Hola
¿Sabía que las plataformas publicitarias a menudo copian contenido de los competidores para aumentar la cantidad de anuncios que alojan? Lo hacen de esta manera: llaman a los vendedores y les ofrecen establecerse en su plataforma. Y a veces copian completamente los anuncios sin permiso del usuario. Avito es un lugar popular, y a menudo nos encontramos con una competencia tan injusta. Lea acerca de cómo estamos luchando contra este fenómeno, lea debajo del corte.

El problema
La copia de contenido de Avito a otras plataformas existe en varias categorías de bienes y servicios. Este artículo se centrará solo en automóviles. En una publicación anterior, hablé sobre cómo ocultamos los números automáticamente en los automóviles.

Pero resultó (a juzgar por los resultados de búsqueda de otras plataformas) que lanzamos esta función de inmediato en tres sitios de anuncios.

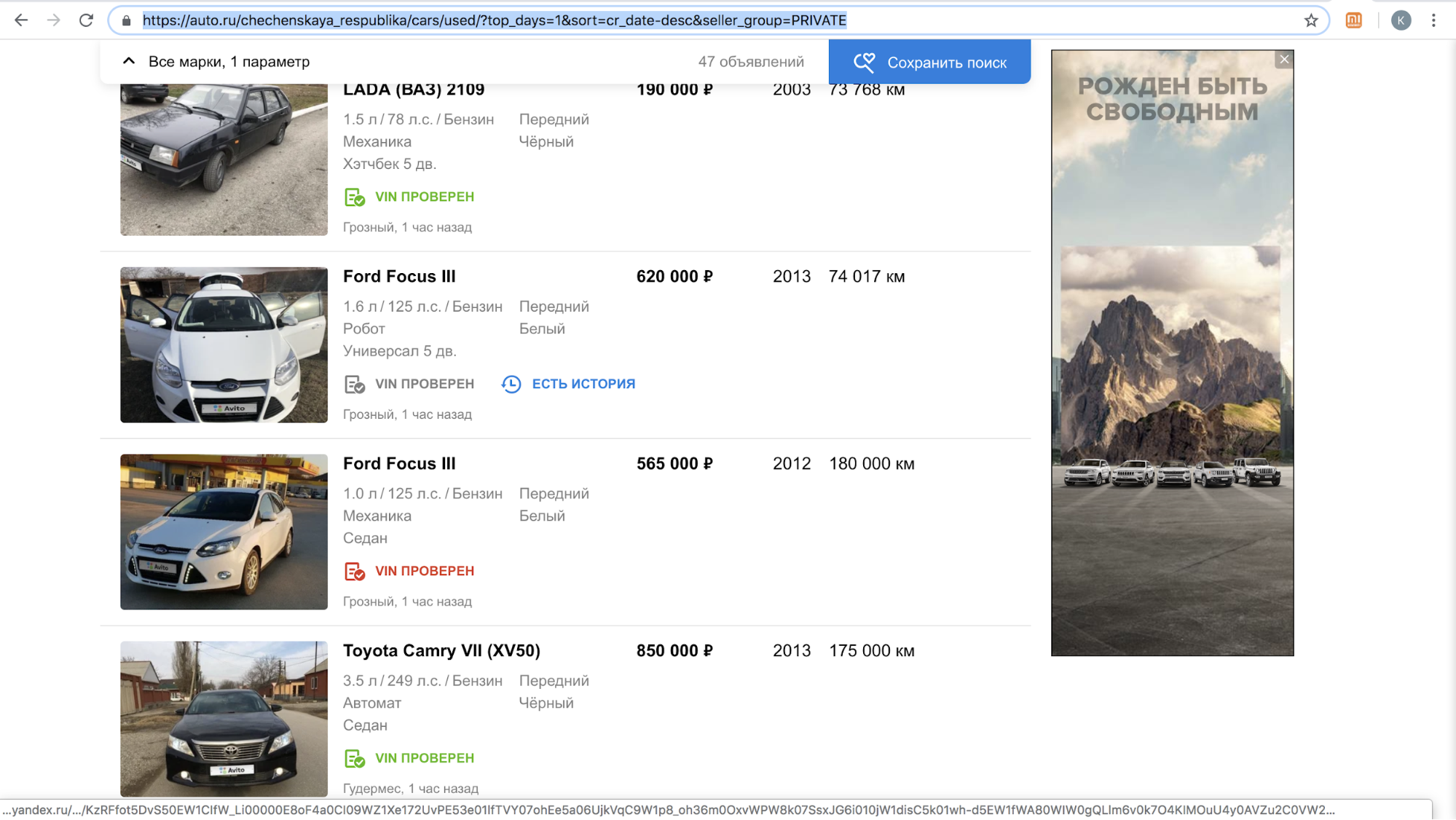
Uno de estos sitios, después de lanzar la función, suspendió temporalmente la llamada a nuestros usuarios con ofertas para copiar el anuncio en su plataforma: había demasiado contenido con el logotipo de Avito en su sitio, solo en noviembre de 2018: más de 70,000 anuncios. Por ejemplo, así es como se veían sus resultados de búsqueda por día en la República Chechena.
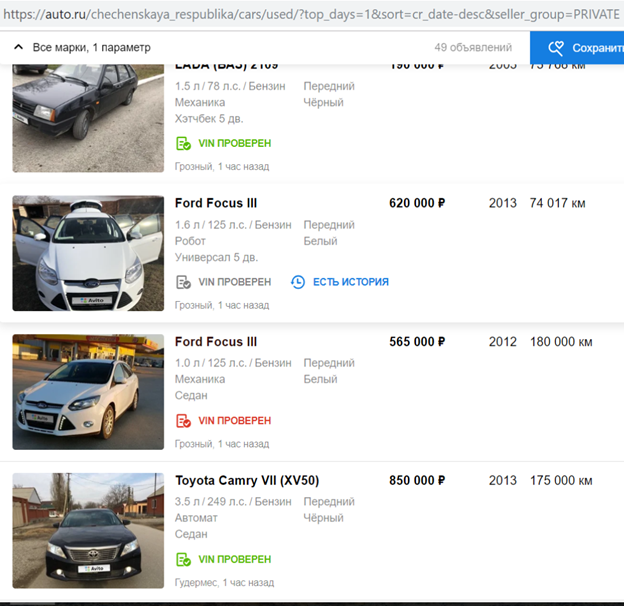
Después de completar su algoritmo para ocultar las placas para que detecte y cierre automáticamente el logotipo de Avito, reanudaron el proceso.

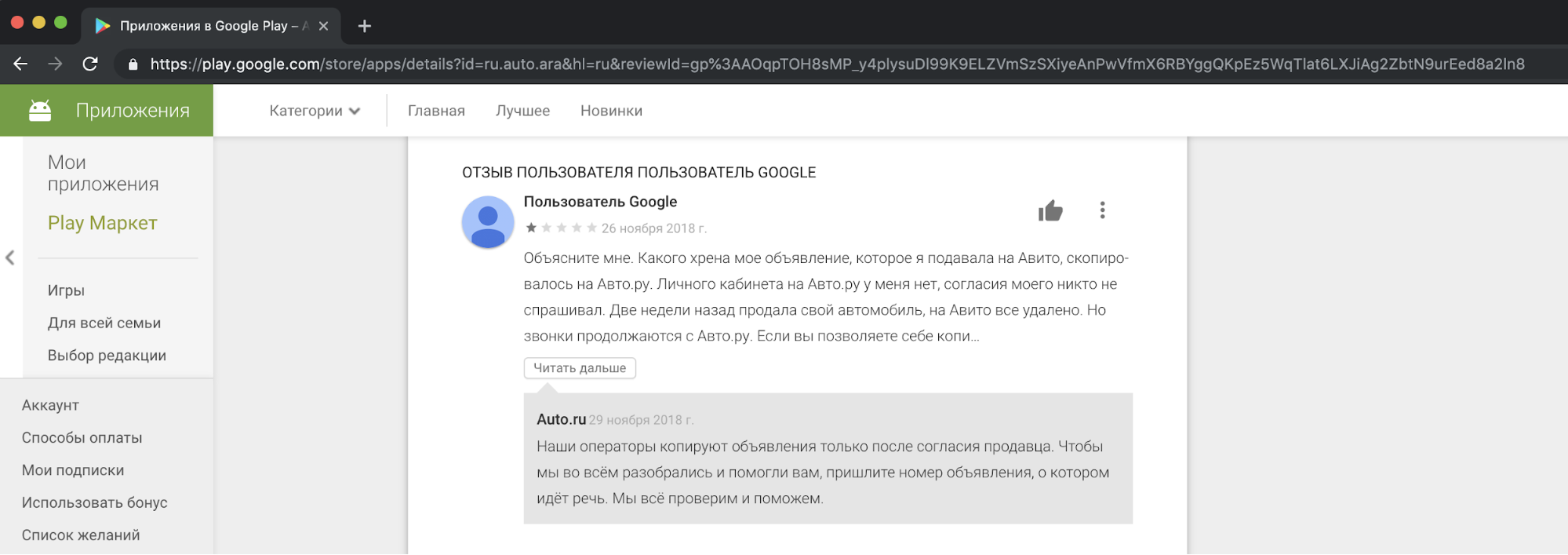
Desde nuestro punto de vista, copiar el contenido de la competencia y usarlo con fines comerciales es poco ético e inaceptable. Recibimos quejas de nuestros usuarios, que no están contentos con esto, en nuestro soporte. Aquí hay un ejemplo de una reacción en una de las historias.
Debo decir que la solicitud del consentimiento de las personas para copiar anuncios no justifica tales acciones. Esto es una violación de las leyes "sobre publicidad" y "sobre datos personales", las normas de Avito, los derechos de marca registrada y la base de datos de anuncios.
No podíamos estar en paz con un competidor, pero no queríamos dejar la situación como está.
Formas de resolver el problema.
El primer método es legal. Antecedentes similares ya han existido en otros países. Por ejemplo, el conocido clasificador estadounidense Craigslist ha incautado grandes cantidades de dinero de sitios que copian contenido de él.
La segunda forma de resolver el problema de la copia es agregar una marca de agua grande a la imagen para que no se pueda recortar.
El tercer método es tecnológico. Podemos complicar el proceso de copiar nuestro contenido. Es lógico suponer que algún modelo se dedica a ocultar el logotipo de Avito a los competidores. También se sabe que muchos modelos son propensos a los "ataques" que les impiden funcionar correctamente. Este artículo será solo sobre ellos.
Ataque adversario

Idealmente, el ejemplo de confrontación para la red parece ruido que el ojo humano no puede distinguir, pero para el clasificador agrega una señal suficiente a la clase que no está en la imagen. Como resultado, una imagen, por ejemplo, con un panda, se clasifica con gran confianza como un gibón. La creación de ruido de confrontación es posible no solo para las redes de clasificación de imágenes, sino también para la segmentación y la detección. Un ejemplo interesante es un trabajo reciente de Keen Labs: engañaron a un piloto automático Tesla con puntos en el pavimento y un detector de lluvia al mostrar exactamente ese ruido de adversidad . También hay ataques para otros dominios, por ejemplo, sonido: el conocido ataque a Amazon Alexa y otros asistentes de voz consistió en jugar equipos que el oído humano no podía distinguir (los crackers ofrecieron comprar algo en Amazon).
La creación de ruido de confrontación para modelos que analizan imágenes es posible debido al uso no estándar del gradiente necesario para entrenar el modelo. Por lo general, en el método de propagación hacia atrás de errores, utilizando el gradiente calculado de la función objetivo, solo se cambian los pesos de las capas de red para que se confunda menos en el conjunto de datos de entrenamiento. Al igual que para las capas de red, puede calcular el gradiente de la función objetivo a partir de la imagen de entrada y cambiarla. El cambio de la imagen de entrada usando un gradiente se usó para varios algoritmos conocidos. ¿Recuerdas Deepdream ?

Si calculamos iterativamente el gradiente de la función objetivo a partir de la imagen de entrada y le agregamos este gradiente, en la imagen aparece más información sobre la clase prevaleciente de ImageNet: aparecen más caras de perros, debido a que el valor de la función de pérdida disminuye y el modelo se vuelve más seguro en la clase "perro". ¿Por qué está el perro en el ejemplo? Solo en ImageNet de 1000 clases - 120 clases de perros . Se utilizó un enfoque similar para la modificación de la imagen en el algoritmo Style Transfer, conocido principalmente por la aplicación Prisma.
Para crear un ejemplo de confrontación, también puede usar el método iterativo para cambiar la imagen de entrada.
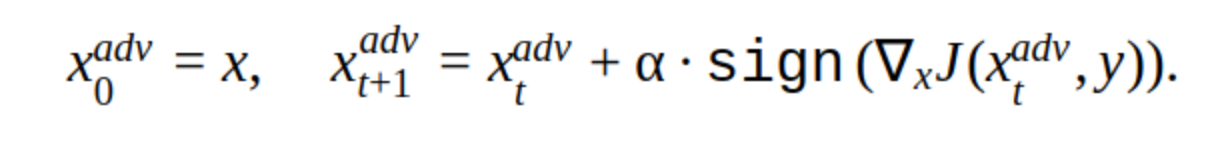
Hay varias modificaciones a este método, pero la idea básica es simple: la imagen original se desplaza iterativamente en la dirección del gradiente de la pérdida de la función de clasificación J (porque solo se usa el signo) con el paso α. 'y' es la clase que se representa en la imagen para reducir la confianza de la red en la respuesta correcta. Tal ataque se llama no dirigido. Puede elegir el paso óptimo y el número de iteraciones para que el cambio en la imagen de entrada sea indistinguible del habitual para una persona. Pero desde el punto de vista de los costos de tiempo, tal ataque no nos conviene. 5-10 iteraciones para una imagen en el producto es mucho tiempo.
Una alternativa a los métodos iterativos es el método FGSM.

Este es un método de disparo único, es decir Para usarlo, debe calcular el gradiente de la función de pérdida para la imagen de entrada una vez, y el ruido de confrontación está listo para agregarse a la imagen. Este método es obviamente más productivo. Se puede usar en producción.
Crear ejemplos adversos
Decidimos comenzar hackeando nuestro propio modelo.
Esta es la imagen que reduce la probabilidad de encontrar una placa para nuestro modelo.

Es evidente que este método tiene un inconveniente: los cambios que agrega a la imagen son visibles a simple vista. Además, este método no está dirigido, pero se puede cambiar para realizar un ataque dirigido. Luego, el modelo predecirá el lugar de la placa en otro lugar. Este es el método T-FGSM.
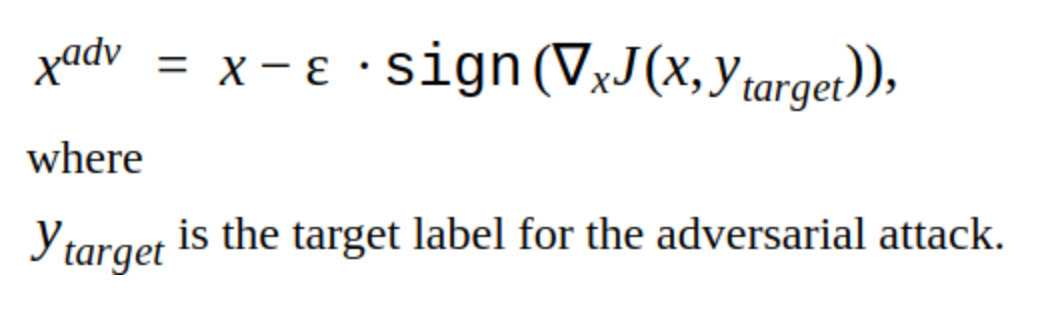
Para romper nuestro modelo con este método, debe cambiar la imagen de entrada un poco más notablemente.

Todavía no es posible decir que los resultados son ideales, pero al menos se ha verificado la eficacia de los métodos. También probamos bibliotecas listas para hackear las redes Foolbox, CleverHans y ART-IBM, pero con su ayuda no fue posible romper nuestra red para la detección. Los métodos dados allí son mejores para las redes de clasificación. Esta es una tendencia general en el pirateo de redes: es más difícil hacer un ataque más difícil para la detección de objetos, especialmente cuando se trata de modelos complejos, por ejemplo, Mask RCNN.
Prueba de ataque
Todo lo que se describió hasta ahora no fue más allá de nuestros experimentos internos, pero fue necesario descubrir cómo probar los ataques en los detectores de otras plataformas publicitarias.
Resulta que al solicitar una de las plataformas, la placa se detecta automáticamente, por lo que puede cargar fotos muchas veces y verificar cómo el algoritmo de detección hace frente al nuevo ejemplo adversario.
¡Esto es genial! Pero ...
Ninguno de los ataques que funcionaron en nuestro modelo funcionó al probar en otra plataforma. ¿Por qué sucedió esto? Esto es una consecuencia de las diferencias en los modelos y la forma en que los ataques adversos se generalizan a diferentes arquitecturas de red. Debido a la complejidad de la reproducción de los ataques, se dividen en dos grupos: cuadro blanco y cuadro negro.

Esos ataques que hicimos en nuestro modelo: era una caja blanca. Lo que necesitamos es un cuadro negro con restricciones adicionales en la inferencia: no hay API, todo lo que puede hacer es cargar fotos manualmente y verificar los ataques. Si hubiera una API, entonces podría hacer un modelo sustituto.

La idea es crear un conjunto de datos de imágenes de entrada y respuestas del modelo de caja negra, en el que puede entrenar varios modelos de diferentes arquitecturas, para aproximar el modelo de caja negra. Luego puede llevar a cabo un ataque de caja blanca en estos modelos y es más probable que funcionen en una caja negra. En nuestro caso, esto implica mucho trabajo manual, por lo que esta opción no nos convenía.
Romper el punto muerto
En busca de trabajos interesantes sobre el tema de los ataques de caja negra, se encontró un artículo ShapeShifter: Robusto ataque físico adversario en un detector de objetos R-CNN más rápido
Los autores del artículo atacaron la detección de objetos de una red de máquinas autónomas al agregar iterativamente imágenes distintas de la verdadera clase al fondo de la señal de stop.


Tal ataque es claramente visible para el ojo humano, sin embargo, rompe con éxito el trabajo de la red de detección de objetos, que es lo que necesitamos. Por lo tanto, decidimos descuidar la invisibilidad deseada del ataque en aras de la capacidad de trabajo.
Queríamos verificar cuánto se volvió a entrenar el modelo de detección, ¿utiliza información sobre el automóvil o solo se necesita la placa Avito?
Para hacer esto, creó la siguiente imagen:

Lo subimos como una máquina a una plataforma publicitaria con un modelo de caja negra. Recibido:

Esto significa que solo puede cambiar la placa Avito, el resto de la información en la imagen de entrada no es necesaria para la detección del modelo de caja negra.
Después de varios intentos, surgió la idea de agregar al ruido de confrontación de la placa Avito obtenido por el método FGSM, que rompió nuestro propio modelo, pero con un coeficiente ε bastante grande. Resultó así:

En coche, se ve así:

Subimos una foto a la plataforma con un modelo de caja negra. El resultado fue exitoso.

Aplicando este método a varias otras fotos, descubrimos que no funciona a menudo. Luego, después de varios intentos, decidimos centrarnos en la otra parte más notable del problema: la frontera. Se sabe que las capas convolucionales iniciales de la red tienen activaciones en objetos simples como líneas, ángulos. Al "romper" la línea de borde, podemos evitar que la red detecte correctamente el área del número. Esto se puede hacer, por ejemplo, agregando ruido en forma de cuadrados blancos de un tamaño aleatorio en todo el borde de la habitación.

Al subir dicha imagen a una plataforma con un modelo de caja negra, obtuvimos un ejemplo de confrontación exitoso.

Después de probar este enfoque en un conjunto de otras imágenes, descubrimos que el modelo de caja negra ya no puede detectar la placa Avito (el conjunto se ensambló manualmente, hay menos de cien imágenes y, por supuesto, no es representativo, pero lleva mucho tiempo hacer más). Una observación interesante: el ataque tiene éxito solo cuando se combina el ruido en las letras de Avito y los cuadrados blancos aleatorios en un marco, el uso de estos métodos por separado no da un resultado exitoso.
Como resultado, implementamos este algoritmo en el producto, y esto es lo que salió de él :)
Múltiples anuncios encontrados


Algo más fresco:
Incluso nos metimos en la plataforma publicitaria:
Total
Como resultado, logramos realizar un ataque de confrontación, que en nuestra implementación no aumenta el tiempo de procesamiento de la imagen. El tiempo que dedicamos a crear el ataque es dos semanas antes del Año Nuevo. Si no hubiera sido posible hacerlo durante este tiempo, habrían colocado una marca de agua. Ahora, la placa de la licencia de adversarios está deshabilitada, porque ahora un competidor llama a los usuarios, les ofrece subir fotos al anuncio ellos mismos o reemplazar las fotos del automóvil con otras de Internet.