Hola a todos Mi nombre es Danila, trabajo en un equipo que desarrolla infraestructura analítica en Avito. El centro de esta infraestructura es la prueba A / B.
Los experimentos A / B son una herramienta clave para la toma de decisiones en Avito. En nuestro ciclo de desarrollo de productos, una prueba A / B es imprescindible. Probamos cada hipótesis y lanzamos solo cambios positivos.
Recopilamos cientos de métricas y podemos desglosarlas en secciones comerciales: verticales, regiones, usuarios autorizados, etc. Hacemos esto automáticamente usando una única plataforma para experimentos. En el artículo, le contaré con suficiente detalle cómo está organizada la plataforma y profundizaremos en algunos detalles técnicos interesantes.

Las funciones principales de la plataforma A / B se formulan de la siguiente manera.
- Te ayuda a ejecutar experimentos rápidamente
- Controla las intersecciones de experimentos no deseados
- Cuenta métricas, estadísticas. pruebas, visualiza resultados
En otras palabras, la plataforma ayuda a tomar decisiones sin errores más rápidamente.
Si dejamos de lado el proceso de desarrollo de características que se envían para la prueba, el ciclo completo del experimento se ve así:

- El cliente (analista o gerente de producto) configura los parámetros del experimento a través del panel de administración.
- El servicio dividido, de acuerdo con estos parámetros, distribuye el grupo A / B necesario al dispositivo cliente.
- Las acciones del usuario se recopilan en registros sin procesar que pasan por la agregación y se convierten en métricas.
- Las métricas se ejecutan a través de pruebas estadísticas.
- Los resultados se visualizan en el portal interno el día después del lanzamiento.
Todo el transporte de datos en un ciclo lleva un día. Como regla general, los experimentos duran una semana, pero el cliente recibe un incremento de resultados todos los días.
Ahora profundicemos en los detalles.
Gestión de experimentos
El panel de administración usa el formato YAML para configurar los experimentos.

Esta es una solución conveniente para un equipo pequeño: finalizar las capacidades de la configuración no tiene un frente. El uso de configuraciones de texto simplifica el trabajo para el usuario: debe hacer menos clics con el mouse. Una solución similar es utilizada por el marco A / B de Airbnb .
Para dividir el tráfico en grupos, utilizamos la técnica común de hash de sal.
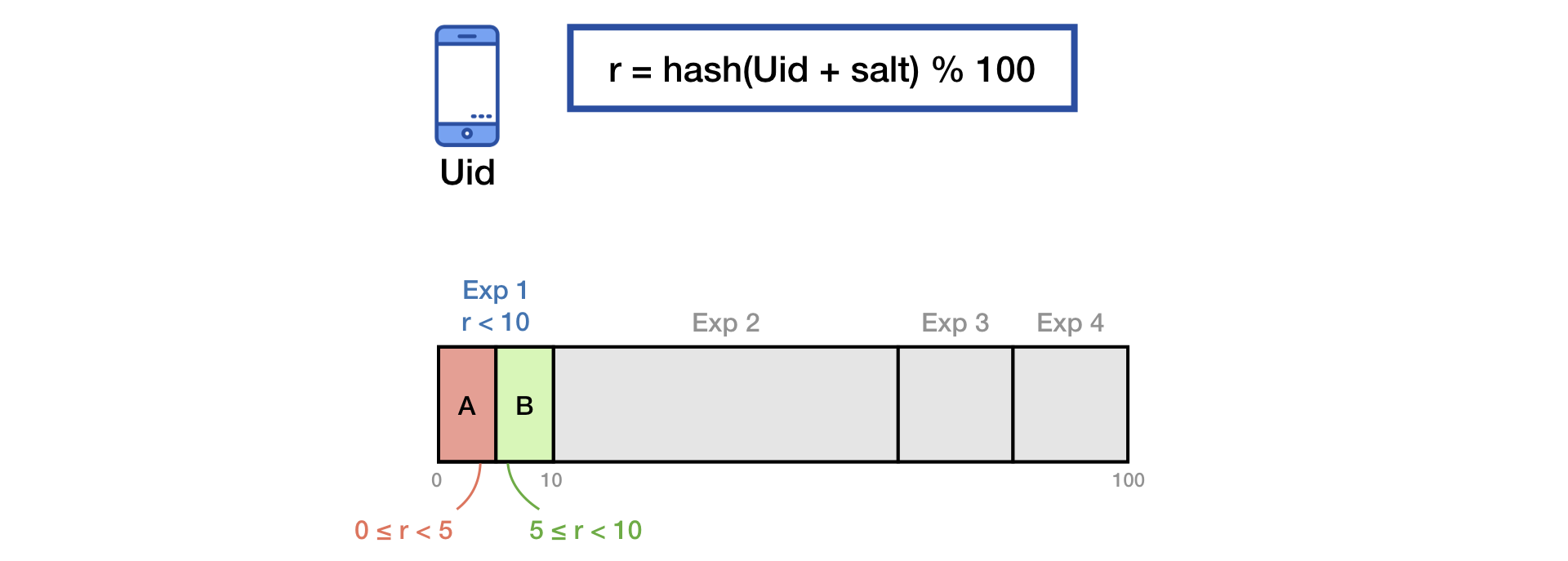
Para eliminar el efecto de "memoria" de los usuarios, al comenzar un nuevo experimento, hacemos una mezcla adicional con la segunda sal:

El mismo principio se describe en la presentación de Yandex .
Para evitar intersecciones de experimentos potencialmente peligrosas, utilizamos una lógica similar a las "capas" en Google .
Colección de métricas
Colocamos registros sin procesar en Vertica y los agregamos en tablas de preparación con la estructura:

Las observaciones suelen ser simples contadores de eventos. Las observaciones se usan como componentes en la fórmula de cálculo métrico.
La fórmula para calcular cualquier métrica es una fracción, cuyo numerador y denominador es la suma de las observaciones:
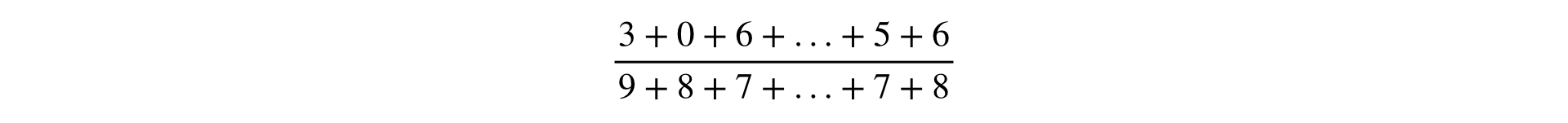
En uno de los informes de Yandex, las métricas se dividieron en dos tipos: por usuarios y Ratio. Esto tiene sentido comercial, pero en la infraestructura es más conveniente considerar todas las métricas de la misma manera que Ratio. Esta generalización es válida, porque la métrica "posyuzerny" es obviamente representable como una fracción:
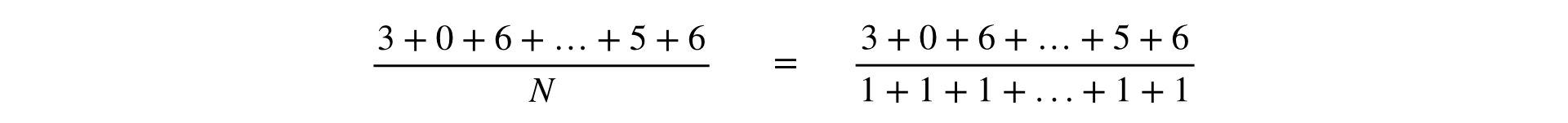
Resumimos las observaciones en el numerador y el denominador de la métrica de dos maneras.
Simple:
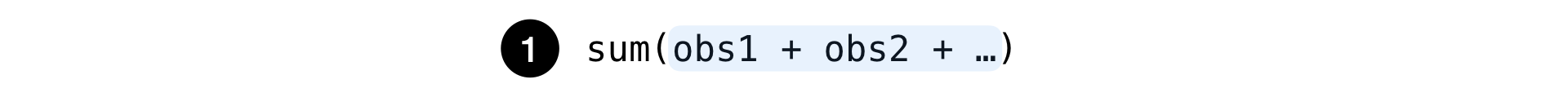
Esta es la cantidad habitual de cualquier conjunto de observaciones: el número de búsquedas, clics en anuncios, etc.
Y más complicado:

Un número único de claves, en la agrupación por la cual el total de observaciones es mayor que un umbral dado.
Dichas fórmulas se configuran fácilmente con la configuración YAML:

Los parámetros groupby y umbral son opcionales. Solo ellos determinan el segundo método de suma.
Los estándares descritos le permiten configurar casi cualquier métrica en línea que se le ocurra. Al mismo tiempo, se conserva una lógica simple que no impone una carga excesiva en la infraestructura.
Criterio estadístico
Medimos la importancia de las desviaciones por métrica utilizando los métodos clásicos: prueba T, prueba U de Mann-Whitney . La principal condición necesaria para aplicar estos criterios es que las observaciones en la muestra no deben depender unas de otras. En casi todos nuestros experimentos, creemos que los usuarios (Uid) satisfacen esta condición.

Ahora surge la pregunta: ¿cómo realizar la prueba T y la prueba MW para las métricas de relación? Para la prueba T, debe poder leer la varianza de la muestra, y para MW, la muestra debe estar "definida por el usuario".
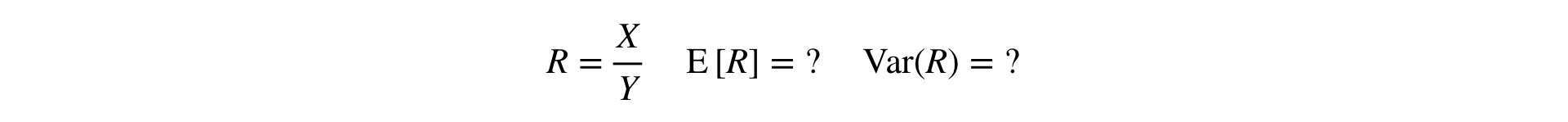
Respuesta: necesita expandir Ratio en una serie de Taylor a primer orden en un punto :
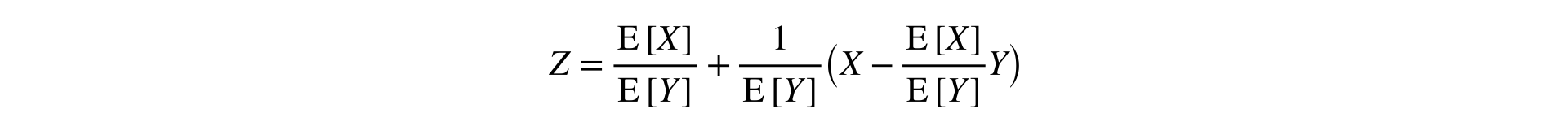
Esta fórmula convierte dos muestras (numerador y denominador) en una, preservando la media y la varianza (asintóticamente), lo que permite el uso de estadísticas clásicas. pruebas
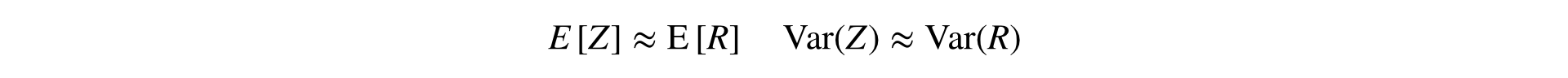
Los colegas de Yandex llaman a una idea similar el método de linealización de la relación (apariciones de una y dos veces ).
Rendimiento de escala
Uso rápido para estadísticas de CPU. Los criterios permiten llevar a cabo millones de iteraciones (comparaciones de tratamiento frente a control) en minutos en un servidor completamente normal con 56 núcleos. Pero en el caso de grandes volúmenes de datos, el rendimiento descansa, en primer lugar, en el almacenamiento y el tiempo de lectura del disco.
El cálculo diario de las métricas Uid genera muestras con un tamaño total de cientos de miles de millones de valores (debido a la gran cantidad de experimentos simultáneos, cientos de métricas y acumulación acumulativa). Es demasiado problemático exprimir tales volúmenes del disco todos los días (a pesar del gran grupo de la base de la columna Vertica). Por lo tanto, nos vemos obligados a reducir la cardinalidad de los datos. Pero hacemos esto casi sin pérdida de información sobre la varianza utilizando una técnica llamada "Bucket".
La idea es simple: dividimos los Uid y, según el resto de la división, los "dispersamos" en varios cubos (denotamos su número por B):
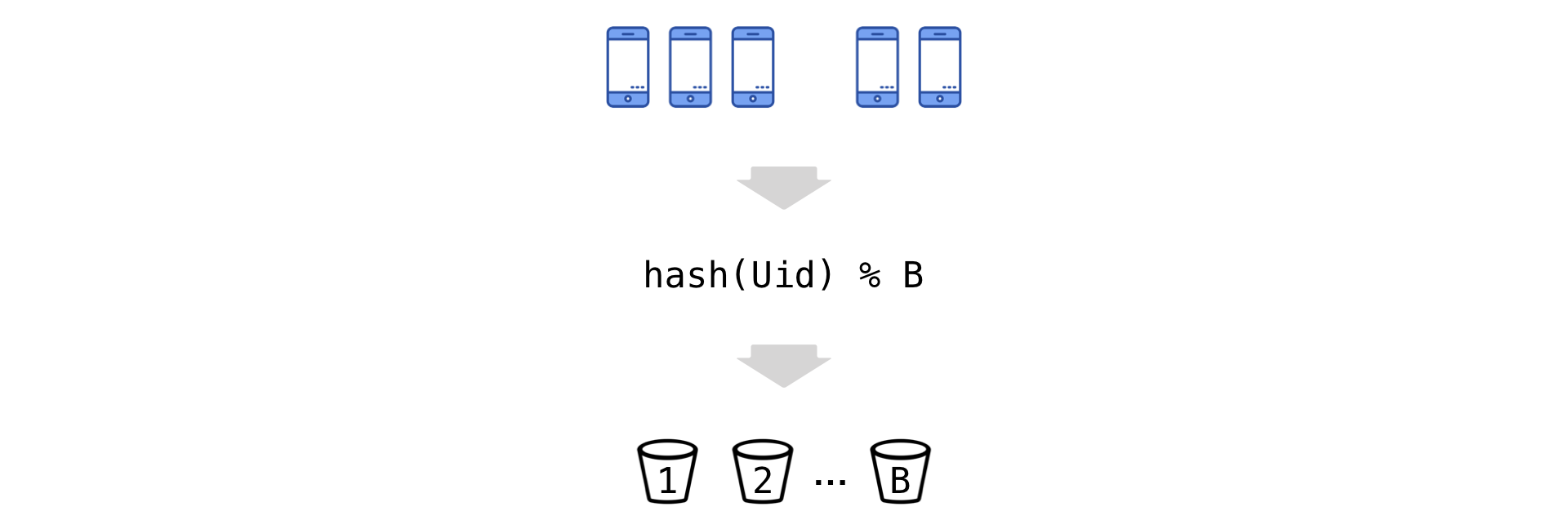
Ahora pasamos a la nueva unidad experimental: el cubo. Resumimos las observaciones en el cubo (el numerador y el denominador son independientes):

Con esta transformación, se cumple la condición de independencia de las observaciones, el valor de la métrica no cambia y es fácil verificar que se conserva la varianza de la métrica (promedio sobre la muestra de observaciones):

Cuanto más cubeta, menos información se pierde y menor es el error en igualdad. En Avito, tomamos B = 200.
La densidad de distribución métrica después de la conversión del cubo siempre se vuelve similar a la normal.
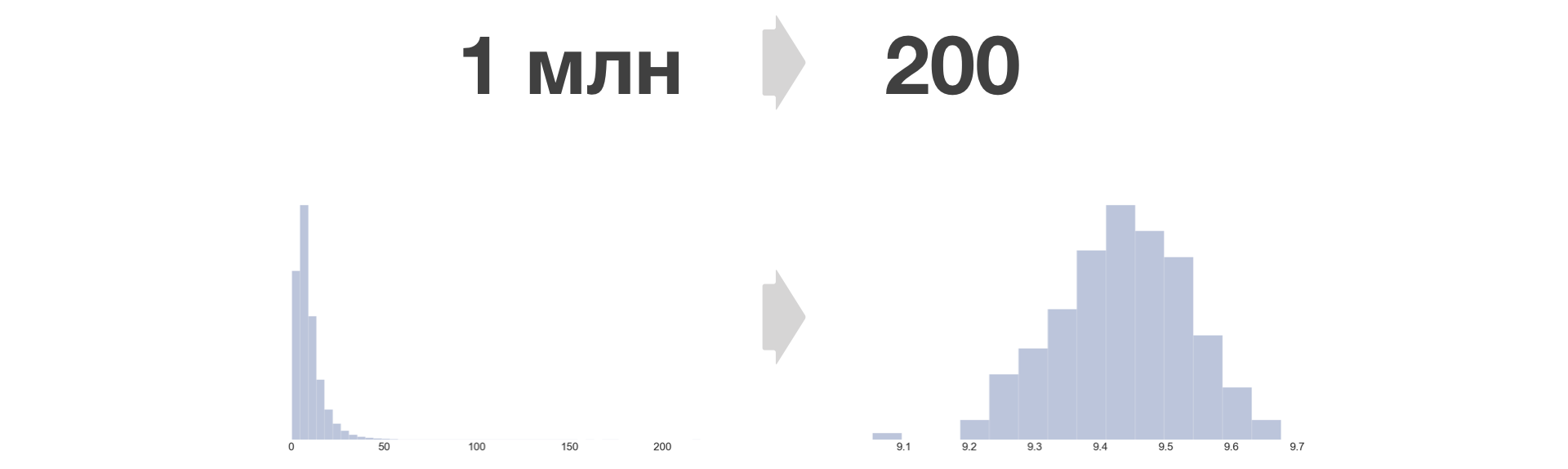
Se pueden reducir a un tamaño fijo tantas muestras grandes como desee. El crecimiento en la cantidad de datos almacenados en este caso solo depende linealmente del número de experimentos y métricas.
Visualización de resultados
Como herramienta de visualización, utilizamos Tableau y webview en Tableau Server. Todos los empleados de Avito tienen acceso allí. Cabe señalar que Tableau hace bien el trabajo. Implementar una solución similar usando un desarrollo completo de atrás / adelante sería una tarea mucho más intensiva en recursos.
Los resultados de cada experimento son una hoja de varios miles de números. La visualización debe ser tal que minimice las conclusiones incorrectas en el caso de la implementación de errores del primer y segundo tipo y, al mismo tiempo, no "omita" los cambios en métricas y secciones importantes.
Primero, monitoreamos las métricas de "salud" de los experimentos. Es decir, respondemos las preguntas: "¿Es cierto que los participantes fueron" vertidos "en cada uno de los grupos?", "¿Es igual a los usuarios autorizados o nuevos?"
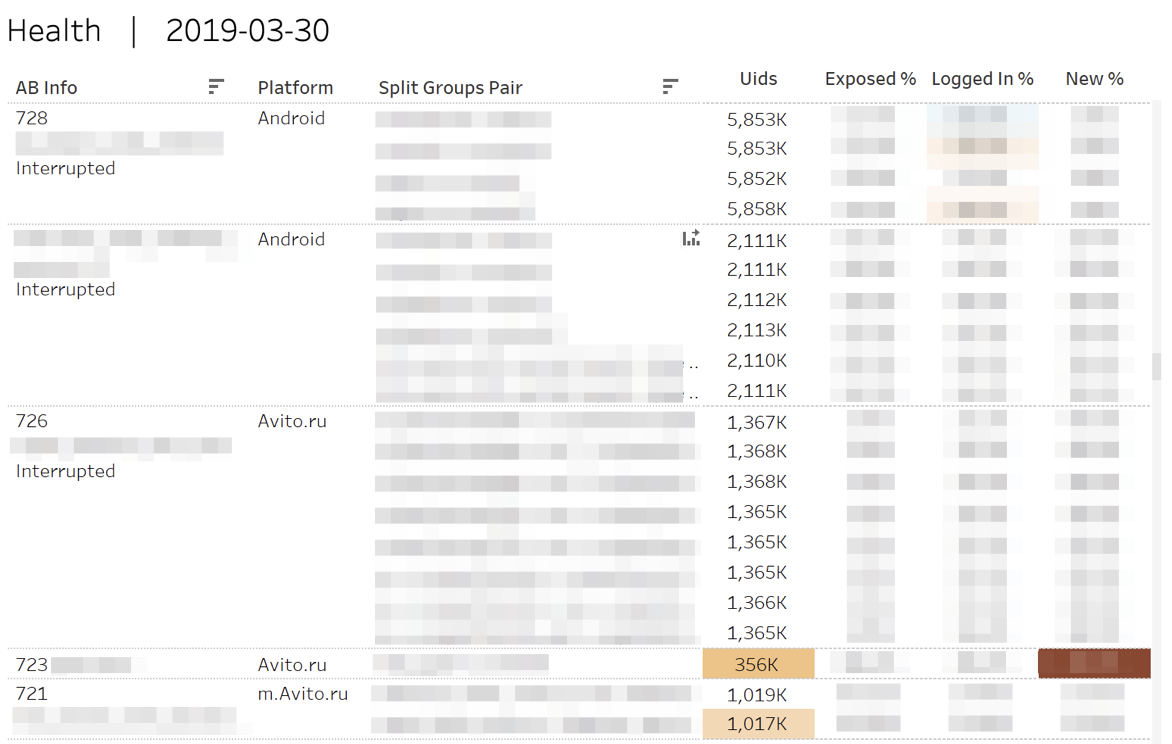
En el caso de desviaciones estadísticamente significativas, se resaltan las celdas correspondientes. Cuando pasa el cursor sobre cualquier número, se muestra la dinámica acumulativa del día.
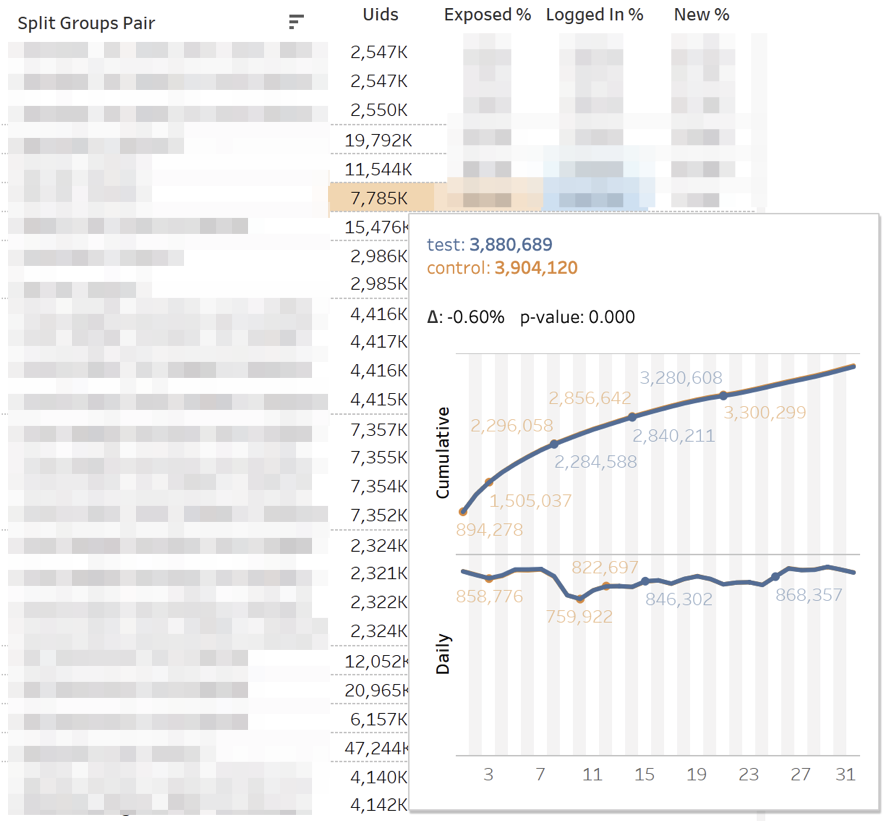
El panel principal con métricas se ve así:
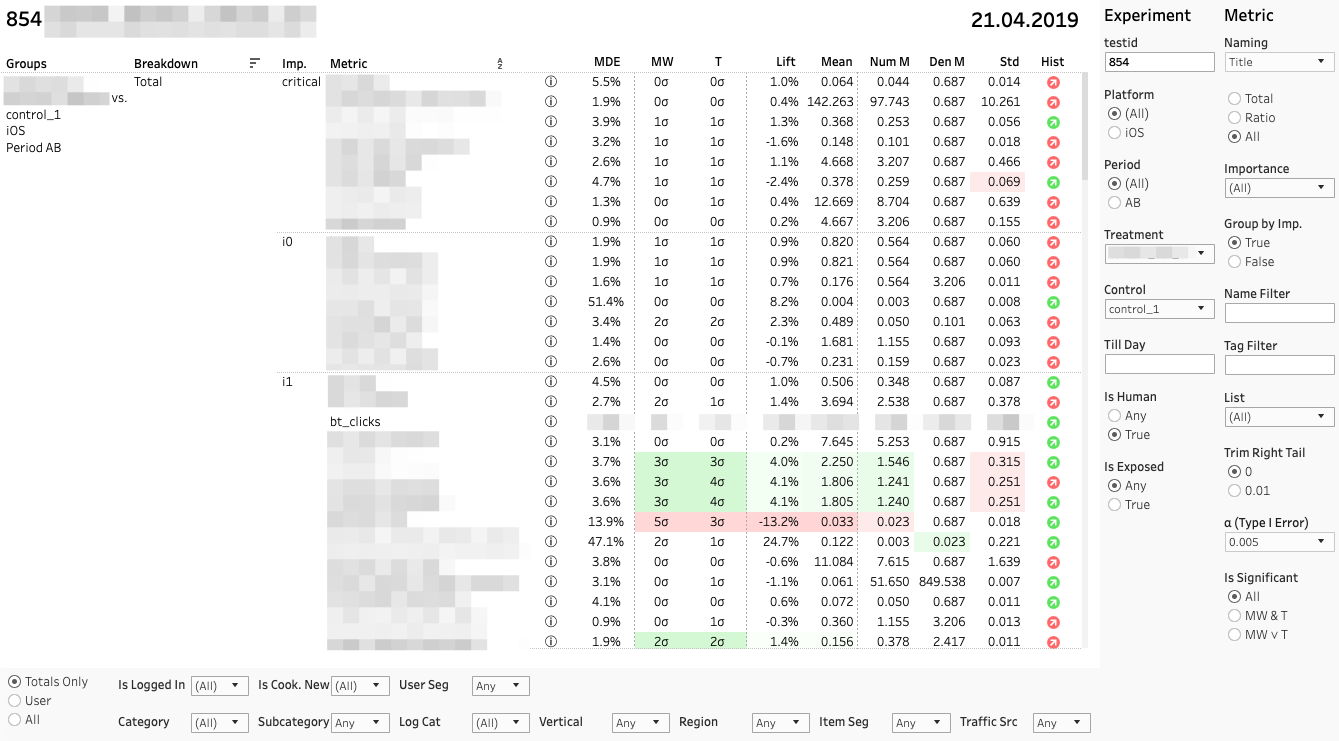
Cada fila es una comparación de grupos por una métrica específica en una sección específica. A la derecha hay un panel con filtros para experimentos y métricas. Panel de filtro de la sección inferior.
Cada comparación de métrica consta de varias métricas. Analicemos sus valores de izquierda a derecha:
1. MDE. Efecto mínimo detectable

⍺ y β son probabilidades de error preseleccionadas del primer y segundo tipo. MDE es muy importante si el cambio no es estadísticamente significativo. Al tomar una decisión, el cliente debe recordar que la falta de estadísticas. la importancia no equivale a ningún efecto. De manera bastante confiable, solo podemos decir que el posible efecto no es más que MDE.
2. MW | T. Mann-Whitney Resultados de las pruebas U y T
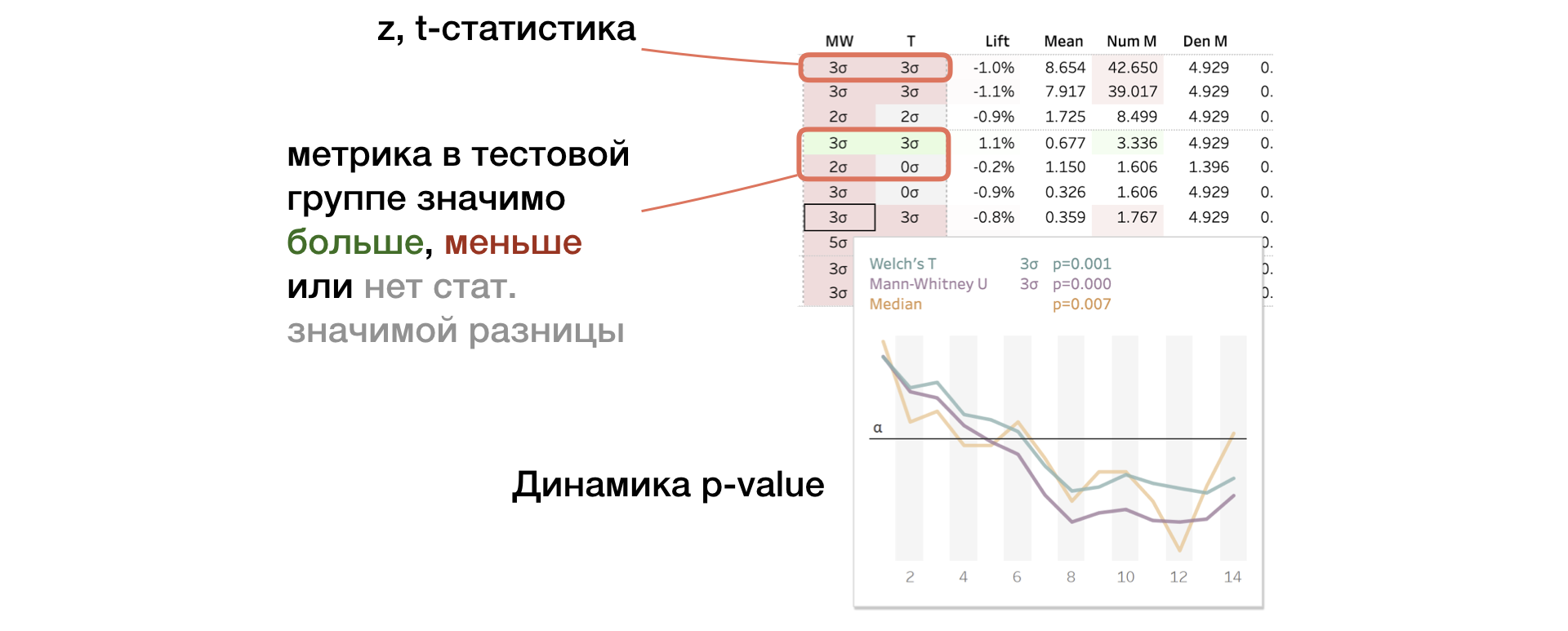
El panel muestra el valor de las estadísticas z y t (para MW y T, respectivamente). En una descripción emergente: dinámica del valor p. Si el cambio es significativo, la celda se resalta en rojo o verde, según el signo de la diferencia entre los grupos. En este caso, decimos que la métrica está "coloreada".
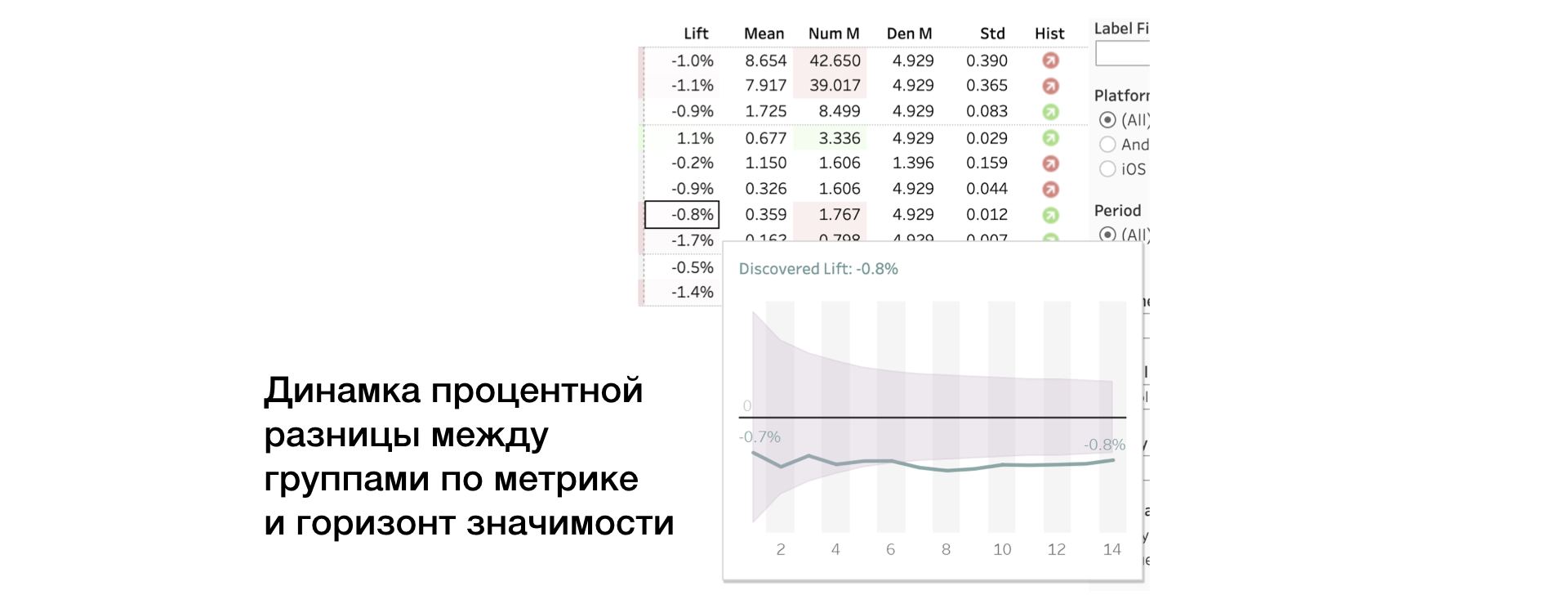
3. Ascensor. Diferencia porcentual entre grupos
4. Media | Num | Den Valor métrico, así como numerador y denominador por separado
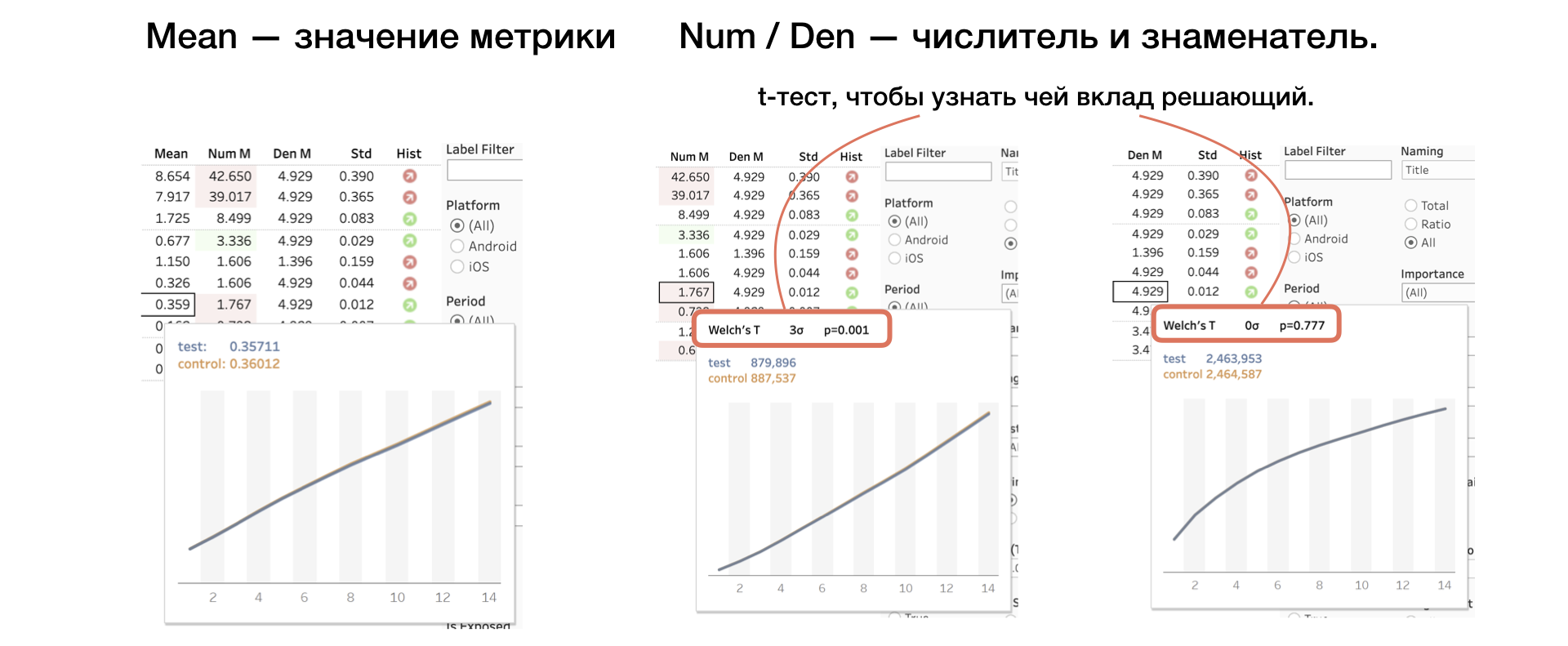
Aplicamos otra prueba T al numerador y al denominador, lo que ayuda a comprender qué contribución es decisiva.
5. Std. Desviación estándar selectiva
6. Hist. Prueba de Shapiro-Wilk para la normalidad de la distribución de "cubos".
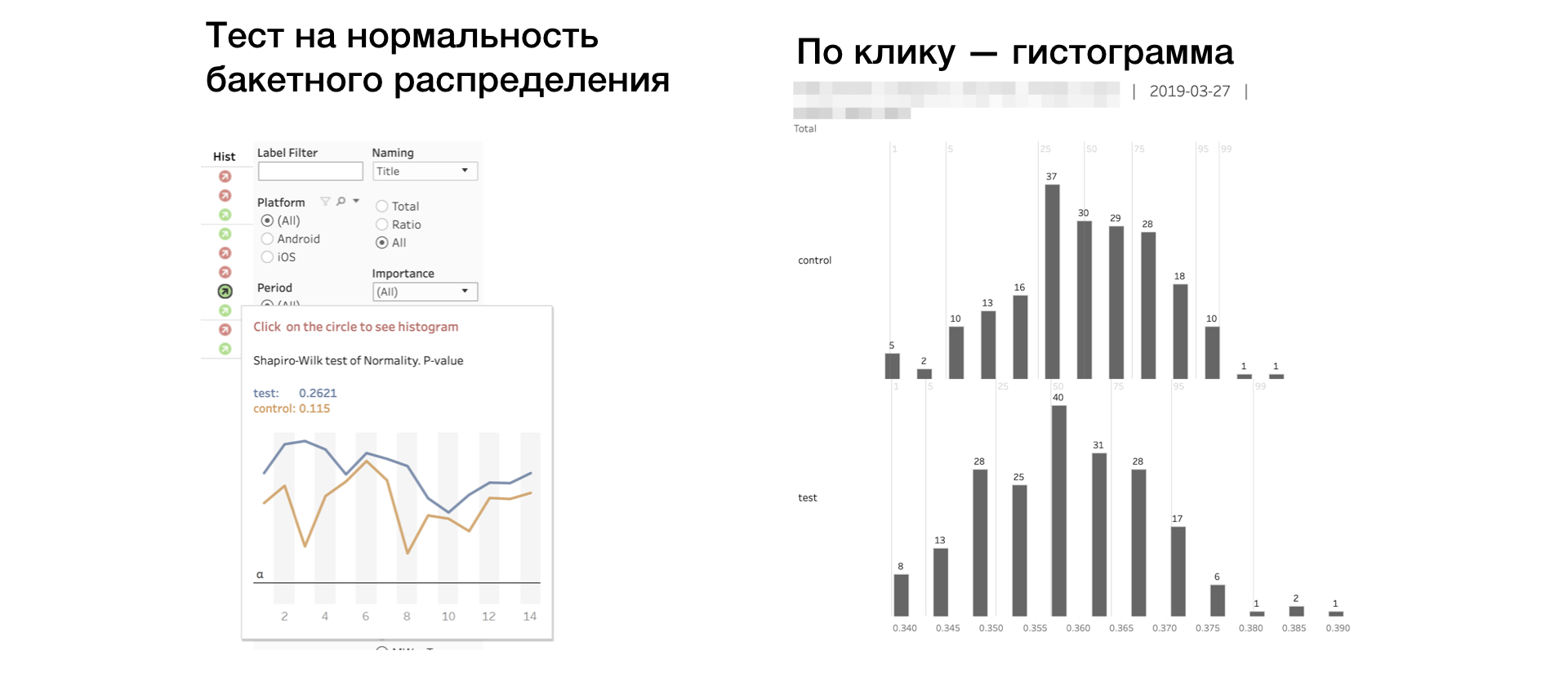
Si el indicador es rojo, entonces quizás la muestra tenga valores atípicos o una cola anormalmente larga. En este caso, debe tomar el resultado de acuerdo con esta métrica con cuidado, o nada en absoluto. Al hacer clic en el indicador, se abre el histograma de la métrica por grupo. El histograma muestra claramente anomalías: es más fácil sacar conclusiones.
Conclusión
El surgimiento de la plataforma A / B en Avito es un hito cuando nuestro producto comenzó a crecer más rápido. Todos los días, realizamos experimentos ecológicos que cargan al equipo; y "rojos", que proporcionan alimento saludable para el pensamiento.
Logramos construir un sistema efectivo de pruebas y métricas A / B. A menudo resolvimos problemas complejos con métodos simples. Debido a esta simplicidad, la infraestructura tiene un buen margen de seguridad.
Estoy seguro de que aquellos que van a construir la plataforma A / B en su empresa encontraron algunas ideas interesantes en el artículo. Me complace compartir nuestra experiencia con usted.
Escriba preguntas y comentarios, trataremos de responderlas.