En un artículo anterior, examinamos el enfoque que aplicamos al tema del procesamiento de datos computacionales (agregación) para la visualización en paneles interactivos. El artículo abordaba la etapa de entrega de información de fuentes primarias a los usuarios en el contexto de casos analíticos, que hacen posible rotar el cubo de información. El modelo de conversión de datos presentado sobre la marcha crea una abstracción, proporcionando un único formato de consulta y un constructor para describir los cálculos, la agregación y la integración de todos los tipos de fuentes conectadas: tablas de base de datos, servicios y archivos .
Es más probable que las fuentes enumeradas sean estructuradas, lo que implica la previsibilidad del formato de datos y la singularidad de los procedimientos para su procesamiento y visualización. Pero para el analista, los datos no estructurados no son menos interesantes, lo que cuando aparecen los primeros resultados, a veces sobreestima las expectativas de tales sistemas. El apetito viene con comer, y la pérdida de precaución puede repetir exactamente la historia ...
- Más! ¡Más oro!
Pero su silbido apenas era audible y el horror apareció en sus ojos.
(cuento de hadas "Golden Antelope")

Bajo el corte, el artículo describe las características clave y el diseño de un clúster de múltiples funciones y un rastreador de comportamiento por parte de usuarios virtuales que automatizan la rutina de recopilar información de recursos complejos de Internet. Y solo se plantea la cuestión del límite de tales sistemas.
Al considerar los métodos de rastreo, cualquier recurso hipotético de Internet del que necesitemos extraer información se puede colocar en una escala con dos extremos: desde recursos estáticos simples y API hasta sitios interactivos dinámicos que requieren una alta participación del usuario. Los primeros incluyen la generación anterior de robots de búsqueda (los modernos, al menos, han aprendido a procesar JavaScript ), los últimos incluyen sistemas con granjas de navegador y algoritmos que simulan el trabajo del usuario o lo atraen al recopilar información.
En otras palabras, las tecnologías de rastreo se pueden colocar en una escala de complejidad:

Por un lado, la complejidad de la fuente puede entenderse como una cadena de acciones necesarias para obtener información primaria y, por otro lado, tecnologías que deben aplicarse para obtener datos legibles por máquina adecuados para el análisis.
Incluso la extracción aparentemente simple de textos de páginas estáticas no siempre es trivial en la práctica: es necesario desarrollar y mantener reglas de planarización HTML para todo tipo de páginas, o automatizar e inventar heurísticas y soluciones complejas. Hasta cierto punto, la estructuración se simplifica mediante el desarrollo de micro-marcado ( en particular, Schema.org , RDFa , Linked Data ), pero solo en casos especiales estrechos, para descargar tarjetas de empresa, productos, tarjetas de visita y otros productos de optimización de motores de búsqueda y datos abiertos.
A continuación, reduciremos deliberadamente el alcance y nos enfocaremos en el componente tecnológico de un subconjunto de rastreadores de navegador diseñados para descargar información de sitios complejos, en particular redes sociales; este es el caso correcto cuando otros métodos simples de rastreo no funcionan.
Considere un enfoque que reduce la tarea de recopilar información de las redes sociales a la formación de una cinta de línea de tiempo de información: una colección actualizada o flujo de objetos con atributos y marcas de tiempo. La lista de tipos de objetos y sus atributos es diferente, modificable y ampliable, por ejemplo: publicaciones, me gusta, comentarios, reposts y otras entidades que los desarrolladores y operadores analíticos agregan al sistema y que los rastreadores cargan.
Como la cinta es un flujo de objetos estructurados, surge la cuestión de su relleno. Apoyamos dos tipos de cintas:
- una cinta simple que está llena de contenido de fuentes fijas;
- un feed de temas lleno de contenido según palabras clave, frases y términos de búsqueda.
Un ejemplo de un feed simple con fuentes fijas (se establecen listas de URL para perfiles y páginas ):

Un tipo simple de cinta implica el rastreo periódico de estos perfiles y páginas en varias redes sociales con una profundidad de rastreo determinada y la carga de objetos seleccionados por el usuario. A medida que se llena, la cinta queda disponible para ver, analizar y cargar datos:

La cinta temática es una extensión simple, proporciona búsqueda de texto completo y filtrado de objetos cargados en la cinta. El sistema controla automáticamente el conjunto de fuentes de cinta y la profundidad de su derivación, analizando la relevancia y las relaciones de las fuentes. Esta característica de la implementación se debe a la ausencia o al trabajo "extraño" de la búsqueda integrada de palabras clave en las redes sociales. Incluso cuando dicha función está disponible, la mayoría de las veces los resultados no se generan por completo y de acuerdo con algún algoritmo interno, que es completamente incompatible con los requisitos del rastreador.
Un mecanismo especial con una cierta heurística es responsable de administrar la cinta en el sistema: analiza los datos y el historial, agrega fuentes relevantes (perfil y feeds de la comunidad), en las que se mencionan expresiones específicas o de alguna manera están relacionadas con ellas, y elimina las irrelevantes.
Un ejemplo de una cinta temática:

En el futuro, las cintas se utilizan como fuente en las transformaciones analíticas con la visualización posterior de los resultados, por ejemplo, en forma de gráfico:

En algunos casos, el procesamiento de transmisión de objetos entrantes se realiza con el almacenamiento en colecciones de destino especializadas o la carga a través de la API REST para utilizar el contenido recopilado en sistemas de terceros ( ejemplo ). En otros, se realiza el procesamiento de bloque por temporizador. El operador describe el script de procesamiento con un script o construye un proceso con señales de control y bloques de funciones, por ejemplo:

Grupo de tareas
Las cintas activas definen el grupo de tareas principal, cada una de las cuales forma tareas relacionadas. Por ejemplo, una tarea transversal de un solo perfil puede generar muchas subtareas relacionadas: omitir amigos, suscriptores o descargar nuevas publicaciones e información detallada, etc. También hay una etapa de preprocesamiento de nuevos objetos de la cinta temática, que también forma tareas relacionadas con nuevas fuentes relevantes.
Como resultado, obtenemos una gran cantidad de diferentes tipos de tareas relacionadas entre sí, que tienen prioridades, tiempo y condiciones de ejecución: todo este zoológico debe gestionarse correctamente para que no haya situaciones en las que algunas tareas arrastren todos los recursos del clúster en detrimento de las tareas de otras cintas .
Para resolver las inconsistencias, el sistema implementa recursos virtuales compartidos y un mecanismo para la priorización dinámica, que tiene en cuenta los tipos de tareas, la hora actual y la probabilidad de lanzamiento en forma de "domo". En términos generales, la prioridad en cierto punto se convierte en máxima, pero pronto se desvanece, la tarea "agria", pero bajo ciertas circunstancias puede volver a crecer.
La fórmula para dicho domo tiene en cuenta varios factores, en particular: la prioridad de las tareas principales, la relevancia de la fuente asociada y el momento del último intento (con rastreos repetidos para rastrear cambios o cuando se produce un error).
Usuarios virtuales
En sentido amplio, un usuario virtual puede entenderse como la máxima imitación de las acciones humanas, en términos prácticos, un conjunto de propiedades que un rastreador debería tener:
- ejecute el código de la página utilizando las mismas herramientas que el usuario: sistema operativo, navegador, UserAgent, complementos, conjuntos de fuentes y más;
- interactuar con la página, simulando el trabajo de una persona con un teclado y un mouse: mueva el cursor en la página, haga movimientos aleatorios, pausas, presione las teclas al imprimir texto y más ( no se olvide de los dispositivos móviles );
- interactuar con un centro de decisiones que tenga en cuenta el contexto y el contenido de la página:
- tenga en cuenta los duplicados, la relevancia de los objetos en la página, la profundidad de rastreo, los plazos y más;
- responder a situaciones inusuales: en caso de captcha o error, formule una solicitud y espere una solución, ya sea utilizando un servicio de terceros o con la participación de un operador del sistema;
- tenga una leyenda creíble: guarde su historial de navegación y cookies (perfil del navegador), use ciertas direcciones IP, tenga en cuenta los períodos de mayor actividad (por ejemplo, mañana-tarde o almuerzo-noche).
En una vista idealizada, un usuario virtual puede tener varias cuentas, usar varios navegadores en diferentes períodos de tiempo y estar conectado con otros usuarios virtuales, además de poseer el comportamiento y los hábitos de navegación en Internet característicos de una persona.
Por ejemplo, imagine una situación así: la virtual usa un navegador e IP como si estuviera en el trabajo (los "colegas" pueden usar la misma IP, otro navegador e IP como si estuviera en casa (los "vecinos" los usan), y de vez en cuando teléfono móvil Con esta visión del problema, contrarrestar la recolección automatizada por los servicios de Internet parece ser una tarea no trivial y, posiblemente, poco práctica.
En la práctica, todo es mucho más simple: la lucha contra los rastreadores es como una ola e incluye un pequeño conjunto de técnicas: moderación manual, análisis del comportamiento del usuario (frecuencia y uniformidad de las acciones) y mostrar captcha. Claruler, que posee al menos en cierta medida las propiedades de la lista anterior, implementa completamente el concepto de usuarios virtuales y, con la debida atención del operador, puede cumplir su función durante mucho tiempo, permaneciendo como " elusivo Joe ".
Pero, ¿qué pasa con el lado ético y legal del uso de usuarios virtuales?
Para no jugar con los conceptos de datos públicos y personales, cada una de las partes tiene sus propios argumentos de peso, solo tocaremos los puntos fundamentales.
La publicación automatizada de contenido, el envío de correo no deseado, el registro de cuentas y otras actividades "activas" de usuarios virtuales pueden considerarse fácilmente ilegales o afectar los intereses de terceros. En este sentido, el sistema implementa un enfoque en el que los usuarios virtuales solo son observadores curiosos que representan al usuario (su operador) y realizan una rutina para recopilar información.
Gestión de recursos virtuales compartidos.
Como se describió anteriormente, un usuario virtual es una entidad colectiva que utiliza varios sistemas y recursos virtuales en el proceso. Algunos recursos se usan solos, mientras que otros son compartidos y utilizados por varios usuarios virtuales, por ejemplo:
- dirección de nodo de salida (IP externa): asociada con uno o más usuarios virtuales;
- perfil del navegador: asociado con un solo usuario virtual;
- recurso informático: conectado al servidor, establece las limitaciones del servidor en su conjunto y para cada tipo de tarea;
- pantalla virtual: establece restricciones de servidor, pero es utilizada por el usuario virtual.
Cada recurso virtual tiene un tipo y un grupo de instancias llamadas ranuras. En cada nodo del clúster, se define la configuración de los recursos virtuales y las ranuras, que se agregan al grupo de recursos virtuales y son accesibles para todos los nodos del clúster. Además, para un tipo de recurso virtual, se pueden agregar un número fijo y variable de ranuras.
Cada ranura puede tener atributos que se utilizarán como condiciones al vincular y asignar recursos. Por ejemplo, podemos asociar a cada usuario virtual con ciertos tipos de tareas, servidores, direcciones IP, cuentas, períodos de mayor actividad de rastreo y otros atributos arbitrarios.
En el caso general, el ciclo de vida de un recurso consta de ciertas etapas:
- Cuando se inicia un nodo de clúster en el grupo compartido de recursos virtuales, se registran espacios abiertos adicionales, así como enlaces entre recursos;
- Cuando un despachador inicia una tarea desde un grupo de recursos virtuales, se selecciona y bloquea un espacio libre adecuado. A su vez, el bloqueo del recurso padre conduce al bloqueo de los recursos relacionados y, en ausencia de espacios libres, se genera una falla;
- Al finalizar la tarea, se liberan el espacio de recursos principal y sus espacios asociados.
Además de los especificados en la configuración del nodo, también hay recursos virtuales de usuario, entidades con las que trabaja el operador del sistema. En particular, el operador utiliza la interfaz de registro de usuario virtual, que admite varias funciones útiles a la vez:
- gestión de detalles y atributos adicionales que indican los detalles de uso, en particular, los usuarios virtuales pueden dividirse en grupos y usarse para diferentes propósitos;
- seguimiento del estado y estadísticas de usuarios virtuales;
- conexión a la pantalla virtual: seguimiento en tiempo real del trabajo, realización de acciones en el navegador en lugar del usuario virtual (widget de escritorio remoto).
Ejemplo de registro de recursos virtuales de usuario:

Caso genial que no echó raíces
Además de las cintas informativas como un "fitchi asesino", desarrollamos un gráfico de búsqueda prototipo para realizar búsquedas complejas y realizar investigaciones en línea. La idea principal es construir un gráfico visual en el que los nodos sean las plantillas de objetos (personas, organizaciones, grupos, publicaciones, me gusta, etc.), y los enlaces sean los patrones de conexión entre los objetos encontrados.
Un ejemplo de un simple gráfico de búsqueda de personas y las relaciones entre ellas:

Este enfoque supone que la búsqueda comienza con un mínimo de información conocida. Después de la búsqueda inicial, el usuario examina los resultados y agrega gradualmente condiciones adicionales al gráfico de búsqueda, reduciendo la selección y aumentando la profundidad de rastreo y la precisión del resultado. En última instancia, el gráfico toma la forma en que cada uno de los nodos es una fuente de información separada con los resultados. Esta cinta también se puede utilizar como fuente para análisis y visualización adicionales en paneles y widgets.

Por ejemplo ...Como ejemplo, podemos considerar algunos casos simples:
- encuentre a todos los amigos de la persona con el nombre de pila;
- Encuentra todas las publicaciones de amigos de una persona con un nombre de pila y otros atributos;
- encuentre todos los suscriptores a las páginas donde se mencionan las frases clave especificadas, o reúna el entorno en torno a ciertas publicaciones o autores;
- o encontrar intersecciones: autores de comentarios en todas las publicaciones escritas por autores que alguna vez publicaron publicaciones sobre temas específicos.
Cuando anunciamos el desarrollo de tal ajuste, nuestros clientes y socios respaldaron calurosamente esta idea, que parecía ser exactamente lo que faltaba en soluciones similares existentes. Pero al completar el prototipo de trabajo, en la práctica resultó que los clientes no estaban listos para cambiar sus procesos internos, y las investigaciones de Internet se consideraron más bien como algo que podría ser útil si de repente lo necesitaran. Al mismo tiempo, desde el punto de vista tecnológico, la funcionalidad es seria y requiere un mayor refinamiento y soporte. Como resultado, debido a la falta de demanda y el interés práctico de nuestros socios, este ajuste tuvo que congelarse temporalmente hasta tiempos mejores.
Reencarnación
Dado el vector actual de desarrollo de nuestras soluciones, esta característica todavía parece relevante, pero desde el punto de vista técnico ya se ve de una manera diferente. Más bien, es una extensión de la funcionalidad de Cubisio, es decir, el editor del modelo de dominio y el editor de procesos de procesamiento de datos, que hasta ahora se han implementado como un prototipo, pero proporcionan un enfoque similar en una forma generalizada.
Un ejemplo del modelo ontológico del área temática "Redes sociales" (al hacer clic en la imagen del editor se abre):

Un ejemplo de un gráfico analítico de búsqueda basado en la ontología anterior (al hacer clic en la imagen se abre el editor):

Pila de tecnología de clúster

El sistema descrito se desarrolló en conjunto con la plataforma (lo llamamos dWires) hace varios años, está funcionando y todavía está en uso. Las principales soluciones exitosas migraron naturalmente a nuestros nuevos desarrollos. En particular, la plataforma descrita representa la primera generación del diseñador de sistemas analíticos de información, de la cual la plataforma jsBeans y nuestros otros desarrollos se han separado.
En resumen, el sistema se basa en el clúster de Akka, el intérprete de Rhino y el servidor web incorporado Jetty. Algunas características arquitectónicas útiles se pueden ver en el diagrama de arriba. , , , JavaScript- , jsBeans .
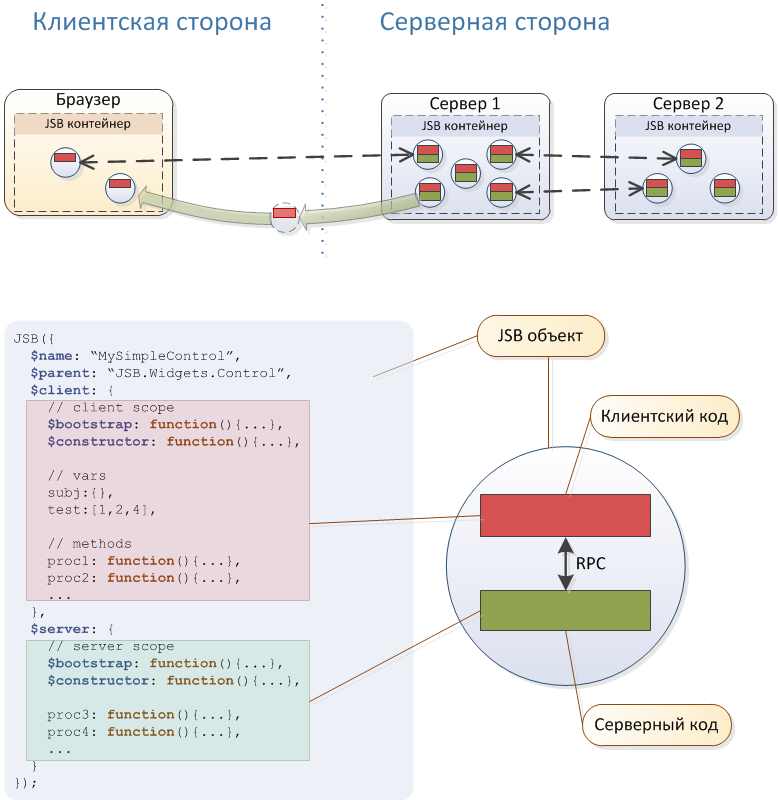
, – .
Java. , , – - JavaScript. JavaScript ( ), , , . – , , , , , - .
Akka - . - Akka Cluster , . , " " ( ) .
Selenium WebDriver , : , , API . WebDriver ( , IP ).
( ):
- , , Xvfb;
- VNC , , x11vnc;
- VNC Web Viewer , , noVNC -.
MongoDB, – . Elasticsearch, MongoDB. (H2, EhCache, Db4o).
" ", , bash , ( ). . , .
, .
. – . , " ".
, .
,
( « »)