La identificación biométrica de una persona es una de las ideas más antiguas para reconocer a las personas, que generalmente intentaron implementar técnicamente. Las contraseñas se pueden robar, espiar, olvidar, las claves se pueden falsificar. Pero las características únicas de la persona misma son mucho más difíciles de fingir y perder. Esto puede ser huellas digitales, voz, dibujo de los vasos de la retina, marcha y más.

¡Por supuesto, los sistemas biométricos están tratando de engañar! De eso es de lo que hablaremos hoy. Cómo los atacantes intentan eludir los sistemas de reconocimiento facial personificando a otra persona y cómo se puede detectar esto.
Puede ver una versión en video de esta historia aquí , y aquellos que prefieren leer a ver, los invito a continuar
Según las ideas de los directores de Hollywood y los escritores de ciencia ficción, es bastante fácil engañar a la identificación biométrica. Solo es necesario presentar al sistema las "partes requeridas" del usuario real, ya sea individualmente o tomándolo como rehén. O puede "ponerse la máscara" de otra persona sobre usted mismo, por ejemplo, usando una máscara de trasplante físico o, en general, presentando signos genéticos falsos
En la vida real, los atacantes también intentan presentarse como alguien más. Por ejemplo, robe un banco usando la máscara de un hombre negro, como en la imagen a continuación.

El reconocimiento facial parece un área muy prometedora para su uso en el sector móvil. Si todos han estado acostumbrados a usar huellas digitales y la tecnología de la voz se está desarrollando de manera gradual y bastante predecible, entonces, al identificarse personalmente, la situación se ha desarrollado de manera bastante inusual y digna de una pequeña digresión en la historia del problema.
Cómo comenzó todo o de la ficción a la realidad
Los sistemas de reconocimiento de hoy demuestran una precisión tremenda. Con la llegada de grandes conjuntos de datos y arquitecturas complejas, fue posible lograr una precisión de reconocimiento facial de hasta 0.000001 (¡un error por millón!) Y ahora son adecuados para transferir a plataformas móviles. El cuello de botella era su vulnerabilidad.
Para hacerse pasar por otra persona en nuestra realidad técnica, y no en la película, las máscaras se usan con mayor frecuencia. También intentan engañar al sistema informático presentando a otra persona en lugar de su cara. Las máscaras pueden ser de una calidad completamente diferente, desde la foto de otra persona impresa frente a la cara impresa en la impresora hasta máscaras tridimensionales muy complejas con calentamiento. Las máscaras se pueden presentar por separado en forma de sábana o pantalla, o se pueden usar en la cabeza.
Se prestó mucha atención al tema por un intento exitoso de engañar al sistema Face ID en el iPhone X con una máscara bastante compleja de polvo de piedra con inserciones especiales alrededor de los ojos que imitan el calor de una cara viva usando radiación infrarroja.
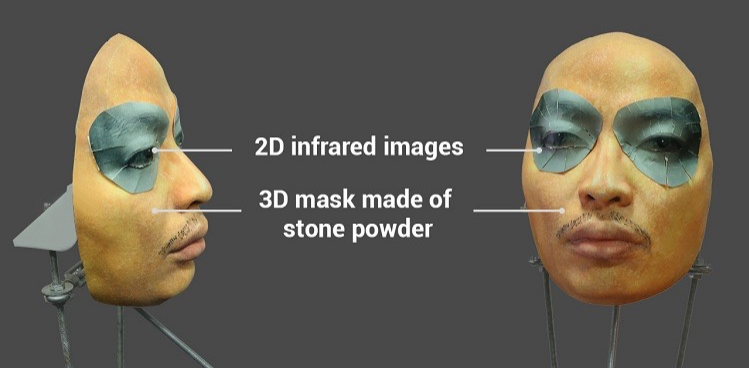
Se alega que al usar una máscara de este tipo fue posible engañar a Face ID en el iPhone X. Puede encontrar un video y algo de texto aquí
La presencia de tales vulnerabilidades es muy peligrosa para los sistemas bancarios o estatales para autenticar a un usuario en persona, donde la penetración de un atacante conlleva pérdidas significativas.
Terminología
El campo de investigación del anti-spoofing facial es bastante nuevo y aún no puede presumir incluso de la terminología prevaleciente.
Aceptemos llamar a un intento de engañar al sistema de identificación presentándolo con un falso parámetro biométrico (en este caso, una persona) ataque de suplantación de identidad .
En consecuencia, un conjunto de medidas de protección para contrarrestar tal engaño se llamará anti-spoofing . Se puede implementar en forma de una variedad de tecnologías y algoritmos integrados en el transportador de un sistema de identificación.
El ISO ofrece un conjunto de terminología ligeramente expandido, con términos como ataque de presentación : intentos de forzar al sistema a identificar incorrectamente al usuario o permitirle evitar la identificación al mostrar una imagen, un video grabado, etc. Normal (Bona Fide) : corresponde al algoritmo habitual del sistema, es decir, todo lo que NO es un ataque. El instrumento de ataque de presentación significa un medio de ataque, por ejemplo, una parte artificial del cuerpo. Y, por último, la detección de ataques de presentación : medios automatizados para detectar tales ataques. Sin embargo, los estándares mismos todavía están en desarrollo, por lo que es imposible hablar sobre conceptos establecidos. La terminología en ruso está casi completamente ausente.
Para determinar la calidad del trabajo, los sistemas a menudo usan la métrica HTER (Tasa de error medio total - mitad del error total), que se calcula como la suma de los coeficientes de identificaciones erróneamente permitidas (FAR - Tasa de aceptación falsa) e identificaciones erróneamente prohibidas (FRR - Tasa de rechazo falso), dividido a la mitad
HTER = (FAR + FRR) / 2
Vale la pena decir que en los sistemas biométricos, FAR suele recibir la mayor atención, a fin de hacer todo lo posible para evitar que un atacante ingrese al sistema. Y están haciendo un buen progreso en esto (¿recuerdan la millonésima parte del comienzo del artículo?). La otra cara es el inevitable aumento en FRR: el número de usuarios comunes clasificados erróneamente como intrusos. Si esto se puede sacrificar por el estado, la defensa y otros sistemas similares, entonces las tecnologías móviles que funcionan con su enorme escala, una variedad de dispositivos de suscriptor y, en general, orientados a la perspectiva del usuario, son muy sensibles a cualquier factor que pueda hacer que los usuarios rechacen los servicios. Si desea reducir la cantidad de teléfonos que se estrellaron contra la pared después de la décima negación consecutiva de identificación, ¡debe prestar atención a FRR!
Tipos de ataques. Sistema de trampa

Finalmente, descubramos exactamente cómo los atacantes engañan al sistema de reconocimiento, y cómo se puede oponer esto.
Los medios más populares de hacer trampa son las máscaras. No hay nada más obvio que ponerse la máscara de otra persona y presentar su rostro a un sistema de identificación (a menudo denominado ataque de máscara).
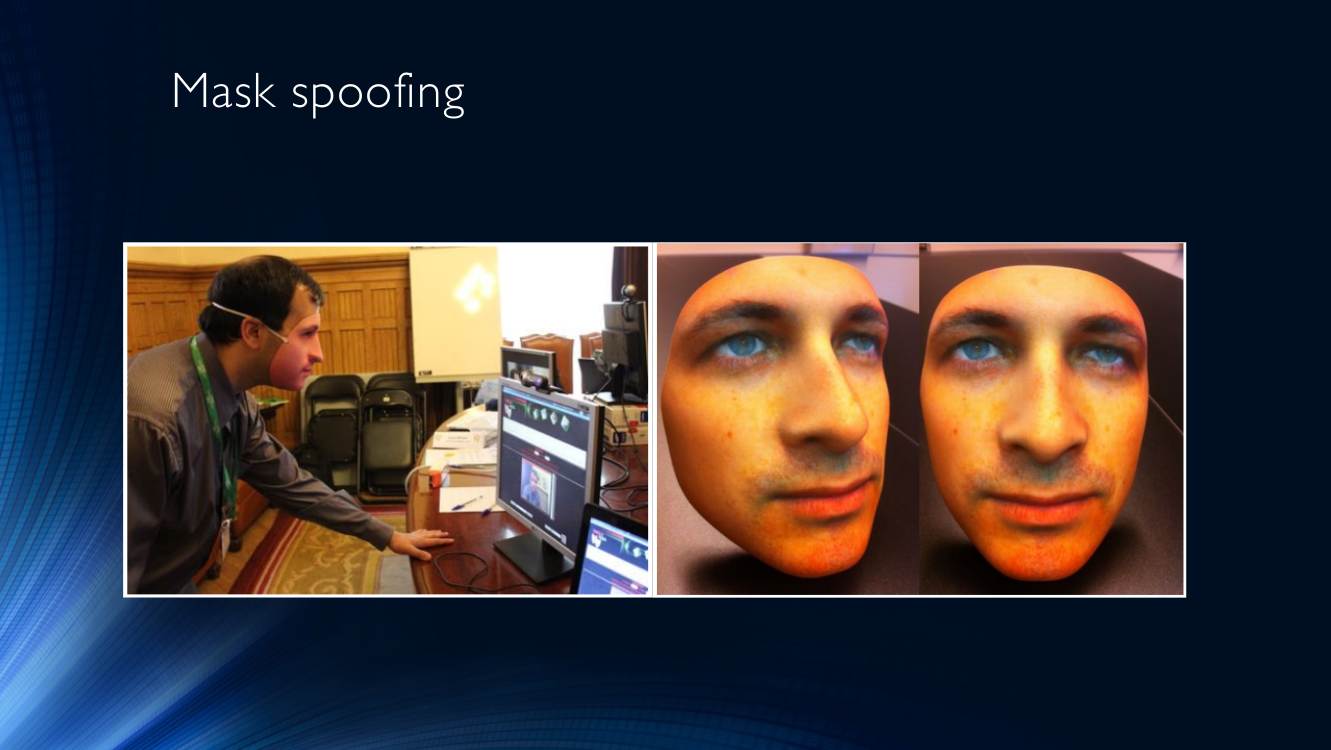
También puede imprimir una foto suya o de otra persona en una hoja de papel y llevarla a la cámara (llamemos a este tipo de ataque Ataque impreso).

Un poco más complicado es el ataque Replay, cuando el sistema se presenta con la pantalla de otro dispositivo en el que se reproduce un video previamente grabado con otra persona. La complejidad de la ejecución se compensa con la alta eficiencia de dicho ataque, ya que los sistemas de control a menudo usan signos basados en el análisis de secuencias de tiempo, por ejemplo, seguimiento de parpadeo, micro movimientos de la cabeza, presencia de expresiones faciales, respiración, etc. Todo esto se puede reproducir fácilmente en video.

Ambos tipos de ataques tienen una serie de características que permiten detectarlos y, por lo tanto, distinguen una pantalla de tableta o una hoja de papel de una persona real.
Resumimos las características que nos permiten identificar estos dos tipos de ataques en una tabla:
Algoritmos de detección de ataques. Buen viejo clásico

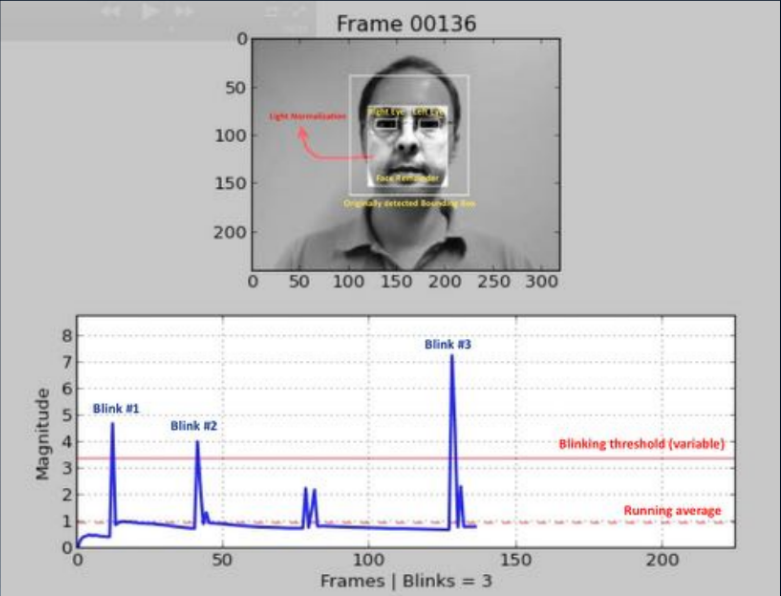
Uno de los enfoques más antiguos (2007, 2008) se basa en la detección de parpadeos humanos mediante el análisis de la imagen con una máscara. El punto es construir algún tipo de clasificador binario que le permita seleccionar imágenes con los ojos abiertos y cerrados en una secuencia de cuadros. Esto puede ser un análisis de la transmisión de video utilizando la identificación de partes de la cara (detección de puntos de referencia) o el uso de alguna red neuronal simple. Y hoy este método se usa con mayor frecuencia; Se le pide al usuario que realice una secuencia de acciones: girar la cabeza, guiñar un ojo, sonreír y más. Si la secuencia es aleatoria, no es fácil para un atacante prepararse con anticipación. Desafortunadamente, para un usuario honesto, esta búsqueda tampoco siempre es superable, y el compromiso cae bruscamente.
También puede usar las características de deterioro de la calidad de la imagen al imprimir o reproducir en la pantalla. Lo más probable es que incluso algunos patrones locales, incluso elusivos a la vista, se detecten en la imagen. Esto se puede hacer, por ejemplo, contando patrones binarios locales (LBP, patrón binario local) para diferentes áreas de la cara después de seleccionarlo desde el marco ( PDF ). El sistema descrito puede considerarse el fundador de toda la dirección de los algoritmos faciales anti-spoofing basados en el análisis de imágenes. En pocas palabras, al calcular el LBP, cada píxel de la imagen, ocho de sus vecinos se toman secuencialmente y se compara su intensidad. Si la intensidad es mayor que en el píxel central, se asigna uno, si es menor, cero. Por lo tanto, para cada píxel se obtiene una secuencia de 8 bits. En base a las secuencias obtenidas, se construye un histograma por píxel, que se alimenta a la entrada del clasificador SVM.
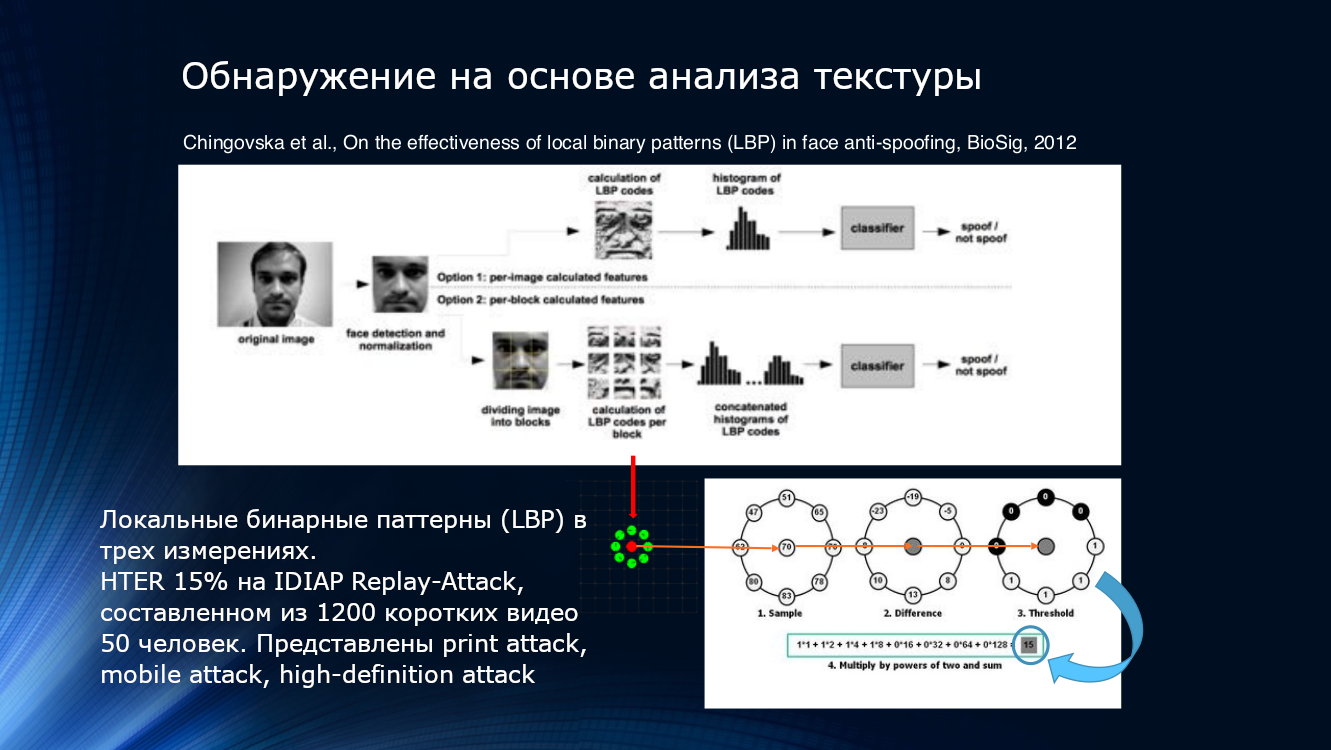
Patrones binarios locales, histograma y SVM. Puedes unirte a los clásicos atemporales aquí
El indicador de eficiencia HTER es "tanto como" 15%, y significa que una parte significativa de los atacantes supera la protección sin mucho esfuerzo, aunque debe reconocerse que se elimina mucho. El algoritmo se probó en el conjunto de datos IDIAP Replay-Attack , que se compone de 1200 videos cortos de 50 encuestados y tres tipos de ataques: ataque impreso, ataque móvil, ataque de alta definición.
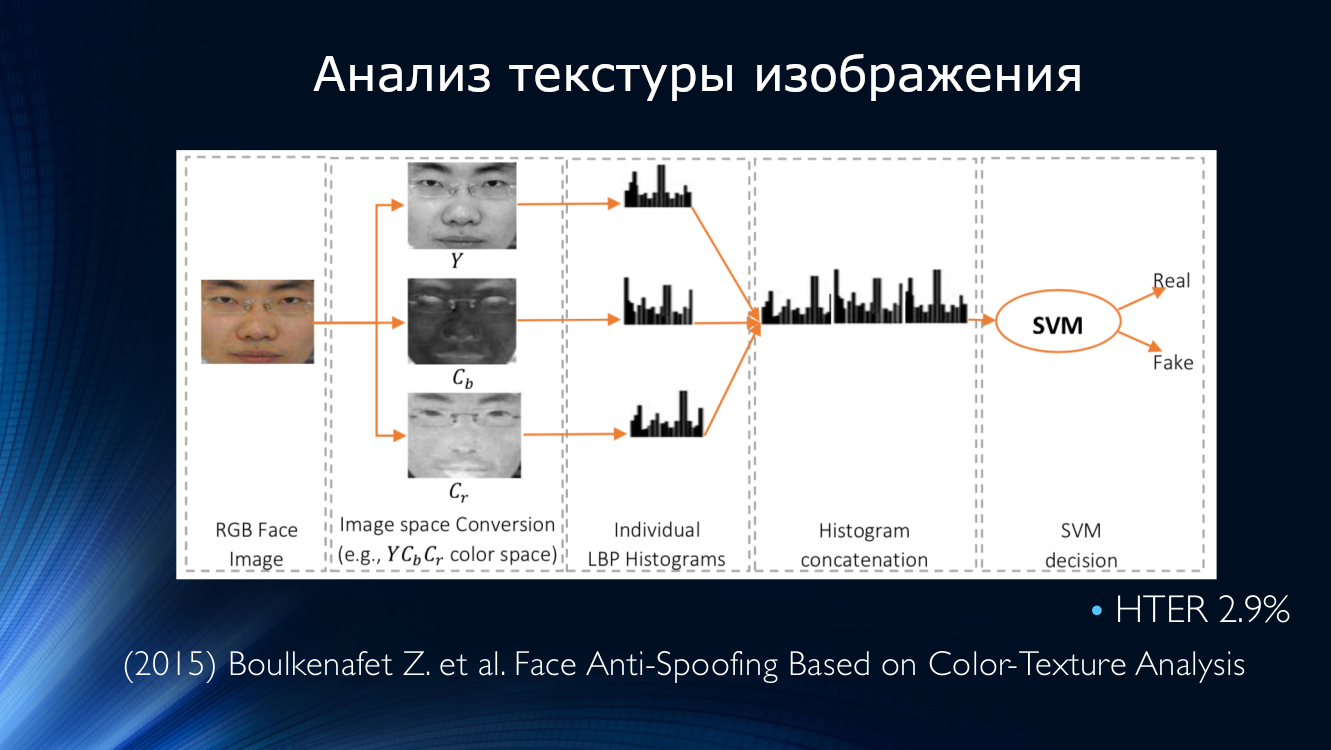
Se han continuado las ideas para analizar la textura de la imagen. En 2015, Bukinafit desarrolló un algoritmo para dividir alternativamente la imagen en canales, además del RGB tradicional, para cuyos resultados se calcularon nuevamente los patrones binarios locales, que, como en el método anterior, se introdujeron en la entrada del clasificador SVN. La precisión HTER, calculada en los conjuntos de datos CASIA y Replay-Attack, fue impresionante en ese momento 3%.
Al mismo tiempo, apareció trabajo en la detección de muaré. Patel publicó un artículo donde sugirió buscar artefactos de imágenes en forma de un patrón periódico causado por la superposición de dos escaneos. El enfoque resultó ser viable, mostrando HTER alrededor del 6% en los conjuntos de datos IDIAP, CASIA y RAFS. También fue el primer intento de comparar el rendimiento de un algoritmo en diferentes conjuntos de datos.

Patrón periódico en la imagen causado por barridos superpuestos
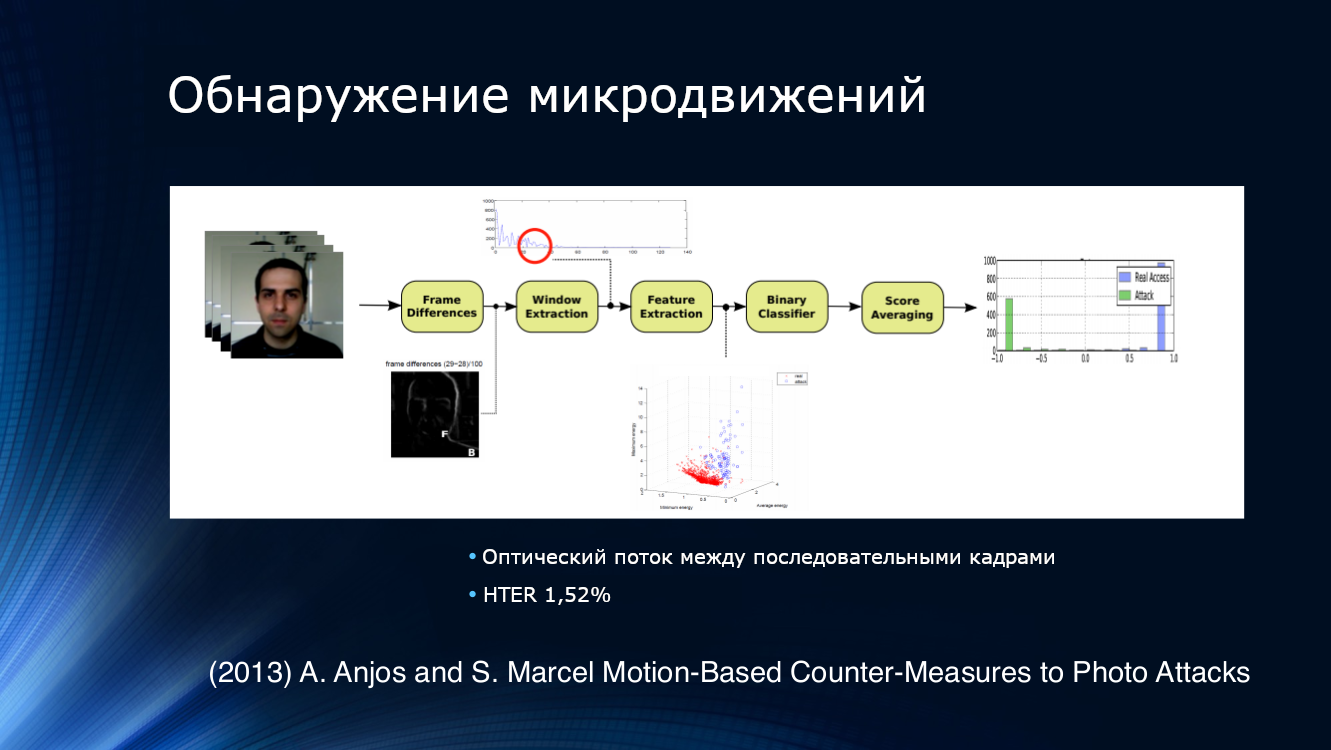
Para detectar intentos de presentar fotos, la solución lógica era tratar de analizar no una imagen, sino su secuencia tomada de la transmisión de video. Por ejemplo, Anjos y sus colegas sugirieron aislar características de la corriente óptica en pares adyacentes de cuadros, alimentar el clasificador binario a la entrada y promediar los resultados. El enfoque resultó ser bastante efectivo, demostrando un HTER de 1.52% en su propio conjunto de datos.
Un método interesante para rastrear movimientos, que es algo distante de los enfoques convencionales. Dado que en 2013 el principio "aplicar una imagen en bruto a la entrada de la red convolucional y ajustar las capas de la cuadrícula para obtener el resultado" no era habitual en los proyectos modernos de aprendizaje profundo, Bharadzha aplicó consistentemente transformaciones preliminares más complejas. En particular, utilizó el algoritmo de aumento de video Eulerian conocido por el trabajo de los científicos del MIT, que se utilizó con éxito para analizar los cambios de color en la piel según el pulso. Reemplacé LBP con HOOF (histogramas de direcciones de flujo óptico), habiendo notado correctamente que dado que queremos rastrear movimientos, necesitamos los signos apropiados, y no solo el análisis de textura. Todos los mismos SVM, tradicionales en ese momento, se utilizaron como clasificador. El algoritmo mostró resultados extremadamente impresionantes en los conjuntos de datos Print Attack (0%) y Replay Attack (1.25%).

¡Aprendamos ya la grilla!

Desde algún punto se hizo evidente que la transición al aprendizaje profundo había madurado. La notoria "revolución del aprendizaje profundo" se enfrentó a la lucha contra la suplantación de identidad.
El "primer trago" puede considerarse el método de análisis de mapas de profundidad en secciones individuales ("parches") de la imagen. Obviamente, un mapa de profundidad es una muy buena señal para determinar el plano en el que se encuentra la imagen. Aunque solo sea porque la imagen en la hoja de papel no tiene "profundidad" por definición. En el trabajo de Ataum en 2017, se extrajeron muchas secciones pequeñas separadas de la imagen; se calcularon mapas de profundidad para ellas, que luego se fusionaron con el mapa de profundidad de la imagen principal. Se señaló que diez parches de imágenes de caras aleatorias son suficientes para identificar de manera confiable el ataque impreso. Además, los autores reunieron los resultados de dos redes neuronales convolucionales, la primera de las cuales calculó mapas de profundidad para parches, y la segunda para la imagen en su conjunto. Al entrenar en conjuntos de datos, la clase de Ataque Impreso se asoció con un mapa de profundidad de cero, y una serie de secciones seleccionadas al azar se asoció con un modelo de cara tridimensional. En general, el mapa de profundidad en sí mismo no era tan importante, solo se utilizó una determinada función de indicador, que caracteriza la "profundidad de la sección". El algoritmo mostró un valor HTER de 3.78%. Se utilizaron tres conjuntos de datos públicos para la capacitación: CASIA-MFSD, MSU-USSA y Replay-Attack.

Desafortunadamente, la disponibilidad de una gran cantidad de marcos excelentes para el aprendizaje profundo ha llevado a la aparición de una gran cantidad de desarrolladores que están tratando de resolver el problema de la suplantación de la cara de una manera conocida de ensamblar redes neuronales. Por lo general, parece una pila de mapas de características en las salidas de varias redes pre-entrenadas en un conjunto de datos generalizado que se alimenta a un clasificador binario.
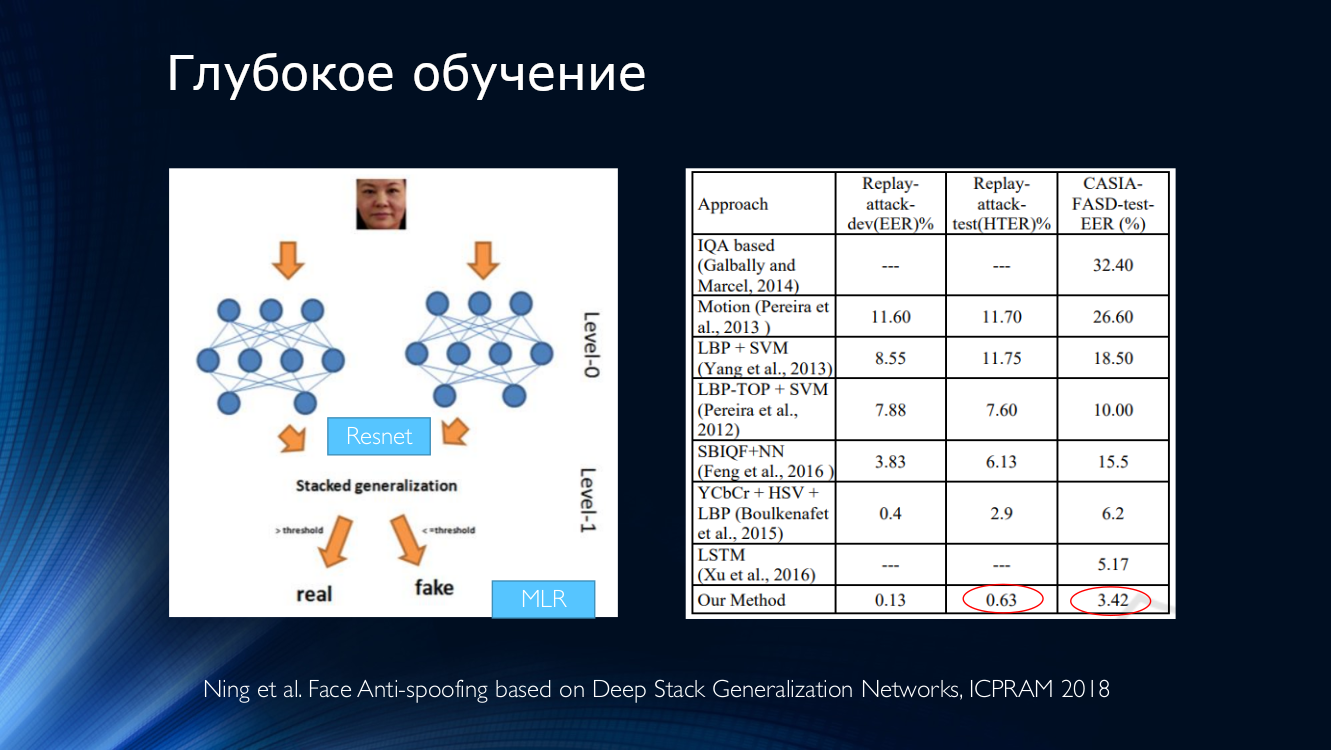
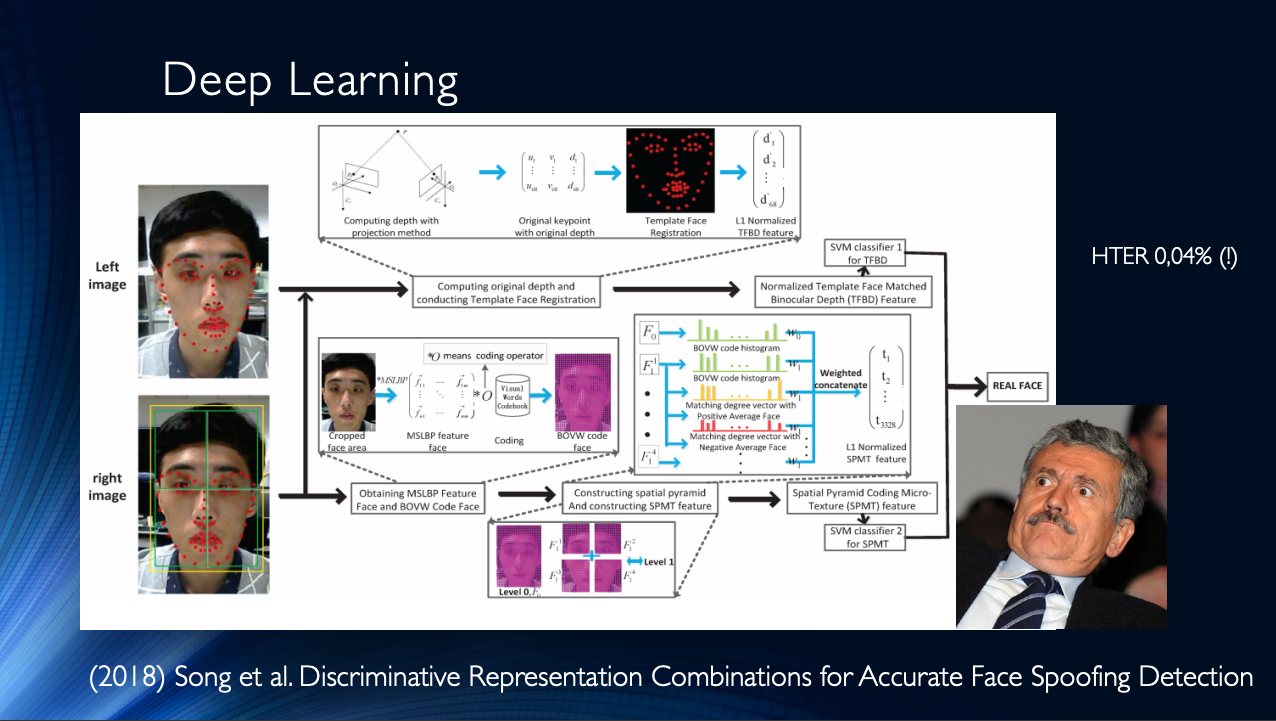
En general, vale la pena concluir que hasta la fecha, se han publicado bastantes trabajos, que generalmente muestran buenos resultados, y que une solo un pequeño "pero". ¡Todos estos resultados se demuestran en un conjunto de datos específico! La situación se ve agravada por la disponibilidad limitada de conjuntos de datos y, por ejemplo, en el famoso Replay-Attack, no es sorprendente HTER 0%. Todo esto lleva a la aparición de arquitecturas muy complejas, como estas , que utilizan varias funciones ingeniosas, algoritmos auxiliares ensamblados en la pila, con varios clasificadores, cuyos resultados son promediados, y así sucesivamente ... ¡Los autores obtienen HTER = 0.04% en la salida!
Esto sugiere que el problema de la suplantación de la cara se ha resuelto dentro de un conjunto de datos específico. Traigamos a la mesa varios métodos modernos basados en redes neuronales. Es fácil ver que los "resultados de referencia" se lograron mediante métodos muy diversos que solo surgieron en las mentes inquisitivas de los desarrolladores.
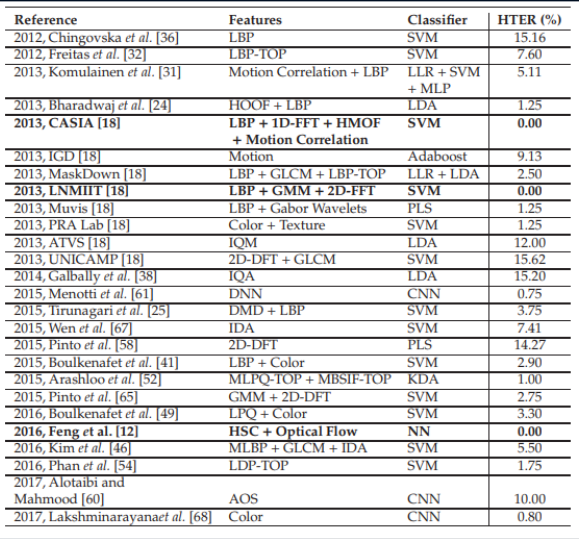
Resultados comparativos de varios algoritmos. La tabla está tomada desde aquí .
Desafortunadamente, el mismo factor "pequeño" viola la buena imagen de la lucha por décimas de porcentaje. Si intenta entrenar la red neuronal en un conjunto de datos y aplicarlo en otro, los resultados serán ... no tan optimistas. Peor aún, los intentos de aplicar clasificadores en la vida real no dejan ninguna esperanza.
Como ejemplo, tomamos los datos de 2015, donde se utilizó una métrica de su calidad para determinar la autenticidad de la imagen presentada. Echa un vistazo por ti mismo:
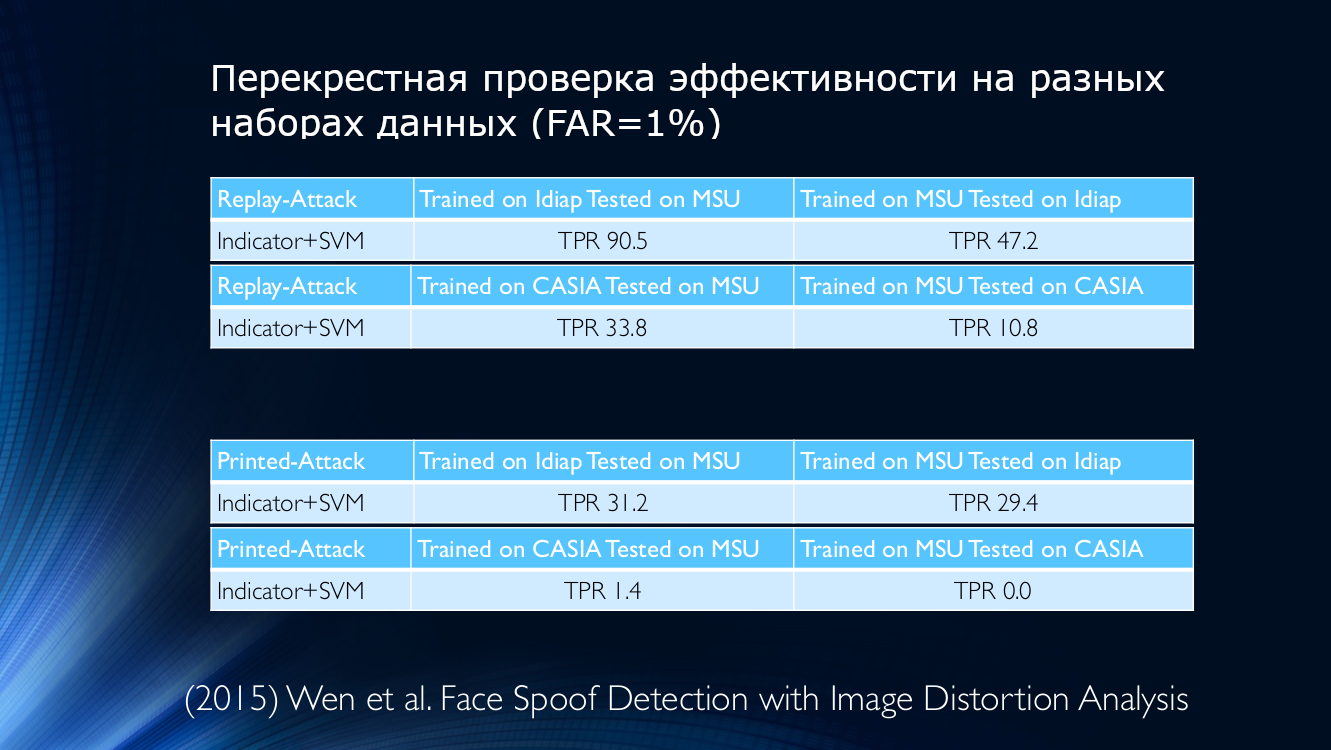
En otras palabras, un algoritmo entrenado en datos de Idiap, pero aplicado en MSU, dará una tasa de detección verdaderamente positiva del 90.5%, y si hace lo contrario (entrene en MSU y pruebe en Idiap), entonces solo 47.2 puede determinarse correctamente % (!) Para otras combinaciones, la situación empeora aún más y, por ejemplo, si entrena el algoritmo en MSU y lo comprueba en CASIA, ¡entonces el TPR será del 10.8%! Esto significa que una gran cantidad de usuarios honestos fueron asignados por error a los atacantes, lo que no puede dejar de ser deprimente. Incluso la capacitación en bases de datos cruzadas no podría revertir la situación, que parece ser una salida perfectamente razonable.
A ver más. Los resultados presentados en el artículo de Patel 2016 muestran que incluso con tuberías de procesamiento bastante complejas y la selección de características confiables como el parpadeo y la textura, los resultados en conjuntos de datos desconocidos no pueden considerarse satisfactorios. Entonces, en algún momento se hizo bastante obvio que los métodos propuestos desesperadamente no eran suficientes para resumir los resultados.
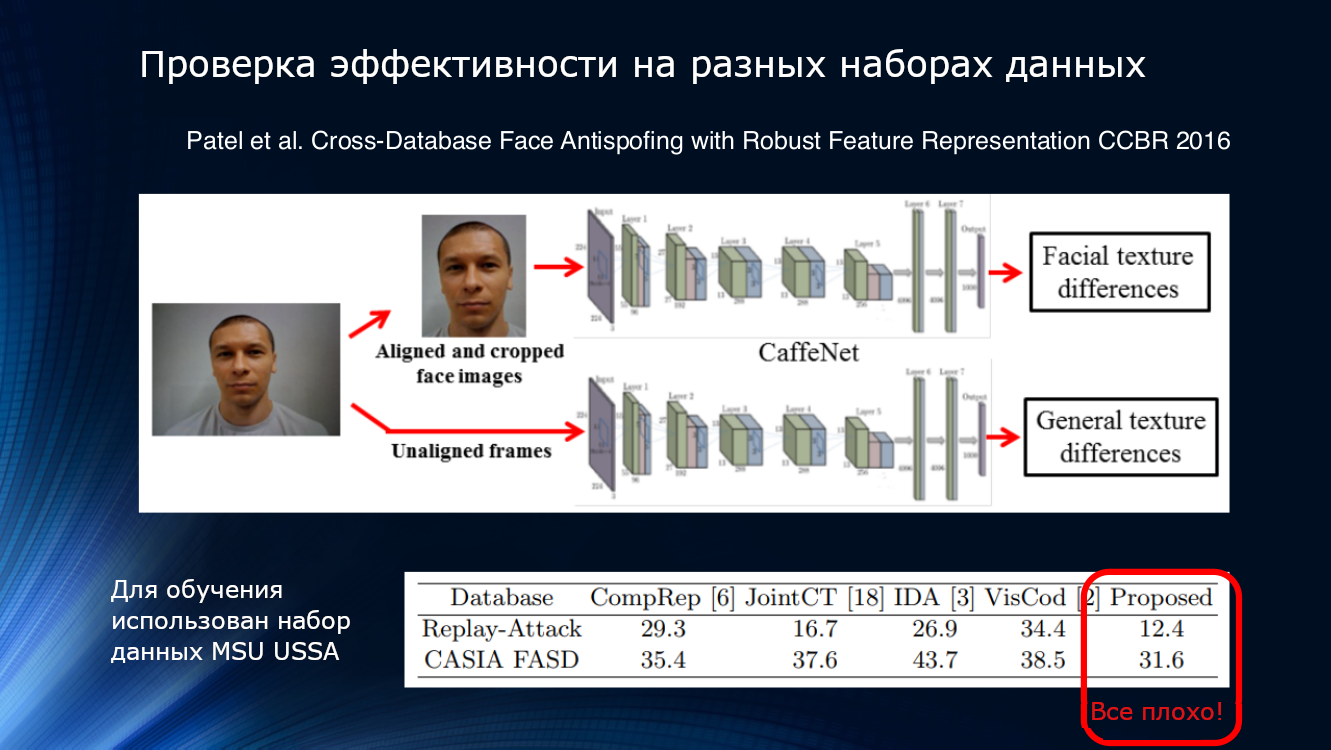
Y si organizas una competencia ...
Por supuesto, en el campo de la lucha contra la falsificación de rostros no estuvo exento de competencia. En 2017, se realizó una competencia en la Universidad de Oulu en Finlandia en su propio conjunto de datos con protocolos bastante interesantes, orientados específicamente para su uso en el campo de las aplicaciones móviles.
- Protocolo 1: hay una diferencia en la iluminación y el fondo. Los conjuntos de datos se registran en varios lugares y difieren en el fondo y la iluminación.
-Protocolo 2: se utilizaron varios modelos de impresoras y pantallas para los ataques. Entonces, en el conjunto de datos de verificación, se utiliza una técnica que no se encuentra en el conjunto de entrenamiento
Protocolo 3: intercambiabilidad de sensores. Los videos y ataques de usuarios reales se graban en cinco teléfonos inteligentes diferentes y se usan en un conjunto de datos de entrenamiento. , .
- 4: .
. , , , - . , , 10%. :
GRADIENT
- ( HSV YCbCr), .
- .
- HSV YCbCr, . ROI (region-of-interest) 160×160 ..
- ROI 3×3 5×5 , LBP , 6018.
- (Recursive Feature Elimination) 6018 1000.
- SVM .|
SZCVI
Recod
- SqueezeNet Imagenet
- Transfer learning : CASIA UVAD
- 224×224 pixels. , , , CNN.
- .
CPqD
- Inception-v3, ImageNet
- C
- , , 224×224 RGB |
, . LBP, , , .. GRADIANT , , , . .
. , . -, ( 15 NUAA 1140 MSU-USSA) , , , , . , , , , . -, . , CASIA , . , , , , … , , , .
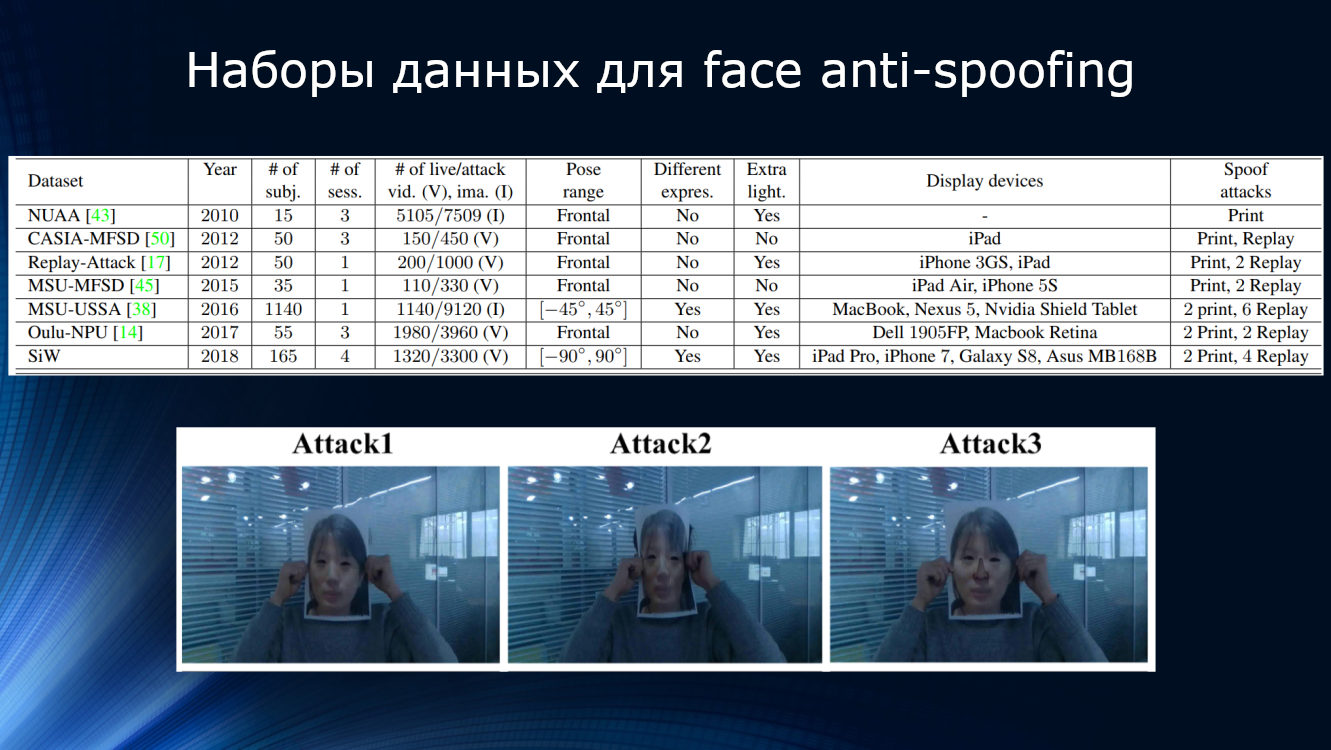
30 . , , . , .
, , « ». . , (rPPG – remote photoplethysmography), . , , -, – . . , , , . , , . , , , .


El trabajo mostró un valor HTER de aproximadamente el 10%, confirmando la aplicabilidad principal del método. Hay varios trabajos que confirman las perspectivas de este enfoque.
(CVPR 2018) JH-Ortega et al. Análisis de tiempo de Anti-Spoofing facial basado en pulsos en visible y NIR
(2016) X. Li. et al. Anti-spoofing facial generalizado mediante la detección de pulso de videos faciales
(2016) J. Chen y col. Realsense = frecuencia cardíaca real: estimación de la frecuencia cardíaca invariante de iluminación a partir de videos
(2014) HE Tasli et al. Medición remota de signos vitales basada en PPG utilizando regiones faciales adaptativas
En 2018, Liu y sus colegas de la Universidad de Michigan propusieron abandonar la clasificación binaria a favor del enfoque que llamaron "supervisión binaria", es decir, usar una estimación más compleja basada en un mapa de profundidad y una fotopletismografía remota. Para cada una de estas imágenes faciales, se reconstruyó un modelo tridimensional utilizando una red neuronal y se le dio un mapa de profundidad. A las imágenes falsas se les asignó un mapa de profundidad que consta de ceros, ¡al final es solo un trozo de papel o la pantalla de un dispositivo! Estas características fueron tomadas como "verdad", las redes neuronales fueron entrenadas en su propio conjunto de datos SiW. Luego, se superpuso una máscara facial tridimensional en la imagen de entrada, se calculó un mapa de profundidad y un pulso, y todo esto se unió en un transportador bastante complicado. Como resultado, el método mostró una precisión de aproximadamente el 10 por ciento en el conjunto de datos competitivos de OULU. Curiosamente, el ganador de la competencia organizada por la Universidad de Oulu construyó el algoritmo sobre patrones de clasificación binarios, seguimiento intermitente y otros signos "diseñados a mano", y su solución también tuvo una precisión de aproximadamente el 10%. ¡La ganancia fue solo del medio por ciento! La nueva tecnología combinada está respaldada por el hecho de que el algoritmo fue entrenado en su propio conjunto de datos y probado en OULU, mejorando el resultado del ganador. Esto indica una cierta portabilidad de los resultados del conjunto de datos al conjunto de datos, y lo que no es broma, es posible para la vida real. Sin embargo, al intentar realizar capacitación en otros conjuntos de datos: CASIA y ReplayAttack, el resultado nuevamente fue de alrededor del 28%. Por supuesto, esto excede el rendimiento de otros algoritmos cuando se entrena en varios conjuntos de datos, pero con tales valores de precisión, ¡no se puede hablar de ningún uso industrial!
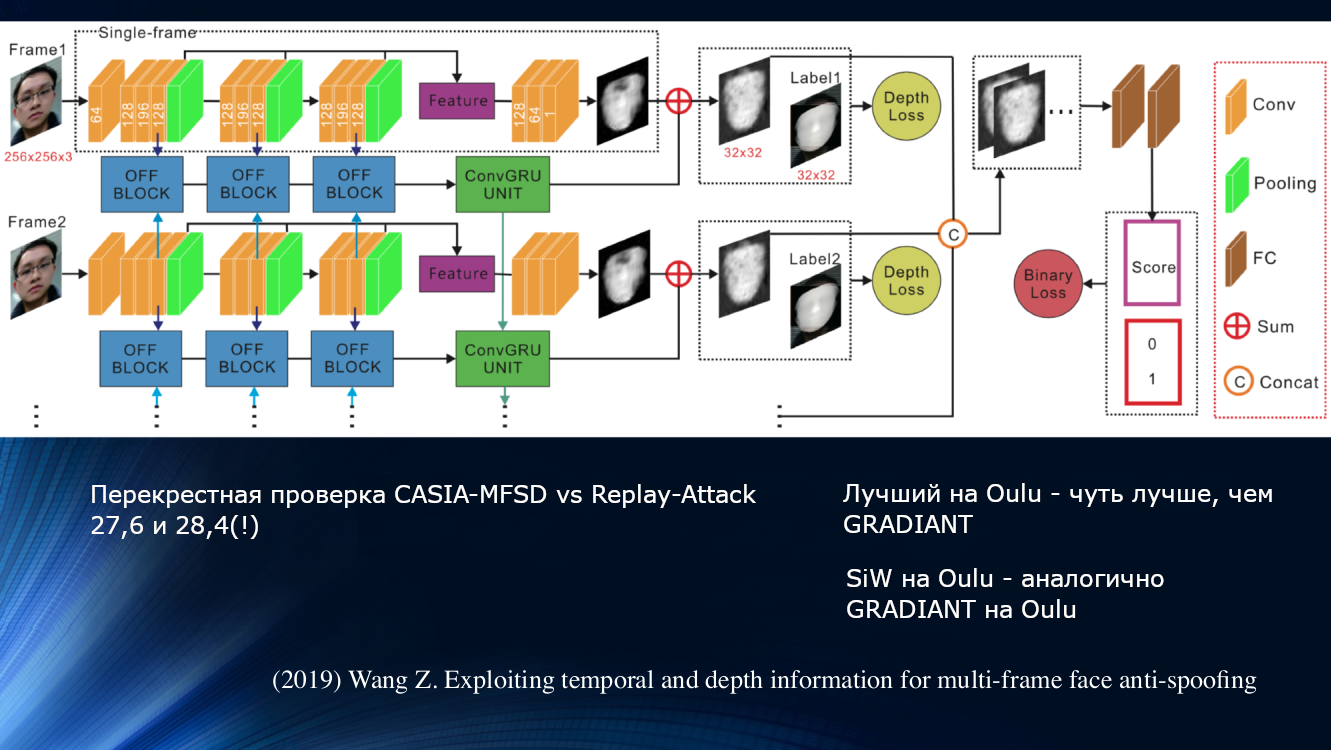
Wang y sus colegas propusieron un enfoque diferente en un trabajo reciente de 2019. Se observó que en el análisis de micromovimiento de la cara, las rotaciones y los desplazamientos de la cabeza son notables, lo que lleva a un cambio característico en los ángulos y las distancias relativas entre los signos en la cara. Entonces, cuando la cara se desplaza horizontalmente, el ángulo entre la nariz y la oreja aumenta. Pero, si cambia una hoja de papel con una imagen de la misma manera, ¡el ángulo disminuirá! Por ejemplo, vale la pena citar un dibujo de la obra.
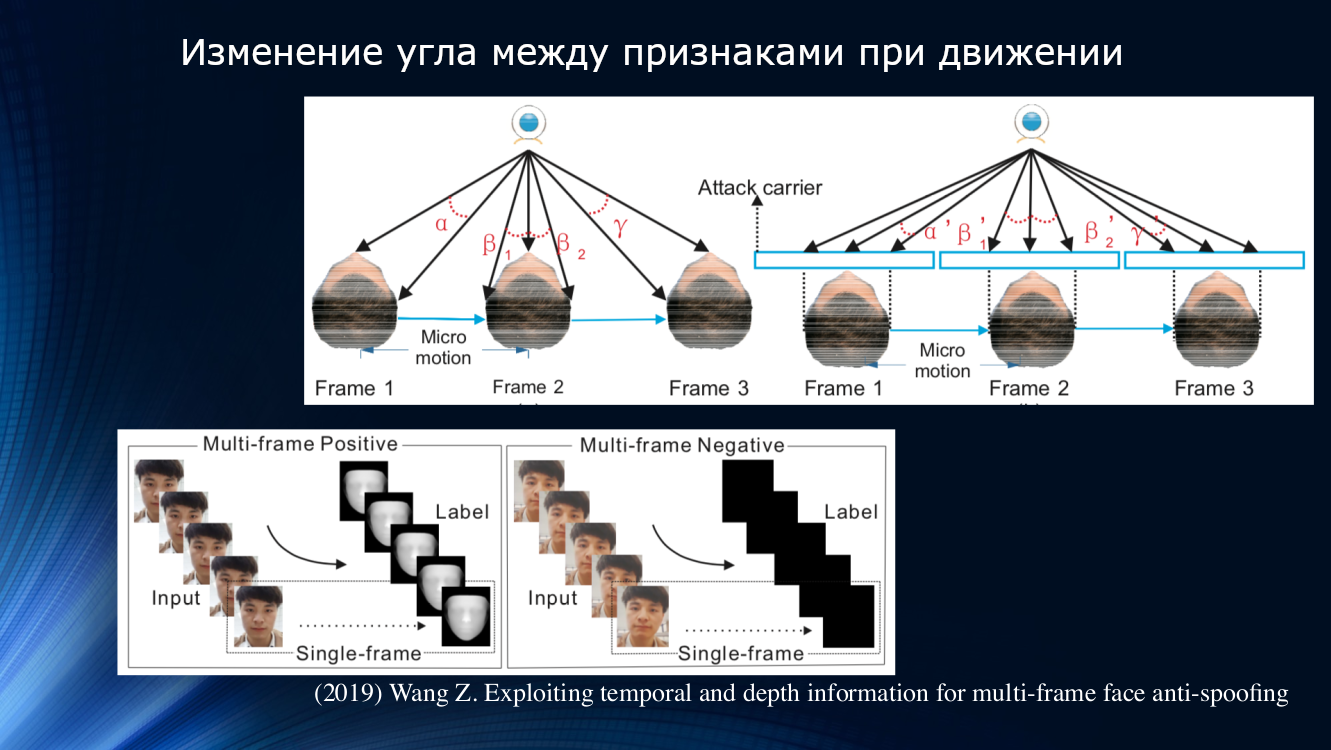
Sobre este principio, los autores construyeron una unidad de aprendizaje completa para transferir datos entre capas de una red neuronal. Tomó en cuenta las "compensaciones incorrectas" para cada cuadro en una secuencia de dos cuadros, y esto permitió que los resultados se usaran en el siguiente bloque de análisis de dependencia a largo plazo basado en la Unidad Recurrente Cerrada GRU. Luego, todos los signos se concatenaron, se calculó la función de pérdida y se realizó la clasificación final. Esto nos permitió mejorar ligeramente el resultado en el conjunto de datos OULU, pero el problema de la dependencia de los datos de entrenamiento persistió, ya que para el par CASIA-MFSD y Replay-Attack, los indicadores fueron 17.5 y 24 por ciento, respectivamente.
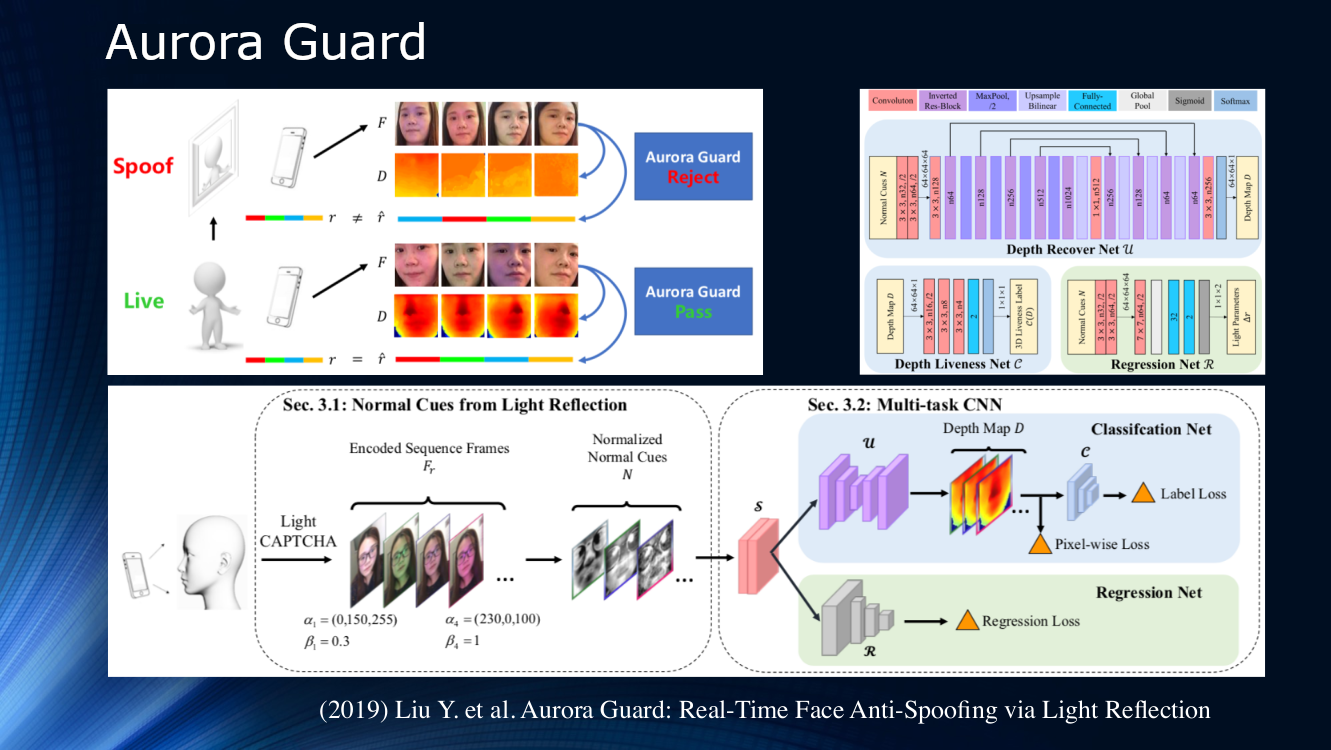
Hacia el final, vale la pena señalar el trabajo de los expertos de Tencent, quienes propusieron cambiar la forma en que se recibe la imagen de video fuente. En lugar de observar pasivamente la escena, sugirieron iluminar dinámicamente la cara y leer los reflejos. El principio de irradiación activa de un objeto se ha aplicado durante mucho tiempo en sistemas de localización de varios tipos, por lo tanto, su uso para estudiar la cara parece muy lógico. Obviamente, para una identificación confiable en la imagen en sí no hay suficientes signos, y puede ser de gran ayuda iluminar la pantalla del teléfono o tableta con una secuencia de símbolos de luz (CAPTCHA de luz según la terminología de los autores). A continuación, se determina la diferencia en la dispersión y la reflexión sobre un par de cuadros, y los resultados se envían a una red neuronal multitarea para su posterior procesamiento en el mapa de profundidad y el cálculo de diversas funciones de pérdida. Al final, se realiza una regresión de los marcos de luz normalizados. Los autores no analizaron la capacidad de generalización de su algoritmo en otros conjuntos de datos y lo entrenaron en su propio conjunto de datos privado. El resultado es aproximadamente el 1% y se informa que el modelo ya se ha implementado para uso real.
Hasta 2017, el área de anti-spoofing facial no estaba muy activa. Pero 2019 ya ha presentado una serie completa de trabajos, que se asocia con la promoción agresiva de las tecnologías móviles de identificación facial, principalmente por parte de Apple. Además, los bancos están interesados en las tecnologías de reconocimiento facial. Muchas personas nuevas han venido a la industria, lo que nos permite esperar un progreso rápido. Pero hasta ahora, a pesar de los hermosos títulos de las publicaciones, la capacidad de generalización de los algoritmos sigue siendo muy débil y no nos permite hablar sobre la idoneidad para el uso práctico.
Conclusión Y finalmente, diré que ...
- Los patrones binarios locales, el seguimiento del parpadeo, la respiración, los movimientos y otros signos diseñados manualmente no han perdido su importancia en absoluto. Esto se debe principalmente al hecho de que el entrenamiento profundo en el campo de la suplantación de la cara sigue siendo muy ingenuo.
- Está claro que en la "misma" solución, se combinarán varios métodos. Análisis de reflexión, dispersión, mapas de profundidad deben usarse juntos. Lo más probable es que la adición de un canal de datos adicional ayude, por ejemplo, la grabación de voz y algún tipo de enfoque del sistema que le permitirá recopilar varias tecnologías en un solo sistema
- Casi todas las tecnologías utilizadas para el reconocimiento facial encuentran aplicación en el anti-spoofing facial (¡cap!) Todo lo que se desarrolló para el reconocimiento facial, de una forma u otra, ha encontrado aplicación para el análisis de ataque
- Los conjuntos de datos existentes han alcanzado la saturación. De diez conjuntos de datos básicos en cinco, se logró un error cero. Esto ya habla, por ejemplo, de la eficiencia de los métodos basados en mapas de profundidad, pero no permite mejorar la capacidad de generalización. Necesitamos nuevos datos y nuevos experimentos sobre ellos.
- Existe un claro desequilibrio entre el grado de desarrollo del reconocimiento facial y el anti-spoofing facial. Las tecnologías de reconocimiento están significativamente por delante de los sistemas de protección. Además, es la falta de sistemas de protección confiables lo que inhibe el uso práctico de los sistemas de reconocimiento facial. Sucedió que la atención principal se prestó específicamente al reconocimiento facial, y los sistemas de detección de ataques se mantuvieron algo distantes
- Existe una gran necesidad de un enfoque sistemático en el campo de la suplantación de la cara. La competencia anterior de la Universidad de Oulu mostró que cuando se usa un conjunto de datos no representativo, es muy posible derrotarlo con un simple ajuste competente de las soluciones establecidas, sin desarrollar nuevas. Quizás una nueva competencia puede cambiar el rumbo
- Con un creciente interés en el tema y la introducción de tecnologías de reconocimiento facial por parte de grandes jugadores, aparecieron "ventanas de oportunidad" para los nuevos equipos ambiciosos, ya que existe una gran necesidad de una nueva solución a nivel arquitectónico.