
Introduccion
En Shopify estábamos implementando Istio como una malla de servicios. En principio, todo vale, excepto por una cosa: es costoso .
Los puntos de referencia publicados para Istio dicen:
Con Istio 1.1, el proxy consume aproximadamente 0.6 vCPU (núcleos virtuales) por 1000 solicitudes por segundo.
Para la primera región en la malla de servicio (2 proxies en cada lado de la conexión), tendremos 1200 núcleos solo para proxies, a razón de un millón de solicitudes por segundo. Según la calculadora de costos de Google, obtienes alrededor de $ 40 / mes / núcleo por la configuración n1-standard-64 , es decir, solo esta región nos costará más de $ 50,000 por mes por 1 millón de solicitudes por segundo.
Ivan Sim ( Ivan Sim ) comparó claramente los retrasos en la malla del servicio el año pasado y prometió lo mismo para la memoria y el procesador, pero falló:
Aparentemente, values-istio-test.yaml aumentará seriamente las solicitudes de procesador. Si calculé todo correctamente, necesitará unos 24 núcleos de procesador para el panel de control y 0.5 CPU para cada proxy. No tengo mucho. Repetiré las pruebas cuando se me asignen más recursos.
Quería ver por mí mismo cómo el rendimiento de Istio es similar a otra malla de servicios de código abierto: Linkerd .
Servicio de instalación de mallas
Lo primero que instalé en el clúster SuperGloo fue :
$ supergloo init installing supergloo version 0.3.12 using chart uri https://storage.googleapis.com/supergloo-helm/charts/supergloo-0.3.12.tgz configmap/sidecar-injection-resources created serviceaccount/supergloo created serviceaccount/discovery created serviceaccount/mesh-discovery created clusterrole.rbac.authorization.k8s.io/discovery created clusterrole.rbac.authorization.k8s.io/mesh-discovery created clusterrolebinding.rbac.authorization.k8s.io/supergloo-role-binding created clusterrolebinding.rbac.authorization.k8s.io/discovery-role-binding created clusterrolebinding.rbac.authorization.k8s.io/mesh-discovery-role-binding created deployment.extensions/supergloo created deployment.extensions/discovery created deployment.extensions/mesh-discovery created install successful!
Usé SuperGloo porque simplifica enormemente el arranque de la malla de servicio. No tenía casi nada que hacer. En producción, no usamos SuperGloo, pero es ideal para una tarea similar. Tuve que aplicar solo un par de comandos a cada malla de servicio. Usé dos grupos para el aislamiento, uno para Istio y Linkerd.
El experimento se realizó en Google Kubernetes Engine. Utilicé Kubernetes 1.12.7-gke.7 y el 1.12.7-gke.7 n1-standard-4 con escalado automático de nodos (mínimo 4, máximo 16).
Luego instalé ambas mallas de servicio desde la línea de comando.
Linkerd primero:
$ supergloo install linkerd --name linkerd +---------+--------------+---------+---------------------------+ | INSTALL | TYPE | STATUS | DETAILS | +---------+--------------+---------+---------------------------+ | linkerd | Linkerd Mesh | Pending | enabled: true | | | | | version: stable-2.3.0 | | | | | namespace: linkerd | | | | | mtls enabled: true | | | | | auto inject enabled: true | +---------+--------------+---------+---------------------------+
Entonces Istio:
$ supergloo install istio --name istio --installation-namespace istio-system --mtls=true --auto-inject=true +---------+------------+---------+---------------------------+ | INSTALL | TYPE | STATUS | DETAILS | +---------+------------+---------+---------------------------+ | istio | Istio Mesh | Pending | enabled: true | | | | | version: 1.0.6 | | | | | namespace: istio-system | | | | | mtls enabled: true | | | | | auto inject enabled: true | | | | | grafana enabled: true | | | | | prometheus enabled: true | | | | | jaeger enabled: true | +---------+------------+---------+---------------------------+
Crash-loop tomó varios minutos, y luego los paneles de control se estabilizaron.
(Nota: SuperGloo actualmente solo admite Istio 1.0.x. Repetí el experimento con Istio 1.1.3, pero no noté ninguna diferencia notable).
Configurar la implementación automática de Istio
Para que Istio instale el Enviado lateral, utilizamos el inyector MutatingAdmissionWebhook - MutatingAdmissionWebhook . No hablaremos de él en este artículo. Solo puedo decir que este es un controlador que monitorea el acceso de todos los nuevos pods y agrega dinámicamente un sidecar e initContainer, que es responsable de las tareas de iptables .
En Shopify escribimos nuestro controlador de acceso para implementar el sidecar, pero en este punto de referencia tomé el controlador que viene con Istio. El controlador inyecta sidecar de manera predeterminada cuando hay un acceso directo istio-injection: enabled en el espacio de nombres:
$ kubectl label namespace irs-client-dev istio-injection=enabled namespace/irs-client-dev labeled $ kubectl label namespace irs-server-dev istio-injection=enabled namespace/irs-server-dev labeled
Configurar la implementación automática de Linkerd
Para configurar la implementación de los sidecar s de Linkerd, utilizamos anotaciones (las agregué manualmente a través de kubectl edit ):
metadata: annotations: linkerd.io/inject: enabled
$ k edit ns irs-server-dev namespace/irs-server-dev edited $ k get ns irs-server-dev -o yaml apiVersion: v1 kind: Namespace metadata: annotations: linkerd.io/inject: enabled name: irs-server-dev spec: finalizers: - kubernetes status: phase: Active
Simulador de tolerancia a fallos Istio
Creamos el simulador de tolerancia a fallas Istio para experimentar con el tráfico exclusivo de Shopify. Necesitábamos una herramienta para crear una topología arbitraria que representara una cierta parte del gráfico de nuestro servicio con ajuste dinámico para simular cargas de trabajo específicas.
La infraestructura de Shopify está bajo una gran carga durante las ventas flash. Al mismo tiempo, Shopify recomienda que los vendedores realicen tales ventas con mayor frecuencia . Los grandes clientes a veces advierten sobre una venta flash planificada. Otros los gastan inesperadamente para nosotros en cualquier momento del día o de la noche.
Queríamos que nuestro simulador de tolerancia a fallas modelara flujos de trabajo que coincidan con las topologías y las cargas de trabajo que han sobrecargado la infraestructura de Shopify en el pasado. El propósito principal de usar la malla de servicio es que necesitamos confiabilidad y tolerancia a fallas a nivel de red, y es importante para nosotros que la malla de servicio haga frente efectivamente a las cargas que anteriormente interrumpían la operación de los servicios.
El simulador de conmutación por error se basa en un nodo de trabajo que actúa como un nodo de malla de servicio. El nodo de trabajo puede configurarse estáticamente al inicio o dinámicamente a través de la API REST. Utilizamos la optimización dinámica de los nodos de trabajo para crear flujos de trabajo en forma de pruebas de regresión.
Aquí hay un ejemplo de tal proceso:
- Iniciamos 10 servidores como un servicio de
bar , que devuelve una respuesta 200/OK después de 100 ms. - Iniciamos 10 clientes, cada uno envía 100 solicitudes por segundo a la
bar . - Cada 10 segundos eliminamos 1 servidor, monitoreamos los errores
5xx en el cliente.
Al final del flujo de trabajo, estudiamos los registros y las métricas y verificamos si la prueba pasa. Así es como aprendemos sobre el rendimiento de nuestra malla de servicios y realizamos una prueba de regresión para probar nuestras suposiciones sobre la tolerancia a fallas.
(Nota: Estamos considerando abrir el código fuente para el simulador de tolerancia a fallas Istio, pero aún no estamos listos para ello).
Simulador de tolerancia a fallas Istio para benchmark de malla de servicio
Configuramos varios nodos de trabajo del simulador:
irs-client-loadgen : 3 réplicas que envían 100 solicitudes por segundo a irs-client .irs-client : 3 réplicas que reciben la solicitud esperan 100 ms y redirigen la solicitud al irs-server .irs-server : 3 réplicas que devuelven 200/OK después de 100 ms.
Con esta configuración, podemos medir un flujo de tráfico estable entre 9 puntos finales. Los sidecar en irs-client-loadgen y irs-client-loadgen irs-server reciben 100 solicitudes por segundo, e irs-client - 200 (entrantes y salientes).
Hacemos un seguimiento del uso de recursos a través de DataDog porque no tenemos un clúster de Prometheus.
Resultados
Paneles de control
Primero, examinamos el consumo de CPU.

Panel de control Linkerd ~ 22M
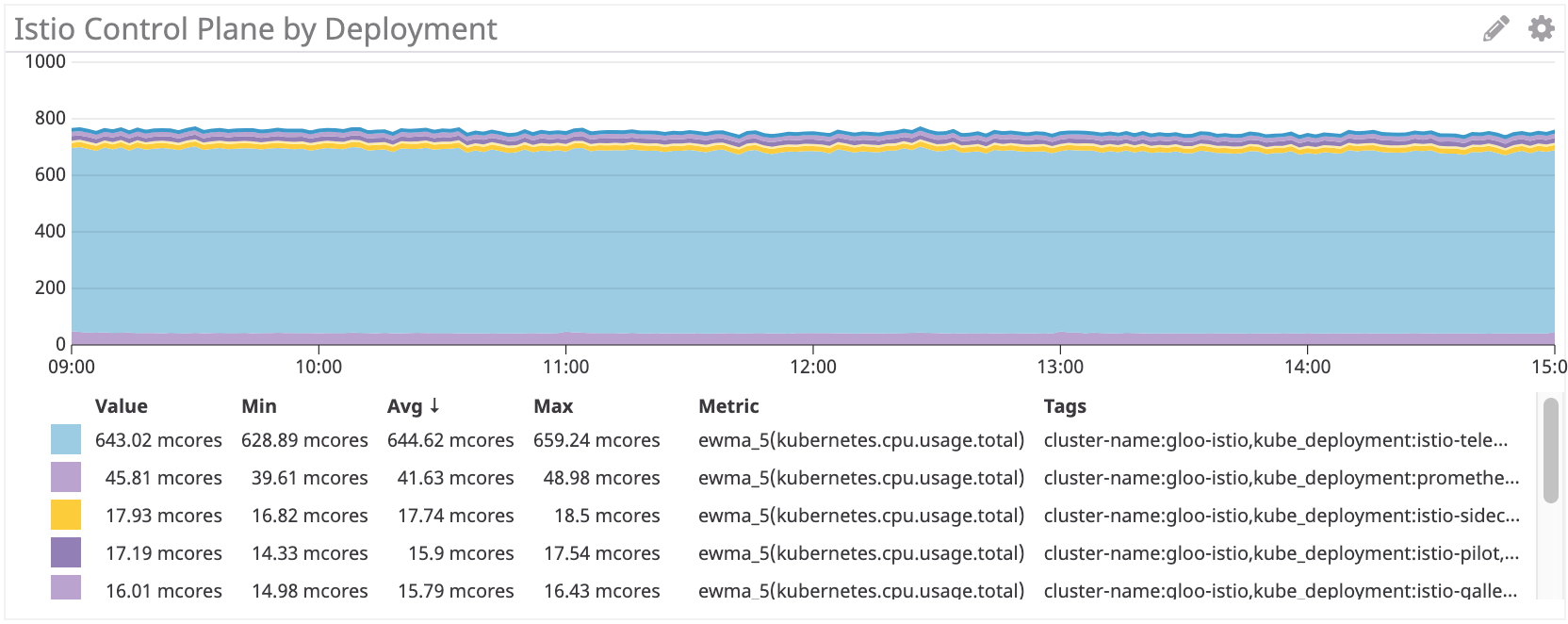
Panel de control Istio: ~ 750 millones de núcleos
El panel de control de Istio utiliza aproximadamente 35 veces más recursos de procesador que Linkerd. Por supuesto, todo está configurado de forma predeterminada, y la istio-telemetría consume muchos recursos del procesador (puede deshabilitarlo abandonando algunas funciones). Si elimina este componente, sigue siendo más de 100 multinúcleo, es decir, 4 veces más que Linkerd.
Proxy sidecar
Luego verificamos el uso de proxies. Debe haber una dependencia lineal en el número de solicitudes, pero para cada sidecar hay algunos gastos generales que afectan la curva.

Linkerd: ~ 100Mnuclear para irs-client, ~ 50Mnuclear para irs-client-loadgen
Los resultados parecen lógicos, porque el proxy del cliente recibe el doble de tráfico que el proxy loadgen: por cada solicitud saliente de loadgen, el cliente tiene un entrante y uno saliente.
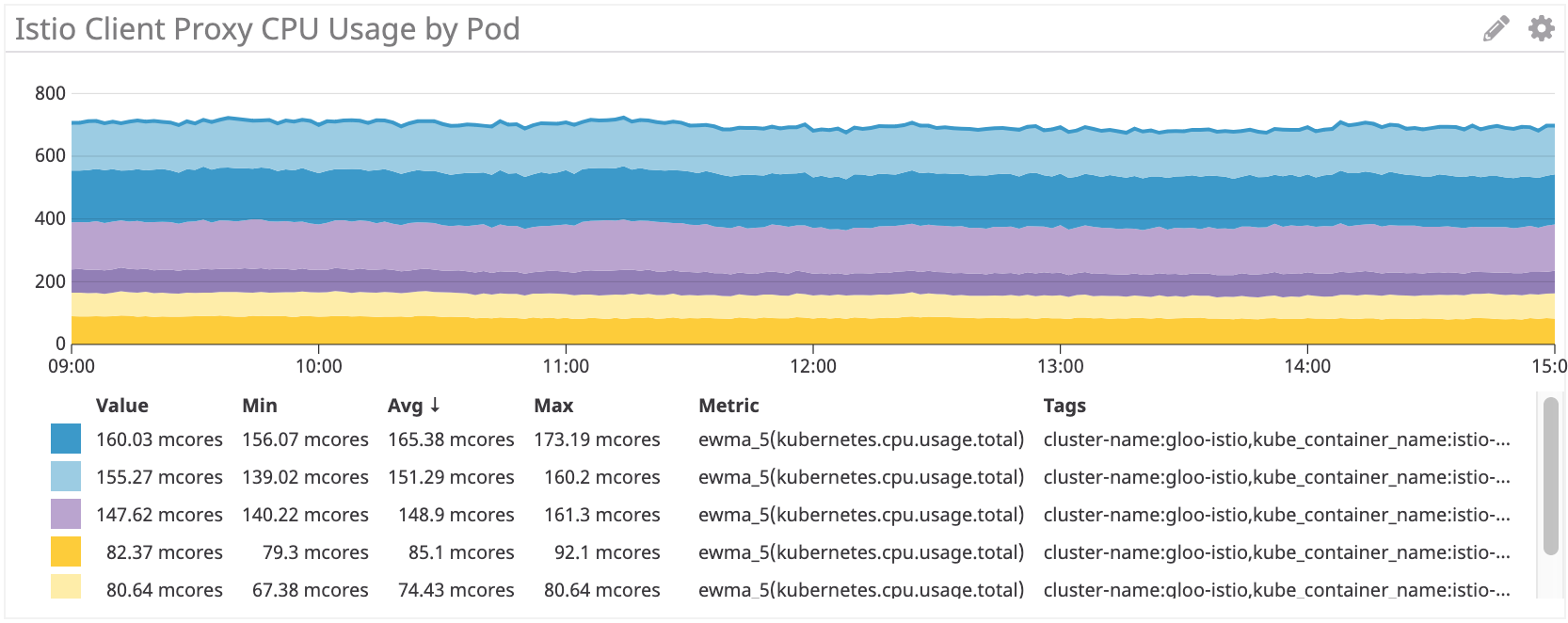
Istio / Envoy: ~ 155 millonarios para irs-client, ~ 75 millonarios para irs-client-loadgen
Vemos resultados similares para el sidecar Istio.
Pero, en general, los servidores proxy Istio / Envoy consumen aproximadamente un 50% más de recursos de procesador que Linkerd.
Vemos el mismo esquema en el lado del servidor:
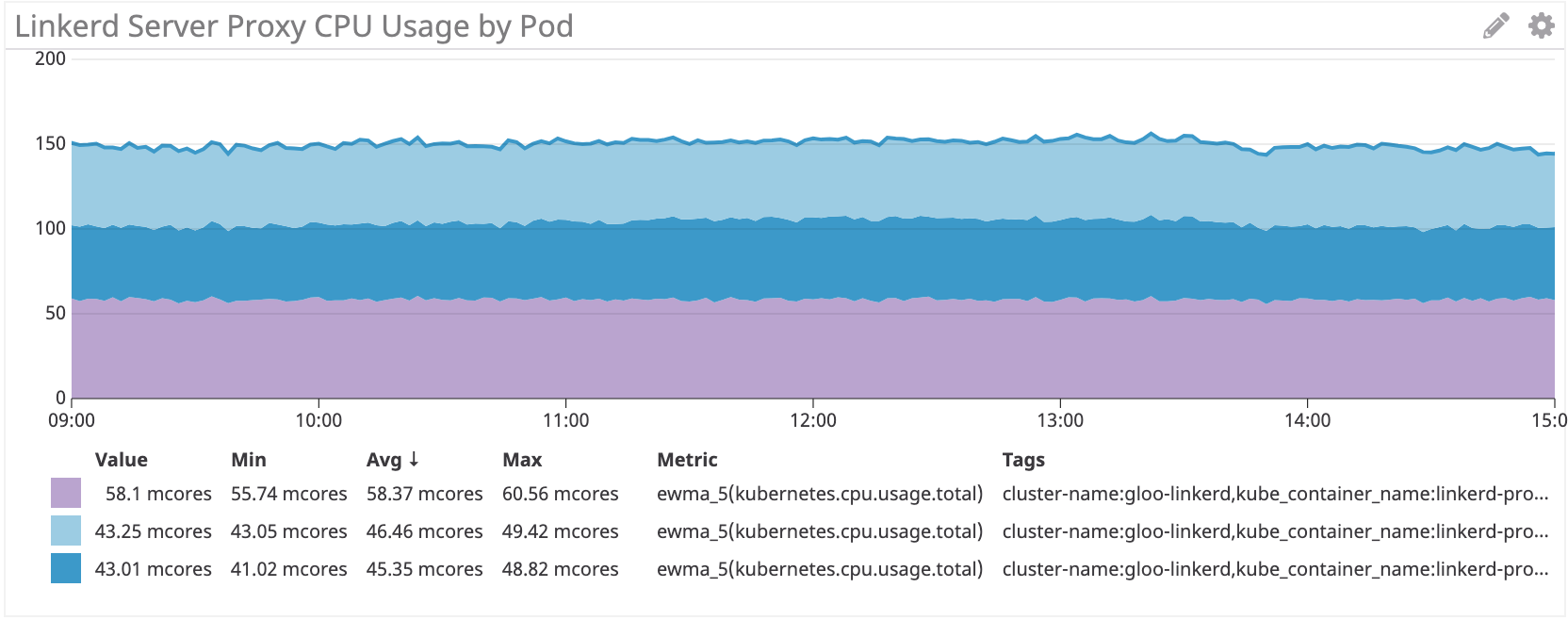
Linkerd: ~ 50 multinúcleo para irs-server
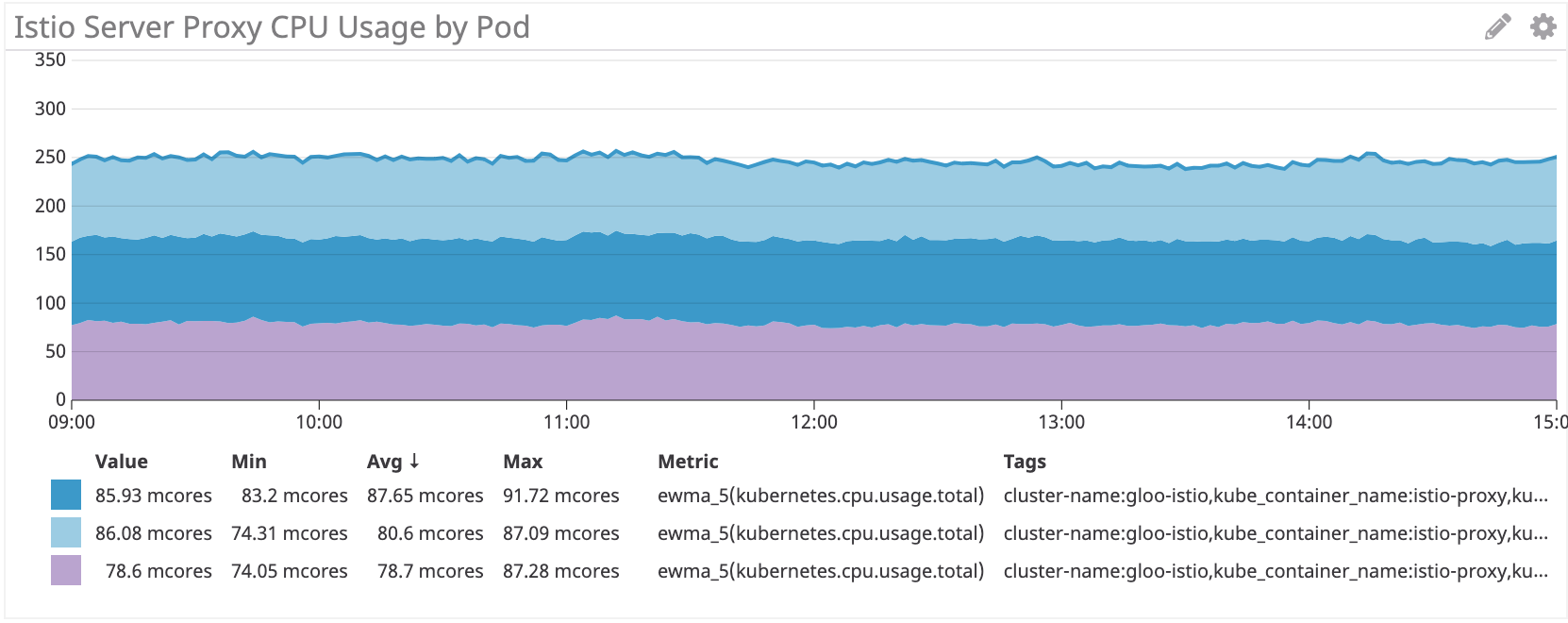
Istio / Envoy: ~ 80 multinúcleo para irs-server
En el lado del servidor, el sidecar Istio / Envoy consume aproximadamente un 60% más de recursos de procesador que Linkerd.
Conclusión
El proxy Istio Envoy consume más del 50% de CPU que Linkerd en nuestra carga de trabajo simulada. El panel de control de Linkerd consume muchos menos recursos que Istio, especialmente para los componentes principales.
Todavía estamos pensando en cómo reducir estos costos. Si tienes alguna idea, ¡comparte!