Ya hemos discutido el
motor de indexación PostgreSQL, la interfaz de los métodos de acceso y los principales métodos de acceso, tales como:
índices hash ,
árboles B ,
GiST ,
SP-GiST y
GIN . En este artículo, veremos cómo la ginebra se convierte en ron.
Ron
Aunque los autores afirman que la ginebra es un genio poderoso, el tema de las bebidas finalmente ha ganado: la próxima generación de GIN se ha llamado RUM.
Este método de acceso amplía el concepto que subyace a GIN y nos permite realizar búsquedas de texto completo aún más rápido. En esta serie de artículos, este es el único método que no se incluye en una entrega estándar de PostgreSQL y es una extensión externa. Hay varias opciones de instalación disponibles para ello:
- Tome el paquete "yum" o "apt" del repositorio PGDG . Por ejemplo, si instaló PostgreSQL desde el paquete "postgresql-10", también instale "postgresql-10-rum".
- Construya a partir del código fuente en github e instálelo usted mismo (la instrucción también está allí).
- Úselo como parte de Postgres Pro Enterprise (o al menos lea la documentación desde allí).
Limitaciones de la ginebra
¿Qué limitaciones de GIN nos permite RUM trascender?
Primero, el tipo de datos "tsvector" contiene no solo lexemas, sino también información sobre sus posiciones dentro del documento. Como observamos la
última vez , el índice GIN no almacena esta información. Por esta razón, las operaciones para buscar frases, que aparecieron en la versión 9.6, son compatibles con el índice GIN de manera ineficiente y tienen que acceder a los datos originales para volver a verificar.
En segundo lugar, los sistemas de búsqueda generalmente devuelven los resultados ordenados por relevancia (lo que sea que eso signifique). Podemos utilizar las funciones de clasificación "ts_rank" y "ts_rank_cd" para este fin, pero deben calcularse para cada fila del resultado, lo que sin duda es lento.
Para una primera aproximación, el método de acceso RUM puede considerarse como GIN que además almacena información de posición y puede devolver los resultados en el orden necesario (como
GiST puede devolver los vecinos más cercanos). Movámonos paso a paso.
Buscando frases
Una consulta de búsqueda de texto completo puede contener operadores especiales que tengan en cuenta la distancia entre lexemas. Por ejemplo, podemos encontrar documentos en los que "mano" se separa de "muslo" con dos palabras más:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
O podemos indicar que las palabras deben ubicarse una tras otra:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
El índice GIN normal puede devolver los documentos que contienen ambos lexemas, pero podemos verificar la distancia entre ellos solo mirando tsvector:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
En el índice RUM, cada lexema no solo hace referencia a las filas de la tabla: cada TID se suministra con la lista de posiciones donde se produce el lexema en el documento. Así es como podemos imaginar el índice creado en la tabla "hoja de corte", que ya nos es bastante familiar (la clase de operador "rum_tsvector_ops" se usa para tsvector por defecto):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
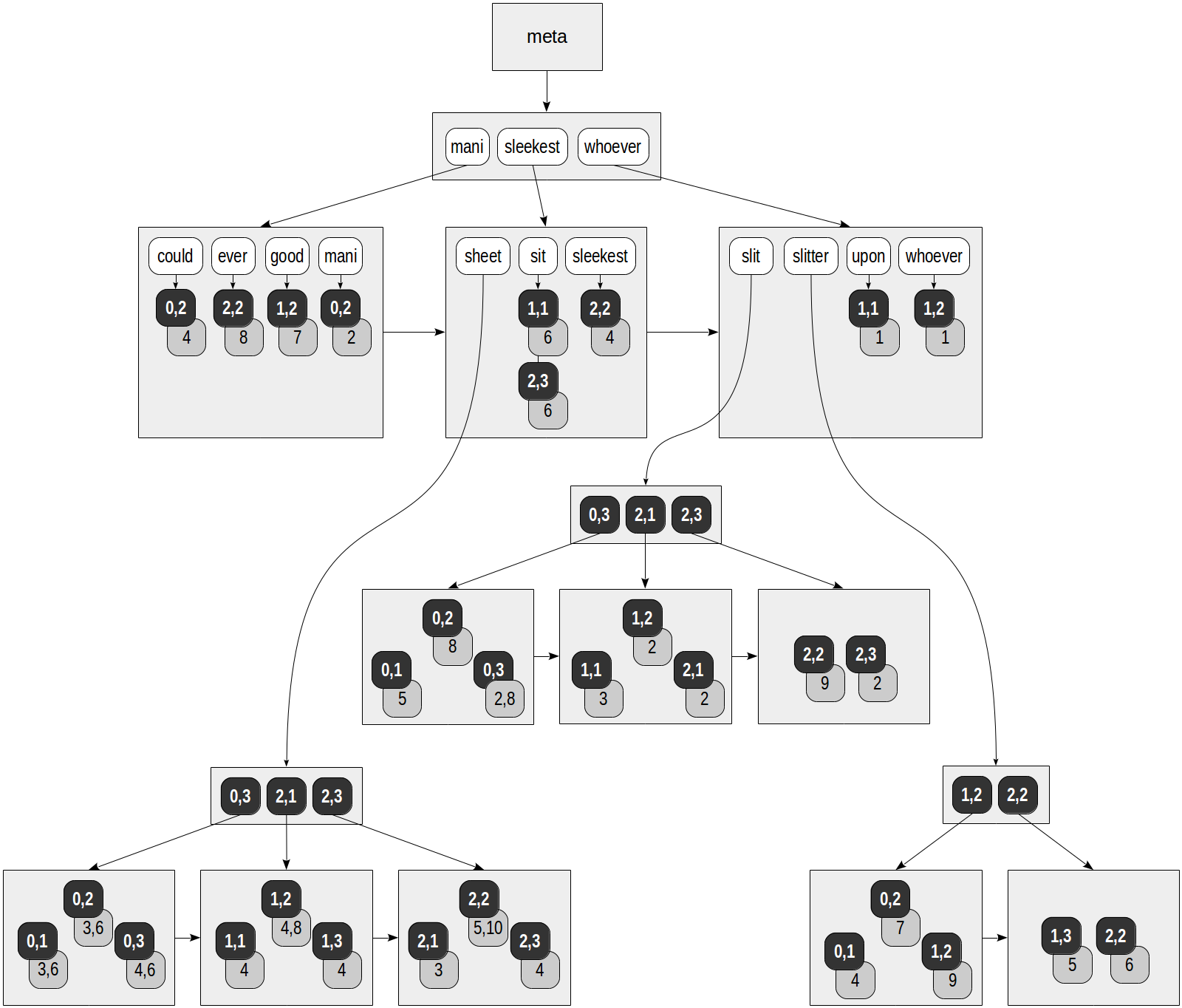
Los cuadrados grises en la figura contienen la información de posición agregada:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
GIN también proporciona una inserción pospuesta cuando se especifica el parámetro "fastupdate"; Esta funcionalidad se elimina de RUM.
Para ver cómo funciona el índice en los datos en vivo, usemos el
archivo familiar de la lista de correo pgsql-hackers.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
Así es como se realiza una consulta que usa la búsqueda de frases con el índice GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
Como podemos ver en el plan, se utiliza el índice GIN, pero devuelve 1776 coincidencias potenciales, de las cuales quedan 259 y 1517 se eliminan en la etapa de verificación.
Eliminemos el índice GIN y creemos RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
El índice ahora contiene toda la información necesaria, y la búsqueda se realiza con precisión:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
Ordenar por relevancia
Para devolver documentos fácilmente en el orden necesario, el índice RUM admite operadores de pedidos, que discutimos en el artículo relacionado con
GiST . La extensión RUM define dicho operador,
<=> , que devuelve cierta distancia entre el documento ("tsvector") y la consulta ("tsquery"). Por ejemplo:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
El documento parecía ser más relevante para la primera consulta que para la segunda: cuanto más a menudo aparece la palabra, menos "valiosa" es.
Intentemos nuevamente comparar GIN y RUM en un tamaño de datos relativamente grande: seleccionaremos los diez documentos más relevantes que contienen "hola" y "piratas informáticos".
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
El índice GIN devuelve 1776 coincidencias, que luego se ordenan como un paso separado para seleccionar los diez mejores éxitos.
Con el índice RUM, la consulta se realiza mediante un escaneo de índice simple: no se examinan documentos adicionales y no se requiere una clasificación por separado:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
Información adicional
El índice RUM, así como el GIN, se pueden construir en varios campos. Pero mientras GIN almacena lexemas de cada columna independientemente de los de otra columna, RUM nos permite "asociar" el campo principal ("tsvector" en este caso) con uno adicional. Para hacer esto, necesitamos usar una clase de operador especializada "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
Podemos usar este índice para devolver los resultados ordenados en el campo adicional:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
Aquí buscamos que las filas coincidentes estén lo más cerca posible de la fecha especificada, sin importar antes o después. Para obtener los resultados que son estrictamente anteriores (o siguientes) a la fecha especificada, necesitamos usar
<=| (o
|=> ) operador.
Como esperamos, la consulta se realiza simplemente mediante un escaneo de índice simple:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
Si creáramos el índice sin la información adicional sobre la asociación de campo, para una consulta similar, tendríamos que ordenar todos los resultados de la exploración del índice.
Además de la fecha, ciertamente podemos agregar campos de otros tipos de datos al índice RUM. Prácticamente todos los tipos base son compatibles. Por ejemplo, una tienda en línea puede mostrar rápidamente productos por novedad (fecha), precio (numérico) y popularidad o valor de descuento (entero o punto flotante).
Otras clases de operador
Para completar la imagen, debemos mencionar otras clases de operadores disponibles.
Comencemos con
"rum_tsvector_hash_ops" y
"rum_tsvector_hash_addon_ops" . Son similares a los ya discutidos "rum_tsvector_ops" y "rum_tsvector_addon_ops", pero el índice almacena el código hash del lexema en lugar del lexema mismo. Esto puede reducir el tamaño del índice, pero, por supuesto, la búsqueda se vuelve menos precisa y requiere una nueva verificación. Además, el índice ya no admite la búsqueda de una coincidencia parcial.
Es interesante observar la clase de operador
"rum_tsquery_ops" . Nos permite resolver un problema "inverso": buscar consultas que coincidan con el documento. ¿Por qué podría ser necesario? Por ejemplo, para suscribir a un usuario a nuevos productos de acuerdo con su filtro o para clasificar automáticamente nuevos documentos. Mira este sencillo ejemplo:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
Las clases de operador restantes
"rum_anyarray_ops" y
"rum_anyarray_addon_ops" están diseñadas para manipular matrices en lugar de "tsvector". Esto ya se discutió para GIN la
última vez y no necesita repetirse.
Los tamaños del índice y el registro de escritura anticipada (WAL)
Está claro que dado que RUM almacena más información que GIN, debe tener un tamaño mayor. Estábamos comparando los tamaños de diferentes índices la última vez; agreguemos RUM a esta tabla:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
Como podemos ver, el tamaño creció significativamente, que es el costo de la búsqueda rápida.
Vale la pena prestar atención a un punto más obvio: RUM es una extensión, es decir, se puede instalar sin modificaciones en el núcleo del sistema. Esto fue habilitado en la versión 9.6 gracias a un parche de
Alexander Korotkov . Uno de los problemas que tuvo que resolverse con este fin fue la generación de registros de anotaciones. Una técnica para el registro de operaciones debe ser absolutamente confiable, por lo tanto, no se puede permitir una extensión en esta cocina. En lugar de permitir que la extensión cree sus propios tipos de registros, se establece lo siguiente: el código de la extensión comunica su intención de modificar una página, le hace cambios y señala la finalización, y es el núcleo del sistema, que compara las versiones antiguas y nuevas de la página y genera los registros de registro unificados necesarios.
El algoritmo actual de generación de registros compara páginas byte a byte, detecta fragmentos actualizados y registra cada uno de estos fragmentos, junto con su desplazamiento desde el inicio de la página. Esto funciona bien cuando se actualizan solo varios bytes o toda la página. Pero si agregamos un fragmento dentro de una página, moviendo el resto del contenido hacia abajo (o viceversa, eliminando un fragmento, moviendo el contenido hacia arriba), cambiarán significativamente más bytes de los que realmente se agregaron o eliminaron.
Debido a esto, el cambio intenso del índice RUM puede generar registros de registro de un tamaño significativamente mayor que GIN (que, al no ser una extensión, sino una parte del núcleo, administra el registro por sí solo). El alcance de este efecto molesto depende en gran medida de una carga de trabajo real, pero para obtener una idea del problema, intentemos eliminar y agregar varias filas varias veces, intercalando estas operaciones con "vacío". Podemos evaluar el tamaño de los registros de registro de la siguiente manera: al principio y al final, recuerde la posición en el registro utilizando la función "pg_current_wal_location" ("pg_current_xlog_location" en versiones anteriores a la diez) y luego observe la diferencia.
Pero, por supuesto, deberíamos considerar muchos aspectos aquí. Debemos asegurarnos de que solo un usuario trabaje con el sistema (de lo contrario, se tendrán en cuenta los registros "adicionales"). Incluso si este es el caso, tenemos en cuenta no solo RUM, sino también actualizaciones de la tabla en sí y del índice que admite la clave primaria. Los valores de los parámetros de configuración también afectan el tamaño (aquí se utilizó el nivel de registro "réplica", sin compresión). Pero intentemos de todos modos.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
Entonces, obtenemos alrededor de 3 GB. Pero si repetimos el mismo experimento con el índice GIN, esto generará solo alrededor de 700 MB.
Por lo tanto, es deseable tener un algoritmo diferente, que encontrará el número mínimo de operaciones de inserción y eliminación que pueden transformar un estado de la página en otro. La utilidad "Diff" funciona de manera similar.
Oleg Ivanov ya ha implementado dicho algoritmo, y se está discutiendo su
parche . En el ejemplo anterior, este parche nos permite reducir el tamaño de los registros en 1.5 veces, a 1900 MB, a costa de una pequeña desaceleración.
Desafortunadamente, el parche se ha pegado y no hay actividad a su alrededor.
Propiedades
Como de costumbre, echemos un vistazo a las propiedades del método de acceso RUM, prestando atención a las diferencias de GIN (
ya se han proporcionado consultas ).
Las siguientes son las propiedades del método de acceso:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
Las siguientes propiedades de capa de índice están disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
Tenga en cuenta que, a diferencia de GIN, RUM admite la exploración de índice; de lo contrario, no habría sido posible devolver exactamente el número requerido de resultados en consultas con la cláusula "límite". No hay necesidad de la contraparte del parámetro "gin_fuzzy_search_limit" en consecuencia. Y como consecuencia, el índice se puede utilizar para admitir restricciones de exclusión.
Las siguientes son propiedades de capa de columna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
La diferencia aquí es que RUM admite operadores de pedidos. Sin embargo, esto no es cierto para todas las clases de operadores: por ejemplo, esto es falso para "tsquery_ops".
Sigue leyendo .