Como en la
mayoría de las publicaciones , hubo un problema con un servicio distribuido, llamemos a este servicio Alvin. Esta vez no encontré el problema por mí mismo, los chicos de la parte del cliente me informaron.
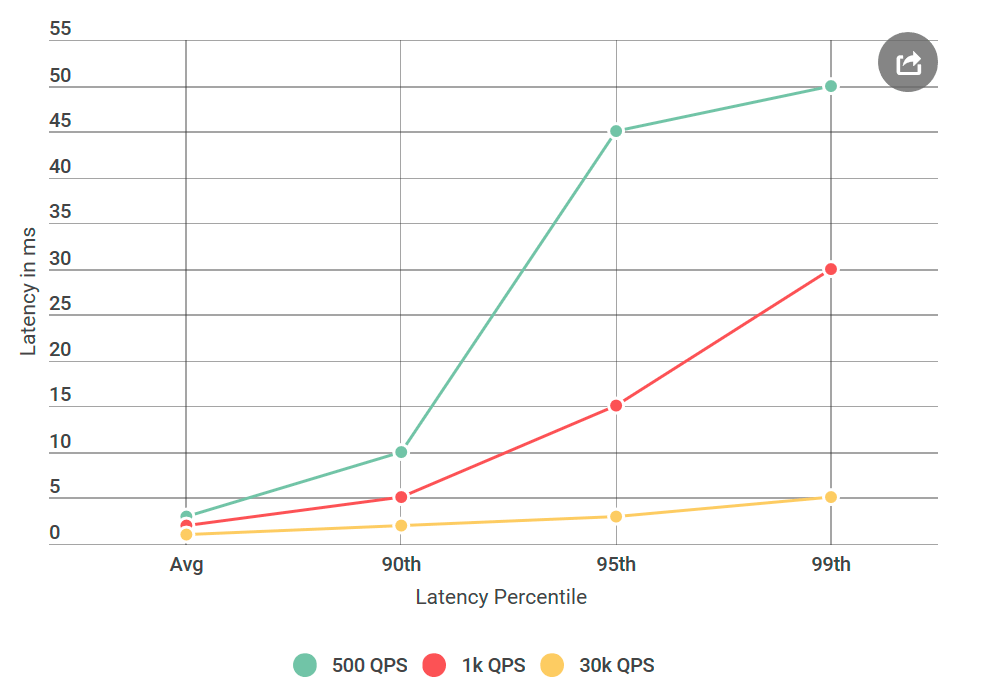
Una vez que me desperté de una carta disgustada debido a los grandes retrasos de Alvin, a quien planeamos lanzar en un futuro próximo. En particular, el cliente encontró un retraso del percentil 99 alrededor de 50 ms, muy por encima de nuestro presupuesto de retraso. Esto fue sorprendente, ya que probé a fondo el servicio, especialmente por retrasos, porque este es el tema de quejas frecuentes.
Antes de dar a Alvin para pruebas, realicé muchos experimentos con 40 mil solicitudes por segundo (QPS), todos mostraron un retraso de menos de 10 ms. Estaba listo para declarar que no estaba de acuerdo con sus resultados. Pero una vez más, mirando la carta, llamé la atención sobre algo nuevo: definitivamente no probé las condiciones que mencionaron, su QPS era mucho más bajo que el mío. Probé en 40k QPS, y solo en 1k. Realicé otro experimento, esta vez con QPS más bajo, solo para complacerlos.
Como escribo sobre esto en mi blog, probablemente ya entendiste: sus números resultaron ser correctos. Probé mi cliente virtual una y otra vez, todo con el mismo resultado: un número bajo de solicitudes no solo aumenta el retraso, sino que también aumenta el número de solicitudes con un retraso de más de 10 ms. En otras palabras, si a 40k QPS aproximadamente 50 solicitudes por segundo excedían los 50 ms, entonces a 1k QPS por segundo había 100 solicitudes por encima de 50 ms. Paradoja!
Limita tu búsqueda
Ante el problema de la demora en un sistema distribuido con muchos componentes, lo primero que debe hacer es hacer una breve lista de sospechosos. Profundizamos un poco más en la arquitectura de Alvin:
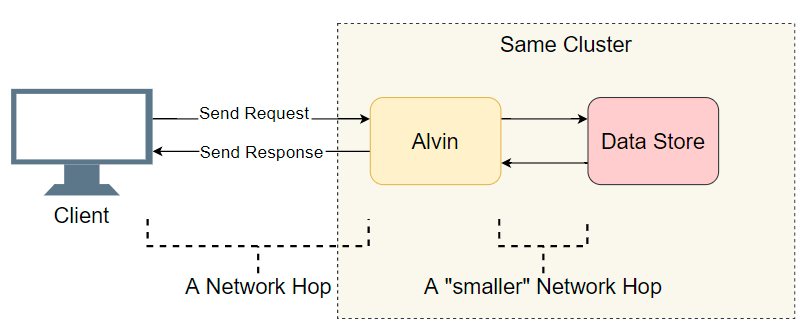
Un buen punto de partida es una lista de transiciones de E / S completadas (llamadas de red / búsquedas de disco, etc.). Tratemos de averiguar dónde está el retraso. Además de la obvia E / S con el cliente, Alvin da un paso adicional: accede al almacén de datos. Sin embargo, este almacenamiento funciona en el mismo clúster con Alvin, por lo que debería haber menos retraso que con el cliente. Entonces, la lista de sospechosos:
- Llamada de red del cliente a Alvin.
- Llamada de red de Alvin al almacén de datos.
- Buscar en disco en el almacén de datos.
- Llamada de red desde el almacén de datos a Alvin.
- Llamada de red de Alvin al cliente.
Intentemos tachar algunos puntos.
Almacén de datos
Lo primero que hice fue convertir Alvin a un servidor de ping-ping que no maneja las solicitudes. Al recibir la solicitud, devuelve una respuesta vacía. Si la demora disminuye, entonces un error en la implementación de Alvin o el almacén de datos no es desconocido. En el primer experimento, obtenemos el siguiente gráfico:
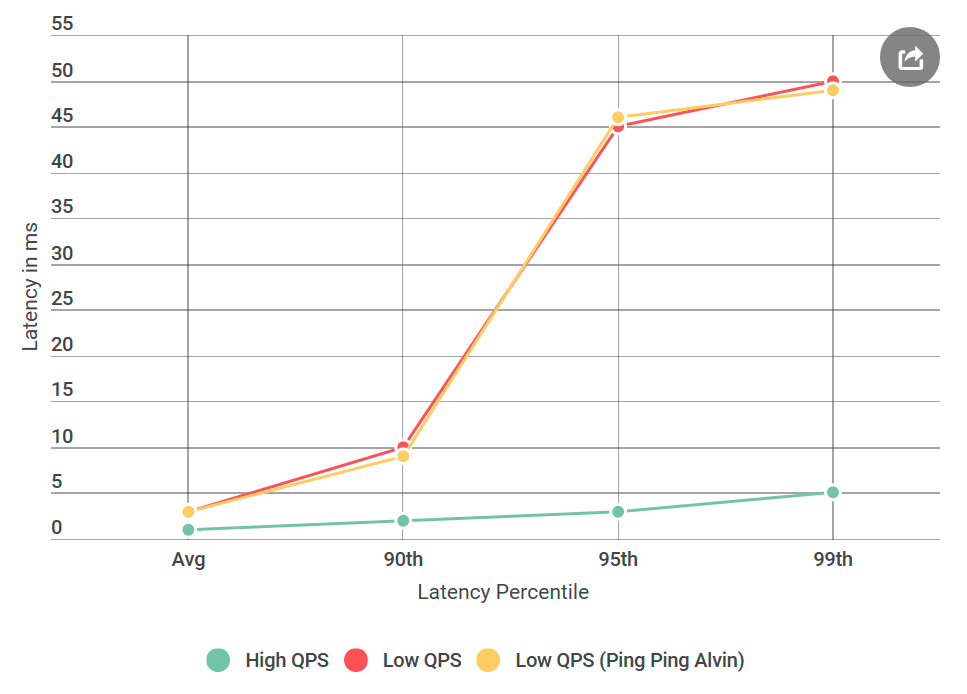
Como puede ver, cuando se usa el servidor ping-ping no hay mejoras. Esto significa que el almacén de datos no aumenta el retraso y la lista de sospechosos se reduce a la mitad:
- Llamada de red del cliente a Alvin.
- Llamada de red de Alvin al cliente.
Wow! La lista se está reduciendo rápidamente. Pensé que casi descubrí la razón.
gRPC
Ahora es el momento de presentarte a un nuevo jugador:
gRPC . Esta es una biblioteca de código abierto de Google para comunicaciones
RPC en proceso. Aunque
gRPC bien optimizado y ampliamente utilizado, lo utilicé por primera vez en un sistema de esta escala, y esperaba que mi implementación fuera subóptima, por decir lo menos.
La presencia de
gRPC en la pila planteó una nueva pregunta: ¿tal vez esta es mi implementación o el propio
gRPC causa un problema de retraso? Añadir a la lista del nuevo sospechoso:
- El cliente llama a la biblioteca
gRPC
- La biblioteca
gRPC en el cliente realiza una llamada de red a la biblioteca gRPC en el servidor
gRPC biblioteca gRPC accede a Alvin (ninguna operación en el caso del servidor de ping-pong)
Para hacerle entender cómo se ve el código, mi implementación de cliente / Alvin no es muy diferente de los
ejemplos asíncronos de cliente-servidor.
Nota: la lista anterior está un poco simplificada, ya que gRPC permite usar su propio modelo Stream (¿plantilla?), En el que la gRPC ejecución de gRPC y la implementación del usuario están entrelazadas. En aras de la simplicidad, nos atendremos a este modelo.
El perfilado lo arreglará todo
Al tachar los almacenes de datos, pensé que ya casi había terminado: “¡Ahora fácil! Aplicaremos el perfil y descubriremos dónde se produce el retraso ". Soy un
gran admirador de los perfiles precisos porque las CPU son muy rápidas y, a menudo, no son un cuello de botella. La mayoría de los retrasos ocurren cuando el procesador debe detener el procesamiento para hacer otra cosa. El perfil preciso de la CPU se realizó solo para esto: registra con precisión todos los
cambios de contexto y deja en claro dónde se producen los retrasos.
Tomé cuatro perfiles: bajo QPS alto (latencia baja) y con un servidor de ping-pong en QPS bajo (latencia alta), tanto en el lado del cliente como en el lado del servidor. Y por si acaso, también tomé un perfil de procesador de muestra. Al comparar perfiles, generalmente busco una pila de llamadas anormal. Por ejemplo, en el lado malo con un alto retraso, hay muchos más cambios de contexto (10 o más veces). Pero en mi caso, el número de cambios de contexto casi coincidió. Para mi horror, no había nada significativo allí.
Depuración adicional
Estaba desesperado No sabía qué otras herramientas podrían usarse, y mi próximo plan era esencialmente repetir experimentos con diferentes variaciones, y no diagnosticar claramente el problema.
Que pasa si
Desde el principio, me preocupaba el tiempo de retraso específico de 50 ms. Este es un momento muy grande. Decidí que cortaría las piezas del código hasta que pudiera averiguar exactamente qué parte estaba causando este error. Luego siguió un experimento que funcionó.
Como de costumbre, con la mente vuelta parece que todo era obvio. Puse el cliente en la misma máquina que Alvin y envié la solicitud a
localhost . ¡Y el aumento en la demora ha desaparecido!
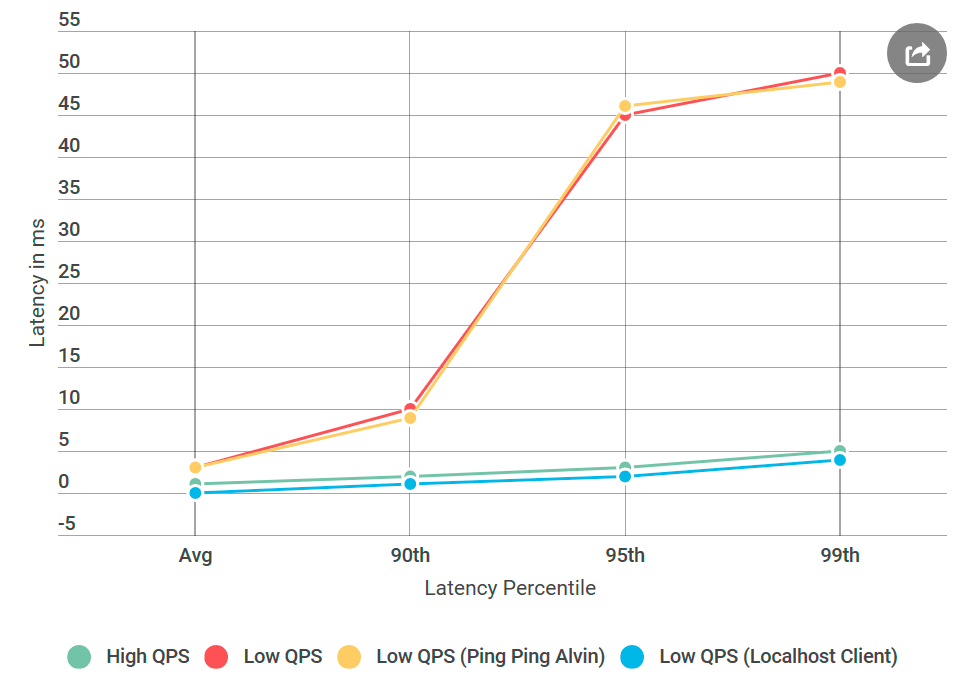
Algo estaba mal con la red.
Aprender las habilidades de un ingeniero de redes.
Debo admitir: mi conocimiento de las tecnologías de red es terrible, especialmente teniendo en cuenta el hecho de que trabajo con ellas a diario. Pero la red era el principal sospechoso, y necesitaba aprender a depurarla.
Afortunadamente, Internet ama a aquellos que quieren aprender. La combinación de ping y tracert parecía un buen comienzo para depurar problemas de transporte de red.
Primero, ejecuté
PsPing en el puerto TCP de
Alvin . Usé las opciones predeterminadas, nada especial. De los más de mil pings, ninguno superó los 10 ms, con la excepción del primero para el calentamiento. Esto contradice el aumento observado en el retraso de 50 ms en el percentil 99: allí, por cada 100 solicitudes, deberíamos ver aproximadamente una solicitud con un retraso de 50 ms.
Luego probé
tracert : tal vez el problema está en uno de los nodos a lo largo de la ruta entre Alvin y el cliente. Pero el rastreador regresó con las manos vacías.
Por lo tanto, la razón del retraso no fue mi código, ni la implementación de gRPC, ni la red. Ya he comenzado a preocuparme de que nunca entenderé esto.
¿En qué sistema operativo estamos?
gRPC usa ampliamente en Linux, pero es exótico para Windows. Decidí realizar un experimento que funcionó: creé una máquina virtual Linux, compilé Alvin para Linux y la implementé.
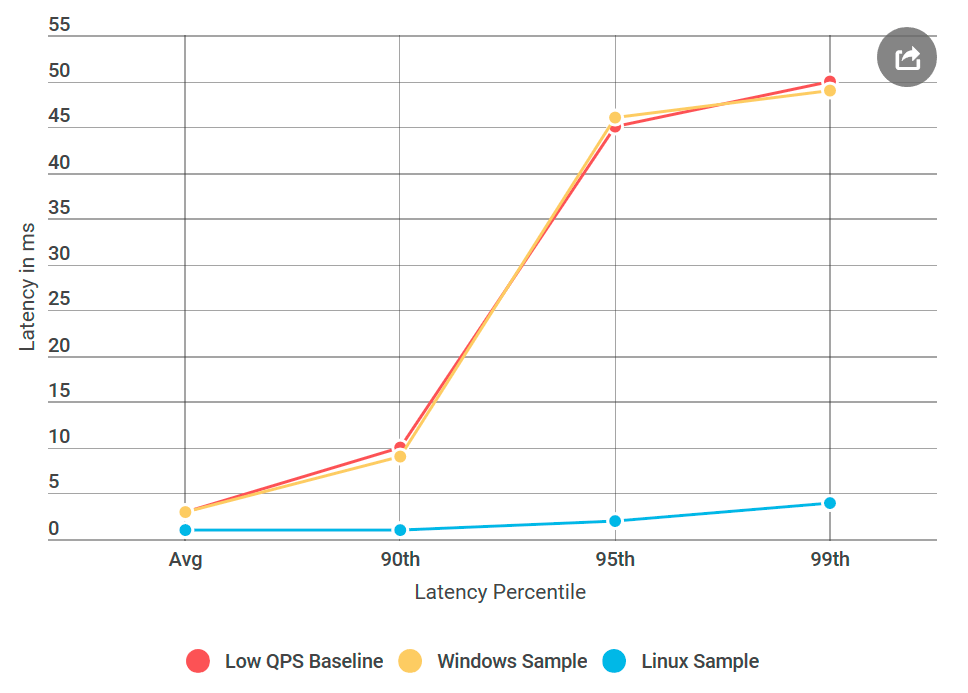
Y esto es lo que sucedió: el servidor Linux de ping-pong no tuvo demoras como un nodo de Windows similar, aunque la fuente de datos no fue diferente. Resulta que el problema está en implementar gRPC para Windows.
Algoritmo Nagle
Todo este tiempo, pensé que me faltaba la bandera de
gRPC . Ahora me di cuenta de que esto
gRPC carece de la bandera de Windows en
gRPC . Encontré la biblioteca RPC interna, en la que estaba seguro de que funciona bien para todos
los indicadores
Winsock instalados. Luego agregó todas estas banderas a gRPC e implementó Alvin en Windows, ¡en el servidor fijo de ping-pong para Windows!
 Casi
Casi hecho: comencé a eliminar las banderas agregadas de una en una hasta que regresó la regresión, para poder identificar su causa. Fue el infame
TCP_NODELAY , un interruptor del algoritmo Nagle.
El algoritmo Neigl intenta reducir el número de paquetes enviados a través de la red al retrasar la transmisión de mensajes hasta que el tamaño del paquete exceda un cierto número de bytes. Aunque esto puede ser agradable para el usuario promedio, es destructivo para los servidores en tiempo real, ya que el sistema operativo retrasará algunos mensajes, causando demoras en QPS bajo.
gRPC tenía este indicador establecido en la implementación de Linux para sockets TCP, pero no para Windows. Lo
arregléConclusión
Un gran retraso en el bajo QPS fue causado por la optimización del sistema operativo. Mirando hacia atrás, la creación de perfiles no detectó un retraso porque se realizó en modo kernel y no en
modo usuario . No sé si es posible observar el algoritmo de Nagle a través de capturas ETW, pero eso sería interesante.
En cuanto al experimento localhost, probablemente no tocó el código de red real, y el algoritmo Neigl no se inició, por lo que los problemas de retraso desaparecieron cuando el cliente contactó a Alvin a través de localhost.
¡La próxima vez que vea un aumento en la latencia mientras disminuye la cantidad de solicitudes por segundo, el algoritmo Neigl debería estar en su lista de sospechosos!