El título del artículo puede parecer extraño y por una buena razón: es hermoso precisamente porque no fue escrito por mí, sino por la red neuronal LSTM (o más bien, su parte antes de "o").
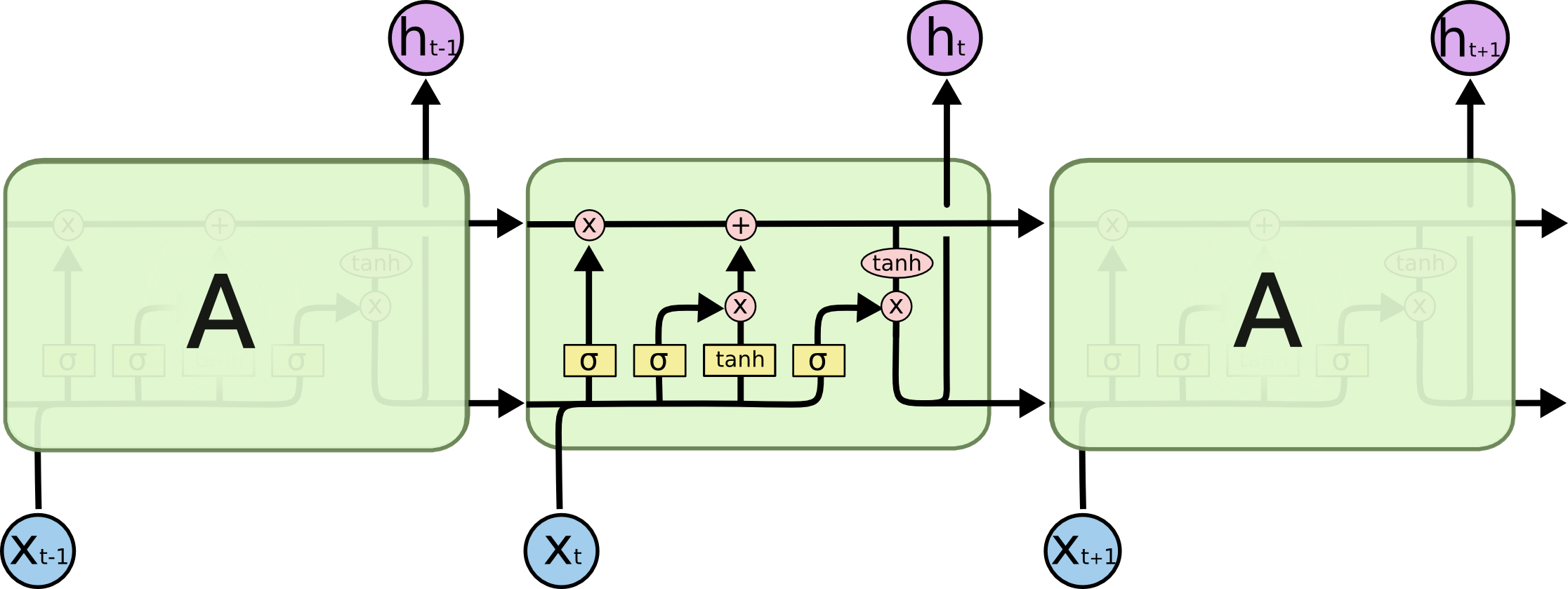
(Esquema LSTM tomado de Understanding LSTM Networks )
Y hoy descubriremos cómo puede generar los encabezados de los artículos de Habr (y, en principio, el texto en sí puede ser generado por la misma neuroarquitectura). Todo el código está disponible para ejecutarse en línea en cuadernos de Google. Los datos, como siempre, están abiertos en github .
Y aquí puede ejecutar el modelo ya entrenado en la GPU de Google (de forma gratuita y sin SMS) y generar encabezados.
Enlaces clave
La teoría y la descripción de las redes neuronales (en particular LSTM) en este artículo se basan en
Descripción de datos
En total, se recopilaron alrededor de 40.000 títulos de artículos : cada título se complementó con dos caracteres especiales <START_CHAR> y <END_CHAR> al principio y al final, así como <PADDING_CHAR> después de <END_CHAR> hasta el tamaño máximo del título.
Un ejemplo de los datos recopilados:
Google IT . Now it's official
Teoría LSTM
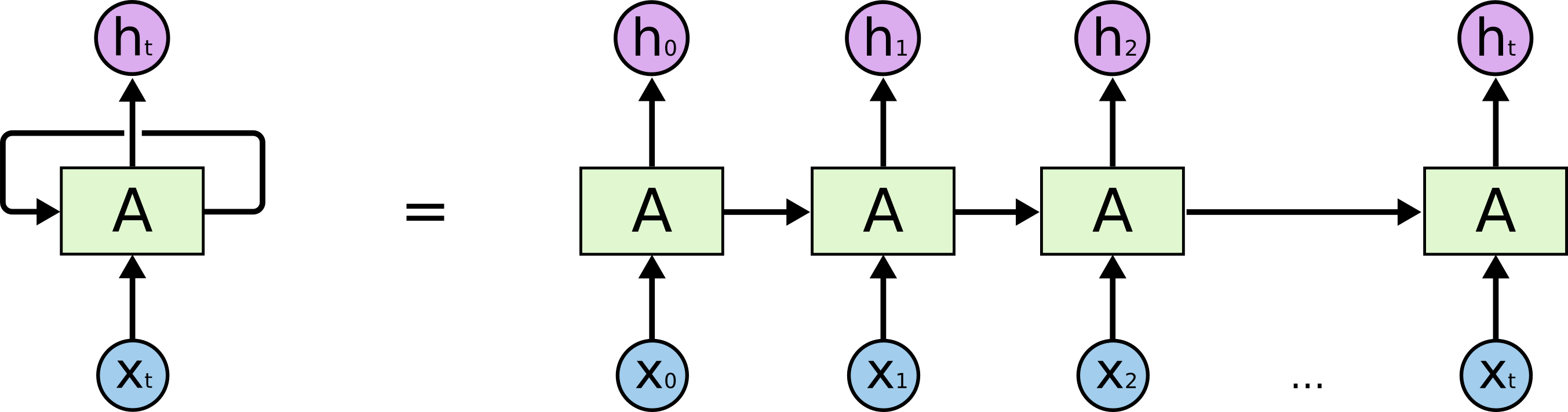
Comencemos con la tarea real que estamos resolviendo: queremos predecir la línea (N + 1) en N caracteres, ilustrativamente desde el punto de vista del modelo LSTM, se ve como en la imagen a continuación: X a continuación: datos de entrada; h arriba son fines de semana; entre ellos está el estado interno de la red. Con un poco más de detalle: la imagen de la izquierda con un bucle de retroalimentación, equivalente a una cadena detallada a la derecha.
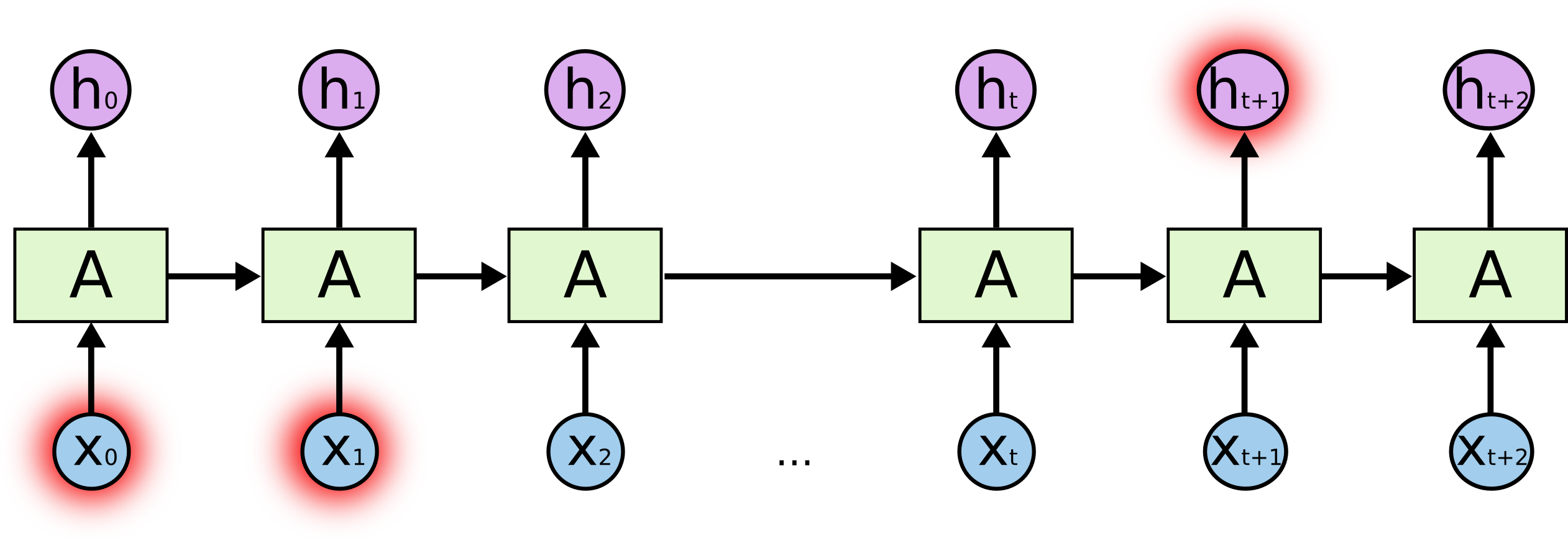
¿Qué es la sal? Al predecir un personaje resaltado al final, los personajes resaltados al principio pueden desempeñar un papel clave, de ahí el término Dependencias a largo plazo. Está claro que, a menudo, los personajes que se encuentran inmediatamente junto a ellos juegan un papel importante: estas dependencias se denominan dependencias a corto plazo.
Componentes internos de la celda LSTM:
Toda la celda contiene cuatro elementos básicos.
- Puertas del olvido: un elemento decide que se quedará sin memoria
- Puerta de entrada: crea un conjunto de "valores candidatos" que podemos usar para escribir y actualizar la memoria
- Memoria: un elemento decide qué es realmente y cómo ahorramos
- Elemento de salida: define la salida del modelo
Designaciones:

Puerta del olvido
Si estamos tratando de predecir el final de una palabra, es importante saber el género del nombre actual, si vimos un nombre nuevo, vale la pena olvidar el significado anterior:

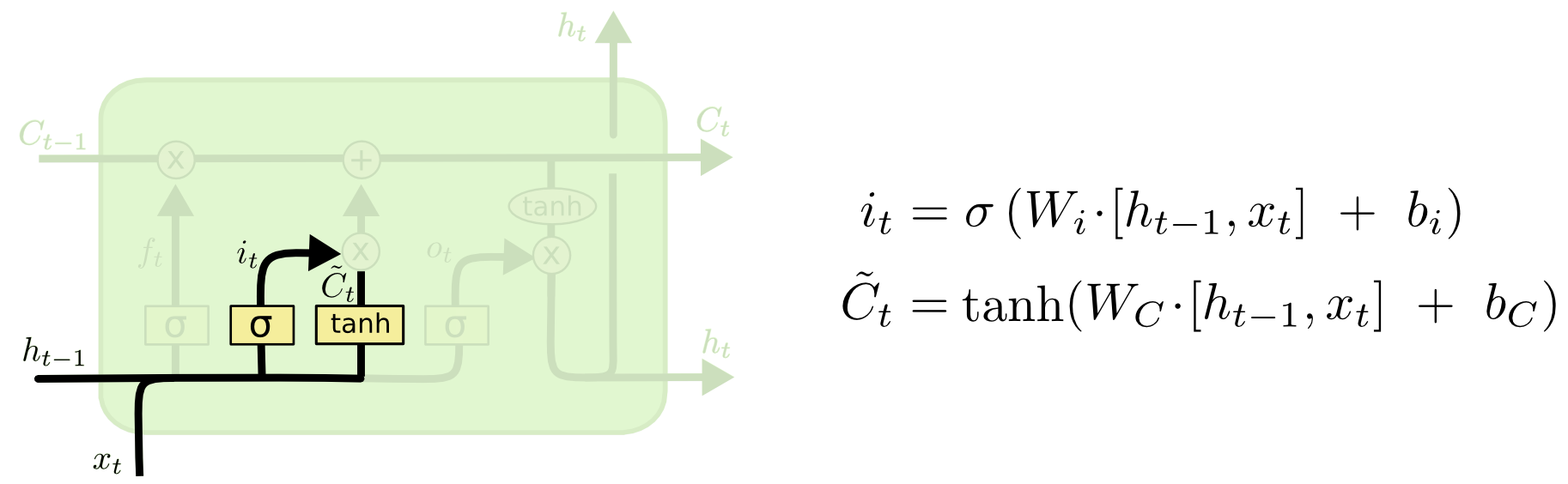
Puerta de entrada
A continuación, calculamos i t , que determinará qué valores de la celda de memoria queremos actualizar, y
calcula los valores candidatos para la actualización.
Celda de memoria
Luego, los valores de la memoria son una superposición de lo que olvidamos en el estado actual y lo que agregamos

Modelo de salida
¿Qué es la inferencia del modelo? Una combinación de tres cosas: el símbolo de entrada actual, la predicción previa y la memoria del modelo

Código
La lógica básica del modelo se presenta a continuación, como regla: este es aproximadamente el 5-10% del código completo, todo el código restante es la limpieza, preparación y procesamiento de datos, así como la salida en una forma legible para los humanos.
Aquí puede ejecutar el código con un modelo ya entrenado.
model = Sequential()
Ejemplos de encabezados creados
Muestreo personal:
python powershell
(Las referencias de modelos aleatorios al Dr. Strangelove son especialmente agradables)
¿Qué es la temperatura (en el contexto de DL)
En la salida, el modelo genera los pesos x w de las palabras w: tenemos opciones sobre cómo convertir estos pesos en probabilidades p (w), por ejemplo, usando la fórmula:
Donde T es un parámetro libre (en física, así es como se determina estadísticamente la temperatura, de ahí el nombre), cuanto menor sea la temperatura, mayor será el exponente y los pesos más altos "eliminarán" toda probabilidad, es decir, el modelo predecirá solo unas pocas palabras con el máximo pesos, si la temperatura es alta, entonces la distribución se moverá a un uniforme y más "creativo". Esto nos da la oportunidad de controlar el equilibrio entre seguir con precisión los datos disponibles y la creatividad condicional del modelo.
Ejemplo de salida del modelo using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
Conclusiones
- La arquitectura LSTM modela secuencias bien y claramente
- La gramática y la lógica a menudo sufren, probablemente problemas en dos lugares: primero, el dispositivo de memoria es bastante simple y no puede captar todas las reglas y el contexto; segundo, el poder del caso: el conjunto de datos es bastante pequeño y no demasiado diverso
- Sería interesante echar un vistazo a la versión de Better Language Models y sus implicaciones en el gran caso del idioma ruso, para comprender si la arquitectura y un caso más poderoso resuelven estos problemas
- Algunos de los titulares salieron increíblemente ridículos y autoirónicos, por ejemplo, "... y por qué la culpa de esto"
- Vemos ciertas regularidades de los títulos de Habr, por ejemplo, "hicimos \ creamos \ construimos", un claro indicador de que a la gente le gusta compartir historias personales sobre Habr