Una lección introductoria gratuita es la función de Skyeng School. Un estudiante potencial puede familiarizarse con la plataforma, verificar su nivel de inglés y, finalmente, divertirse. Para la escuela, la lección introductoria es parte del embudo de ventas, seguida del primer pago. Lo lleva a cabo un metodólogo introductorio de la lección: una persona especial que combina un maestro y un vendedor, su tiempo se paga independientemente de si el cliente compró el primer paquete o no, y de si apareció para la lección. El absentismo es una ocurrencia muy común debido a que el precio de una lección se vuelve demasiado alto.
En este artículo, describiremos cómo, con la ayuda del modelo analítico y la experiencia de las aerolíneas, pudimos reducir los costos de la lección introductoria a casi la mitad.
El embudo de ventas de Skyeng consta de cinco pasos: registrarse en el sitio, llamar a la primera línea de ventas con una entrada a la lección introductoria, lección introductoria, llamar a la segunda línea de ventas, pagar el primer paquete. Anteriormente, después de la primera llamada, establecimos un tiempo de lección para un metodólogo particular de lecciones introductorias, que estaba esperando al estudiante en ese momento. Si una persona se ha registrado y no ha venido, el metodólogo está malgastando su tiempo y la escuela está malgastando dinero para pagar este tiempo. El absentismo ocurre en promedio en la mitad de los casos; un tercio de los clientes compra el primer paquete después de una lección introductoria. Por lo tanto, la conversión de la grabación a una lección introductoria en pago es de solo 0.15. Una exitosa lección introductoria (convertida en pago) en el antiguo esquema nos costó 4.000 rublos, y tuvimos que hacer algo al respecto.
Simplemente puede rechazarlo, pero en este caso, la conversión final de plomo a pago disminuirá significativamente, lo que no nos conviene. Tendremos que buscar otra solución, construir modelos, contar y experimentar.
Primer panqueque
Pasamos a la experiencia de las aerolíneas, específicamente a la práctica de la sobreventa. Los transportistas saben que el 100% de los pasajeros que han comprado un boleto rara vez están en un vuelo, y aprovechan esto vendiendo más boletos que asientos en el avión. Si de repente todos los pasajeros llegan para aterrizar, puede encontrar voluntarios entre ellos que estén listos para volar para el próximo bollo en el próximo vuelo. Las aerolíneas aumentan así sus ganancias, y podemos reducir los costos por un método similar.
Entonces: rechazamos el registro a una persona específica, creamos un grupo de metodólogos de la lección introductoria, dispersamos las aplicaciones entre ellos con la expectativa de que la mitad no aparezca. Y si ha llegado más, le sugerimos que se registre para otro día. Lanzamos tal MVP en la prueba e inmediatamente nos dimos cuenta de que habíamos hecho todo mal.
La mitad de los que ingresan a la lección introductoria son estadísticas, en realidad, la proporción varía mucho según la hora, el día y el canal de donde vino la persona. Además, más del 80% de los estudiantes potenciales, en respuesta a una propuesta para posponer la lección, se caen inmediatamente o no llegan al segundo registro. Todo esto podría llevar al hecho de que en los días malos perderíamos hasta un tercio de los clientes. La prueba se apagó y se hizo todo de manera inteligente.
Modelo, pronósticos, polinomios.
En primer lugar, era necesario averiguar de qué depende la proporción de los que van a la lección introductoria. La primera observación es que depende del canal de comercialización de donde vino la persona. Dividimos estos canales desde el punto de vista de la conversión en pago en "caliente", donde la conversión es más alta, "cálida" y "fría", donde es más baja; Resultó que la "temperatura del canal" afecta la conversión a la salida de la lección introductoria de la misma manera.
Continuando con la analogía de la aviación, hicimos diferentes "mostradores de facturación" para los cables de diferentes canales, colocándolos con coeficientes correspondientes a la probabilidad histórica de que este canal salga: 0.8, 0.4 y 0.2. Para los canales "calientes", asignamos más metodólogos, "fríos", menos. Esto funcionó mejor, pero aún en los días malos hubo más del 20% de "salidas" (situaciones en las que más clientes asistieron a la lección introductoria que los metodólogos gratuitos). Intentaron aumentar los coeficientes agregando un margen de 0.1: por un lado, cuanto más sacamos a los metodólogos, menos perdemos clientes, por otro, los costos de llevar a cabo lecciones introductorias están creciendo.
A partir de estas observaciones, creció el segundo MVP. Para cada inscrito, hacemos un pronóstico de la probabilidad de que él vaya a una lección introductoria. Realizamos una distribución de probabilidad conjunta y un intervalo de confianza con un nivel de confianza del 95%. Para casos raros en los que salen más clientes de lo planeado, tenemos un grupo de reserva de metodólogos, maestros que actualmente se dedican a trabajos no urgentes, como la verificación de ensayos.
Para calcular el pronóstico para un estudiante en particular, creamos un modelo estadístico basado en nuestros datos históricos y teniendo en cuenta varios factores: canal, región, niño / adulto, cliente privado / corporativo, tiempo desde la grabación hasta la lección introductoria.
El modelo funciona con los siguientes conceptos:
- espacio : fecha y hora de la lección introductoria;
- factor de corrección : la probabilidad de una salida anormal en este día y hora;
- peso de la aplicación : probabilidad admisible de salida de un cliente determinado;
- Salida : aplicación no servida (el cliente salió, todos los metodólogos están ocupados);
- Metodólogo simple : resultó menos de lo previsto, la gente está inactiva;
- restricción :% en el intervalo de confianza, después del cual el modelo prohíbe agregar pedidos a la ranura.
Cada ranura contiene N metodólogos, y la ranura en sí tiene un factor de corrección k (con una base de 100). El número de metodólogos disponibles para el modelo se define como redondo (N * k / 100). Cuando aparece una aplicación, el modelo determina su peso , observa la suma de dichos pesos que ya están en la ranura y determina la ranura como disponible si, como resultado de agregar esta aplicación, la suma de los pesos de la aplicación en la ranura no excede el número de metodólogos. Las métricas para evaluar el modelo son: la proporción de salidas (necesarias para minimizar), la carga de espacios (maximizada), el tiempo de espera para la lección introductoria por parte del cliente (minimizado). Los parámetros variables del modelo incluyen el peso y la restricción de la aplicación .
Para predecir cuántos clientes se liberarán, se utilizó la fórmula para el producto de probabilidades:

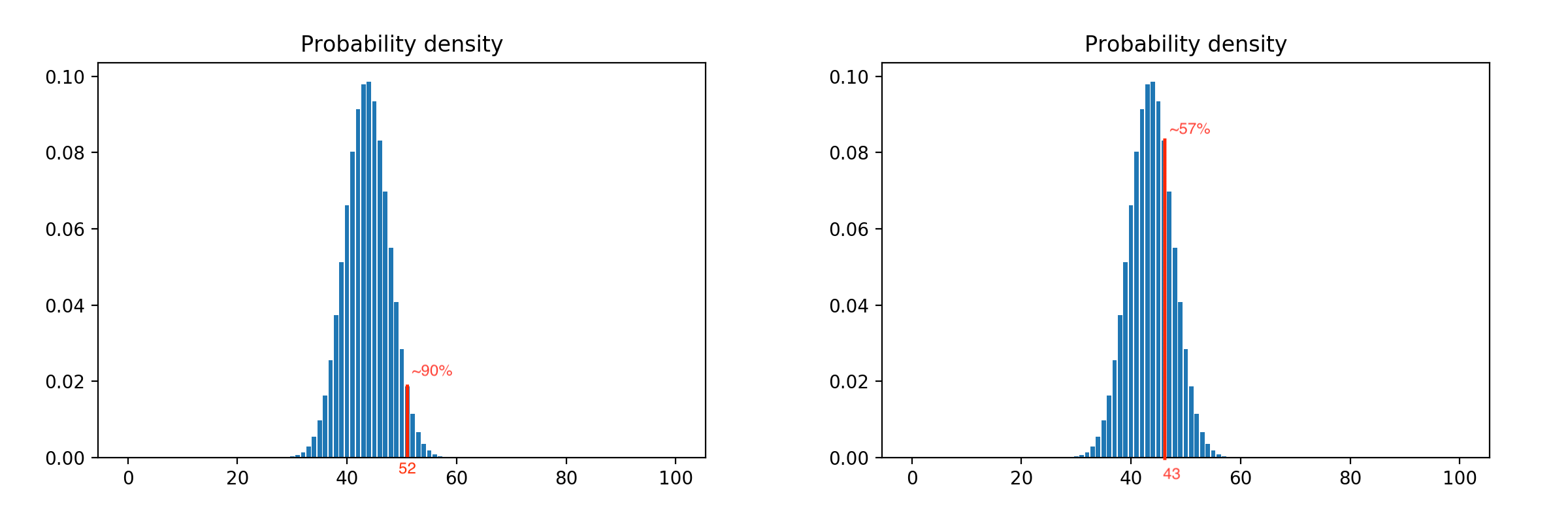
Considerando todas las combinaciones posibles de salidas, obtenemos una distribución de probabilidad muy cercana a la natural. La distribución para cien clientes se ve así:

Aplicando el intervalo de confianza, podemos ajustar la agresividad del modelo. Por ejemplo, desplazar la restricción hacia la izquierda la aumenta, es decir liberamos más clientes con el mismo número de metodólogos, y un cambio a la derecha lo reduce, porque La restricción se activa antes. Ejemplo con restricciones del 90% y 57%:
Además, la agresividad del modelo se puede ajustar mediante un factor de corrección: una disminución lo reduce, un aumento lo aumenta. Esto es útil cuando sabemos que en un día / hora específico, ciertos factores externos pueden provocar la anormalidad.
La fórmula con multiplicación de probabilidades se mostró bien en las pruebas, pero fue difícil desde el punto de vista computacional, por lo que la reescribimos con polinomios:

Las desventajas del modelo incluyen:
- debido al hecho de que se basa en datos históricos, no responde bien a cambios repentinos en la salida;
- Si el metodólogo tiene un evento de fuerza mayor y se retira de la ranura, esta es una partida casi garantizada, los gerentes deben reasignar la lección con urgencia;
- Si la marca dinámica del "calor" de los canales cae, el modelo estima incorrectamente la probabilidad de que el cliente salga.
Como resultado de usar este modelo, recibimos hasta un 45% de ahorro en costos en la lección introductoria con una pérdida mínima para los clientes.
¿Por qué no el aprendizaje automático?
Debido a que el modelo estadístico funciona bastante bien, y en lugar de mejorar la precisión de un pronóstico existente utilizando ML, es más rentable dirigir los esfuerzos de los desarrolladores de ML a otras tareas.
Por ejemplo, estamos desarrollando un sistema de puntuación para un cliente potencial, remotamente similar a uno bancario. Utilizando la puntuación, los bancos determinan la probabilidad de reembolso de un préstamo, y podemos determinar la probabilidad de un primer pago. Si es muy bajo, no hay necesidad de gastar recursos en organizar una lección introductoria; si, por el contrario, es muy alto, puede enviar inmediatamente al cliente a la página de pago.
Pero esta historia es para otro momento.