
Si administra una infraestructura virtual basada en VMware vSphere (o cualquier otra pila de tecnología), probablemente escuche quejas de los usuarios: "¡La máquina virtual es lenta!". En esta serie de artículos analizaré las métricas de rendimiento y explicaré qué y por qué se "ralentiza" y cómo asegurarse de que no se "ralentice".
Consideraré los siguientes aspectos de rendimiento de las máquinas virtuales:
Comenzaré con la CPU.
Para el análisis de rendimiento necesitamos:
- Los vCenter Performance Counters son contadores de rendimiento cuyos gráficos se pueden ver a través de vSphere Client. La información sobre estos contadores está disponible en cualquier versión de cliente (cliente "grueso" en C #, cliente web en Flex y cliente web en HTML5). En estos artículos, utilizaremos capturas de pantalla del cliente C #, solo porque se ven mejor en miniatura :)
- ESXTOP es una utilidad que se ejecuta desde la línea de comandos de ESXi. Con su ayuda, puede obtener los valores de los contadores de rendimiento en tiempo real o cargar estos valores durante un período determinado en un archivo .csv para su posterior análisis. A continuación, le contaré más sobre esta herramienta y le proporcionaré algunos enlaces útiles a la documentación y artículos relacionados.
Poco de teoría
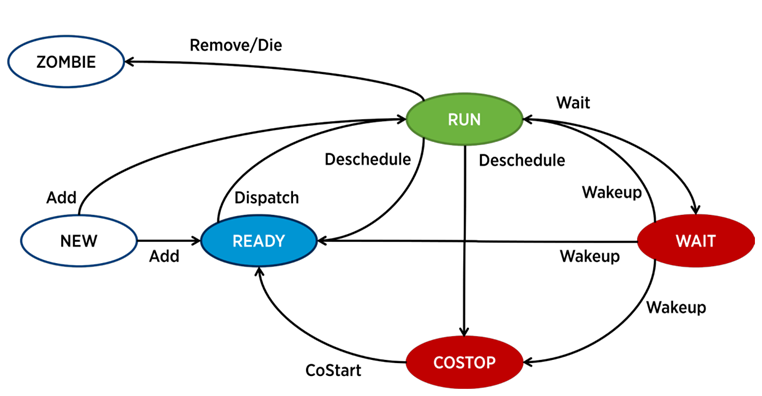
En ESXi, un proceso separado es responsable del funcionamiento de cada vCPU (núcleo de máquina virtual), el mundo en terminología de VMware. También hay procesos de servicio, pero desde el punto de vista del análisis de rendimiento de VM, son menos interesantes.
Un proceso en ESXi puede estar en uno de cuatro estados:
- Ejecutar : el proceso hace un trabajo útil.
- Espere : el proceso no funciona (inactivo) o está esperando entrada / salida.
- Costop es una condición que ocurre en máquinas virtuales multinúcleo. Ocurre cuando el planificador de la CPU del hipervisor (ESXi CPU Scheduler) no puede programar todos los núcleos activos de la máquina virtual para que se ejecuten simultáneamente en los núcleos del servidor físico. En el mundo físico, todos los núcleos de procesador funcionan en paralelo, el sistema operativo invitado dentro de la VM espera un comportamiento similar, por lo que el hipervisor debe ralentizar los núcleos de VM, que tienen la capacidad de terminar el ritmo más rápido. En las versiones modernas de ESXi, el programador de la CPU utiliza un mecanismo llamado co-programación relajada: el hipervisor considera la brecha entre el núcleo de la máquina virtual más rápido y más lento (sesgo). Si los núcleos de VM pasan mucho tiempo en este estado, esto puede causar problemas de rendimiento.
- Listo : el proceso pasa a este estado cuando el hipervisor no tiene la capacidad de asignar recursos para su ejecución. Los valores altos listos pueden causar problemas de rendimiento de VM.
Contadores básicos de rendimiento de CPU de una máquina virtual
Uso de CPU,%. Muestra el porcentaje de uso de CPU para un período determinado.
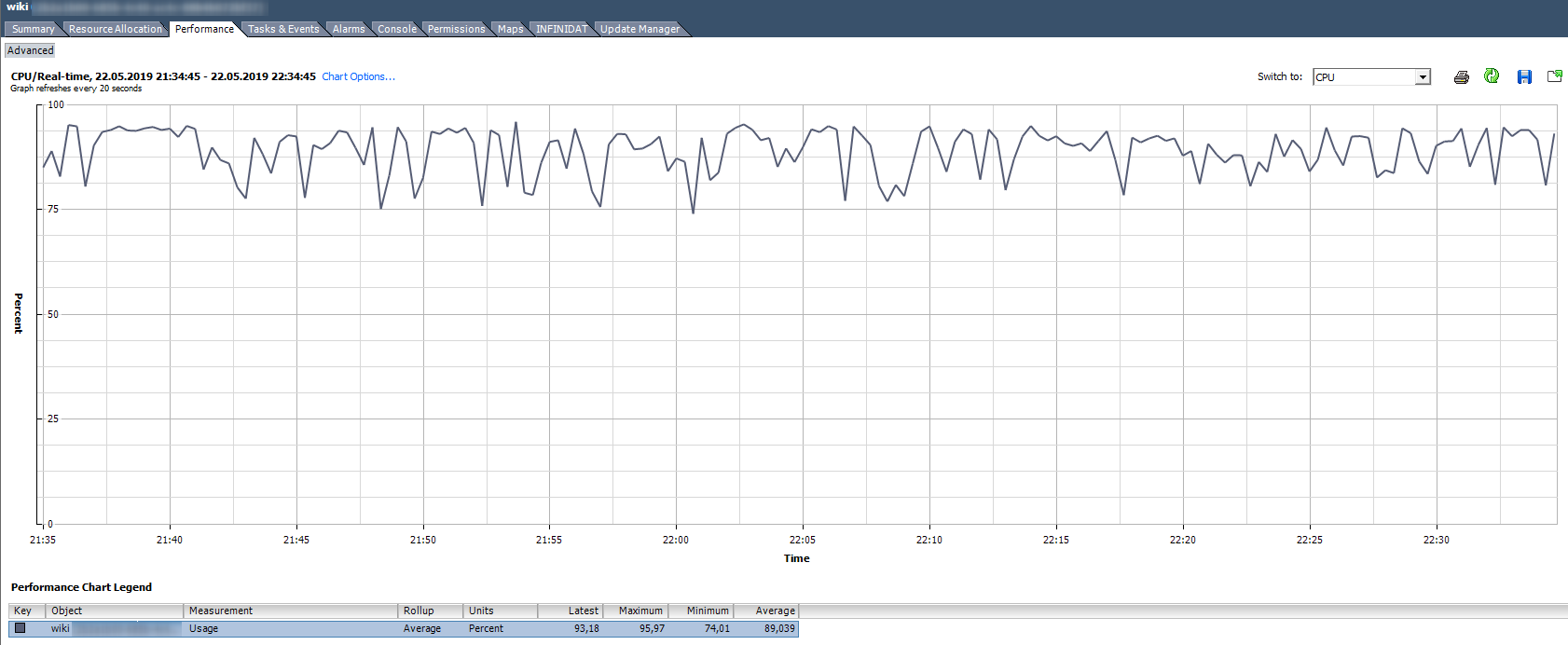 ¿Cómo analizar?
¿Cómo analizar? Si la VM utiliza de manera estable la CPU para el 90% o hay picos de hasta el 100%, entonces tenemos problemas. Los problemas se pueden expresar no solo en el funcionamiento "lento" de la aplicación dentro de la VM, sino también en la inaccesibilidad de la VM a través de la red. Si el sistema de monitoreo muestra que la VM se cae periódicamente, preste atención a los picos en el gráfico de Uso de la CPU.
Hay una alarma estándar, que muestra la carga de CPU de la máquina virtual:
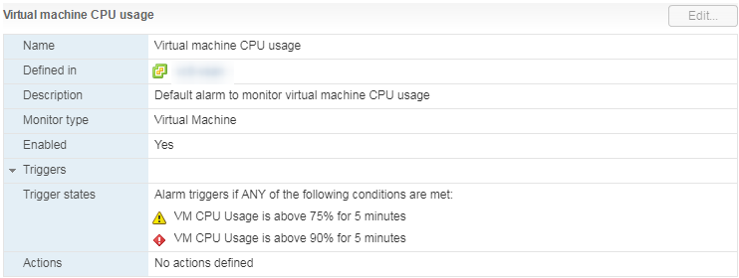 Que hacer
Que hacer Si el uso de la CPU está constantemente abrumando a la VM, puede pensar en aumentar el número de vCPU (desafortunadamente, esto no siempre ayuda) o transferir las VM a un servidor con procesadores más eficientes.
Uso de CPU en Mhz
En los gráficos de uso de vCenter en% solo puede ver la máquina virtual completa, no hay gráficos para núcleos individuales (Esxtop tiene valores en% para núcleos). Para cada núcleo, puede ver Uso en MHz.
¿Cómo analizar? Sucede que la aplicación no está optimizada para la arquitectura multinúcleo: utiliza 100% solo un núcleo, y el resto está inactivo sin carga. Por ejemplo, con la configuración de copia de seguridad predeterminada, MS SQL inicia el proceso en un solo núcleo. Como resultado, la copia de seguridad se ralentiza no debido a la velocidad lenta del disco (esto es de lo que se quejó inicialmente el usuario), sino porque el procesador no puede hacer frente. El problema se resolvió cambiando los parámetros: la copia de seguridad comenzó a ejecutarse en paralelo en varios archivos (respectivamente, en varios procesos).
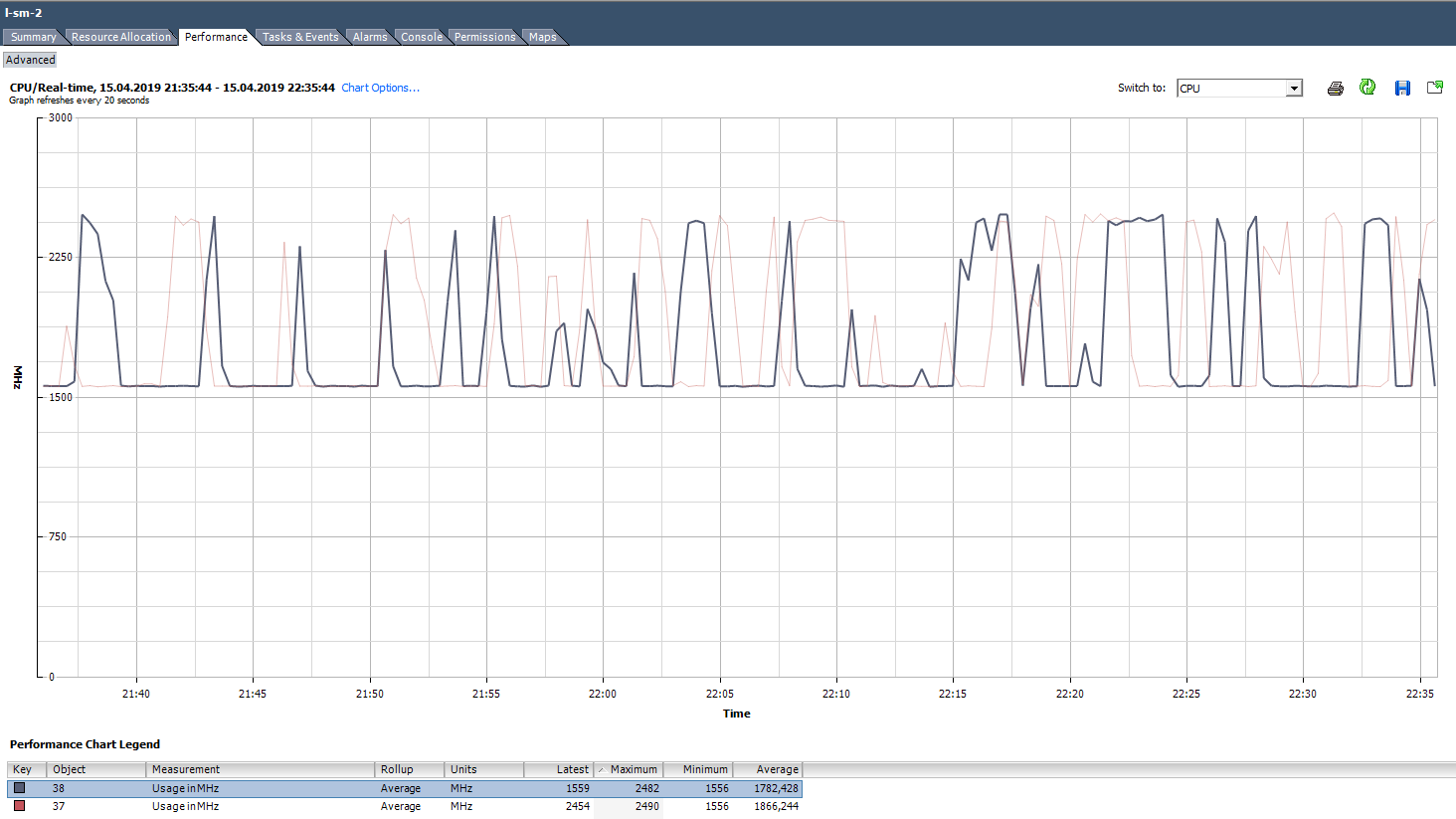 Un ejemplo de una carga desigual de núcleos.
Un ejemplo de una carga desigual de núcleos.También existe una situación (como en el gráfico anterior) cuando los núcleos están cargados de manera desigual y algunos de ellos tienen picos del 100%. Al igual que con la carga de un solo núcleo, la alarma en el uso de la CPU no funcionará (está en toda la VM), pero habrá problemas de rendimiento.
Que hacer Si el software en la máquina virtual carga los núcleos de manera desigual (usa solo un núcleo o parte de los núcleos), no tiene sentido aumentar su número. En este caso, es mejor mover la VM a un servidor con procesadores más eficientes.
También puede intentar verificar la configuración de energía en el BIOS del servidor. Muchos administradores activan el modo de alto rendimiento en el BIOS y, por lo tanto, desactivan las tecnologías de ahorro de energía de los estados C y P. Los procesadores Intel modernos usan la tecnología Turbo Boost, que aumenta la frecuencia de los núcleos de procesadores individuales debido a otros núcleos. Pero solo funciona con las tecnologías de ahorro de energía incluidas. Si los apagamos, el procesador no puede reducir el consumo de energía de los núcleos que no están cargados.
VMware recomienda no desactivar las tecnologías de ahorro de energía en los servidores, sino elegir modos que maximicen la administración de energía para el hipervisor. Al mismo tiempo, en la configuración de energía del hipervisor, debe seleccionar Alto rendimiento.
Si tiene máquinas virtuales separadas (o núcleos de máquinas virtuales) en su infraestructura que requieren una frecuencia de CPU aumentada, la configuración correcta del consumo de energía puede mejorar significativamente su rendimiento.
CPU lista (preparación)
Si el núcleo de VM (vCPU) está en estado Listo, no hace un trabajo útil. Esta condición ocurre cuando el hipervisor no encuentra un núcleo físico libre al que se pueda asignar el proceso de vCPU de la máquina virtual.
¿Cómo analizar? Por lo general, si los núcleos de la máquina virtual están en estado Listo durante más del 10% del tiempo, notará problemas de rendimiento. En pocas palabras, más del 10% del tiempo que una VM espera la disponibilidad de recursos físicos.
En vCenter, puede ver 2 contadores asociados con la CPU Ready:
Los valores de ambos contadores se pueden ver tanto en toda la VM como en núcleos individuales.
La preparación muestra el valor inmediatamente en porcentaje, pero solo en tiempo real (datos de la última hora, intervalo de medición de 20 segundos). Este contador se usa mejor solo para buscar problemas "en persecución".
Los valores de contador listos también se pueden ver en perspectiva histórica. Esto es útil para establecer patrones y para un análisis más profundo del problema. Por ejemplo, si una máquina virtual comienza a tener problemas de rendimiento en algún momento específico, puede comparar los intervalos del valor de CPU Ready bloqueado con la carga total en el servidor donde se está ejecutando la VM, y tomar medidas para reducir la carga (si DRS no puede hacer frente).
Listo, a diferencia de Readiness, no se muestra en porcentajes, sino en milisegundos. Este es un contador de tipo de Suma, es decir, muestra cuánto tiempo estuvo el núcleo de VM en el estado Listo durante el período de medición. Puede traducir este valor en porcentaje mediante una fórmula simple:
(Valor de suma de CPU listo / (intervalo de actualización predeterminado del gráfico en segundos * 1000)) * 100 =% de CPU listo
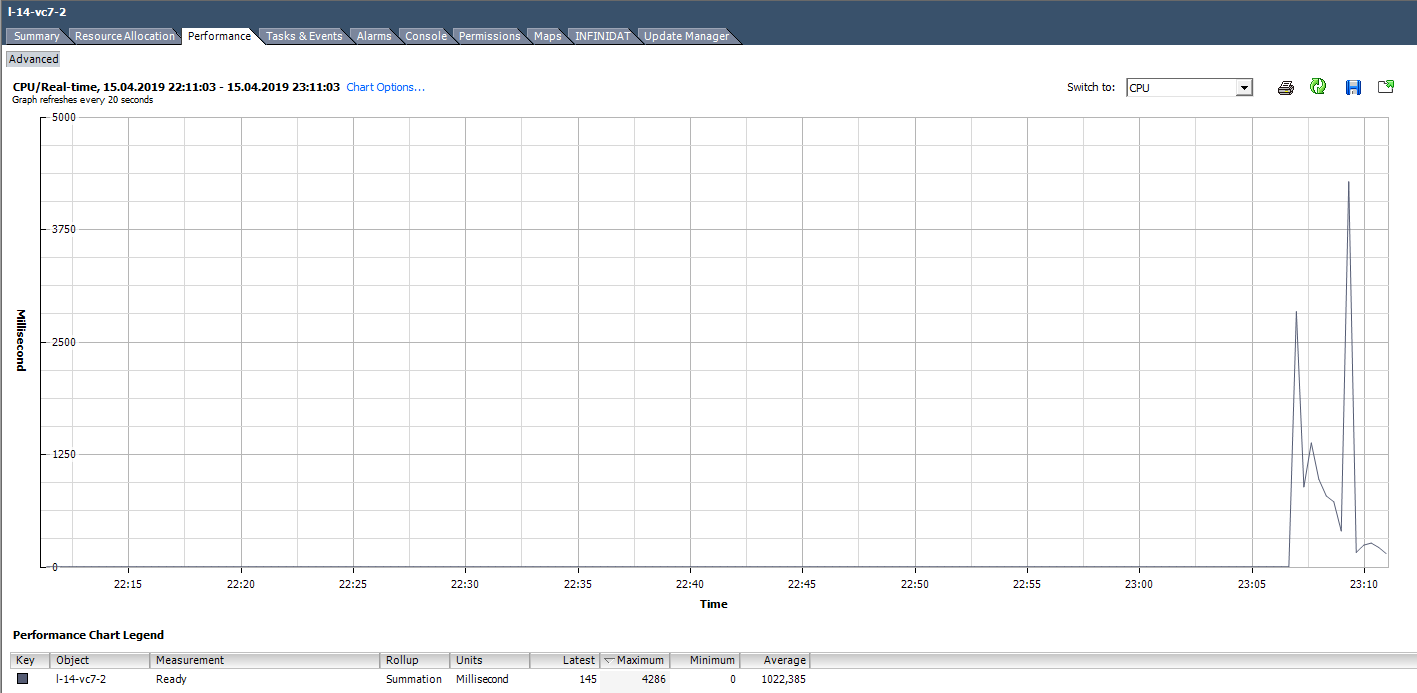
Por ejemplo, para las máquinas virtuales en el gráfico a continuación, el valor máximo de Ready para toda la máquina virtual es el siguiente:
Al calcular el valor Listo como un porcentaje, debe prestar atención a dos puntos:
- El valor de Ready en toda la VM es la suma de Ready en los núcleos.
- Intervalo de medida. En tiempo real, son 20 segundos y, por ejemplo, en gráficos diarios, son 300 segundos.
Con la resolución activa de problemas, estos puntos simples se pueden perder fácilmente y se puede dedicar un tiempo valioso a resolver problemas inexistentes.
Calculamos Ready en base a los datos del gráfico a continuación. (324474 / (20 * 1000)) * 100 = 1622% para toda la VM. Si nos fijamos en los núcleos, resultará no tan aterrador: 1622/64 = 25% por núcleo. En este caso, detectar un truco es bastante simple: el valor Listo no es realista. Pero si estamos hablando del 10-20% para toda la VM con varios núcleos, entonces para cada núcleo el valor puede estar dentro del rango normal.
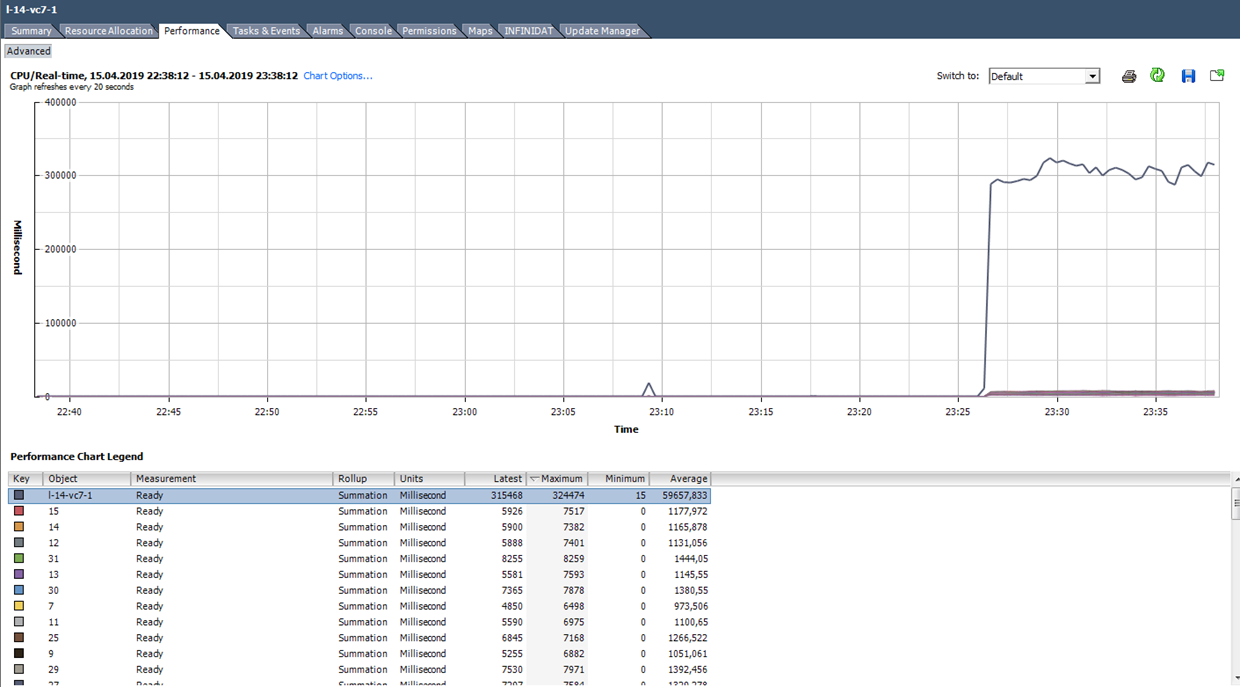 Que hacer
Que hacer Un valor alto de Listo indica que el servidor no tiene suficientes recursos de procesador para el funcionamiento normal de las máquinas virtuales. En esta situación, solo queda reducir la suscripción excesiva en el procesador (vCPU: pCPU). Obviamente, esto se puede lograr reduciendo los parámetros de las máquinas virtuales existentes o migrando parte de la máquina virtual a otros servidores.
Co-stop
¿Cómo analizar? Este contador también tiene el tipo de Suma y se traduce en porcentajes como Listo:
(Valor de suma de paro de CPU / (intervalo de actualización predeterminado del gráfico en segundos * 1000)) * 100 =% de paro de CPU
Aquí también debe prestar atención a la cantidad de núcleos por VM y al intervalo de medición.
En el estado costop, el núcleo no hace un trabajo útil. Con la selección correcta del tamaño de la máquina virtual y la carga normal en el servidor, el contador de parada simultánea debe estar cerca de cero.
 En este caso, la carga es claramente anormal :)Que hacer
En este caso, la carga es claramente anormal :)Que hacer Si varias máquinas virtuales con una gran cantidad de núcleos se ejecutan en el mismo hipervisor y hay una suscripción excesiva en la CPU, entonces el contador de detención simultánea puede crecer, lo que provocará problemas con el rendimiento de estas máquinas virtuales.
Además, co-stop aumentará si se usan subprocesos para núcleos activos de una VM en el mismo núcleo del servidor físico con hipercadena habilitada. Tal situación puede surgir, por ejemplo, si la VM tiene más núcleos de los que tiene físicamente en el servidor donde trabaja, o si la configuración "preferHT" está habilitada para la VM. Puede leer sobre esta configuración
aquí .
Para evitar problemas con el rendimiento de la VM debido a la alta parada simultánea, seleccione el tamaño de la VM de acuerdo con las recomendaciones del fabricante del software que se ejecuta en esta VM y con las capacidades del servidor físico donde se ejecuta la VM.
No agregue kernels en reserva, esto puede causar problemas de rendimiento no solo de la VM en sí, sino también de sus servidores vecinos.
Otras métricas útiles de CPU
Ejecutar : cuánto tiempo (ms) para el período de medición de vCPU estuvo en el estado EJECUTAR, es decir, realmente realizó un trabajo útil.
Inactivo : cuánto tiempo (ms) para el período de medición de vCPU estuvo inactivo. Los valores altos de inactividad no son un problema, solo vCPU no tenía "nada que hacer".
Esperar : cuánto tiempo (ms) para el período de medición de vCPU estuvo en el estado Esperar. Dado que IDLE se incluye en este contador, los valores de espera altos tampoco indican un problema. Pero si el nivel de espera alto es bajo, entonces la máquina virtual estaba esperando que se completaran las operaciones de E / S y esto, a su vez, puede indicar un problema con el rendimiento del disco duro o de algunos dispositivos virtuales de la máquina virtual.
Limitado máximo : cuánto tiempo (ms) para el período de medición de vCPU estuvo en estado Listo debido al límite de recursos establecido. Si el rendimiento es inexplicablemente bajo, es útil verificar el valor de este contador y el límite de CPU en la configuración de VM. De hecho, las máquinas virtuales pueden tener límites que desconoce. Por ejemplo, esto sucede cuando la VM se inclinó desde la plantilla en la que se estableció el límite de CPU.
Swap wait : cuánto tiempo esperó la vCPU para funcionar con VMkernel Swap durante el período de medición. Si los valores de este contador están por encima de cero, entonces la VM definitivamente tiene problemas de rendimiento. Hablaremos más sobre SWAP en el artículo sobre contadores de RAM.
ESXTOP
Si los contadores de rendimiento en vCenter son buenos para analizar datos históricos, entonces el análisis en línea del problema se realiza mejor en ESXTOP. Aquí, todos los valores se presentan en forma terminada (no es necesario traducir nada), y el período mínimo de medición es de 2 segundos.
La pantalla "c" activa la pantalla ESXTOP en la CPU y tiene este aspecto:

Para mayor comodidad, solo puede dejar procesos de máquinas virtuales presionando Shift-V.
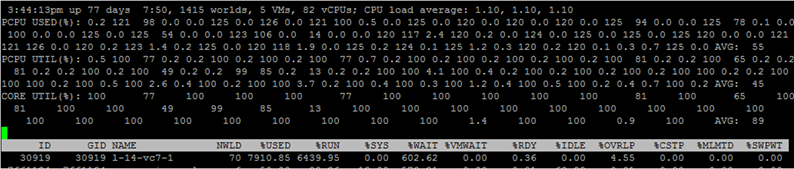
Para ver las métricas de los núcleos de máquinas virtuales individuales, presione "e" y escriba el GID de la máquina virtual que le interesa (30919 en la captura de pantalla a continuación):

Revise brevemente las columnas que se presentan por defecto. Se pueden agregar columnas adicionales presionando "f".
NWLD (Número de mundos) : el número de procesos en el grupo. Para expandir el grupo y ver las métricas de cada proceso (por ejemplo, para cada núcleo de una VM multinúcleo), presione "e". Si un grupo tiene más de un proceso, los valores de las métricas para el grupo son iguales a la suma de las métricas para los procesos individuales.
% USADO : cuántos ciclos utiliza la CPU del servidor un proceso o grupo de procesos.
% RUN : cuánto tiempo durante el período de medición el proceso estuvo en el estado RUN, es decir realizó un trabajo útil. Se diferencia del% USADO en que no tiene en cuenta el subprocesamiento, el escalado de frecuencia y el tiempo dedicado a las tareas del sistema (% SYS).
% SYS : tiempo dedicado a tareas del sistema, por ejemplo: manejo de interrupciones, entrada / salida, funcionamiento de la red, etc. El valor puede ser alto si hay mucha entrada / salida en la VM.
% OVRLP : cuánto tiempo pasó el núcleo físico en el que se ejecuta el proceso VM en tareas de otros procesos.
Estas métricas están relacionadas de la siguiente manera:
% USED =% RUN +% SYS -% OVRLP.
Por lo general, la métrica% USADO es más informativa.
% WAIT : cuánto tiempo durante el período de medición estuvo el proceso en el estado Wait. Incluye inactivo.
% IDLE : cuánto tiempo estuvo el proceso en estado IDLE durante el período de medición.
% SWPWT : cuánto tiempo esperó vCPU para la operación con VMkernel Swap durante el período de medición.
% VMWAIT : cuánto tiempo estuvo la vCPU en el estado de espera de un evento (generalmente E / S) durante el período de medición. No hay un contador similar en vCenter. Los valores altos indican problemas con la entrada / salida a la VM.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
Si la VM no usa VMkernel Swap, cuando analice problemas de rendimiento es aconsejable mirar% VMWAIT, ya que esta métrica no tiene en cuenta el momento en que la VM no hizo nada (% IDLE).
% RDY : cuánto tiempo estuvo el proceso en estado Listo durante el período de medición.
% CSTP : cuánto tiempo estuvo el proceso en el estado posterior durante el período de medición.
% MLMTD : cuánto tiempo durante el período de medición de vCPU estuvo en estado Listo debido al límite de recursos establecido.
% WAIT +% RDY +% CSTP +% RUN = 100%: el núcleo de VM siempre está en uno de estos cuatro estados.
CPU en el hipervisor
También hay contadores de rendimiento de CPU para el hipervisor en vCenter, pero no representan nada interesante: es solo la suma de los contadores para todas las máquinas virtuales en el servidor.
La forma más conveniente de ver el estado de la CPU en el servidor es en la pestaña Resumen:

Para el servidor, así como para la máquina virtual, hay una alarma estándar:
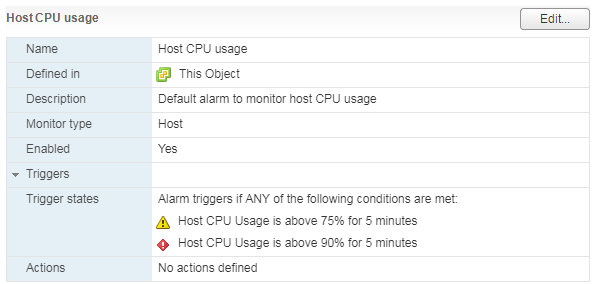
Con una alta carga en la CPU del servidor, las máquinas virtuales que se ejecutan en él comienzan a experimentar problemas de rendimiento.
En ESXTOP, los datos de utilización de la CPU del servidor se presentan en la parte superior de la pantalla. Además de la carga estándar de la CPU, que no es informativa para los hipervisores, hay tres métricas más:
CORE UTIL (%) : carga del núcleo del servidor físico. Este contador muestra cuánto tiempo el núcleo realizó el trabajo durante el período de medición.
PCPU UTIL (%) : si el hiperprocesamiento está habilitado, entonces hay dos subprocesos (PCPU) para cada núcleo físico. Esta métrica muestra cuánto tiempo trabajó cada subproceso.
PCPU USED (%) es lo mismo que PCPU UTIL (%), pero tiene en cuenta la escala de frecuencia (ya sea reduciendo la frecuencia del núcleo para ahorrar energía o aumentando la frecuencia del núcleo debido a la tecnología Turbo Boost) e hiper-threading.
PCPU_USED% = PCPU_UTIL% * frecuencia central efectiva / frecuencia central nominal.
 En esta captura de pantalla, para algunos núcleos, debido a la operación de Turbo Boost, el valor USADO es más del 100%, ya que la frecuencia del núcleo es más alta que la nominal.
En esta captura de pantalla, para algunos núcleos, debido a la operación de Turbo Boost, el valor USADO es más del 100%, ya que la frecuencia del núcleo es más alta que la nominal.Algunas palabras sobre cómo se tiene en cuenta el hiperprocesamiento. Si los procesos se ejecutan el 100% del tiempo en ambos subprocesos del núcleo físico del servidor, mientras que el núcleo se ejecuta a la frecuencia nominal, entonces:
- CORE UTIL para el núcleo será 100%,
- PCPU UTIL para ambos hilos será 100%,
- PCED UTILIZADO para ambos hilos será del 50%.
Si ambos hilos no funcionaron el 100% del tiempo durante el período de medición, entonces, en aquellos períodos en que los hilos trabajaron en paralelo, la PCPU UTILIZADA para núcleos se divide por la mitad.
ESXTOP también tiene una pantalla con los parámetros de consumo de energía del servidor de la CPU. Aquí puede ver si el servidor utiliza tecnologías de ahorro de energía: estados C y estados P. Llamado por la tecla p:

Problemas comunes de rendimiento de la CPU
Finalmente, revisaré por razones típicas de problemas con el rendimiento de la CPU VM y daré algunos consejos para resolverlos:
No hay suficiente velocidad de reloj central. Si no hay forma de transferir máquinas virtuales a núcleos más eficientes, puede intentar cambiar la configuración de energía para que Turbo Boost funcione de manera más eficiente.
Dimensionamiento incorrecto de la VM (demasiados / pocos núcleos). Si coloca pocos núcleos, habrá una gran carga en la CPU de VM. Si es mucho, coge una parada alta.
Gran sobresuscripción en la CPU en el servidor. Si la máquina virtual está preparada, reduzca la suscripción excesiva en la CPU.
Topología de NUMA incorrecta en máquinas virtuales grandes. La topología NUMA que ve la VM (vNUMA) debe coincidir con la topología del servidor NUMA (pNUMA). Los diagnósticos y las posibles soluciones a este problema están escritos, por ejemplo, en el libro
"VMware vSphere 6.5 Host Resources Deep Dive" . Si no desea profundizar y no tiene restricciones de licencia en el sistema operativo instalado en la VM, realice muchos sockets virtuales en la VM en un núcleo. No perderás mucho :)
Eso es todo por la CPU. Haz preguntas En la
siguiente parte hablaré sobre RAM.