SDSM ha terminado, pero el deseo incontrolado de escribir permanece.

Durante muchos años, nuestro hermano sufrió el desempeño del trabajo de rutina, cruzó los dedos antes de comprometerse y no pudo dormir debido a los retrocesos nocturnos.
Pero los tiempos oscuros están llegando a su fin.
Con este artículo, comenzaré una serie sobre cómo veo la automatización.
En el proceso, abordaremos las etapas de automatización, almacenando variables, formalizando el diseño, con RestAPI, NETCONF, YANG, YDK y programaremos mucho.
Significa para
mí que a) esta no es una verdad objetiva, b) no incondicionalmente el mejor enfoque c) mi opinión puede cambiar incluso durante el movimiento del primer al último artículo; para ser honesto, desde la etapa de borrador hasta la publicación, reescribí todo dos veces.
Contenido
- Objetivos
- La red es como un solo organismo.
- Prueba de configuración
- Versionado
- Servicios de monitoreo y autocuración
- Significa
- Sistema de inventario
- Sistema de gestión de espacio IP
- Sistema de descripción de servicios de red
- Mecanismo de inicialización del dispositivo
- Modelo de configuración agnóstica del proveedor
- Conductor específico del proveedor
- El mecanismo para entregar la configuración al dispositivo.
- CI / CD
- Mecanismo de respaldo y desviación
- Sistema de monitoreo
- Conclusión
Intentaré mantener el ADSM en un formato ligeramente diferente del SDSM. Continuarán apareciendo grandes artículos detallados y numerados, y entre ellos publicaré pequeñas notas de la experiencia cotidiana. Trataré de luchar contra el perfeccionismo aquí y no lamer cada uno de ellos.
Qué gracioso que la segunda vez tengas que ir por el mismo camino.
Primero, tuve que escribir artículos sobre la red en sí debido al hecho de que no estaban en RuNet.
Ahora no pude encontrar un documento completo que sistematizara los enfoques de automatización y utilizara ejemplos prácticos simples para analizar las tecnologías anteriores.
Quizás me equivoque, por lo tanto, arroje enlaces a recursos adecuados. Sin embargo, esto no cambiará mi determinación de escribir, porque el objetivo principal sigue siendo aprender algo por mí mismo, y facilitarle la vida a mi vecino es un bono agradable que acaricia el gen para la difusión de la experiencia.
Intentaremos tomar un centro de datos LAN DC de tamaño mediano y resolver todo el esquema de automatización.
Haré algunas cosas casi la primera vez contigo.
En las ideas y herramientas descritas aquí, no seré original. Dmitry Figol tiene un excelente canal con transmisiones sobre este tema .
Los artículos en muchos aspectos se superpondrán con ellos.
La LAN DC tiene 4 DC, unos 250 conmutadores, media docena de enrutadores y un par de firewalls.
No es Facebook, pero es suficiente para pensar profundamente sobre la automatización.
Sin embargo, existe la opinión de que si tiene más de 1 dispositivo, ya necesita automatización.
De hecho, es difícil imaginar que alguien pueda vivir sin al menos un montón de guiones hasta la rodilla.
Aunque escuché que existen tales oficinas donde las direcciones IP se mantienen en Excel, y cada uno de los miles de dispositivos de red se configura manualmente y tiene su propia configuración única. Esto, por supuesto, puede pasarse como arte contemporáneo, pero los sentimientos del ingeniero ciertamente se ofenderán.
Objetivos
Ahora estableceremos los objetivos más abstractos:
- La red es como un solo organismo.
- Prueba de configuración
- Versiones de estado de red
- Servicios de monitoreo y autocuración
Más adelante en este artículo analizaremos qué medios usaremos, y en lo siguiente, metas y medios en detalle.
La red es como un solo organismo.
La frase definitoria del ciclo, aunque a primera vista puede no parecer tan significativa:
configuraremos la red, no los dispositivos individuales .
En los últimos años, hemos visto un cambio en el énfasis en cómo tratar la red como una entidad única, por lo tanto, la
red definida por software ,
las redes impulsadas por la intención y
las redes
autónomas llegan a nuestras vidas.
Después de todo, lo que necesitan globalmente las aplicaciones de la red: conectividad entre los puntos A y B (bueno, a veces + B-Z) y aislamiento de otras aplicaciones y usuarios.

Y, por lo tanto, nuestra tarea en esta serie es
construir un sistema que admita la configuración actual de
toda la red , que ya se descompone en la configuración actual en cada dispositivo de acuerdo con su función y ubicación.
El sistema de administración de red implica que para hacer cambios recurrimos a él, y este, a su vez, calcula el estado deseado para cada dispositivo y lo configura.
Por lo tanto, minimizamos el uso de CLI en nuestras manos a casi cero (cualquier cambio en la configuración del dispositivo o el diseño de la red debe formalizarse y documentarse) y solo luego desplegarse en los elementos de red necesarios.
Es decir, por ejemplo, si decidimos que a partir de ahora los conmutadores de montaje en bastidor de Kazan deberían anunciar dos redes en lugar de una,
- Primero documentamos los cambios en los sistemas.
- Generamos la configuración de destino de todos los dispositivos de red.
- Iniciamos el programa de actualización de la configuración de la red, que calcula qué debe eliminarse en cada nodo, qué agregar y lleva los nodos al estado deseado.
Al mismo tiempo, con nuestras manos hacemos cambios solo en el primer paso.
Prueba de configuración
Se sabe que el 80% de los problemas suceden durante los cambios de configuración; una evidencia indirecta de esto es que durante las vacaciones de Año Nuevo, generalmente todo está tranquilo.
Personalmente, presencié docenas de tiempos de inactividad globales debido a un error humano: el comando incorrecto, la configuración se ejecutó en la rama incorrecta, la comunidad olvidó, demolió MPLS globalmente en el enrutador, configuró cinco piezas de hierro y no notó el sexto error, cometió los viejos cambios realizados por otra persona . Escenarios la oscuridad es oscura.
La automatización nos permitirá cometer menos errores, pero a mayor escala. Por lo tanto, puede bloquear no un dispositivo, sino toda la red a la vez.
Desde tiempos inmemoriales, nuestros abuelos verificaron la corrección de los cambios realizados con un ojo agudo, huevos de acero y la eficiencia de la red después de desplegarlos.
Esos abuelos, cuyo trabajo condujo al tiempo de inactividad y pérdidas catastróficas, dejaron menos descendientes y deberían morir con el tiempo, pero la evolución es un proceso lento y, por lo tanto, no todos verifican los cambios en el laboratorio antes.
Sin embargo, a la vanguardia de aquellos que automatizaron el proceso de probar la configuración y su posterior aplicación a la red. En otras palabras, tomé prestado el procedimiento CI / CD (
Integración continua, Implementación continua ) de los desarrolladores.
En una parte, veremos cómo implementar esto usando un sistema de control de versiones, probablemente un github.
Tan pronto como se acostumbre a la idea de un CI / CD de red, de la noche a la mañana, el método de verificar la configuración aplicándolo a la red de producción le parecerá una ignorancia medieval temprana. Sobre cómo martillar una ojiva con un martillo.
Una continuación orgánica de las ideas sobre
el sistema de administración de red y CI / CD es la versión completa de la configuración.
Versionado
Asumiremos que con cualquier cambio, incluso el más pequeño, incluso en un dispositivo discreto, toda la red pasa de un estado a otro.
Y siempre no ejecutamos el comando en el dispositivo, cambiamos el estado de la red.
¿Ahora vamos a obtener estos estados y llamarlos versiones?
Digamos que la versión actual es 1.0.0.
¿Ha cambiado la dirección IP de la interfaz Loopback en uno de los ToR? Esta es una versión menor: obtenga el número 1.0.1.
Se revisaron las políticas de importación de rutas en BGP, un poco más serio, ya 1.1.0
Decidimos deshacernos de IGP y cambiar solo a BGP; este es un cambio de diseño radical: 2.0.0.
Al mismo tiempo, diferentes DC pueden tener diferentes versiones: la red se está desarrollando, se están instalando nuevos equipos, en algún lugar se agregan nuevos niveles de columna vertebral, en algún lugar, no, etc.
Hablaremos sobre
versiones semánticas en un artículo separado.
Repito: cualquier cambio (excepto los comandos de depuración) es una actualización de la versión. Los administradores deben ser notificados de cualquier desviación de la versión actual.
Lo mismo se aplica a la reversión de los cambios: esta no es la abolición de los últimos comandos, no es una reversión por parte del sistema operativo del dispositivo, esto está llevando a toda la red a una nueva (antigua) versión.
Servicios de monitoreo y autocuración
Esta tarea evidente en las redes modernas llega a un nuevo nivel.
A menudo, los grandes proveedores de servicios practican el enfoque de que un servicio caído debe terminarse rápidamente y plantearse uno nuevo, en lugar de averiguar qué sucedió.
"Muy" significa que desde todos los lados es necesario untar abundantemente con el monitoreo, que en segundos detectará las más mínimas desviaciones de la norma.
Y aquí no hay suficientes métricas familiares, como cargar una interfaz o la accesibilidad de un nodo. No hay suficiente y seguimiento manual del oficial de servicio para ellos.
Para muchas cosas, generalmente debería haber
una autocuración : los controles se encendieron en rojo y se fueron del plátano, donde duele.
Y aquí también monitoreamos no solo dispositivos individuales, sino también el estado de la red en su conjunto, tanto whitebox, que es relativamente claro, como blackbox, que ya es más complicado.
¿Qué necesitamos para implementar planes tan ambiciosos?
- Tenga una lista de todos los dispositivos en la red, su ubicación, roles, modelos, versiones de software.
kazan-leaf-1.lmu.net, Kazan, hoja, Juniper QFX 5120, R18.3.
- Tener un sistema para describir servicios de red.
IGP, BGP, L2 / 3VPN, Política, ACL, NTP, SSH. - Poder inicializar el dispositivo.
Nombre de host, gestión de IP, ruta de gestión, usuarios, claves RSA, LLDP, NETCONF - Configure el dispositivo y lleve la configuración a la versión deseada (incluida la anterior).
- Configuración de prueba
- Verifique periódicamente el estado de todos los dispositivos en busca de desviaciones del actual y diga quién debería hacerlo.
Por la noche, alguien silenciosamente agregó una regla a la ACL . - Supervisar el rendimiento.
Significa
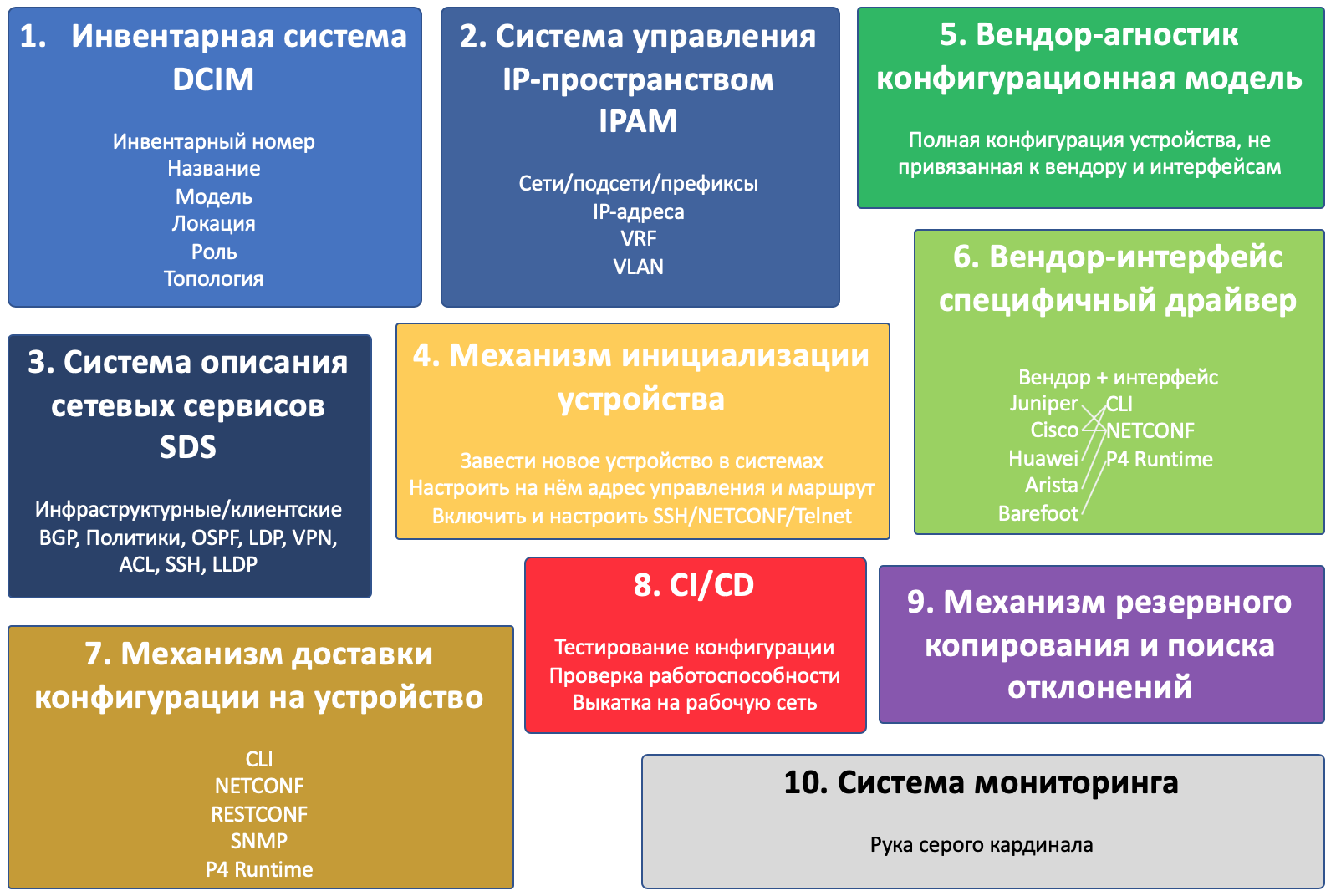
Suena lo suficientemente complicado como para comenzar a descomponer un proyecto en componentes.
Y habrá diez de ellos:
- Sistema de inventario
- Sistema de gestión de espacio IP
- Sistema de descripción de servicios de red
- Mecanismo de inicialización del dispositivo
- Modelo de configuración agnóstica del proveedor
- Conductor específico del proveedor
- El mecanismo para entregar la configuración al dispositivo.
- CI / CD
- Mecanismo de respaldo y desviación
- Sistema de monitoreo
Esto, por cierto, es un ejemplo de cómo cambió la visión sobre los objetivos del ciclo: había 4 componentes en el borrador de componentes.

En la ilustración, describí todos los componentes y el dispositivo en sí.
Los componentes de intersección interactúan entre sí.
Cuanto más grande es el bloque, más atención debe prestar a este componente.
Componente 1. Sistema de inventario
Obviamente, queremos saber a qué equipo, dónde se encuentra, a qué está conectado.
El sistema de inventario es una parte integral de cualquier empresa.
Con mayor frecuencia, para dispositivos de red, la empresa tiene un sistema de inventario separado que resuelve tareas más específicas.
Como parte de una serie de artículos, lo llamaremos DCIM - Data Center Infrastructure Management. Aunque el término DCIM en sí mismo, estrictamente hablando, incluye mucho más.
Para nuestras tareas, almacenaremos la siguiente información sobre el dispositivo:
- Número de inventario
- Título / Descripción
- Modelo ( Huawei CE12800, Juniper QFX5120, etc. )
- Parámetros típicos ( placas, interfaces, etc. )
- Rol ( hoja, columna vertebral, enrutador de borde, etc. )
- Ubicación ( región, ciudad, centro de datos, bastidor, unidad )
- Interconexiones entre dispositivos
- Topología de red

Está perfectamente claro que nosotros mismos queremos saber todo esto.
¿Pero ayudará a la automatización?
Por supuesto
Por ejemplo, sabemos que en este centro de datos en los conmutadores Leaf, si es Huawei, las ACL para filtrar cierto tráfico deben aplicarse en la VLAN, y si es Juniper, entonces en la unidad 0 de la interfaz física.
O necesita implementar un nuevo servidor Syslog para todos los huéspedes de la región.
En él, almacenaremos dispositivos de red virtuales, como enrutadores virtuales o reflectores raíz. Podemos agregar un servidor DNS, NTP, Syslog y, en general, todo lo que de alguna manera se relaciona con la red.
Componente 2. Sistema de gestión del espacio IP
Sí, y en nuestro tiempo hay equipos de personas que realizan un seguimiento de los prefijos y las direcciones IP en un archivo de Excel. Pero el enfoque moderno sigue siendo una base de datos, con una interfaz en nginx / apache, una API y amplias funciones para tener en cuenta las direcciones IP y las redes con separación en VRF.
IPAM - Gestión de direcciones IP.
Para nuestras tareas, almacenaremos la siguiente información:
- VLAN
- VRF
- Redes / Subredes
- Direcciones IP
- Enlace de direcciones a dispositivos, redes a ubicaciones y números de VLAN

Una vez más, está claro que queremos estar seguros de que al asignar una nueva dirección IP para el bucle de retorno de ToR, no tropezaremos con el hecho de que ya está asignado a alguien. O que usamos el mismo prefijo dos veces en diferentes extremos de la red.
Pero, ¿cómo ayuda esto en la automatización?
Fácil
Solicitamos un prefijo en el sistema con la función Loopbacks, en el que hay direcciones IP disponibles para la asignación; si es así, seleccione la dirección; de lo contrario, solicitamos la creación de un nuevo prefijo.
O, al crear una configuración de dispositivo, desde el mismo sistema podemos averiguar en qué VRF debe estar la interfaz.
Y cuando inicia un nuevo servidor, el script ingresa al sistema, descubre en qué servidor está el conmutador, en qué puerto y qué subred está asignada a la interfaz; la dirección del servidor se asignará desde él.
Pide el deseo de DCIM e IPAM de combinarse en un solo sistema para no duplicar funciones y no servir a dos entidades similares.
Entonces lo haremos.
Componente 3. Sistema de descripción de servicios de red
Si los dos primeros sistemas almacenan variables que aún deben usarse de alguna manera, entonces el tercero describe para cada rol del dispositivo cómo debe configurarse.
Cabe destacar dos tipos diferentes de servicios de red:
Los primeros están diseñados para proporcionar conectividad básica y administración de dispositivos. Estos incluyen VTY, SNMP, NTP, Syslog, AAA, protocolos de enrutamiento, CoPP, etc.
Los segundos organizan el servicio para el cliente: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP, etc.
Por supuesto, también hay casos límite: ¿dónde incluir MPLS LDP, BGP? Sí, y los protocolos de enrutamiento se pueden usar para los clientes. Pero esto no es importante.
Ambos tipos de servicios se descomponen en primitivas de configuración:
- interfaces físicas y lógicas (tag / anteg, mtu)
- Direcciones IP y VRF (IP, IPv6, VRF)
- ACL y políticas de manejo de tráfico
- Protocolos (IGP, BGP, MPLS)
- Políticas de enrutamiento (listas de prefijos, comunidad, filtros ASN).
- Servicios de servicio (SSH, NTP, LLDP, Syslog ...)
- Etc.
Cómo haremos exactamente esto, no lo pensaré todavía. Trataremos en un artículo separado.

Si un poco más cerca de la vida, podríamos describir eso
El conmutador hoja debe tener sesiones BGP con todos los conmutadores Spine conectados, importar las redes conectadas al proceso y aceptar solo redes de un prefijo específico de los conmutadores Spine. Limite CoPP IPv6 ND a 10 pps, etc.
A su vez, los giros llevan a cabo sesiones con todos los corpiños conectados, actuando como reflectores de la raíz, y reciben de ellos solo rutas de cierta longitud y con una determinada comunidad.
Componente 4. Mecanismo de inicialización del dispositivo
Bajo este encabezado, combino las muchas acciones que deben ocurrir para que el dispositivo aparezca en los radares y se acceda de forma remota.
- Inicie el dispositivo en el sistema de inventario.
- Resalte la dirección IP de administración.
- Configure el acceso básico a él:
Nombre de host, dirección IP de administración, ruta a la red de administración, usuarios, claves SSH, protocolos - telnet / SSH / NETCONF
Hay tres enfoques:
- Todo es completamente manual. El dispositivo se lleva a un soporte donde una persona orgánica común lo llevará al sistema, se conectará a la consola y se configurará. Puede funcionar en pequeñas redes estáticas.
- ZTP: aprovisionamiento cero táctil. Iron vino, se puso de pie, recibió una dirección a través de DHCP, fue a un servidor especial y se configuró.
- La infraestructura de los servidores de consola, donde la configuración inicial se produce a través del puerto de la consola en modo automático.
Hablaremos de los tres en un artículo separado.

Componente 5. Modelo de configuración independiente del proveedor
Hasta ahora, todos los sistemas han sido trapos dispersos que dan variables y una descripción declarativa de lo que nos gustaría ver en la red. Pero tarde o temprano, tienes que lidiar con detalles.
En esta etapa, para cada dispositivo en particular, las primitivas, los servicios y las variables se combinan en un modelo de configuración que realmente describe la configuración completa de un dispositivo en particular, solo de manera independiente del proveedor.
¿Qué da este paso? ¿Por qué no configurar inmediatamente el dispositivo, que simplemente puede completar?
De hecho, esto nos permite resolver tres problemas:
- No se adapte a una interfaz específica para interactuar con el dispositivo. Ya sea CLI, NETCONF, RESTCONF, SNMP, el modelo será el mismo.
- No conserve el número de plantillas / scripts por el número de proveedores en la red y, en caso de un cambio de diseño, cambie el mismo en varios lugares.
- Descargue la configuración del dispositivo (copia de seguridad), colóquela exactamente en el mismo modelo y compare directamente la configuración de destino y la disponible para calcular el delta y preparar el parche de configuración, que cambiará solo aquellas partes que sean necesarias o para detectar desviaciones.

Como resultado de esta etapa, obtenemos una configuración independiente del proveedor.
Componente 6. Controlador específico de la interfaz del proveedor
No se consuele con la esperanza de que una vez que pueda configurar un tsiska, será posible de la misma manera que un puente, simplemente enviándoles exactamente las mismas llamadas. A pesar de la creciente popularidad de las cajas blancas y la aparición de soporte para NETCONF, RESTCONF, OpenConfig, el contenido específico que ofrecen estos protocolos es diferente de un proveedor a otro, y esta es una de sus diferencias competitivas que simplemente no van a renunciar.
Esto es casi lo mismo que OpenContrail y OpenStack, con RestAPI como su interfaz NorthBound, esperan llamadas completamente diferentes.
Entonces, en el quinto paso, el modelo independiente del vendedor debe tomar la forma en que irá al hierro.
Y aquí, todos los medios son buenos (no): CLI, NETCONF, RESTCONF, SNMP en una simple caída.
Por lo tanto, necesitamos un controlador que traduzca el resultado del paso anterior al formato deseado para un proveedor en particular: un conjunto de comandos CLI, una estructura XML.
Componente 7. El mecanismo para entregar la configuración al dispositivo.
Generamos la configuración, pero aún debe entregarse a los dispositivos, y, obviamente, no a mano.En primer lugar , nos enfrentamos a la pregunta, ¿qué tipo de transporte utilizaremos? Y la elección hoy ya no es pequeña:- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- API REST
- OpenFlow (aunque está eliminado de la lista, ya que esta es una forma de entregar FIB, no configuraciones)
Vamos a salpicar aquí con e. CLI es legado. SNMP ... jeje.RESTCONF sigue siendo un animal desconocido; la API REST casi no es compatible con nadie. Por lo tanto, nos centraremos en NETCONF en un bucle.De hecho, como el lector ya entendió, ya habíamos decidido la interfaz en este punto: el resultado del paso anterior ya se presentó en el formato de la interfaz seleccionada.En segundo lugar , ¿con qué herramientas haremos esto?Aquí la elección también es grande:- Guión o plataforma autoescrita. Nos armamos con ncclient y asyncIO y hacemos todo nosotros mismos. ¿Cuánto nos cuesta construir un sistema de implementación desde cero?
- Ansible con su rica biblioteca de módulos de red.
- Salt con su exiguo trabajo en red y paquete con Napalm.
- En realidad, Napalm, que conoce a un par de vendedores y eso es todo, adiós.
- Nornir es otra bestia que estamos preparando para el futuro.
Todavía no hay ningún favorito elegido: pisotearemos.¿Qué más es importante aquí? Las consecuencias de aplicar la configuración.Con éxito o no. Acceso restante a la pieza de hardware o no.Parece que commit ayudará aquí con la confirmación y validación de lo que se descargó en el dispositivo.Esto, combinado con la implementación correcta de NETCONF, reduce significativamente la gama de dispositivos adecuados; no muchos fabricantes admiten confirmaciones normales. Pero este es solo uno de los requisitos previos en RFP . Al final, a nadie le preocupa que ningún proveedor ruso pase bajo la condición de interfaz 32 * 100GE. O preocupaciones?
Componente 8. CI / CD
En este punto, ya estamos listos para todos los dispositivos de red.Escribo "para todo" porque estamos hablando de versionar el estado de la red. E incluso si necesita cambiar la configuración de un solo conmutador, se calculan los cambios para toda la red. Obviamente, pueden ser cero para la mayoría de los nodos.Pero, como ya se mencionó anteriormente, no somos unos bárbaros para lanzar todo de una vez al mercado.La configuración generada primero debe pasar por el Pipeline CI / CD.CI / CD significa Integración continua, Despliegue continuo. Este es un enfoque en el que el equipo publica una versión principal importante más de una vez cada seis meses, reemplazando por completo la anterior, y regularmente Deploment introduce nuevas funcionalidades en lotes pequeños, cada uno de los cuales prueba exhaustivamente la compatibilidad, la seguridad y el rendimiento (Integración).
Para hacer esto, tenemos un sistema de control de versiones que monitorea los cambios de configuración, un laboratorio donde verificamos si el servicio al cliente está fallando, un sistema de monitoreo que verifica este hecho, y el último paso es implementar los cambios en la red de producción.Con la excepción de los equipos de depuración, absolutamente todos los cambios en la red deben pasar por la canalización de CI / CD: esta es nuestra garantía de una vida tranquila y una carrera larga y feliz.
Componente 9. Sistema de respaldo y rechazo
Bueno, no tengo que volver a hablar de copias de seguridad.Simplemente los agregaremos de acuerdo a la corona o al hecho de un cambio de configuración en el git.Pero la segunda parte es más interesante: alguien debería vigilar estas copias de seguridad. Y en algunos casos, este alguien tiene que ir y rotar todo como estaba, y en otros, maullar a alguien, ese trastorno.Por ejemplo, si hay un nuevo usuario que no está registrado en las variables, debe eliminarlo del hack. Y si es mejor no tocar la nueva regla de firewall, tal vez alguien simplemente activó la depuración, o tal vez un nuevo servicio, un desastre, no se registró de acuerdo con las reglas, pero la gente ya lo hizo.Todavía no nos escaparemos de un cierto pequeño delta en la escala de toda la red, a pesar de los sistemas de automatización y una mano de obra de acero. Para depurar problemas de todos modos, nadie traerá la configuración al sistema. Además, puede que ni siquiera sean provistos por el modelo de configuración.Por ejemplo, una regla de firewall para contar el número de paquetes en una IP específica, para localizar el problema, una configuración temporal completamente ordinaria.

Componente 10. Sistema de monitoreo
Al principio, no iba a cubrir el tema del monitoreo, que sigue siendo un tema voluminoso, controvertido y complejo. Pero en el camino, resultó que esto es una parte integral de la automatización. Y no puedes evitarlo incluso sin práctica.Desarrollar el pensamiento es una parte orgánica del proceso de CI / CD. Después de implementar la configuración en la red, debemos poder determinar si todo está bien ahora.Y no se trata solo y no tanto de las gráficas del uso de interfaces o la disponibilidad del host, sino de cosas más sutiles: la disponibilidad de las rutas necesarias, los atributos en ellas, la cantidad de sesiones BGP, vecinos OSPF, servicios de tiempo de actividad de extremo a extremo.¿Pero los syslogs en el servidor externo dejaron de plegarse, el agente SFlow se descompuso, las caídas en las colas comenzaron a crecer y la conexión entre cualquier par de prefijos se rompió?En otro artículo, reflexionamos sobre esto.
Conclusión
Como base, elegí uno de los diseños de red de centros de datos modernos: L3 Clos Fabric con BGP como protocolo de enrutamiento.Esta vez construiremos una red en Juniper, porque ahora la interfaz de JunOs es un vanlav.Vamos a complicar nuestras vidas usando solo herramientas de código abierto y una red de múltiples proveedores; por lo tanto, aparte del enebro, en el camino elegiré a otro tipo con suerte.El plan para las próximas publicaciones es algo como esto:primero hablaré sobre redes virtuales. En primer lugar, porque quiero, y en segundo lugar, porque sin esto, el diseño de la red de infraestructura no será muy claro.Luego sobre el diseño de la red en sí: topología, enrutamiento, políticas.Armemos el soporte de laboratorio.Consideremos y quizás practiquemos inicializar el dispositivo en la red.Y luego sobre cada componente en detalles íntimos.Y sí, no prometo terminar con elegancia este ciclo con una solución preparada. :)
Enlaces utiles
- Antes de profundizar en la serie, debe leer el libro de Natasha Samoilenko Python para ingenieros de redes . Y, tal vez, tomar un curso .
- También será útil leer el RFC sobre el diseño de fábricas de centros de datos de Facebook para la autoría de Peter Lapukhov.
- La documentación de arquitectura de Tungsten Fabric (anteriormente Open Contrail) le dará una idea de cómo funciona el Overlay SDN .
Gracias
Garganta Romana. Para comentarios y ediciones.Artyom Chernobay. Para KDPV