
Hola En este artículo, quiero explicar, en términos simples, cómo aparece el
robo en las máquinas virtuales y contarle sobre algunos de los artefactos menos que obvios que encontramos durante la investigación sobre el tema en el que estuve involucrado como CTO del
Correo. plataforma de
soluciones Cloud com . La plataforma ejecuta KVM.
El tiempo de robo de la CPU es el tiempo durante el cual una VM no recibe los recursos necesarios para operar. Este tiempo solo se puede calcular en un SO huésped en entornos de virtualización. No está muy claro dónde se pierden los recursos asignados, como en situaciones de la vida real. Sin embargo, decidimos resolverlo e incluso realizamos una serie de pruebas para hacerlo. Eso no quiere decir que sepamos todo sobre el
robo, pero hay algunas cosas fascinantes que nos gustaría compartir con usted.
1. ¿Qué es robar ?
Steal es una métrica que indica una falta de tiempo de CPU para los procesos de VM. Como se describe en el
parche del kernel KVM ,
robar es el tiempo que un hipervisor pasa ejecutando otros procesos en un sistema operativo host, mientras que el proceso VM está en una cola de ejecución. En otras palabras, el
robo se calcula como la diferencia entre el momento en que un proceso está listo para ejecutarse y el momento en que el tiempo de CPU se asigna al proceso.
El kernel VM obtiene la métrica de
robo del hipervisor. El hipervisor no especifica qué procesos está ejecutando. Simplemente dice: "Estoy ocupado y no puedo asignarle tiempo". En un KVM, el cálculo de
robo se admite en
parches . Hay dos puntos principales con respecto a esto:
- Una VM aprende sobre el robo del hipervisor. Esto significa que, en términos de pérdidas, el robo es una medida indirecta que puede distorsionarse de varias maneras.
- El hipervisor no comparte con la VM información sobre con qué está ocupado. El punto más crucial es que no le asigna tiempo. La VM en sí misma, por lo tanto, no puede detectar distorsiones en la métrica de robo , lo que podría estimarse por la naturaleza de los procesos competitivos.
2. ¿Qué afecta al robo ?
2.1. Cálculo de robo
Esencialmente, el
robo se calcula más o menos de la misma manera que el tiempo de utilización de la CPU. No hay mucha información sobre cómo se calcula la utilización. Eso es probablemente porque la mayoría de los profesionales piensan que es obvio. Sin embargo, hay algunas trampas. El proceso se describe en
un artículo de Brendann Gregg . Analiza una gran cantidad de matices sobre cómo calcular la utilización y los escenarios en los que el cálculo será incorrecto:
- CPU sobrecalentamiento y estrangulamiento.
- Activar / desactivar Turbo Boost, lo que resulta en un cambio en la velocidad del reloj de la CPU.
- El cambio de intervalo de tiempo que ocurre cuando se utilizan tecnologías de ahorro de energía de la CPU, por ejemplo, SpeedStep.
- Problemas relacionados con el cálculo de promedios: medir la utilización durante un minuto al 80% de potencia podría ocultar un aumento del 100% a corto plazo.
- Un spinlock que da como resultado un escenario en el que se utiliza el procesador, pero el proceso del usuario no progresa. Como resultado, la utilización calculada de la CPU será del 100%, pero el proceso no consumirá realmente el tiempo de la CPU.
No he encontrado ningún artículo que describa tales cálculos de
robo (si conoce alguno, por favor compártalos en la sección de comentarios). Como puede ver en el código fuente, el mecanismo de cálculo es el mismo que para la utilización. La única diferencia es que se agrega otro contador específicamente para el proceso KVM (proceso VM), que calcula cuánto tiempo el proceso KVM ha estado esperando el tiempo de CPU. El contador toma datos de la CPU de su especificación y comprueba si el proceso de VM está utilizando todos sus ticks. Si se utilizan todos los ticks, entonces la CPU solo estaba ocupada con el proceso de VM. De lo contrario, sabemos que la CPU estaba haciendo otra cosa y aparece
robar .
El proceso por el cual se calcula el
robo está sujeto a los mismos problemas que el cálculo regular de la utilización. Estos problemas no son tan comunes, pero pueden parecer bastante confusos.
2.2. Tipos de virtualización KVM
En general, hay tres tipos de virtualización, y todos son compatibles con un KVM. El mecanismo por el cual ocurre el
robo puede depender del tipo de virtualización.
Traducción En este caso, el sistema operativo VM funcionará con dispositivos de hipervisor físico de la siguiente manera:
- El SO invitado envía un comando a su dispositivo invitado.
- El controlador del dispositivo invitado acepta el comando, crea una solicitud de dispositivo BIOS y envía el comando al hipervisor.
- El proceso del hipervisor traduce el comando en un comando de dispositivo físico, lo que lo hace más seguro, entre otras cosas.
- El controlador del dispositivo físico acepta el comando modificado y lo reenvía al propio dispositivo físico.
- Los resultados de ejecución del comando vuelven siguiendo la misma ruta.
La ventaja de la traducción es que nos permite emular cualquier dispositivo y no requiere una preparación especial del núcleo del sistema operativo. Pero esto viene a expensas del rendimiento.
Virtualización de hardware. En este caso, un dispositivo recibe comandos del sistema operativo en el nivel de hardware. Este es el mejor método más rápido y en general. Desafortunadamente, no todos los dispositivos físicos, hipervisores y sistemas operativos invitados lo admiten. Por ahora, los principales dispositivos que admiten la virtualización de hardware son las CPU.
Paravirtualización. La opción más común para la virtualización de dispositivos en un KVM y el tipo de virtualización más extendido para los SO invitados. Su característica principal es que funciona con algunos subsistemas de hipervisor (por ejemplo, red o pila de unidades) y asigna páginas de memoria usando una API de hipervisor sin traducir comandos de bajo nivel. La desventaja de este método de virtualización es la necesidad de modificar el kernel del sistema operativo invitado para permitir la interacción con el hipervisor utilizando la misma API. La solución más común a este problema es instalar controladores especiales en el sistema operativo invitado. En un KVM, esta API se llama
virtio API .
Cuando se usa la paravirtualización, la ruta al dispositivo físico es mucho más corta que en los casos en que se usa la traducción, porque los comandos se envían directamente desde la VM al proceso del hipervisor en el host. Esto acelera la ejecución de todas las instrucciones dentro de la VM. En un KVM, una API virtio es responsable de esto. Solo funciona para algunos dispositivos como adaptadores de red y unidad. Es por eso que los controladores virtio están instalados en las máquinas virtuales.
La otra cara de dicha aceleración es que no todos los procesos ejecutados en una VM permanecen dentro de la VM. Esto da como resultado una serie de efectos, que pueden causar
robo . Si desea obtener más información, comience con
una API para E / S virtual: virtio .
2.3. Programación justa
Una VM en un hipervisor es, de hecho, un proceso regular, que está sujeto a las leyes de programación (distribución de recursos entre procesos) en un kernel de Linux. Echemos un vistazo más de cerca a esto.
Linux usa el llamado CFS, Completely Fair Scheduler, que se convirtió en el predeterminado con el kernel 2.6.23. Para conocer este algoritmo, lea Linux Kernel Architecture o el código fuente. La esencia de CFS radica en la distribución del tiempo de CPU entre procesos, dependiendo de su tiempo de ejecución. Cuanto más tiempo de CPU requiere un proceso, menos tiempo de CPU obtiene. Esto garantiza la ejecución "justa" de todos los procesos y ayuda a evitar que un proceso ocupe todos los procesadores, todo el tiempo y permite que otros procesos también se ejecuten.
Algunas veces este paradigma da como resultado artefactos interesantes. Los usuarios de Linux de larga data sin duda recordarán cómo un editor de texto normal en el escritorio se congelaría al ejecutar aplicaciones de uso intensivo de recursos como un compilador. Esto sucedió porque las tareas con pocos recursos, como las aplicaciones de escritorio, competían con tareas que usaban muchos recursos, como un compilador. CFS considera que esto es injusto, por lo que detiene el editor de texto de vez en cuando y permite que la CPU procese las tareas del compilador. Esto se solucionó utilizando el mecanismo
sched_autogroup ; Sin embargo, hay muchas otras peculiaridades de la distribución del tiempo de la CPU. Este artículo no trata realmente sobre qué tan malo es el SFC. Es más bien un intento de llamar la atención sobre el hecho de que la distribución "justa" del tiempo de CPU no es la tarea más trivial.
Otro aspecto importante de un planificador es la preferencia. Esto es necesario para liberar a la CPU de cualquier proceso excesivo y permitir que otros también trabajen. Esto se llama
cambio de contexto . Se retiene todo el contexto de la tarea: estado de la pila, registros, etc., después de lo cual el proceso se deja esperar y se reemplaza por otro proceso. Esta es una operación costosa para un sistema operativo. Raramente se usa, pero en realidad no está nada mal. El cambio de contexto frecuente puede ser un indicador de un problema del sistema operativo, pero generalmente ocurre continuamente y no es un signo de ningún problema en particular.
Este largo discurso fue necesario para explicar un hecho: en un planificador de Linux justo, cuantos más recursos de CPU consume el proceso, más rápido se detendrá para permitir que otros procesos funcionen. Si esto es correcto o no es una pregunta compleja, y la solución es diferente dependiendo de la carga. Hasta hace poco, el programador de Windows priorizaba las aplicaciones de escritorio, lo que resultaba en procesos en segundo plano más lentos. En Sun Solaris había cinco clases de planificador diferentes. Cuando se introdujo la virtualización, agregaron otro, el
programador de reparto justo , porque los demás no se ejecutaban correctamente con la virtualización de Zonas de Solaris. Para profundizar en esto, recomiendo comenzar con
Solaris Internals: Solaris 10 y OpenSolaris Kernel Architecture o
Comprender el kernel de Linux .
2.4. ¿Cómo podemos monitorear el robo ?
Al igual que cualquier otra métrica de CPU, es fácil monitorear el
robo dentro de una VM. Puede usar cualquier herramienta de medición métrica de CPU. Lo principal es que la VM debe estar en Linux. Por alguna razón, Windows no proporciona dicha información al usuario. :(
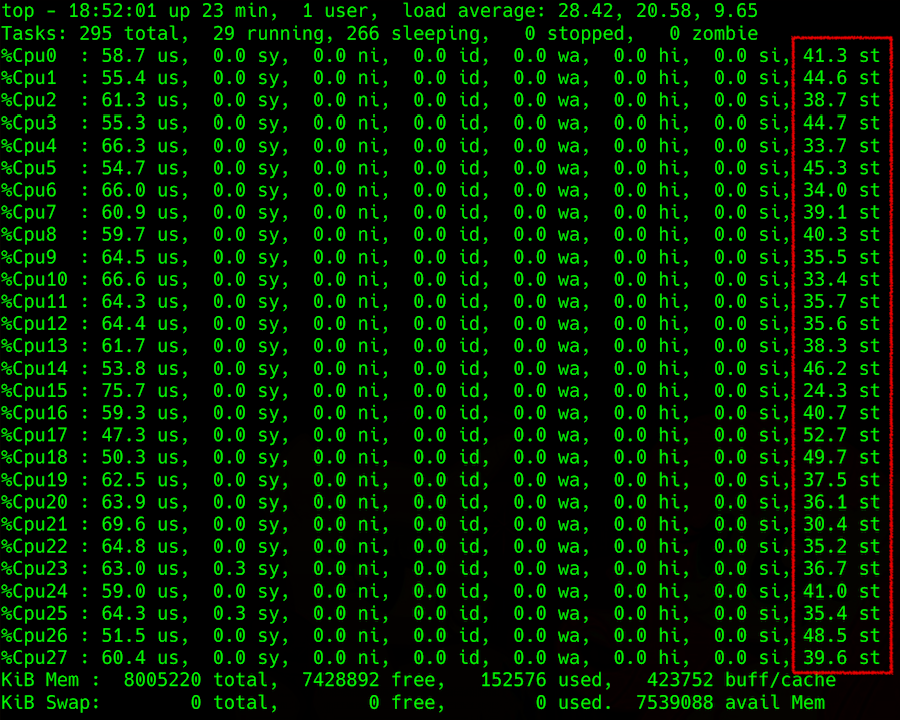 salida superior: especificación de carga de CPU con robo en la columna derecha
salida superior: especificación de carga de CPU con robo en la columna derechaLas cosas se complican cuando se trata de obtener esta información de un hipervisor. Puede intentar pronosticar el
robo en una máquina host, utilizando Load Average (LA), por ejemplo. Este es el valor promedio de la cantidad de procesos en la cola de ejecución. El método de cálculo para este parámetro no es simple, pero en general, si un LA que se ha estandarizado de acuerdo con el número de subprocesos de la CPU es mayor que 1, significa que el servidor Linux está sobrecargado.
Entonces, ¿qué están esperando todos estos procesos? Obviamente, la CPU. Sin embargo, esta respuesta no es del todo precisa, porque a veces la CPU es libre y la LA es demasiado alta. Recuerde
que NFS cae y LA aumenta al mismo tiempo . Una situación similar podría ocurrir con la unidad y otros dispositivos de entrada / salida. De hecho, los procesos pueden estar esperando el final de un bloqueo: físico (relacionado con dispositivos de entrada / salida) o lógico (un objeto mutex, por ejemplo). Lo mismo es cierto para bloqueos a nivel de hardware (por ejemplo, respuesta de disco) o bloqueos a nivel lógico (llamados "primitivas de bloqueo", que incluyen una serie de entidades, mutex adaptable y spin, semáforos, variables de condición, bloqueos rw, ipc locks ...).
Otra característica de LA es que se calcula como un valor promedio dentro del sistema operativo. Por ejemplo, si 100 procesos compiten por un archivo, el LA es 50. Este gran número podría hacer que parezca que es malo para el sistema operativo. Sin embargo, para un código mal escrito, esto puede ser normal. Solo ese código específico sería malo, y el resto del sistema operativo podría estar bien.
Debido a este promedio (durante menos de un minuto), determinar cualquier cosa usando un LA no es la mejor idea, ya que puede producir resultados extremadamente ambiguos en algunos casos. Si intenta obtener más información al respecto, verá que Wikipedia y otros recursos disponibles solo describen los casos más simples, y el proceso no se describe en detalle. Si está interesado en esto, visite
Brendann Gregg y siga los enlaces.
3. Efectos especiales
Ahora veamos los principales casos de
robo que encontramos. Permítanme explicar cómo resultan de lo anterior y cómo se correlacionan con las métricas del hipervisor.
Sobreutilización El caso más simple y más común: el hipervisor se está sobreutilizando. De hecho, con una gran cantidad de máquinas virtuales que se ejecutan y consumen muchos recursos de la CPU, la competencia es alta y la utilización según LA es mayor que 1 (estandarizada según los hilos de la CPU). Todo se retrasa dentro de todas las máquinas virtuales.
El robo enviado desde el hipervisor también crece. Tienes que redistribuir la carga o apagar algo. En general, todo esto es lógico y directo.
Paravirtualización frente a instancias individuales. Solo hay una VM en un hipervisor. La VM consume una pequeña parte, pero proporciona una alta carga de entrada / salida, por ejemplo, para una unidad. Inesperadamente, aparece un pequeño
robo de menos del 10% (como muestran algunas de las pruebas que realizamos).
Este es un caso curioso. Aquí, el
robo aparece debido a bloqueos en el nivel de los dispositivos paravirtualizados. Dentro de la VM, se crea un punto de interrupción. El controlador lo procesa y va al hipervisor. Debido al procesamiento del punto de interrupción en el hipervisor, la VM lo ve como una solicitud enviada. Está listo para ejecutarse y espera a la CPU, pero no recibe tiempo de CPU. El VM piensa que el tiempo ha sido robado.
Esto sucede cuando se envía el búfer. Va al espacio del kernel del hipervisor y lo esperamos. Desde el punto de vista de la VM, debería regresar de inmediato. Por lo tanto, de acuerdo con nuestro algoritmo de cálculo de
robo , esta vez se considera robado. Es probable que otros mecanismos puedan estar involucrados en esto (por ejemplo, el procesamiento de otras
llamadas del sistema ), pero no deberían diferir en ningún grado significativo.
Programador frente a máquinas virtuales altamente cargadas. Cuando una VM sufre de
robo más que las otras, esto se conecta directamente con el planificador. Cuanto mayor sea la carga que un proceso pone en una CPU, más rápido lo lanzará un planificador, para permitir que otros procesos funcionen. Si la VM consume poco, casi no experimentará
robo. Su proceso acaba de estar sentado y esperando, y se le debe dar más tiempo. Si la VM pone una carga máxima en todos los núcleos, el proceso se descarta con más frecuencia y se le otorga menos tiempo a la VM.
Es aún peor cuando los procesos dentro de la VM intentan obtener más CPU, porque no pueden procesar los datos. Luego, el sistema operativo en el hipervisor proporcionará menos tiempo de CPU debido a la optimización justa. Esto procesa bolas de nieve y
roba oleadas a gran altura, mientras que otras máquinas virtuales pueden ni siquiera notarlo. Cuantos más núcleos haya, peor es para el desafortunado VM. En resumen, las máquinas virtuales altamente cargadas con muchos núcleos son las que más sufren.
Baja LA pero el
robo está presente. Si la LA es de aproximadamente 0.7 (lo que significa que el hipervisor parece estar subcargado), pero hay
robo en algunas máquinas virtuales:
- Se aplica el ejemplo de paravirtualización mencionado anteriormente. La VM puede estar recibiendo métricas que indican robo , mientras que el hipervisor no tiene problemas. Según los resultados de nuestras pruebas, dicho robo no tiende a exceder el 10% y no tiene un impacto significativo en el rendimiento de la aplicación dentro de la VM.
- El parámetro LA se ha calculado incorrectamente. Más precisamente, se ha calculado correctamente en un momento específico, pero al promediar, es más bajo de lo que debería ser durante un minuto. Por ejemplo, si una VM (un tercio del hipervisor) consume todas las CPU durante 30 segundos, la LA por un minuto será 0.15. Cuatro de esas máquinas virtuales, trabajando al mismo tiempo, darán como resultado un valor de 0.6. Según el LA, no podría deducir que durante 30 segundos para cada uno de ellos, el robo fue casi del 25%.
- Nuevamente, esto sucedió debido al planificador, que decidió que alguien estaba "comiendo" demasiado y los hizo esperar. Mientras tanto, cambiará de contexto, procesará puntos de interrupción y atenderá otros asuntos importantes del sistema. Como resultado, algunas máquinas virtuales no experimentan problemas y otras sufren pérdidas de rendimiento significativas.
4. Otras distorsiones
Hay un millón de posibles razones para la distorsión de la asignación equitativa de tiempo de CPU en una VM. Por ejemplo, hyperthreading y NUMA agregan complejidad a los cálculos. Complican la elección del núcleo utilizado para ejecutar un proceso porque un planificador utiliza coeficientes; es decir, los pesos, que complican los cálculos aún más que esto al cambiar de contexto.
Hay distorsiones que surgen de tecnologías como Turbo Boost o su modo opuesto de ahorro de energía, que podrían aumentar o disminuir artificialmente la velocidad del núcleo de la CPU e incluso el intervalo de tiempo. Activar Turbo Boost para disminuir la productividad de un subproceso de CPU debido a un aumento del rendimiento en otro. En ese momento, la información sobre la velocidad actual del reloj de la CPU no se envía a la VM, que cree que alguien está robando su tiempo (por ejemplo, solicitó 2 GHz y obtuvo la mitad).
De hecho, puede haber muchas razones para la distorsión. Puede encontrar algo completamente diferente en cualquier sistema dado. Recomiendo comenzar con los libros vinculados anteriormente y obtener estadísticas del hipervisor utilizando herramientas como perf, sysdig, systemtap y
docenas de otras .
5. Conclusiones
- Puede aparecer algo de robo debido a la paravirtualización y esto puede considerarse normal. Las fuentes en línea dicen que este valor puede ser del 5-10%. Depende de la aplicación dentro de una VM y la carga que la VM pone en sus dispositivos físicos. Es importante prestar atención a cómo se sienten las aplicaciones dentro de una VM.
- La correlación entre la carga en el hipervisor y el robo dentro de una VM no siempre es segura. Ambos cálculos de robo pueden ser incorrectos en algunos casos y con diferentes cargas.
- El programador no favorece los procesos que solicitan muchos recursos. Intenta dar menos a los que piden más. Las grandes instancias son malas.
- Un pequeño robo también puede ser normal sin paravirtualización (teniendo en cuenta la carga dentro de la VM, las particularidades de las cargas de los vecinos, la distribución de la carga entre subprocesos y otros factores).
- Si desea calcular el robo en un sistema en particular, investigue las diversas posibilidades, recopile métricas, analícelas a fondo y piense en cómo distribuir la carga de manera justa. En cualquier caso, puede haber desviaciones, que deben verificarse mediante pruebas o verlas en un depurador de kernel.