Parte 1
Parte 3
Pasar de datos a resultados sin salir de su computadora

Una pila de imágenes de una pequeña zona en Eslovenia, y un mapa con una cubierta de tierra clasificada obtenida utilizando los métodos descritos en el artículo.
Prólogo
La segunda parte de una serie de artículos sobre clasificación de la cobertura del suelo utilizando la biblioteca eo-learn. Le recordamos que el primer artículo demostró lo siguiente:
- Dividiendo AOI (área de interés) en fragmentos llamados EOPatch
- Recepción de imágenes y máscaras en la nube de los satélites Sentinel-2
- Cálculo de información adicional como NDWI , NDVI
- Crear una máscara de referencia y agregarla a los datos de origen
Además, realizamos un estudio de superficie de los datos, que es un paso extremadamente importante antes de comenzar una inmersión en el aprendizaje automático. Las tareas anteriores se complementaron con un ejemplo en forma de un cuaderno Jupyter , que ahora contiene material de este artículo.
En este artículo, finalizaremos la preparación de los datos y también construiremos el primer modelo para construir mapas de cobertura del suelo para Eslovenia en 2017.
Preparación de datos
La cantidad de código que se relaciona directamente con el aprendizaje automático es bastante pequeña en comparación con el programa completo. La mayor parte del trabajo es borrar los datos, manipular los datos de tal manera que se garantice un uso perfecto con el clasificador. Esta parte del trabajo se describirá a continuación.

Un diagrama de canalización de aprendizaje automático que muestra que el código en sí mismo usando ML es una pequeña fracción de todo el proceso. Fuente
Filtro de imagen en la nube
Las nubes son entidades que generalmente aparecen en una escala que excede nuestro EOPatch promedio (1000x1000 píxeles, resolución 10m). Esto significa que cualquier sitio puede estar completamente cubierto por nubes en fechas aleatorias. Dichas imágenes no contienen información útil y solo consumen recursos, por lo que las omitimos en función de la proporción de píxeles válidos con respecto al número total y establecemos un umbral. Podemos llamar válidos todos los píxeles que no están clasificados como nubes y que se encuentran dentro de una imagen de satélite. Tenga en cuenta también que no utilizamos las máscaras suministradas con las imágenes Sentinel-2, ya que se calculan al nivel de las imágenes completas (el tamaño de la imagen S2 completa es de 10980 × 10980 píxeles, aproximadamente 110 × 110 km), lo que significa que, en su mayor parte, no es necesario para nuestro AOI. Para determinar las nubes, utilizaremos el algoritmo del paquete s2cloudless para obtener una máscara de píxeles de nubes.
En nuestro cuaderno, el umbral se establece en 0.8, por lo que seleccionamos solo imágenes llenas de datos normales en un 80%. Esto puede parecer un valor bastante alto, pero dado que las nubes no son un problema demasiado grande para nuestro AOI, podemos pagarlo. Vale la pena considerar que este enfoque no se puede aplicar irreflexivamente a ningún punto del planeta, ya que el área que ha elegido puede estar cubierta de nubes durante una parte importante del año.
Interpolación temporal
Debido al hecho de que las imágenes pueden omitirse en algunas fechas, así como debido a fechas de adquisición de AOI inconsistentes, la falta de datos es una ocurrencia muy común en el campo de la observación de la Tierra. Una forma de resolver este problema es imponer una máscara de validez de píxeles (del paso anterior) e interpolar los valores para "rellenar huecos". Como resultado del proceso de interpolación, los valores de píxeles faltantes se pueden calcular para crear un EOPatch que contenga instantáneas en días distribuidos de manera uniforme. En este ejemplo, utilizamos interpolación lineal, pero hay otros métodos, algunos de los cuales ya están implementados en eo-learn.

A la izquierda hay una pila de imágenes Sentinel-2 de un AOI seleccionado al azar. Los píxeles transparentes significan datos faltantes debido a las nubes. La imagen de la derecha muestra la pila después de la interpolación, teniendo en cuenta las máscaras de nubes.
La información temporal es extremadamente importante en la clasificación de la cobertura, y aún más importante en la tarea de identificar una cultura de germinación. Todo esto se debe al hecho de que una gran cantidad de información sobre la cobertura del suelo está oculta en la forma en que la trama cambia a lo largo del año. Por ejemplo, al ver los valores de NDVI interpolados, puede ver que los valores en los bosques y campos alcanzan sus máximos en la primavera / verano y caen fuertemente en el otoño / invierno, mientras que el agua y las superficies artificiales mantienen estos valores aproximadamente constantes durante todo el año. Las superficies artificiales tienen valores de NDVI ligeramente más altos en comparación con el agua, y repiten parcialmente el desarrollo de bosques y campos, ya que en las ciudades a menudo se pueden encontrar parques y otra vegetación. También debe tener en cuenta las limitaciones asociadas con la resolución de las imágenes: a menudo, en el área cubierta por un píxel, puede observar varios tipos de cobertura al mismo tiempo.
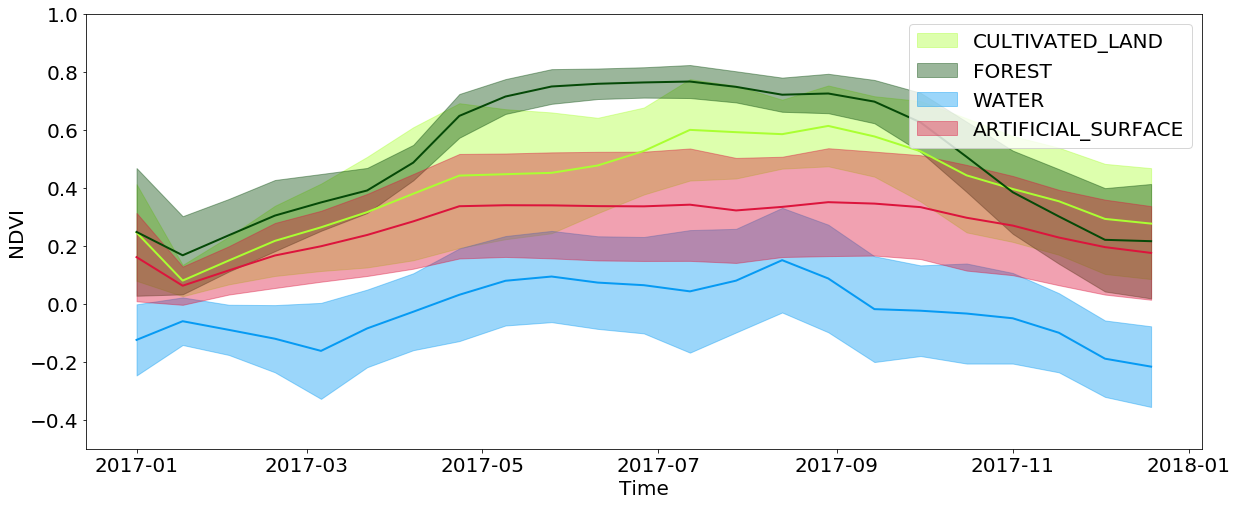
Desarrollo temporal de valores NDVI para píxeles de tipos específicos de cobertura terrestre durante todo el año.
Almacenamiento en búfer negativo
Aunque una resolución de imagen de 10 m es suficiente para una amplia gama de tareas, los efectos secundarios de los objetos pequeños son bastante significativos. Dichos objetos se encuentran en el borde entre los diferentes tipos de cubierta, y a estos píxeles se les asignan los valores de solo uno de los tipos. Debido a esto, al entrenar al clasificador, hay un exceso de ruido en los datos de entrada, lo que empeora el resultado. Además, las carreteras y otros objetos con un ancho de 1 píxel están presentes en el mapa original, aunque son extremadamente difíciles de identificar a partir de las imágenes. Aplicamos un búfer negativo de 1 píxel al mapa de referencia, eliminando casi todas las áreas problemáticas de la entrada.
Mapa de referencia de AOI antes (izquierda) y después (derecha) de almacenamiento en búfer negativo
Selección aleatoria de datos
Como se mencionó en un artículo anterior, el AOI completo se divide en aproximadamente 300 fragmentos, cada uno de los cuales consta de ~ 1 millón de píxeles. Esta es una cantidad bastante impresionante de estos mismos píxeles, por lo que tomamos aproximadamente 40,000 píxeles por cada EOPatch para obtener un conjunto de datos de 12 millones de copias. Dado que los píxeles se toman de manera uniforme, un gran número no importa en el mapa de referencia, ya que estos datos son desconocidos (o se perdieron después del paso anterior). Tiene sentido filtrar dichos datos para simplificar la capacitación del clasificador, ya que no necesitamos enseñarle a definir la etiqueta de "sin datos". El mismo procedimiento se repite para el conjunto de pruebas, ya que dichos datos degradan artificialmente los indicadores de calidad de las predicciones del clasificador.
Dividimos los datos de entrada en conjuntos de entrenamiento / prueba en una proporción del 80/20%, respectivamente, en el nivel EOPatch, lo que nos garantiza que estos conjuntos no se cruzan. También dividimos los píxeles del conjunto para entrenamiento en conjuntos para prueba y validación cruzada de la misma manera. Después de la separación, obtenemos una matriz de dimensión numpy.ndarray (p,t,w,h,d) , donde:
p es el número de EOPatch en el conjunto de datos
t - el número de imágenes interpoladas para cada EOPatch
* w, h, d - ancho, alto y el número de capas en las imágenes, respectivamente.
Después de seleccionar los subconjuntos, el ancho w corresponde al número de píxeles seleccionados (por ejemplo, 40,000), mientras que la dimensión h es 1. La diferencia en la forma de la matriz no cambia nada, este procedimiento solo es necesario para simplificar el trabajo con imágenes.
Los datos de los sensores y la máscara d en cualquier imagen t determinan los datos de entrada para el entrenamiento, donde tales casos totalizan p*w*h . Para convertir los datos en una forma digerible para el clasificador, debemos reducir la dimensión de la matriz de 5 a la matriz de la forma (p*w*h, d*t) . Esto es fácil de hacer con el siguiente código:
import numpy as np p, t, w, h, d = features_array.shape
Tal procedimiento permitirá hacer una predicción sobre nuevos datos de la misma forma, y luego convertirlos nuevamente y visualizarlos por medios estándar.
Crear un modelo de aprendizaje automático
La elección óptima del clasificador depende en gran medida de la tarea específica, e incluso con la elección correcta no debemos olvidar los parámetros de un modelo específico, que debe cambiarse de una tarea a otra. Por lo general, es necesario realizar muchos experimentos con diferentes conjuntos de parámetros para decir con precisión lo que se necesita en una situación particular.
En esta serie de artículos, utilizamos el paquete LightGBM , porque es un marco intuitivo, rápido, distribuido y productivo para construir modelos basados en árboles de decisión. Para seleccionar hiperparámetros clasificadores, se pueden usar diferentes enfoques, como la búsqueda de cuadrícula , que se debe probar en un conjunto de prueba. Para simplificar, omitiremos este paso y utilizaremos los parámetros predeterminados.
El esquema de trabajo de los árboles de decisión en LightGBM. Fuente
La implementación del modelo es bastante simple, y dado que los datos ya vienen en forma de matriz, simplemente alimentamos estos datos a la entrada del modelo y esperamos. Felicidades Ahora puedes decirle a todos que estás involucrado en el aprendizaje automático y que serás el chico más a la moda en una fiesta, mientras que tu madre estará nerviosa por la rebelión de los robots y la muerte de la humanidad.
Validación del modelo
La formación de modelos en aprendizaje automático es fácil. La dificultad es entrenarlos bien . Para esto, necesitamos un algoritmo adecuado, una tarjeta de referencia confiable y una cantidad suficiente de recursos informáticos. Pero incluso en este caso, los resultados pueden no ser los deseados, por lo que es absolutamente necesario verificar el clasificador con matrices de error y otras métricas para tener al menos algo de confianza en los resultados de su trabajo.
Matriz de error
Las matrices de error son lo primero que se debe tener en cuenta al evaluar la calidad de los clasificadores. Muestran el número de etiquetas predichas correcta e incorrectamente para cada etiqueta de la tarjeta de referencia y viceversa. Por lo general, se usa una matriz normalizada, donde todos los valores en las líneas se dividen por la cantidad total. Esto muestra si el clasificador no tiene un sesgo hacia un cierto tipo de cobertura en relación con otro
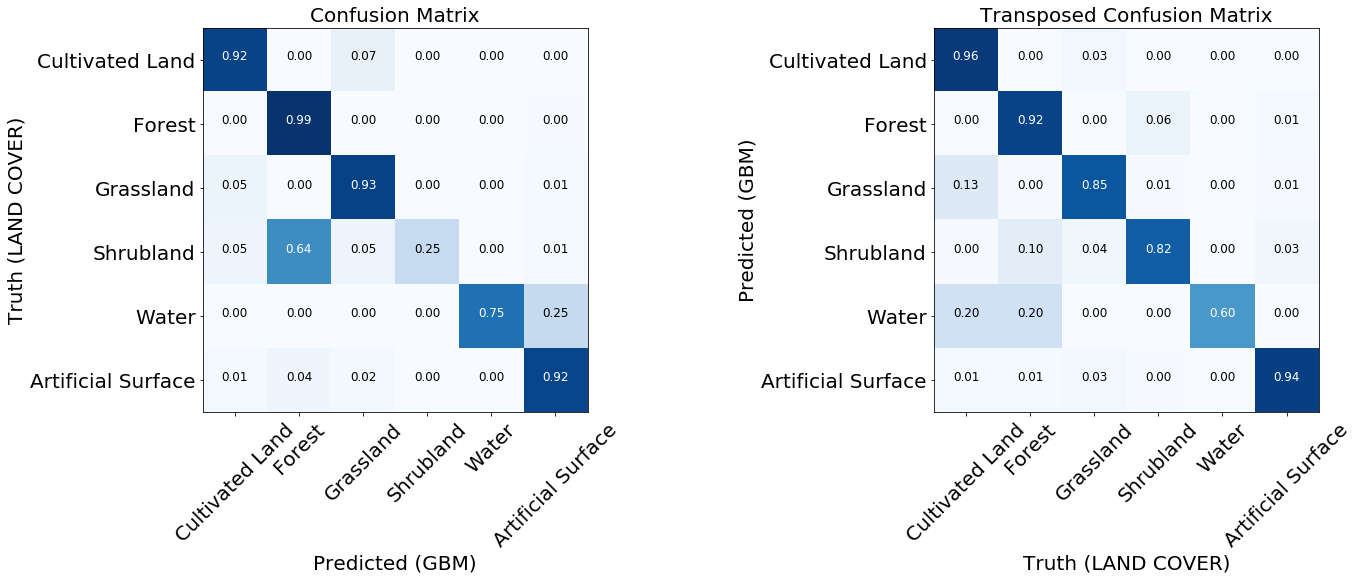
Dos matrices de error normalizadas del modelo entrenado.
Para la mayoría de las clases, el modelo muestra buenos resultados. Para algunas clases, se producen errores debido al desequilibrio en los datos de entrada. Vemos que el problema es, por ejemplo, arbustos y agua, para lo cual el modelo a menudo confunde las etiquetas de píxeles y las identifica incorrectamente. Por otro lado, lo que está marcado como arbusto o agua se correlaciona bastante bien con el mapa de referencia. De la siguiente imagen, podemos notar que surgen problemas para las clases que tienen una pequeña cantidad de instancias de entrenamiento; esto se debe principalmente a la pequeña cantidad de datos en nuestro ejemplo, pero este problema puede ocurrir en cualquier tarea real.
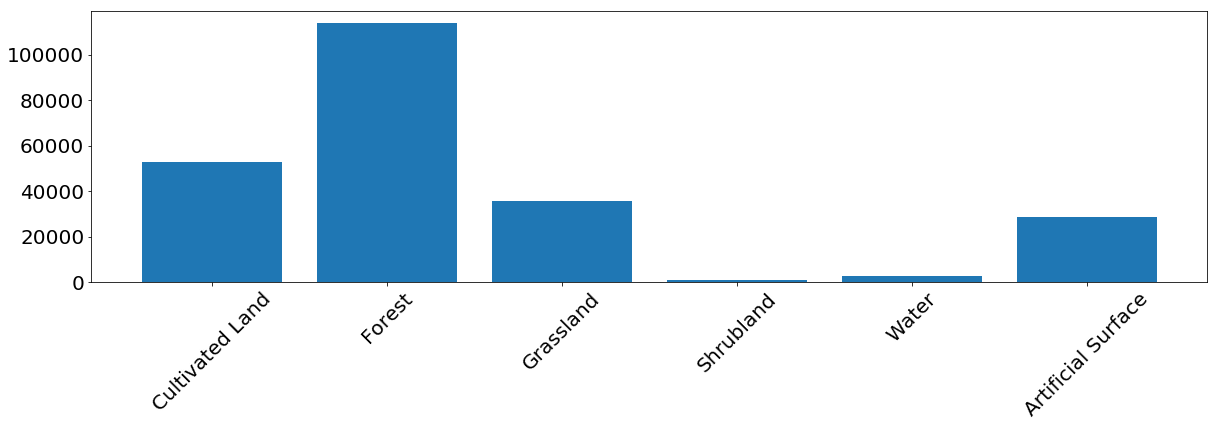
La frecuencia de aparición de píxeles de cada clase en el conjunto de entrenamiento.
Características operativas del receptor: curva ROC
Los clasificadores predicen las etiquetas con cierta certeza, pero este umbral para una etiqueta en particular se puede cambiar. La curva ROC muestra la capacidad del clasificador para hacer predicciones correctas al cambiar el umbral de sensibilidad. Por lo general, este gráfico se usa para sistemas binarios , pero puede usarse en nuestro caso si calculamos la característica "etiqueta contra todos los demás" para cada clase. El eje x muestra resultados falsos positivos (necesitamos minimizar su número), y el eje y muestra resultados positivos verdaderos (necesitamos aumentar su número) en diferentes umbrales. Un buen clasificador puede describirse mediante una curva bajo la cual el área de la curva es máxima. Este indicador también se conoce como área bajo curva, AUC. De los gráficos de las curvas ROC se pueden sacar las mismas conclusiones sobre un número insuficiente de ejemplos de la clase "bush", aunque la curva para el agua se ve mucho mejor, esto se debe al hecho de que visualmente el agua es muy diferente de otras clases, incluso con un número insuficiente de ejemplos en los datos.

Curvas ROC del clasificador, en forma de "uno contra todos" para cada clase. Los números entre paréntesis son valores AUC.
La importancia de los síntomas.
Si desea profundizar en las complejidades del clasificador, puede ver el gráfico de importancia de la característica, que nos dice cuáles de los signos influyeron más en el resultado final. Algunos algoritmos de aprendizaje automático, como el que utilizamos en este artículo, devuelven estos valores. Para otros modelos, esta métrica debe ser considerada por nosotros mismos.

La matriz de importancia de las características para el clasificador del ejemplo
Aunque otros signos en primavera (NDVI) son generalmente más importantes, vemos que hay una fecha exacta en que uno de los signos (B2 - azul) es el más importante. Si miras las imágenes, resulta que el AOI durante este período estaba cubierto de nieve. Se puede concluir que la nieve revela información sobre la cubierta subyacente, lo que ayuda en gran medida al clasificador a determinar el tipo de superficie. Vale la pena recordar que tal fenómeno es específico del AOI observado y, en general, no se puede confiar en él.

Nevado 3x3 EOPatch AOI parte
Resultados de predicción
Después de la validación, comprendemos mejor las fortalezas y debilidades de nuestro modelo. Si no estamos satisfechos con el estado actual de las cosas, puede hacer cambios en la tubería e intentar nuevamente. Después de optimizar el modelo, definimos una EOTask simple que acepta EOPatch y el modelo clasificador, hace una predicción y la aplica al fragmento.
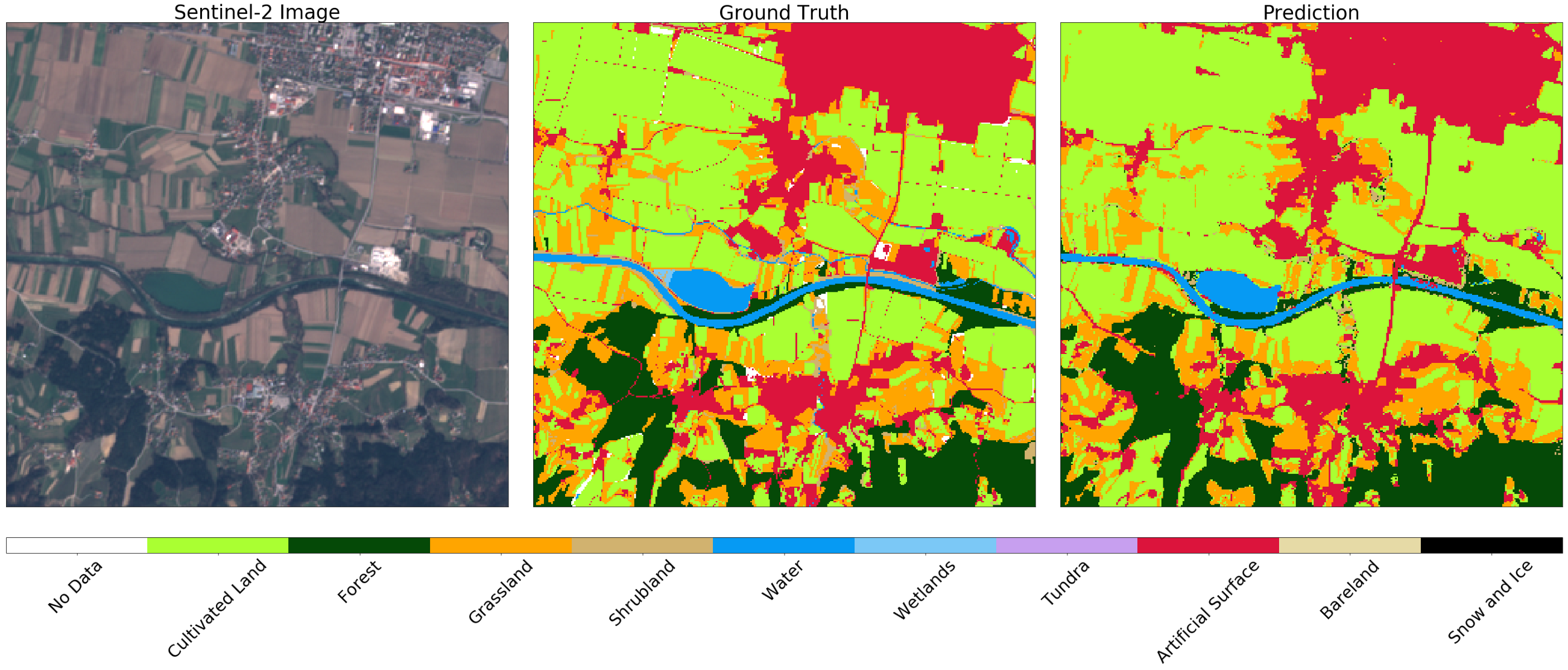
Imagen de Sentinel-2 (izquierda), verdad (centro) y predicción (derecha) para un fragmento aleatorio de AOI. Puede notar algunas diferencias en las imágenes, que pueden explicarse mediante el uso de almacenamiento en búfer negativo en el mapa original. En general, el resultado para este ejemplo es satisfactorio.
El camino posterior es claro. Es necesario repetir el procedimiento para todos los fragmentos. Incluso puede exportarlos en formato GeoTIFF y pegarlos con gdal_merge.py .
Subimos GeoTIFF pegado a nuestro portal GeoPedia, puede ver los resultados en detalle aquí
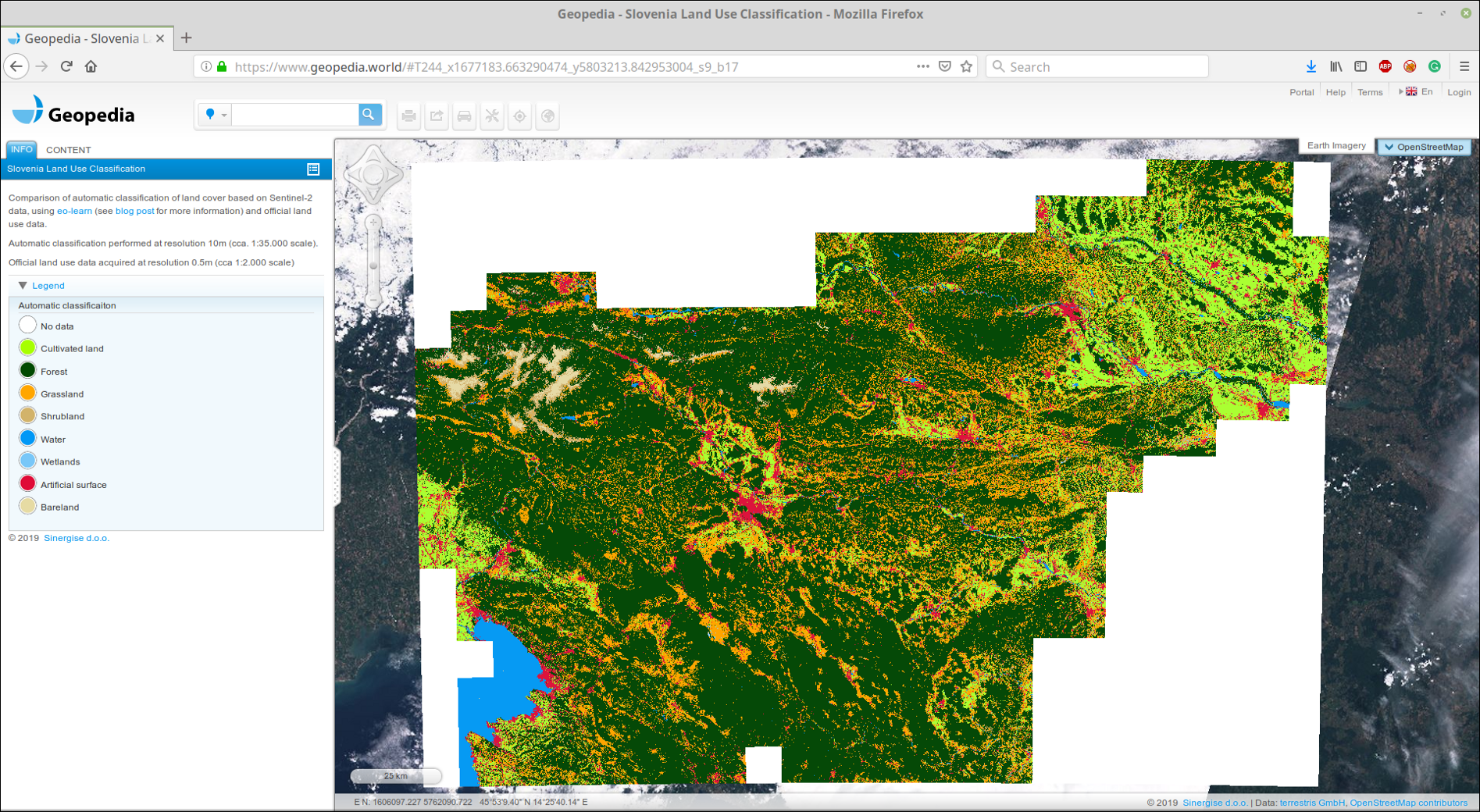
Captura de pantalla de la predicción de la cobertura del suelo en Eslovenia 2017 utilizando el enfoque de esta publicación. Disponible en formato interactivo en el enlace de arriba
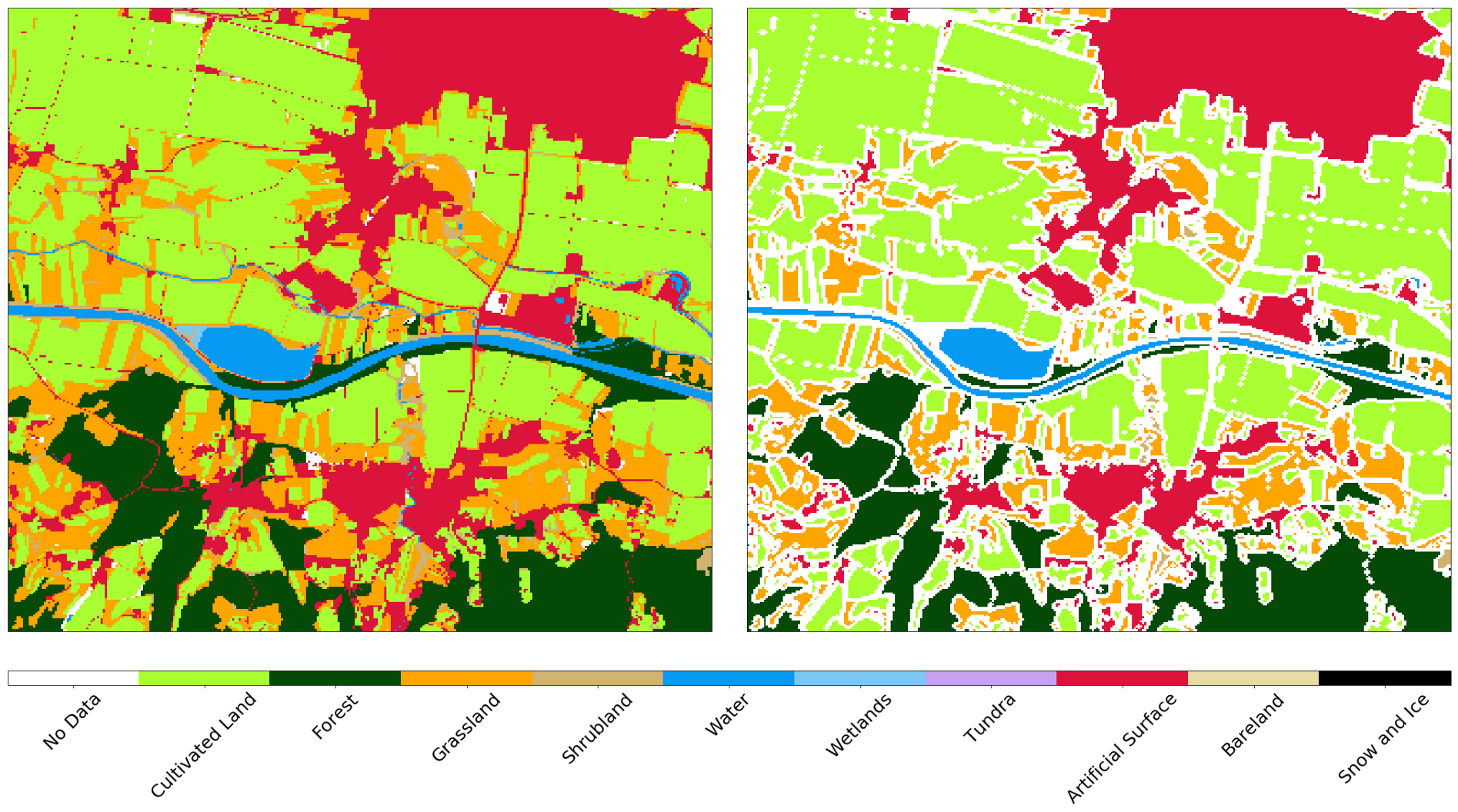
También puede comparar datos oficiales con el resultado del clasificador. Preste atención a la diferencia entre los conceptos de uso de la tierra y la cobertura de la tierra , que a menudo se encuentra en las tareas de aprendizaje automático: no siempre es fácil asignar datos de registros oficiales a clases en la naturaleza. Como ejemplo, mostramos dos aeropuertos en Eslovenia. El primero es Levets, cerca de la ciudad de Celje . Este aeropuerto es pequeño, se utiliza principalmente para aviones privados y está cubierto de hierba. Oficialmente, el territorio está marcado como superficie artificial, aunque el clasificador puede identificar correctamente el territorio como hierba, ver más abajo.

Imagen de Sentinel-2 (izquierda), verdadero (centro) y predicción (derecha) para el área alrededor del pequeño aeropuerto deportivo. El clasificador define la pista como hierba, aunque está marcada como superficie artificial en los datos actuales.
Por otro lado, en el aeropuerto más grande de Eslovenia, Ljubljana , las zonas marcadas como superficie artificial en el mapa son carreteras. En este caso, el clasificador distingue entre estructuras, mientras que distingue correctamente el césped y los campos en el territorio vecino.
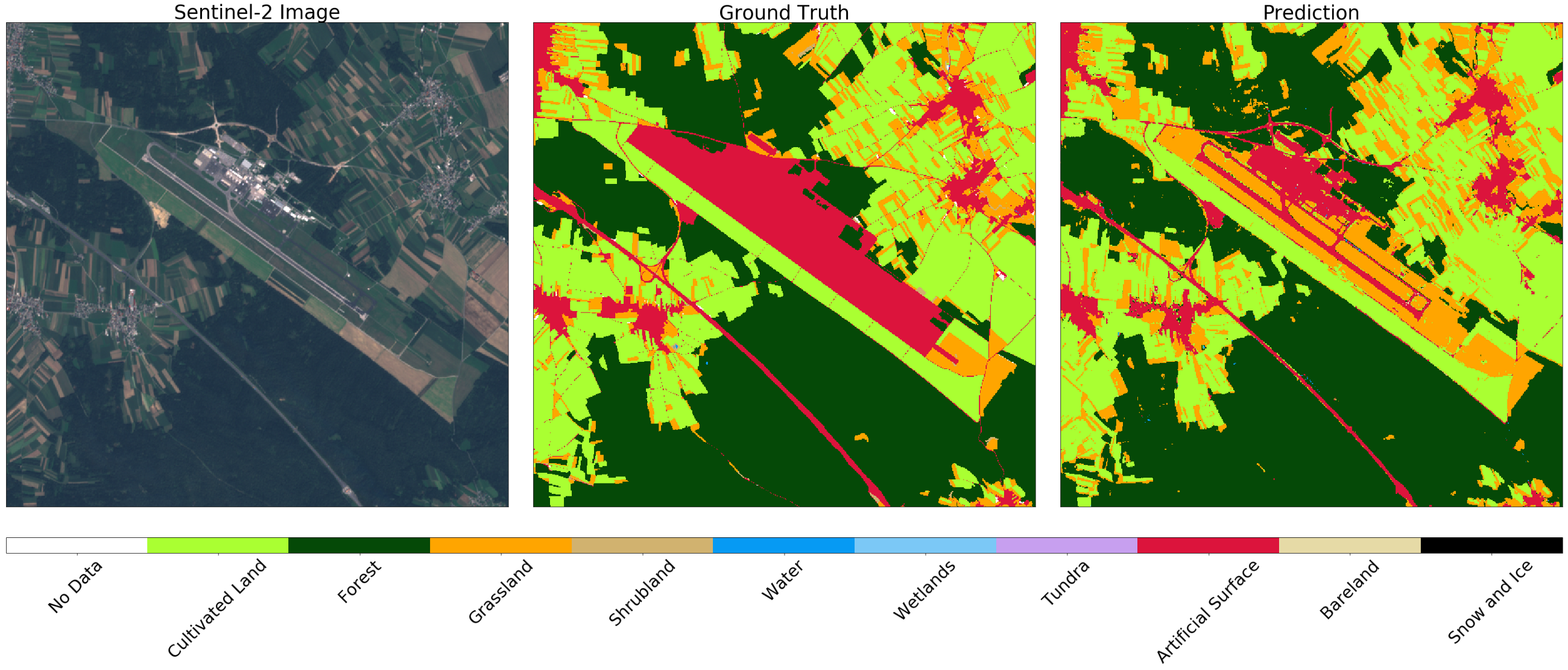
Imagen de Sentinel-2 (izquierda), verdad (centro) y predicción (derecha) para el área alrededor de Ljubljana. El clasificador determina la pista y las carreteras, mientras distingue correctamente el césped y los campos en el vecindario.
Voila!
¡Ahora ya sabe cómo crear un modelo confiable a escala nacional! Recuerde agregar esto a su currículum.