Todos los días, decenas de miles de empleados de varios miles de organizaciones de todo el mundo trabajan en Pyrus. Consideramos que la capacidad de respuesta del servicio (la velocidad de procesamiento de solicitudes) es una ventaja competitiva importante, ya que afecta directamente la experiencia del usuario. La métrica clave para nosotros es el "porcentaje de consultas lentas". Al estudiar su comportamiento, notamos que una vez por minuto en los servidores de aplicaciones hay pausas de aproximadamente 1000 ms de longitud. En estos intervalos, el servidor no responde y surge una cola de varias docenas de solicitudes. En este artículo se analizará la búsqueda de las causas y la eliminación de los cuellos de botella causados por la recolección de basura en la aplicación.

Los lenguajes de programación modernos se pueden dividir en dos grupos. En lenguajes como C / C ++ o Rust, se usa la administración manual de memoria, por lo que los programadores pasan más tiempo escribiendo código, administrando la vida útil de los objetos y luego depurando. Al mismo tiempo, los errores debidos al uso incorrecto de la memoria son algunos de los más difíciles de depurar, por lo que el desarrollo más moderno se lleva a cabo en idiomas con administración automática de memoria. Estos incluyen, por ejemplo, Java, C #, Python, Ruby, Go, PHP, JavaScript, etc. Los programadores ahorran tiempo de desarrollo, pero debe pagar el tiempo de ejecución adicional que el programa dedica regularmente a la recolección de basura, liberando memoria ocupada por objetos para los que no quedan enlaces en el programa. En programas pequeños, este tiempo es insignificante, pero a medida que aumenta el número de objetos y la intensidad de su creación, la recolección de basura comienza a hacer una contribución notable al tiempo total de ejecución del programa.
Los servidores web de Pyrus se ejecutan en la plataforma .NET, que utiliza la administración automática de memoria. La mayoría de las recolecciones de basura son 'detener el mundo', es decir en el momento de su trabajo, detienen todos los hilos de la aplicación. Los ensamblajes sin bloqueo (en segundo plano) también detienen todos los subprocesos, pero durante un período de tiempo muy corto. Durante el bloqueo de subprocesos, el servidor no procesa las solicitudes, las solicitudes existentes se bloquean, se agregan otras nuevas a la cola. Como resultado, las solicitudes que se procesaron en el momento de la recolección de basura se ralentizan directamente, y las solicitudes se procesan más lentamente inmediatamente después de que se completa la recolección de basura debido a las colas acumuladas. Esto empeora la métrica "porcentaje de consultas lentas".
Armado con el libro recientemente publicado
Konrad Kokosa: Pro .NET Memory Management (sobre cómo trajimos su primera copia a Rusia en 2 días, puede escribir una publicación por separado), completamente dedicado al tema de la administración de memoria en .NET, comenzamos a estudiar el problema.
Medida
Para perfilar el servidor web Pyrus, utilizamos la utilidad PerfView (
https://github.com/Microsoft/perfview ), mejorada para perfilar aplicaciones .NET. La utilidad se basa en el motor de Rastreo de eventos para Windows (ETW) y tiene un impacto mínimo en el rendimiento de la aplicación perfilada, lo que permite su uso en un servidor de combate. Además, el impacto en el rendimiento depende de qué tipos de eventos y qué información recopilamos. No recopilamos nada: la aplicación funciona como de costumbre. Además, PerfView no requiere recompilación ni reinicio de la aplicación.
Ejecute la traza PerfView con el parámetro / GCCollectOnly (tiempo de traza 1,5 horas). En este modo, solo recolecta eventos de recolección de basura y tiene un impacto mínimo en el rendimiento. Veamos el informe de seguimiento Grupo de memoria / GCStats, y en él un resumen de los eventos del recolector de basura:
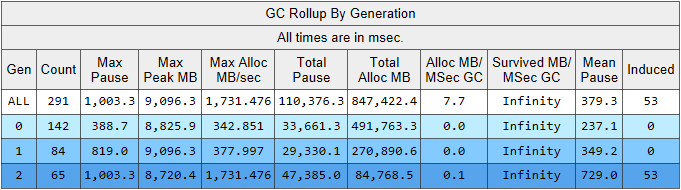
Aquí vemos varios indicadores interesantes a la vez:
- El tiempo de pausa de construcción promedio en la segunda generación es de 700 milisegundos, y la pausa máxima es de aproximadamente un segundo. Esta figura muestra el momento en que todos los subprocesos de la aplicación .NET se detienen, en particular, esta pausa se agregará a todas las solicitudes procesadas.
- El número de ensamblajes de la 2da generación es comparable al de la 1ra generación y es ligeramente menor que el número de ensamblajes de la 0a generación.
- La columna Inducida enumera 53 ensamblajes en la 2da generación. El ensamblaje inducido es el resultado de una llamada explícita a GC.Collect (). En nuestro código, no encontramos una sola llamada a este método, lo que significa que algunas de las bibliotecas utilizadas por nuestra aplicación tienen la culpa.
Expliquemos la observación sobre el número de recolecciones de basura. La idea de dividir los objetos por su tiempo de vida se basa en la
hipótesis generacional : una parte significativa de los objetos creados muere rápidamente, y la mayoría del resto vive mucho tiempo (en otras palabras, pocos objetos que tienen un tiempo de vida "promedio"). Es bajo este modo que el recolector de basura .NET está encarcelado, y en este modo los ensambles de segunda generación deben ser mucho más pequeños que la generación 0. Es decir, para el funcionamiento óptimo del recolector de basura, debemos adaptar el trabajo de nuestra aplicación a la hipótesis generacional. Formulemos la regla de la siguiente manera: los objetos deben morir rápidamente, sin sobrevivir a la generación anterior, o vivir de acuerdo con ellos y vivir allí para siempre. Esta regla también se aplica a otras plataformas que usan administración automática de memoria con separación generacional, como Java.
Los datos que nos interesan se pueden extraer de otra tabla en el informe de GCStats:

Estos son algunos casos en los que una aplicación intenta crear un objeto grande (en .NET Framework se crean objetos> 85,000 bytes de tamaño en el LOH - Montón de objetos grandes), y tiene que esperar la finalización del ensamblado de segunda generación, que tiene lugar en paralelo en segundo plano. Estas pausas del asignador no son tan críticas como las pausas del recolector de basura, ya que afectan solo un hilo. Antes de eso, utilizamos la versión de .NET Framework 4.6.1, y en la versión 4.7.1 Microsoft finalizó el recolector de basura, ahora le permite asignar memoria en el Montón de objetos grandes durante la compilación en segundo plano de la segunda generación:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clrPor lo tanto, hemos actualizado a la última versión 4.7.2 en ese momento.
Construcciones de segunda generación
¿Por qué tenemos tantas versiones de la generación anterior? La primera suposición es que tenemos una pérdida de memoria. Para probar esta hipótesis, echemos un vistazo al tamaño de la segunda generación (configuramos el monitoreo de los contadores de rendimiento correspondientes en Zabbix). A partir de los gráficos del tamaño de segunda generación para 2 servidores Pyrus, se puede ver que su tamaño crece primero (principalmente debido al llenado de cachés), pero luego se estabiliza (grandes fallas en el gráfico - reinicio regular del servicio web para actualizar la versión):
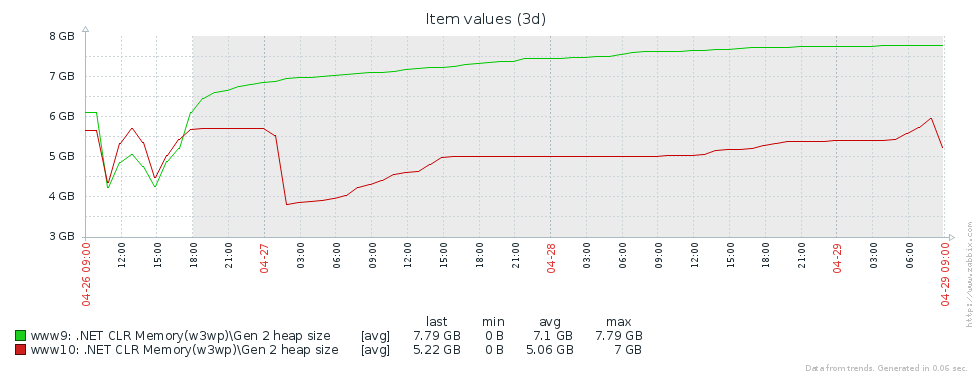
Esto significa que no hay pérdidas de memoria notables, es decir, se produce un gran número de ensamblajes de segunda generación por otra razón. La siguiente hipótesis es que hay mucho tráfico de memoria, es decir, muchos objetos caen en la segunda generación y muchos objetos mueren allí. PerfView tiene un modo / GCOnly para encontrar dichos objetos. De los informes de seguimiento, prestemos atención a las 'Pilas de muertes de objetos gen 2 (muestreo grueso)', que contiene una selección de objetos que mueren en la segunda generación, junto con pilas de llamadas de los lugares donde se crearon estos objetos. Aquí vemos los siguientes resultados:
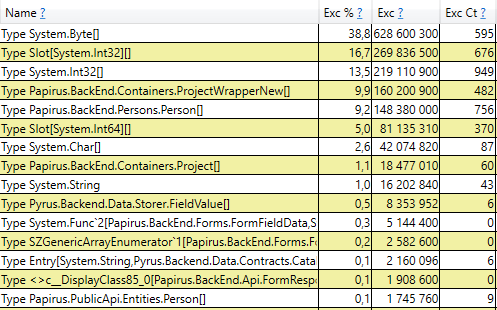
Una vez abierta la línea, en el interior vemos una pila de llamadas de esos lugares en el código que crean objetos que están a la altura de la segunda generación. Entre ellos están:
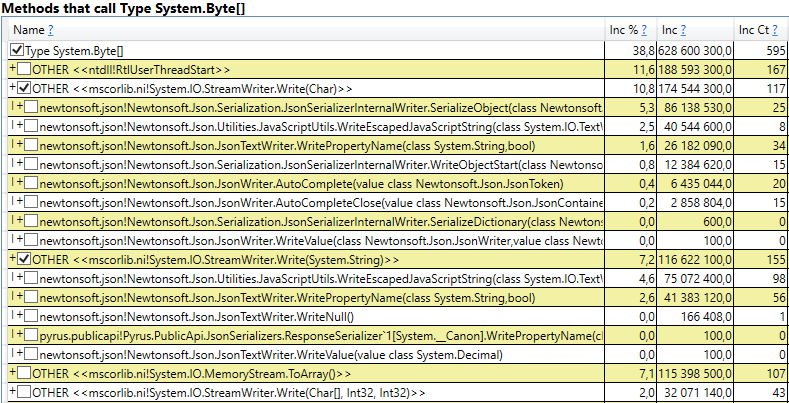
- System.Byte [] Si miras dentro, veremos que más de la mitad son memorias intermedias para la serialización en JSON:
- Ranura [System.Int32] [] (esto es parte de la implementación de HashSet), System.Int32 [], etc. Este es nuestro código que calcula los cachés del cliente: los directorios, formularios, listas, amigos, etc. que este usuario ve y que se almacenan en caché en su navegador o aplicación móvil:

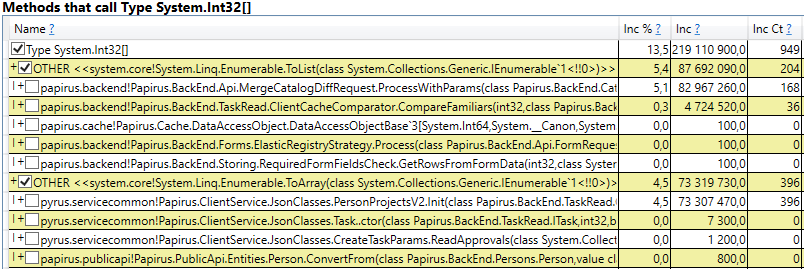
Curiosamente, las memorias intermedias para JSON y para el almacenamiento en caché de clientes son todos objetos temporales que viven en la misma solicitud. ¿Por qué viven hasta la 2da generación? Tenga en cuenta que todos estos objetos son matrices de un tamaño bastante grande. Y en un tamaño> 85000 bytes, la memoria para ellos se asigna en el Montón de objetos grandes, que solo se recopila junto con la segunda generación.
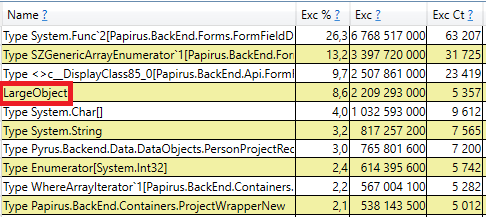
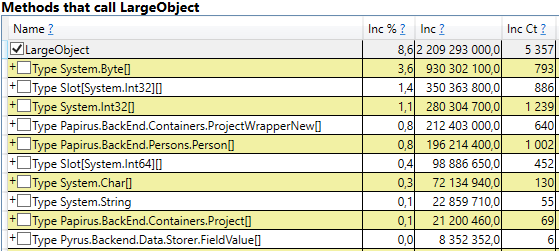
Para verificar, abra la sección 'Pilas de GC Heap Alloc Ignore Free (Coarse Sampling)' en los resultados de perfview / GCOnly. Allí vemos la línea LargeObject, en la que PerfView agrupa la creación de objetos grandes, y en el interior vemos las mismas matrices que vimos en el análisis anterior. Reconocemos la causa raíz de los problemas con el recolector de basura: creamos muchos objetos grandes temporales.
Cambios en el sistema Pyrus
En función de los resultados de la medición, identificamos las principales áreas de trabajo adicional: la lucha contra los objetos grandes al calcular las memorias caché del cliente y la serialización en JSON. Hay varias soluciones a este problema:
- Lo más simple es no crear objetos grandes. Por ejemplo, si se usa el búfer grande B en las transformaciones de datos secuenciales A-> B-> C, entonces a veces estas transformaciones se pueden combinar convirtiéndolas en A-> C y eliminando la creación del objeto B. Esta opción no siempre es aplicable, pero El más simple y más efectivo.
- Piscina de objetos. En lugar de crear constantemente nuevos objetos y tirarlos, cargando el recolector de basura, podemos almacenar una colección de objetos gratuitos. En el caso más simple, cuando necesitamos un nuevo objeto, lo tomamos del grupo o creamos uno nuevo si el grupo está vacío. Cuando ya no necesitamos el objeto, lo devolvemos al grupo. Un buen ejemplo es ArrayPool en .NET Core, que también está disponible en .NET Framework como parte del paquete System.Buffers Nuget.
- Use objetos pequeños en lugar de grandes.
Consideremos por separado ambos casos de objetos grandes: computar cachés de clientes y serializar en JSON.
Cálculo de caché del cliente
El cliente web de Pyrus y las aplicaciones móviles almacenan en caché los datos disponibles para el usuario (proyectos, formularios, usuarios, etc.) El almacenamiento en caché se usa para acelerar el trabajo, también es necesario para trabajar en modo fuera de línea. Las cachés se calculan en el servidor y se transfieren al cliente. Son individuales para cada usuario, ya que dependen de sus derechos de acceso, y a menudo se actualizan, por ejemplo, al cambiar los directorios a los que tiene acceso.
Por lo tanto, muchos de los cálculos de caché del cliente se realizan regularmente en el servidor y se crean muchos objetos temporales de corta duración. Si el usuario es una organización grande, puede obtener acceso a muchos objetos, respectivamente, las memorias caché del cliente para él serán grandes. Es por eso que vimos la asignación de memoria para grandes matrices temporales en el montón de objetos grandes.
Analicemos las opciones propuestas para deshacerse de la creación de objetos grandes:
- Eliminación completa de objetos grandes. Este enfoque no es aplicable, ya que los algoritmos de preparación de datos utilizan, entre otras cosas, la clasificación y la unión de conjuntos, y requieren memorias intermedias temporales.
- Usando un grupo de objetos. Este enfoque tiene dificultades:
- La variedad de colecciones utilizadas y los tipos de elementos en ellas: se utilizan HashSet, List y Array (las últimas 2 se pueden combinar). Int32, Int64, así como todo tipo de clases de datos se almacenan en colecciones. Para cada tipo utilizado, necesitará su propio grupo, que también almacenará colecciones de diferentes tamaños.
- Difícil tiempo de vida de las colecciones. Para obtener beneficios del grupo, los objetos que contenga deberán devolverse después de su uso. Esto se puede hacer si el objeto se usa en un método. Pero en nuestro caso la situación es más complicada, ya que muchos objetos grandes viajan entre métodos, se colocan en estructuras de datos, se transfieren a otras estructuras, etc.
- Implementación Hay ArrayPool de Microsoft, pero aún necesitamos List y HashSet. No encontramos ninguna biblioteca adecuada, por lo que tendríamos que implementar las clases nosotros mismos.
- Uso de objetos pequeños. Una matriz grande se puede dividir en varias piezas pequeñas, que no cargaré el montón de objetos grandes, sino que se crearán en la generación 0 y luego seguirán el camino estándar en la 1ra y 2da. Esperamos que no estén a la altura de la 2da, sino que sean recolectados por el recolector de basura en la 0, o en casos extremos en la 1ra generación. La ventaja de este enfoque es que los cambios en el código existente son mínimos. Dificultades:
- Implementación No encontramos ninguna biblioteca adecuada, por lo que tendríamos que escribir las clases nosotros mismos. La falta de bibliotecas es comprensible, ya que el escenario "colecciones que no cargan el montón de objetos grandes" es un ámbito muy limitado.
Decidimos seguir el tercer camino e
inventar nuestra bicicleta para escribir List y HashSet, sin cargar el montón de objetos grandes.
Lista de piezas
Nuestra ChunkedList <T> implementa interfaces estándar, incluida IList <T>, que requiere cambios mínimos en el código existente. Sí, y la biblioteca Newtonsoft.Json que utilizamos es capaz de serializarlo automáticamente, ya que implementa IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
La lista estándar <T> tiene los siguientes campos: matriz de elementos y el número de elementos rellenos. En ChunkedList <T> hay una matriz de matrices de elementos, la cantidad de matrices completamente llenas, la cantidad de elementos en la última matriz. Cada una de las matrices de elementos con menos de 85,000 bytes:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
Como la ChunkedList <T> es bastante complicada, escribimos pruebas detalladas sobre ella. Cualquier operación debe probarse en al menos 2 modos: en "pequeño" cuando la lista completa cabe en una sola pieza de hasta 85,000 bytes de tamaño, y "grande" cuando consiste en más de una pieza. Además, para los métodos que cambian el tamaño (por ejemplo, Agregar), los escenarios son aún mayores: "pequeño" -> "pequeño", "pequeño" -> "grande", "grande" -> "grande", "grande" -> pequeño ". Aquí hay bastantes casos confusos de límites que las pruebas unitarias funcionan bien.
La situación se simplifica por el hecho de que algunos de los métodos de la interfaz IList no se utilizan y pueden omitirse (como Insertar, Eliminar). Su implementación y pruebas serían bastante costosas. Además, la escritura de pruebas unitarias se simplifica por el hecho de que no necesitamos crear una nueva funcionalidad, ChunkedList <T> debería comportarse igual que List <T>. Es decir, todas las pruebas se organizan de la siguiente manera: cree una Lista <T> y ChunkedList <T>, realice las mismas operaciones en ellas y compare los resultados.
Medimos el rendimiento utilizando la biblioteca BenchmarkDotNet para asegurarnos de que no ralentizamos mucho nuestro código al cambiar de List <T> a ChunkedList <T>. Probemos, por ejemplo, agregando elementos a la lista:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
Y la misma prueba usando List <T> para comparar. Resultados al agregar 500 elementos (todo cabe en una matriz):
Resultados al agregar 50,000 elementos (divididos en varias matrices):
Descripción detallada de las columnas en los resultados. BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
Si observa la columna 'Media', que muestra el tiempo promedio de ejecución de la prueba, puede ver que nuestra implementación es solo 2-2.5 veces más lenta que el estándar. Teniendo en cuenta que en el código real, las operaciones con listas son solo una pequeña parte de todas las acciones realizadas, esta diferencia se vuelve insignificante. Pero la columna 'Gen 2 / 1k op' (el número de ensamblajes de la segunda generación para 1000 pruebas) muestra que hemos logrado el objetivo: con una gran cantidad de elementos, ChunkedList no crea basura en la segunda generación, que era nuestra tarea.
Conjunto de piezas
Del mismo modo, ChunkedHashSet <T> implementa la interfaz ISet <T>. Al escribir el ChunkedHashSet <T>, reutilizamos la pequeña lógica de fragmentos ya implementada en la ChunkedList. Para hacer esto, tomamos una implementación lista para usar de HashSet <T> de la Fuente de referencia de .NET, disponible bajo la licencia MIT, y reemplazamos los arreglos con ChunkedLists.
En las pruebas unitarias, también usamos el mismo truco que para las listas: compararemos el comportamiento de ChunkedHashSet <T> con la referencia HashSet <T>.
Finalmente, pruebas de rendimiento. La operación principal que utilizamos es la unión de conjuntos, por lo que lo estamos probando:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
Y exactamente la misma prueba para el HashSet estándar. Primera prueba para juegos pequeños:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
La segunda prueba para conjuntos grandes que causó un problema con un montón de objetos grandes:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
Los resultados son similares a los listados. ChunkedHashSet es más lento 2-2.5 veces, pero al mismo tiempo en conjuntos grandes, carga la segunda generación 2 órdenes de magnitud menos.
Serialización en JSON
El servidor web Pyrus proporciona varias API que utilizan diferentes serializaciones. Descubrimos la creación de objetos grandes en la API utilizada por los bots y la utilidad de sincronización (en adelante, la API pública). Tenga en cuenta que, básicamente, la API utiliza su propia serialización, que no se ve afectada por este problema. Escribimos sobre esto en el artículo
https://habr.com/en/post/227595/ , en la sección "2. No sabes dónde está el cuello de botella de tu aplicación ". Es decir, la API principal ya está funcionando bien, y el problema apareció en la API pública a medida que crecía la cantidad de solicitudes y la cantidad de datos en las respuestas.
Optimicemos la API pública. Usando el ejemplo de la API principal, sabemos que puede devolver una respuesta al usuario en modo de transmisión. Es decir, no es necesario crear memorias intermedias intermedias que contengan la respuesta completa, sino escribir la respuesta inmediatamente en la secuencia.
Tras una inspección más cercana, descubrimos que en el proceso de serialización de la respuesta, creamos un búfer temporal para el resultado intermedio ('contenido' es una matriz de bytes que contiene JSON en la codificación UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
Veamos dónde se usa el contenido. Por razones históricas, la API pública se basa en WCF, para el cual XML es el formato estándar de solicitud y respuesta. En nuestro caso, la respuesta XML tiene un único elemento 'Binario', dentro del cual se escribe JSON codificado en Base64:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
Tenga en cuenta que aquí no se necesita un búfer temporal. JSON se puede escribir inmediatamente en el búfer XmlWriter que nos proporciona WCF, codificándolo en Base64 sobre la marcha. Por lo tanto, iremos por el primer camino, eliminando la asignación de memoria:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
Aquí Base64Writer es un contenedor simple sobre XmlWriter que implementa la interfaz Stream, que escribe en XmlWriter como Base64. Al mismo tiempo, desde toda la interfaz, es suficiente implementar solo un método de escritura, que se llama en StreamWriter:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
Gc inducido
Tratemos de lidiar con misteriosas recolecciones de basura inducidas. Volvimos a verificar nuestro código 10 veces para las llamadas de GC.Collect, pero esto falló. Logré capturar estos eventos en PerfView, pero la pila de llamadas no es muy indicativa (DotNETRuntime / GC / Triggered event):
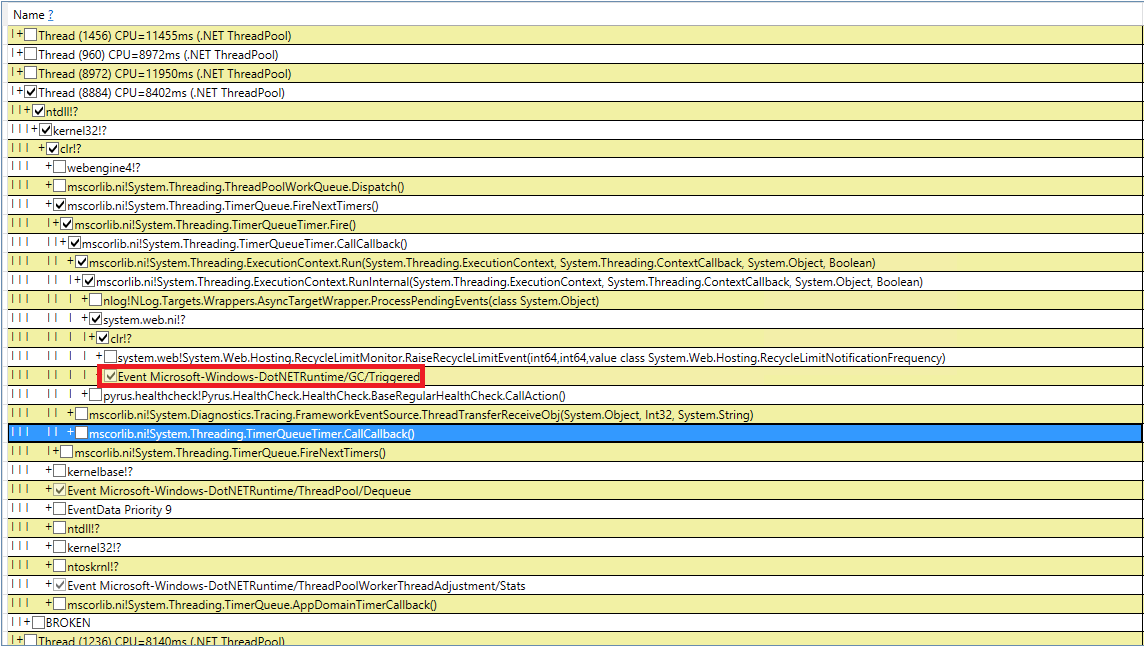
Hay una pequeña pista: llamar a RecycleLimitMonitor.RaiseRecycleLimitEvent antes de la recolección de basura inducida. Rastreemos la pila de llamadas al método RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
Los nombres de los métodos son consistentes con sus funciones:
- En el constructor de RecycleLimitMonitor.RecycleLimitMonitorSingleton, se crea un temporizador que llama a PBytesMonitorThread en un intervalo determinado.
- PBytesMonitorThread recopila estadísticas sobre el uso de la memoria y, en algunas condiciones, llama a CollectInfrerecuentemente.
- CollectInfreually llama a AlertProxyMonitors, obtiene un bool como resultado y llama a GC.Collect () si se vuelve verdadero. También supervisa el tiempo transcurrido desde la última llamada al recolector de basura, y no lo llama con demasiada frecuencia.
- AlertProxyMonitors revisa la lista de aplicaciones web IIS en ejecución, para cada una levanta el objeto RecycleLimitMonitor correspondiente y llama a RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent plantea la lista IObserver <RecycleLimitInfo>. Los manejadores reciben como parámetro RecycleLimitInfo, en el que pueden establecer el indicador RequestGC, que vuelve a CollectInfrecasionalmente, provocando una recolección de basura inducida.
Una investigación adicional revela que los controladores IObserver <RecycleLimitInfo> se agregan en el método RecycleLimitMonitor.Subscribe (), que se llama en el método AspNetMemoryMonitor.Subscribe (). Además, el controlador predeterminado IObserver <RecycleLimitInfo> (la clase RecycleLimitObserver) se cuelga en la clase AspNetMemoryMonitor, que limpia los cachés ASP.NET y, a veces, solicita la recolección de basura.
El enigma del GC inducido está casi resuelto. Queda por descubrir la pregunta de por qué se llama esta recolección de basura. RecycleLimitMonitor monitorea el uso de la memoria IIS (más precisamente, el número de bytes privados), y cuando su uso se acerca a un cierto límite, comienza con un algoritmo bastante confuso para generar el evento RaiseRecycleLimitEvent. El valor de AspNetMemoryMonitor.ProcessPrivateBytesLimit se utiliza como límite de memoria y, a su vez, contiene la siguiente lógica:
- Si el grupo de aplicaciones en IIS se establece en 'Límite de memoria privada (KB)', entonces el valor en kilobytes se toma de allí
- De lo contrario, para sistemas de 64 bits, se toma el 60% de la memoria física (para sistemas de 32 bits, la lógica es más complicada).
La conclusión de la investigación es la siguiente: ASP.NET se está acercando a su límite de memoria y comienza a llamar regularmente a la recolección de basura. El 'Límite de memoria privada (KB)' no estaba configurado, por lo que ASP.NET estaba limitado al 60% de la memoria física. El problema estaba enmascarado por el hecho de que en el servidor del Administrador de tareas mostraba mucha memoria libre y parecía que faltaba. Hemos aumentado el valor del 'Límite de memoria privada (KB)' en la configuración del grupo de aplicaciones en IIS al 80% de la memoria física. Esto alienta a ASP.NET a usar más memoria disponible. También agregamos la supervisión del contador de rendimiento '.NET CLR Memory / # Induced GC' para no perderse la próxima vez que ASP.NET decida que se está acercando al límite de uso de memoria.
Mediciones repetidas
Veamos qué sucedió con la recolección de basura después de todos estos cambios. Comencemos con perfview / GCCollectOnly (tiempo de rastreo - 1 hora), informe GCStats:
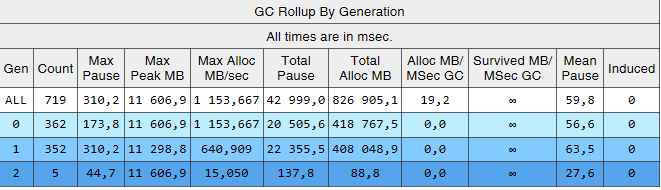
Se puede ver que las asambleas de la segunda generación ahora son 2 órdenes de magnitud más pequeñas que la 0 y la 1ra. Además, el tiempo de estas asambleas disminuyó. Los ensamblajes inducidos ya no se observan. Veamos la lista de ensamblajes de la 2da generación:
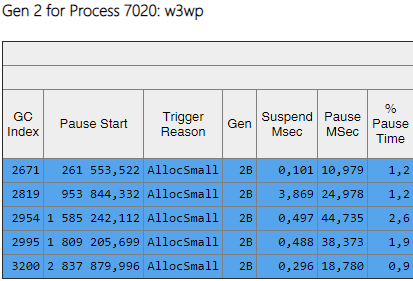
La columna Gen muestra que todos los ensamblajes de la segunda generación se han convertido en segundo plano ('2B' significa segunda generación, segundo plano). Es decir, la mayor parte del trabajo se realiza en paralelo con la ejecución de la aplicación, y todos los subprocesos se bloquean por un corto tiempo (columna 'Pausar MSec'). Veamos las pausas al crear objetos grandes:

Se puede ver que el número de tales pausas al crear objetos grandes disminuyó significativamente.
Resumen
Gracias a los cambios descritos en el artículo, fue posible reducir significativamente el número y la duración de los ensamblajes de la segunda generación. Logré encontrar la causa de las asambleas inducidas y deshacerme de ellas. El número de ensamblajes de la generación 0 y 1 aumentó, pero su duración promedio disminuyó (de ~ 200 ms a ~ 60 ms). La duración máxima de ensamblaje de la generación 0 y 1 ha disminuido, pero no tan notablemente. Los ensambles de segunda generación se hicieron más rápidos, las pausas largas de hasta 1000 ms desaparecieron por completo.
En cuanto a la métrica clave: "porcentaje de consultas lentas", disminuyó en un 40% después de todos los cambios.
Gracias a nuestro trabajo, nos dimos cuenta de qué contadores de rendimiento son necesarios para evaluar la situación con la memoria y la recolección de basura, y los agregamos a Zabbix para un monitoreo continuo. Aquí hay una lista de los más importantes a los que prestamos atención y descubrimos el motivo (por ejemplo, un mayor flujo de solicitudes, una gran cantidad de datos transmitidos, un error en la aplicación):