El curso completo en ruso se puede encontrar en
este enlace .
El curso de inglés original está disponible en
este enlace .
 Nuevas conferencias están programadas cada 2-3 días.
Nuevas conferencias están programadas cada 2-3 días.Entrevista con Sebastian Trun, CEO de Udacity
"Entonces, todavía estamos contigo y con nosotros, como antes, Sebastián". Solo queremos discutir las capas completamente conectadas, esas mismas capas densas. Antes de eso, me gustaría hacer una pregunta. ¿Cuáles son los límites y los principales obstáculos que se interpondrán en el camino del aprendizaje profundo y tendrán el mayor impacto en los próximos 10 años? ¡Todo cambia muy rápido! ¿Cuál crees que será la próxima "gran cosa"?
- Yo diría dos cosas. El primero es la IA general para más de una tarea. ¡Esto es genial! Las personas pueden resolver más de un problema y nunca deben hacer lo mismo. El segundo es llevar la tecnología al mercado. Para mí, la peculiaridad del aprendizaje automático es que proporciona a las computadoras la capacidad de observar y encontrar patrones en los datos, ayudando a las personas a mejorar en el campo, ¡a nivel experto! El aprendizaje automático se puede utilizar en derecho, medicina, automóviles autónomos. Desarrolle tales aplicaciones porque pueden aportar una gran cantidad de dinero, pero lo más importante es que tiene la oportunidad de hacer del mundo un lugar mucho mejor.
“Realmente me gusta la forma en que lo dices todo en una sola imagen del aprendizaje profundo y su aplicación: esta es solo una herramienta que puede ayudarte a resolver un problema en particular.
- Sí, exactamente! Herramienta increíble, ¿verdad?
- Sí, sí, estoy completamente de acuerdo contigo!
"¡Casi como un cerebro humano!"
- Usted mencionó aplicaciones médicas en nuestra primera entrevista, en la primera parte del curso de video. ¿En qué aplicaciones, en su opinión, el uso del aprendizaje profundo causa el mayor deleite y sorpresa?
- Mucho! Muy! La medicina está en la breve lista de áreas que utilizan activamente el aprendizaje profundo. Perdí a mi hermana hace unos meses, estaba enferma de cáncer, lo cual es muy triste. Creo que hay muchas enfermedades que podrían detectarse antes, en las primeras etapas, lo que permite curar o ralentizar el proceso de su desarrollo. La idea, de hecho, es transferir algunas herramientas a la casa (hogar inteligente), para que sea posible detectar tales desviaciones en la salud mucho antes del momento en que la persona misma las ve. También agregaría: todo es repetitivo, cualquier trabajo de oficina, donde se realiza el mismo tipo de acciones una y otra vez, por ejemplo, la contabilidad. Incluso yo, como CEO, hago muchas acciones repetitivas. ¡Sería genial automatizarlos, incluso trabajar con correspondencia por correo!
- No puedo estar en desacuerdo contigo! En esta lección, presentaremos a los estudiantes a un curso con una capa de red neuronal llamada capa densa. ¿Podría decirnos con más detalle lo que piensa sobre las capas totalmente conectadas?
- Entonces, comencemos con el hecho de que cada red se puede conectar de diferentes maneras. Algunos de ellos pueden tener una conectividad muy estrecha, lo que le permite obtener algún beneficio al escalar y "ganar" contra redes grandes. A veces no sabes cuántas conexiones necesitas, por lo que conectas todo con todo, esto se llama una capa completamente conectada. Agrego que este enfoque tiene mucho más poder y potencial que algo más estructurado.
- Estoy completamente de acuerdo contigo! Gracias por ayudarnos a aprender un poco más sobre las capas totalmente conectadas. Espero el momento en que finalmente comencemos a implementarlos y a escribir código.
- Diviértete! ¡Será muy divertido!
Introduccion
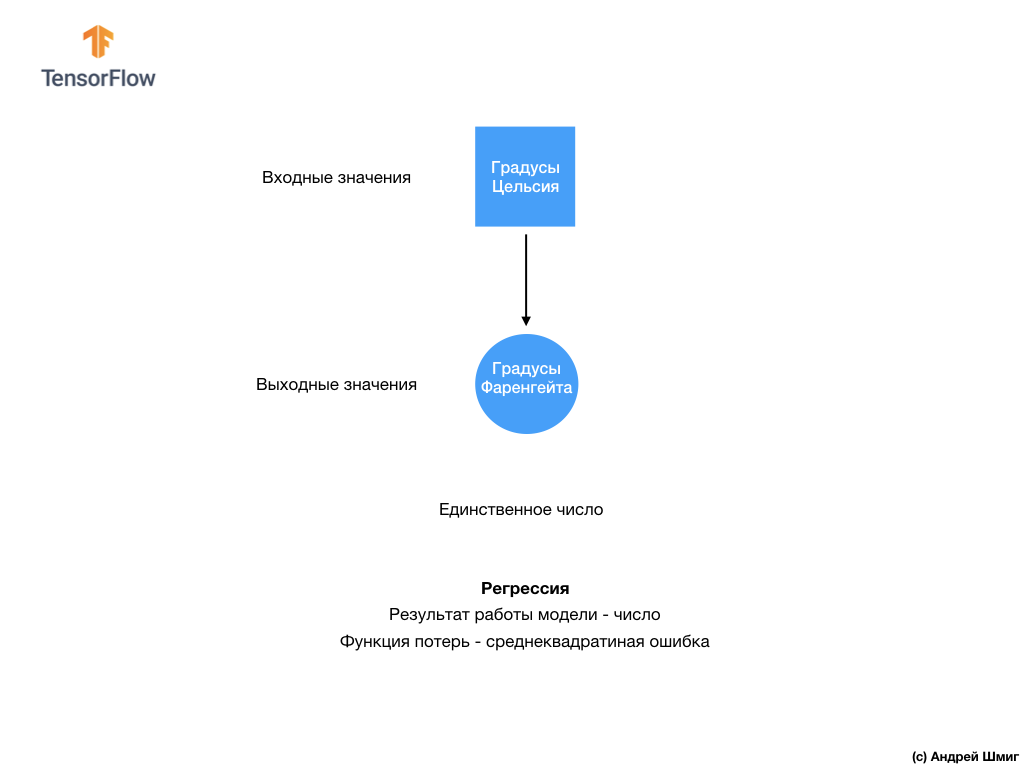
- Bienvenido de nuevo! En la última lección, descubriste cómo construir tu primera red neuronal usando TensorFlow y Keras, cómo funcionan las redes neuronales y cómo funciona el proceso de entrenamiento (entrenamiento). En particular, vimos cómo entrenar el modelo para convertir grados Celsius a grados Fahrenheit.

- También nos familiarizamos con el concepto de capas completamente conectadas (capas densas), la capa más importante en las redes neuronales. ¡Pero en esta lección haremos cosas mucho más geniales! En esta lección, desarrollaremos una red neuronal que pueda reconocer elementos e imágenes de la ropa. Como mencionamos anteriormente, el aprendizaje automático utiliza entradas llamadas "características" y salidas llamadas "etiquetas", mediante las cuales el modelo aprende y encuentra un algoritmo de transformación. Por lo tanto, en primer lugar, necesitaremos muchos ejemplos para entrenar a la red neuronal a reconocer varios elementos de la ropa. Permítame recordarle que un ejemplo de entrenamiento es un par de valores: una función de entrada y una etiqueta de salida, que se alimentan a la entrada de una red neuronal. En nuestro nuevo ejemplo, la entrada será una imagen, y la etiqueta de salida debe ser la categoría de ropa a la que pertenece la prenda que se muestra en la imagen. Afortunadamente, ese conjunto de datos ya existe. Se llama Moda MNIST. Echaremos un vistazo más de cerca a este conjunto de datos en la siguiente parte.
Conjunto de datos de moda MNIST
¡Bienvenido al mundo del conjunto de datos MNIST! Por lo tanto, nuestro conjunto consta de imágenes de 28x28, cada píxel representa un tono de gris.

El conjunto de datos contiene imágenes de camisetas, tops, sandalias e incluso botas. Aquí hay una lista completa de lo que contiene nuestro conjunto de datos MNIST:
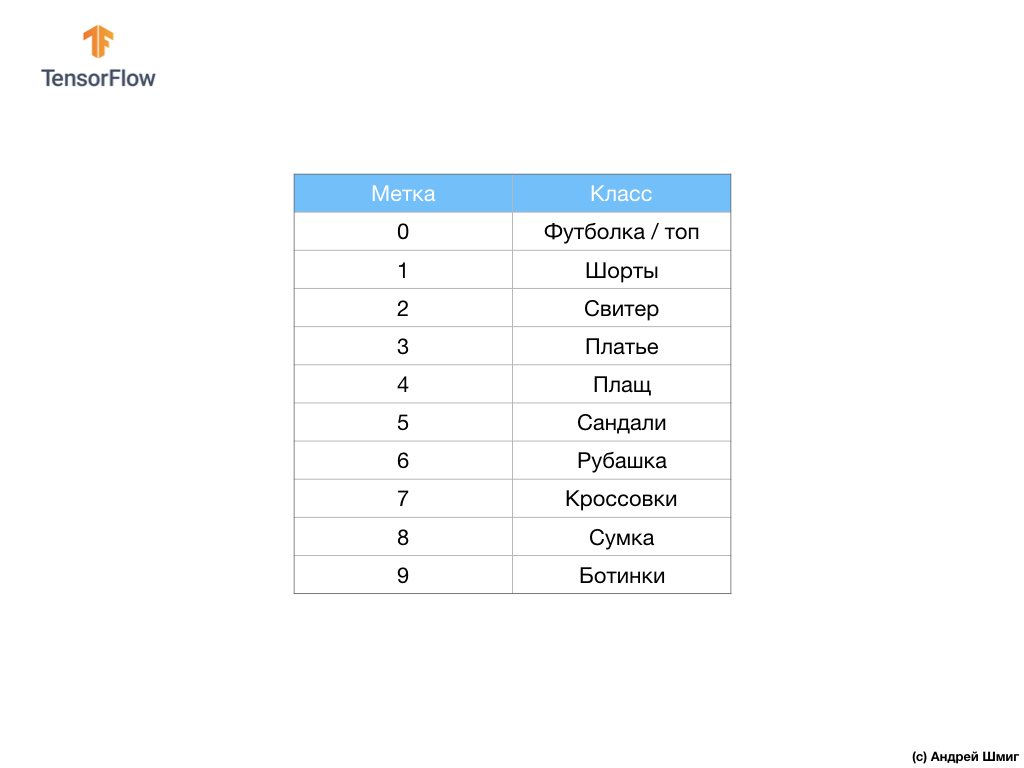
Cada imagen de entrada corresponde a una de las etiquetas anteriores. El conjunto de datos Fashion MNIST contiene 70,000 imágenes, por lo que tenemos un lugar para comenzar y trabajar. De estos 70,000, utilizaremos 60,000 para entrenar la red neuronal.
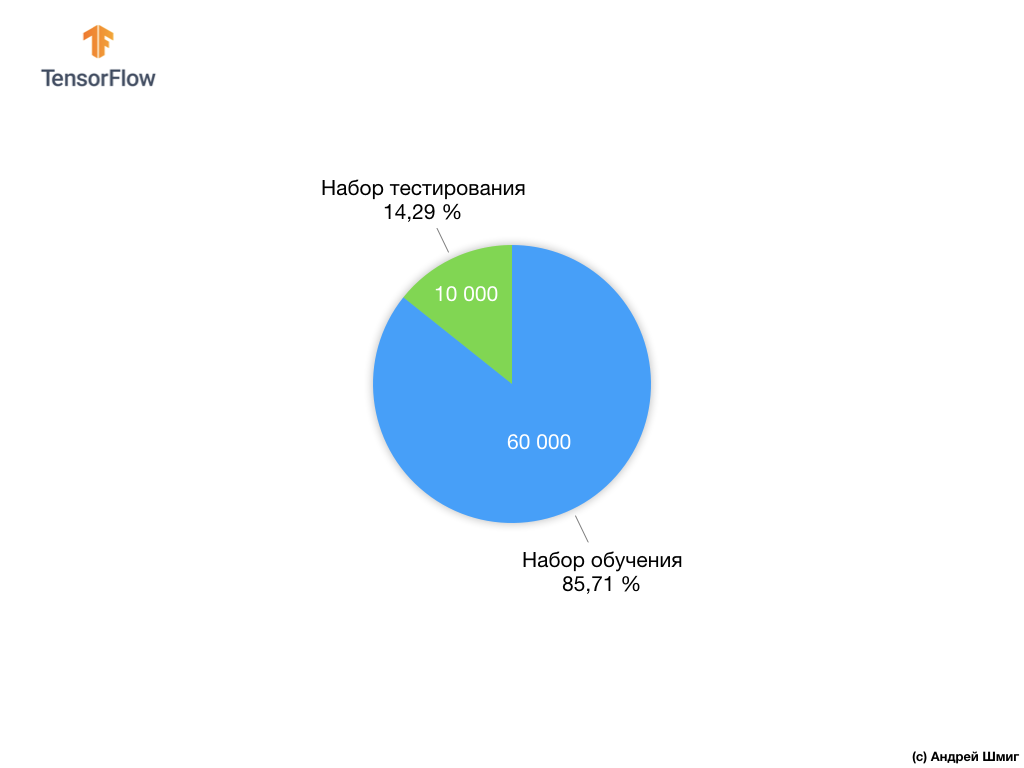
Y usaremos los 10,000 elementos restantes para probar qué tan bien nuestra red neuronal ha aprendido a reconocer los elementos de la ropa. Más adelante explicaremos por qué dividimos el conjunto de datos en un conjunto de entrenamiento y un conjunto de prueba.
Así que aquí está nuestro conjunto de datos Fashion MNIST.
Recuerde, cada imagen en el conjunto de datos es una imagen de tamaño 28x28 en tonos de gris, lo que significa que cada imagen tiene un tamaño de 784 bytes. Nuestra tarea es crear una red neuronal, que reciba estos 784 bytes en la entrada, y en la salida regrese a qué categoría de ropa de las 10 disponibles, pertenece el elemento aplicado en la entrada.
Red neuronal
En esta lección, utilizaremos una red neuronal profunda que aprende a clasificar imágenes del conjunto de datos Fashion MNIST.
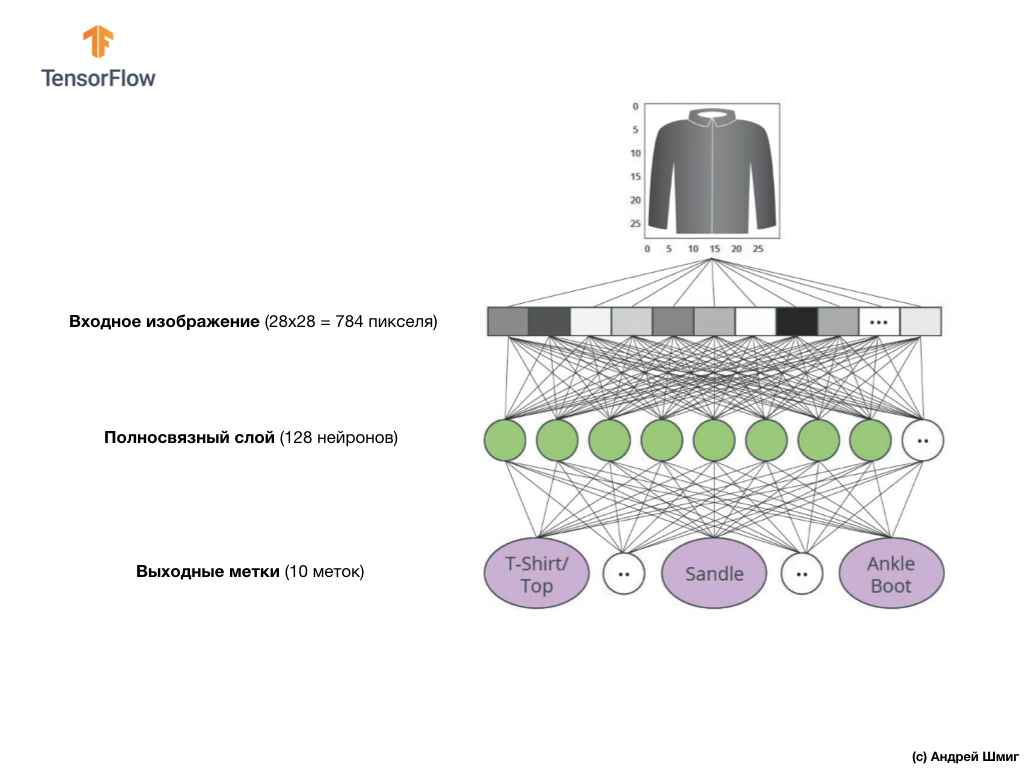
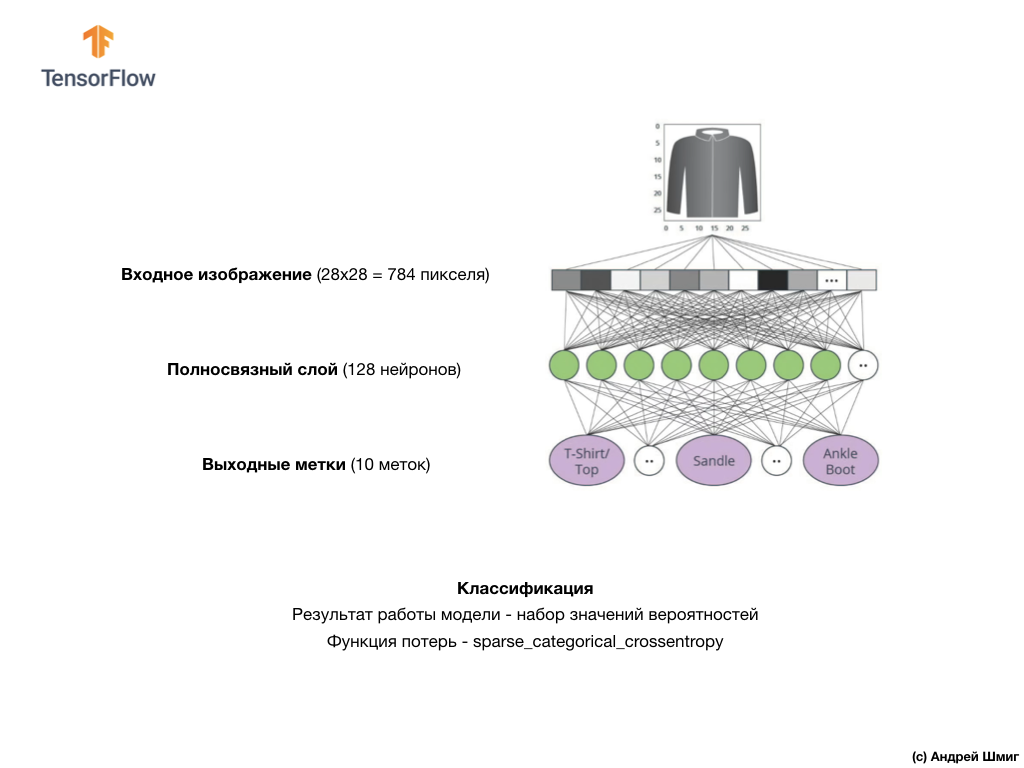
La imagen de arriba muestra cómo se verá nuestra red neuronal. Miremos con más detalle.
El valor de entrada de nuestra red neuronal es una matriz unidimensional con una longitud de 784, una matriz de exactamente esa longitud por la razón de que cada imagen tiene 28x28 píxeles (= 784 píxeles en total en la imagen), que convertiremos en una matriz unidimensional. El proceso de convertir una imagen 2D en un vector se denomina aplanamiento y se implementa a través de una capa de suavizado, una capa de aplanamiento.
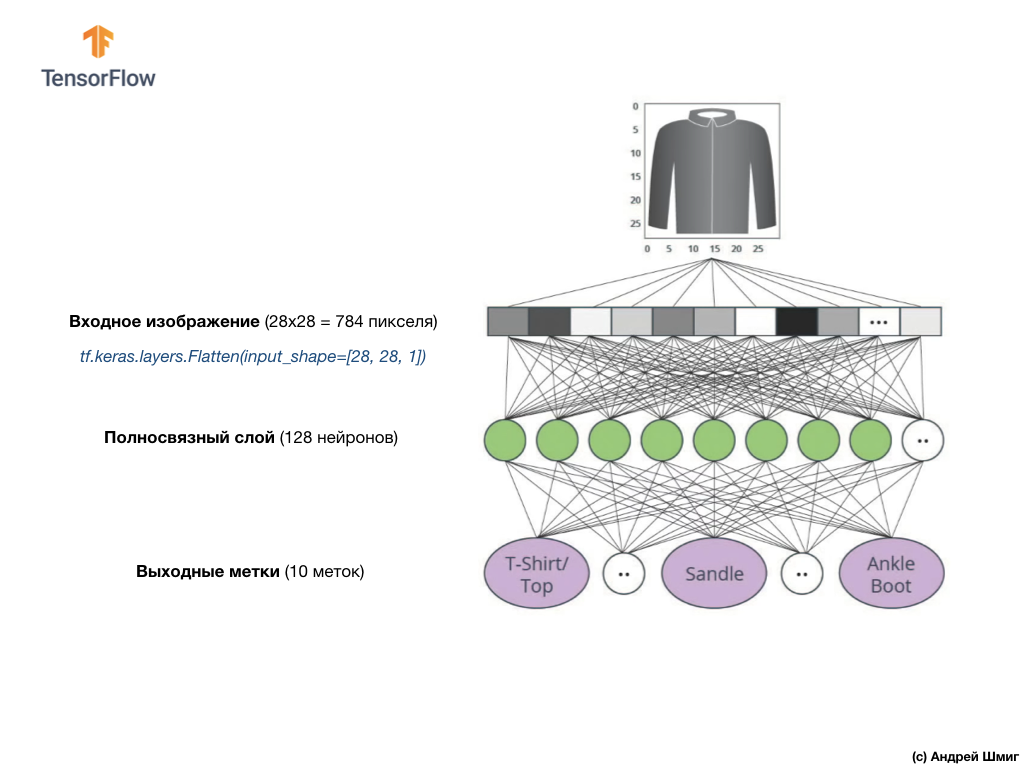
Puede realizar el suavizado creando la capa adecuada:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Esta capa convierte una imagen 2D de 28x28 píxeles (1 byte para sombras de gris para cada píxel) en una matriz 1D de 784 píxeles.
Los valores de entrada estarán completamente asociados con nuestra primera capa de red
dense , cuyo tamaño elegimos igual a 128 neuronas.
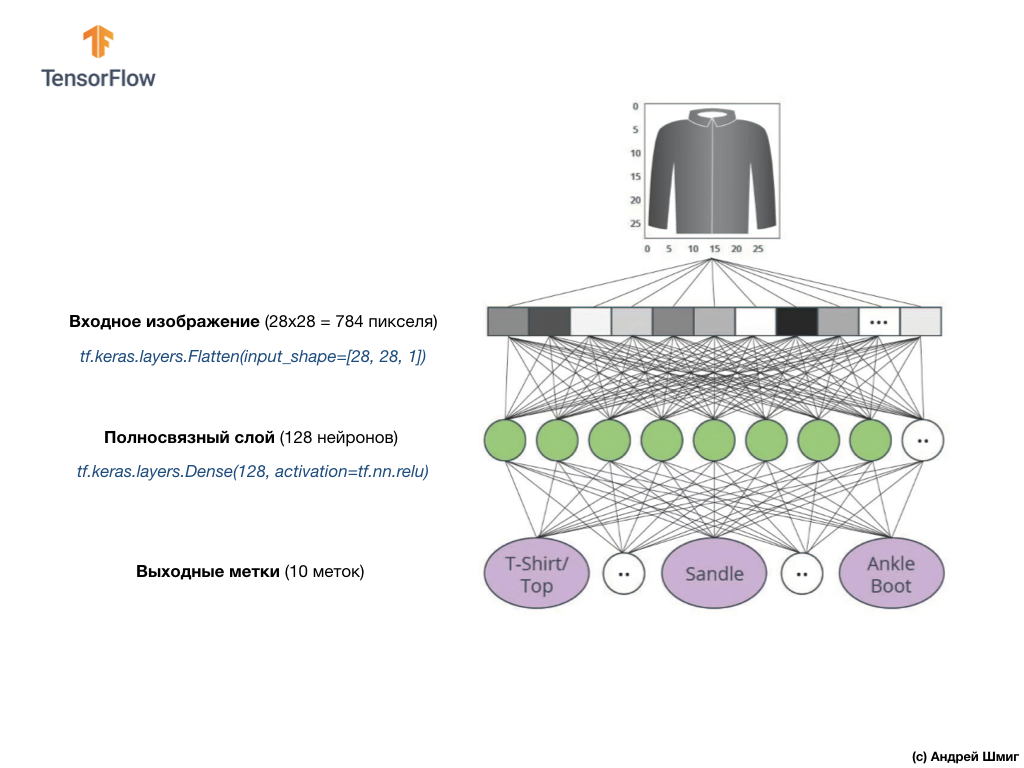
Así se verá la creación de esta capa en el código:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Basta! ¿Qué es
tf.nn.relu ? ¡No utilizamos esto en nuestro ejemplo de red neuronal anterior al convertir grados Celsius a grados Fahrenheit! La conclusión es que la tarea actual es mucho más complicada que la que se usó como ejemplo de investigación: convertir grados Celsius en grados Fahrenheit.
ReLU es una función matemática que agregamos a nuestra capa totalmente conectada y que le da más poder a nuestra red. De hecho, esta es una pequeña extensión para nuestra capa totalmente conectada, que permite que nuestra red neuronal resuelva problemas más complejos. No entraremos en detalles, pero a continuación se puede encontrar información un poco más detallada.
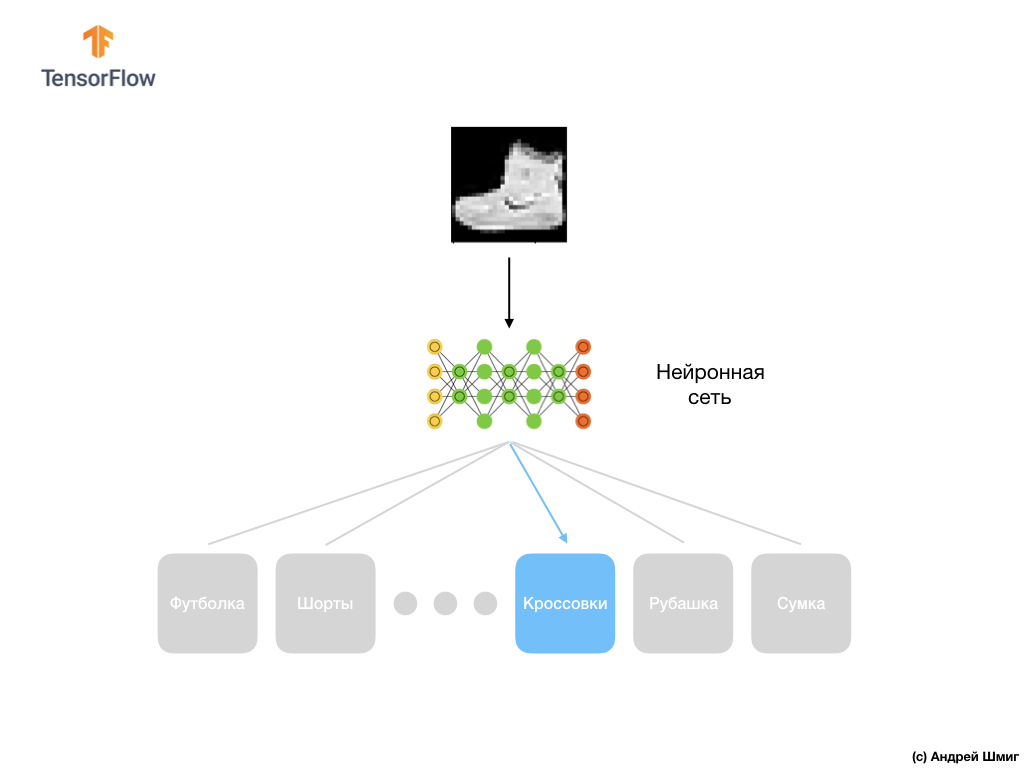
Finalmente, nuestra última capa, también conocida como capa de salida, consta de 10 neuronas. Se compone de 10 neuronas porque nuestro conjunto de datos Fashion MNIST contiene 10 categorías de ropa. Cada uno de estos 10 valores de salida representará la probabilidad de que la imagen de entrada esté en esta categoría de ropa. En otras palabras, estos valores reflejan la "confianza" del modelo en la exactitud de la predicción y la correlación de la imagen archivada con una de las 10 categorías de ropa específicas en la salida. Por ejemplo, ¿cuál es la probabilidad de que la imagen muestre un vestido, zapatillas, zapatos, etc.
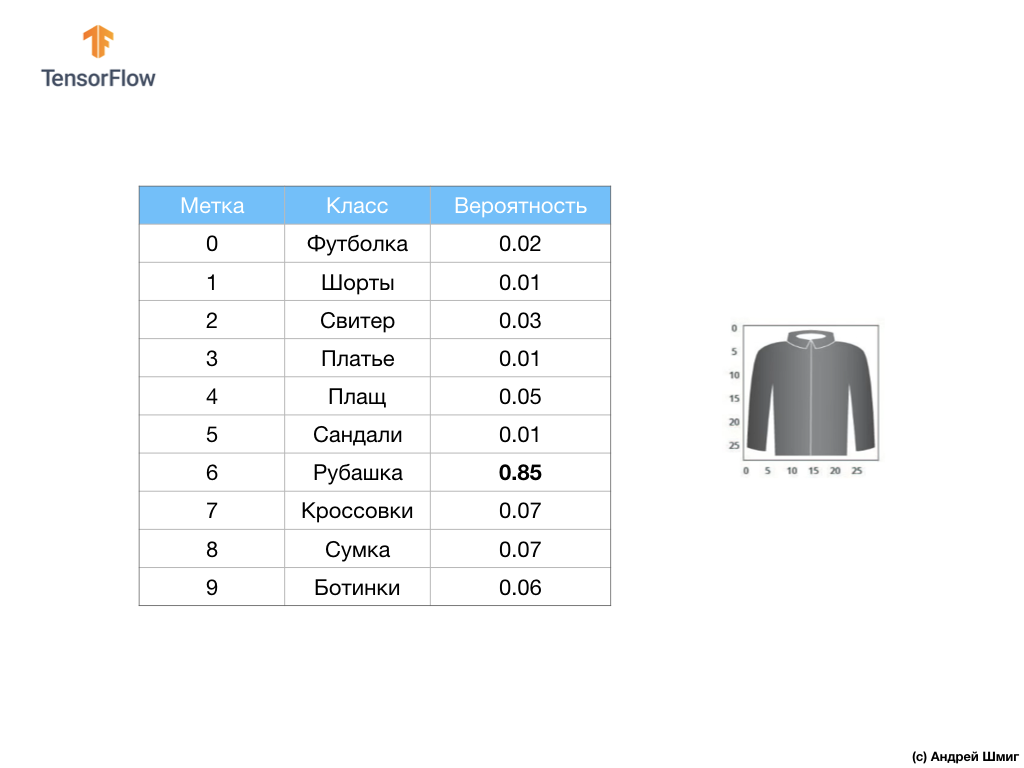
Por ejemplo, si se envía una imagen de camisa a la entrada de nuestra red neuronal, entonces el modelo puede darnos resultados como los que ve en la imagen de arriba: la probabilidad de que la imagen de entrada coincida con la etiqueta de salida.
Si prestas atención, notarás que la mayor probabilidad: 0,85 se refiere a la etiqueta 6, que corresponde a la camisa. El modelo está 85% seguro de que la imagen en la camisa. Por lo general, las cosas que parecen camisas también tendrán una calificación de alta probabilidad, y las cosas que son menos similares tendrán una calificación de probabilidad más baja.
Dado que los 10 valores de salida corresponden a probabilidades, al sumar todos estos valores obtenemos 1. Estos 10 valores también se denominan distribución de probabilidad.
Ahora necesitamos una capa de salida para calcular las probabilidades para cada etiqueta.

Y haremos esto con el siguiente comando:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
De hecho, siempre que creamos redes neuronales que resuelven problemas de clasificación, siempre usamos una capa totalmente conectada como la última capa de una red neuronal. La última capa de la red neuronal debe contener el número de neuronas igual al número de clases, a las que determinamos la
softmax y usamos la función de activación softmax.
ReLU - función de activación neuronal
En esta lección, hablamos sobre
ReLU como algo que extiende las capacidades de nuestra red neuronal y le da potencia adicional.
ReLU es una función matemática que se ve así:
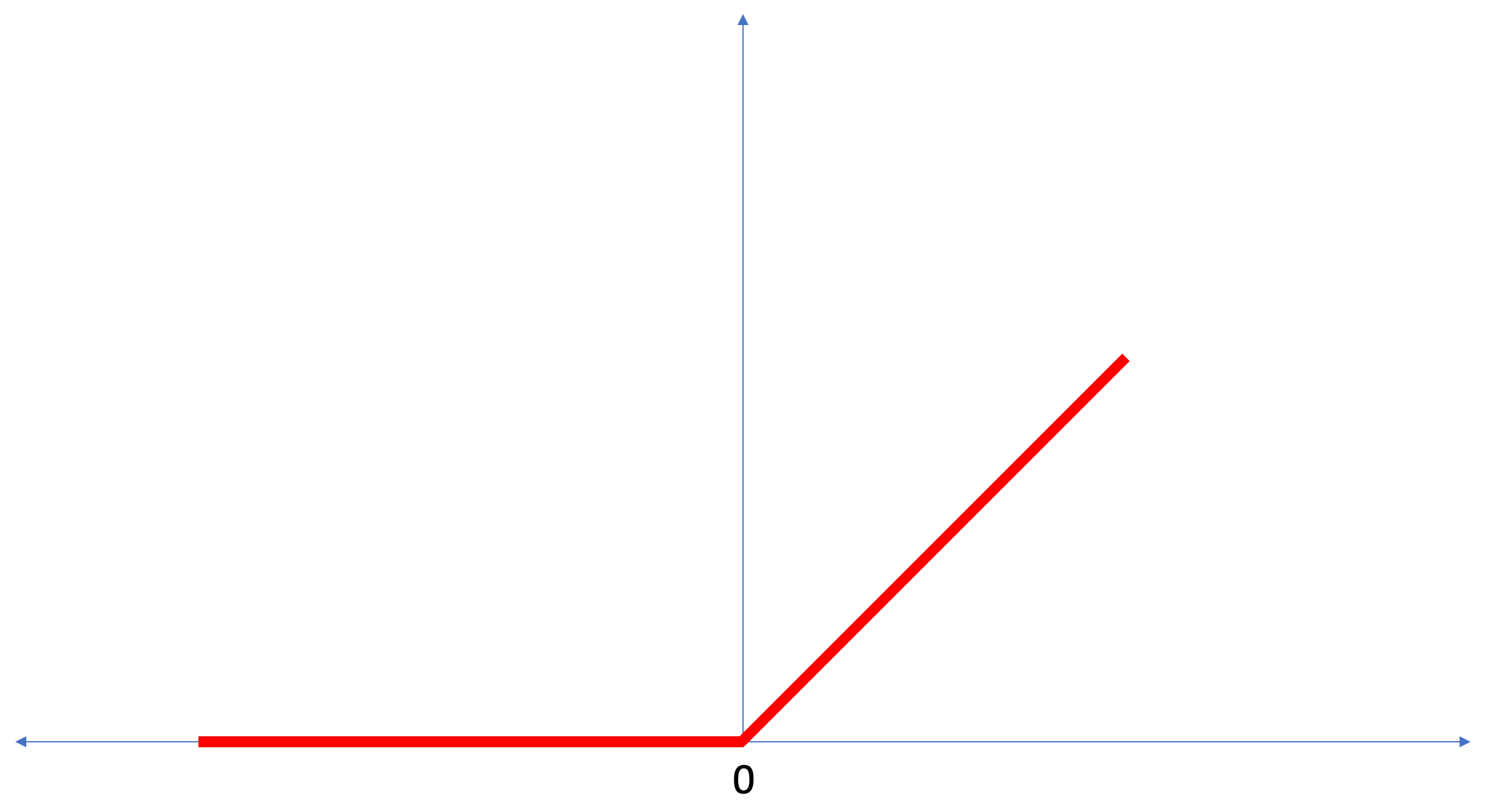
La función
ReLU devuelve 0 si el valor de entrada era un valor negativo o cero, en todos los demás casos la función devolverá el valor de entrada original.
ReLU hace posible resolver problemas no lineales.
Convertir grados Celsius en grados Fahrenheit es una tarea lineal, porque la expresión
f = 1.8*c + 32 es la ecuación de la línea -
y = m*x + b . Pero la mayoría de las tareas que queremos resolver son no lineales. En tales casos, agregar la función de activación ReLU a nuestra capa totalmente conectada puede ayudar con este tipo de tarea.
ReLU es solo un tipo de función de activación. Hay funciones de activación como sigmoide, ReLU, ELU, tanh, sin embargo, es
ReLU que
ReLU usa con mayor frecuencia como la función de activación predeterminada. Para crear y usar modelos que incluyen ReLU, no necesita comprender cómo funciona internamente. Si todavía quiere entender mejor, le recomendamos
este artículo .
Repasemos los nuevos términos introducidos en esta lección:
- Suavizado : el proceso de convertir una imagen 2D en un vector 1D;
- ReLU es una función de activación que permite que el modelo resuelva problemas no lineales;
- Softmax : una función que calcula las probabilidades para cada posible clase de salida;
- Clasificación : una clase de tareas de aprendizaje automático utilizadas para determinar las diferencias entre dos o más categorías (clases).
Entrenamiento y pruebas
Al entrenar un modelo, cualquier modelo de aprendizaje automático, siempre es necesario dividir el conjunto de datos en al menos dos conjuntos diferentes: el conjunto de datos utilizado para el entrenamiento y el conjunto de datos utilizado para las pruebas. En esta parte entenderemos por qué vale la pena hacerlo.
Recordemos cómo distribuimos nuestro conjunto de datos de Fashion MNIST que consta de 70,000 copias.
Propusimos dividir 70,000 en dos partes: en la primera parte, dejar 60,000 para capacitación y en la segunda parte 10,000 para pruebas. La necesidad de tal enfoque es causada por el siguiente hecho: después de que el modelo se capacitó en 60,000 copias, es necesario verificar los resultados y la efectividad de su trabajo en ejemplos que aún no estaban en el conjunto de datos en el que se capacitó el modelo.
A su manera, se parece a pasar un examen en la escuela. Antes de aprobar el examen, se dedica diligentemente a resolver problemas de una clase en particular. Luego, en el examen, te encuentras con la misma clase de problemas, pero con diferentes datos de entrada. No tiene sentido enviar los mismos datos que durante la capacitación; de lo contrario, la tarea se reducirá a recordar decisiones y no buscar un modelo de solución. Es por eso que en los exámenes te enfrentas a tareas que no estaban previamente en el plan de estudios. Solo de esta manera podemos verificar si el modelo ha aprendido la solución general o no.
Lo mismo sucede con el aprendizaje automático. Muestra algunos datos que representan una determinada clase de tareas que desea aprender a resolver. En nuestro caso, con un conjunto de datos de Fashion MNIST, queremos que la red neuronal pueda determinar la categoría a la que pertenece el elemento de ropa en la imagen. Es por eso que entrenamos nuestro modelo en 60,000 ejemplos que contienen todas las categorías de prendas de vestir. Después del entrenamiento, queremos verificar la efectividad del modelo, por lo que alimentamos los 10,000 artículos de ropa restantes que el modelo aún no ha "visto". Si decidimos no hacer esto, no probar con 10,000 ejemplos, no podríamos decir con certeza si nuestro modelo fue entrenado realmente para determinar la clase de la prenda de vestir o si recordaba todos los pares de valores de entrada + salida.
Es por eso que en el aprendizaje automático siempre tenemos un conjunto de datos para capacitación y un conjunto de datos para pruebas.
TensorFlow es una colección de datos de capacitación listos para usar.
Los conjuntos de datos generalmente se dividen en varios bloques, cada uno de los cuales se utiliza en una determinada etapa de entrenamiento y prueba de la efectividad de la red neuronal. En esta parte hablamos de:
- conjunto de datos de entrenamiento : un conjunto de datos destinado a entrenar una red neuronal;
- conjunto de datos de prueba : un conjunto de datos diseñado para verificar la eficiencia de una red neuronal;
Considere otro conjunto de datos, que llamo un conjunto de datos de validación. Este conjunto de datos no se utiliza
para entrenar el modelo, solo
durante el entrenamiento. Entonces, después de que nuestro modelo ha pasado por varios ciclos de entrenamiento, lo alimentamos con nuestro conjunto de datos de prueba y miramos los resultados. Por ejemplo, si durante el entrenamiento el valor de la función de pérdida disminuye y la precisión se deteriora en el conjunto de datos de prueba, esto significa que nuestro modelo simplemente recuerda pares de valores de entrada-salida.
El conjunto de datos de verificación se reutiliza al final del entrenamiento para medir la precisión final de las predicciones del modelo.
Para
obtener más
información sobre la formación y los conjuntos de datos de prueba, consulte el Curso acelerado de Google .
Parte práctica en CoLab
Enlace al CoLab original en inglés y un
enlace al CoLab ruso .
Clasificación de imágenes de prendas de vestir.
En esta parte de la lección, construiremos y entrenaremos una red neuronal para clasificar imágenes de elementos de ropa, como vestidos, zapatillas, camisas, camisetas, etc.
Está bien si algunos momentos no están claros. El propósito de este curso es presentarle TensorFlow y, al mismo tiempo, explicar los algoritmos de su trabajo y desarrollar una comprensión común de los proyectos que utilizan TensorFlow, en lugar de profundizar en los detalles de implementación.
En esta parte, usamos
tf.keras , una API de alto nivel para construir y entrenar modelos en TensorFlow.
Instalar e importar dependencias
Necesitaremos
un conjunto de datos TensorFlow , una API que simplifique la carga y el acceso a los conjuntos de datos proporcionados por varios servicios. También necesitaremos algunas bibliotecas auxiliares.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
Importe el conjunto de datos Fashion MNIST
Este ejemplo utiliza el conjunto de datos Fashion MNIST, que contiene 70,000 imágenes de prendas de vestir en 10 categorías en escala de grises. Las imágenes contienen prendas de vestir en baja resolución (28x28 píxeles), como se muestra a continuación:

Fashion MNIST se usa como un reemplazo para el clásico conjunto de datos MNIST, que se usa con mayor frecuencia como "¡Hola, mundo!" en aprendizaje automático y visión por computadora. El conjunto de datos MNIST contiene imágenes de números escritos a mano (0, 1, 2, etc.) en el mismo formato que las prendas de vestir en nuestro ejemplo.
En nuestro ejemplo, utilizamos Fashion MNIST debido a la variedad y porque esta tarea es más interesante desde el punto de vista de la implementación que resolver un problema típico en el conjunto de datos MNIST. Ambos conjuntos de datos son lo suficientemente pequeños, por lo tanto, se utilizan para verificar la correcta operatividad del algoritmo. Grandes conjuntos de datos para comenzar a aprender el aprendizaje automático, las pruebas y el código de depuración.
Utilizaremos 60,000 imágenes para entrenar la red y 10,000 imágenes para probar la precisión del entrenamiento y la clasificación de imágenes. Puede acceder directamente al conjunto de datos Fashion MNIST a través de TensorFlow utilizando la API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
Al cargar un conjunto de datos obtenemos metadatos, un conjunto de datos de entrenamiento y un conjunto de datos de prueba.
- El modelo está entrenado en un conjunto de datos de `train_dataset`
- El modelo se prueba en un conjunto de datos de `test_dataset`
Las imágenes son matrices bidimensionales de
2828 , donde los valores en cada celda pueden estar en el intervalo
[0, 255] . Etiquetas: una matriz de enteros, donde cada valor está en el intervalo
[0, 9] . Estas etiquetas corresponden a la clase de imagen de salida de la siguiente manera:
Cada imagen pertenece a una etiqueta. Como los nombres de clase no están contenidos en el conjunto de datos original, los guardaremos para usarlos en el futuro cuando dibujemos las imágenes:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
Investigamos datos
Estudiemos el formato y la estructura de los datos presentados en el conjunto de entrenamiento antes de entrenar el modelo. El siguiente código mostrará que 60,000 imágenes están en el conjunto de datos de entrenamiento y 10,000 imágenes en el conjunto de datos de prueba:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
Preprocesamiento de datos
El valor de cada píxel en la imagen está en el rango
[0,255] . Para que el modelo funcione correctamente, estos valores deben normalizarse, reducirse a valores en el intervalo
[0,1] . Por lo tanto, un poco más abajo, declaramos e implementamos la función de normalización, y luego la aplicamos a cada imagen en los conjuntos de datos de entrenamiento y prueba.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
Estudiamos los datos procesados.
Dibujemos una imagen para echarle un vistazo:
Mostramos las primeras 25 imágenes del conjunto de datos de entrenamiento y debajo de cada imagen indicamos a qué clase pertenece.
Asegúrese de que los datos estén en el formato correcto y que estemos listos para comenzar a crear y capacitar la red.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

Construyendo un modelo
La construcción de una red neuronal requiere el ajuste de capas y luego el ensamblaje de un modelo con funciones de optimización y pérdida.
Personaliza capas
El elemento básico en la construcción de una red neuronal es la capa. La capa extrae la vista de los datos que ingresaron en su entrada. Como resultado del trabajo de varias capas conectadas, obtenemos una vista que tiene sentido para resolver el problema.
La mayoría de las veces, haciendo un aprendizaje profundo, creará vínculos entre capas simples. La mayoría de las capas, por ejemplo, como tf.keras.layers.Dense, tienen un conjunto de parámetros que se pueden "ajustar" durante el proceso de aprendizaje.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
La red consta de tres capas:
- input
tf.keras.layers.Flatten : esta capa convierte imágenes de 28x28 píxeles de tamaño en una matriz 1D con tamaño 784 (28 * 28). En esta capa, no tenemos parámetros para el entrenamiento, ya que esta capa solo se ocupa de la conversión de datos de entrada. - capa oculta
tf.keras.layers.Dense : una capa estrechamente conectada de 128 neuronas. Cada neurona (nodo) toma los 784 valores de la capa anterior como entrada, cambia los valores de entrada de acuerdo con los pesos internos y los desplazamientos durante el entrenamiento, y devuelve un valor único a la siguiente capa. - capa de salida
ts.keras.layers.Dense - softmax consta de 10 neuronas, cada una de las cuales representa una clase particular de elemento de vestimenta. Como en la capa anterior, cada neurona recibe los valores de entrada de las 128 neuronas de la capa anterior. Los pesos y desplazamientos de cada neurona en esta capa cambian durante el entrenamiento para que el valor resultante esté en el intervalo [0,1] y represente la probabilidad de que la imagen pertenezca a esta clase. La suma de todos los valores de salida de 10 neuronas es 1.
Compila el modelo
Antes de comenzar a entrenar el modelo, vale la pena algunas configuraciones más. Esta configuración se realiza durante el ensamblaje del modelo cuando se llama al método de compilación:
- función de pérdida : un algoritmo para medir qué tan lejos está el valor deseado del predicho.
- función de optimización : un algoritmo para "ajustar" los parámetros internos (pesos y compensaciones) del modelo para minimizar la función de pérdida;
- métricas : se utilizan para monitorear el proceso de capacitación y las pruebas. El siguiente ejemplo utiliza métricas como la
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Nosotros entrenamos el modelo
En primer lugar, determinamos la secuencia de acciones durante el entrenamiento en un conjunto de datos de entrenamiento:
- Repita el conjunto de datos de entrada un número infinito de veces utilizando el método
dataset.repeat() (el parámetro epochs , que se describe a continuación, determina el número de todas las iteraciones de entrenamiento que se realizarán) - El método
dataset.shuffle(60000) todas las imágenes para que la formación de nuestro modelo no se vea afectada por el orden de entrada de datos. - El método
model.fit dataset.batch(32) le dice al model.fit entrenamiento model.fit use bloques de 32 imágenes y etiquetas model.fit vez que se actualizan las variables internas del modelo.
La capacitación se lleva a cabo llamando al método
model.fit :
- Envía
train_dataset a la entrada del modelo. - El modelo aprende a hacer coincidir la imagen de entrada con la etiqueta.
- El parámetro
epochs=5 limita el número de sesiones de entrenamiento a 5 iteraciones de entrenamiento completas en un conjunto de datos, lo que finalmente nos da entrenamiento en 5 * 60,000 = 300,000 ejemplos.
(puede ignorar el parámetro
steps_per_epoch , pronto este parámetro será excluido del método).
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
Y aquí está la conclusión:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Durante el entrenamiento del modelo, el valor de la función de pérdida y la métrica de precisión se muestran para cada iteración de entrenamiento. Este modelo logra una precisión de aproximadamente 0,88 (88%) en los datos de entrenamiento.
Verificar precisión
Veamos qué precisión produce el modelo en los datos de prueba. Utilizaremos todos los ejemplos que tenemos en el conjunto de datos de prueba para verificar la precisión.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
Conclusión
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
Como puede ver, la precisión en el conjunto de datos de prueba resultó ser menor que la precisión en el conjunto de datos de entrenamiento. Esto es bastante normal ya que el modelo fue entrenado en datos train_dataset. Cuando un modelo descubre imágenes que nunca antes había visto (del conjunto de datos train_dataset), es obvio que la eficiencia de clasificación disminuirá.
Predecir y explorar
Podemos usar el modelo entrenado para obtener predicciones para algunas imágenes.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
:
(32, 10)
. :
predictions[0]
:
array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
, — 10 . «» , ( ). :
np.argmax(predictions[0])
:
6
, , 6 (class_names[6]). , :
test_labels[0]
6
10 :
def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
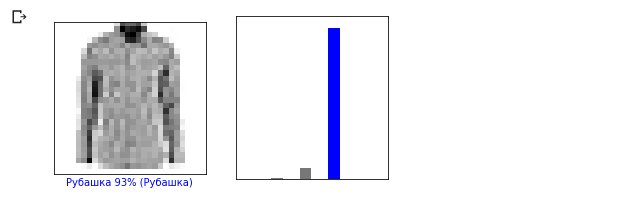
0- , .
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
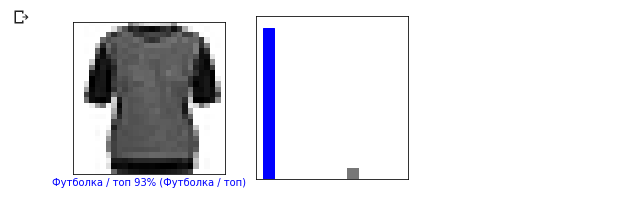
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
. — , — . , . , , «» .
num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)

, :
img = test_images[0] print(img.shape)
:
(28, 28, 1)
tf.keras (). , , :
img = np.array([img]) print(img.shape)
:
(1, 28, 28, 1):
predictions_single = model.predict(img) print(predictions_single)
:
[[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
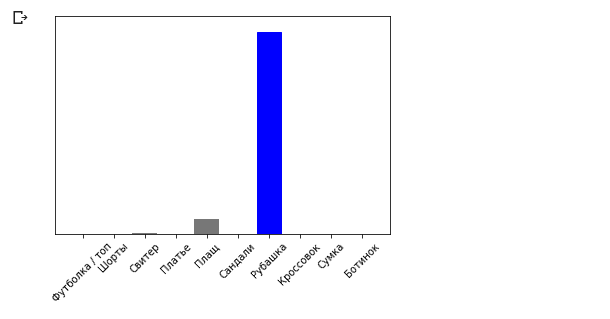
model.predict ( ), . :
np.argmax(predictions_single[0])
:
6
6 ().
. , :
- epochs 1;
- , , 10 512 , ;
- flatten- ( ) dense-, ;
- , .
GPU , (
Runtime -> Change runtime type -> Hardware accelertor -> GPU ). , , :
Edit -> Clear all outputsRuntime -> Reset all runtimes
VS MNIST
— . , , .
10 , , .
.
, ,
. . , , .
, ,
. («» , ). , 10 , , — , .
—
.
, ! , — (CNN, convolutional neural networks).
Resumen
. Fashion MNIST, 70 000 . 60 000 , 10 000 . () 2D 2828 1D 784 . 128 10 , (, ). 10 .
softmax .
.
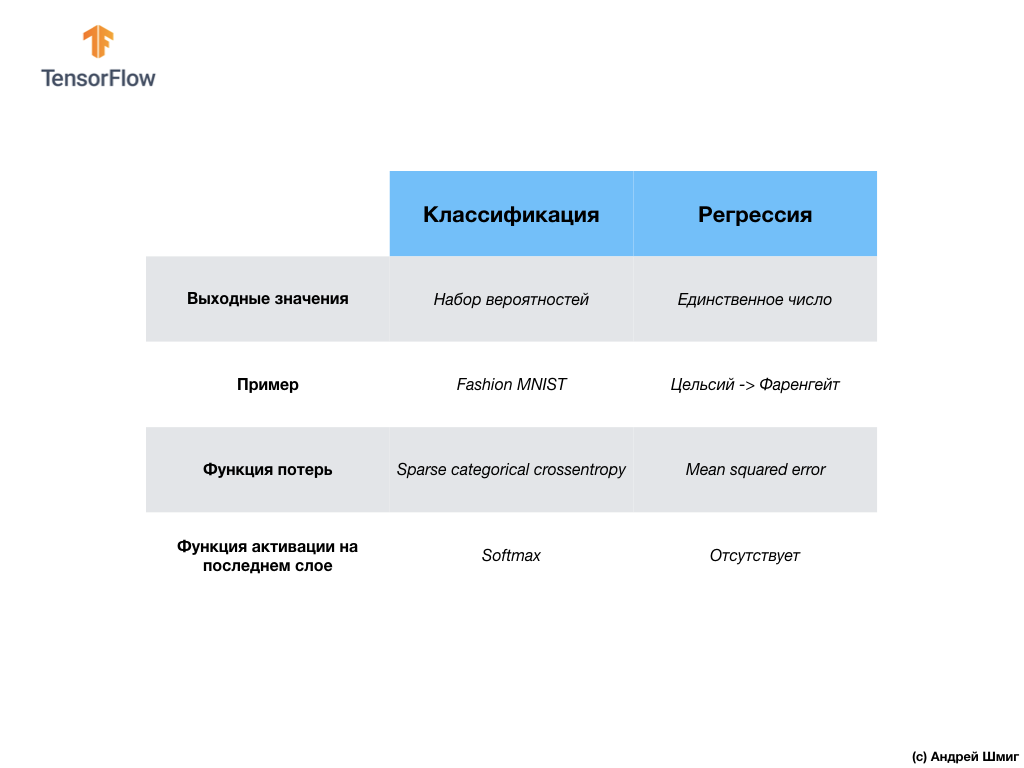
- : , , , .
- : , . , Fashion MNIST, 10 , ( ). , softmax , .
... y un llamado a la acción estándar: regístrese, ponga un plus y comparta :)
YouTubeTelegramaVKontakte