Cada año en Moscú, se celebra la conferencia de
Diálogo , en la que participan lingüistas y especialistas en análisis de datos. Discuten qué es el lenguaje natural, cómo enseñarle a una máquina a entenderlo y procesarlo. La conferencia tradicionalmente llevó a cabo concursos (pistas)
Diálogo Evaluación . A ellos pueden asistir representantes de grandes empresas que crean soluciones en el campo del procesamiento del lenguaje natural (Natural Language Processing, PNL), así como investigadores individuales. Puede parecer que si eres un estudiante simple, ¿compites con los sistemas que los grandes especialistas de grandes compañías han estado creando durante años? Evaluación del diálogo: este es exactamente el caso cuando en la clasificación final un estudiante simple puede ser más alto que una empresa famosa.
Este año será el noveno consecutivo cuando se lleve a cabo la Evaluación del Diálogo en el Diálogo. Cada año, el número de competiciones es diferente. Las tareas de PNL, como el análisis de sentimientos, la inducción del sentido de las palabras, la corrección ortográfica automática, el reconocimiento de entidades con nombre y otras, ya se han convertido en temas para las pistas.

Este año, cuatro grupos de organizadores prepararon tales pistas:
- Generación de titulares para reportajes.
- Resolución de anáforas y coreferencia.
- Análisis morfológico sobre el material de lenguas de bajos recursos.
- Análisis automático de uno de los tipos de puntos suspensivos (gapping).
Hoy hablaremos sobre el último de ellos: qué es una elipse y por qué enseñarle al automóvil cómo restaurarlo en el texto, cómo creamos un nuevo edificio para resolver este problema, cómo se realizaron las competencias y qué resultados pudieron lograr los participantes.
AGRR-2019 (Resolución de separación automática para ruso)
En el otoño de 2018, nos enfrentamos a una tarea de investigación relacionada con una elipse, una omisión intencional de una cadena de palabras en un texto que se puede restaurar del contexto. ¿Cómo encontrar automáticamente ese espacio en el texto y llenarlo correctamente? Es fácil para un hablante nativo, pero enseñar este auto no es fácil. Rápidamente se hizo evidente que este es un buen material para la competencia, y nos pusimos manos a la obra.
La organización de concursos sobre un nuevo tema tiene sus propias características, y para nosotros parecen ser en gran medida ventajas. Una de las cosas principales es la creación del corpus (muchos textos con marcado sobre los que puedes aprender). ¿Cómo debería ser y cuánto debería ser? Para muchas tareas, existen estándares para presentar datos a partir de los cuales construir. Por ejemplo, para la
tarea de identificar entidades nombradas , se han desarrollado esquemas de marcado IO / BIO / IOBES, para las tareas de análisis sintáctico y morfológico, el formato CONLL se usa tradicionalmente, no es necesario inventar nada, pero las pautas deben seguirse estrictamente.
En nuestro caso, dependía de nosotros reunir el cuerpo y formular la tarea.
Aquí hay una tarea así ...
Aquí inevitablemente tendremos que hacer una introducción lingüística popular sobre qué es la elipsis en general y la brecha como uno de sus tipos.
Independientemente de las ideas que tenga sobre el idioma, es difícil argumentar que el nivel superficial de expresión (texto o discurso) no es el único. Dicha frase es la punta del iceberg. El iceberg en sí incluye una evaluación pragmática, la construcción de una estructura sintáctica, la selección de material léxico, etc. La elipsis es un fenómeno que conecta bellamente el nivel de la superficie con lo profundo. Esta es la omisión de elementos de sintaxis duplicados. Si presentamos la estructura sintáctica de una oración en forma de árbol y se pueden seleccionar los mismos subárboles en este árbol, entonces a menudo (pero no siempre), para que la oración sea natural, se eliminan los elementos duplicados. Tal eliminación se llama puntos suspensivos (ejemplo 1).
(1)
No me volvieron a llamar y no entiendo por qué no me volvieron a llamar .Las lagunas obtenidas por puntos suspensivos pueden restaurarse sin ambigüedades del contexto del lenguaje. Compare el primer ejemplo con el segundo (2), donde hay un pase, pero lo que falta exactamente no está claro. Este caso no es una elipsis.
(2)
La separación es uno de los tipos de frecuencia de puntos suspensivos. Considere el ejemplo (3) y comprenda cómo funciona.
(3)
La confundí con un italiano y él con un sueco.En todos los ejemplos hay más de dos oraciones (cláusulas), están compuestas entre sí. En la primera cláusula hay un verbo (es más probable que los lingüistas digan "predicado") y sus participantes lo
aceptaron :
yo ,
ella e
italiano . En la segunda cláusula no hay un verbo expresado, solo hay "remanentes" (o remanentes) y
para el sueco que no están sintácticamente relacionados, pero entendemos cómo se restaura el pase.
Para restaurar el pase, pasamos a la primera cláusula y copiamos toda la estructura (ejemplo 4). Reemplazamos solo aquellas partes para las cuales hay restos "paralelos" en una cláusula incompleta. Copiamos el predicado,
lo reemplazamos con
él ,
para el italiano lo reemplazamos con remanente
para el sueco . Para
mí, no había remanente paralelo, lo que significa que lo copiamos sin reemplazo.
(4)
La confundí con italiano, y la confundí con un sueco.Parece que para restaurar la brecha, es suficiente para nosotros determinar si hay una brecha en esta oración, encontrar la cláusula incompleta y la cláusula completa asociada a ella (de la cual se toma el material para la restauración), y luego entender qué "remanentes" (remanentes) están en la cláusula incompleta y lo que corresponden en su totalidad. Parece que estas condiciones son suficientes para llenar efectivamente el vacío. Por lo tanto, tratamos de imitar el proceso en la cabeza de una persona que lee o escucha un texto en el que puede haber omisiones.
Entonces, ¿por qué se necesita esto?
Está claro que para una persona que escucha por primera vez los puntos suspensivos y las dificultades de procesamiento asociadas, puede surgir una pregunta legítima: "¿Por qué?" Los escépticos quisieran
invitar a los padres de la ciencia lingüística a
leer para explicar que si la solución de un problema aplicado proporciona material que puede ser útil en la investigación teórica, entonces esta ya es una respuesta suficiente a la pregunta sobre el propósito de dicha actividad.
Los teóricos han estado estudiando puntos suspensivos en diferentes idiomas durante aproximadamente 50 años, describen las limitaciones, destacan los patrones generales en diferentes idiomas. Al mismo tiempo, no somos conscientes de la existencia de un corpus que ilustre cualquier tipo de puntos suspensivos con más de unos pocos cientos de ejemplos. Esto se debe en parte a la rareza del fenómeno (por ejemplo, en nuestros datos, el grapping se encuentra en no más de 5 oraciones de cada 10 mil). Entonces, la creación de tal cuerpo ya es un resultado importante.
En los sistemas de aplicación que funcionan con datos de texto, la rareza del fenómeno le permite simplemente ignorarlo. La incapacidad del analizador sintáctico para restaurar las brechas faltantes no trae muchos errores exactamente. Pero a partir de eventos raros, se forma una periferia lingüística extensa y heterogénea. Parece que la experiencia de resolver tal problema en sí misma debería ser de interés para aquellos que desean crear sistemas que funcionen no solo en textos simples, cortos y limpios con vocabulario común, es decir, en textos esféricos en un vacío que prácticamente no ocurre en la naturaleza.
Pocos analizadores cuentan con un sistema efectivo para detectar y resolver puntos suspensivos. Pero en el analizador interno ABBYY hay un módulo responsable de restaurar los pases, y se basa en reglas escritas manualmente. Gracias a esta habilidad del analizador, pudimos crear un gran cuerpo para la competencia. El beneficio potencial para el analizador original es reemplazar un módulo de ejecución lenta. Además, mientras trabajábamos en el caso, realizamos un análisis detallado de los errores del sistema actual.
Como creamos el cuerpo
Nuestro edificio está destinado principalmente a la formación de sistemas automáticos, lo que significa que es extremadamente importante que sea voluminoso y diverso. Guiados por esto, construimos el trabajo de recolección de datos de la siguiente manera. Para el cuerpo, seleccionamos textos de varios géneros: desde documentación técnica y patentes hasta noticias y publicaciones de las redes sociales. Todos ellos fueron marcados por el analizador ABBYY. En un mes, distribuimos datos entre lingüistas y escritores. Se invitó a los marcadores, sin cambiar el marcado, para evaluarlo en una escala:
0 - no hay mapeo en la oración, el marcado es irrelevante.
1: hay un mapeo y su marcado es correcto.
2: hay una separación, pero algo está mal con el marcado.
3 - un caso complicado, ¿es un mapeo?
Como resultado, cada uno de los grupos fue útil. Los ejemplos de la categoría 1 cayeron en la clase positiva de nuestro conjunto de datos. Básicamente, no queríamos volver a muestrear manualmente los ejemplos de las categorías 2 y 3 para ahorrar tiempo, pero estos ejemplos nos fueron útiles más tarde para evaluar nuestro corpus resultante. A partir de ellos, se puede juzgar qué casos el sistema marca de manera consistente de manera incorrecta, lo que significa que no entran en nuestro cuerpo. Y finalmente, incluyendo en los ejemplos de casos clasificados por marcadores como categoría 0, les dimos a los sistemas la oportunidad de "aprender de los errores de los demás", es decir, no solo simular el comportamiento del sistema original, sino que funciona mejor que él.
Cada ejemplo fue evaluado por dos marcadores. Después de eso, un poco más de la mitad de las propuestas ingresaron al cuerpo a partir de los datos de origen. Toda la clase positiva de ejemplos y parte de la negativa consiste en ellos. Decidimos hacer que la clase negativa sea el doble de positiva para que, por un lado, las clases sean comparables en volumen y, por otro, se conserve la preponderancia de la clase negativa que existe en el idioma.
Para cumplir con esta proporción, tuvimos que agregar más ejemplos negativos al caso, además de los ejemplos descritos de la categoría 0. Digamos un ejemplo (5) de la categoría 0, que puede confundir no solo al automóvil, sino también a la persona.
(5)
Pero para entonces Jack estaba enamorado de Cindy Page, ahora la señora Jack Svaytek.En la segunda cláusula, ella no se está recuperando
en el amor , porque quiero decir que ahora Cindy Page se ha convertido en la señora Jack Svaytek porque se casó con él.
En general, para un fenómeno sintáctico relativamente raro como la separación, un ejemplo negativo es casi cualquier oración aleatoria del lenguaje, debido a la probabilidad de que haya una pequeña separación en una oración aleatoria. Sin embargo, el uso de tales ejemplos negativos puede conducir a una nueva capacitación en los signos de puntuación. En nuestro caso, los ejemplos para la clase negativa se obtuvieron de acuerdo con criterios simples: la presencia de un verbo, la presencia de una coma o un guión, la longitud mínima de la oración no es inferior a 6 tokens.
Para la competencia, seleccionamos de la parte de desarrollo del edificio de capacitación (en la proporción de 1: 5), que los participantes fueron invitados a usar para configurar sus sistemas. Las versiones finales de los sistemas fueron entrenadas en las partes combinadas de tren y desarrollo. Etiquetamos manualmente el caso de prueba (prueba) por nuestra cuenta, en términos de volumen es la décima parte de train + dev. Aquí está el número exacto de ejemplos de clase:
Además de los datos de capacitación verificados manualmente, agregamos un archivo de marcado sin formato recibido del sistema fuente. Hay más de 100 mil ejemplos, y los participantes podrían usar opcionalmente estos datos para complementar la muestra de capacitación. Mirando hacia el futuro, decimos que solo un participante descubrió cómo aumentar significativamente el edificio de capacitación utilizando datos sucios sin perder calidad.
Formato de marcado
Nos negamos deliberadamente a usar analizadores de terceros y desarrollamos un marcado en el que todos los elementos de interés para nosotros están marcados linealmente en la línea de texto. Utilizamos dos tipos de marcado. El primero, legible para humanos, está diseñado para trabajar con marcado, y es conveniente analizar los errores de los sistemas resultantes. Con este método, todos los elementos de separación se marcan con corchetes dentro de la oración. Cada par de paréntesis está marcado con el nombre del elemento correspondiente. Utilizamos la siguiente notación:

Damos ejemplos de oraciones con espacios entre paréntesis.
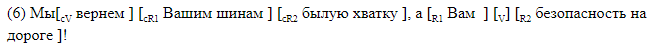
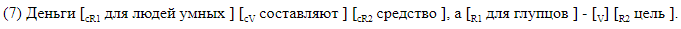

El marcado del soporte es adecuado para el análisis de materiales. En el caso, los datos se almacenan en un formato diferente que, si se desea, se puede convertir fácilmente en paréntesis. Una línea corresponde a una oración. Las columnas indican la presencia de espacios en la oración, y para cada etiqueta posible en su columna se proporcionan desplazamientos simbólicos del comienzo y el final del segmento correspondiente al elemento. Así es como se ve el marcado de desplazamiento, correspondiente al marcado de paréntesis en ().
Tareas para participantes
Los participantes de AGRR-2019 podrían resolver cualquiera de los tres problemas:
- Clasificación binaria Es necesario determinar si hay un espacio en la oración.
- Permiso de separación. Es necesario restaurar la posición del pase (V) y la posición del controlador de verbo (cV).
- Marcado completo. Debe definir compensaciones para todos los elementos de la separación.
Cada tarea siguiente debe resolver de alguna manera la anterior. Está claro que cualquier marcado es posible solo en oraciones donde la clasificación binaria muestra una clase positiva (hay un mapeo), y el marcado completo también incluye encontrar los límites de los predicados faltantes y de control.
Métricas
Para el problema de clasificación binaria, utilizamos métricas estándar: precisión e integridad, y los resultados de los participantes se clasificaron por medida f.
Para las tareas de resolver la separación y completar el marcado, decidimos usar una medida f simbólica, ya que los textos de origen no estaban tokenizados y no queríamos que la diferencia en los participantes usara tokenizadores para afectar los resultados. Los ejemplos verdaderos negativos no contribuyeron a la medida f simbólica, para cada elemento de marcado se consideró su propia medida f, el resultado final se obtuvo por macro-promedio en todo el cuerpo. Gracias a tal cálculo de la métrica, los casos de falsos positivos fueron multados significativamente, lo cual es importante cuando hay muchos menos ejemplos positivos en datos reales que los negativos.
Curso de competencia
Paralelamente al montaje del edificio, aceptamos solicitudes de participación en el concurso. Como resultado, registramos más de 40 participantes. Luego presentamos el edificio de entrenamiento y lanzamos la competencia. Los participantes tuvieron 4 semanas para construir sus modelos.
La etapa de evaluación de los resultados fue la siguiente: los participantes recibieron 20 mil ofertas sin márgenes, dentro de los cuales se incluyó un caso de prueba. Los equipos tuvieron que marcar estos datos con sus sistemas, después de lo cual evaluamos los resultados de las marcas en el edificio de prueba. La combinación de la prueba en una gran cantidad de datos nos garantizó que, con todos nuestros deseos, el caso no podría marcarse manualmente en los pocos días que se dieron para la ejecución (marcado automático).
Resultados de la competencia
Nueve equipos llegaron a la final, incluidos representantes de dos empresas de TI, investigadores de la Universidad Estatal de Moscú, el Instituto de Física y Tecnología de Moscú, HSE e IPPI RAS.
Todos menos uno de los equipos participaron en las tres competiciones. Según los términos de AGRR-2019, todos los equipos publicaron un código para sus decisiones. Se proporciona una tabla resumen con los resultados en
nuestro repositorio , donde también puede encontrar enlaces a las soluciones establecidas de los equipos con breves descripciones.
Casi todos mostraron buenos resultados. Aquí están las evaluaciones de las decisiones de los equipos ganadores:
Una descripción detallada de las mejores soluciones pronto estará disponible en los artículos de los participantes en la colección Dialogue.
Entonces, en este artículo hablamos sobre cómo, tomando como base un fenómeno lingüístico raro, formular una tarea, preparar un cuerpo y conducir competencias. También se beneficia este trabajo para la comunidad de PNL, porque los concursos ayudan a comparar diferentes arquitecturas y enfoques entre sí sobre material específico, y los lingüistas obtienen un caso de un fenómeno raro con la posibilidad de reponerlo (usando las decisiones de los ganadores). El cuerpo reunido es varias veces más grande que los volúmenes del cuerpo actualmente existente (además, para la separación, el volumen del cuerpo es un orden de magnitud mayor que los volúmenes del cuerpo no solo para el ruso, sino para todos los idiomas en general). Todos los datos y enlaces a las decisiones de los participantes se pueden encontrar en nuestro github.
El 30 de mayo, en la sesión especial del
Diálogo dedicada al análisis automático de las competencias brechas, se resumirán los resultados de AGRR-2019. Hablaremos sobre la organización del concurso y nos detendremos en el contenido del edificio creado, y los participantes presentarán la arquitectura seleccionada con la que resolvieron el problema.
Grupo de investigación avanzada de PNL