En los artículos anteriores discutimos el
motor de indexación PostgreSQL, la interfaz de los métodos de acceso y los siguientes métodos:
índices hash ,
árboles B ,
GiST ,
SP-GiST ,
GIN y
RUM . El tema de este artículo son los índices BRIN.
Brin
Concepto general
A diferencia de los índices con los que ya nos hemos reunido, la idea de BRIN es evitar mirar filas definitivamente inadecuadas en lugar de encontrar rápidamente las que coincidan. Este es siempre un índice inexacto: no contiene TID de filas de tabla en absoluto.
Simplísticamente, BRIN funciona bien para columnas donde los valores se correlacionan con su ubicación física en la tabla. En otras palabras, si una consulta sin la cláusula ORDER BY devuelve los valores de la columna prácticamente en orden creciente o decreciente (y no hay índices en esa columna).
Este método de acceso se creó en el ámbito de
Axle , el proyecto europeo para bases de datos analíticas extremadamente grandes, con un ojo puesto en tablas de varios terabytes o docenas de terabytes de gran tamaño. Una característica importante de BRIN que nos permite crear índices en tales tablas es un tamaño pequeño y costos generales mínimos de mantenimiento.
Esto funciona de la siguiente manera. La tabla se divide en
rangos de varias páginas (o varios bloques, que es lo mismo); de ahí el nombre: Índice de rango de bloques, BRIN. El índice almacena
información resumida sobre los datos en cada rango. Como regla, estos son los valores mínimos y máximos, pero resulta ser diferente, como se muestra más adelante. Suponga que se realiza una consulta que contiene la condición para una columna; si los valores buscados no entran en el intervalo, se puede omitir todo el rango; pero si se obtienen, todas las filas en todos los bloques deberán revisarse para elegir las que coincidan entre ellas.
No será un error tratar a BRIN no como un índice, sino como un acelerador de la exploración secuencial. Podemos considerar BRIN como una alternativa a la partición si consideramos cada rango como una partición "virtual".
Ahora analicemos la estructura del índice con más detalle.
Estructura
La primera página (más exactamente, cero) contiene los metadatos.
Las páginas con la información de resumen se encuentran en un cierto desplazamiento de los metadatos. Cada fila de índice en esas páginas contiene información de resumen en un rango.
Entre la meta página y los datos de resumen, se encuentran las páginas con el
mapa de rango inverso (abreviado como "revmap"). En realidad, esta es una matriz de punteros (TID) a las filas de índice correspondientes.
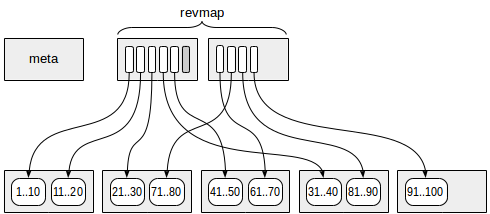
Para algunos rangos, el puntero en "revmap" puede conducir a una fila sin índice (una está marcada en gris en la figura). En tal caso, se considera que el rango aún no tiene información de resumen.
Escaneando el índice
¿Cómo se usa el índice si no contiene referencias a las filas de la tabla? Este método de acceso ciertamente no puede devolver las filas TID por TID, pero puede construir un mapa de bits. Puede haber dos tipos de páginas de mapa de bits: precisas, en la fila, e imprecisas, en la página. Se utiliza un mapa de bits inexacto.
El algoritmo es simple. El mapa de rangos se escanea secuencialmente (es decir, los rangos se procesan en el orden de su ubicación en la tabla). Los punteros se utilizan para determinar filas de índice con información de resumen en cada rango. Si un rango no contiene el valor buscado, se omite y si puede contener el valor (o la información de resumen no está disponible), todas las páginas del rango se agregan al mapa de bits. El mapa de bits resultante se usa como de costumbre.
Actualizando el índice
Es más interesante cómo se actualiza el índice cuando se cambia la tabla.
Al
agregar una nueva versión de una fila a una página de tabla, determinamos en qué rango está contenido y utilizamos el mapa de rangos para encontrar la fila de índice con la información de resumen. Todas estas son operaciones aritméticas simples. Deje, por ejemplo, que el tamaño de un rango sea cuatro y en la página 13, se produce una versión de fila con el valor de 42. El número del rango (comenzando con cero) es 13/4 = 3, por lo tanto, en "revmap" tomamos el puntero con el desplazamiento de 3 (su número de orden es cuatro).
El valor mínimo para este rango es 31, y el máximo es 40. Dado que el nuevo valor de 42 está fuera del intervalo, actualizamos el valor máximo (ver la figura). Pero si el nuevo valor aún está dentro de los límites almacenados, el índice no necesita actualizarse.

Todo esto se relaciona con la situación cuando la nueva versión de la página ocurre en un rango para el cual la información de resumen está disponible. Cuando se crea el índice, la información de resumen se calcula para todos los rangos disponibles, pero mientras la tabla se expande aún más, pueden aparecer nuevas páginas que caen fuera de los límites. Hay dos opciones disponibles aquí:
- Por lo general, el índice no se actualiza de inmediato. Esto no es un gran problema: como ya se mencionó, al escanear el índice, se examinará todo el rango. La actualización real se realiza durante el "vacío", o se puede hacer manualmente llamando a la función "brin_summarize_new_values".
- Si creamos el índice con el parámetro "autosummarize", la actualización se realizará de inmediato. Pero cuando las páginas del rango se rellenan con nuevos valores, las actualizaciones pueden ocurrir con demasiada frecuencia, por lo tanto, este parámetro está desactivado de forma predeterminada.
Cuando ocurren nuevos rangos, el tamaño de "revmap" puede aumentar. Siempre que el mapa, ubicado entre la meta página y los datos de resumen, necesite ser extendido por otra página, las versiones de fila existentes se mueven a otras páginas. Por lo tanto, el mapa de rangos siempre se encuentra entre la meta página y los datos de resumen.
Cuando se
elimina una fila, ... no pasa nada. Podemos notar que a veces se eliminará el valor mínimo o máximo, en cuyo caso el intervalo podría reducirse. Pero para detectar esto, tendríamos que leer todos los valores en el rango, y esto es costoso.
La exactitud del índice no se ve afectada, pero la búsqueda puede requerir examinar más rangos de los que realmente se necesitan. En general, la información resumida puede recalcularse manualmente para dicha zona (llamando a las funciones "brin_desummarize_range" y "brin_summarize_new_values"), pero ¿cómo podemos detectar tal necesidad? De todos modos, no hay un procedimiento convencional disponible para este fin.
Finalmente,
actualizar una fila es solo una eliminación de la versión desactualizada y la adición de una nueva.
Ejemplo
Intentemos construir nuestro propio mini almacén de datos para los datos de las tablas de la
base de datos de demostración . Supongamos que, para los informes de BI, se necesita una tabla desnormalizada para reflejar los vuelos que partieron de un aeropuerto o aterrizaron en el aeropuerto con la precisión de un asiento en la cabina. Los datos de cada aeropuerto se agregarán a la tabla una vez al día, cuando sea medianoche en la zona horaria correspondiente. Los datos no serán actualizados ni eliminados.
La tabla tendrá el siguiente aspecto:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
Podemos simular el procedimiento de cargar los datos usando bucles anidados: uno externo por días (consideraremos
una base de datos grande , por lo tanto 365 días) y un bucle interno por zonas horarias (de UTC + 02 a UTC + 12) . La consulta es bastante larga y no es de particular interés, así que la esconderé debajo del spoiler.
Simulación de cargar los datos al almacenamiento. DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
Tenemos 30 millones de filas y 4 GB. No es un tamaño tan grande, pero lo suficientemente bueno para una computadora portátil: el escaneo secuencial me llevó unos 10 segundos.
¿En qué columnas debemos crear el índice?
Dado que los índices BRIN tienen un tamaño pequeño y los costos generales moderados y las actualizaciones ocurren con poca frecuencia, si es que hay alguna, surge una rara oportunidad de construir muchos índices "por si acaso", por ejemplo, en todos los campos en los que los usuarios analistas pueden crear sus consultas ad-hoc . No será útil, no importa, pero incluso un índice que no sea muy eficiente funcionará mejor que la exploración secuencial con seguridad. Por supuesto, hay campos en los que es absolutamente inútil construir un índice; El sentido común puro los impulsará.
Pero debería ser extraño limitarnos a este consejo, por lo tanto, tratemos de establecer un criterio más preciso.
Ya hemos mencionado que los datos deben estar algo correlacionados con su ubicación física. Aquí tiene sentido recordar que PostgreSQL reúne estadísticas de columna de tabla, que incluyen el valor de correlación. El planificador usa este valor para seleccionar entre un escaneo de índice regular y un escaneo de mapa de bits, y podemos usarlo para estimar la aplicabilidad del índice BRIN.
En el ejemplo anterior, los datos se ordenan evidentemente por días (por "horario_programado", así como por "tiempo_real", no hay mucha diferencia). Esto se debe a que cuando se agregan filas a la tabla (sin eliminaciones ni actualizaciones), se presentan en el archivo una tras otra. En la simulación de la carga de datos, ni siquiera utilizamos la cláusula ORDER BY, por lo tanto, las fechas dentro de un día pueden, en general, mezclarse de manera arbitraria, pero el orden debe estar en su lugar. Vamos a ver esto:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
El valor que no está demasiado cerca de cero (idealmente, cerca de más menos menos, como en este caso), nos dice que el índice BRIN será apropiado.
La clase de viaje "fare_condition" (la columna contiene tres valores únicos) y el tipo de vuelo "flight_type" (dos valores únicos) aparecieron inesperadamente en el segundo y tercer lugar. Esto es una ilusión: formalmente, la correlación es alta, mientras que en varias páginas sucesivas se encontrarán todos los valores posibles, lo que significa que BRIN no servirá de nada.
La zona horaria "airport_utc_offset" va a continuación: en el ejemplo considerado, dentro de un ciclo de un día, los aeropuertos se ordenan por zonas horarias "por construcción".
Son estos dos campos, hora y zona horaria, con los que experimentaremos más.
Posible debilitamiento de la correlación.
La correlación que se coloca "por construcción" se puede debilitar fácilmente cuando se modifican los datos. Y el asunto aquí no está en un cambio a un valor particular, sino en la estructura del control de concurrencia de varias versiones: la versión de fila obsoleta se elimina en una página, pero se puede insertar una nueva versión siempre que haya espacio libre disponible. Debido a esto, las filas enteras se mezclan durante las actualizaciones.
Podemos controlar parcialmente este efecto reduciendo el valor del parámetro de almacenamiento "factor de relleno" y de esta manera dejando espacio libre en una página para futuras actualizaciones. ¿Pero queremos aumentar el tamaño de una mesa ya enorme? Además, esto no resuelve el problema de las eliminaciones: también "establecen trampas" para las nuevas filas al liberar el espacio en algún lugar dentro de las páginas existentes. Debido a esto, las filas que de otro modo llegarían al final del archivo, se insertarán en algún lugar arbitrario.
Por cierto, este es un hecho curioso. Dado que el índice BRIN no contiene referencias a las filas de la tabla, su disponibilidad no debería obstaculizar las actualizaciones HOT, pero lo hace.
Por lo tanto, BRIN está diseñado principalmente para tablas de tamaños grandes e incluso enormes que no se actualizan en absoluto o se actualizan muy ligeramente. Sin embargo, se adapta perfectamente a la adición de nuevas filas (al final de la tabla). Esto no es sorprendente, ya que este método de acceso se creó con miras a almacenes de datos e informes analíticos.
¿Qué tamaño de rango necesitamos seleccionar?
Si tratamos con una tabla de terabytes, nuestra principal preocupación al seleccionar el tamaño de un rango probablemente no sea hacer que el índice BRIN sea demasiado grande. Sin embargo, en nuestra situación, podemos permitirnos analizar los datos con mayor precisión.
Para hacer esto, podemos seleccionar valores únicos de una columna y ver en cuántas páginas aparecen. La localización de los valores aumenta las posibilidades de éxito en la aplicación del índice BRIN. Además, el número de páginas encontradas indicará el tamaño de un rango. Pero si el valor se "extiende" por todas las páginas, BRIN es inútil.
Por supuesto, debemos usar esta técnica vigilando la estructura interna de los datos. Por ejemplo, no tiene sentido considerar cada fecha (más exactamente, una marca de tiempo, que también incluye la hora) como un valor único: necesitamos redondearlo a días.
Técnicamente, este análisis se puede hacer mirando el valor de la columna oculta "ctid", que proporciona el puntero a una versión de fila (TID): el número de la página y el número de la fila dentro de la página. Desafortunadamente, no existe una técnica convencional para descomponer TID en sus dos componentes, por lo tanto, tenemos que emitir tipos a través de la representación de texto:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
Podemos ver que cada día se distribuye en las páginas de manera bastante uniforme, y los días están ligeramente mezclados entre sí (1500 y veces 365 = 547500, que es solo un poco más grande que el número de páginas en la tabla 528172). De todos modos, esto está claro "por construcción".
La información valiosa aquí es un número específico de páginas. Con un tamaño de rango convencional de 128 páginas, cada día ocupará 9-14 rangos. Esto parece realista: con una consulta para un día específico, podemos esperar un error de alrededor del 10%.
Probemos
demo=# create index on flights_bi using brin(scheduled_time);
El tamaño del índice es tan pequeño como 184 KB:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
En este caso, apenas tiene sentido aumentar el tamaño de un rango a costa de perder la precisión. Pero podemos reducir el tamaño si es necesario, y la precisión, por el contrario, aumentará (junto con el tamaño del índice).
Ahora veamos las zonas horarias. Aquí tampoco podemos utilizar un enfoque de fuerza bruta. Todos los valores deben dividirse por el número de ciclos de día, ya que la distribución se repite dentro de cada día. Además, dado que solo hay algunas zonas horarias, podemos ver toda la distribución:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
En promedio, los datos para cada zona horaria ocupan 133 páginas por día, pero la distribución es altamente no uniforme: Petropavlovsk-Kamchatskiy y Anadyr se ajustan a tan solo seis páginas, mientras que Moscú y su vecindario requieren cientos de ellas. El tamaño predeterminado de un rango no es bueno aquí; establezcamos, por ejemplo, cuatro páginas.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
Plan de ejecucion
Veamos cómo funcionan nuestros índices. Seleccionemos algún día, digamos, hace una semana (en la base de datos de demostración, "hoy" está determinado por la función "booking.now"):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
Como podemos ver, el planificador utilizó el índice creado. ¿Qué tan exacto es? La relación entre el número de filas que cumplen las condiciones de consulta ("filas" del nodo Bitmap Heap Scan) y el número total de filas devueltas usando el índice (el mismo valor más las filas eliminadas por la comprobación de índice) nos informa sobre esto. En este caso 83954 / (83954 + 12045), que es aproximadamente el 90%, como se esperaba (este valor cambiará de un día para otro).
¿De dónde se origina el número 16640 en las "filas reales" del nodo Escaneo de índice de mapa de bits? La cuestión es que este nodo del plan construye un mapa de bits inexacto (página por página) y desconoce por completo cuántas filas tocará el mapa de bits, mientras que algo debe mostrarse. Por lo tanto, en la desesperación se supone que una página contiene 10 filas. El mapa de bits contiene 1664 páginas en total (este valor se muestra en "Heap Blocks: lossy = 1664"); entonces, obtenemos 16640. En total, este es un número sin sentido, al que no debemos prestarle atención.
¿Qué hay de los aeropuertos? Por ejemplo, tomemos la zona horaria de Vladivostok, que ocupa 28 páginas al día:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
El planificador nuevamente utiliza el índice BRIN creado. La precisión es peor (alrededor del 75% en este caso), pero esto se espera ya que la correlación es menor.
Varios índices BRIN (como cualquiera de los otros) ciertamente se pueden unir a nivel de mapa de bits. Por ejemplo, los siguientes son los datos en la zona horaria seleccionada durante un mes (observe el nodo "BitmapAnd"):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
Comparación con b-tree
¿Qué sucede si creamos un índice B-tree regular en el mismo campo que BRIN?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
¡Parecía ser
varios miles de veces más grande que nuestro BRIN! Sin embargo, la consulta se realiza un poco más rápido: el planificador utilizó estadísticas para descubrir que los datos están ordenados físicamente y no es necesario para construir un mapa de bits y, principalmente, que no es necesario volver a verificar la condición del índice:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
Eso es lo maravilloso de BRIN: sacrificamos la eficiencia, pero ganamos mucho espacio.
Clases de operador
minmax
Para los tipos de datos cuyos valores se pueden comparar entre sí, la información resumida consta de
los valores mínimos y máximos . Los nombres de las clases de operador correspondientes contienen "minmax", por ejemplo, "date_minmax_ops". En realidad, estos son tipos de datos que estábamos considerando hasta ahora, y la mayoría de los tipos son de este tipo.
inclusivo
Los operadores de comparación se definen no para todos los tipos de datos. Por ejemplo, no están definidos para puntos (tipo "punto"), que representan las coordenadas geográficas de los aeropuertos. Por cierto, es por esta razón que las estadísticas no muestran la correlación para esta columna.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
Pero muchos de estos tipos nos permiten introducir un concepto de "área delimitadora", por ejemplo, un rectángulo delimitador para formas geométricas. Discutimos en detalle cómo el índice
GiST usa esta característica. De manera similar, BRIN también permite recopilar información de resumen en columnas que tienen tipos de datos como estos:
el área delimitadora para todos los valores dentro de un rango es solo el valor de resumen.
A diferencia de GiST, el valor de resumen para BRIN debe ser del mismo tipo que los valores que se indexan. Por lo tanto, no podemos construir el índice para los puntos, aunque está claro que las coordenadas podrían funcionar en BRIN: la longitud está estrechamente relacionada con la zona horaria. Afortunadamente, nada impide la creación del índice en una expresión después de transformar puntos en rectángulos degenerados. Al mismo tiempo, estableceremos el tamaño de un rango en una página, solo para mostrar el caso límite:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
El tamaño del índice es tan pequeño como 30 MB incluso en una situación tan extrema:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
Ahora podemos inventar consultas que limitan los aeropuertos por coordenadas. Por ejemplo:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
Sin embargo, el planificador se negará a usar nuestro índice.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Por qué Desactivemos el análisis secuencial y veamos qué sucede:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Parece que
se puede usar el índice, pero el planificador supone que el mapa de bits tendrá que construirse en toda la tabla (observe las "filas" del nodo Escaneo de índice de mapa de bits), y no es de extrañar que el planificador elija el escaneo secuencial en este caso El problema aquí es que para los tipos geométricos, PostgreSQL no recopila ninguna estadística, y el planificador tiene que ir a ciegas:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
Por desgracia Pero no hay quejas sobre el índice: funciona y funciona bien:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
La conclusión debe ser así: se necesita PostGIS si se requiere algo no trivial de la geometría. Puede recopilar estadísticas de todos modos.
Internos
La extensión convencional "pageinspect" nos permite mirar dentro del índice BRIN.
Primero, la metainformación nos indicará el tamaño de un rango y cuántas páginas se asignan para "revmap":
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
Las páginas 1-3 aquí están asignadas para "revmap", mientras que el resto contiene datos de resumen. Desde "revmap" podemos obtener referencias a datos de resumen para cada rango. Digamos que la información sobre el primer rango, que incorpora las primeras 128 páginas, se encuentra aquí:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
Y este es el resumen de datos en sí:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
Siguiente rango:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
Y así sucesivamente.
Para las clases de "inclusión", el campo "valor" mostrará algo como
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
El primer valor es el rectángulo de incrustación, y las letras "f" al final denotan la falta de elementos vacíos (el primero) y los valores que no se pueden fusionar (el segundo). En realidad, los únicos valores no fusionables son las direcciones "IPv4" e "IPv6" (tipo de datos "inet").
Propiedades
Recordando las consultas que
ya se han proporcionado .
Las siguientes son las propiedades del método de acceso:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
Los índices se pueden crear en varias columnas. En este caso, se recopilan sus propias estadísticas de resumen para cada columna, pero se almacenan juntas para cada rango. Por supuesto, este índice tiene sentido si el mismo tamaño de un rango es adecuado para todas las columnas.
Las siguientes propiedades de capa de índice están disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Evidentemente, solo se admite el escaneo de mapa de bits.
Sin embargo, la falta de agrupación puede parecer confusa. Aparentemente, dado que el índice BRIN es sensible al orden físico de las filas, sería lógico poder agrupar los datos de acuerdo con el índice. Pero esto no es así. Solo podemos crear un índice "regular" (árbol B o GiST, según el tipo de datos) y agruparlo de acuerdo con él. Por cierto, ¿desea agrupar una tabla supuestamente enorme teniendo en cuenta los bloqueos exclusivos, el tiempo de ejecución y el consumo de espacio en disco durante la reconstrucción?
Las siguientes son las propiedades de la capa de columna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
La única propiedad disponible es la capacidad de manipular NULL.
Sigue leyendo .