Hola Habr! Les presento la traducción del artículo " Clasificación de la cobertura del suelo con eo-learn: Parte 1 " de Matic Lubej.
Parte 2
Parte 3
Prólogo
Hace unos seis meses, se realizó la primera confirmación en el repositorio eo-learn en GitHub. Hoy, eo-learn ha convertido en una maravillosa biblioteca de código abierto, lista para ser utilizada por cualquier persona interesada en datos EO (Observación de la Tierra, etc.) Todos en el equipo de Sinergise esperaban el momento de la transición de la etapa de construcción de las herramientas necesarias a la etapa de su uso para el aprendizaje automático. Es hora de presentarle una serie de artículos sobre la clasificación de la cobertura del suelo utilizando eo-learn
eo-learn es una biblioteca de Python de código abierto que actúa como un puente que conecta la Observación de la Tierra / Teledetección con el ecosistema de las bibliotecas de aprendizaje automático de Python. Ya escribimos una publicación separada en nuestro blog , que recomendamos que se familiarice con usted. La biblioteca utiliza primitivas de las bibliotecas numpy y shapely numpy para almacenar y manipular datos de satélites. Por el momento, está disponible en el repositorio de GitHub , y la documentación está disponible en el enlace correspondiente a ReadTheDocs .

Imagen de satélite Sentinel-2 y máscara NDVI de una pequeña área en Eslovenia en invierno
Para demostrar las capacidades de eo-learn , decidimos usar nuestro transportador multitemporal para clasificar la cobertura del territorio de la República de Eslovenia (el país donde vivimos), utilizando datos de 2017. Como el procedimiento completo puede ser demasiado complicado para un artículo, decidimos dividirlo en tres partes. Gracias a esto, no hay necesidad de saltear los pasos e inmediatamente proceder al aprendizaje automático; primero tenemos que entender realmente los datos con los que estamos trabajando. Cada artículo irá acompañado de un ejemplo de Jupyter Notebook. Además, para los interesados, ya hemos preparado un ejemplo completo que cubre todas las etapas.
- En el primer artículo, lo guiaremos a través del procedimiento para seleccionar / dividir un área de interés (en adelante, AOI, área de interés) y obtener la información necesaria, como datos de sensores satelitales y máscaras de nubes. También mostramos un ejemplo de cómo crear una máscara ráster de datos sobre la cobertura real de un territorio a partir de datos vectoriales. Todos estos son pasos necesarios para obtener un resultado confiable.
- En la segunda parte, nos sumergimos de lleno en la preparación de datos para el procedimiento de aprendizaje automático. Este proceso incluye tomar muestras aleatorias para entrenamiento \ validación de píxeles, eliminar imágenes de la nube, interpolar datos temporales para llenar "agujeros", etc.
- En la tercera parte, consideraremos la capacitación y validación del clasificador, así como, por supuesto, ¡hermosos gráficos!

Imagen de satélite Sentinel-2 y máscara NDVI de un área pequeña en Eslovenia en verano
Area de interes? Elegir!
La biblioteca eo-learn permite dividir AOI en pequeños fragmentos que pueden procesarse en condiciones de recursos informáticos limitados. En este ejemplo, la frontera eslovena se tomó de la Tierra Natural , sin embargo, puede seleccionar una zona de cualquier tamaño. También agregamos un búfer al borde, después de lo cual la dimensión AOI era de aproximadamente 250x170 km. Usando la magia de las geopandas y las bibliotecas shapely geopandas , creamos una herramienta para romper AOI. En este caso, dividimos el territorio en 25x17 cuadrados del mismo tamaño, como resultado de lo cual recibimos ~ 300 fragmentos de 1000x1000 píxeles, en una resolución de 10m. La decisión de dividirse en fragmentos se toma en función de la potencia informática disponible. Como resultado de este paso, obtenemos una lista de cuadrados que cubren el AOI.

AOI (territorio de Eslovenia) se divide en pequeños cuadrados con un tamaño de aproximadamente 1000x1000 píxeles en una resolución de 10 m.
Recibir datos de satélites Sentinel
Después de determinar los cuadrados, eo-learn permite descargar automáticamente datos de los satélites Sentinel. En este ejemplo, obtenemos todas las tomas Sentinel-2 L1C que se tomaron en 2017. Vale la pena señalar que los productos Sentinel-2 L2A, así como fuentes de datos adicionales (Landsat-8, Sentinel-1) se pueden agregar a la tubería de manera similar. También vale la pena señalar que el uso de productos L2A puede mejorar los resultados de clasificación, pero decidimos usar L1C para la versatilidad de la solución. Esto se hizo usando sentinelhub-py , una biblioteca que funciona como un contenedor en los servicios de Sentinel-Hub. El uso de estos servicios es gratuito para institutos de investigación y nuevas empresas, pero en otros casos es necesario suscribirse.

Imágenes en color de un fragmento en días diferentes. Algunas imágenes están nubladas, lo que significa que se necesita un detector de nubes.
Además de los datos de Sentinel, eo-learn permite acceder de manera transparente a la nube y a los datos de probabilidad de la nube gracias a la biblioteca s2cloudless . Esta biblioteca proporciona herramientas para detectar nubes automáticamente píxel por píxel . Los detalles se pueden leer aquí .
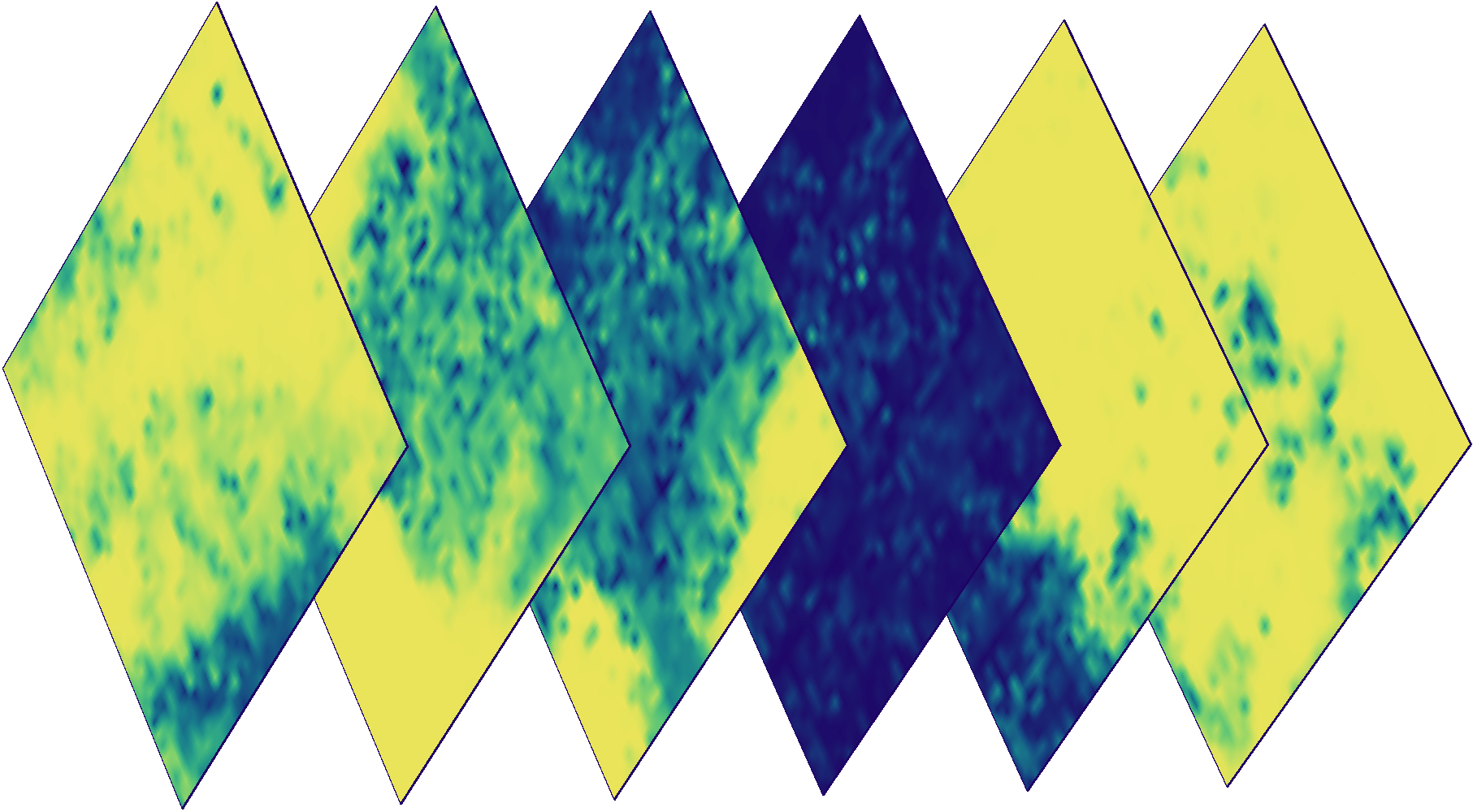
Cloud Masks para las imágenes de arriba. El color indica la probabilidad de nubosidad de un píxel específico (azul - baja probabilidad, amarillo - alto).
Agregar datos reales
La enseñanza con un maestro requiere una tarjeta con datos reales o verdad . El último término no debe tomarse literalmente, porque en realidad, los datos son solo una aproximación de lo que está en la superficie. Desafortunadamente, el comportamiento del clasificador depende en gran medida de la calidad de esta tarjeta ( sin embargo, como para la mayoría de las otras tareas en el aprendizaje automático ). Las tarjetas marcadas suelen estar disponibles como datos vectoriales en formato shapefile (por ejemplo, proporcionados por el estado o la comunidad ). eo-learn contiene herramientas para rasterizar datos vectoriales en forma de una máscara ráster.

El proceso de rasterizar datos en máscaras utilizando el ejemplo de un cuadrado. Los polígonos en un archivo vectorial se muestran en la imagen izquierda, las máscaras de trama para cada etiqueta se muestran en el medio: los colores blanco y negro indican la presencia y ausencia de un atributo específico, respectivamente. La imagen de la derecha muestra una máscara ráster combinada en la que diferentes colores indican diferentes etiquetas.
Poniendo todo junto
Todas estas tareas se comportan como bloques de construcción que se pueden combinar en una secuencia conveniente de acciones realizadas para cada cuadrado. Debido a la cantidad extremadamente grande de dichos fragmentos, la automatización de la tubería es absolutamente necesaria
Conocer los datos reales es el primer paso para trabajar con tareas de este tipo. Usando máscaras de nubes combinadas con datos de Sentinel-2, puede determinar el número de observaciones de calidad de todos los píxeles, así como la probabilidad promedio de nubes en un área en particular. Gracias a esto, puede comprender mejor los datos existentes y utilizarlos para depurar problemas adicionales.

Imagen en color (izquierda), máscara del número de mediciones de calidad para 2017 (centro) y probabilidad promedio de cobertura de nubes para 2017 (derecha) para un fragmento aleatorio de AOI.
Alguien podría estar interesado en el NDVI promedio para una zona arbitraria, ignorando las nubes. Usando máscaras de nube, puede calcular el valor promedio de cualquier característica, ignorando píxeles sin datos. Por lo tanto, gracias a las máscaras, podemos eliminar imágenes del ruido para casi cualquier característica de nuestros datos.
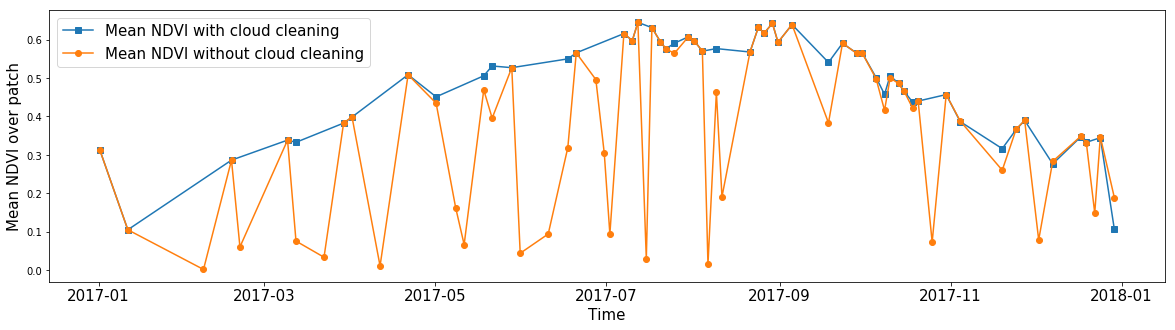
El NDVI promedio de todos los píxeles en un fragmento de AOI aleatorio durante todo el año. La línea azul muestra el resultado del cálculo obtenido si se ignoran los valores dentro de las nubes. La línea naranja muestra el valor promedio cuando se tienen en cuenta todos los píxeles.
"¿Pero qué pasa con la escala?"
Después de configurar nuestro transportador utilizando el ejemplo de un fragmento, todo lo que queda por hacer es comenzar un procedimiento similar para todos los fragmentos automáticamente (en paralelo, si los recursos lo permiten), mientras se relaja con una taza de café y piensa en qué tan grande se sorprenderá gratamente el jefe Los resultados de tu trabajo. Después del final de la canalización, puede exportar los datos que le interesan en una sola imagen en formato GeoTIFF. El script gdal_merge.py recibe las imágenes y las combina, dando como resultado una imagen que cubre todo el país.
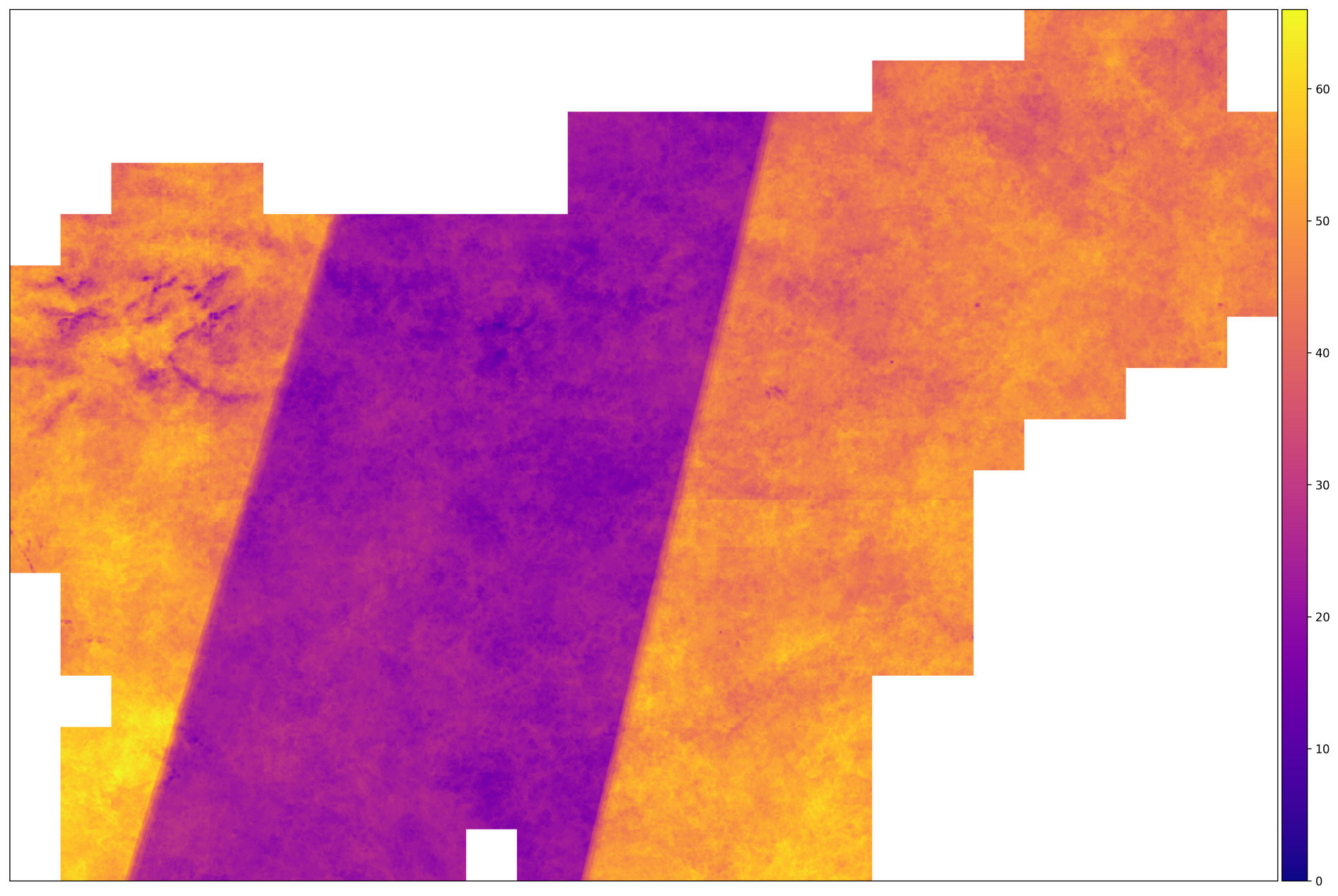
El número de disparos correctos para AOI en 2017. Las regiones con una gran cantidad de imágenes se encuentran en el territorio donde se cruzan la trayectoria de los satélites Sentinel-2A y Sentinel-2B. En el medio de esto no sucede.
De la imagen de arriba, podemos concluir que los datos de entrada son heterogéneos: para algunos fragmentos, el número de imágenes es dos veces mayor que para otros. Esto significa que debemos tomar medidas para normalizar los datos, como la interpolación a lo largo del eje de tiempo.
La ejecución de la tubería especificada demora aproximadamente 140 segundos para un fragmento, lo que en total da ~ 12 horas al iniciar el proceso en todo el AOI. La mayor parte de este tiempo está descargando datos satelitales. El fragmento promedio sin comprimir con la configuración descrita toma aproximadamente 3 GB, lo que en total da ~ 1 TB de espacio para todo el AOI.
Ejemplo en un cuaderno Jupyter
Para una introducción más fácil al código eo-learn , hemos preparado un ejemplo que cubre los temas discutidos en esta publicación. El ejemplo está diseñado como un cuaderno Jupyter, y puede encontrarlo en el directorio de ejemplos del paquete eo-learn .