
Muchas personas están acostumbradas a calificar una película en KinoPoisk o imdb después de verla, y las secciones "También comprado con este producto" y "Productos populares" se encuentran en cualquier tienda en línea. Pero hay tipos de recomendaciones menos familiares. En este artículo hablaré sobre qué tareas recomiendan los sistemas de recomendación, dónde ejecutarlas y qué buscar en Google.
¿Qué recomendamos?
¿Qué sucede si queremos recomendar una
ruta que sea
cómoda para el usuario ? Los diferentes aspectos del viaje son importantes para diferentes usuarios: la disponibilidad de asientos, el tiempo de viaje, el tráfico, el aire acondicionado, una hermosa vista desde la ventana. Una tarea inusual, pero está bastante claro cómo construir un sistema de este tipo.
¿Qué pasa si recomendamos las
noticias ? Las noticias se vuelven obsoletas rápidamente: debe mostrar a los usuarios los últimos artículos mientras sigan siendo relevantes. Es necesario comprender el contenido del artículo. Ya mas dificil.
¿Y si recomendamos
restaurantes basados en comentarios? Pero recomendamos no solo el restaurante, sino también platos específicos que vale la pena probar. También puede dar recomendaciones a los restaurantes sobre lo que vale la pena mejorar.
¿Qué sucede si
ampliamos la tarea y tratamos de responder la pregunta: "¿Qué producto será de interés para el grupo más grande de personas?". Se está volviendo muy inusual y no está claro de inmediato cómo resolver esto.
De hecho, hay muchas variaciones de la tarea de recomendaciones y cada una tiene sus propios matices. Puedes recomendar cosas completamente inesperadas. Mi ejemplo favorito es recomendar
vistas previas en Netflix .

Tarea más estrecha
Tome la tarea familiar y familiar de recomendar música. ¿Qué es exactamente lo que queremos recomendar?

En este collage puedes encontrar ejemplos de varias recomendaciones de Spotify, Google y Yandex.
- Destacando intereses homogéneos en el Daily Mix
- Radar de lanzamiento de noticias personalizado, nuevos lanzamientos recomendados, estreno
- Selección personal de lo que te gusta - Lista de reproducción del día
- Selección personal de pistas que el usuario aún no ha escuchado - Discover Weekly, Dejavu
- Una combinación de los dos puntos anteriores con un sesgo en nuevas pistas: I'm Feeling Lucky
- Ubicado en la biblioteca, pero aún no escuchado - Caché
- Tus mejores canciones 2018
- Las canciones que escuchaste a los 14 años y que dieron forma a tus gustos
- Pistas que te pueden gustar, pero que difieren de lo que el usuario suele escuchar
- Pistas de artistas que actúan en tu ciudad
- Colecciones de estilo
- Selección de actividad y estado de ánimo.
Y seguro que puedes pensar en otra cosa. Incluso si somos absolutamente capaces de predecir qué pistas le gustan al usuario, la pregunta sigue siendo en qué forma y en qué diseño deben emitirse.
Puesta en escena clásica
En el enunciado clásico del problema, todo lo que tenemos es una matriz de calificación de elementos de usuario. Es muy escaso y nuestra tarea es completar los valores faltantes. Por lo general, el RMSE de la calificación pronosticada se usa como una métrica, sin embargo,
existe la opinión de que esto no es del todo correcto y que las características de la recomendación en su conjunto deben tenerse en cuenta y no la precisión de predecir un número específico.
¿Cómo evaluar la calidad?
Evaluación en línea
La forma más preferible de evaluar la calidad del sistema es la verificación directa de los usuarios en el contexto de las métricas comerciales. Este puede ser el CTR, el tiempo que pasa en el sistema o la cantidad de compras. Pero los experimentos con los usuarios son caros, y no quiero implementar un algoritmo malo ni siquiera para un pequeño grupo de usuarios, por lo que utilizan métricas de calidad fuera de línea antes de las pruebas en línea.
Evaluación fuera de línea
Las métricas de clasificación, como MAP @ k y nDCG @ k, generalmente se usan como métricas de calidad.
Relevance en el contexto de
MAP@k es un valor binario, y en el contexto de
nDCG@k puede haber una escala de calificación.
Pero, además de la precisión de la predicción, podemos estar interesados en otras cosas:
- veragecobertura: la proporción de bienes emitidos por el recomendante,
- personalización: cuán diferentes son las recomendaciones entre usuarios,
- diversidad: cuán diversos son los productos dentro de la recomendación.
En general, hay una buena revisión de las métricas.
¿Qué tan bueno es su sistema de recomendación? Una encuesta sobre evaluaciones en recomendación . Se puede encontrar un ejemplo de formalización de métricas de novedad en
Clasificación y relevancia en Novedad y métricas de diversidad para sistemas de recomendación .
Datos
Comentarios explícitos
La matriz de calificación es un ejemplo de datos explícitos. Me gusta, no me gusta, calificación: el usuario mismo ha expresado claramente el grado de su interés en el artículo. Tales datos son generalmente escasos. Por ejemplo, en el
Rekko Challenge en los datos de prueba, solo el 34% de los usuarios tienen al menos una marca.
Retroalimentación implícita
Hay mucha más información sobre preferencias implícitas: vistas, clics, marcadores, configuración de notificaciones. Pero si el usuario vio la película, solo significa que antes de ver la película le pareció lo suficientemente interesante. No podemos sacar conclusiones directas sobre si le gustó o no a la película.
Funciones de pérdida para el aprendizaje
Para utilizar la retroalimentación implícita, ideamos métodos de enseñanza apropiados.
Ranking personalizado bayesiano
Artículo originalSe sabe con qué elementos interactuó el usuario. Asumimos que estos son ejemplos positivos que le gustaron. Todavía hay muchos elementos con los que el usuario no ha interactuado. No sabemos cuáles serán de interés para el usuario y cuáles no, pero ciertamente sabemos que no todos estos ejemplos resultarán positivos. Hacemos una generalización aproximada y consideramos la ausencia de interacción como un ejemplo negativo.
Tomaremos muestras de triples {usuario, elemento positivo, elemento negativo} y multaremos el modelo si un ejemplo negativo tiene una calificación más alta que uno positivo.
Rango aproximado ponderado por parejas
Agregar a la idea anterior la tasa de aprendizaje adaptativo. Evaluaremos la capacitación del sistema en función del número de muestras que tuvimos que buscar para encontrar un ejemplo negativo para el par dado {usuario, ejemplo positivo}, que el sistema calificó más que positivo.
Si encontramos ese ejemplo la primera vez, entonces la multa debería ser grande. Si tuvo que buscar durante mucho tiempo, entonces el sistema ya está funcionando bien y no necesita multar tanto.
¿En qué más vale la pena pensar?
Arranque en frío
Tan pronto como hemos aprendido a hacer predicciones para los usuarios y productos existentes, surgen dos preguntas: "¿Cómo recomendar un producto que nadie ha visto todavía?" y "¿Qué debo recomendar a un usuario que aún no tiene una calificación única?". Para resolver este problema, intentan extraer información de otras fuentes. Estos pueden ser datos sobre un usuario de otros servicios, un cuestionario durante el registro, información sobre un elemento de su contenido.
En este caso, hay tareas para las cuales el estado de un arranque en frío es constante. En los Recomendaciones basadas en sesiones, debe tener tiempo para comprender algo sobre el usuario durante el tiempo que está en el sitio. Los artículos nuevos aparecen constantemente en los recomendadores de noticias o productos de moda, mientras que los artículos antiguos se vuelven rápidamente obsoletos.
Cola larga
Si para cada elemento calculamos su popularidad en forma de la cantidad de usuarios que interactuaron con él o dieron una calificación positiva, muy a menudo obtendremos un gráfico como en la imagen:
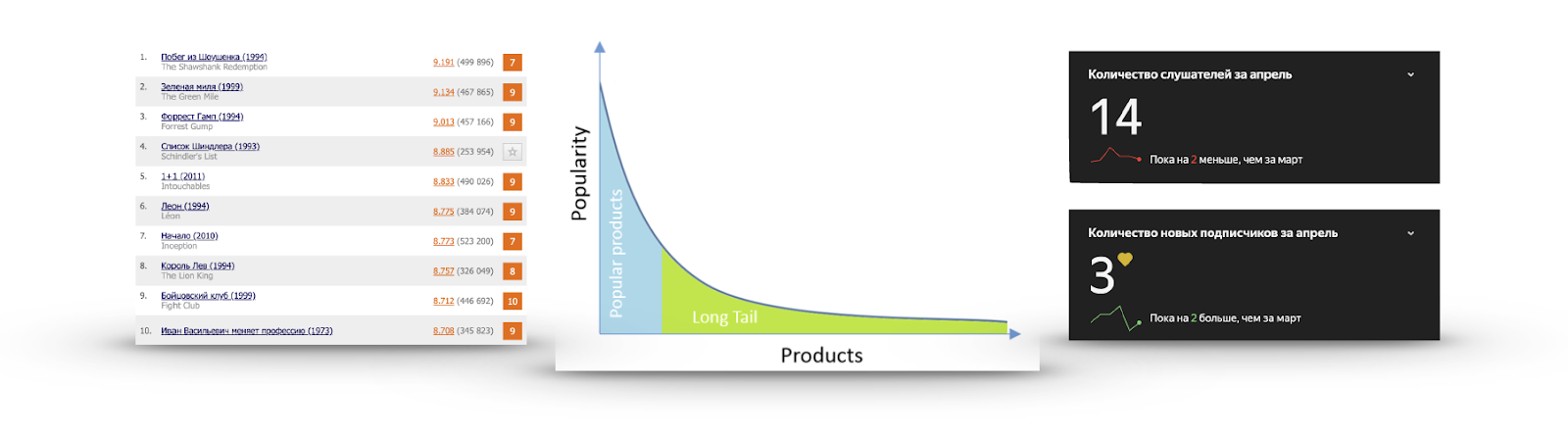
Hay un número muy pequeño de artículos que todos conocen. No tiene sentido recomendarlos, porque es muy probable que el usuario ya los haya visto y simplemente no haya dado una calificación, los conozca y los vaya a ver, o haya decidido firmemente no mirarlos. Vi el avance de la Lista de Schindler más de una vez, pero no iba a verlo.
Por otro lado, la popularidad está cayendo muy rápidamente, y casi nadie ha visto la gran mayoría de los artículos. Hacer recomendaciones de esta parte es más útil: hay contenido interesante que es poco probable que el usuario se encuentre. Por ejemplo, a la derecha están las estadísticas de escucha de uno de mis grupos favoritos en Yandex.Music.
Exploración vs Explotación
Digamos que sabemos exactamente lo que le gusta al usuario. ¿Esto significa que deberíamos recomendar lo mismo? Existe la sensación de que tales recomendaciones se volverán rápidamente aburridas y, a veces, vale la pena mostrar algo nuevo. Cuando recomendamos lo que exactamente debería gustar es la explotación. Si intentamos agregar algo menos popular a las recomendaciones o de alguna manera diversificarlas, esto es exploración. Quiero equilibrar estas cosas.
Recomendaciones no personalizadas
La opción más fácil es recomendar lo mismo a todos.
Ordenar por popularidad
Puntuación = (Calificaciones positivas) - (Calificaciones negativas)
Puede restar disgustos de me gusta y ordenarlos. Pero en este caso, no tenemos en cuenta su porcentaje. Existe la sensación de que 200 likes de 50 disgustos no son lo mismo que 1200 likes y 1050 disgustos.
Puntuación = (Calificaciones positivas) / (Calificaciones totales)
Puede dividir la cantidad de Me gusta por la cantidad de No me gusta, pero en este caso no tenemos en cuenta la cantidad de calificaciones y un producto con una calificación de 5 puntos tendrá una calificación más alta que un producto muy popular con una calificación promedio de 4.8.
¿Cómo
no ordenar por la calificación promedio y considerar el número de calificaciones? Calcule el intervalo de confianza: "Según las estimaciones disponibles, ¿es la probabilidad de una probabilidad del 95% de la verdadera proporción de calificaciones positivas al menos qué?" La respuesta a esta pregunta fue dada por Edwin Wilson en 1927.
- porcentaje observado de calificaciones positivas
- 1-alpha cuantil de la distribución normal
Compatibilidad
La selección de conjuntos de productos que se encuentran con frecuencia incluye un grupo completo de tareas de minería de patrones:
minería de patrones periódica, minería de reglas secuenciales, minería de patrones secuenciales, minería de conjuntos de elementos de alta utilidad ,
minería de conjuntos de elementos frecuentes (análisis de cesta) . Cada tarea específica tendrá sus propios
métodos , pero si son más o menos generalizados, los algoritmos para encontrar conjuntos frecuentes realizan una búsqueda abreviada de amplitud, tratando de no clasificar las opciones obviamente malas.
Los conjuntos raros se cortan en el soporte de límite dado: el número o la frecuencia de aparición del conjunto en los datos.
Después de resaltar el conjunto de elementos frecuentes, la calidad de su dependencia se evalúa utilizando las métricas Levantamiento o Confindencia (a, b) / Confianza (! A, b). Su objetivo es eliminar las dependencias falsas.
Por ejemplo, los plátanos a menudo se pueden encontrar en la canasta de comestibles junto con los productos enlatados. Pero el punto no está en una conexión especial, sino en el hecho de que los plátanos son populares por sí mismos, y esto debe tenerse en cuenta al buscar coincidencias.
Recomendaciones personalizadas
Contenido basado
La idea de un enfoque basado en contenido es crear para él un vector de sus preferencias en el espacio de objetos basado en el historial de acciones del usuario y recomendar productos cercanos a este vector.
Es decir, el artículo debe tener alguna descripción característica. Por ejemplo, estos pueden ser géneros de películas. La historia de los gustos y disgustos de las películas forma un vector de preferencia,
destacando algunos géneros y evitando otros. Al comparar el vector del usuario y el vector del elemento, puede hacer una clasificación y obtener recomendaciones.
Filtrado colaborativo

El filtrado colaborativo supone una matriz de evaluación de elementos de usuario. La idea es encontrar los "vecinos" más similares para cada usuario y llenar los vacíos de un usuario específico ponderando el promedio de las calificaciones de "vecinos".
Del mismo modo, puede observar la similitud de los artículos, creyendo que personas similares les gustan a los artículos similares. Técnicamente, esto será simplemente una consideración de la matriz de estimaciones transpuesta.
Los usuarios usan la escala de calificación de manera diferente: alguien nunca la pone por encima de ocho y alguien usa la escala completa. Es útil tener esto en cuenta y, por lo tanto, es posible predecir no la calificación en sí, sino una desviación de la calificación promedio.
O puede normalizar las estimaciones por adelantado.
Factorización matricial
Por matemática,
sabemos que cualquier matriz puede descomponerse en el producto de tres matrices. Pero la matriz de calificaciones es muy escasa, el 99% es común. Y SVD no sabe qué brechas hay. Llenarlos con un valor promedio no es muy deseable. Y, en general, no estamos muy interesados en la matriz de valores singulares: solo queremos obtener una vista oculta de los usuarios y los objetos, que, cuando se multiplica, se aproximará a la calificación real. Puede descomponerse inmediatamente en dos matrices.
¿Qué hacer con los pases? Martillo sobre ellos. Resultó que puede entrenar para obtener clasificaciones aproximadas por métrica RMSE usando SGD o ALS, ignorando por completo las omisiones. El primer algoritmo de este tipo es
Funk SVD , que se inventó en 2006 para resolver la competencia de Netflix.
Premio de Netflix
Premio Netflix : un evento importante que dio un fuerte impulso al desarrollo de sistemas de recomendación. El objetivo de la competencia es superar el sistema de recomendación Cinematch RMSE existente en un 10%. Con este fin, se proporcionó un gran conjunto de datos que contenía 100 millones de calificaciones en ese momento. La tarea puede no parecer tan difícil, pero para lograr la calidad requerida fue necesario redescubrir la competencia dos veces: solo se recibió una solución durante 3 años de la competencia. Si fuera necesario obtener una mejora del 15%, quizás esto no hubiera sido posible con los datos proporcionados.
Durante la competencia, se encontraron
algunas características
interesantes en los datos. El gráfico muestra la calificación promedio de las películas según la fecha en que aparecieron en el catálogo de Netflix. La brecha aparente está asociada con el hecho de que en este momento Netflix cambió de una escala objetiva (una mala película, una buena película) a una subjetiva (no me gustó, realmente me gustó). Las personas son menos críticas cuando expresan su evaluación, en lugar de caracterizar un objeto.
Este gráfico muestra cómo cambia la calificación promedio de la película después del lanzamiento. Se puede ver que durante 2000 días el puntaje aumenta en 0.2. Es decir, después de que la película ha dejado de ser nueva, aquellos que están bastante seguros de que le gustará la película, que aumenta la calificación, comienzan a verla.
El primer premio intermedio fue tomado por un equipo de especialistas de AT&T - Korbell. Después de 2000 horas de trabajo y compilando un conjunto de 107 algoritmos, lograron una mejora del 8.43%.
Entre los modelos había una variación de SVD y RBM, que en sí mismos proporcionaban la mayor parte de la información. Los 105 algoritmos restantes mejoraron solo una centésima parte de la métrica. Netflix adaptó estos dos algoritmos para sus volúmenes de datos y todavía los usa como parte del sistema.
En el segundo año de la competencia, los dos equipos se fusionaron y ahora Bellkor se llevó el premio en BigChaos. Atacaron un total de 207 algoritmos y mejoraron la precisión en otra centésima, alcanzando un valor de 0.8616. La calidad requerida aún no se logra, pero ya está claro que el próximo año todo debería funcionar.
Tercer año En combinación con otro equipo más, renombrando el Caos Pragmático de Bellkor y logrando la calidad requerida, ligeramente inferior a The Ensemble. Pero esto es solo la parte pública del conjunto de datos.
En el lado oculto, resultó que la precisión de estos equipos coincide con el cuarto decimal, por lo que el ganador fue determinado por una diferencia de compromisos de 20 minutos.
Netflix pagó el millón prometido a los ganadores, pero nunca
utilizó la solución resultante . La implementación del conjunto resultó ser demasiado costosa y no tiene muchos beneficios: después de todo, solo dos algoritmos ya proporcionan la mayor parte del aumento en la precisión. Y lo más importante: al final de la competencia en 2009, Netflix ya había comenzado a participar en su servicio de transmisión además de alquilar un DVD durante dos años. Tenían muchas otras tareas y datos que podían usar en su sistema. Sin embargo, su servicio de alquiler de correo en DVD todavía
atiende a 2.7 millones de suscriptores felices .
Redes neuronales
En los sistemas de recomendación modernos, una pregunta frecuente es cómo tener en cuenta varias fuentes de información explícitas e implícitas. A menudo hay datos adicionales sobre el usuario o elemento y desea utilizarlos. Las redes neuronales son una buena forma de contabilizar dicha información.
Sobre el tema del uso de redes para recomendaciones, debe prestar atención a la revisión del
Sistema de recomendaciones basado en aprendizaje profundo: una encuesta y nuevas perspectivas . Describe ejemplos del uso de una gran cantidad de arquitecturas para diversas tareas.
Hay muchas arquitecturas y enfoques. Uno de los nombres repetidos es
DSSM . También me gustaría mencionar el
filtrado colaborativo atento .
ACF propone introducir dos niveles de atenuación:
- Incluso con las mismas calificaciones, algunos elementos contribuyen más a sus preferencias que otros.
- Los artículos no son atómicos, sino compuestos de componentes. Algunos tienen un mayor impacto en la evaluación que otros. La película puede ser interesante solo debido a la presencia de un actor favorito.
Los bandidos multi-armados son uno de los temas más populares de los últimos tiempos. Lo que son bandidos multi-armados se puede leer en un artículo sobre
Habré o en el
Medio .
Cuando se aplica a las recomendaciones, la tarea Contexto-Bandido sonará así: "Alimentamos al usuario y los vectores de contexto del elemento a la entrada del sistema, queremos maximizar la probabilidad de interacción (clics, compras) para todos los usuarios a lo largo del tiempo, realizando actualizaciones frecuentes de la política de recomendación". Esta formulación resuelve naturalmente el problema de exploración vs explotación y le permite implementar rápidamente estrategias óptimas para todos los usuarios.
A raíz de la popularidad de la arquitectura de transformadores, también hay intentos de usarlos en las recomendaciones.
El siguiente ítem de recomendación con auto atención intenta combinar las preferencias de los usuarios a largo plazo y recientes para mejorar las recomendaciones.
Las herramientas
Las recomendaciones no son un tema tan popular como CV o PNL, por lo que para usar las arquitecturas de cuadrícula más recientes tendrá que implementarlas usted mismo o esperar que la implementación del autor sea bastante conveniente y comprensible. Sin embargo, algunas herramientas básicas siguen ahí:
Conclusión
Los sistemas de recomendación se han alejado mucho de la declaración estándar sobre cómo completar la matriz de evaluaciones, y cada área específica tendrá sus propios matices. Esto introduce dificultades, pero también agrega interés. Además, puede ser difícil separar el sistema de recomendación del producto en su conjunto. De hecho, no solo la lista de elementos es importante, sino también el método y el contexto de la presentación. Qué, cómo, a quién y cuándo recomendar. Todo esto determina la impresión de interacción con el servicio.