
Recientemente, ha habido varios artículos que critican a ImageNet, quizás el conjunto de imágenes más famoso utilizado para entrenar redes neuronales.
En el primer artículo, La aproximación de CNN con modelos de bolsa de características locales funciona sorprendentemente bien en ImageNet, los autores toman un modelo similar a la bolsa de palabras y usan fragmentos de la imagen como "palabras". Estos fragmentos pueden tener hasta 9x9 píxeles. Y al mismo tiempo, en dicho modelo, donde la información sobre la disposición espacial de estos fragmentos está completamente ausente, los autores obtienen una precisión del 70 al 86% (por ejemplo, la precisión de un ResNet-50 regular es ~ 93%).
En el segundo artículo de CNNs entrenados en ImageNet están sesgados hacia la textura, los autores concluyen que el conjunto de datos de ImageNet en sí mismo y la forma en que las personas y las redes neuronales perciben las imágenes son culpables de esto y sugieren usar un nuevo conjunto de datos: Stylized-ImageNet.
Con más detalle sobre lo que la gente ve en las imágenes y qué redes neuronales
ImageNet
El conjunto de datos ImageNet comenzó a crearse en 2006 por los esfuerzos del profesor Fei-Fei Li y continúa evolucionando hasta nuestros días. Por el momento, contiene alrededor de 14 millones de imágenes pertenecientes a más de 20 mil categorías diferentes.
Desde 2010, un subconjunto de este conjunto de datos, conocido como ImageNet 1K con ~ 1 millón de imágenes y miles de clases, se ha utilizado en el ImageNet Large Scale Visual Recognition Challenge (ILSVRC). En esta competencia, en 2012, AlexNet, una red neuronal convolucional, disparó con una precisión de top 1 del 60% y top 5 del 80%.
Es en este subconjunto del conjunto de datos que las personas del entorno académico miden su SOTA cuando ofrecen nuevas arquitecturas de red.
Un poco sobre el proceso de aprendizaje en este conjunto de datos. Hablaremos sobre el protocolo de capacitación en ImageNet en el entorno académico. Es decir, cuando en el artículo se nos muestran los resultados de un bloque SE, una red ResNeXt o DenseNet, el proceso se ve así: la red aprende durante 90 eras, la velocidad de aprendizaje disminuye en las eras 30 y 60, cada 10 veces, como optimizador se selecciona un SGD ordinario con una pequeña disminución de peso, solo se usan RandomCrop y HorizontalFlip de los aumentos, la imagen generalmente se redimensiona a 224x224 píxeles.
Aquí hay un ejemplo de script pytorch para capacitación en ImageNet.
BagNet
Volvamos a los artículos mencionados anteriormente. En el primero de ellos, los autores querían un modelo que fuera más fácil de interpretar que las redes profundas comunes. Inspirados en la idea de los modelos de bolsa de características, crean su propia familia de modelos: BagNets. Utilizando como base la red ResNet-50 habitual.
Reemplazando algunas convoluciones de 3x3 con 1x1 en ResNet-50, aseguran que el campo receptivo de neuronas en la última capa convolucional se reduzca significativamente, hasta 9x9 píxeles. Por lo tanto, limitan la información disponible para una neurona individual a un fragmento muy pequeño de toda la imagen, un parche de varios píxeles. Cabe señalar que para el ResNet-50 prístino, el tamaño del campo receptivo es de más de 400 píxeles, lo que cubre completamente la imagen, que generalmente cambia a 224x224 píxeles.
Este parche es el fragmento máximo de la imagen de la que el modelo podría extraer datos espaciales. Al final del modelo, todos los datos simplemente se resumieron y el modelo de ninguna manera pudo saber dónde se encuentra cada parche en relación con otros parches.
En total, se probaron tres variantes de redes con campo receptivo 9x9, 17x17 y 33x33. Y, a pesar de la completa falta de información espacial, tales modelos pudieron lograr una buena precisión en la clasificación en ImageNet. La precisión del Top 5 para los parches 9x9 fue del 70%, para 17x17 - 80%, para 33x33 - 86%. A modo de comparación, la precisión de ResNet-50 top-5 es aproximadamente del 93%.

La estructura del modelo se muestra en la figura anterior. Cada parche de qxqx3 píxeles cortados de la imagen se convierte en un vector 2048. A continuación, este vector se alimenta a la entrada de un clasificador lineal, que produce puntuaciones para cada una de las 1000 clases. Al recopilar las puntuaciones de cada parche en una matriz 2D, puede obtener un mapa de calor para cada clase y cada píxel de la imagen original. Los puntajes finales de la imagen se obtuvieron sumando el mapa de calor de cada clase.
Ejemplos de mapas de calor para algunas clases:

Como puede ver, la mayor contribución al beneficio de una clase en particular se realiza mediante parches ubicados en los bordes de los objetos. Los parches del fondo son casi ignorados. Hasta ahora, todo va bien.
Veamos los parches más informativos:

Por ejemplo, los autores tomaron cuatro clases. Para cada uno de ellos, se seleccionaron 2x7 parches más significativos (es decir, parches donde el puntaje de esta clase fue el más alto). La fila superior de 7 parches se toma de imágenes de solo la clase correspondiente, la inferior, de toda la muestra de imágenes.
Lo que se puede ver en estas imágenes es notable. Por ejemplo, para la clase de tencas (tencas, peces), los dedos son un rasgo característico. Sí, dedos humanos comunes sobre un fondo verde. Y todo porque hay un pescador en casi todas las imágenes con esta clase, que, de hecho, sostiene este pez en sus manos, mostrando un trofeo.
Para las computadoras portátiles, un rasgo característico son las teclas de letras. Las teclas de máquina de escribir también cuentan para esta clase.
Un rasgo característico de la portada de un libro son las letras sobre un fondo de color. Que sea incluso una inscripción en una camiseta o en una bolsa.
Parece que este problema no debería molestarnos. Dado que es inherente solo en una clase estrecha de redes con un campo receptivo muy limitado. Pero además, los autores calcularon la correlación entre logits (salidas de red antes del softmax final) asignado a cada clase BagNet con un campo receptivo diferente, y logits de VGG-16, que tiene un campo receptivo bastante grande. Y la encontraron bastante alta.
Correlación entre BagNets y VGG-16 Los autores se preguntaron si BagNet contiene alguna pista sobre cómo otras redes toman decisiones.
Para una de las pruebas, utilizaron una técnica como Image Scrambling. Que consistía en usar un generador de texturas basado en matrices de gramo para componer una imagen donde se guardan las texturas, pero falta información espacial.

VGG-16, entrenado en imágenes normales, hizo frente a esas imágenes revueltas bastante bien. Su precisión de top 5 cayó del 90% al 80%. Es decir, incluso las redes con un campo receptivo bastante grande prefirieron recordar texturas e ignorar la información espacial. Por lo tanto, su precisión no recayó en gran medida en las imágenes codificadas.
Los autores realizaron una serie de experimentos en los que compararon qué partes de las imágenes son más significativas para BagNet y otras redes (VGG-16, ResNet-50, ResNet-152 y DenseNet-169). Todo insinuó que otras redes, como BagNet, dependen de pequeños fragmentos de imágenes y cometen los mismos errores al tomar decisiones. Esto fue especialmente notable para redes no muy profundas como VGG.
Esta tendencia de las redes a tomar decisiones basadas en texturas, a diferencia de nosotros, las personas que prefieren la forma (ver la figura a continuación), llevó a los autores del segundo artículo a crear un nuevo conjunto de datos basado en ImageNet.
ImageNet estilizada
En primer lugar, los autores del artículo que usaron la transferencia de estilo crearon un conjunto de imágenes donde la forma (datos espaciales) y las texturas en una imagen se contradecían. Y comparamos los resultados de las personas y las redes de convolución profunda de diferentes arquitecturas en un conjunto de datos sintetizados de 16 clases.

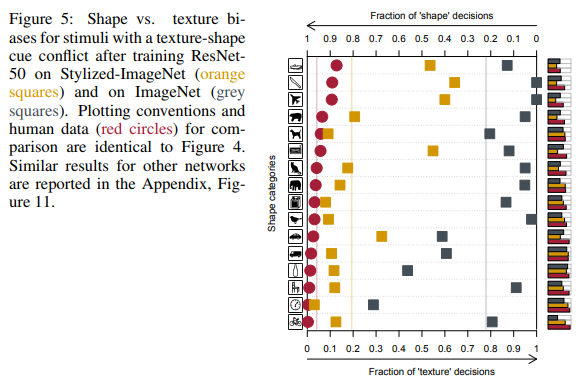
En la figura de la extrema derecha, la gente ve un gato, una red, un elefante.

Comparación de los resultados de personas y redes neuronales.
Como puede ver, las personas al asignar un objeto a una clase en particular se basaban en la forma de los objetos, las redes neuronales en las texturas. En la figura anterior, la gente vio un gato, una red, un elefante.
Sí, aquí puede encontrar fallas en el hecho de que las redes también son algo correctas y esto, por ejemplo, podría ser un elefante fotografiado de cerca con un tatuaje de un gato querido. Pero el hecho de que las redes cuando toman decisiones se comportan de manera diferente a las personas, los autores consideraron el problema y comenzaron a buscar formas de resolverlo.
Como se mencionó anteriormente, confiando solo en las texturas, la red puede lograr un buen resultado con un 86% de precisión entre los 5 mejores. Y no se trata de varias clases, donde las texturas ayudan a clasificar las imágenes correctamente, sino de la mayoría de las clases.
El problema está en ImageNet, ya que se mostrará más adelante que la red puede aprender la forma, pero no lo hace, ya que las texturas son suficientes para este conjunto de datos y las neuronas responsables de las texturas están en capas poco profundas, que son mucho más fáciles de entrenar
Utilizando esta vez un mecanismo de transferencia de estilo rápido AdaIN ligeramente diferente, los autores crearon un nuevo conjunto de datos: ImageNet estilizada. La forma de los objetos fue tomada de ImageNet y el conjunto de texturas de esta competencia en Kaggle . El script para la generación está disponible en el enlace .

Además, por brevedad, ImageNet se denominará IN , ImageNet estilizada como SIN .
Los autores tomaron ResNet-50 y tres BagNet con diferentes campos receptivos y entrenaron en un modelo separado para cada conjunto de datos.
Y esto es lo que hicieron:
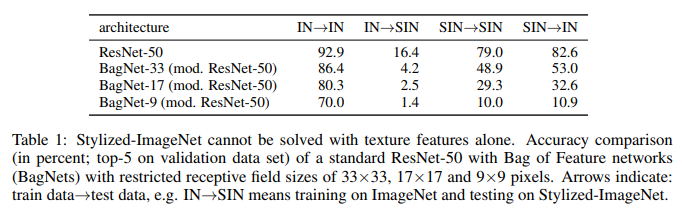
Lo que vemos aquí. ResNet-50 entrenado en IN está completamente incapacitado en SIN. Lo que confirma en parte que cuando se entrena en IN, la red se adapta a las texturas e ignora la forma de los objetos. Al mismo tiempo, el ResNet-50 entrenado en SIN se adapta perfectamente tanto a SIN como a IN. Es decir, si se ve privado de una ruta simple, la red sigue una ruta difícil: enseña la forma de los objetos.
BagNet finalmente ha comenzado a comportarse como se esperaba, especialmente en parches pequeños, ya que no tiene nada a lo que aferrarse: la información de textura simplemente falta en el SIN.
En esas dieciséis clases que se mencionaron anteriormente, ResNet-50, capacitado en SIN, comenzó a dar respuestas más similares a las que dan las personas:
Además de simplemente entrenar ResNet-50 en SIN, los autores trataron de entrenar la red en un conjunto mixto de SIN e IN, incluida la optimización por separado en IN puro.

Como puede ver, al usar SIN + IN para capacitación, los resultados mejoraron no solo en la tarea principal: la clasificación de imágenes en ImageNet, sino también en la tarea de detectar objetos en el conjunto de datos PASCAL VOC 2007.
Además, las redes capacitadas por SIN se han vuelto más resistentes a diversos ruidos en los datos.
Conclusión
Incluso ahora, en 2019, después de siete años de éxito con AlexNet, cuando las redes neuronales se utilizan ampliamente en la visión por computadora, cuando ImageNet 1K se convirtió de hecho en el estándar para evaluar el rendimiento de los modelos en el entorno académico, el mecanismo de cómo las redes neuronales toman decisiones no está del todo claro . Y cómo los conjuntos de datos en los que se formaron estas redes influyen en esto.
Los autores del primer artículo intentaron arrojar luz sobre cómo se toman tales decisiones en redes con arquitectura de bolsa de características con un campo receptivo limitado, que es más fácil de interpretar. Y, al comparar las respuestas de BagNet y las redes neuronales profundas habituales, llegamos a la conclusión de que los procesos de toma de decisiones en ellas son bastante similares.
Los autores del segundo artículo compararon cómo las personas y las redes neuronales perciben imágenes en las que la forma y las texturas se contradicen entre sí. Y sugirieron usar un nuevo conjunto de datos, Stylized ImageNet, para reducir las diferencias de percepción. Después de recibir como bonificación un aumento en la precisión de la clasificación en ImageNet y la detección en conjuntos de datos de terceros.
La conclusión principal se puede hacer de la siguiente manera: las redes que aprenden de las imágenes, que tienen la capacidad de recordar propiedades espaciales de los objetos de mayor nivel, prefieren una forma más fácil de lograr el objetivo: sobreajustar las texturas. Si el conjunto de datos en el que entrenan lo permite.
Además del interés académico, el problema del sobreajuste de texturas es importante para todos los que usamos modelos pre-entrenados para transferir el aprendizaje en sus tareas.
Una consecuencia importante de todo esto para nosotros es que no debe confiar en el peso de los modelos que generalmente se entrenan previamente en ImageNet, ya que para la mayoría de ellos se utilizaron aumentos bastante simples, que de ninguna manera contribuyen a deshacerse del sobreajuste. Y es mejor, si es posible, tener modelos entrenados con aumentos más serios o ImageNet + ImageNet estilizados en el nido. Para poder comparar cuál es el más adecuado para nuestra tarea actual.