
Hace algún tiempo, me sucedió una historia desagradable, que sirvió como desencadenante de un pequeño proyecto en un github y resultó en este artículo.
Un día típico, una liberación normal: todas las tareas son revisadas por nuestro ingeniero de control de calidad, por lo que con la tranquilidad de la vaca sagrada "rodamos" al escenario. La aplicación se comporta bien, en los registros: silencio. Decidimos hacer el cambio (etapa <-> prod). Cambiamos, miramos los dispositivos ...
Tarda un par de minutos, el vuelo es estable. El ingeniero de control de calidad realiza una prueba de humo y se da cuenta de que la aplicación se está ralentizando de forma poco natural. Escribimos para calentar los cachés.
Pasan un par de minutos, la primera queja de la primera línea: los datos se descargan de los clientes durante mucho tiempo, la aplicación se ralentiza, tarda mucho en responder, etc. Comenzamos a preocuparnos ... miramos los registros, buscamos posibles razones.
Un par de minutos después, llega una carta de los administradores de DB. Escriben que el tiempo de ejecución de las consultas a la base de datos (en adelante, la base de datos) ha roto todos los límites posibles y tiende al infinito.
Abro el monitoreo (uso
JavaMelody ), encuentro estas solicitudes. Comienzo PGAdmin, me reproduzco. Muy largo Agrego "explicar", miro el plan de ejecución ... es decir, nos olvidamos de los índices.
¿Por qué la revisión de código no es suficiente?
Ese incidente me enseñó mucho. Sí, "apagué el fuego" durante una hora, creando de alguna manera el índice correcto directamente en el producto (no se olvide de la opción CONCURRENTEMENTE):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
De acuerdo, esto fue equivalente a un despliegue con tiempo de inactividad. Para la aplicación en la que estoy trabajando, esto es inaceptable.
Llegué a conclusiones y agregué un punto especial en negrita a la lista de verificación para la revisión del código: si veo que durante el proceso de desarrollo se agregó / cambió una de las clases del Repositorio, compruebo las migraciones de SQL para la presencia de un script que crea y cambia el índice allí. Si él no está allí, le escribo una pregunta al autor: ¿está seguro de que el índice no es necesario aquí?
Es probable que no se necesite un índice si hay pocos datos, pero si trabajamos con una tabla en la que se cuenta el número de filas en millones, un error de índice puede volverse fatal y conducir a la historia establecida al comienzo del artículo.
En este caso, le pido al autor de la solicitud de extracción (en adelante, PR) que esté 100% seguro de que la consulta que escribió en HQL está al menos parcialmente cubierta por el índice (se utiliza Index Scan). Para esto, el desarrollador:
- lanza la aplicación
- buscando consulta convertida (HQL -> SQL) en los registros
- abre PGAdmin u otra herramienta de administración de bases de datos
- genera en la base de datos local, para no molestar a nadie con sus experimentos, una cantidad de datos aceptable para las pruebas (mínimo 10K - 20K registros)
- cumple la solicitud
- solicita plan de ejecución
- lo estudia cuidadosamente y saca conclusiones apropiadas
- agrega / modifica el índice, asegurando que el plan de ejecución se adapte a él
- se da de baja en PR que la cobertura de la solicitud ha verificado
- Al evaluar de manera experta los riesgos y la gravedad de la solicitud, puedo verificar sus acciones
Muchas acciones rutinarias y el factor humano, pero durante algún tiempo estuve satisfecho y viví con esto.
Camino a casa
Dicen que es muy útil al menos a veces ir del trabajo sin escuchar música / podcasts en el camino. En este momento, solo pensando en la vida, puede llegar a conclusiones e ideas interesantes.
Un día caminé a casa y pensé en lo que pasó ese día. Hubo algunas revisiones, revisé cada una con una lista de verificación e hice una serie de acciones descritas anteriormente. Esa vez me cansé tanto, pensé, ¿qué demonios? ¿Es imposible hacer esto automáticamente? ... Di un paso rápido, queriendo "cortar" rápidamente esta idea.
Declaración del problema.
¿Qué es lo más importante para el desarrollador en el plan de ejecución?
Por supuesto, seq escanea en grandes cantidades de datos causados por la falta de un índice.
Por lo tanto, era necesario hacer una prueba que:
- Realizado en una base de datos con una configuración similar a la del producto
- Intercepta una consulta de base de datos realizada por un repositorio JPA (Hibernate)
- Lo consigue plan de ejecución
- Plan de Ejecución Parsit, estableciéndolo en una estructura de datos conveniente para cheques
- Usando un conjunto conveniente de métodos Assert, verifica las expectativas. Por ejemplo, esa exploración seq no se usa.
Era necesario probar rápidamente esta hipótesis haciendo un prototipo.
Arquitectura de soluciones
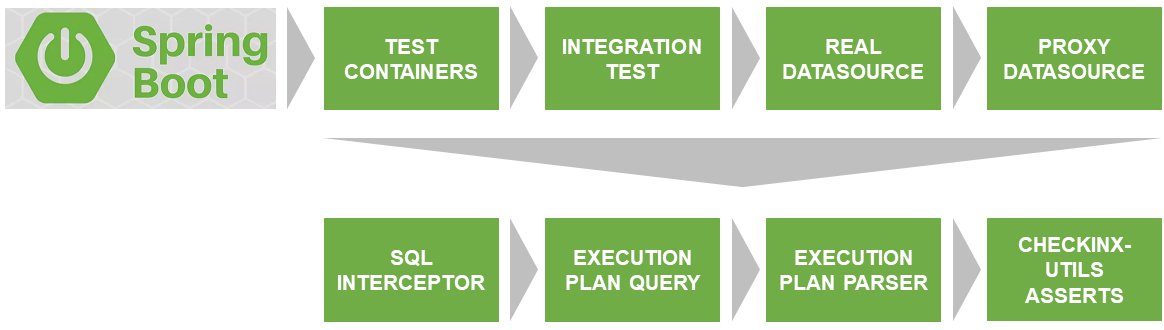
El primer problema que debía resolverse fue el lanzamiento de la prueba en una base de datos real que coincide con la versión y la configuración con la utilizada en el producto.
Gracias a
Docker & TestContainers , resuelven este problema.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse y AssertService son las interfaces que he implementado actualmente para Postgres. Los planes son implementar para otras bases de datos. Si quieres participar, bienvenido. El código está escrito en Kotlin.
Todo esto junto lo
publiqué en GitHub y llamé
checkinx-utils . No necesita repetir esto, solo conecte la dependencia a checkinx en maven / gradle y use afirmaciones convenientes. Cómo hacer esto, lo describiré con más detalle a continuación.
Descripción de la interacción de los componentes CheckInx
ProxyDataSource
El primer problema que debía resolverse era la intercepción de consultas de bases de datos listas para su ejecución. Ya con los parámetros establecidos, sin preguntas, etc.
Para hacer esto, necesita envolver el dataSource real en un Proxy determinado, lo que le permitiría integrarse en la canalización de ejecución de consultas y, en consecuencia, interceptarlos.
Tal ProxyDataSource ya ha sido implementado por muchos. Utilicé la solución
ttddyy lista para
usar , que me permite instalar mi Listener interceptando la solicitud que necesito.
Sustituyo la fuente DataSource usando la clase DataSourceWrapper (BeanPostProcessor).
SqlInterceptor
De hecho, su método start () establece su Listener en proxyDataSource y comienza a interceptar solicitudes, almacenándolas en la lista de declaraciones internas. El método stop (), respectivamente, elimina el oyente instalado.
EjecuciónPlanQuery
Aquí, la solicitud original se transforma en una solicitud de un plan de ejecución. En el caso de Postgres, esta es una adición a la palabra clave de consulta "EXPLICAR".
Además, esta consulta se ejecuta en la misma base de datos desde los contenedores de prueba y se devuelve un plan de ejecución "sin procesar" (lista de líneas).
EjecuciónPlanParser
Es inconveniente trabajar con un plan de ejecución sin procesar. Por lo tanto, lo analizo en un árbol que consiste en nodos (PlanNode).
Analicemos los campos PlanNode usando un ejemplo de un ExecutionPlan real:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
Ya es posible trabajar normalmente con la estructura de datos devuelta por el analizador. CheckInxAssertService es un conjunto de comprobaciones del árbol PlanNode descrito anteriormente. Le permite establecer sus propias lambdas de cheques o utilizar los predefinidos, en mi opinión, los más populares. Por ejemplo, para que su consulta no tenga Seq Scan, o si desea asegurarse de que se utiliza / no se utiliza un índice específico.
Nivel de cobertura
Muy importante Enum, lo describiré por separado:
A continuación, veremos algunos ejemplos de uso.
Ejemplos de prueba con CheckInx
Hice un proyecto por separado en
checkinx-demo de GitHub, donde implementé un repositorio JPA para la tabla de mascotas y las pruebas para este repositorio comprobando la cobertura, los índices, etc. Será útil mirar allí como punto de partida.
Es posible que tenga una prueba como esta:
@Test fun testFindByLocation() {
El plan de implementación podría ser el siguiente:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
... o así si nos olvidamos del índice (las pruebas se vuelven rojas):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
En mi proyecto, utilizo principalmente la afirmación más simple, que dice que no hay Seq Scan en el plan de ejecución:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
La presencia de tal prueba sugiere que, al menos, estudié el plan de implementación.
También hace que la gestión de proyectos sea más explícita, y aumenta la capacidad de documentar y predecir el código.
Modo experimentadoRecomiendo usar CheckInxAssertService, pero si es necesario, puede omitir el árbol analizado (ExecutionPlanParser) usted mismo o, en general, analizar el plan de ejecución sin procesar (el resultado de ejecutar ExecutionPlanQuery).
@Test fun testFindByLocation() {
Conexión al proyecto.
En mi proyecto, asigné tales pruebas a un grupo separado, llamándolo Pruebas de integración intensiva.
Conectarse y comenzar a usar checkinx-utils es bastante fácil. Comencemos con el script de compilación.
Conecte el repositorio primero. Algún día subiré checkinx a maven, pero ahora puedes descargar artefactos solo desde GitHub a través de jitpack.
repositories { // ... maven { url 'https://jitpack.io' } }
A continuación, agregue la dependencia:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
Completamos la conexión agregando la configuración. Solo Postgres es compatible actualmente.
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
Presta atención al perfil de prueba. De lo contrario, encontrará ProxyDataSource en su producto.
PostgresConfig conecta varios beans:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
Si necesita algún tipo de personalización que la API actual no proporciona, siempre puede reemplazar uno de los beans con su implementación.
Problemas conocidos
A veces, un DataSourceWrapper no puede reemplazar el dataSource original debido al proxy Spring CGLIB. En este caso, no un DataSource llega a BeanPostProcessor, sino ScopedProxyFactoryBean y existen problemas con la verificación de tipos.
La solución más fácil sería crear manualmente HikariDataSource para las pruebas. Entonces su configuración será la siguiente:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
Planes de desarrollo
- Me gustaría entender si alguien más que yo necesita esto. Para hacer esto, cree una encuesta. Estaré encantado de responder honestamente.
- Vea lo que realmente necesita y expanda la lista estándar de métodos de afirmación.
- Escribir implementaciones para otras bases de datos.
- La construcción de sqlInterceptor.statements [0] no parece muy obvia, quiero mejorarla.
Me alegraría si alguien quiere unirse y ganar algo de crédito practicando en Kotlin.
Conclusión
Estoy seguro de que habrá comentarios:
es imposible predecir cómo se comportará el planificador de consultas en el producto, todo depende de las estadísticas recopiladas .
De hecho, un planificador. Usando las estadísticas recopiladas anteriormente, puede construir un plan diferente al que se está probando. El significado es un poco diferente.
La tarea del planificador es mejorar, no empeorar, la solicitud. Por lo tanto, sin razón aparente, no usará repentinamente Seq Scan, pero puede hacerlo sin saberlo.
Necesita CheckInx para que al escribir una prueba, no olvide estudiar el plan de ejecución de la consulta y considere la posibilidad de crear un índice, o viceversa, que muestre claramente con una prueba que no se necesitan índices aquí y que está satisfecho con Seq Scan. Esto le ahorraría preguntas innecesarias sobre la revisión del código.
Referencias
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki