
Hoy en día, se requiere una alta disponibilidad de servicios siempre y en todas partes, no solo en grandes proyectos costosos. Los sitios que no están disponibles temporalmente con el mensaje "Lo sentimos, se está realizando el mantenimiento" aún ocurren, pero generalmente causan una sonrisa condescendiente. Agregue a esto la vida en las nubes, cuando para iniciar un servidor adicional solo necesita una llamada a la API, y no necesita pensar en la operación "iron". Y ya no hay ninguna excusa por la cual el sistema crítico no se hizo de manera confiable utilizando tecnologías de clúster y redundancia.
Le diremos qué soluciones consideramos para garantizar la fiabilidad de las bases de datos en nuestros servicios y a qué llegamos. Además de una demostración con conclusiones de largo alcance.
Legado en arquitectura de alta disponibilidad
Esto se ve aún mejor en el contexto del desarrollo de varios sistemas de código abierto. Las soluciones antiguas se vieron obligadas a agregar tecnologías de alta disponibilidad a medida que aumentaba la demanda. Y su calidad era diferente. Las soluciones de próxima generación ponen la alta disponibilidad en el centro de su arquitectura. Por ejemplo, MongoDB posiciona el clúster como el caso de uso principal. El clúster se escala horizontalmente, lo cual es una gran ventaja competitiva de este DBMS.
Volver a PostgreSQL. Este es uno de los proyectos populares de código abierto más antiguos, cuyo primer lanzamiento tuvo lugar en el año 95 del siglo pasado. Durante mucho tiempo, el equipo del proyecto no consideró la alta disponibilidad como una tarea que el sistema debe abordar. Por lo tanto, la tecnología de replicación para crear copias de datos se integró solo en la versión 8.2 en 2006, pero se archivó (envío de registros). En 2010, apareció la replicación de transmisión en la versión 9.0, y es la base para crear una amplia variedad de clústeres. De hecho, esto es muy sorprendente para las personas que conocen PostgreSQL después de Enterprise SQL o NoSQL moderno: la solución estándar de la comunidad es solo un par de réplicas maestras con replicación síncrona o asíncrona. Al mismo tiempo, el asistente se cambia manualmente en el drenaje, y también se propone que el problema de cambiar clientes se resuelva de forma independiente.
Cómo decidimos hacer PostgreSQL confiable y qué elegimos para esto
Sin embargo, PostgreSQL no se habría vuelto tan popular si no hubiera una gran cantidad de proyectos y herramientas que ayuden a construir una solución tolerante a fallas que no requiera atención constante. Desde el lanzamiento de DBaaS, los servidores únicos de PostgreSQL y los pares de réplicas maestras con replicación asíncrona han estado disponibles en
Mail.ru Cloud Solutions (MCS).
Naturalmente, queríamos simplificar la vida de todos y hacer que la instalación de PostgreSQL esté disponible, lo que podría servir como base para servicios altamente accesibles que no tendría que monitorear constantemente y despertarse por la noche para hacer el cambio. En este segmento hay soluciones probadas y una generación de nuevas utilidades que utilizan los últimos desarrollos.
Hoy, el problema de la alta disponibilidad no se basa en la redundancia (no hace falta decirlo), sino en el consenso: un algoritmo para elegir un líder (elección de líder). La mayoría de las veces, los accidentes mayores ocurren no por falta de servidores, sino por problemas de consenso: un nuevo líder no salió, dos líderes aparecieron en diferentes centros de datos, etc. Un ejemplo es un bloqueo en el clúster MySQL de Github: escribieron un
post mortem detallado .
La base matemática en este asunto es muy seria. Por un lado, existe un
teorema de CAP , que impone restricciones teóricas sobre la posibilidad de construir soluciones de HA, y por otro, algoritmos de determinación de consenso matemáticamente probados como
Paxos y
Raft . Sobre esta base, existen DCS (sistemas de consenso descentralizados) bastante populares: Zookeeper, etc., cónsul. Por lo tanto, si el sistema de toma de decisiones funciona con algunos de sus propios algoritmos, escritos de forma independiente, debe ser extremadamente cuidadoso al respecto. Después de analizar una gran cantidad de sistemas, nos decidimos por Patroni, un sistema de código abierto, desarrollado principalmente por Zalando.
Como una digresión lírica, diré que también consideramos soluciones multimaestro, es decir, grupos que se pueden escalar horizontalmente para grabar. Sin embargo, por dos razones principales, decidieron no hacer ese grupo. En primer lugar, tales soluciones tienen una alta complejidad y, en consecuencia, más vulnerabilidades. Será difícil tomar una decisión estable para todos los casos. En segundo lugar, en este caso, PostgreSQL deja de ser puro (nativo), algunas funciones no estarán disponibles, algunas aplicaciones pueden experimentar errores ocultos cuando funcionan.
Patroni
Entonces, ¿cómo funciona Patroni? Los desarrolladores no reinventaron la rueda y sugirieron utilizar una de las soluciones DCS probadas como base. Todos los problemas con la sincronización de las configuraciones, la elección de un líder y el quórum se le dan. Hemos elegido etcd para esto.
Luego, Patroni se ocupa de la aplicación correcta de todas las configuraciones en PostgreSQL y las configuraciones de replicación, así como la ejecución de comandos en conmutación y conmutación por error (es decir, asistentes de conmutación regulares y no estándar). Específicamente, en la nube MCS, puede crear un clúster a partir de una réplica maestra, síncrona y una o más réplicas asíncronas. La presencia de una réplica sincrónica garantiza la seguridad de los datos en al menos 2 servidores, y esta réplica será el principal "candidato para el maestro".
Dado que etcd se implementa en los mismos servidores, se recomienda que el número de servidores sea 3 o 5, para obtener el valor de quórum óptimo. Tal grupo se escala horizontalmente para leer (escribí sobre escalar para escribir arriba). Sin embargo, debe tenerse en cuenta que las réplicas asíncronas están retrasadas, especialmente a altas cargas.
El uso de tales réplicas en espera de lectura está justificado para tareas de informes o analíticas y descarga el servidor maestro.
Si desea crear un clúster de este tipo, necesitará:
- prepare 3 o más servidores, configure el direccionamiento IP y las reglas de firewall entre ellos;
- instalar paquetes para servicios, etcd, Patroni, PostgreSQL;
- configurar el clúster etcd;
- configurar el servicio patroni para trabajar con PostgreSQL.
Es decir, en total, debe componer correctamente una docena de archivos de configuración y no cometer errores en ningún lado. Para hacer esto, definitivamente vale la pena usar una herramienta de administración de configuración como Ansible, por ejemplo. Sin embargo, todavía no hay un equilibrador TCP altamente disponible. Hacerlo es un trabajo separado.
Para aquellos que necesitan un clúster listo para usar, pero no quieren jugar con todo esto, tratamos de simplificar nuestra vida e hicimos un clúster listo para usar en Patroni en nuestra nube, se puede probar de forma gratuita. Además del clúster en sí, hicimos:
- Equilibrador TCP en diferentes puertos, siempre apunta a la réplica principal, síncrona o asíncrona actual, respectivamente;
- API para cambiar el asistente activo de Patroni.
Se pueden conectar a través de la API de nube MCS y la consola web.
Demo
Para probar las capacidades del clúster PostgreSQL en la nube MCS, veamos cómo se comporta una aplicación en vivo en caso de problemas con el DBMS.
El siguiente es el código para una aplicación que registrará eventos artificiales e informará esto a la pantalla. En caso de errores, informará esto y continuará su trabajo en un ciclo hasta que lo detengamos con la combinación Ctrl + C.
from __future__ import print_function from datetime import datetime from random import randint from time import sleep import psycopg2 def main(): try: connection = psycopg2.connect(user = "admin", password = "P@ssw0rd", host = "89.208.87.38", port = "5432", database = "myproddb") cursor = connection.cursor() cursor.execute("SELECT version();") record = cursor.fetchone() print("Connection opened to", record[0]) cursor.execute( "INSERT INTO log VALUES ({});".format(randint(1, 10000))) connection.commit() cursor.execute("SELECT COUNT(event_id) from log;") record = cursor.fetchone() print("Logged a value, overall count: {}".format(record[0])) except Exception as error: print ("Error while connecting to PostgreSQL", error) finally: if connection: cursor.close() connection.close() print("Connection closed") if __name__ == '__main__': try: while True: try: print(datetime.now()) main() sleep(3) except Exception as e: print("Caught error:\n", e) sleep(1) except KeyboardInterrupt: print("exit")
Una aplicación necesita PostgreSQL para funcionar. Cree un clúster en la nube MCS utilizando la API. En un terminal normal, donde la variable OS_TOKEN contiene un token para acceder a la API (puede obtenerlo con el comando de emisión de token openstack), escribimos los comandos:
Crea un clúster:
cat <<EF > pgc10.json {"cluster":{"name":"postgres10","allow_remote_access":true,"datastore":{"type":"postgresql","version":"10"},"databases":[{"name":"myproddb"}],"users":[{"databases":[{"name":"myproddb"}],"name":"admin","password":"P@ssw0rd"}],"instances":[{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}}]}} EOF curl -s -H "X-Auth-Token: $OS_TOKEN" \ -H 'Accept: application/json' \ -H 'Content-Type: application/json' \ -d @pgc10.json https://infra.mail.ru:8779/v1.0/ce2a41bbd1434013b85bdf0ba07c770f/clusters
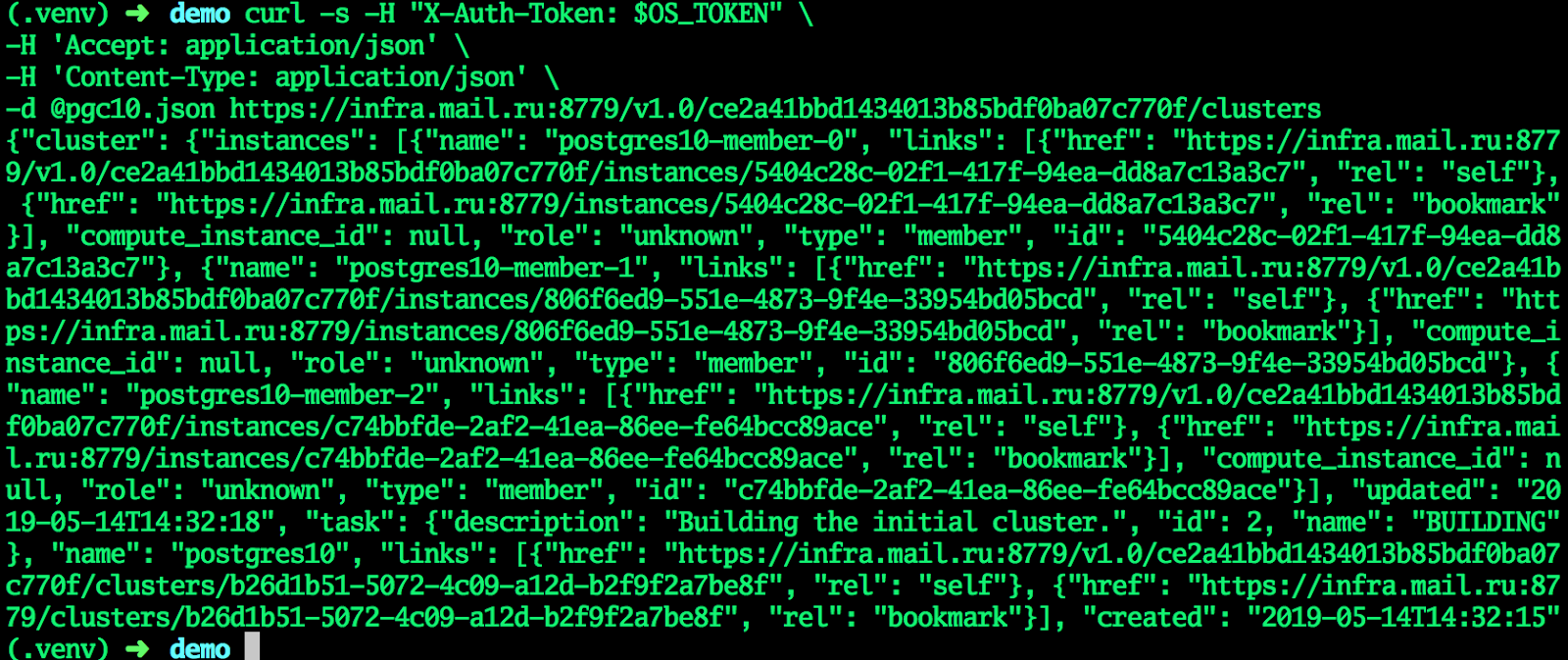
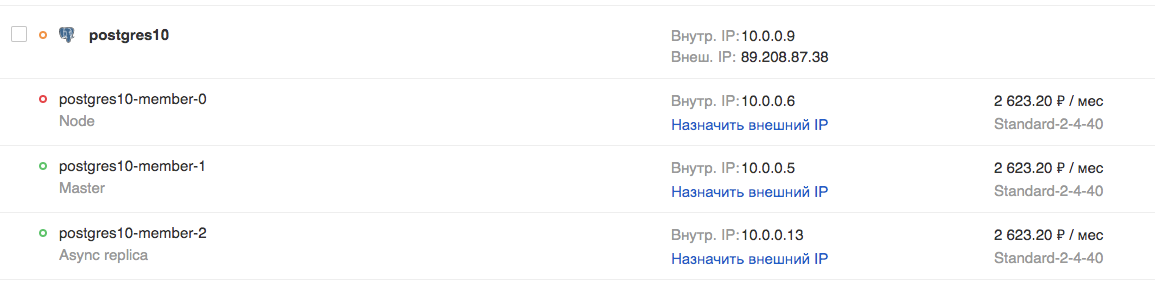
Cuando el clúster ingresa al estado ACTIVO, todos los campos recibirán los valores actuales: el clúster está listo.
En la GUI:
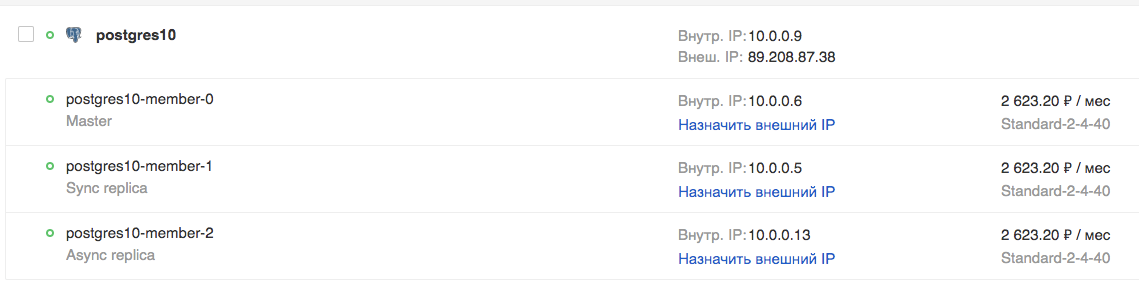
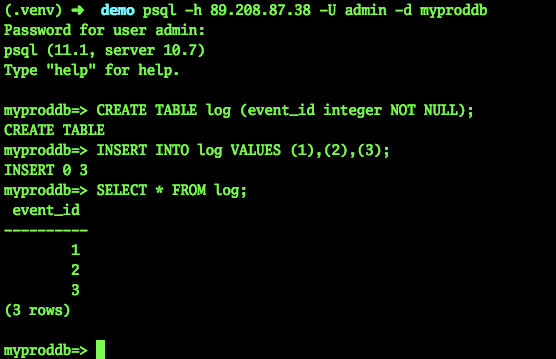
Intentemos conectarnos y crear una tabla:
psql -h 89.208.87.38 -U admin -d myproddb Password for user admin: psql (11.1, server 10.7) Type "help" for help. myproddb=> CREATE TABLE log (event_id integer NOT NULL); CREATE TABLE myproddb=> INSERT INTO log VALUES (1),(2),(3); INSERT 0 3 myproddb=> SELECT * FROM log; event_id ---------- 1 2 3 (3 rows) myproddb=>
En la aplicación, indicamos la configuración actual para conectarse a PostgreSQL. Especificaremos la dirección del equilibrador TCP, eliminando así la necesidad de cambiar manualmente a la dirección del asistente. Ejecútalo. Como puede ver, los eventos se registran correctamente en la base de datos.

Interruptor maestro programado
Ahora probaremos el funcionamiento de nuestra aplicación durante el cambio planificado del asistente:
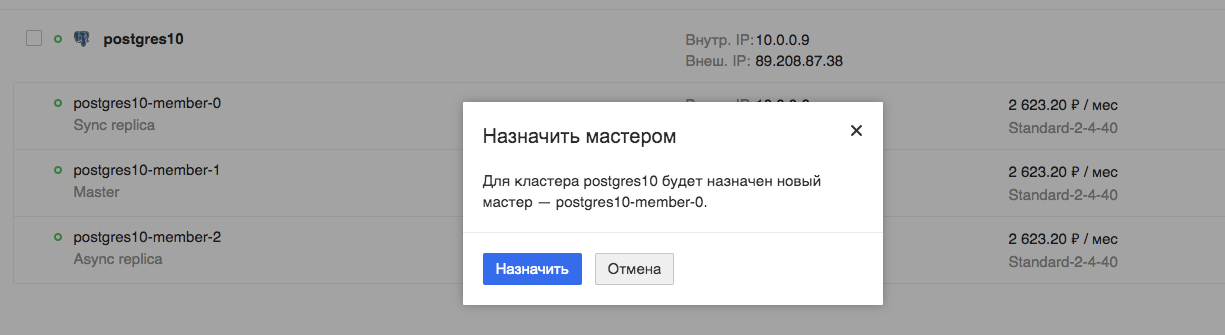
Estamos viendo la aplicación. Vemos que la aplicación se interrumpe realmente, pero solo lleva unos segundos, en este caso particular, un máximo de 9.
Caída del coche
Ahora intentemos simular la caída de una máquina virtual, el maestro actual. Sería posible simplemente apagar la máquina virtual a través de la interfaz Horizon, solo que será un apagado regular. Tal cambio será procesado por todos los servicios, incluido Patroni.
Necesitamos un cierre impredecible. Por lo tanto, les pedí a nuestros administradores con fines de prueba que apagaran la máquina virtual, el maestro actual, de manera anormal.
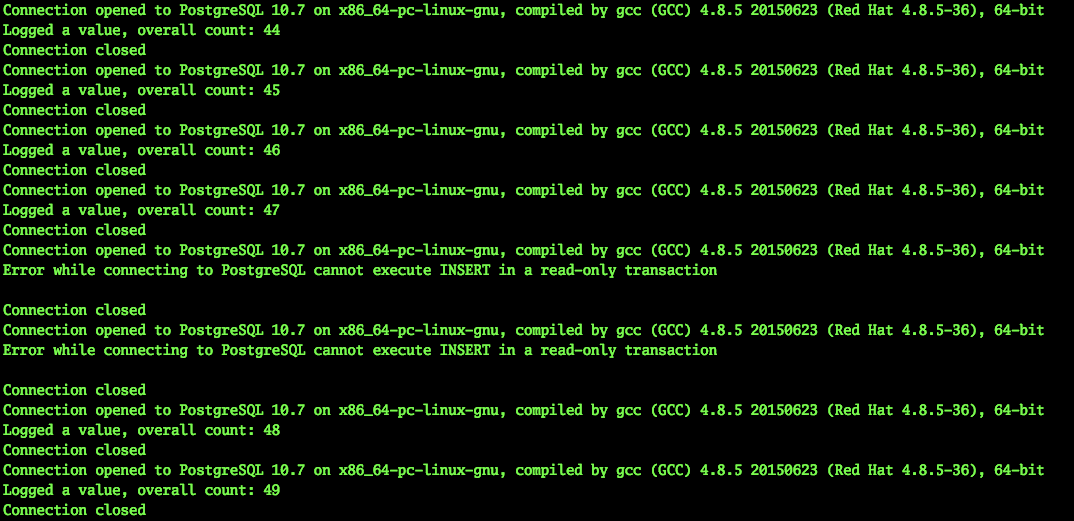
Al mismo tiempo, nuestra aplicación continuó funcionando. Naturalmente, dicho interruptor de emergencia del maestro no puede pasar desapercibido.
2019-03-29 10:45:56.071234 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 453 Connection closed 2019-03-29 10:45:59.205463 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 454 Connection closed 2019-03-29 10:46:02.661440 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment ……………………………………………………….. - - 2019-03-29 10:46:30.930445 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment 2019-03-29 10:46:31.954399 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 455 Connection closed 2019-03-29 10:46:35.409800 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 456 Connection closed ^Cexit
Como puede ver, la aplicación pudo continuar su trabajo en menos de 30 segundos. Sí, cierto número de usuarios del servicio tendrá tiempo para notar problemas. Sin embargo, esta es una falla grave del servidor, esto no sucede con tanta frecuencia. Al mismo tiempo, la persona (administrador) difícilmente habría logrado reaccionar tan rápido, a menos que estuviera sentado en la consola listo con un script de cambio.
Conclusión
Me parece que dicho clúster ofrece una tremenda ventaja para los administradores. De hecho, las averías graves y el mal funcionamiento de los servidores de bases de datos no serán perceptibles para la aplicación y, en consecuencia, para el usuario. No tendrá que reparar algo rápidamente y cambiar a configuraciones temporales, servidores, etc. Y si utiliza esta solución en forma de un servicio listo para usar en la nube, no necesitará perder el tiempo preparándolo. Será posible hacer algo más interesante.