Hola a todos! Mi nombre es Pasha y soy ingeniero de control de calidad para el equipo de procesamiento de pedidos en Lamoda. Recientemente hablé en PHP Badoo Meetup. Hoy quiero proporcionar una transcripción de mi informe.
Hablaremos sobre Codeception, sobre cómo lo usamos en Lamoda y cómo escribir pruebas en él.
Lamoda tiene muchos servicios. Hay servicios al cliente que interactúan directamente con nuestros usuarios, con los usuarios del sitio, la aplicación móvil. No hablaremos de ellos. Y existe lo que nuestra compañía llama backends profundos: estos son nuestros sistemas de back-office que automatizan nuestros procesos comerciales. Estos incluyen entrega, almacenamiento, automatización de estudios fotográficos y un centro de llamadas. La mayoría de estos servicios se desarrollan en PHP.
Hablando brevemente sobre nuestra pila, esto es PHP + Symfony. Aquí y allá hay proyectos antiguos en Zend'e. PostgreSQL y MySQL se usan como bases de datos, y Rabbit o Kafka se usan como sistemas de mensajería.
¿Por qué backends PHP?Debido a que generalmente tienen una API ramificada, es REST, en algunos lugares hay un poco de SOAP. Si tienen una interfaz de usuario, entonces esta interfaz de usuario es más auxiliar, que utilizan nuestros usuarios internos.
¿Por qué necesitamos autotests en Lamoda?En general, cuando llegué a trabajar en Lamoda, había un eslogan de este tipo: "Eliminemos la regresión manual". No probaremos manualmente ninguna regresión. Y trabajamos en esta tarea. En realidad, esta es una de las razones principales por las que necesitamos pruebas automáticas, para no generar regresión a mano. ¿Por qué necesitamos esto? Derecho a liberar rápidamente. Para que podamos desplegar sin problemas, muy rápidamente nuestros lanzamientos y al mismo tiempo tener algún tipo de cuadrícula de las pruebas automáticas que nos dirán, buenas o malas. Estos son probablemente los objetivos más importantes. Pero hay un par de auxiliares, sobre los cuales también quiero decir.
¿Por qué necesitamos autotests?
- No pruebes la regresión con tus manos
- Liberación rápida
- Usar como documentación
- Acelerar la incorporación de nuevos empleados
- Las pruebas automáticas se utilizan convenientemente (en algunos casos) como documentación. A veces es más fácil entrar a las pruebas, ver qué casos están cubiertos, cómo funcionan y comprender cómo funciona esta o aquella funcionalidad, y acelerar la entrada de nuevos empleados, tanto desarrolladores como probadores, en un nuevo proyecto. Cuando te sientas a escribir pruebas automáticas, inmediatamente queda claro cómo funciona el sistema.
Ok, hablamos de por qué necesitamos autotest. Ahora hablemos de las pruebas que escribimos en Lamoda.
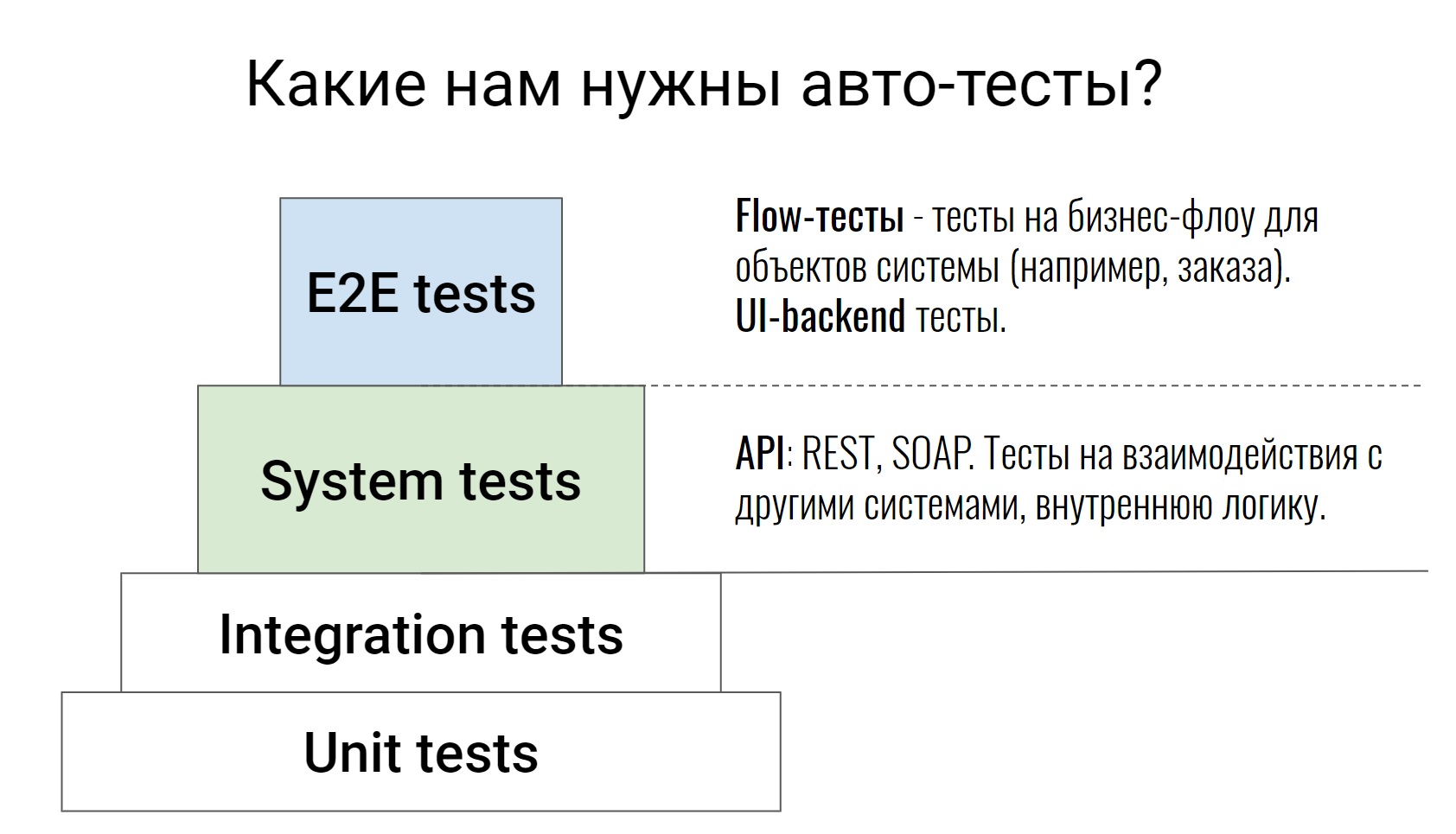
Esta es una pirámide de prueba bastante estándar, desde pruebas unitarias hasta pruebas E2E, donde algunas cadenas comerciales ya están probadas. No voy a hablar de los dos niveles inferiores; no es por nada que están pintados en ese color blanco. Estas son pruebas en el código en sí, están escritas por nuestros desarrolladores. En casos extremos, el probador puede entrar en la Solicitud de extracción, mirar el código y decir: "Bueno, aquí no hay suficientes casos, cubramos otra cosa". Esto completa el trabajo del probador para estas pruebas.
Hablaremos sobre los niveles anteriores, que están escritos por desarrolladores y probadores. Comencemos con las pruebas del sistema. Estas son pruebas que prueban la API (REST o SOAP), prueban alguna lógica interna del sistema, varios comandos, analizan colas en Rabbit o intercambian con sistemas externos. Como regla, estas pruebas son bastante atómicas. No verifican ninguna cadena, pero marcan una acción. Por ejemplo, un método API o un comando. Y verifican tantos casos como sea posible, tanto positivos como negativos.
Adelante, pruebas E2E. Los dividí en 2 partes. Tenemos pruebas que prueban un montón de UI y backend. Y hay pruebas que llamamos pruebas de flujo. Prueban la cadena: la vida de un objeto de principio a fin.
Por ejemplo, tenemos un sistema para gestionar el procesamiento de nuestros pedidos. Dentro de dicho sistema puede haber una prueba: un pedido desde la creación hasta la entrega, es decir, pasarlo por todos los estados. Es en tales pruebas que es muy fácil y sencillo observar cómo funciona el sistema. Inmediatamente ve todo el flujo de ciertos objetos, con qué sistemas externos interactúa todo esto, qué comandos se utilizan para esto.
Como tenemos esta IU utilizada por usuarios internos, el acceso a través del navegador no es importante para nosotros. No realizamos estas pruebas en ninguna granja, es suficiente para nosotros registrarnos en un navegador y, a veces, ni siquiera necesitamos usar un navegador.
"¿Por qué elegimos Codeception para la automatización de pruebas?" - Probablemente preguntes.
Para ser honesto, no tengo respuesta a esta pregunta. Cuando llegué a Lamoda, Codeception ya estaba seleccionado como el estándar para escribir autotests, y de hecho lo encontré. Pero después de trabajar con este marco durante algún tiempo, todavía entendí por qué Codeception. Esto es lo que quiero compartir contigo.
¿Por qué la codecepción?- Puede escribir y ejecutar las mismas pruebas de cualquier tipo (unidad, funcional, aceptación).
- Muchos rastrillos ya se han resuelto, muchos módulos ya se han escrito.
- En todos los proyectos, a pesar de las necesidades ligeramente diferentes, las pruebas tendrán el mismo aspecto.
- El concepto de Codeception sugiere que escriba cualquier prueba en este marco: unidad, integración, funcional, aceptación. Y usted, al menos, se lanzarán por igual.
- Codeception es un procesador suficientemente potente en el que ya se han resuelto muchos problemas, muchas preguntas, muchas tareas para las pruebas. Si algo no se decide, lo más probable es que encuentre algo desde el exterior: algún complemento para algún trabajo específico. No necesita escribir ningún contenedor de prueba para bases de datos, para otra cosa. Simplemente tome y conecte módulos a Codeception y trabaje con ellos.
- Bueno, tal ventaja (probablemente sea más adecuada para grandes empresas cuando tienes muchos proyectos y servicios): en todos los proyectos las pruebas se verán más o menos iguales. Esto es genial
Diré brevemente cómo es Codeception, ya que muchos trabajaron con él.

La codecepción funciona en un modelo de actor. Después de arrastrarlo al proyecto e inicializar, se genera dicha estructura.
Tenemos archivos yml, a continuación:
funcional.suite.yml ,
Integration.suit.yml ,
unit.suite.yml . Crean la configuración de sus pruebas. Hay papis para cada tipo de prueba, donde están estas pruebas, hay 3 papás auxiliares:
_
datos : para datos de prueba;
_
salida : donde se colocan los informes (xml, html);
_
soporte - donde algunos ayudantes auxiliares, funciones y todo lo que escribes se usan en tus pruebas.
Para empezar, le diré lo que tomamos de Codeception y lo usaré de inmediato, sin modificar nada, sin resolver tareas o problemas adicionales.
Módulos estándar- Phpbrowser
- DESCANSO
- Db
- Cli
- AMQP
El primer módulo de este tipo es PhpBrowser. Este módulo es un contenedor sobre Guzzle que le permite interactuar con su aplicación: abrir páginas, completar formularios, enviar formularios. Y si no le interesan las pruebas entre navegadores y navegadores, si de repente prueba la interfaz de usuario, puede usar PhpBrowser. Como regla general, lo usamos en nuestras pruebas de IU, porque no necesitamos ninguna lógica de interacción complicada, solo necesitamos abrir la página y hacer algo pequeño allí.
El segundo módulo que utilizamos es REST. Creo que el nombre deja en claro lo que está haciendo. Para cualquier interacción http, puede usar este módulo. Me parece que casi todas las interacciones se resuelven en él: encabezados, cookies, autorización. Todo lo que necesitas está en él.
El tercer módulo que usamos fuera de la caja es el módulo Db. En versiones recientes de Codeception, no se ha agregado soporte para una, sino varias bases de datos. Por lo tanto, si de repente tiene varias bases de datos en su proyecto, ahora funciona de inmediato.
El módulo Cli, que le permite ejecutar
comandos de shell y
bash desde pruebas, y también lo usamos.
Hay un módulo AMQP que funciona con cualquier agente de mensajes basado en este protocolo. Quiero señalar que se ha probado oficialmente en RabbitMQ. Como usamos RabbitMQ, todo está bien con él.
De hecho, Codeception, al menos en nuestro caso, cubre el 80-85% de todas las tareas que necesitamos. Pero aún tenía que trabajar en algo.
Comencemos con SOAP.

En nuestros servicios, en algunos lugares hay puntos finales SOAP. Necesitan ser probados, tirados, algo que ver con ellos. Pero dirá que en Codeception existe un módulo que le permite enviar solicitudes y luego hacer algo con las respuestas. De alguna manera analizar, agregar cheques y todo está bien. Pero el módulo SOAP no funciona de fábrica con múltiples puntos finales SOAP.

Por ejemplo, tenemos monolitos que tienen varios WSDL, varios puntos finales SOAP. Esto significa que es imposible en el módulo Codeception configurar esto en un archivo yml para que pueda funcionar con varios.

Codeception tiene una reconfiguración de módulo dinámico, y puede escribir algún tipo de adaptador para recibir, por ejemplo, un módulo SOAP y reconfigurarlo dinámicamente. En este caso, es necesario reemplazar el punto final y el esquema utilizado. Luego, en la prueba, si necesita cambiar el punto final al que desea enviar una solicitud, obtenemos nuestro adaptador y lo cambiamos a un nuevo punto final, a un nuevo circuito y le enviamos una solicitud.

En Codeception, no hay trabajo con Kafka y no hay complementos de terceros más o menos oficiales para trabajar con Kafka. No hay nada de qué preocuparse, escribimos nuestro módulo.

Por lo tanto, está configurado en un archivo yml. Algunas configuraciones están establecidas para corredores, consumidores y temas. Estas configuraciones, cuando escribe su módulo, puede incorporarlo a los módulos con la función de inicialización e inicializar este módulo con la misma configuración. Y, de hecho, el módulo tiene todos los otros métodos para implementar: poner el mensaje en el tema y leerlo. Eso es todo lo que necesitas de este módulo.
 Conclusión
Conclusión : los módulos para Codeception son fáciles de escribir.
Adelante Como dije, Codeception tiene un módulo Cli, un contenedor para comandos de
shell y que trabaja con su salida.

Pero a veces el comando de
shell debe ejecutarse no en pruebas, sino en la aplicación. En general, las pruebas y las aplicaciones son entidades ligeramente diferentes, pueden estar en diferentes lugares. Las pruebas se pueden ejecutar en un lugar y la aplicación puede estar en otro.
Entonces, ¿por qué necesitamos ejecutar
shell en las pruebas?
Tenemos comandos en aplicaciones que, por ejemplo, analizan colas en RabbitMQ y mueven objetos por estado. Estos comandos en modo profesional se inician desde debajo del supervisor. El supervisor supervisa su implementación. Si se caen, entonces él comienza de nuevo y así sucesivamente.
Cuando probamos, el supervisor no se está ejecutando. De lo contrario, las pruebas se vuelven inestables, impredecibles. Nosotros mismos queremos controlar el lanzamiento de estos comandos dentro de la aplicación. Por lo tanto, necesitamos ejecutar estos comandos desde las pruebas en la aplicación. Usamos dos opciones. Esa, que la otra, en principio, todo es igual y todo funciona.
¿Cómo ejecutar un
shell en una aplicación?
Primero: ejecute las pruebas en el mismo lugar donde se encuentra la aplicación. Como todas las aplicaciones que tenemos en Docker, las pruebas se pueden ejecutar en el mismo contenedor donde se encuentra el servicio.
La segunda opción: hacer un contenedor separado para las pruebas, algún
corredor de prueba , pero hacerlo igual que la aplicación. Es decir, de la misma imagen de Docker, y luego todo funcionará de manera similar.

Otro problema que encontramos en las pruebas es trabajar con varios sistemas de archivos. A continuación se muestra un ejemplo de lo que puede y debe trabajar. Los tres primeros son relevantes para nosotros. Estos son Webdav, SFTP y el sistema de archivos de Amazon.
¿Con qué necesitas trabajar?
- Webdav
- FTP / SFTP
- AWS S3
- Local
- Azure, Dropbox, Google Drive
Si hurga en Codeception, puede encontrar algunos módulos para casi cualquier sistema de archivos más o menos popular.
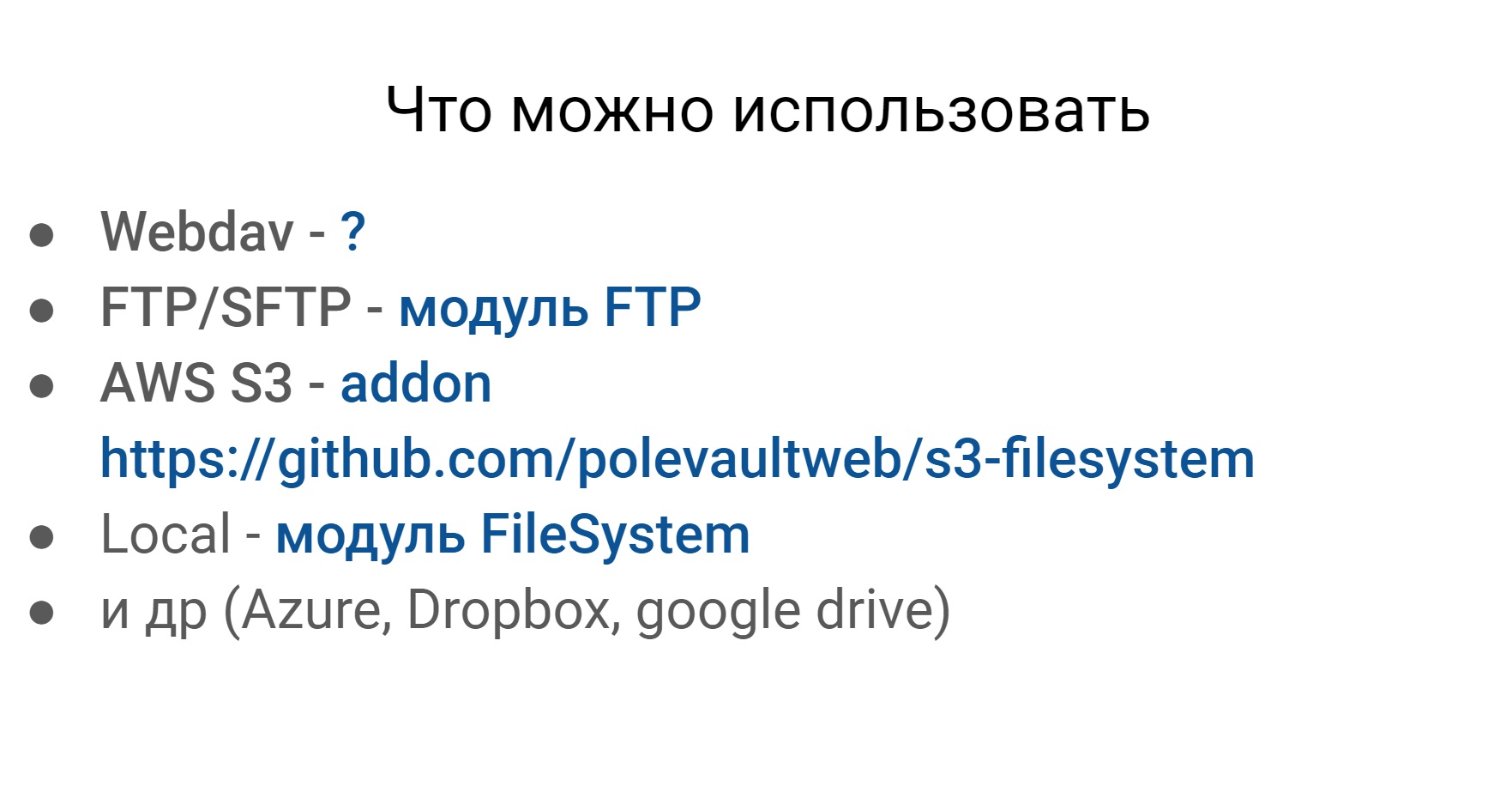
Lo único que no encontré es para Webdav. Pero estos sistemas de archivos, más o menos, son los mismos en términos de trabajo externo con ellos, y queremos trabajar con ellos de la misma manera.
Escribimos nuestro módulo llamado Flysystem. Se encuentra en
Github en el dominio público y admite 2 sistemas de archivos, SFTP y Webdav, y le permite trabajar con ambos utilizando la misma API.

Obtenga una lista de archivos, limpie el directorio, escriba un archivo, etc. Si también agrega el sistema de archivos de Amazon allí, nuestras necesidades definitivamente serán cubiertas.
El siguiente punto, creo, es muy importante para las pruebas automáticas, especialmente el nivel del sistema, es trabajar con bases de datos. En general, quiero que sea, como en la imagen, - VZHUH y todo se inicia, funciona, y estas bases de datos deberían ser menos compatibles en las pruebas.

¿Cuáles son las tareas principales que veo aquí?
- Cómo desplegar la base de datos de la estructura deseada - Db
- Cómo llenar la base de datos con datos de prueba: Db, accesorios
- Cómo hacer selecciones y comprobaciones - Db
Para las 3 tareas en Codeception, hay 2 módulos: Db, del que ya hablé, otro se llama Fixtures.
De estos 2 módulos y 3 tareas, usamos solo DB para la tercera tarea.
Para la primera tarea, puede usar DB. Allí puede configurar el volcado de SQL desde el que se implementará la base de datos, bueno, el módulo con accesorios, creo que está claro por qué es necesario.
Habrá accesorios en forma de matrices que pueden persistir en la base de datos.
Como dije, las primeras 2 tareas las resolvemos de manera un poco diferente, ahora te diré cómo lo hacemos.
Despliegue de base de datos- Levantar un contenedor con PostgreSQL o MySQL
- Rodamos todas las migraciones con doctrina migraciones
El primero se trata de implementar una base de datos. ¿Cómo sucede esto en las pruebas? Levantamos el contenedor con la base de datos deseada, ya sea PostgreSQL o MySQL, y luego hacemos todas las migraciones necesarias usando
migraciones de doctrina . Todo, la base de datos de la estructura deseada está lista, se puede usar en pruebas.
Por qué no utilizamos la humedad, porque no es necesario que sea compatible. Este es un tipo de volcado que se encuentra en las pruebas, que debe actualizarse constantemente si algo cambia en la base de datos. Hay migraciones, no es necesario mantener un volcado.
El segundo punto es la creación de datos de prueba. No utilizamos el módulo Fixtures de Codeception, utilizamos el paquete
Symfony para los fixtures.

Hay un
enlace y un ejemplo de cómo puede crear accesorios en la base de datos.
Su dispositivo se creará como un objeto del dominio, se puede almacenar en la base de datos y los datos de prueba estarán listos.
¿Por qué DoctrineFixtureBundle?
- Más fácil de crear cadenas de objetos relacionados.
- Menos duplicación de datos si los accesorios para diferentes pruebas son similares.
- Menos ediciones al cambiar la estructura de la base de datos.
- Las clases de fijación son mucho más visuales que las matrices.
¿Por qué lo usamos? Sí, por la misma razón: estos accesorios son mucho más fáciles de mantener que los accesorios de Codeception. Es más fácil crear cadenas de objetos relacionados, porque todo está en el paquete de Symfony. Es necesario duplicar menos datos, ya que los accesorios se pueden heredar, estas son clases. Si la estructura de la base de datos cambia, estas matrices siempre deben editarse, y las clases no siempre. Los accesorios en forma de objetos de dominio siempre son más visibles que las matrices.
Hablamos de bases de datos, hablemos un poco sobre moki.
Dado que estas son pruebas de un nivel suficientemente alto que prueban todo el sistema y que nuestros sistemas están altamente interconectados, está claro que hay algunos intercambios e interacciones. Ahora hablaremos de mokeys sobre la interacción entre sistemas.
Reglas para mok- Llora todas las interacciones externas del servicio http
- Verificación no solo de escenarios positivos, sino también negativos
Las interacciones son algunas interacciones http REST o SOAP. Todas estas interacciones en el marco de las pruebas que estamos mojando. Es decir, en nuestras pruebas no existe un atractivo real para los sistemas externos en ninguna parte. Esto hace que las pruebas sean estables. Debido a que un servicio externo puede funcionar, puede no funcionar, puede responder lentamente, puede que rápidamente, en general, no sepa cuál es su comportamiento. Por lo tanto, lo cubrimos todo con moks.
También tenemos esa regla. Estamos mojando no solo las interacciones positivas, sino también tratando de verificar algunos casos negativos. Por ejemplo, cuando un servicio de terceros responde con un error número 500 o produce un error más significativo, intentamos verificarlo todo.
Usamos Wiremock para simulacros, Codeception es compatible ..., tiene un complemento oficial Httpmock, pero nos gustó más Wiremock. Como funciona
Wiremock se eleva como un contenedor Docker separado durante las pruebas, y todas las solicitudes que deben ir al sistema externo van a Wiremock.
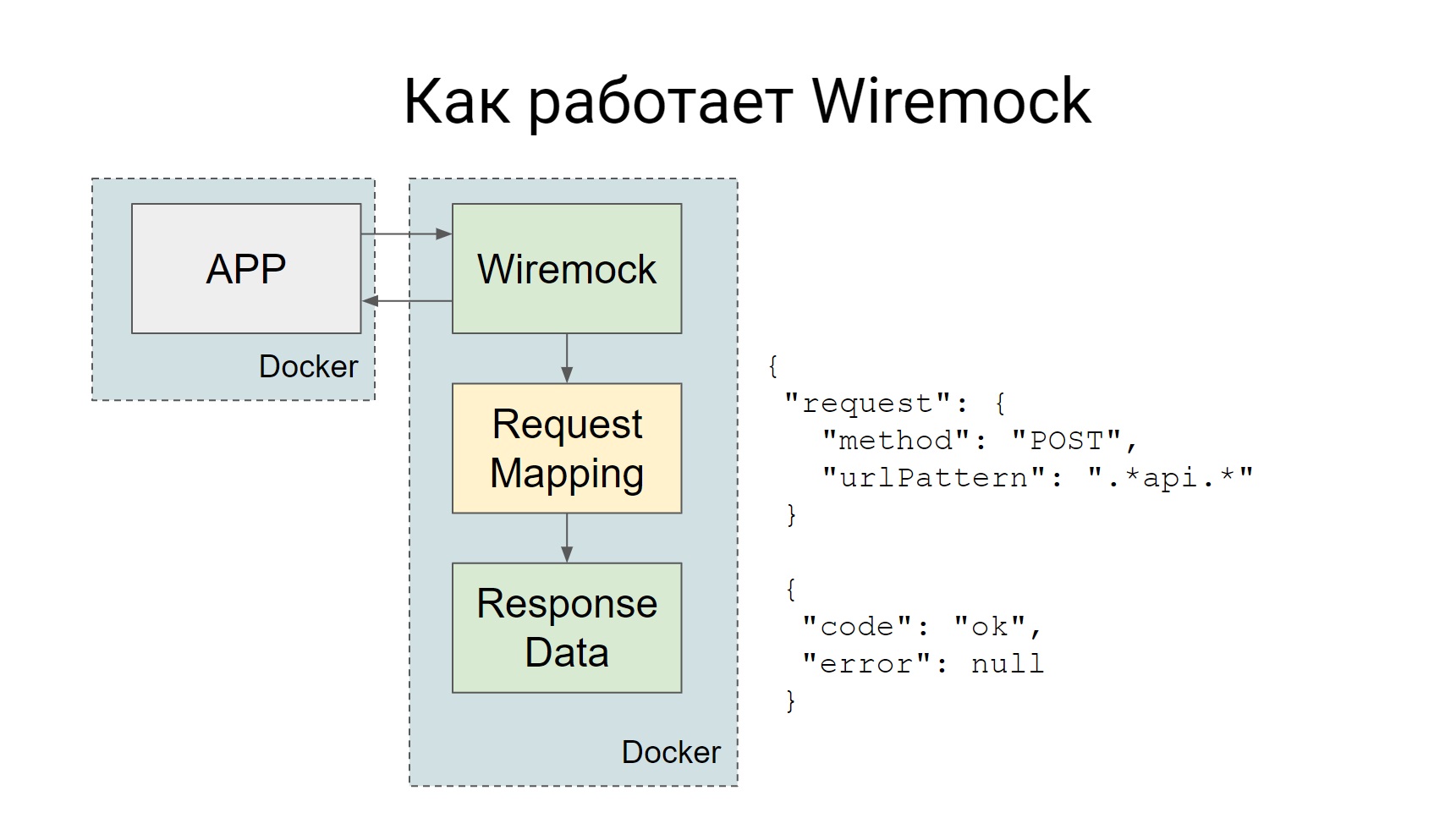
Wiremock, si nos fijamos en la diapositiva, hay un cuadro de este tipo, Solicitud de asignación, tiene un conjunto de asignaciones que dicen que si llega tal solicitud, debe dar esa respuesta. Todo es muy simple: llegó una solicitud, recibió un simulacro.
Los simulacros se pueden crear estáticamente, luego el contenedor, cuando ya con Wiremock se eleva, estos simulacros estarán disponibles, se pueden usar en pruebas manuales. Puede crear dinámicamente, directamente en el código, en algún tipo de prueba.
Aquí hay un ejemplo de cómo crear un simulacro dinámicamente, como puede ver, la descripción es bastante declarativa, del código queda claro de inmediato qué tipo de simulacro estamos creando: un simulacro para el método GET que viene a tal URL y, de hecho, qué devolver.

Además del hecho de que este simulacro se puede crear, Wiremock tiene la oportunidad de verificar qué solicitud se envió a este simulacro. Esto también es muy útil en las pruebas.
Sobre Codeception en sí, probablemente, todo, y algunas palabras sobre cómo se ejecutan nuestras pruebas y un poco de infraestructura.
Que estamos usando

Bueno, en primer lugar, todos los servicios que tenemos en Docker, por lo que lanzar un entorno de prueba está generando los contenedores correctos.
Make se usa para comandos internos, Bamboo se usa como CI.
¿Cómo se ve la prueba de CI?

Primero, creamos la versión deseada de la aplicación, luego elevamos el entorno: esta es la aplicación, todos los servicios que necesita, como Kafka, Rabbit, la base de datos, y trasladamos la migración a la base de datos.
Todo este entorno se plantea con la ayuda de Docker Compose. Es en CI, en prod que todos los contenedores giran bajo Kubernetes. Luego ejecuta las pruebas y corre.
¿Cuánto tiempo lleva todo?
Todo depende del servicio específico, pero, por regla general, aumentar el entorno antes de ejecutar las pruebas es de 5 a 10 minutos, pruebas, de 6 a 30 minutos.

Advertiré inmediatamente esta pregunta mientras todas las pruebas persiguen en un hilo.
Bueno, tal pregunta. ¿Con qué frecuencia se deben ejecutar las pruebas? Por supuesto, cuanto más a menudo, mejor. Cuanto antes pueda detectar un problema, más rápido podrá resolverlo.
Tenemos 2 reglas principales. Cuando una tarea entra en pruebas, todas las pruebas, tanto las pruebas unitarias como las no unitarias, deben pasarla. Si algunas pruebas fallan, esta es una ocasión para transferir la tarea a la reparación.Naturalmente, cuando lancemos el lanzamiento. En el lanzamiento, todas las pruebas deben pasar.Al final, me gustaría decir algo inspirador: escribir pruebas, dejar que sean verdes, usar Codeception, hacer moki. Creo que todos entienden perfectamente esto.