
Introduccion
Hice este informe en inglés en la conferencia GopherCon Rusia 2019 en Moscú y en ruso en la reunión en Nizhny Novgorod. Se trata de un índice de mapa de bits, menos común que el árbol B, pero no menos interesante. Comparto la
grabación del discurso en la conferencia en inglés y la transcripción del texto en ruso.
Examinaremos cómo funciona el índice de mapa de bits, cuándo es mejor, cuándo es peor que otros índices y en qué casos es mucho más rápido que ellos; Veremos qué DBMS populares ya tienen índices de mapa de bits. intenta escribir el tuyo en Go. Y para el postre, utilizaremos bibliotecas listas para crear nuestra propia base de datos especializada súper rápida.
Realmente espero que mi trabajo sea útil e interesante para usted. Vamos!
Introduccion
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Hola a todos! Son las seis de la tarde, todos estamos súper cansados. Buen momento para hablar sobre la aburrida teoría de los índices de bases de datos, ¿verdad? No se preocupe, tendré un par de líneas de código fuente aquí y allá. :-)
Sin bromas, entonces el informe está lleno de información y no tenemos mucho tiempo. Entonces comencemos.

Hoy hablaré sobre lo siguiente:
- ¿Qué son los índices?
- ¿Qué es un índice de mapa de bits?
- dónde se usa y dónde NO se usa y por qué;
- implementación simple en Go y un poco de lucha con el compilador;
- implementación un poco menos simple, pero mucho más productiva en Go-assembler;
- "Problemas" de los índices de mapa de bits;
- implementaciones existentes.
Entonces, ¿qué son los índices?
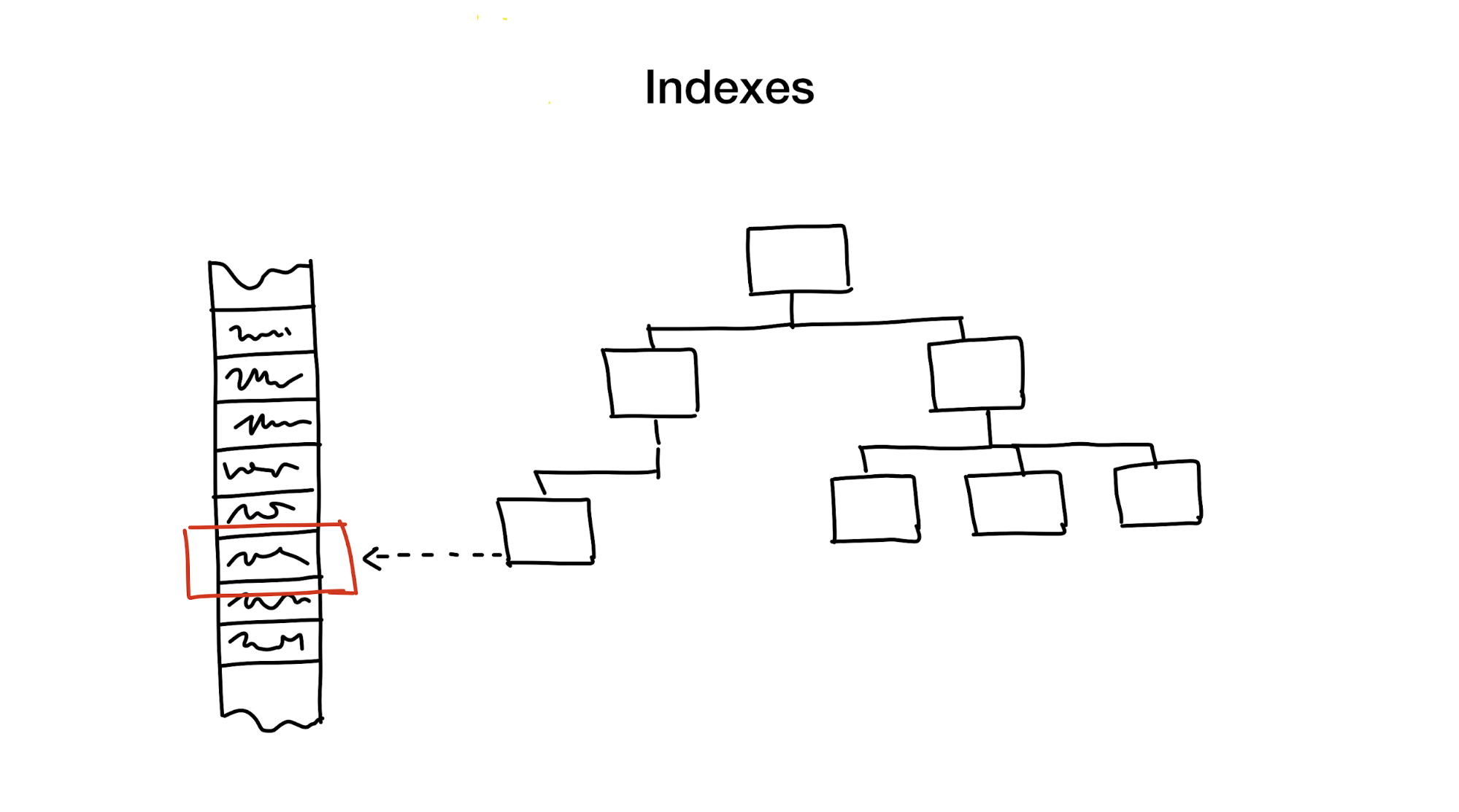
Un índice es una estructura de datos separada que mantenemos y actualizamos además de los datos principales. Se utiliza para acelerar la búsqueda. Sin índices, una búsqueda requeriría un pase completo a través de los datos (un proceso llamado exploración completa), y este proceso tiene una complejidad algorítmica lineal. Pero las bases de datos generalmente contienen una gran cantidad de datos y la complejidad lineal es demasiado lenta. Idealmente, obtendríamos un logarítmico o constante.
Este es un tema enorme y complejo, abrumado por sutilezas y compromisos, pero después de mirar décadas de desarrollo e investigación de varias bases de datos, estoy listo para argumentar que solo hay unos pocos enfoques ampliamente utilizados para crear índices de bases de datos.

El primer enfoque es reducir jerárquicamente el área de búsqueda, dividiendo el área de búsqueda en partes más pequeñas.
Usualmente hacemos esto usando todo tipo de árboles. Un ejemplo es una caja grande con materiales en su armario, en la que hay cajas más pequeñas con materiales divididos por varios temas. Si necesita materiales, probablemente los buscará en una caja con las palabras "Materiales", y no en la que dice "Cookies", ¿verdad?
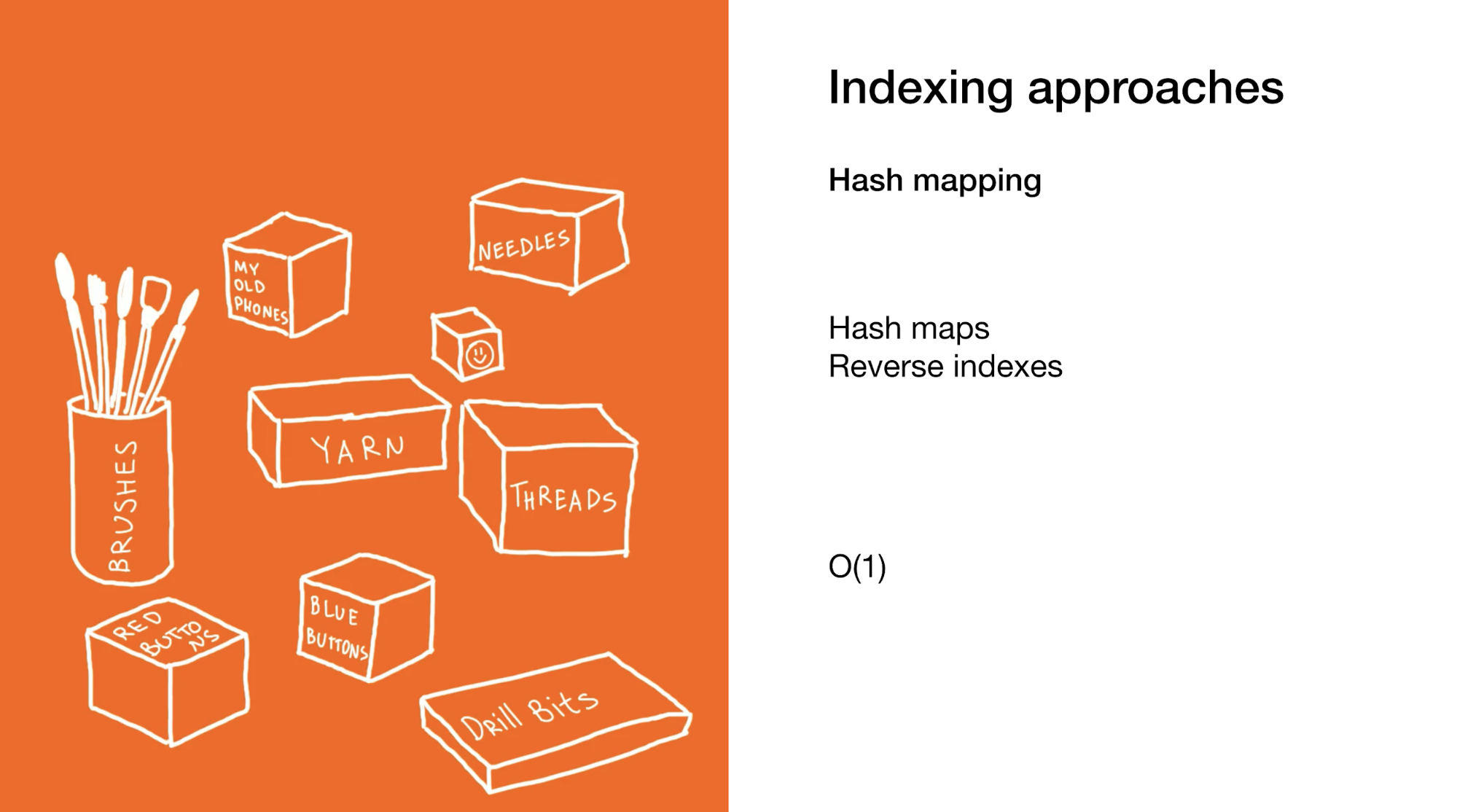
El segundo enfoque es seleccionar inmediatamente el elemento o grupo de elementos deseado. Hacemos esto en mapas hash o en índices inversos. El uso de mapas hash es muy similar al ejemplo anterior, solo que en lugar de una caja con cajas en su armario, hay muchas cajas pequeñas con elementos finales.

El tercer enfoque es deshacerse de la necesidad de una búsqueda. Hacemos esto usando filtros Bloom o filtros de cuco. Los primeros proporcionan una respuesta al instante, eliminando la necesidad de buscar.
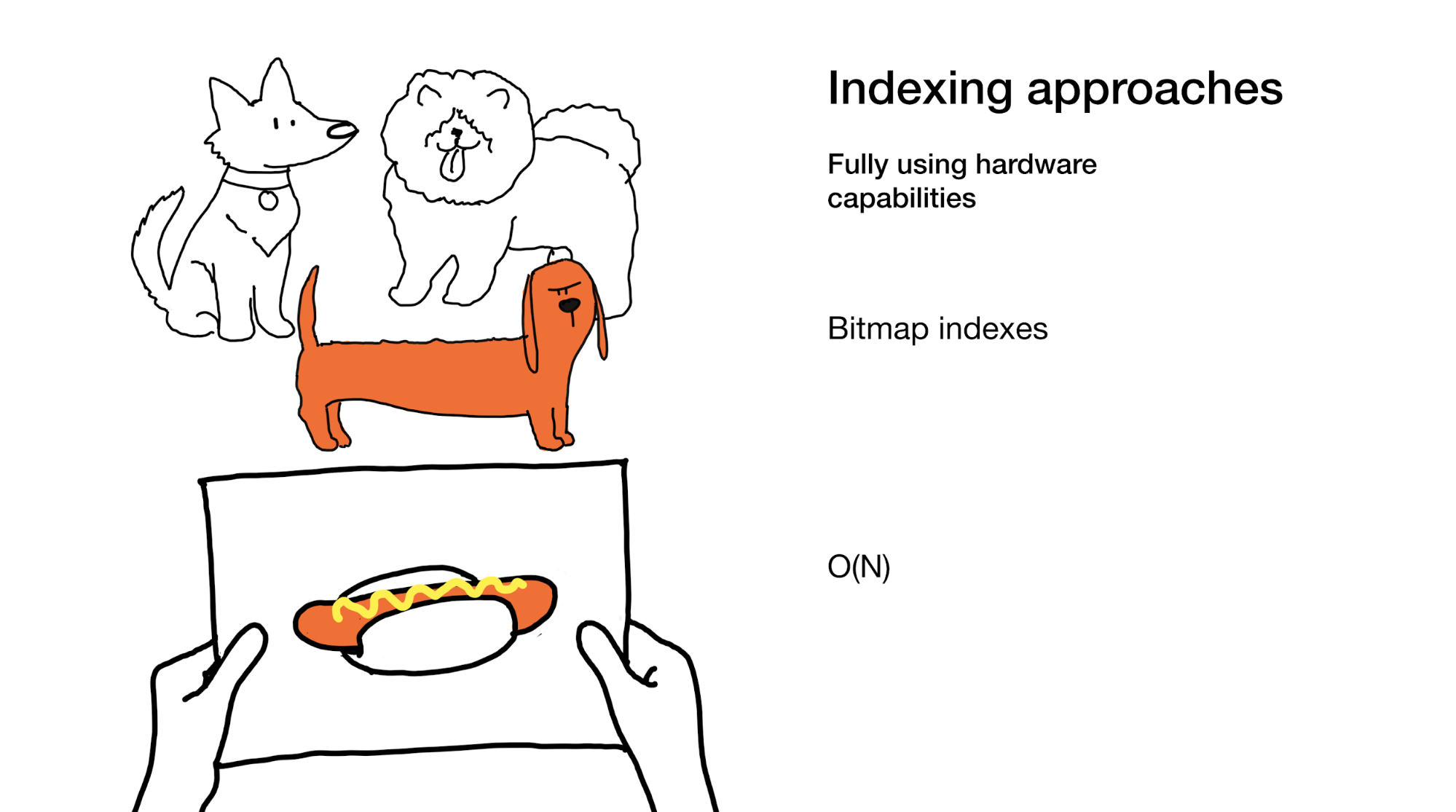
El último enfoque es utilizar plenamente todas las capacidades que nos brinda el hierro moderno. Esto es exactamente lo que hacemos en los índices de mapa de bits. Sí, cuando los usamos, a veces necesitamos revisar todo el índice, pero lo hacemos de manera súper eficiente.
Como dije, el tema de los índices de bases de datos es vasto y está lleno de compromisos. Esto significa que a veces podemos usar varios enfoques al mismo tiempo: si necesitamos acelerar la búsqueda aún más o si es necesario cubrir todos los tipos posibles de búsqueda.
Hoy hablaré sobre el enfoque menos conocido de estos: sobre los índices de mapas de bits.
¿Quién soy yo para hablar de esto?
Trabajo como líder de equipo en Badoo (quizás conozca mejor nuestro otro producto, Bumble). Ya tenemos más de 400 millones de usuarios en todo el mundo y muchas funciones que se dedican a seleccionar el mejor par para ellos. Hacemos esto usando servicios personalizados que también usan índices de mapas de bits.
Entonces, ¿qué es un índice de mapa de bits?
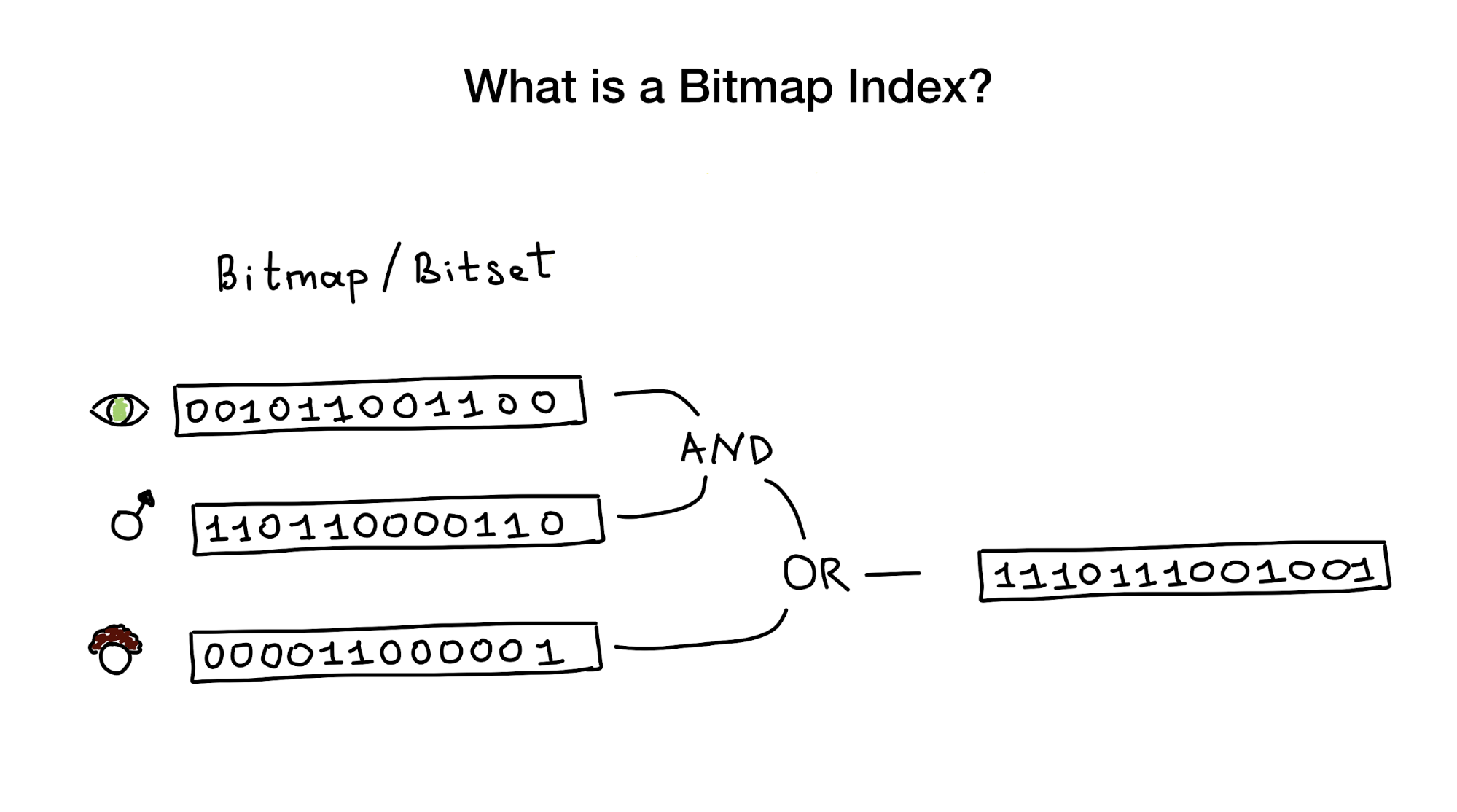
Los índices de mapa de bits, como su nombre nos dice, usan mapas de bits o conjuntos de bits para implementar un índice de búsqueda. Desde una vista de pájaro, este índice consta de uno o más de estos mapas de bits que representan cualquier entidad (como personas) y sus propiedades o parámetros (edad, color de ojos, etc.), y de un algoritmo que utiliza operaciones de bits (AND, O, NO) para responder a una consulta de búsqueda.

Se nos dice que los índices de mapas de bits son los más adecuados y muy productivos para los casos en los que hay una búsqueda que combina consultas en muchas columnas que tienen poca cardinalidad (imagine "color de ojos" o "estado civil" frente a algo como "distancia del centro de la ciudad" ) Pero luego mostraré que funcionan perfectamente en el caso de columnas con alta cardinalidad.
Considere el ejemplo más simple de un índice de mapa de bits.

Imagine que tenemos una lista de restaurantes de Moscú con propiedades binarias como estas:
- cerca del metro (cerca del metro);
- hay un estacionamiento privado (tiene estacionamiento privado);
- hay una veranda (tiene terraza);
- Puede reservar una mesa (acepta reservas);
- adecuado para vegetarianos (vegana amigable);
- caro (caro)
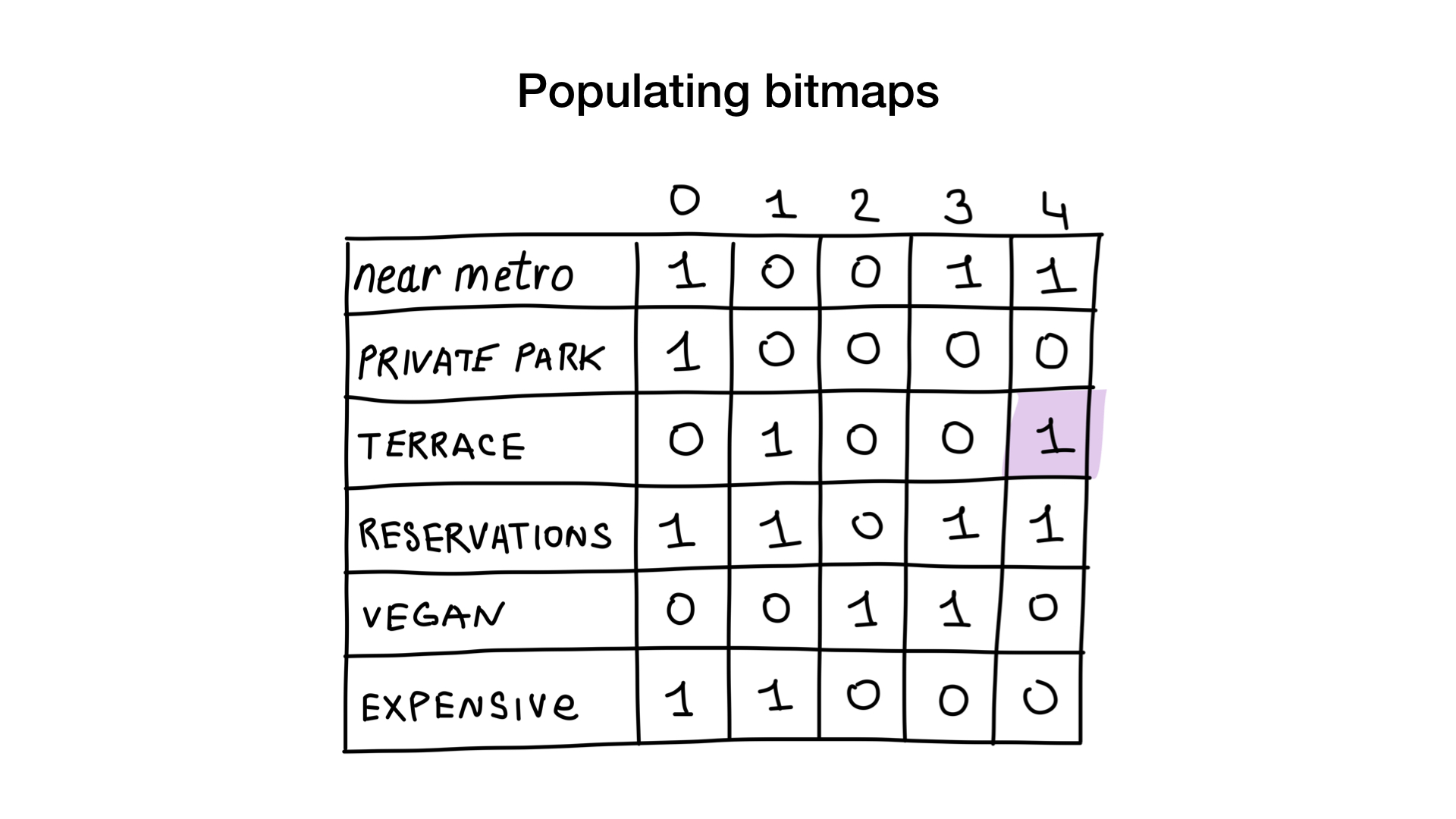
Démosle a cada restaurante un número de serie que comience en 0 y asigne memoria para 6 mapas de bits (uno para cada característica). Luego completamos estos mapas de bits, dependiendo de si el restaurante tiene esta propiedad o no. Si el restaurante 4 tiene una veranda, entonces el bit No. 4 en el mapa de bits “hay una veranda” se establecerá en 1 (si no hay veranda, entonces en 0).

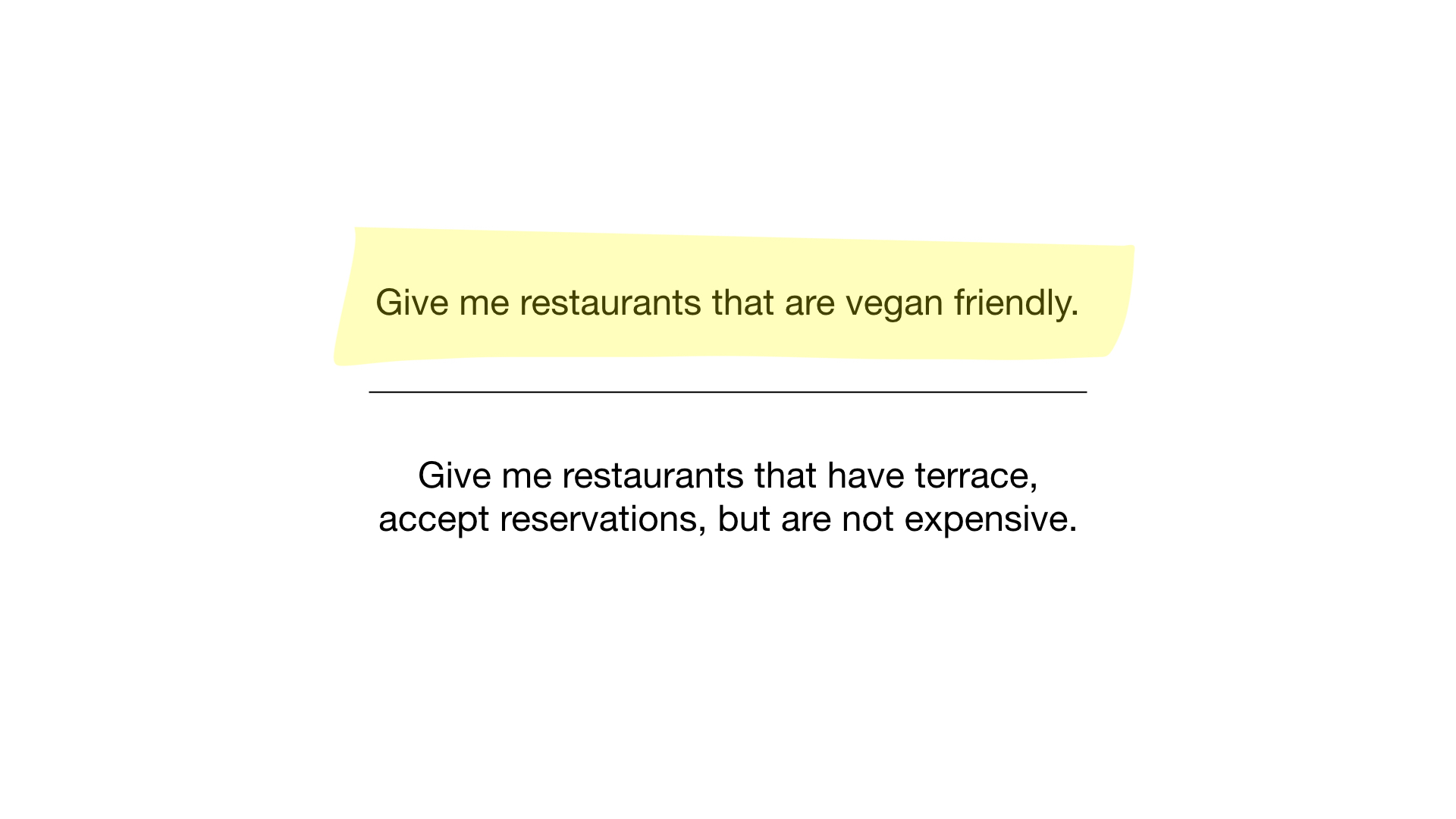
Ahora tenemos el índice de mapa de bits más simple posible, y podemos usarlo para responder consultas como:
- "Muéstrame restaurantes aptos para vegetarianos";
- "Muéstrame restaurantes económicos con una terraza donde puedas reservar una mesa".
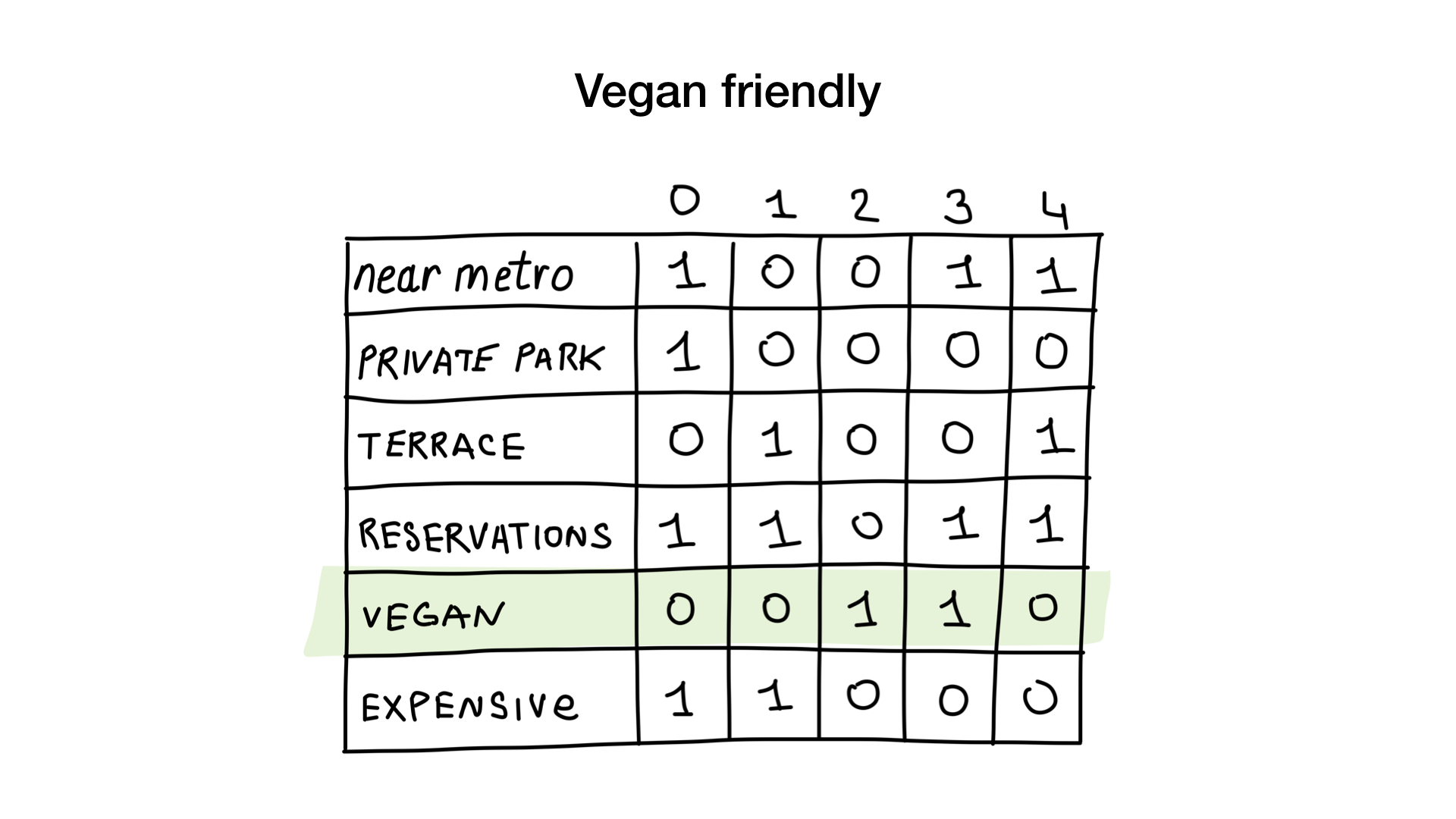
Como? A ver La primera solicitud es muy simple. Todo lo que necesitamos hacer es tomar el mapa de bits "adecuado para vegetarianos" y convertirlo en una lista de restaurantes cuyos bits están en exhibición.
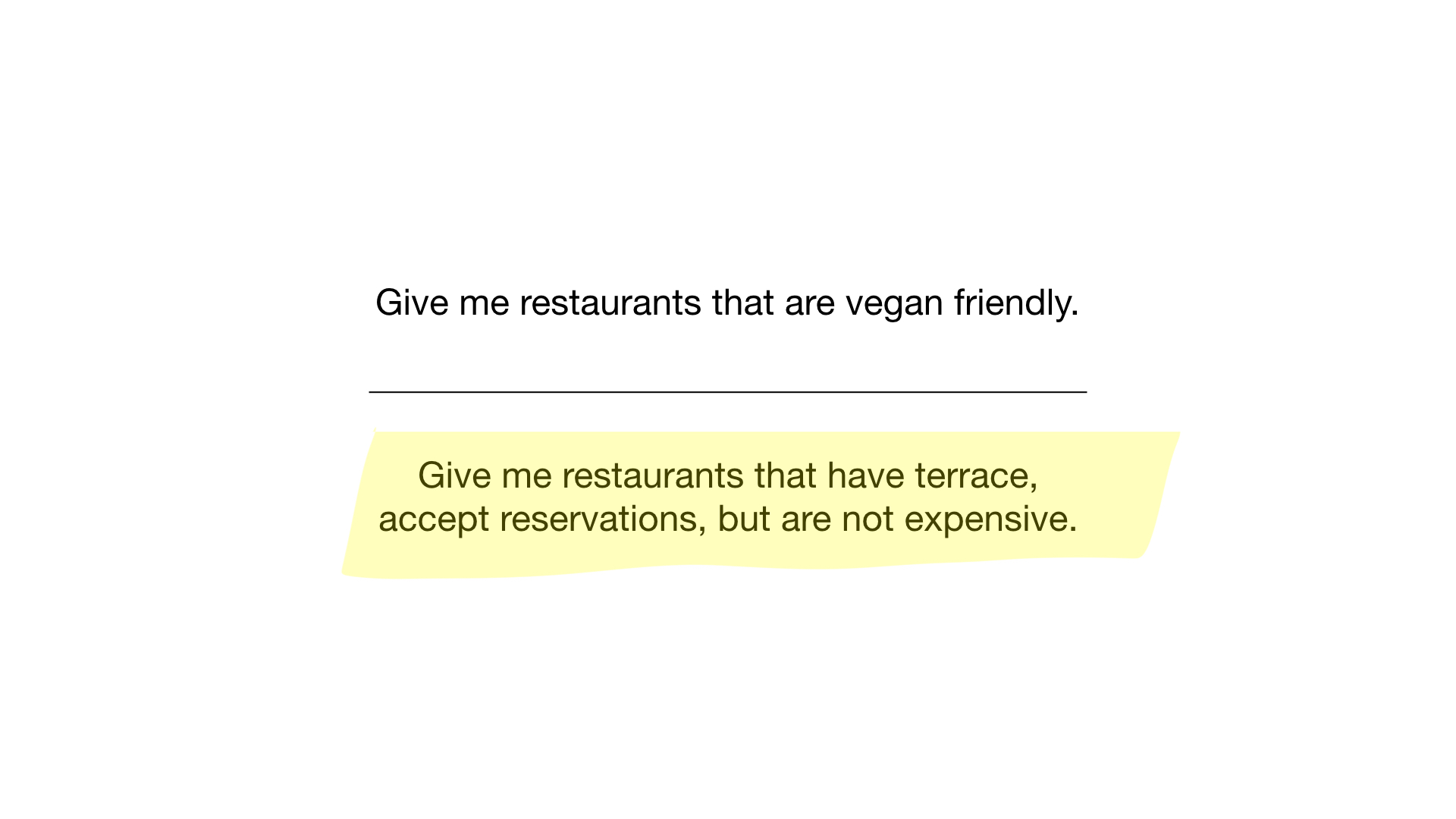

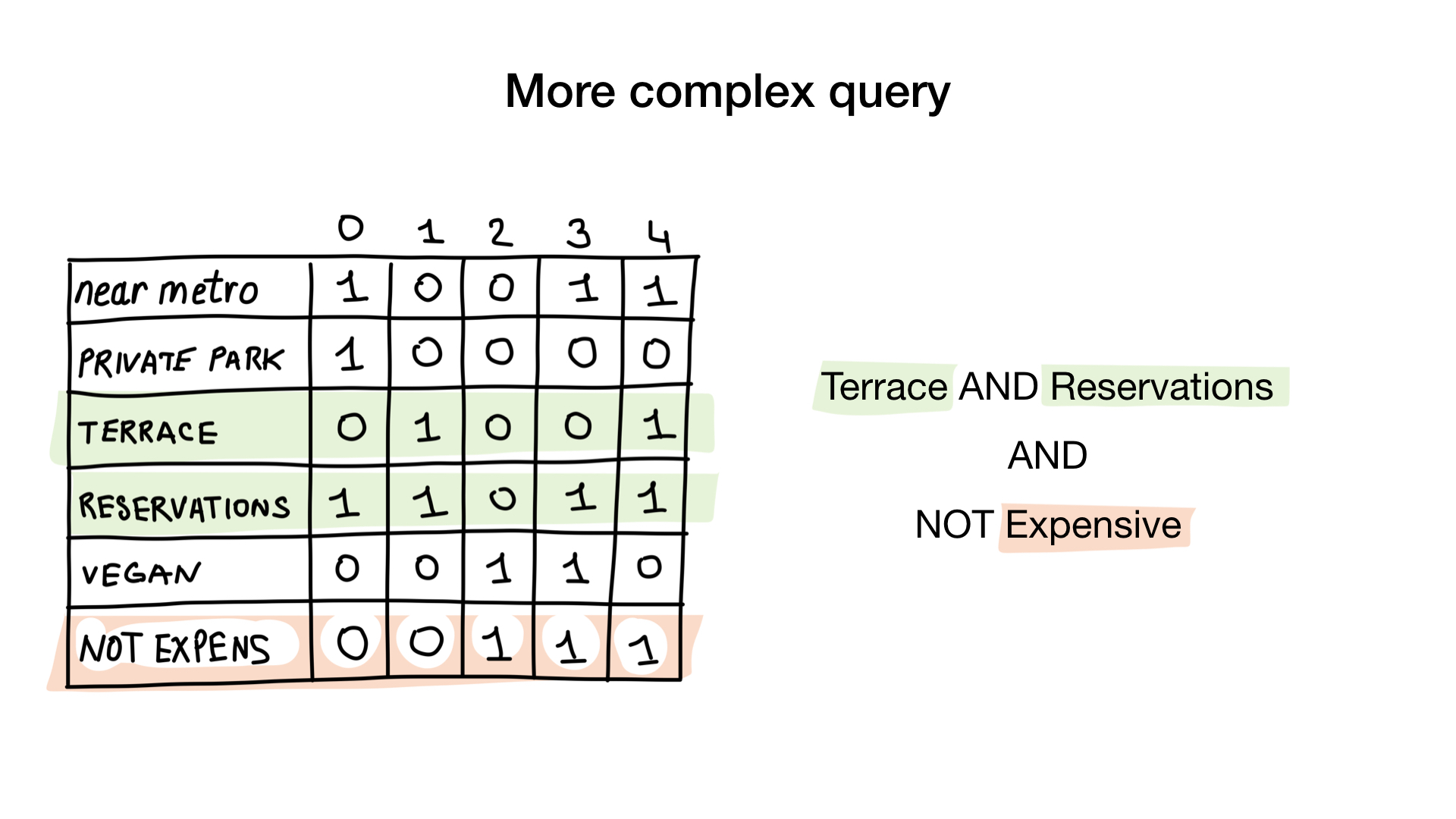
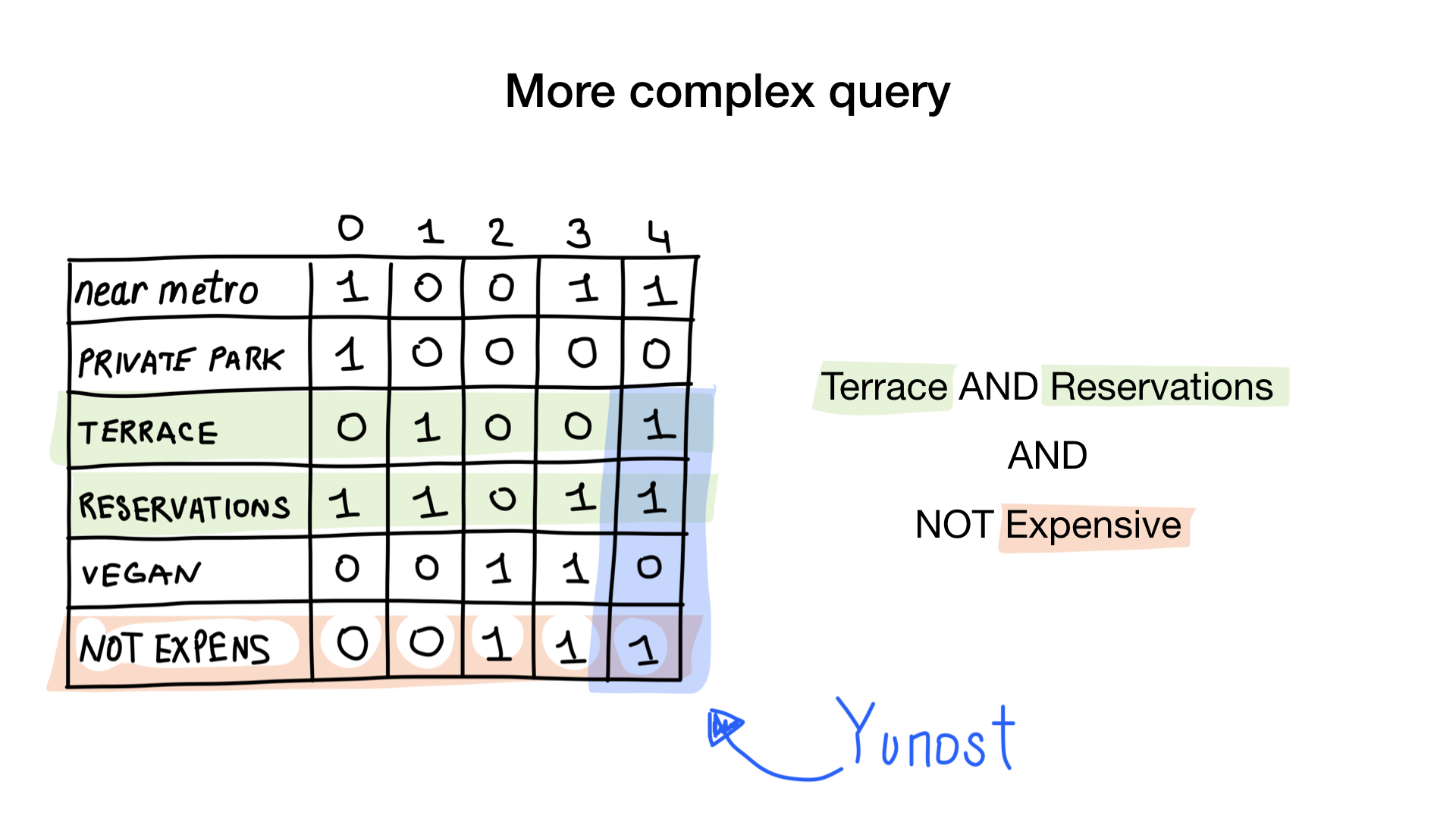
La segunda consulta es un poco más complicada. Necesitamos usar la operación NOT bit en el mapa de bits "caro" para obtener una lista de restaurantes económicos, luego configurarlo con el mapa de bits "puede reservar una mesa" y establecer el resultado con el mapa de bits "hay una veranda". El mapa de bits resultante contendrá una lista de establecimientos que cumplen con todos nuestros criterios. En este ejemplo, este es solo el restaurante Yunost.
Hay mucha teoría, pero no se preocupe, veremos el código muy pronto.
¿Dónde se usan los índices de mapa de bits?

Si "googlea" los índices de mapa de bits, el 90% de las respuestas estarán relacionadas de alguna manera con Oracle DB. Pero el resto del DBMS también es compatible con algo tan genial, ¿verdad? En realidad no
Repasemos la lista de los principales sospechosos.

MySQL aún no admite índices de mapa de bits, pero hay una propuesta con una propuesta para agregar esta opción (
https://dev.mysql.com/worklog/task/?id=1524 ).
PostgreSQL no admite índices de mapa de bits, pero utiliza mapas de bits simples y operaciones de bits para combinar los resultados de búsqueda en varios otros índices.
Tarantool tiene índices de bitset, admite una simple búsqueda en ellos.
Redis tiene campos de bits simples
(https://redis.io/commands/bitfield ) sin la capacidad de buscar a través de ellos.
MongoDB aún no admite índices de mapa de bits, pero también hay una Propuesta con una propuesta para agregar esta opción
https://jira.mongodb.org/browse/SERVER-1723Elasticsearch utiliza mapas de bits en su interior
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- Pero apareció un nuevo vecino en nuestra casa: Pilosa. Esta es una nueva base de datos no relacional escrita en Go. Contiene solo índices de mapa de bits y basa todo en ellos. Hablaremos de ella un poco más tarde.
Ir a la implementación
Pero, ¿por qué los índices de mapas de bits se usan tan raramente? Antes de responder esta pregunta, me gustaría demostrarle la implementación de un índice de mapa de bits muy simple en Go.

Los mapas de bits son esencialmente solo piezas de datos. En Go, usemos rebanadas de bytes para esto.
Tenemos un mapa de bits por característica de restaurante, y cada bit en el mapa de bits indica si un restaurante en particular tiene esta propiedad o no.

Necesitaremos dos funciones auxiliares. Uno se usará para llenar nuestros mapas de bits con datos aleatorios. Aleatorio, pero con cierta probabilidad de que el restaurante tenga todas las propiedades. Por ejemplo, creo que hay muy pocos restaurantes en Moscú donde no se puede reservar una mesa, y me parece que aproximadamente el 20% de los establecimientos son aptos para vegetarianos.
La segunda función convertirá el mapa de bits en una lista de restaurantes.


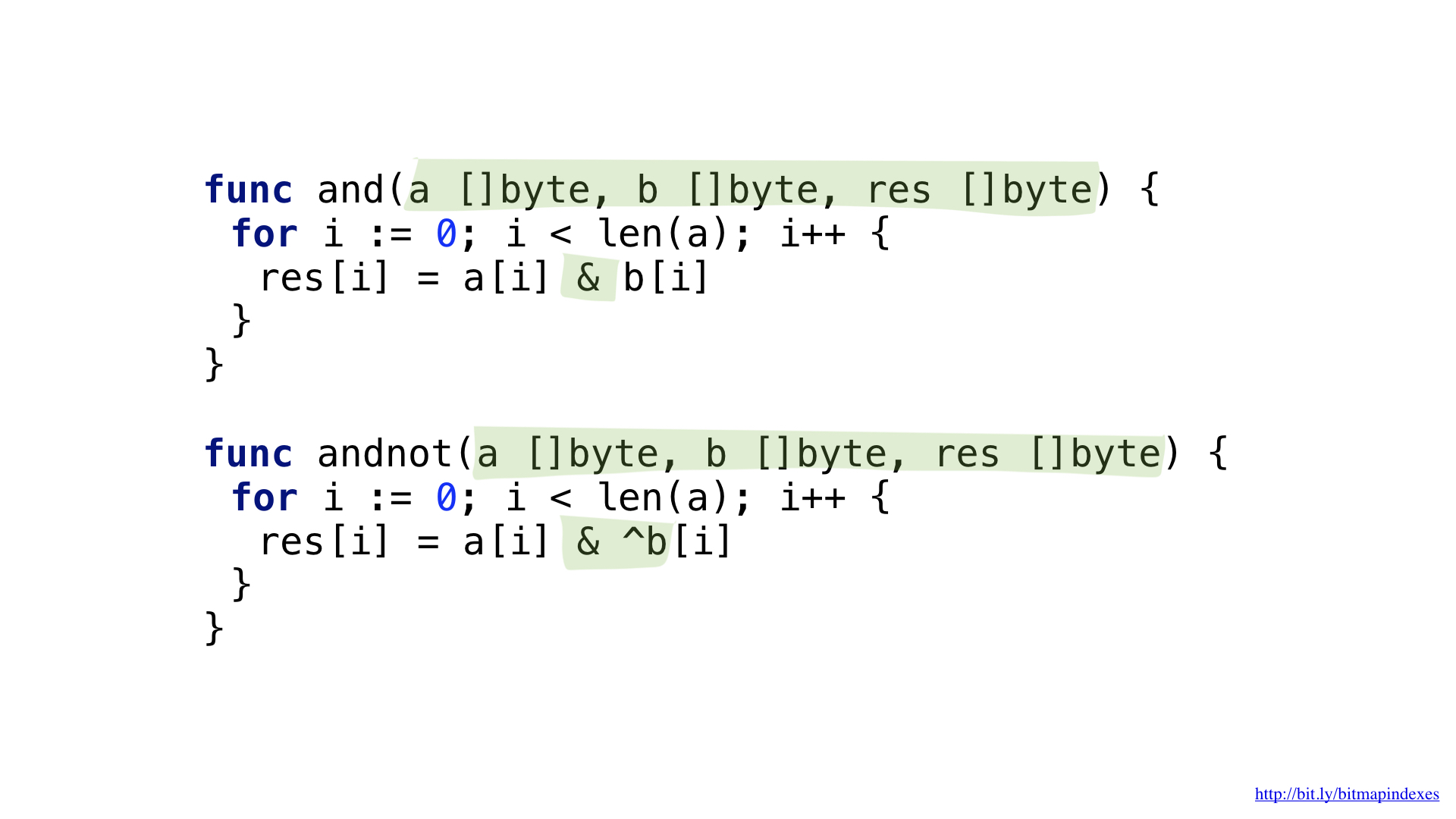
Para responder a la solicitud "Muéstrame restaurantes económicos que tengan una veranda y dónde puedes reservar una mesa", necesitamos operaciones de dos bits: NOT y AND.
Podemos simplificar un poco nuestro código utilizando la operación más compleja Y NO.
Tenemos funciones para cada una de estas operaciones. Ambos pasan por los cortes, toman los elementos correspondientes de cada uno, los combinan con una operación de bits y colocan el resultado en el corte resultante.
Y ahora podemos usar nuestros mapas de bits y funciones para responder a una consulta de búsqueda.

El rendimiento no es tan alto, incluso a pesar del hecho de que las funciones son muy simples y decentemente ahorramos en el hecho de que no devolvimos un nuevo segmento resultante cada vez que se llamó a la función.
Habiendo perfilado un poco con pprof, noté que el compilador Go se perdió una optimización muy simple pero muy importante: la función en línea.
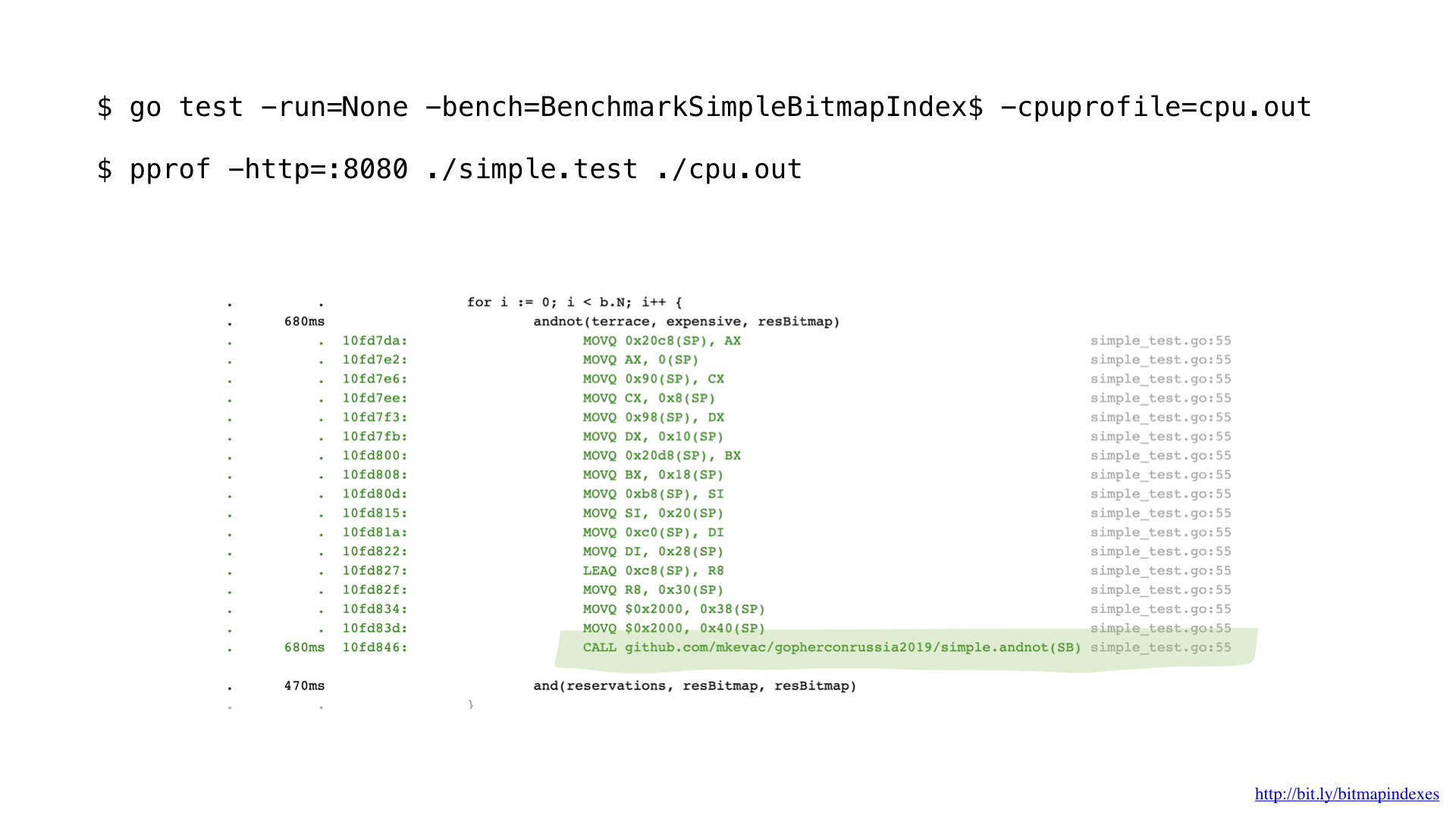
El hecho es que el compilador Go tiene mucho miedo a los bucles que atraviesan sectores, y se niega categóricamente a las funciones en línea que contienen bucles.
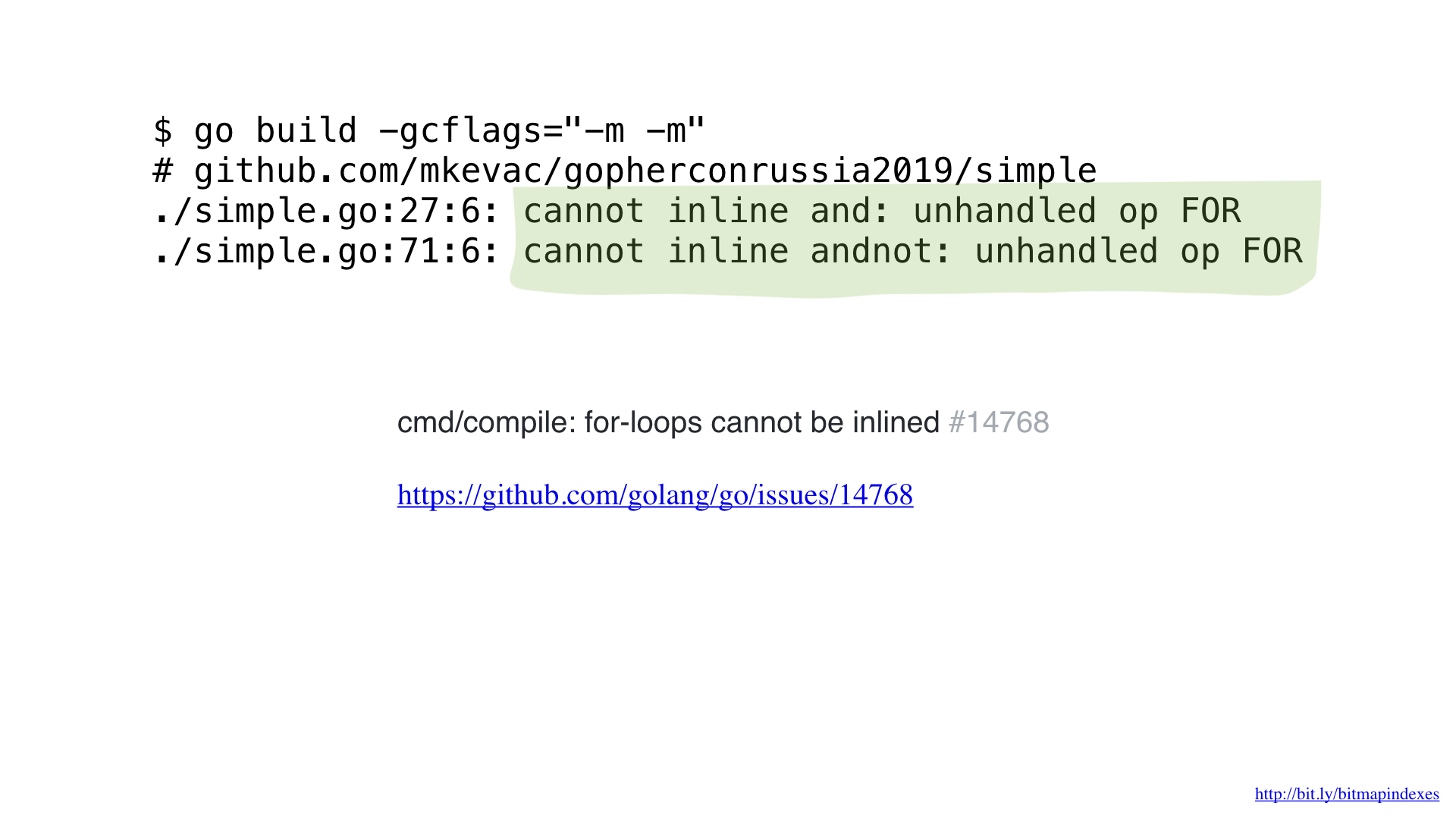
Pero no tengo miedo, y puedo engañar al compilador usando goto en lugar de un bucle, como en los viejos tiempos.


Y, como puede ver, ¡ahora el compilador integra felizmente nuestra función! Como resultado, logramos ahorrar aproximadamente 2 microsegundos. No esta mal!

El segundo cuello de botella es fácil de ver si observa cuidadosamente la salida del ensamblador. El compilador ha agregado la comprobación de la división justo dentro de nuestro bucle más popular. El hecho es que Go es un lenguaje seguro, el compilador teme que mis tres argumentos (tres porciones) tengan diferentes tamaños. Después de todo, habrá una posibilidad teórica de la aparición del llamado desbordamiento del búfer.
Aseguremos al compilador mostrándole que todas las rebanadas son del mismo tamaño. Podemos hacer esto agregando una simple verificación al comienzo de nuestra función.
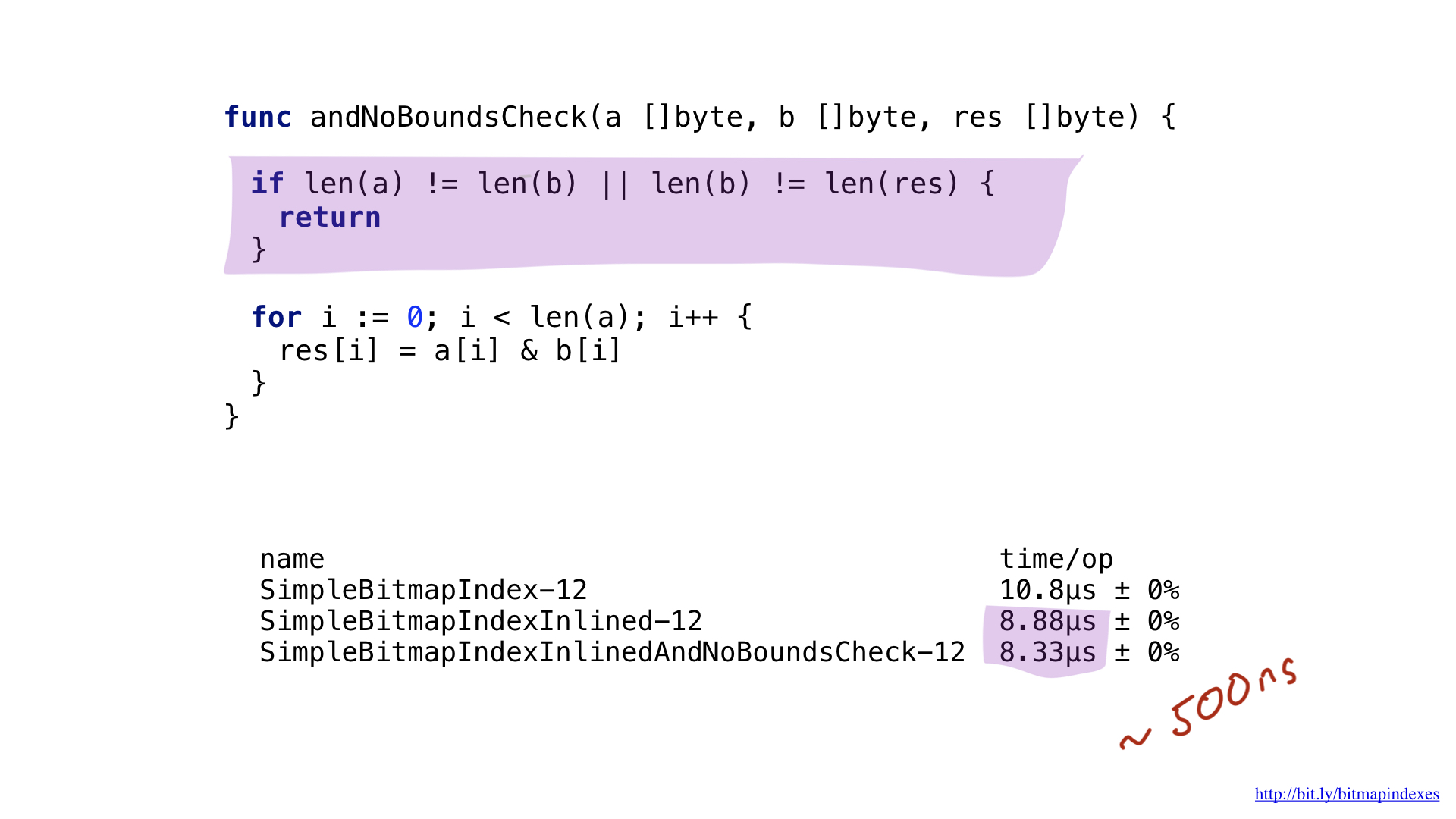
Al ver esto, el compilador felizmente omite la prueba, y terminamos ahorrando otros 500 nanosegundos.
Grandes lotes
De acuerdo, logramos exprimir un poco el rendimiento de nuestra implementación simple, pero este resultado, de hecho, es mucho peor de lo posible con el hardware actual.
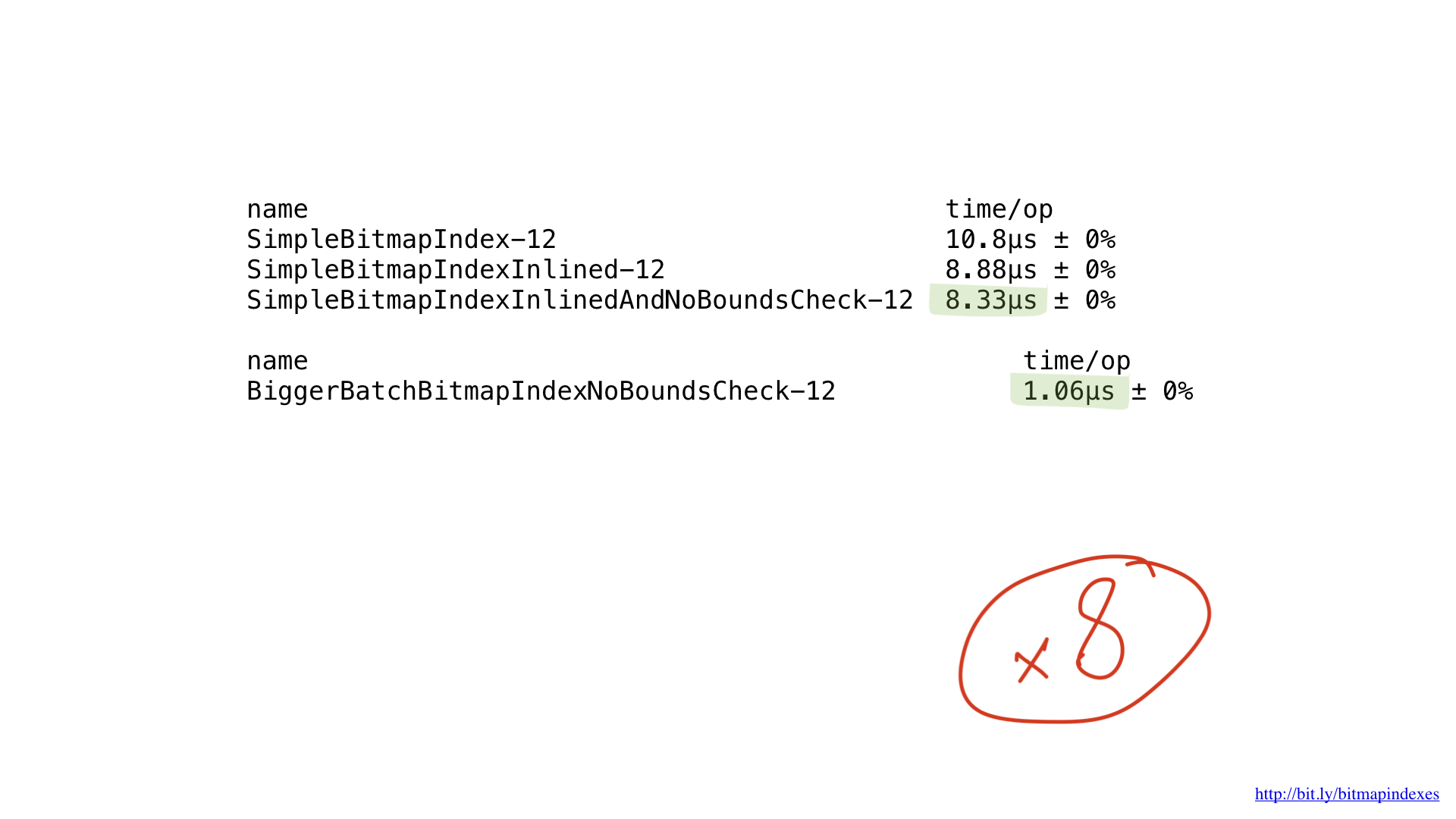
Todo lo que hacemos es operaciones de bits básicas, y nuestros procesadores las realizan de manera muy eficiente. Pero, desafortunadamente, "alimentamos" a nuestro procesador con trabajos muy pequeños. Nuestras funciones realizan operaciones byte a byte. Podemos ajustar fácilmente nuestro código para que funcione con fragmentos de 8 bytes utilizando segmentos UInt64.

Como puede ver, este pequeño cambio ha acelerado nuestro programa ocho veces debido a un aumento en el lote de ocho veces. Se puede decir que la ganancia es lineal.
Implementación de ensamblador

Pero este no es el final. Nuestros procesadores pueden trabajar con piezas de 16, 32 e incluso 64 bytes. Estas operaciones "anchas" se denominan datos múltiples de una sola instrucción (SIMD; una instrucción, muchos datos), y el proceso de transformación del código para que utilice tales operaciones se denomina vectorización.
Desafortunadamente, el compilador Go está lejos de ser un excelente estudiante en vectorización. Actualmente, la única forma de vectorizar código en Go es tomar y poner estas operaciones manualmente usando el ensamblador Go.

Assembler Go es una bestia extraña. Probablemente sepa que el ensamblador es algo que está fuertemente relacionado con la arquitectura de la computadora para la que está escribiendo, pero este no es el caso con Go. El ensamblador Go es más como un IRL (lenguaje de representación intermedio) o un lenguaje intermedio: es prácticamente independiente de la plataforma. Rob Pike hizo una excelente
presentación sobre este tema hace unos años en la GopherCon en Denver.
Además, Go usa el formato inusual del Plan 9, que difiere de los formatos generalmente reconocidos de AT&T e Intel.

Es seguro decir que escribir el ensamblador Go manualmente no es la actividad más divertida.
Pero, afortunadamente, ya hay dos herramientas de alto nivel que nos ayudan a escribir el ensamblador Go: PeachPy y avo. Ambas utilidades generan ensambladores Go a partir de código de nivel superior escrito en Python y Go, respectivamente.

Estas utilidades simplifican cosas como la asignación de registros, los ciclos de escritura y, en general, simplifican el proceso de ingresar al mundo de la programación de ensambladores en Go.
Usaremos avo, por lo que nuestros programas serán programas Go casi normales.

Así es como se ve el ejemplo más simple de un programa avo. Tenemos una función main () que define la función Add () dentro de sí misma, cuyo significado es agregar dos números. Hay funciones auxiliares para obtener parámetros por nombre y obtener uno de los registros de procesador gratuitos y adecuados. Cada operación del procesador tiene una función correspondiente en avo, como se ve en ADDQ. Finalmente, vemos una función auxiliar para almacenar el valor resultante.

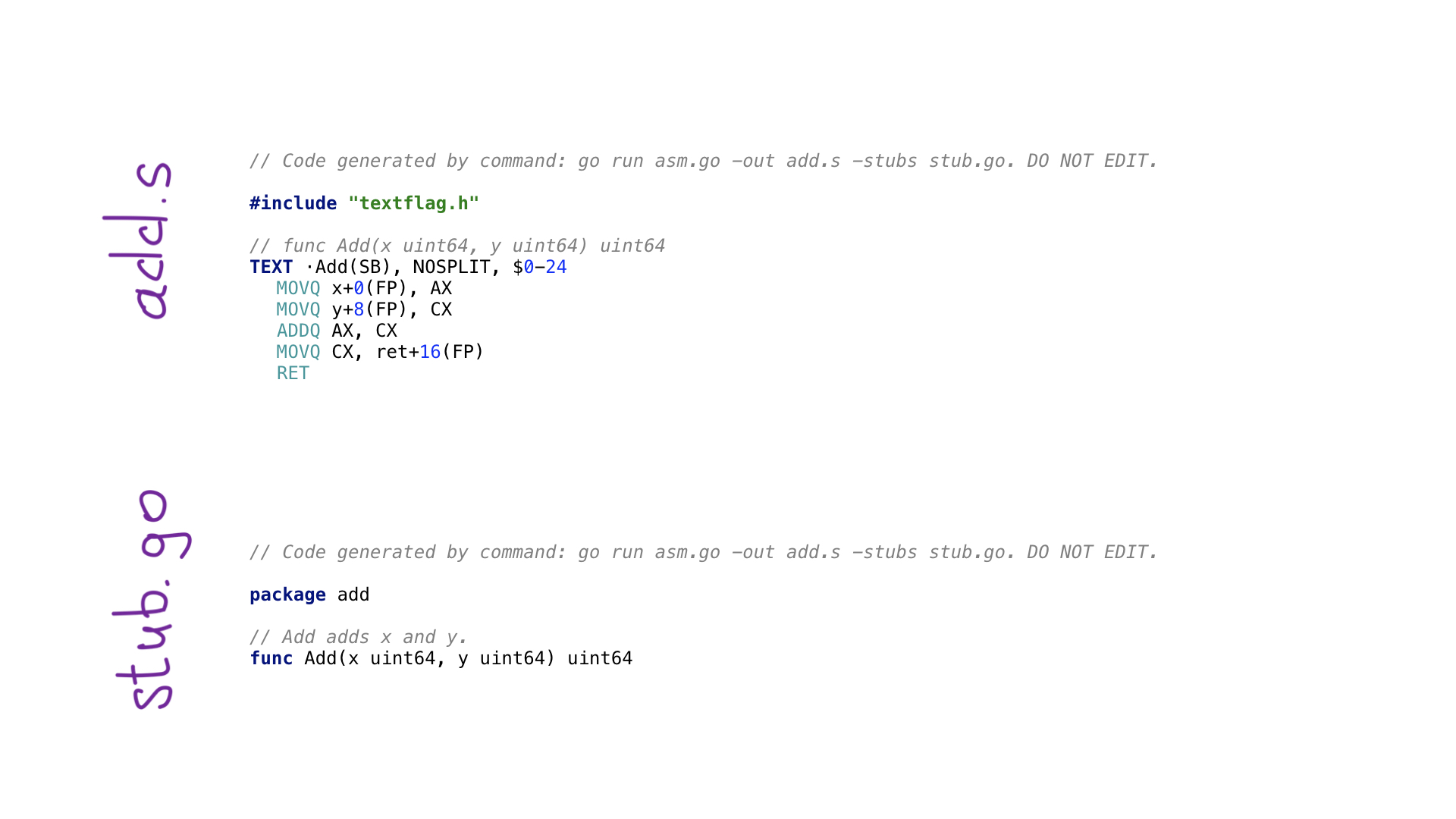
Al llamar a ir a generar, ejecutaremos el programa en avo y al final se generarán dos archivos:
- add.s con el código resultante del ensamblador Go;
- stub.go con encabezados de función para conectar dos mundos: Ir y ensamblador.
Ahora que hemos visto qué y cómo lo hace avo, echemos un vistazo a nuestras funciones. Implementé versiones escalares y vectoriales (SIMD) de funciones.
Primero, mira las versiones escalares.

Como en el ejemplo anterior, le pedimos que nos proporcione un registro gratuito y correcto de uso general, no necesitamos calcular las compensaciones y los tamaños de los argumentos. Todo lo que Avo hace por nosotros.

Anteriormente utilizamos etiquetas y goto (o saltos) para mejorar el rendimiento y engañar al compilador Go, pero ahora lo hacemos desde el principio. El hecho es que los bucles son un concepto de nivel superior. En ensamblador, solo tenemos etiquetas y saltos.

El código restante ya debería ser familiar y comprensible. Emulamos el ciclo con etiquetas y saltos, tomamos una pequeña parte de los datos de nuestros dos segmentos, los combinamos con una operación de bits (Y NO en este caso), y luego colocamos el resultado en el segmento resultante. Eso es todo.

Así es como se ve el código final del ensamblador. No necesitábamos calcular los desplazamientos y los tamaños (resaltados en verde) o realizar un seguimiento de los registros utilizados (resaltados en rojo).
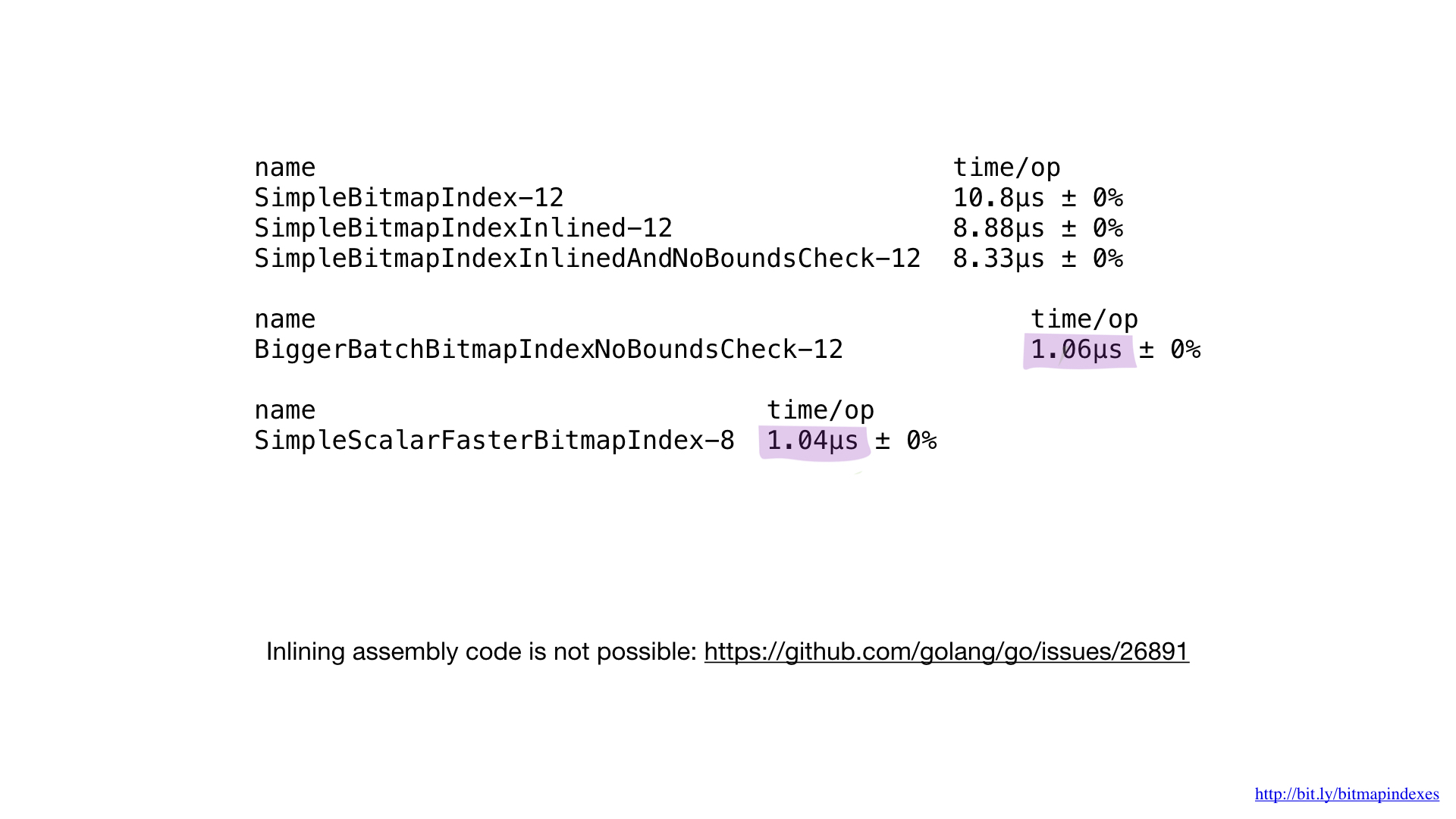
Si comparamos el rendimiento de la implementación en ensamblador con el rendimiento de la mejor implementación en Go, veremos que es lo mismo. Y se espera. Después de todo, no hicimos nada especial, solo reproducimos lo que haría el compilador Go.
Desafortunadamente, no podemos forzar al compilador a que incorpore nuestras funciones escritas en ensamblador. El compilador Go no tiene esta característica hoy en día, aunque la solicitud de agregarla ha existido desde hace bastante tiempo.
Es por eso que es imposible obtener beneficios de pequeñas funciones en ensamblador. Necesitamos escribir funciones grandes, o usar el nuevo paquete matemático / bits, o pasar por alto el lado del ensamblador.
Veamos ahora las versiones vectoriales de nuestras funciones.

Para este ejemplo, decidí usar AVX2, por lo que utilizaremos operaciones que funcionen con fragmentos de 32 bytes. La estructura del código es muy similar a la opción escalar: cargando parámetros, proporciónenos un registro general gratuito, etc.
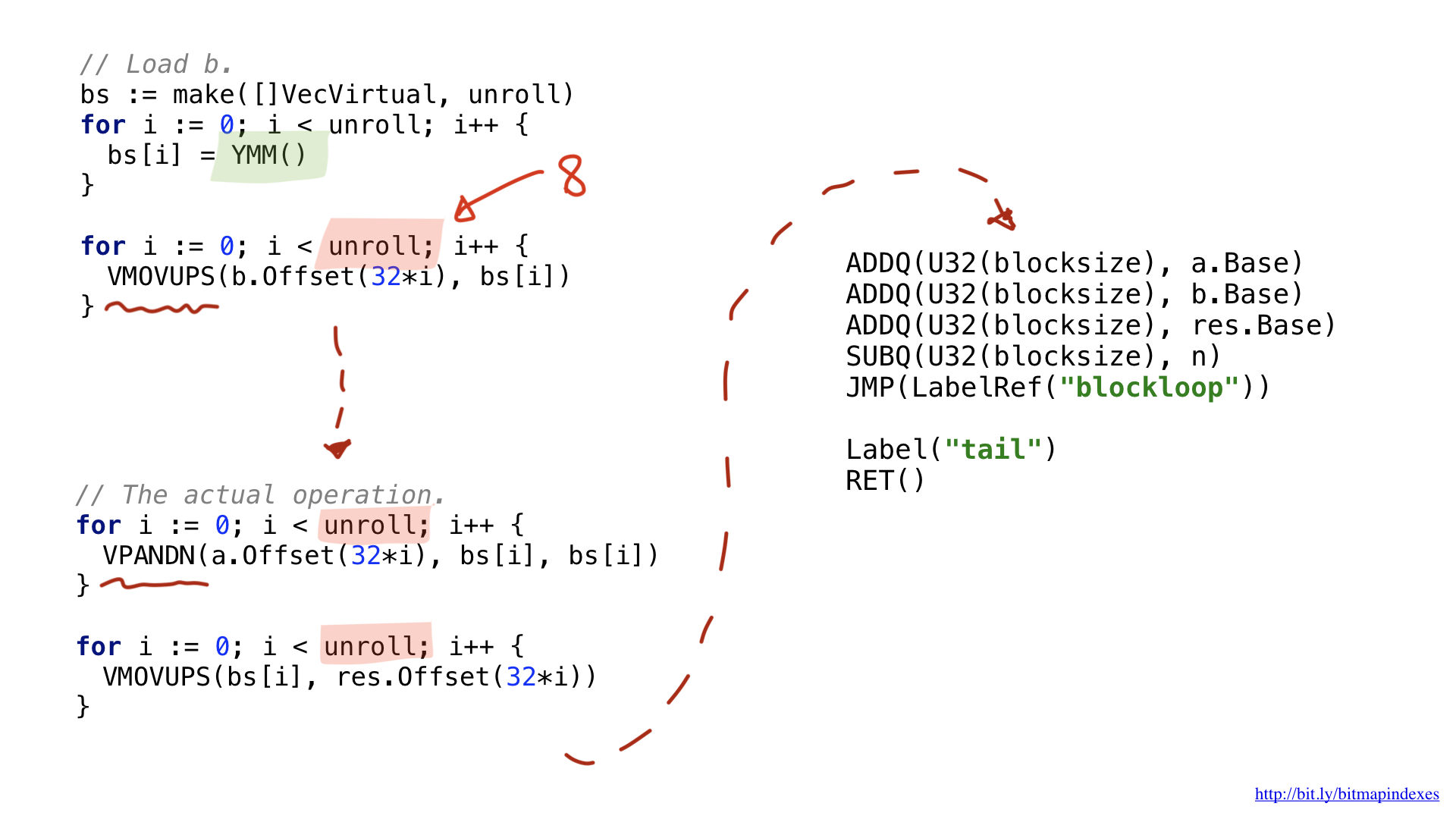
Una de las innovaciones es que las operaciones vectoriales más amplias utilizan registros amplios especiales. En el caso de fragmentos de 32 bytes, estos son registros con el prefijo Y. Es por eso que ve la función YMM () en el código. Si tuviera que usar el AVX-512 con fragmentos de 64 bits, el prefijo sería Z.
La segunda innovación es que decidí usar una optimización llamada desenrollado de bucle, es decir, hacer ocho operaciones de bucle manualmente antes de saltar al inicio del bucle. Esta optimización reduce la cantidad de brunches (ramas) en el código y está limitada por la cantidad de registros libres disponibles.
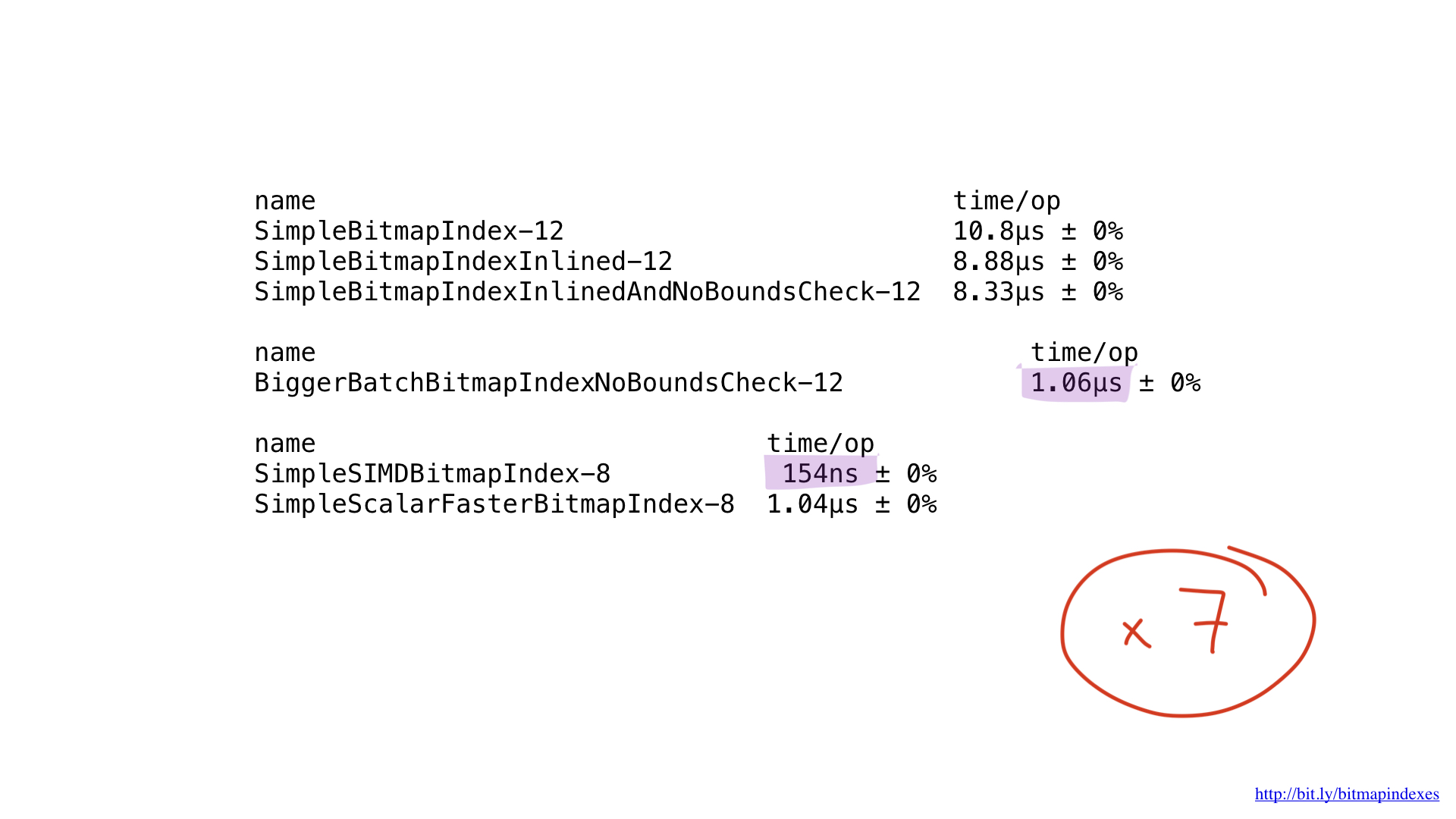
Bueno, ¿qué pasa con el rendimiento? Ella es hermosa Obtuvimos la aceleración unas siete veces en comparación con la mejor solución en Go. Impresionante, ¿eh?
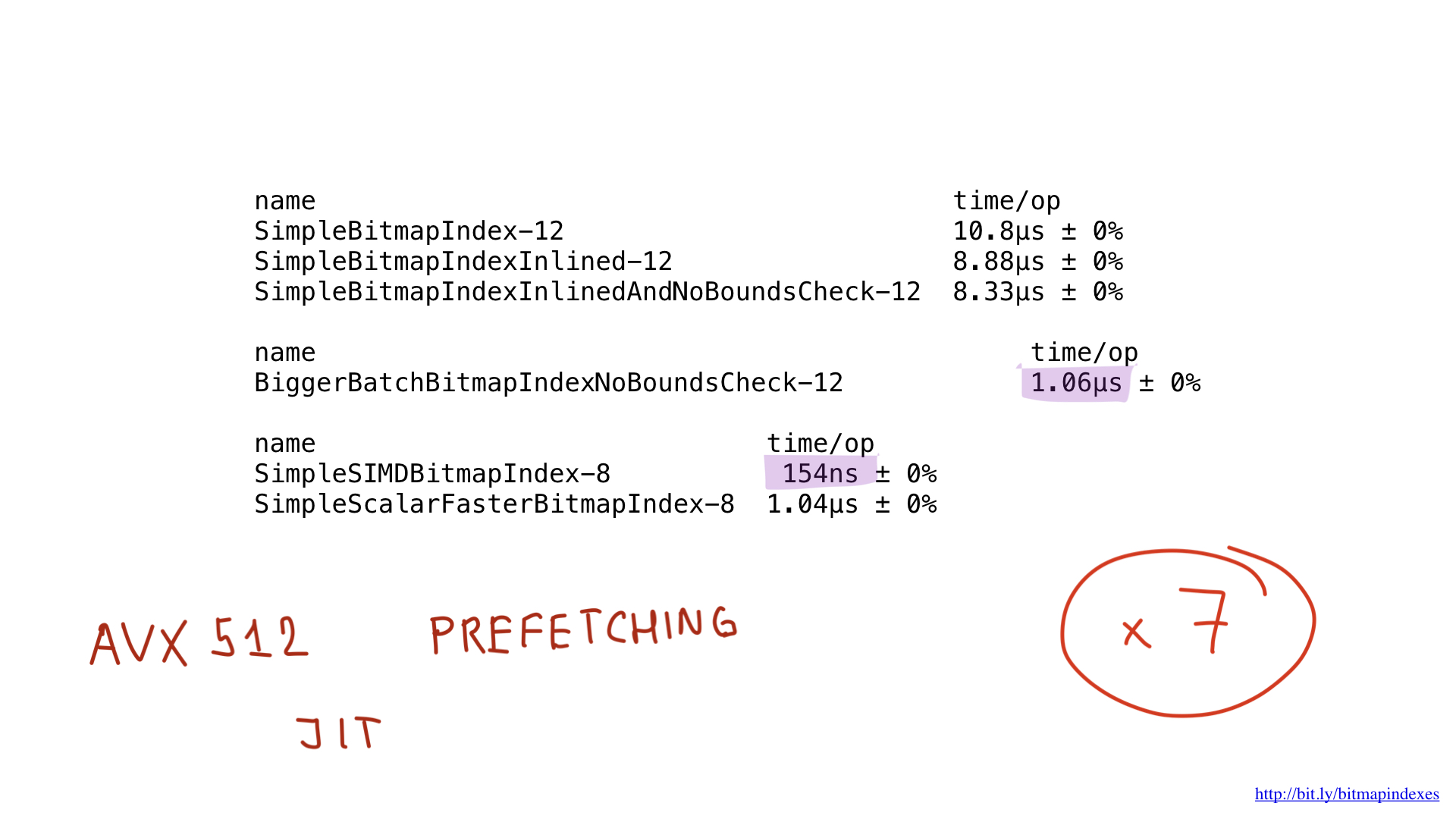
Pero incluso esta implementación podría acelerarse potencialmente utilizando AVX-512, captación previa o JIT (compilador justo a tiempo) para el planificador de consultas. Pero este es ciertamente un tema para un informe separado.
Problemas de índice de mapa de bits
Ahora que ya hemos analizado una implementación simple del índice de mapa de bits Go y un lenguaje ensamblador mucho más eficiente, finalmente hablemos de por qué los índices de mapa de bits se usan tan raramente.

En los antiguos artículos científicos, se mencionan tres problemas de los índices de mapas de bits, pero los artículos científicos más nuevos y yo sostenemos que ya no son relevantes. No profundizaremos en cada uno de estos problemas, pero los consideraremos superficialmente.
El problema de la gran cardinalidad.
Entonces, se nos dice que los índices de mapa de bits son adecuados solo para campos con baja cardinalidad, es decir, aquellos que tienen pocos valores (por ejemplo, género o color de ojos), y la razón es que la representación habitual de tales campos (un bit por valor) en caso de una gran cardinalidad, ocupará demasiado espacio y, además, estos índices de mapa de bits se llenarán débilmente (rara vez).
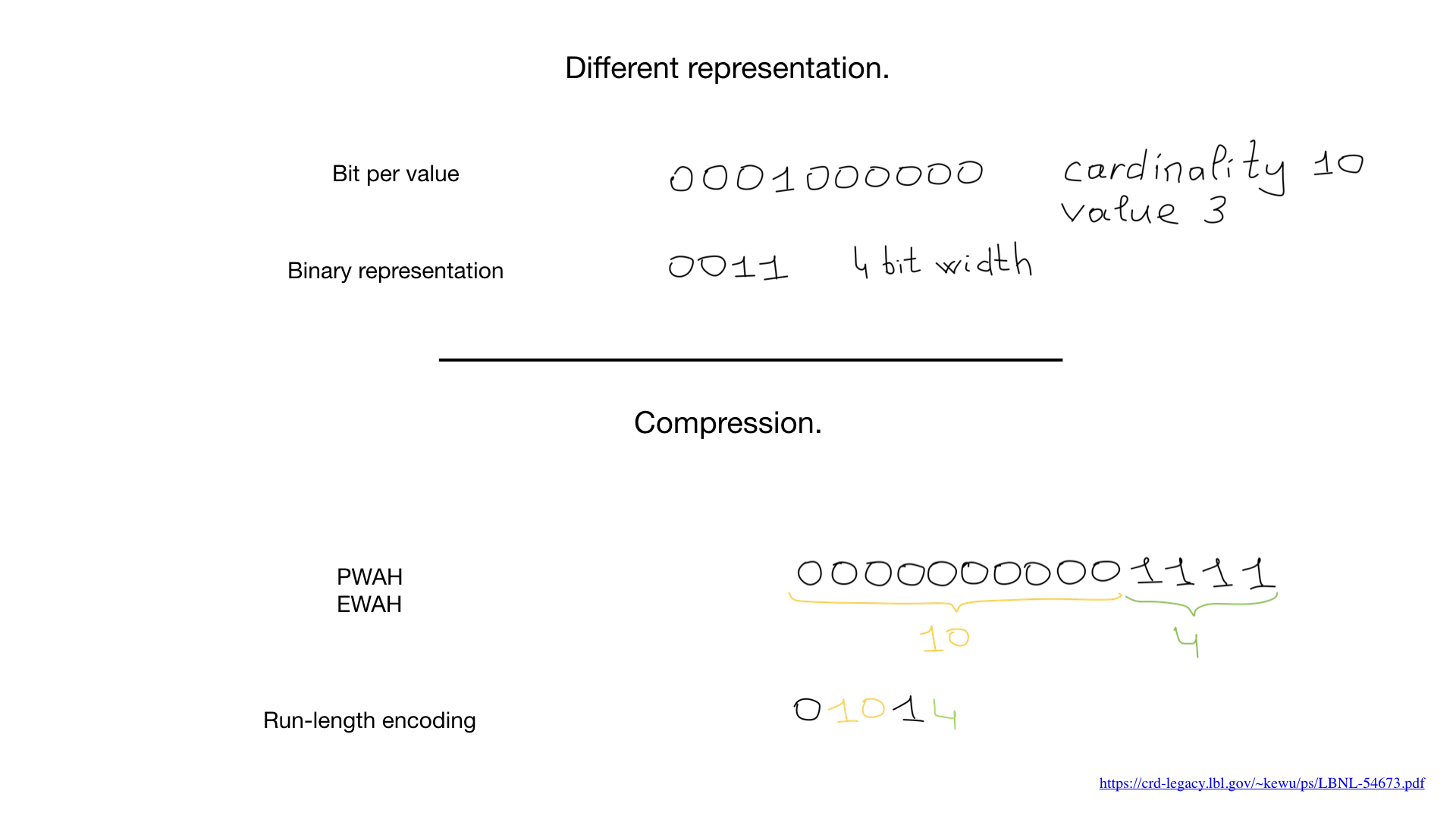 A veces podemos usar otra representación, por ejemplo, la representación estándar, que usamos para representar números. Pero fue la llegada de los algoritmos de compresión lo que lo cambió todo. En las últimas décadas, los científicos e investigadores han creado una gran cantidad de algoritmos de compresión para mapas de bits. Su principal ventaja es que no necesita expandir los mapas de bits para las operaciones de bits: podemos realizar operaciones de bits directamente en mapas de bits comprimidos.
A veces podemos usar otra representación, por ejemplo, la representación estándar, que usamos para representar números. Pero fue la llegada de los algoritmos de compresión lo que lo cambió todo. En las últimas décadas, los científicos e investigadores han creado una gran cantidad de algoritmos de compresión para mapas de bits. Su principal ventaja es que no necesita expandir los mapas de bits para las operaciones de bits: podemos realizar operaciones de bits directamente en mapas de bits comprimidos. Recientemente, han comenzado a aparecer enfoques híbridos, como mapas de bits rugientes. Simultáneamente utilizan tres representaciones diferentes para mapas de bits, en realidad mapas de bits, matrices y las llamadas ejecuciones de bits, y equilibran entre ellos para maximizar el rendimiento y minimizar el consumo de memoria.
Recientemente, han comenzado a aparecer enfoques híbridos, como mapas de bits rugientes. Simultáneamente utilizan tres representaciones diferentes para mapas de bits, en realidad mapas de bits, matrices y las llamadas ejecuciones de bits, y equilibran entre ellos para maximizar el rendimiento y minimizar el consumo de memoria.roaring . , Go.
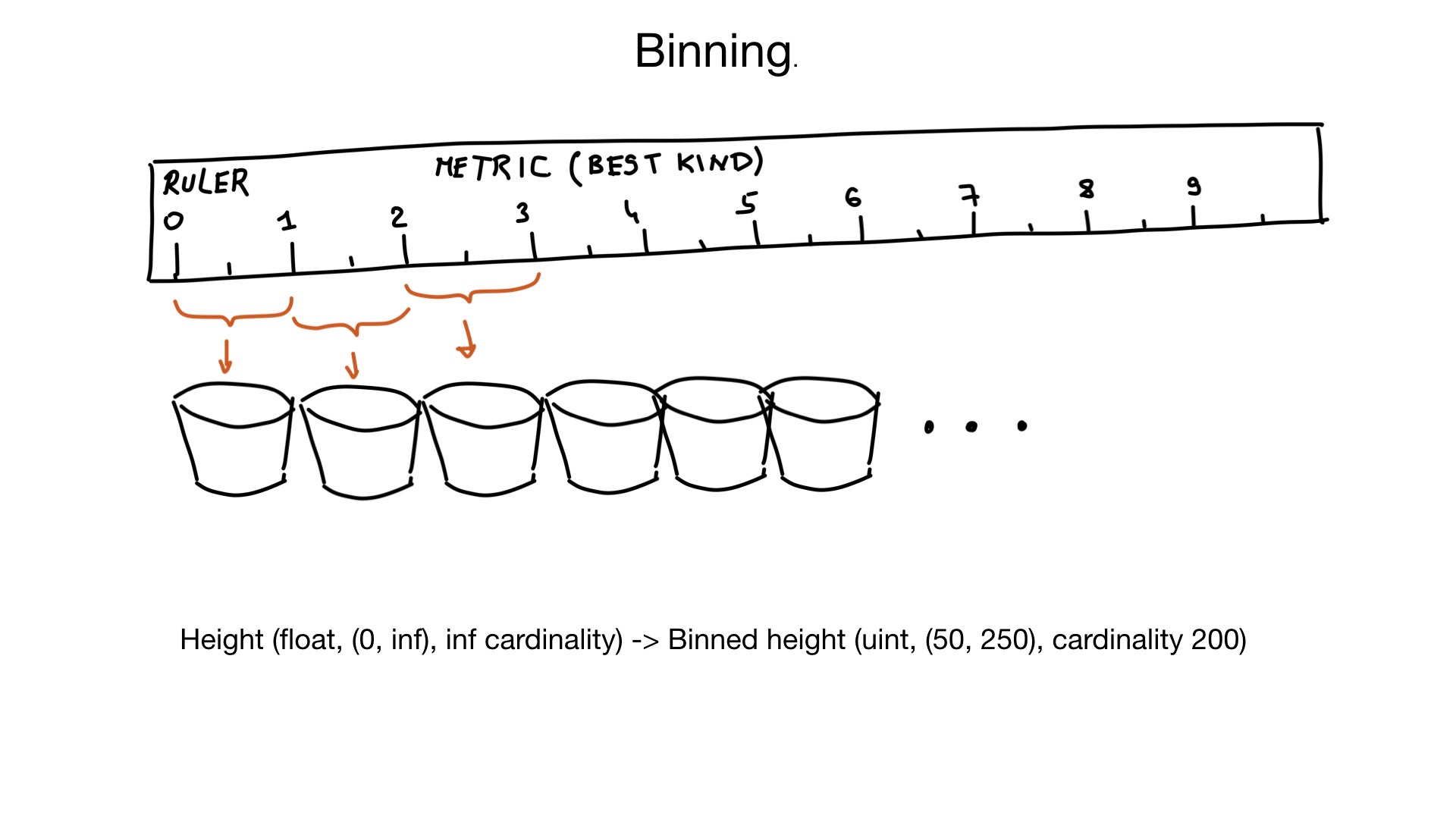
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
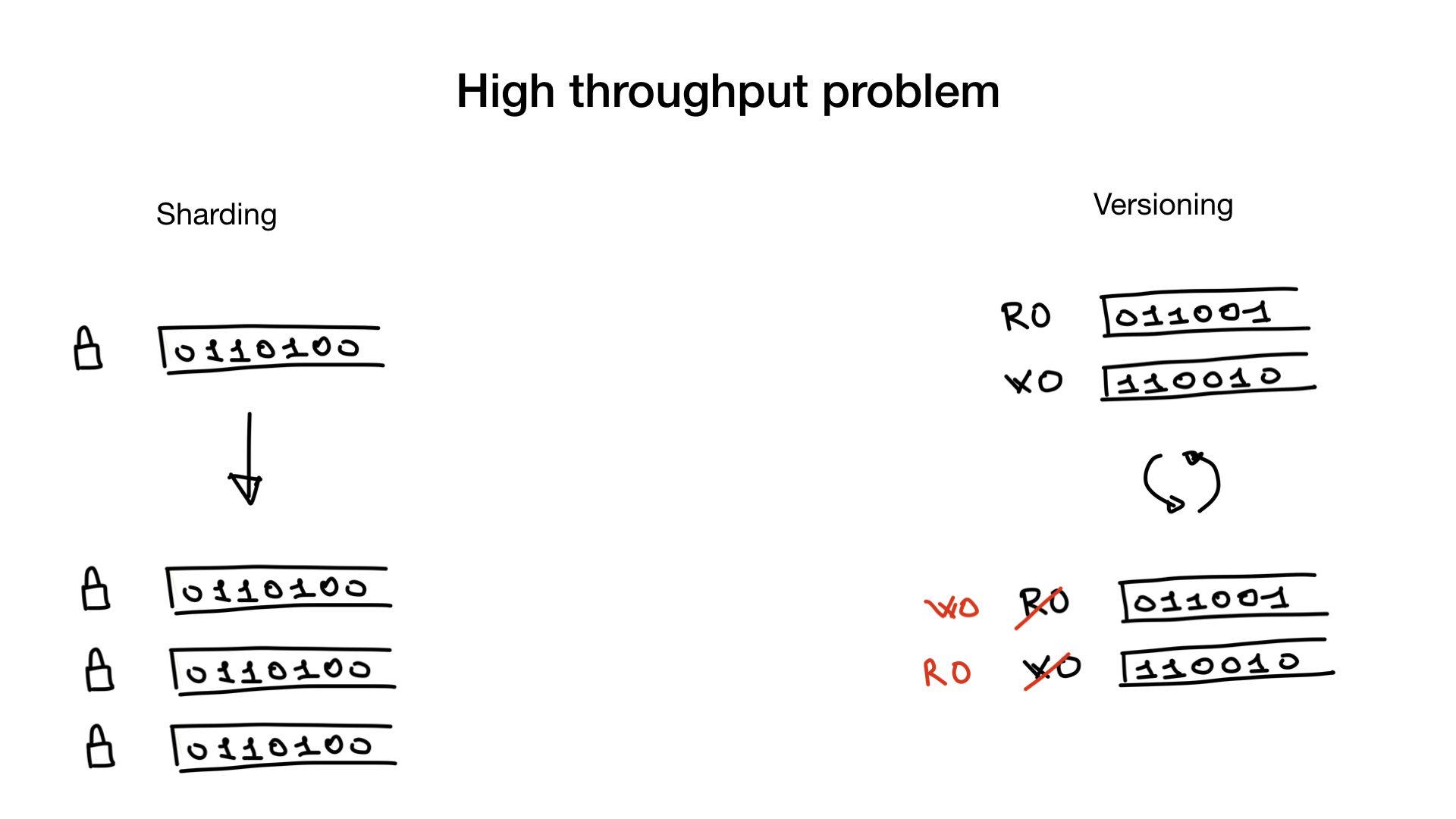
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . Y así sucesivamente.
, , . , 300 , , 199 . Listo

, bitmap-. , , . , S2 Google. , . « » ( ).
Soluciones confeccionadas
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
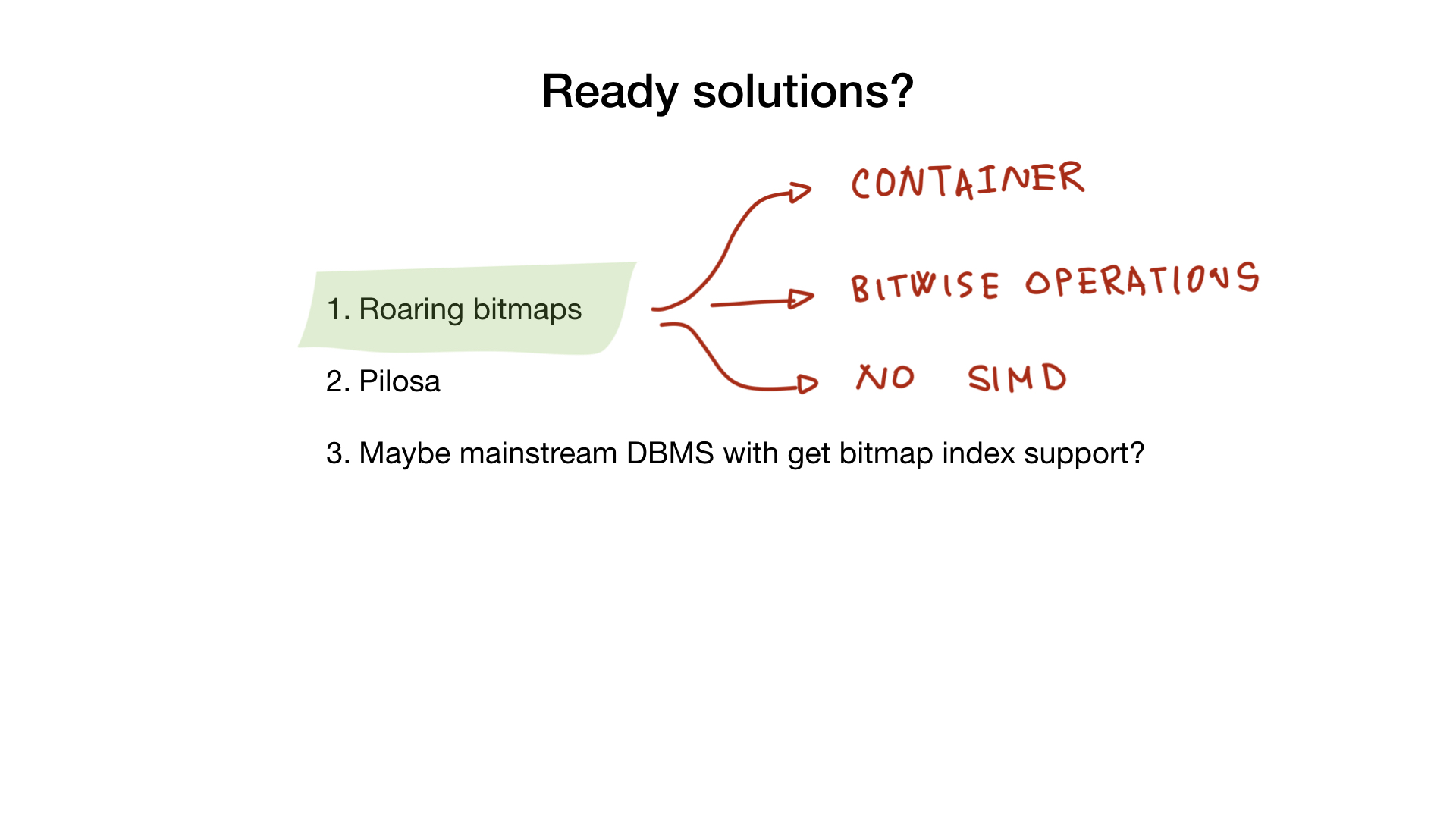
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
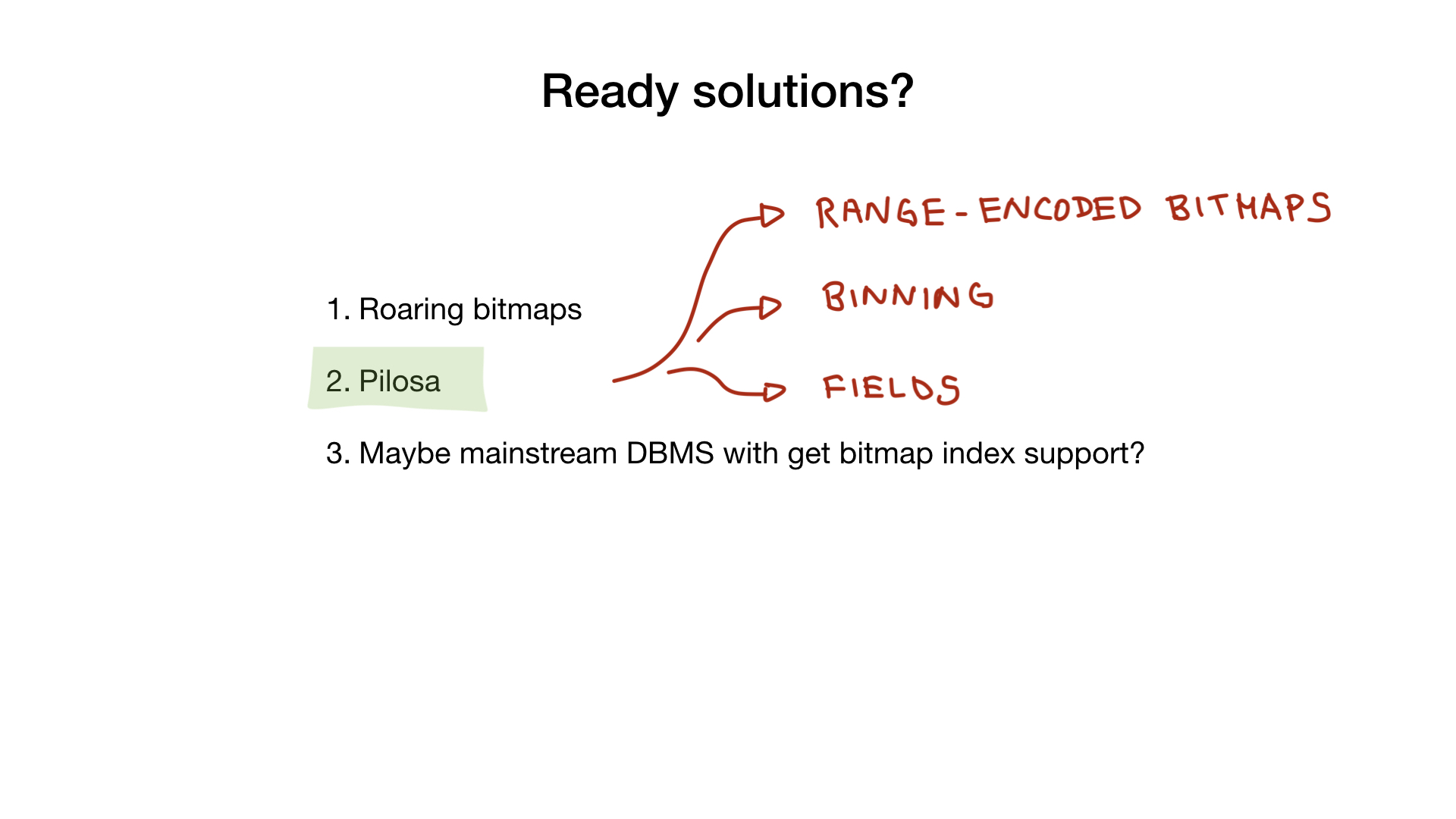
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
Después de eso, usamos NO en el campo "costoso", luego intersectamos el resultado (o AND) con el campo "terraza" y el campo "reservas". Y finalmente, obtenemos el resultado final. Realmente espero que en el futuro previsible en DBMS como MySQL y PostgreSQL este nuevo tipo de índices también aparezca: índices de mapa de bits.
Realmente espero que en el futuro previsible en DBMS como MySQL y PostgreSQL este nuevo tipo de índices también aparezca: índices de mapa de bits.
Conclusión

Si aún no te has quedado dormido, gracias. Tuve que tocar muchos temas de pasada debido a la cantidad limitada de tiempo, pero espero que el informe haya sido útil y, quizás, incluso motivador.
Es bueno saber acerca de los índices de mapas de bits, incluso si no los necesita en este momento. Deja que sean otra herramienta en tu cajón.
Hemos cubierto varios trucos de rendimiento para Go y las cosas con las que el compilador Go no funciona muy bien. Pero es absolutamente útil que todo programador de Go lo sepa.
Eso es todo lo que quería decir. Gracias