Hola
Mi nombre es Marat Gayanov, quiero compartir con ustedes mi solución al problema del
concurso Best Reverser , para mostrar cómo hacer keygen para este caso.
Descripción
En esta competencia, los participantes reciben juegos ROM para Sega Mega Drive (
best_reverser_phd9_rom_v4.bin ).
Tarea: recoger una clave que junto con la dirección de correo electrónico del participante se reconozca como válida.
Entonces la solución ...
Las herramientas
Comprobación de longitud de clave
El programa no acepta todas las claves: debe completar todo el campo, estos son 16 caracteres. Si la clave es más corta, verá un mensaje: “¡Longitud incorrecta! Inténtalo de nuevo ... ".
Intentemos encontrar esta línea en el programa, para lo cual utilizaremos la búsqueda binaria (Alt-B). ¿Qué encontraremos?
Encontraremos no solo esto, sino también las otras líneas de servicio cercanas: “¡Clave incorrecta! Inténtalo de nuevo ... "y" ¡ERES EL MEJOR INVERSOR! ".
Configuré los
WRONG_LENGTH_MSG ,
YOU_ARE_THE_BEST_MSG y
WRONG_KEY_MSG por conveniencia.
0x0000FDFA leer la dirección
0x0000FDFA ; descubra quién trabaja con el mensaje "¡Longitud incorrecta! Inténtalo de nuevo ... ". Y ejecute el depurador (se detendrá varias veces antes de que se pueda ingresar la clave, solo presione F9 en cada parada). Ingrese su correo electrónico, clave
ABCD .
El depurador conduce a
0x00006FF0 tst.b (a1)+ :
No hay nada interesante en el bloque en sí. Es mucho más interesante quién transfiere el control aquí. Nos fijamos en la pila de llamadas:
Haga clic y
0x00001D2A jsr (sub_6FC0).l aquí - a la instrucción
0x00001D2A jsr (sub_6FC0).l :
Vemos que todos los mensajes posibles se encontraron en un solo lugar. Pero veamos a dónde se transfiere el control en el bloque
WRONG_KEY_LEN_CASE_1D1C . No estableceremos descansos, solo mueve el cursor sobre la flecha que va al bloque. La persona que llama se encuentra en
0x000017DE loc_17DE (que
CHECK_KEY_LEN nombre a
CHECK_KEY_LEN ):
Ponga un salto en la dirección
0x000017EC cmpi.b 0x20 (a0, d0.l) (la instrucción en este contexto busca ver si hay un carácter vacío al final de la matriz de caracteres clave), reinicie, vuelva a ingresar el correo y la clave
ABCD . El depurador se detiene y muestra que la clave ingresada se encuentra en la dirección
0x00FF01C7 (almacenada en ese momento en el registro
a0 ):
Este es un buen hallazgo, a través de él tomaremos todo en absoluto. Pero primero, marque los bytes de la clave por conveniencia:
Al desplazarnos hacia arriba desde este lugar, vemos que el correo se almacena junto a la clave:
Nos sumergimos más y más, y es hora de encontrar un criterio para la corrección de la clave. Más bien, la primera mitad de la llave.
Criterio para la corrección de la primera mitad de la clave
Cálculos preliminares
Es lógico suponer que inmediatamente después de verificar la longitud, seguirán otras operaciones con la tecla. Considere el bloqueo inmediatamente después del cheque:
Este bloque está en proceso preliminar. La función
get_hash_2b (en el original era
sub_1526 ) se llama dos veces. Primero, se le transmite la dirección del primer byte de la clave (el registro
a0 contiene la dirección
KEY_BYTE_0 ), la segunda vez, la quinta (
KEY_BYTE_4 ).
Llamé a la función así porque considera algo así como un hash de 2 bytes. Este es el nombre más comprensible que tomé.
No consideraré la función en sí, pero la escribiré de inmediato en python. Ella hace cosas simples, pero su descripción con capturas de pantalla ocupará mucho espacio.
Lo más importante que decir al respecto: la dirección de entrada se proporciona a la entrada, y se está trabajando en 4 bytes desde esta dirección. Es decir, enviaron el primer byte de la clave a la entrada, y la función funcionará con el 1,2,3,4th. Archivado en quinto lugar, la función funciona con el 5,6,7,8. En otras palabras, en este bloque hay cálculos sobre la primera mitad de la clave. El resultado se escribe en el registro
d0 .
Entonces la función
get_hash_2b :
Inmediatamente escriba una función de decodificación hash:
No se me ocurrió una mejor función de decodificación, y no es del todo correcta. Por lo tanto, lo comprobaré así (no ahora, sino mucho más tarde):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
Verifique el funcionamiento de
get_hash_2b . Estamos interesados en el estado del registro
d0 después de ejecutar la función. Ponemos descansos en
0x000017FE ,
0x00001808 , la clave que ingresamos
ABCDEFGHIJKLMNOP .
Los valores
0xABCD ,
0xEF01 se introducen en el registro
d0 . ¿Y qué dará
get_hash_2b ?
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
Verificación aprobada.
Luego se
xor eor.w d0, d5 , el resultado se ingresa en
d5 :
>>> hex(0xabcd ^ 0xef01) 0x44cc
La obtención de dicho hash es
0x44CC y consiste en cálculos preliminares. Además, todo se vuelve más complicado.
¿A dónde va el hash?
No podemos ir más allá si no sabemos cómo funciona el programa con el hash. Seguramente se mueve de
d5 a memoria, porque El registro es útil en otro lugar. Podemos encontrar dicho evento a través de la traza (viendo
d5 ), pero no manual, sino automático. El siguiente script ayudará:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
Permíteme recordarte que ahora estamos en el último descanso
0x00001808 eor.w d0, d5 . Pegue el script (
Shift-F2 ), haga clic en
RunEl script se detendrá en la instrucción
0x00001C94 move.b (a0, a1.l), d5 , pero en este momento
d5 ya se ha borrado. Sin embargo, vemos que el valor de
d5 mueve mediante la instrucción
0x00001C56 move.w d5,a6 : se escribe en la memoria en la dirección
0x00FF0D46 (2 bytes).
Recuerde: el hash se almacena en 0x00FF0D46 .0x00FF0D46-0x00FF0D47 las instrucciones que se leen de
0x00FF0D46-0x00FF0D47 (establecemos un descanso para la lectura). Atrapado 4 bloques:




¿Cómo elegir los correctos / correctos?
Regrese al principio:
Este bloque determina si el programa irá a
LOSER_CASE o a
WINNER_CASE :
Vemos que en el registro
d1 debe ser cero para ganar.
¿Dónde se establece el cero? Solo desplácese hacia arriba:
Si la
loc_1EEC se cumple en el bloque
loc_1EEC :
*(a6 + 0x24) == *(a6 + 0x22)
entonces obtenemos cero en
d5 .
Si ponemos un descanso en la instrucción
0x00001F16 beq.w loc_20EA , veremos que
a6 + 0x24 = 0x00FF0D6A y el valor
0x4840 se almacena allí. Y en
a6 + 0x22 = 0x00FF0D68 se almacena
a6 + 0x22 = 0x00FF0D68 .
Si ingresamos diferentes claves, correos, veremos que
0xCB4C - .
La primera mitad de la clave se aceptará solo si en 0x00FF0D6A también habrá 0xCB4C . Este es el criterio para la corrección de la primera mitad de la clave.Averiguamos qué bloques están escritos en
0x00FF0D6A : ponga un salto en el registro, ingrese el correo y la clave nuevamente.
Y encontraremos este bloque
loc_EAC (en realidad hay 3 de ellos, pero los dos primeros simplemente
0x00FF0D6A a cero
0x00FF0D6A ):
Este bloque pertenece a la función
sub_E3E .
A través de la pila de llamadas descubrimos que la función
sub_E3E llama en los bloques
loc_1F94 ,
loc_203E :
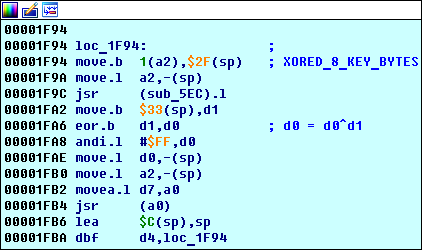

¿Recuerdas que encontramos 4 bloques antes?
loc_1F94 que vimos allí: este es el comienzo del algoritmo de procesamiento de clave principal.
Primer bucle importante loc_1F94
El hecho de que
loc_1F94 es un ciclo es visible desde el código: se ejecuta
d4 veces (consulte la instrucción
0x00001FBA d4,loc_1F94 ):
Qué buscar:
- Hay una función
sub_5EC . - La instrucción 0x00001FB4 jsr (a0) llama a la función sub_E3E (esto se puede ver con una traza simple).
¿Qué está pasando aquí?
- La función
sub_5EC escribe el resultado de su ejecución en el registro d0 (esto se analiza en una sección separada a continuación). - El byte en la dirección
sp+0x33 ( 0x00FFFF79 , nos dice el depurador) se almacena en el registro d1 , es igual al segundo byte de la dirección hash clave ( 0x00FF0D47 ). Esto es fácil de probar si pone un salto en el registro en 0x00FFFF79 : funcionará en las instrucciones 0x00001F94 move.b 1(a2), 0x2F(sp) . El registro a2 en este momento almacena la dirección 0x00FF0D46 - la dirección hash, es decir, 0x1(a2) = 0x00FF0D46 + 1 - la dirección del segundo byte del hash. - El registro
d0 se escribe d0^d1 .
- El resultado xor'a resultante se proporciona a la función
sub_E3E , cuyo comportamiento depende de sus cálculos anteriores (que se muestran a continuación). - Repetir
¿Cuántas veces se ejecuta este ciclo?
Descubre esto. Ejecute el siguiente script:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4 : aquí se determina lo que sucederá en
d4 inmediatamente antes del ciclo:
Nos ocupamos de la función sub_5EC.
sub_5EC
Pieza de código significativa:
donde
0x2c(a2) siempre
0x2c(a2) 0x00FF1D74 .
Esta pieza se puede reescribir así en pseudocódigo:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
Es decir, 4 bytes de
0x00FF1D74 son la dirección, porque son tratados como un puntero.
¿Cómo reescribir la función
sub_5EC en python?
- O haga un volcado de memoria y trabaje con él.
- O simplemente escriba todos los valores devueltos.
El segundo método me gusta más, pero ¿y si, con diferentes datos de autorización, los valores devueltos son diferentes? Mira esto.
El script ayudará en esto:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
Acabo de comparar las salidas a la consola con diferentes claves, correos.
Al ejecutar el script varias veces con diferentes teclas, veremos que la función
sub_5EC siempre devuelve el siguiente valor de la matriz:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
Entonces
sub_5EC está listo.
sub_E3E línea es
sub_E3E .
sub_E3E
Pieza de código significativa:
Descifrar:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
La función
sub_E3E reduce a estos pasos:
- Guarde el argumento de entrada en una matriz.
- Calcule el desplazamiento de desplazamiento.
- Extraiga 2 bytes en la dirección
0x00011FC0 + offset (ROM). - Resultado =
( >> 8) ^ (2 0x00011FC0 + offset) .
Imagine la función
sub_E3E de esta forma:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0 es solo un archivo donde
[0x00011FC0:00011FC0+4096] 4096 bytes de
[0x00011FC0:00011FC0+4096] .
Actividad alrededor de 1FC4
Todavía no hemos visto la dirección
0x00001FC4 , pero es fácil de encontrar, ya que el bloqueo desaparece casi inmediatamente después del primer ciclo.
Este bloque cambia el contenido en la dirección
0x00FF0D46 (registro
a2 ), y ahí es donde se almacena el hash de la clave, por lo que ahora estamos estudiando este bloque. Veamos que pasa aquí.
- La condición que determina si se selecciona la rama izquierda o derecha es:
( ) & 0b1 != 0 . Es decir, se comprueba el primer bit del hash. - Si observas ambas ramas, verás:
- En ambos casos, se produce un desplazamiento hacia la derecha de 1 bit.
- En la rama izquierda, la operación de hash se realiza
0x8000 . - En ambos casos, el valor hash procesado se escribe en la dirección
0x00FF0D46 , es decir, el hash se reemplaza con un nuevo valor. - Los cálculos adicionales no son críticos, porque, en términos generales, no hay operaciones de escritura en
(a2) (no hay instrucciones de dónde estaría el segundo operando (a2) ).
Imagina un bloque como este:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
El segundo bucle importante es loc_203E
loc_203E - bucle, porque
0x0000206C bne.s loc_203E .
Este ciclo calcula el hash y aquí está su característica principal:
jsr (a0) es una llamada a la función
sub_E3E que ya hemos examinado; se basa en el resultado anterior de su propio trabajo y en algún argumento de entrada (se pasó a través del registro
d2 anterior, y aquí a través de
d0 )
Veamos qué le pasa a través del registro
d0 .
Ya nos hemos encontrado con la construcción
0x34(a2) : la función
sub_E3E guarda el argumento pasado allí. Esto significa que los argumentos pasados previamente se usan en este bucle. Pero no todos.
Descifrar la parte del código:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
La conclusión es una acción simple: en cada iteración, tome
d0 argumento almacenado desde el final de la matriz. Es decir, si 4 se almacena en
d0 , entonces tomamos el cuarto elemento desde el final.
Si es así, ¿qué toma exactamente
d0 ? Aquí lo hice sin guiones, pero simplemente los escribí, poniendo un descanso al comienzo de este bloque. Aquí están:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .
Ahora tenemos todo para escribir una función completa de cálculo de clave hash.
Función de cálculo de hash completo
def finish_hash(hash_2b):
Control de salud
- En el depurador, establecemos un
0x0000180A move.l 0x1000,(sp) en la dirección 0x0000180A move.l 0x1000,(sp) (inmediatamente después del cálculo de hash). - Salto a la dirección
0x00001F16 beq.w loc_20EA (comparación del hash final con constante 0xCB4C ). - En el programa, ingrese la clave
ABCDEFGHIJKLMNOP , presione Enter . - El depurador se detiene en
0x0000180A , y vemos que el valor 0xFFFF44CC se 0x44CC registro d5 , 0x44CC es el primer hash. - Comenzamos el depurador aún más.
- Nos detenemos en
0x00001F16 y vemos que en 0x00FF0D6A encuentra 0x4840 : el hash final
- Ahora echa un vistazo a nuestra función finish_hash (hash_2b):
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Estamos buscando la clave correcta 1
La clave correcta es esta clave cuyo hash final es
0xCB4C (que se encuentra arriba). De ahí la pregunta: ¿cuál debería ser el primer hash para que el final se convierta en
0xCB4C ?
Ahora es fácil descubrirlo:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
El resultado del programa sugiere que solo hay una opción: el primer hash debe ser
0xFEDC .
¿Qué caracteres necesitamos para que su primer hash sea
0xFEDC ?
Como
0xFEDC = __4_ ^ __4_ , solo necesita encontrar el
__4_ , porque el
__4_ = __4_ ^ 0xFEDC . Y luego decodifica ambos hashes.
El algoritmo es el siguiente:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Un montón de opciones, elija cualquiera.
Estamos buscando la clave correcta 2
La primera mitad de la llave está lista, ¿qué pasa con la segunda?
Esta es la parte más fácil.
El código responsable se encuentra en
0x00FF2012 , lo obtuve por rastreo manual, comenzando con la dirección
0x00001F16 beg.w loc_20EA (validación de la primera mitad de la clave). En el registro
a0 es la dirección de correo,
loc_FF2012 es un ciclo, porque
bne.s loc_FF2012 . Se ejecuta siempre que haya
*(a0+d0) (el siguiente byte de correo).
Y la
jsr (a3) llama a la función ya conocida
get_hash_2b , que ahora funciona con la segunda mitad de la clave.
Hagamos el código más claro:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
En el registro
d2 -
( -1) << 8 . En
d3 , la suma de bytes de caracteres de correo.
El criterio de corrección es el siguiente:
__ ^ d2 == ___2 ^ d3 .
Escribimos la función de selección de la segunda mitad de la tecla:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Keygen
El correo debe ser una cápsula.
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
Gracias por su atencion! Todo el código está disponible
aquí .