Hola queridos lectores de Habr. Mi nombre es Rustem y soy el desarrollador principal de la empresa de TI de Kazajstán DAR. En este artículo, le diré lo que necesita saber antes de pasar a las plantillas de CQRS y Búsqueda de eventos utilizando el kit de herramientas de Akka.
Alrededor de 2015, comenzamos a diseñar nuestro ecosistema. Después del análisis y de la experiencia con Scala y Akka, decidimos parar en el kit de herramientas de Akka. Tuvimos implementaciones exitosas de plantillas de Event Sourcing con CQRS y no fue así. La acumulación de experiencia en esta área, que quiero compartir con los lectores. Veremos cómo Akka implementa estos patrones, así como qué herramientas están disponibles y hablaremos sobre las trampas de Akka. Espero que después de leer este artículo, comprenda mejor los riesgos de cambiar al kit de herramientas de Akka.
Sobre temas de CQRS y Event Sourcing se escribieron muchos artículos sobre Habré y sobre otros recursos. Este artículo está dirigido a lectores que ya entienden qué son CQRS y Event Sourcing. En el artículo quiero concentrarme en Akka.
Diseño impulsado por dominio
Se ha escrito una gran cantidad de material sobre diseño controlado por dominio (DDD). Hay oponentes y partidarios de este enfoque. Quiero agregar por mi cuenta que si decides cambiar a Event Sourcing y CQRS, no será superfluo estudiar DDD. Además, la filosofía DDD se siente en todas las herramientas de Akka.
De hecho, el Abastecimiento de eventos y CQRS son solo una pequeña parte del panorama general llamado Diseño impulsado por dominio. Al diseñar y desarrollar, es posible que tenga muchas preguntas sobre cómo implementar adecuadamente estos patrones e integrarse en el ecosistema, y saber que DDD le facilitará la vida.
En este artículo, el término entidad (entidad por DDD) significará un actor de persistencia que tiene un identificador único.
¿Por qué Scala?
A menudo se nos pregunta por qué Scala, y no Java. Una razón es Akka. El marco en sí, escrito en el lenguaje Scala con soporte para el lenguaje Java. Aquí debo decir que también hay una implementación en .NET , pero este es otro tema. Para no provocar una discusión, no escribiré por qué Scala es mejor o peor que Java. Solo te diré un par de ejemplos que, en mi opinión, Scala tiene una ventaja sobre Java cuando trabaja con Akka:
- Objetos inmutables. En Java, debe escribir objetos inmutables usted mismo. Créame, no es fácil ni muy conveniente escribir constantemente los parámetros finales. En el
case class Scala case class ya case class inmutable con la función de copy incorporada - Estilo de codificación Cuando se implementa en Java, seguirá escribiendo en el estilo Scala, es decir, funcionalmente.
Aquí hay un ejemplo de implementación de actor en Scala y Java:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Java:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(Ejemplo tomado de aquí )
Preste atención a la implementación del método createReceive() utilizando el ejemplo del lenguaje Java. Internamente, a través de la fábrica ReceiveBuilder , se implementa la coincidencia de patrones. receiveBuilder() es un método de Akka para admitir expresiones lambda, es decir, la coincidencia de patrones en Java. En Scala, esto se implementa de forma nativa. De acuerdo, el código en Scala es más corto y más fácil de leer.
- Documentación y ejemplos. A pesar de que en la documentación oficial hay ejemplos en Java, en Internet, casi todos los ejemplos están en Scala. Además, le será más fácil navegar en las fuentes de la biblioteca Akka.
En términos de rendimiento, no habrá diferencia entre Scala y Java, ya que todo gira en la JVM.
Almacenamiento
Antes de implementar Event Sourcing con Akka Persistence, le recomiendo que seleccione previamente una base de datos para el almacenamiento permanente de datos. La elección de la base depende de los requisitos del sistema, de sus deseos y preferencias. Los datos se pueden almacenar tanto en NoSQL y RDBMS como en un sistema de archivos, por ejemplo, LevelDB de Google .
Es importante tener en cuenta que Akka Persistence no es responsable de escribir y leer datos de la base de datos, sino que lo hace a través de un complemento que debe implementar la API de Akka Persistence.
Después de elegir una herramienta para almacenar datos, debe seleccionar un complemento de la lista o escribirlo usted mismo. La segunda opción, no recomiendo por qué reinventar la rueda.
Para el almacenamiento permanente de datos, decidimos quedarnos en Cassandra. El hecho es que necesitábamos una base confiable, rápida y distribuida. Además, Typesafe acompaña el complemento , que implementa completamente la API de persistencia de Akka . Se actualiza constantemente y, en comparación con otros, el complemento Cassandra ha escrito una documentación más completa.
Vale la pena mencionar que el complemento también tiene varios problemas. Por ejemplo, todavía no hay una versión estable (en el momento de escribir este artículo, la última versión es 0.97). Para nosotros, la mayor molestia que encontramos al usar este complemento fue la pérdida de eventos al leer la consulta persistente para algunas entidades. Para una imagen completa, a continuación se muestra el gráfico CQRS:
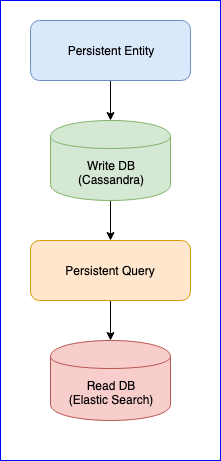
La entidad persistente distribuye los eventos de la entidad en etiquetas usando el algoritmo hash consistente (por ejemplo, 10 fragmentos):
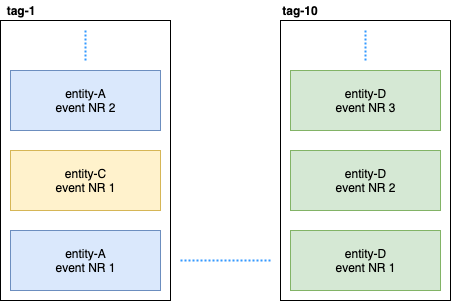
Luego, la consulta persistente se suscribe a estas etiquetas y lanza una secuencia que agrega datos a Elastic Search. Como Cassandra está en un clúster, los eventos se dispersarán por los nodos. Algunos nodos pueden ceder y responderán más lentamente que otros. No hay garantía de que recibirá los eventos en estricto orden. Para resolver este problema, el complemento se implementa de modo que si recibe un evento no ordenado, por ejemplo, el entity-A event NR 2 , espera un cierto tiempo para el evento inicial y, si no lo recibe, simplemente ignorará todos los eventos de esta entidad. Incluso sobre esto, hubo discusiones sobre Gitter. Si alguien está interesado, puede leer la correspondencia entre @kotdv y los desarrolladores del complemento: Gitter
¿Cómo se puede resolver este malentendido?
- Necesita actualizar el complemento a la última versión. En versiones recientes, los desarrolladores de Typesafe han resuelto muchos problemas relacionados con la coherencia eventual. Pero todavía estamos esperando una versión estable.
- Se han agregado configuraciones más precisas para el componente responsable de recibir eventos. Puede intentar aumentar el tiempo de espera para eventos no ordenados para un funcionamiento más confiable del complemento: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Configure Cassandra como lo recomienda DataStax. Coloque el recolector de basura G1 y asigne tanta memoria como sea posible para Cassandra .
Al final, resolvimos el problema con los eventos faltantes, pero ahora hay un retraso de datos estable en el lado de la consulta de persistencia (de cinco a diez segundos). Se decidió abandonar el enfoque de los datos que se utilizan para el análisis, y donde la velocidad es importante, publicamos eventos manualmente en el bus. Lo principal es elegir el mecanismo apropiado para procesar o publicar datos: al menos una vez o como máximo una vez. Una buena descripción de Akka se puede encontrar aquí . Era importante para nosotros mantener la consistencia de los datos y, por lo tanto, después de escribir con éxito los datos en la base de datos, presentamos un estado de transición que controla la publicación exitosa de los datos en el bus. El siguiente es un código de muestra:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
Si por alguna razón no fue posible publicar el evento, en el próximo inicio de SomeEntity , sabrá que el evento DidSomething no llegó al bus e intentará volver a publicar los datos nuevamente.
Serializador
La serialización es un punto igualmente importante en el uso de Akka. Él tiene un módulo interno: Serialización Akka . Este módulo se utiliza para serializar mensajes al intercambiarlos entre actores y al almacenarlos a través de la API de persistencia. Por defecto, se usa el serializador Java, pero se recomienda usar otro. El problema es que el serializador de Java es lento y ocupa mucho espacio. Hay dos soluciones populares: estas son JSON y Protobuf. JSON, aunque lento, es más fácil de implementar y mantener. Si necesita minimizar el costo de serialización y almacenamiento de datos, puede detenerse en Protobuf, pero luego el proceso de desarrollo será más lento. Además del modelo de dominio, tendrá que escribir otro modelo de datos. No te olvides de las versiones de datos. Esté preparado para escribir constantemente el mapeo entre el Modelo de dominio y el Modelo de datos.
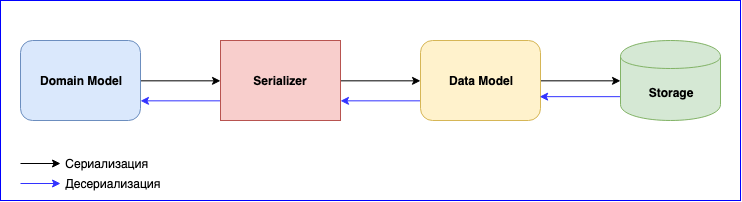
Se agregó un nuevo evento: mapeo de escritura. Cambió la estructura de datos: escriba una nueva versión del Modelo de datos y cambie la función de mapeo. No te olvides de las pruebas para serializadores. En general, habrá mucho trabajo, pero al final obtendrás componentes sueltos.
Conclusiones
- Estudie cuidadosamente y elija una base y un complemento adecuados para usted. Recomiendo elegir un complemento que esté bien mantenido y no deje de desarrollarse. El área es relativamente nueva, todavía hay un montón de fallas que aún no se han resuelto.
- Si selecciona almacenamiento distribuido, tendrá que resolver el problema con un retraso de hasta 10 segundos usted mismo, o soportarlo
- La complejidad de la serialización. Puede sacrificar la velocidad y detenerse en JSON, o elegir Protobuf y escribir muchos adaptadores y apoyarlos.
- Hay ventajas en esta plantilla, estos son componentes sueltos y equipos de desarrollo independientes que crean un sistema grande.