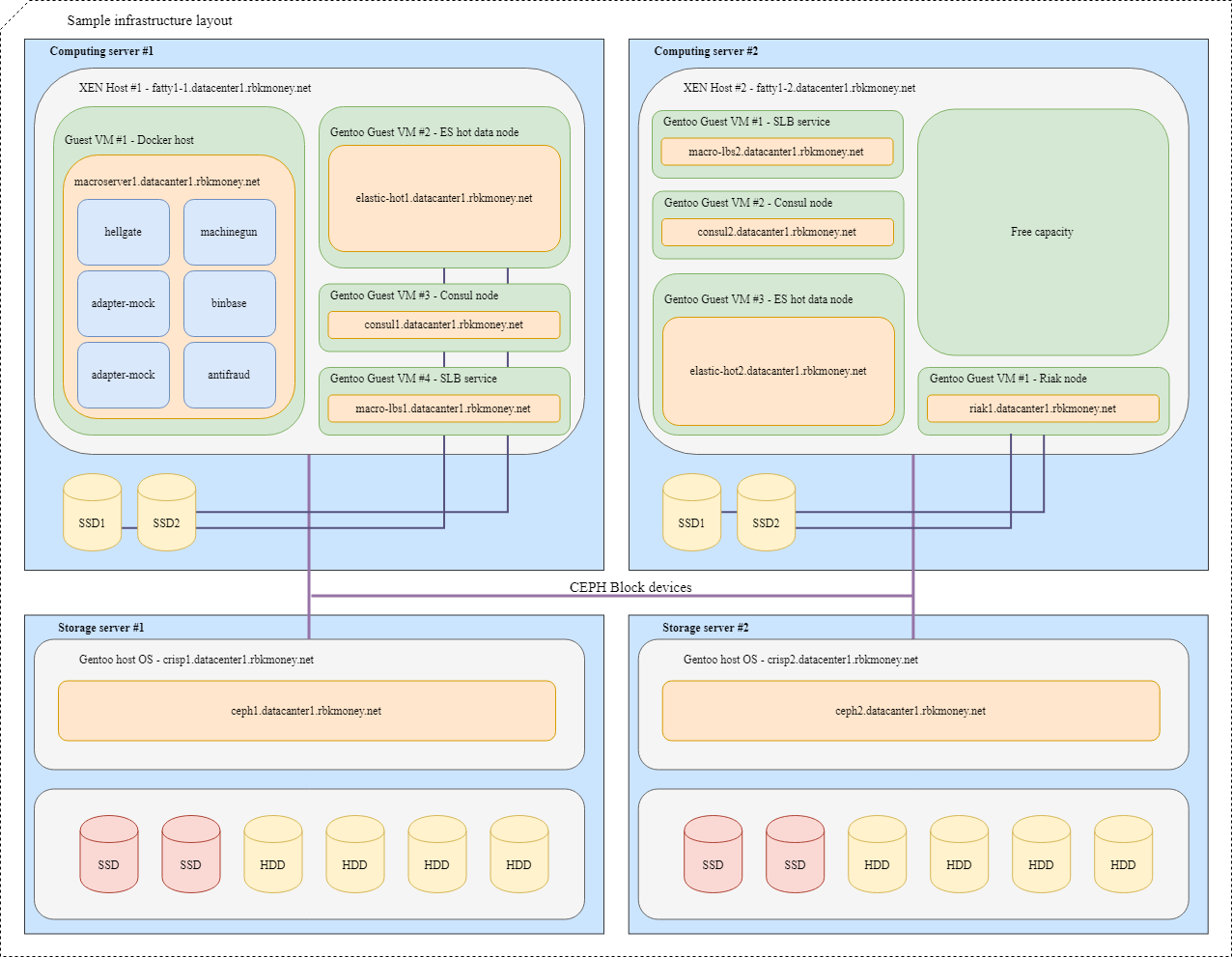
Para las máquinas virtuales con aplicaciones que requieren la velocidad máxima del dispositivo de bloque, como los nodos activos Riak y Elasticsearch, se utilizan particiones en discos NVMe locales. Dichas máquinas virtuales están estrechamente conectadas a su hipervisor, y las propias aplicaciones son responsables de la disponibilidad e integridad de sus datos.
Para dispositivos de bloque comunes, utilizamos Ceph RBD, generalmente con memoria caché de escritura en el disco NVMe local. La OSD para el dispositivo puede ser full-flash o HDD con registro SSD, dependiendo del tiempo de respuesta deseado.
Entrega de tráfico a las aplicaciones.
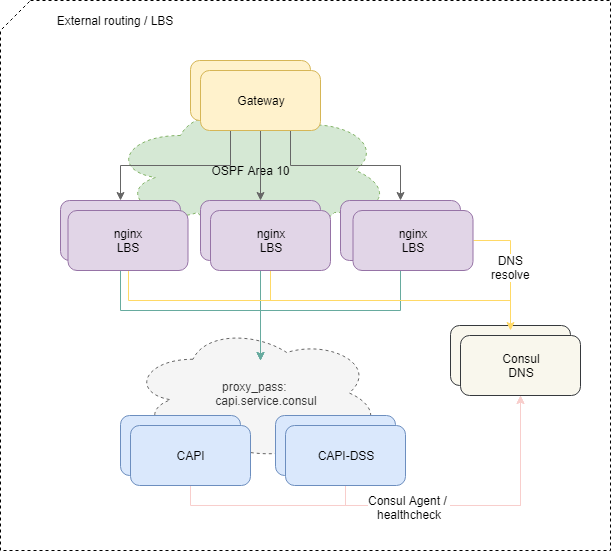
Para equilibrar las solicitudes que provienen del exterior, utilizamos el esquema estándar OSPFv3 ECMP. Pequeñas máquinas virtuales con nginx, bird, cónsul anuncian en la nube OSPF direcciones anycast comunes desde la interfaz lo. En los enrutadores, para estas direcciones, bird crea rutas de múltiples saltos que proporcionan un equilibrio por flujo, donde el flujo es "src-ip src-port dst-ip dst-port". Para deshabilitar rápidamente el balanceador faltante, se utiliza el protocolo BFD.
Al agregar o fallar cualquiera de los equilibradores, los enrutadores ascendentes tienen la ruta correspondiente aparece o se eliminan, y el tráfico de red se les entrega de acuerdo con los enfoques de ruta múltiple de igual costo. Y si no intervenimos específicamente, todo el tráfico de red se distribuye de manera uniforme a todos los equilibradores disponibles en cada flujo de IP.
Por cierto, el enfoque con el equilibrio de ECMP tiene dificultades no obvias, que pueden conducir a pérdidas completamente no obvias de parte del tráfico, especialmente si otros enrutadores o cortafuegos extrañamente configurados están en la ruta entre los sistemas.
Para resolver el problema, utilizamos el demonio PMTUD en esta parte de la infraestructura.
Además, el tráfico va dentro de la plataforma a microservicios específicos de acuerdo con la configuración de nginx en los balanceadores.
Y si equilibrar el tráfico externo es más o menos simple y comprensible, entonces sería difícil extender dicho esquema más hacia adentro: necesitamos más que simplemente verificar la disponibilidad de un contenedor con un microservicio a nivel de red.
Para que el microservicio comience a recibir y procesar solicitudes, debe registrarse con Service Discovery (usamos Consul ), someterse a controles de estado cada segundo y tener un RTT razonable.
Si el microservicio se siente y se comporta bien, Consul comienza a resolver la dirección de su contenedor al acceder a su DNS por el nombre del servicio. Utilizamos la zona interna service.consul y, por ejemplo, el microservicio de la versión 2 de la API común se llamará capi-v2.service.consul .
La configuración de nginx con respecto al equilibrio al final se ve así:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
Por lo tanto, si no volvemos a intervenir a propósito, el tráfico de los equilibradores se distribuye de manera uniforme entre todos los microservicios registrados en Service Discovery, y la adición o eliminación de nuevas instancias de los microservicios necesarios está totalmente automatizada.
Si la solicitud del equilibrador fue ascendente y murió en el camino, devolvemos 502: el equilibrador a su nivel no puede determinar si la solicitud era idempotente o no, por lo que le damos el procesamiento de tales errores a un nivel lógico más alto.
Idempotencia y plazos
En general, no tenemos miedo y no dude en dar errores 5xx con la API, esta es una parte normal del sistema si realiza el procesamiento correcto de dichos errores en el nivel de lógica de negocios RPC. Los principios de este procesamiento se describen en nuestro formulario como un pequeño manual llamado Política de reintento de errores, lo distribuimos a nuestros clientes comerciales y lo implementamos dentro de nuestros servicios.
Para simplificar este procesamiento, hemos implementado varios enfoques.
En primer lugar, para cualquier solicitud de cambio de estado a nuestra API, puede especificar una clave de idempotencia única dentro de la cuenta, que dura para siempre y le permite estar seguro de que una llamada repetida con el mismo conjunto de datos devolverá la misma respuesta.
En segundo lugar, implementamos un mecanismo adicional en forma de un identificador único para la sesión de pago, que garantiza la idempotencia de las solicitudes de fondos de débito, brindando protección contra débitos repetidos erróneos, incluso si no genera y transmite una clave de idempotencia separada.
En tercer lugar, decidimos habilitar un tiempo de respuesta predecible y controlado externamente a cualquier llamada externa a nuestra API en forma de un parámetro de corte de tiempo que determina el tiempo de espera máximo para que una operación se complete a pedido. Es suficiente para transferir, por ejemplo, el encabezado HTTP X-Request-Deadline: 10s para asegurarse de que su solicitud se ejecutará dentro de los 10 segundos o la plataforma la matará en algún lugar dentro, después de lo cual podemos contactarnos nuevamente, guiados por solicitud de política de reenvío.
Usamos SaltStack como herramienta de administración tanto para las configuraciones como para la infraestructura en su conjunto. Las herramientas separadas para el control automatizado de la potencia informática de la plataforma aún no han despegado, aunque ya entendemos que iremos en esta dirección. Con nuestro amor por los productos Hashicorp, es probable que sea Nomad.
Las principales herramientas de monitoreo de infraestructura son las comprobaciones en Nagios, pero para las entidades comerciales, configuramos principalmente alertas en Grafana. Tiene una herramienta muy conveniente para establecer condiciones, y un modelo de plataforma basado en eventos le permite escribir todo en Elasticsearch y configurar las condiciones de selección.
Los centros de datos se encuentran en Moscú, en ellos alquilamos espacios en rack, instalamos y administramos de forma independiente todo el equipo. No utilizamos ópticas oscuras en ningún lugar, solo tenemos Internet fuera de los proveedores locales.
De lo contrario, nuestros enfoques de monitoreo, administración y servicios relacionados son bastante estándar para la industria, no estoy seguro de que valga la pena mencionar la siguiente descripción de la integración de estos servicios en una publicación.
En este artículo, probablemente terminaré la serie de publicaciones de revisión sobre cómo se organiza nuestra plataforma de pago.
Creo que el ciclo resultó ser bastante franco, he conocido algunos artículos que revelarían con tanto detalle la cocina interior de los grandes sistemas de pago.
En general, en mi opinión, un alto nivel de franqueza y franqueza es algo muy importante para el sistema de pago. Este enfoque no solo aumenta el nivel de confianza de los socios y pagadores, sino que también disciplina al equipo, a los creadores y operadores del servicio.
Entonces, guiados por este principio, recientemente publicamos el estado de la plataforma y el historial de tiempo de actividad de nuestros servicios. Toda la historia posterior de nuestro tiempo de actividad, actualizaciones y bloqueos ahora es pública y está disponible en https://status.rbk.money/ .
Espero que haya estado interesado, y tal vez alguien encuentre útiles nuestros enfoques y los errores descritos. Si está interesado en alguna de las áreas descritas en las publicaciones y desea que las divulgue con más detalle, no dude en escribir en los comentarios o en PM.
¡Gracias por estar con nosotros!

PD Para su comodidad, un puntero a los artículos anteriores de la serie: