
Antecedentes
Dio la casualidad de que el servidor fue atacado por un virus ransomware que, por una "casualidad", apartó parcialmente los archivos .ibd (archivos de datos sin procesar de las tablas innodb), pero cifró completamente los archivos .fpm (archivos de estructura). Al mismo tiempo, .idb podría dividirse en:
- sujeto a recuperación a través de herramientas y guías estándar. Para tales casos, hay un gran artículo ;
- tablas parcialmente encriptadas. En su mayoría, estas son tablas grandes, en las cuales (como entendí), los atacantes no tenían suficiente RAM para el cifrado completo;
- Bueno, tablas totalmente encriptadas que no se pueden recuperar.
Fue posible determinar a qué opción pertenecen las tablas abriendo en cualquier editor de texto con la codificación deseada (en mi caso, es UTF8) y simplemente mirando el archivo para ver la presencia de campos de texto, por ejemplo:
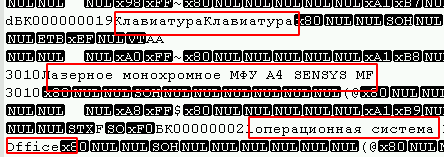
Además, al comienzo del archivo puede observar una gran cantidad de 0 bytes, y los virus que usan el algoritmo de cifrado de bloque (el más común) generalmente los afectan.

En mi caso, los atacantes al final de cada archivo encriptado dejaron una cadena de 4 bytes (1, 0, 0, 0), lo que simplificó la tarea. Un script fue suficiente para buscar archivos no infectados:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
Por lo tanto, resultó encontrar archivos que pertenecen al primer tipo. El segundo implica un manual largo, pero ya encontrado fue suficiente. Todo estaría bien, pero necesita saber la estructura absolutamente exacta y (por supuesto) hubo tal caso que tuve que trabajar con una tabla que cambiaba con frecuencia. Nadie recordaba si el tipo de campo estaba cambiando o si se estaba agregando una nueva columna.
Desafortunadamente, Debri City no pudo ayudar con este caso, por lo tanto, este artículo está siendo escrito.
Llegar al punto
Hay una estructura de tabla de hace 3 meses que no coincide con la actual (quizás un campo, pero posiblemente más). Estructura de la mesa:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
en este caso, necesita extraer:
id_point INT (11);id_user INT (11);date_start DATETIME;date_finish DATETIME.
Para la recuperación, se utiliza un análisis de bytes del archivo .ibd, seguido de su traducción en una forma más legible. Dado que para encontrar lo que se requiere, es suficiente para nosotros analizar tipos de datos como int y datatime, solo se describirán en el artículo, pero a veces también se referirán a otros tipos de datos, que pueden ayudar en otros incidentes similares.
Problema 1 : los campos con los tipos DATETIME y TEXT tenían un valor NULL, y simplemente se omiten en el archivo, debido a esto, no fue posible determinar la estructura para la recuperación en mi caso. En las nuevas columnas, el valor predeterminado era nulo, y algunas de las transacciones podrían perderse debido a la configuración innodb_flush_log_at_trx_commit = 0, por lo que habría que dedicar más tiempo para determinar la estructura.
Problema 2 : debe tenerse en cuenta que las filas eliminadas a través de DELETE estarán todas exactamente en el archivo ibd, pero su estructura no se actualizará con ALTER TABLE. Como resultado, la estructura de datos puede variar desde el comienzo del archivo hasta su final. Si a menudo usa OPTIMIZE TABLE, es poco probable que encuentre un problema similar.
Tenga en cuenta que la versión DBMS afecta la forma en que se almacenan los datos, y este ejemplo puede no funcionar para otras versiones principales. En mi caso, se utilizó la versión de Windows mariadb 10.1.24. Además, aunque en mariadb trabajas con tablas InnoDB, de hecho son XtraDB , lo que excluye la aplicabilidad del método con InnoDB mysql.
Análisis de archivos
En python, el tipo de datos bytes () muestra datos en Unicode en lugar del conjunto habitual de números. Aunque puede considerar el archivo en este formulario, pero por conveniencia, puede traducir bytes a una forma numérica traduciendo la matriz de bytes en una matriz regular (list (example_byte_array)). En cualquier caso, ambos métodos son útiles para el análisis.
Después de mirar varios archivos ibd, puede encontrar lo siguiente:
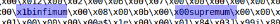
Además, si divide el archivo entre estas palabras clave, obtendrá principalmente bloques de datos planos. Usaremos infimum como divisor.
table = table.split("infimum".encode())
Una observación interesante, para tablas con una pequeña cantidad de datos, entre infimum y supremum, hay un puntero al número de filas en el bloque.
 - mesa de prueba con primera fila
- mesa de prueba con primera fila
 - mesa de prueba con 2 filas
- mesa de prueba con 2 filas
La matriz de la tabla de filas [0] se puede omitir. Después de mirarlo, todavía no pude encontrar los datos en bruto de las tablas. Lo más probable es que este bloque se use para almacenar índices y claves.
Comenzando con la tabla [1] y traduciéndola a una matriz numérica, ya puede notar algunos patrones, a saber:

Estos son valores int almacenados en una cadena. El primer byte indica si el número es positivo o negativo. En mi caso, todos los números son positivos. De los 3 bytes restantes, puede determinar el número utilizando la siguiente función. Guión:
def find_int(val: str):
Por ejemplo, 128, 0, 0, 1 = 1 , o 128, 0, 75, 108 = 19308 .
La tabla tenía una clave principal con incremento automático, y aquí también puede encontrarla.

Al comparar los datos de las tablas de prueba, se reveló que el objeto DATETIME consta de 5 bytes, comenzando con 153 (lo más probable es que indique intervalos anuales). Dado que el rango DATTIME es '1000-01-01' a '9999-12-31', creo que el número de bytes puede variar, pero en mi caso, los datos caen en el período de 2016 a 2019, por lo que suponemos que 5 bytes son suficientes .
Para determinar el tiempo sin segundos, se escribieron las siguientes funciones. Guión:
day_ = lambda x: x % 64 // 2
Durante un año y un mes, no fue posible escribir una función de trabajo saludable, así que tuve que codificar. Guión:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
Estoy seguro de que si pasas n la cantidad de tiempo, este malentendido puede corregirse.
A continuación, la función devuelve un objeto datetime de una cadena. Guión:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
Fue posible detectar valores repetidos frecuentemente de int, int, datetime, datetime 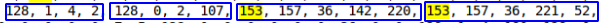 Parece que esto es lo que necesitas. Además, tal secuencia no se repite dos veces por línea.
Parece que esto es lo que necesitas. Además, tal secuencia no se repite dos veces por línea.
Usando una expresión regular, encontramos los datos necesarios:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
Tenga en cuenta que al buscar por esta expresión, no será posible determinar valores NULL en los campos obligatorios, pero en mi caso esto no es crítico. Después de recorrer lo encontrado. Guión:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
En realidad todo, datos de la matriz de resultados, estos son los datos que necesitamos. ### PS. ###
Entiendo que este método no es adecuado para todos, pero el objetivo principal del artículo es impulsar la acción en lugar de resolver todos sus problemas. Creo que la solución más correcta sería comenzar a estudiar el código fuente de mariadb , pero debido al tiempo limitado, el método actual parecía el más rápido.
En algunos casos, después de analizar el archivo, puede determinar la estructura aproximada y restaurar uno de los métodos estándar desde los enlaces anteriores. Será mucho más correcto y causará menos problemas.