¡Hola, ciudadanos de Habrovsk!
El curso para
desarrolladores de Golang ya está comenzando en OTUS hoy
, y consideramos que esta es una gran ocasión para compartir otra publicación útil sobre el tema. Hoy hablemos sobre el enfoque de Go a los errores. ¡Empecemos!

Dominar el manejo pragmático de errores en su código Go
 Esta publicación es parte de la serie Before Getting Started, donde exploramos el mundo de Golang, compartimos consejos e ideas que debes saber al escribir código en Go para que no tengas que rellenar tus propios baches.
Esta publicación es parte de la serie Before Getting Started, donde exploramos el mundo de Golang, compartimos consejos e ideas que debes saber al escribir código en Go para que no tengas que rellenar tus propios baches.Supongo que ya tiene al menos una experiencia básica con Go, pero si siente que en algún momento se encontró con un material de discusión desconocido, no dude en hacer una pausa, explorar el tema y volver.
Ahora que hemos despejado nuestro camino, ¡vamos!
El enfoque de Go para el manejo de errores es una de las características más controvertidas y mal utilizadas. En este artículo, aprenderá el enfoque de Go a los errores y comprenderá cómo funcionan "bajo el capó". Aprenderá algunos enfoques diferentes, consulte el código fuente de Go y la biblioteca estándar para averiguar cómo se manejan los errores y cómo trabajar con ellos. Aprenderá por qué las aserciones de tipo juegan un papel importante en su manejo y verá los próximos cambios en el manejo de errores que planea introducir en Go 2.

Entrada
Lo primero es lo primero: los errores en Go no son una excepción.
Dave Cheney escribió una
publicación épica en el blog sobre esto, así que lo remito y lo resumo: en otros idiomas no puede estar seguro de si una función puede lanzar una excepción o no. En lugar de lanzar excepciones, las funciones Go admiten
múltiples valores de retorno y, por convención, esta característica generalmente se usa para devolver el resultado de una función junto con una variable de error.

Si por alguna razón su función puede fallar, probablemente debería devolverle el tipo de
error previamente declarado. Por convención, devolver un error indica al que llama sobre el problema, y devolver nulo no se considera un error. Por lo tanto, hará que la persona que llama entienda que ha surgido un problema y que debe solucionarlo: quien llama a su función, sabe que no debe confiar en el resultado antes de verificar un error. Si el error no es nulo, está obligado a verificarlo y procesarlo (registrar, devolver, reparar, llamar a algún tipo de mecanismo de reintento / limpieza, etc.).
 (3 // manejo de errores
(3 // manejo de errores
5 // continuación)Estos fragmentos son muy comunes en Go, y algunos los consideran como código repetitivo. El compilador trata las variables no utilizadas como errores de compilación, por lo que si no va a verificar si hay errores, debe asignarlos a
un identificador vacío . Pero no importa cuán conveniente sea, los errores no deben ignorarse.
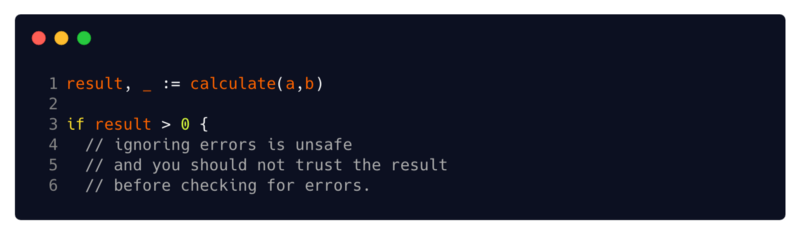 (4 // ignorar los errores no es seguro, y no debe confiar en el resultado antes de buscar errores)no se puede confiar en el resultado hasta que se comprueben los errores
(4 // ignorar los errores no es seguro, y no debe confiar en el resultado antes de buscar errores)no se puede confiar en el resultado hasta que se comprueben los erroresEl error devuelto junto con los resultados, junto con el estricto sistema de tipo Go, complica enormemente la escritura de código etiquetado. Siempre debe suponer que el valor de una función está dañado, a menos que haya verificado el error que devolvió, y al asignar el error a un identificador vacío, ignora explícitamente que el valor de su función puede estar dañado.
 La identificación vacía es oscura y está llena de horrores.
La identificación vacía es oscura y está llena de horrores.Go tiene mecanismos de
panic y
recover , que también se describen en
otra publicación detallada del blog de Go . Pero no están destinados a simular excepciones. Según Dave,
"cuando entras en pánico en Go, realmente entras en pánico: este no es el problema de otra persona, esto ya es un jugador". Son fatales y conducen a un bloqueo en su programa. Rob Pike acuñó el dicho "No entres en pánico", que habla por sí mismo: probablemente deberías evitar estos mecanismos y devolver los errores.
"Los errores son los significados".
“No solo verifique los errores, sino que los maneje con elegancia”.
"No entres en pánico"
todos los dichos de Rob Pike
Debajo del capó
Interfaz de errorBajo el capó, el tipo de error es una
interfaz simple con un método , y si no está familiarizado con él, le recomiendo ver
esta publicación en el blog oficial de Go.
 interfaz de error de la fuente
interfaz de error de la fuenteCometer tus propios errores no es difícil. Existen varios enfoques para las estructuras de usuario que implementan el método de
string Error() . Cualquier estructura que implemente este método único se considera un valor de error válido y se puede devolver como tal.
Veamos algunos de estos enfoques.
Error incorporado Estructura de cadena
La implementación más utilizada y extendida de la interfaz de error es la estructura
errorString . Esta es la implementación más fácil que se te ocurra.
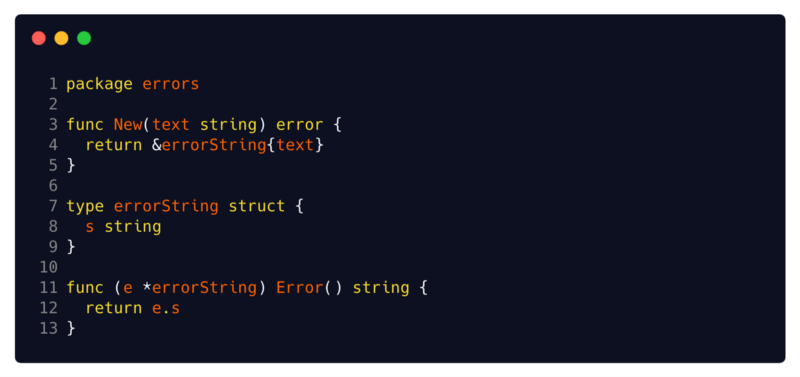
Fuente:
código fuente GoPuede ver su implementación simplificada
aquí . Todo lo que hace es contener una
string , y esta cadena es devuelta por el método
Error . Podemos formatear este error de cadena sobre la base de algunos datos, por ejemplo, usando
fmt.Sprintf . Pero aparte de esto, no contiene ninguna otra característica. Si aplicó
errores. Nuevo o
fmt.Errorf , entonces ya lo ha
usado .
 (13 // salida :)intentar
(13 // salida :)intentargithub.com/pkg/errors
Otro ejemplo simple es el
paquete pkg / errors . No debe confundirse con el paquete de
errors incorporado que aprendió anteriormente, este paquete proporciona características importantes adicionales, como ajuste de errores, expansión, formateo y registro de seguimiento de pila. Puede instalar el paquete ejecutando
go get github.com/pkg/errors .

En los casos en que necesite adjuntar el seguimiento de pila o la información de depuración necesaria a sus errores, el uso de las
Errorf New o
Errorf este paquete proporciona errores que ya están escritos en su seguimiento de pila, y también puede adjuntar metadatos simples al usarlo capacidades de formateo.
Errorf implementa la interfaz
fmt.Formatter , es decir, puede formatearla usando las runas del paquete
fmt (
%s ,
%v ,
%+v , etc.).
 (// 6 o alternativa)
(// 6 o alternativa)Este paquete también presenta las
errors.Wrapf errors.Wrap y
errors.Wrapf . Estas funciones agregan contexto al error usando un mensaje y un seguimiento de pila en el lugar donde fueron llamadas. Por lo tanto, en lugar de simplemente devolver el error, puede envolverlo con contexto y datos de depuración importantes.
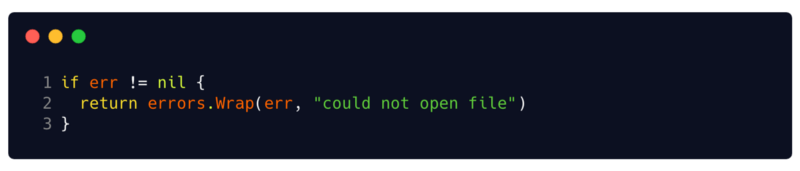
Los contenedores de errores de otros errores admiten el método de
Cause() error , que devuelve su error interno. Además, se pueden usar con
errors.Cause(err error) error Función de
errors.Cause(err error) error , que extrae el error interno principal en el error de ajuste.
Manejo de errores
Aprobación de tipo
Las aserciones de
tipo juegan un papel importante cuando se trata de errores. Los usará para extraer información del valor de la interfaz, y dado que el manejo de errores está asociado con las implementaciones de la interfaz de
error , la implementación de declaraciones de
error es una herramienta muy conveniente.
Su sintaxis es la misma para todos sus propósitos:
x.(T) si
x tiene un tipo de interfaz.
x.(T) establece que
x no
x nil y que el valor almacenado en
x es de tipo
T En las próximas secciones, veremos dos formas de usar sentencias de tipo: con un tipo
T específico y con una interfaz de tipo
T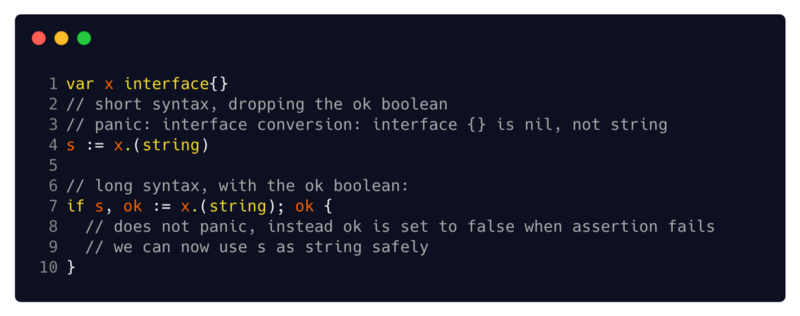 (2 // sintaxis abreviada omitiendo la variable booleana ok
(2 // sintaxis abreviada omitiendo la variable booleana ok
3 // pánico: conversión de interfaz: la interfaz {} es nula, no cadena
6 // sintaxis extendida con booleano ok
8 // no entra en pánico, en cambio establece ok falso cuando la declaración es falsa
9 // ahora podemos usar con seguridad s como una cadena)sandbox: pánico con sintaxis acortada , sintaxis extendida seguraNota de sintaxis adicional: una aserción de tipo se puede usar con una sintaxis acortada (que entra en pánico cuando falla una declaración) o una sintaxis extendida (que usa el valor lógico OK para indicar éxito o fracaso). Siempre recomiendo tomar alargado en lugar de acortado, ya que prefiero verificar la variable OK y no lidiar con el pánico.
Aprobación de tipo T
Una declaración de tipo
x.(T) con una interfaz de tipo
T confirma que
x implementa la interfaz de
T Por lo tanto, puede garantizar que el valor de la interfaz implemente la interfaz, y solo si es así, puede usar sus métodos.
 (5 ... // afirme que x implementa la interfaz de resolución
(5 ... // afirme que x implementa la interfaz de resolución
6 ... // aquí ya podemos usar este método de forma segura)Para entender cómo se puede usar esto, echemos un vistazo a
pkg/errors nuevamente. Ya conoce este paquete de error, así que profundicemos en los
errors.Cause(err error) error función de
errors.Cause(err error) error .
Esta función recibe un error y extrae el error más interno que sufre (el que ya no sirve como envoltorio para otro error). Esto puede parecer primitivo, pero hay muchas cosas excelentes que puede aprender de esta implementación:

fuente:
paquete / erroresLa función recibe el valor de error y no puede suponer que el argumento de
err que recibe es un error de envoltura (soportado por el método
Cause ). Por lo tanto, antes de llamar al método
Cause , debe asegurarse de que está lidiando con un error que implementa este método. Al realizar una declaración de tipo en cada iteración del bucle for, puede asegurarse de que la variable
cause compatible con el método
Cause , y puede continuar extrayendo errores internos hasta encontrar un error que no tenga
Cause .
Al crear una interfaz local simple que contenga solo los métodos que necesita y aplicarle aserciones, su código se separa de otras dependencias. El argumento que recibió no tiene que ser una estructura conocida, solo tiene que ser un error. Cualquier tipo que implemente los métodos
Error y
Cause . Por lo tanto, si implementa el método
Cause en su tipo de error, puede usar esta función con él sin ralentizaciones.
Sin embargo, hay una pequeña falla a tener en cuenta: las interfaces están sujetas a cambios, por lo que debe mantener cuidadosamente el código para que no se violen sus declaraciones. No olvide definir sus interfaces donde las usa, para mantenerlas esbeltas y ordenadas, y estará bien.
Finalmente, si solo necesita un método, a veces es más conveniente hacer una declaración en una interfaz anónima que contenga solo el método en el que confía, es decir
v, ok := x.(interface{ F() (int, error) }) . El uso de interfaces anónimas puede ayudar a separar su código de posibles dependencias y protegerlo de posibles cambios en las interfaces.
Tipo T y aprobación de interruptor de tipo
Prefacio esta sección introduciendo dos patrones similares de manejo de errores que sufren varias fallas y trampas. Esto no significa que no sean comunes. Ambos pueden ser herramientas convenientes en proyectos pequeños, pero no se escalan bien.
La primera es la segunda versión de la aserción de tipo: se realiza una aserción de tipo
x.(T) con un tipo
T específico. Afirma que el valor de
x es del tipo
T , o se puede convertir al tipo
T (2 // podemos usar v como mypkg.SomeErrorType)
(2 // podemos usar v como mypkg.SomeErrorType)Otro es el patrón de
cambio de tipo . Type Switch combina una declaración de cambio con una declaración de tipo utilizando la palabra clave de
type reservada. Son especialmente comunes en el manejo de errores, donde conocer el tipo básico de un error variable puede ser muy útil.
 (3 // procesamiento ...
(3 // procesamiento ...
5 // procesamiento ...)El gran inconveniente de ambos enfoques es que ambos conducen al enlace de código con sus dependencias. Ambos ejemplos deberían estar familiarizados con la estructura
SomeErrorType (que obviamente debería exportarse) y deberían importar el paquete
mypkg .
En ambos enfoques, al manejar sus errores, debe estar familiarizado con el tipo e importar su paquete. La situación se agrava cuando se trata de errores en envoltorios, donde la causa del error puede ser un error derivado de una dependencia interna que no conoce y que no debe conocer.
 (7 // procesamiento ...
(7 // procesamiento ...
9 // procesamiento ...)Type Switch distingue entre
*MyStruct y
MyStruct . Por lo tanto, si no está seguro de si está tratando con un puntero o una instancia real de una estructura, deberá proporcionar ambas opciones. Además, como en el caso de los interruptores normales, los casos en Type Switch no fallan, pero a diferencia del Type Switch habitual, el uso de
fallthrough prohibido en Type Switch, por lo que debe usar una coma y proporcionar ambas opciones, lo cual es fácil de olvidar.

Para resumir
Eso es todo! ¡Ahora está familiarizado con los errores y debe estar preparado para corregir cualquier error que su aplicación Go pueda arrojar (o realmente devolver) a su camino!
Ambos paquetes de
errors proporcionan enfoques simples pero importantes para los errores en Go, y si satisfacen sus necesidades, son una excelente opción. Puede implementar fácilmente sus propias estructuras de errores y aprovechar el manejo de errores de Go combinándolos con
pkg/errors .
Cuando escala errores simples, el uso correcto de las declaraciones de tipo puede ser una gran herramienta para manejar varios errores. Ya sea usando Type Switch o validando el comportamiento del error y verificando las interfaces que implementa.
Que sigue
El manejo de errores en Go ahora es muy relevante. Ahora que tiene los conceptos básicos, es posible que se pregunte qué nos espera para manejar los errores de Go.
La próxima versión de Go 2 presta mucha atención a esto, y ya puedes echar un vistazo a la
versión borrador . Además, durante
dotGo 2019, Marcel van Lojuizen tuvo una excelente conversación sobre un tema que no puedo dejar de recomendar:
"Valores de error GO 2 hoy" .
Obviamente, hay muchos más enfoques, consejos y trucos, ¡y no puedo incluirlos todos en una publicación! A pesar de esto, ¡espero que lo hayan disfrutado, y los veré en el próximo episodio
de Before Getting Started !
Y ahora tradicionalmente esperando sus comentarios.