Otro usuario quiere escribir una nueva pieza de datos en el disco duro, pero no tiene suficiente espacio libre para esto. Tampoco quiero eliminar nada, ya que "todo es muy importante y necesario". ¿Y qué haremos con él?
No tiene tal problema. Terabytes de información descansan en nuestros discos duros, y esta cantidad no tiende a disminuir. ¿Pero qué tan único es? Al final, después de todo, todos los archivos son solo conjuntos de bits de cierta longitud y, lo más probable, el nuevo no es muy diferente del que ya está almacenado.
Está claro que buscar piezas de información ya almacenadas en el disco duro es una tarea, si no una falla, entonces al menos no una efectiva. Por otro lado, porque si la diferencia es pequeña, entonces puede caber un poco ...

TL; DR: el segundo intento de hablar sobre un método extraño de optimización de datos utilizando archivos JPEG, ahora en una forma más comprensible.
Sobre bits y diferencia
Si tomamos dos datos completamente al azar, entonces, en promedio, la mitad de los bits contenidos coinciden en ellos. De hecho, entre los diseños posibles para cada par ('00, 01, 10, 11 '), exactamente la mitad tiene los mismos valores, todo es simple aquí.
Pero, por supuesto, si solo tomamos dos archivos y ajustamos uno debajo del segundo, perderemos uno de ellos. Si mantenemos los cambios, simplemente reinventaremos la codificación delta , que incluso sin nosotros existe perfectamente, aunque generalmente no se usa con el mismo propósito. Puede intentar incrustar una secuencia más pequeña en una más grande, pero aun así, corremos el riesgo de perder segmentos de datos críticos cuando se usan precipitadamente con todo.
¿Entre qué y qué puede eliminarse la diferencia? Bueno, es decir, un nuevo archivo grabado por el usuario es solo una secuencia de bits con los que no podemos hacer nada por sí mismos. Luego, solo necesita encontrar esos bits en el disco duro para que puedan cambiarse sin tener que almacenar la diferencia, para que pueda sobrevivir a su pérdida sin consecuencias graves. Sí, y tiene sentido cambiar no solo el archivo en sí en el FS, sino también alguna información menos confidencial dentro de él. ¿Pero cuál y cómo?
Métodos de ajuste
Los archivos comprimidos con pérdida vienen al rescate. Todos estos archivos JPEG, MP3 y otros, aunque son de compresión con pérdida, contienen un montón de bits disponibles para un cambio seguro. Puede utilizar técnicas avanzadas, modificando discretamente sus componentes en diferentes áreas de codificación. Espera un momento Técnicas avanzadas ... modificación discreta ... algunos bits para otros ... sí, ¡es casi esteganografía !
De hecho, incrustar una información en otra se parece a sus métodos sin importar qué. También impresiona la invisibilidad de los cambios realizados en los sentidos humanos. Ahí es donde los caminos divergen: es un secreto: nuestra tarea es agregar información adicional al disco duro del usuario, solo lo dañará. Olvida más.
Por lo tanto, aunque podemos usarlos, necesitamos hacer algunas modificaciones. Y luego les contaré y mostraré el ejemplo de uno de los métodos existentes y el formato de archivo común.
Sobre los chacales
Si comprimes, entonces el más compresible del mundo. Estamos, por supuesto, hablando de archivos JPEG. No solo hay un montón de herramientas y métodos existentes para incrustar datos en él, es el formato gráfico más popular en este planeta.

Sin embargo, para no participar en la cría de perros, debe limitar su campo de actividad en archivos de este formato. A nadie le gustan los cuadrados monocromos que surgen debido a una compresión excesiva, por lo que debe limitarse a trabajar con un archivo ya comprimido, evitando la transcodificación . Más específicamente, con coeficientes enteros que quedan después de las operaciones responsables de la pérdida de datos: DCT y cuantización, que se muestra perfectamente en el esquema de codificación (gracias a la wiki de la Biblioteca Nacional de Bauman):

Existen muchos métodos de optimización posibles para archivos jpeg. Hay una optimización sin pérdidas (jpegtran), hay una optimización sin pérdidas , que de hecho todavía contribuyen, pero no nos molestan. De hecho, si un usuario está listo para incrustar una información en otra en aras de aumentar el espacio libre en el disco, entonces o bien optimizó sus imágenes durante mucho tiempo o no quiere hacerlo en absoluto por temor a la pérdida de calidad.
F5
En tales condiciones, es adecuada una familia completa de algoritmos, que se pueden encontrar en esta buena presentación . El más avanzado de ellos es el algoritmo F5 , creado por Andreas Westfeld, que trabaja con los coeficientes del componente de brillo, ya que el ojo humano es el menos sensible a sus cambios. Además, utiliza una técnica de incrustación basada en la codificación matricial, que le permite a uno hacer menos cambios al incrustar la misma cantidad de información, cuanto mayor sea el tamaño del contenedor utilizado.
Los cambios en sí mismos se reducen a una disminución en el valor absoluto de los coeficientes por unidad bajo ciertas condiciones (es decir, no siempre), lo que hace posible utilizar F5 para optimizar el almacenamiento de datos en el disco duro. El hecho es que es probable que el coeficiente después de tal cambio ocupe un número menor de bits después de la codificación Huffman debido a la distribución estadística de valores en JPEG, y los nuevos ceros se beneficiarán al codificarlos usando RLE.
Las modificaciones necesarias se reducen a eliminar la parte responsable del secreto (permutación de contraseña), que permite ahorrar recursos y tiempo de ejecución, y agregar un mecanismo para trabajar con muchos archivos en lugar de uno a la vez. Con más detalle, es poco probable que el proceso de cambiar el lector sea interesante, por lo que pasamos a la descripción de la implementación.
Alta tecnología
Para demostrar el trabajo de este enfoque, implementé el método en C puro y realicé varias optimizaciones tanto en términos de velocidad como de memoria (no puede imaginar cuánto pesan estas imágenes sin compresión incluso antes de DCT). El rendimiento multiplataforma se logra utilizando una combinación de las bibliotecas libjpeg , pcre y tinydir , por lo que les agradezco. Todo esto se hará por marca, por lo que los usuarios de Windows desean instalar algunos Cygwin para evaluación, o tratar con Visual Studio y las bibliotecas por su cuenta.
La implementación está disponible en forma de una utilidad de consola y una biblioteca. Puede encontrar más información sobre el uso de este último en el archivo Léame en el repositorio en el github, un enlace al que adjuntaré al final de la publicación.
¿Cómo usarlo?
Con precaución Las imágenes utilizadas para empaquetar se seleccionan mediante búsqueda de expresión regular en el directorio raíz especificado. Al final del archivo, puede mover, renombrar y copiar según lo desee dentro de él, cambiar el archivo y los sistemas operativos, etc. Sin embargo, debe tener mucho cuidado y no cambiar el contenido inmediato. La pérdida del valor de incluso un bit puede conducir a la imposibilidad de restaurar la información.
Al finalizar el trabajo, la utilidad deja un archivo de archivo especial que contiene toda la información necesaria para desempaquetar, incluidos los datos de las imágenes utilizadas. Por sí solo, pesa del orden de un par de kilobytes y no tiene ningún efecto significativo en el espacio en disco ocupado.
Puede analizar la capacidad posible utilizando el indicador '-a': './f5ar -a [carpeta de búsqueda] [expresión regular compatible con Perl]'. El embalaje se realiza con el comando './f5ar -p [carpeta de búsqueda] [expresión regular compatible con Perl] [archivo empaquetado] [nombre de archivo]', y desempaquetando con './f5ar -u [archivo de archivo] [nombre del archivo restaurado]' .
Demostración de trabajo
Para mostrar la efectividad del método, descargué una colección de 225 fotos de perros absolutamente gratis del servicio Unsplash y desenterré un gran pdf de 45 metros en los documentos del segundo volumen del Knut Programming Art .
La secuencia es bastante simple:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Capturas de pantalla para fanáticos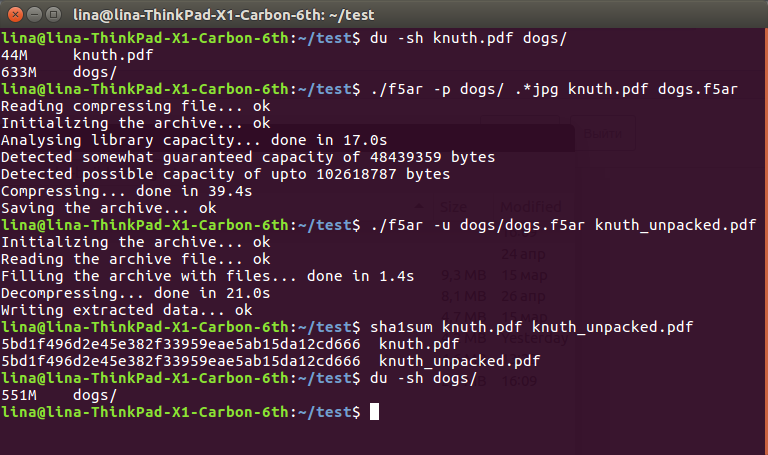
El archivo desempaquetado aún es posible y debe leerse:

Como puede ver, a partir de los 633 + 36 == 669 megabytes de datos originales en el disco duro, llegamos a un 551. más agradable. Esta diferencia radical se explica por la disminución en los valores de los coeficientes, que afectan su compresión posterior sin pérdida: una disminución de uno por uno puede con calma " cortar "un par de bytes del archivo resultante. Sin embargo, esto sigue siendo una pérdida de datos, aunque extremadamente pequeña, que tiene que soportar.
Afortunadamente, no son completamente visibles a simple vista. Bajo el spoiler (debido a que el almacenamiento no puede manejar archivos grandes), el lector puede evaluar la diferencia tanto por ojo como por su intensidad, obtenida restando los valores del componente modificado del original: el original , con la información dentro , la diferencia (cuanto más oscuro es el color, menor es la diferencia en el bloque )
En lugar de una conclusión
Analizar todas estas dificultades, comprar un disco duro o cargar todo a la nube puede parecer una solución mucho más simple al problema. Pero a pesar de que ahora vivimos en un momento tan maravilloso, no hay garantías de que mañana todavía sea posible conectarse y cargar en algún lugar todos sus datos adicionales. O ven a la tienda y cómprate otro disco duro de mil terabytes. Pero siempre puedes usar casas que ya están tumbadas.
-> github