
La tecnología de Harry Potter ha sobrevivido hasta nuestros días. Ahora, para crear un video completo de una persona, solo una de sus fotos o fotografías es suficiente. Investigadores de aprendizaje automático de Skolkovo y el Centro de IA de Samsung en Moscú publicaron su trabajo para crear dicho sistema, junto con una serie de videos de celebridades y objetos de arte que han recibido una nueva vida.

El texto del trabajo científico se puede leer aquí . Todo es bastante interesante allí, con muchas fórmulas, pero el significado es simple: su sistema está guiado por "puntos de referencia", vistas de la cara, como una nariz, dos ojos, dos cejas y la línea de la barbilla. Entonces ella instantáneamente capta lo que es una persona. Y luego puede transferir todo lo demás (color, textura de la cara, bigote, rastrojo, etc.) al video de cualquier otra persona. Adaptando la vieja cara a nuevas situaciones.
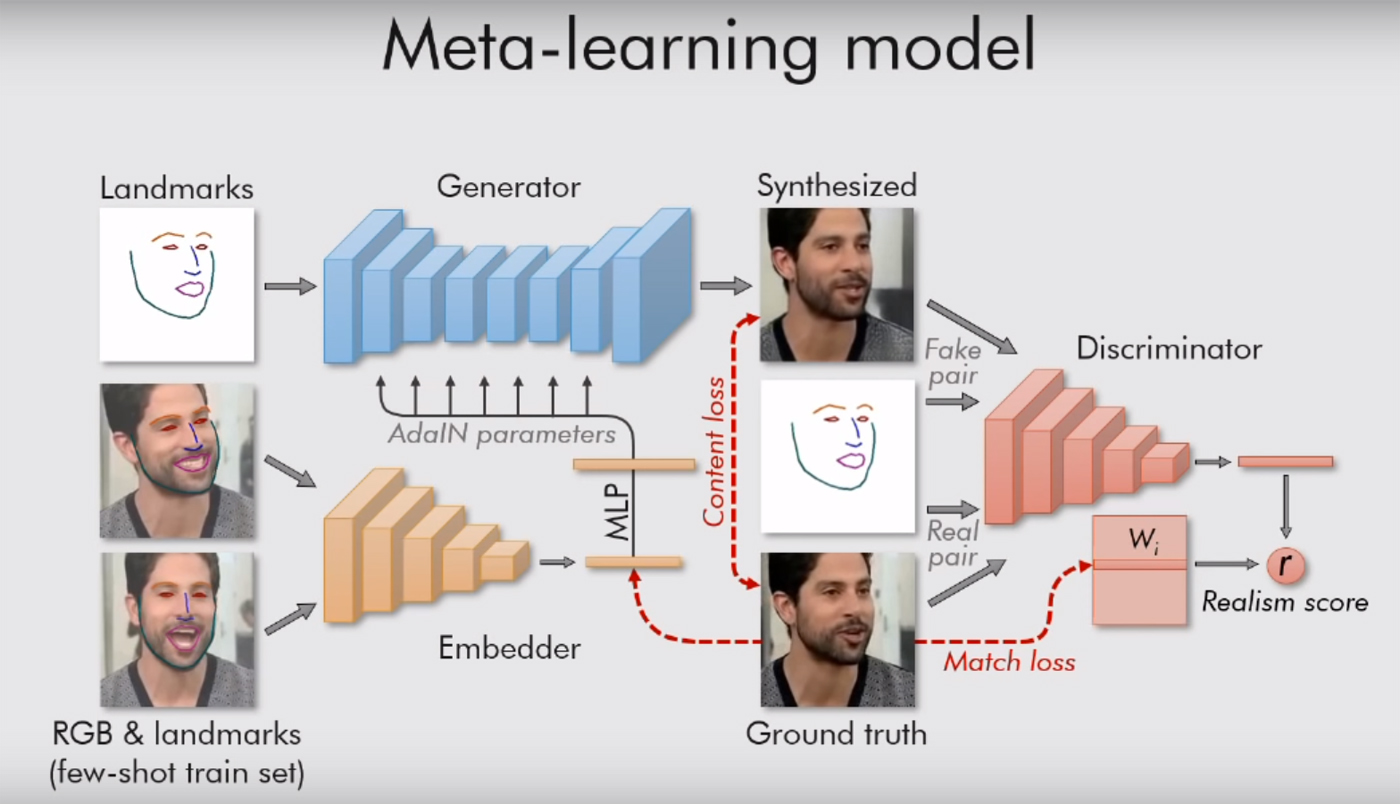
Por supuesto, esto solo funciona en retratos. La modelo solo necesita una persona, con la cara vuelta hacia nosotros, para que al menos pueda ver ambos ojos. Entonces el sistema puede hacer cualquier cosa con él, transmitirle cualquier expresión facial. Es suficiente para darle un video adecuado (con otra persona con la cabeza aproximadamente en la misma posición).
Anteriormente, AI ya había aprendido a hacer diphakes, y los usuarios de Internet se burlaban de las celebridades al insertar sus caras en la pornografía y hacer memes con Nicholas Cage. Pero para esto, tuvieron que entrenar los algoritmos en megabytes (o mejor, gigabytes) de datos, para encontrar tantas imágenes y videos como sea posible con las caras de las celebridades para producir un resultado más o menos decente. El creador del propio Deepfakes dijo que toma 8-12 horas compilar un video corto. El nuevo sistema genera el resultado al instante, y en la entrada solo necesita una imagen.
Con el sistema anterior, nunca podríamos mirar a la Mona Lisa viva, solo tenemos un ángulo. Ahora, con algoritmos de evaluación comparativa, esto se está volviendo posible. El ideal no se logra, pero algo ya está cerca.

Los investigadores de Moscú también usan una red generativa-adversaria. Dos modelos del algoritmo están luchando entre sí. Cada uno intenta engañar al oponente y demostrarle que el video que ella crea es real. De esta manera, se logra un cierto nivel de realismo: una imagen de un rostro humano no se libera "a la luz" si el modelo crítico no está más del 90% seguro de su autenticidad. Como dicen los autores en su trabajo, decenas de millones de parámetros están regulados en las imágenes, pero debido a dicho sistema, el trabajo hierve muy rápidamente.

Si hay varias imágenes, el resultado mejora. Nuevamente, la forma más fácil es trabajar con celebridades que ya están tomadas desde todos los ángulos posibles. Para lograr el "realismo ideal" se necesitan 32 disparos. En este caso, las fotos de IA generadas en baja resolución serán indistinguibles de las fotos humanas reales. Las personas sin entrenamiento en esta etapa ya no pueden identificar una falsificación, tal vez las posibilidades permanezcan con expertos o con familiares cercanos de lo "experimental" de todas estas imágenes.
Si solo hay una foto o imagen, el resultado no siempre es el mejor. Puede ver artefactos en el video cuando la cabeza está en movimiento sin ningún problema. Los propios investigadores dicen que su punto más débil es la mirada. El modelo basado en los puntos de referencia de la cara aún no siempre comprende cómo y dónde debe mirar una persona.
