
¿Está familiarizado con una situación en la que pasa una gran cantidad de tiempo eligiendo una película comparable al tiempo que la vio? Para los usuarios de cines en línea, este es un problema común, y para los cines mismos: ganancias perdidas.
Afortunadamente, tenemos Rekko, un sistema de recomendaciones personales que ha ayudado con éxito a los usuarios de Okko durante un año a elegir películas y series de más de diez mil unidades de contenido. En el artículo le diré cómo está organizado desde el punto de vista algorítmico y técnico, cómo abordamos su desarrollo y cómo evaluamos los resultados. Bueno, también te contaré sobre los resultados de la prueba anual A / B.
Primero, un poco de historia. Okko comenzó su existencia en 2011 como parte de Iota, comenzando con el nombre de Yota Play.
Ya en 2011, los usuarios aceptaron con entusiasmo la idea de ver una película legalmente en Internet. Yota Play fue un servicio único para su época: se integró estrechamente con las redes sociales y utilizó información sobre películas vistas y calificadas por amigos en muchas partes del servicio, incluidas las recomendaciones.

En 2012, se decidió complementar las recomendaciones sociales con las algorítmicas. Así es como apareció "Oracle": el primer sistema de recomendación del cine en línea Okko. Aquí hay algunos extractos de su documento de diseño:
Se utilizó un enfoque similar en el sistema implementado de recomendaciones personales. La escala de niveles se utiliza desde "nada" (vacío, ausencia) hasta "todo" (completamente, al máximo). En el rango [127 .. + 127] 0 - es el medio o "norma". En esta escala, también se evalúa el grado de simpatía por el personaje principal y el precio subjetivo del producto y el grado de color "rojo". Por ejemplo, el tamaño del universo se estima en +127 (en la escala de dimensiones), y la oscuridad se estima en 127 (en la escala de intensidad de la luz).
Al hacer recomendaciones, es importante no solo el fondo, sino también la naturaleza del usuario en particular. El perfil personal también contiene 4 escalas de tipos de personajes (según K. Leonhard: demostrativo, pedante, atascado, excitable).
Los límites fisiológicos del cerebro no dependen de las propiedades del carácter de una persona y de cuán amigable y sociable es. Según el profesor, existen restricciones en la neocorteza, el departamento responsable de los pensamientos conscientes y el habla. Esta restricción también se tiene en cuenta en el sistema implementado, especialmente al desarrollar recomendaciones para un tipo de personaje pedante y al formar una muestra de dichos usuarios entre las conexiones sociales.

Como ya entendió, los tiempos eran salvajes, los límites fisiológicos del cerebro no se limitaban a nada, y el propio neocórtex overclockeado podía generar recomendaciones personales a la velocidad de la luz. Por lo tanto, se decidió que el modelo entrara en producción de inmediato.
Hasta donde se puede juzgar por los artefactos supervivientes de la civilización antigua, "Oracle" fue una mezcla salvaje de algoritmos de filtrado colaborativos, generosamente sazonados con reglas comerciales.

A mediados de 2013, todos comenzaron a soltar un poco y finalmente se decidió verificar la calidad de la máquina de recomendación. Para hacer esto, un editor especialmente entrenado llenó las secciones principales de la aplicación y se lanzó la prueba A / B: la mitad de los usuarios vieron la salida del algoritmo, la mitad, la elección del editor.
Es ahora cuando estamos leyendo artículos sobre las próximas victorias de la inteligencia artificial y con horror imaginamos el día en que perderá nuestro trabajo. Luego, en 2013, la situación fue diferente: una persona derrotó heroicamente el automóvil, creando aún más empleos en el departamento de contenido. El oráculo se apagó y nunca se volvió a encender. Pronto, todas las fichas sociales desaparecieron, y Yota Play se convirtió en Okko.
El período comprendido entre 2013 y 2016 estuvo marcado por el "invierno" de la inteligencia artificial y la regla totalitaria del departamento de contenido: no hubo recomendaciones personales en el servicio.
A mediados de 2017, quedó claro que ya no puedes vivir así. Los éxitos de Netflix eran bien conocidos por todos y toda la industria se estaba moviendo a un ritmo rápido hacia la personalización. Los usuarios ya no estaban interesados en los servicios estáticos "tontos", ya estaban comenzando a acostumbrarse a las interfaces "inteligentes", comprendiéndolos perfectamente y prediciendo todos sus deseos.
Como primera iteración, decidimos integrarnos con dos grandes proveedores rusos de recomendaciones. Una vez al día, ambos servicios tomaron los datos necesarios de Okko, susurraron con sus cajas negras en servidores distantes y subieron los resultados.
Según los resultados de la prueba A / B de seis meses, no se encontraron diferencias estadísticamente significativas en los grupos de control y prueba.
Justo al final de esta prueba A / B, vine a Okko para comenzar a hacer que el servicio sea realmente personal con el jefe de análisis, Mikhail Alekseev ( malekseev ). Menos de un año después, Danil Kazakov ( xaph ) se unió a nosotros y finalmente formó el equipo actual.
Consideraciones generales
Cuando surge un problema comercial que ha sido estudiado por la comunidad internacional por mucho tiempo y que, además, debe resolverse rápidamente, es tentador tomar la primera solución popular de red neuronal profunda que tiene, introducir los datos con una pala, embestirla y arrojarla al producto.

Lo principal es no sucumbir a esta tentación. La tarea de la comunidad científica, lograr la máxima velocidad en conjuntos de datos podridos y sintéticos, a menudo no coincide con la tarea empresarial, de ganar más dinero y gastar menos recursos.

No, esto no significa que no necesite redes recurrentes y que pueda acumular miles de millones utilizando el método de k vecinos más cercanos. Es posible que en sus datos la descomposición clásica de la matriz le permita ganar 100 millones condicionales adicionales por año y redes recurrentes: 105 millones por año. Al mismo tiempo, mantener un rack de servidores con tarjetas de video para estas mismas redes costará 10 millones al año y requerirá varios meses adicionales para desarrollarse e implementarse, y la simple integración de una descomposición matricial lista para usar en otra sección del servicio y la lista de correo requerirá un mes de mejoras y dará otros 100 millones condicionales. por año
Por lo tanto, es importante comenzar con lo básico (métodos básicos probados) y avanzar hacia enfoques cada vez más modernos, asegúrese de medir y predecir qué efecto tendrá cada nuevo método en el negocio, cuánto costará y cuánto le permitirá ganar.
Okko puede medir bien. Literalmente, cada nueva característica, cada innovación que tenemos pasa por una prueba A / B, se examina en el contexto de una variedad de grupos de usuarios, se verifica la importancia estadística de los efectos y solo después de eso se toma la decisión de aceptar o rechazar la nueva funcionalidad.

El panel actual de Rekko, por ejemplo, compara los grupos de control y prueba para más de 50 métricas, incluidos los ingresos, el tiempo dedicado al servicio, el tiempo para elegir una película, el número de vistas por suscripción, la conversión a la compra y la renovación automática, y muchos otros. Y sí, todavía tenemos un pequeño grupo de usuarios que nunca han recibido recomendaciones personalizadas (lo siento).

Sobre los sistemas de recomendación
Para comenzar, una pequeña introducción a los sistemas de recomendación.
El objetivo del sistema de recomendación es que para cada usuario en su historia de interactuar con elementos para construir una relación de orden en el conjunto de todos los elementos. Esto significa esto: no importa qué dos elementos arbitrarios tomemos, siempre podemos decir cuál es más preferible para el usuario y cuál es menos.
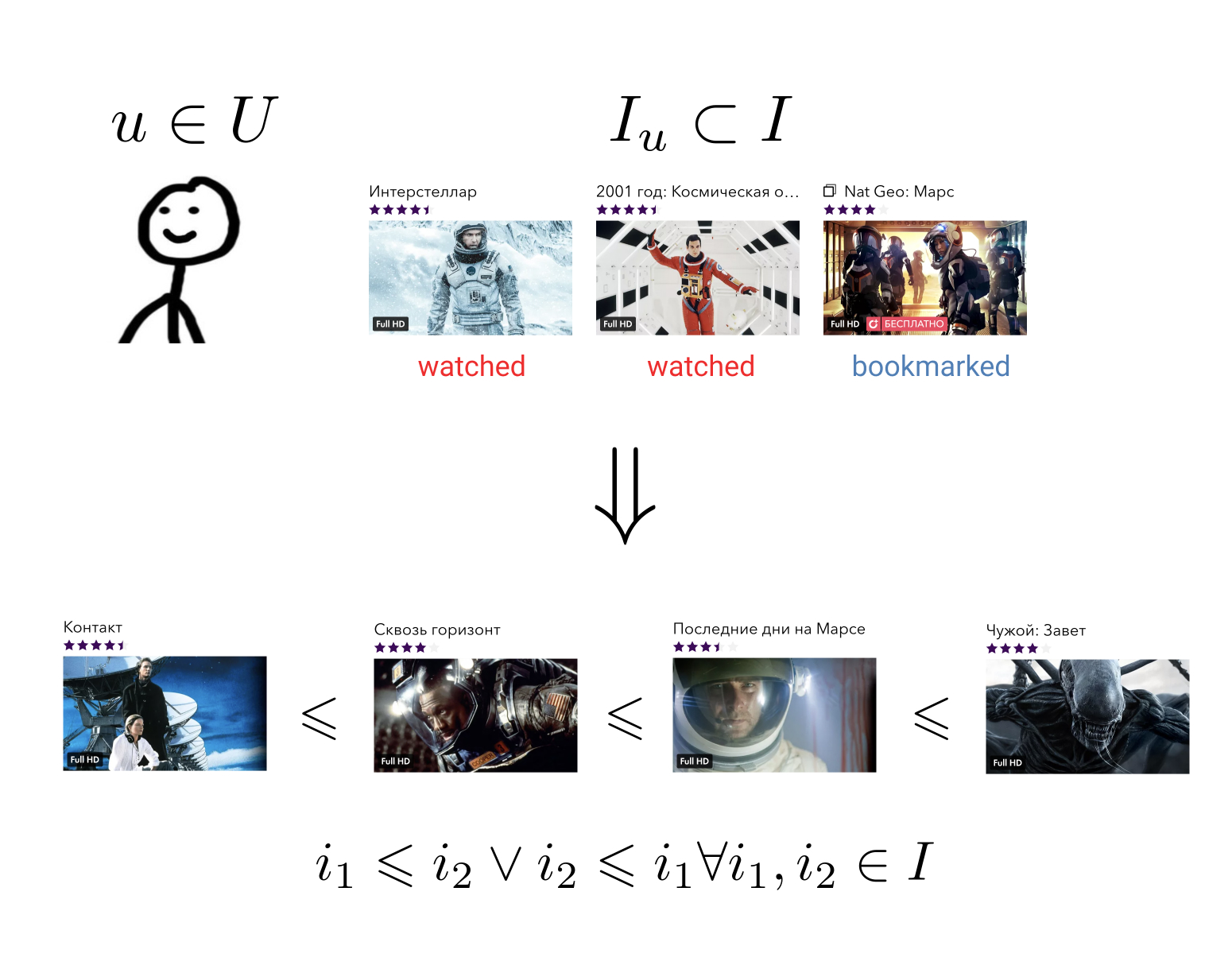
Esta tarea bastante general se puede reducir a una más simple: asignar elementos a un conjunto en el que ya se ha definido una relación de orden. Por ejemplo, en un conjunto de números reales. En este caso, es necesario que cada usuario y cada elemento puedan predecir un cierto valor: cuánto prefiere este elemento este usuario.

Al tener una relación de orden en nuestros elementos, podemos resolver muchos problemas comerciales, por ejemplo, elegir entre todos los elementos N los más relevantes para el usuario u ordenar los resultados de búsqueda de acuerdo con sus preferencias.
Idealmente, necesitamos una familia completa de relaciones de orden sensibles al contexto. Si el usuario ha ingresado en la colección "Fighters", lo más probable es que prefiera la película "Destroyer" a la película "Oscar", pero en la colección "Films with Sylvester Stallone" la preferencia puede ser todo lo contrario. Se pueden dar ejemplos similares para el día de la semana, la hora del día o el dispositivo desde el cual el usuario ingresó al servicio.

Tradicionalmente, todos los métodos para construir recomendaciones personales se dividen en tres grandes grupos: filtrado colaborativo (CF), modelos de contenido (modelos de contenido, CM) y modelos híbridos que combinan los dos primeros enfoques.
Los métodos de filtrado colaborativo utilizan información sobre las interacciones de todos los usuarios y todos los elementos. Dicha información, como regla, se presenta en forma de una matriz dispersa, donde las filas corresponden a los usuarios, las columnas a los elementos, y el usuario y el elemento contienen el valor que caracteriza la interacción entre ellos, o una brecha si esta interacción no lo era. La tarea de construir una relación de orden aquí se reduce a la tarea de completar los elementos de la matriz que faltan.
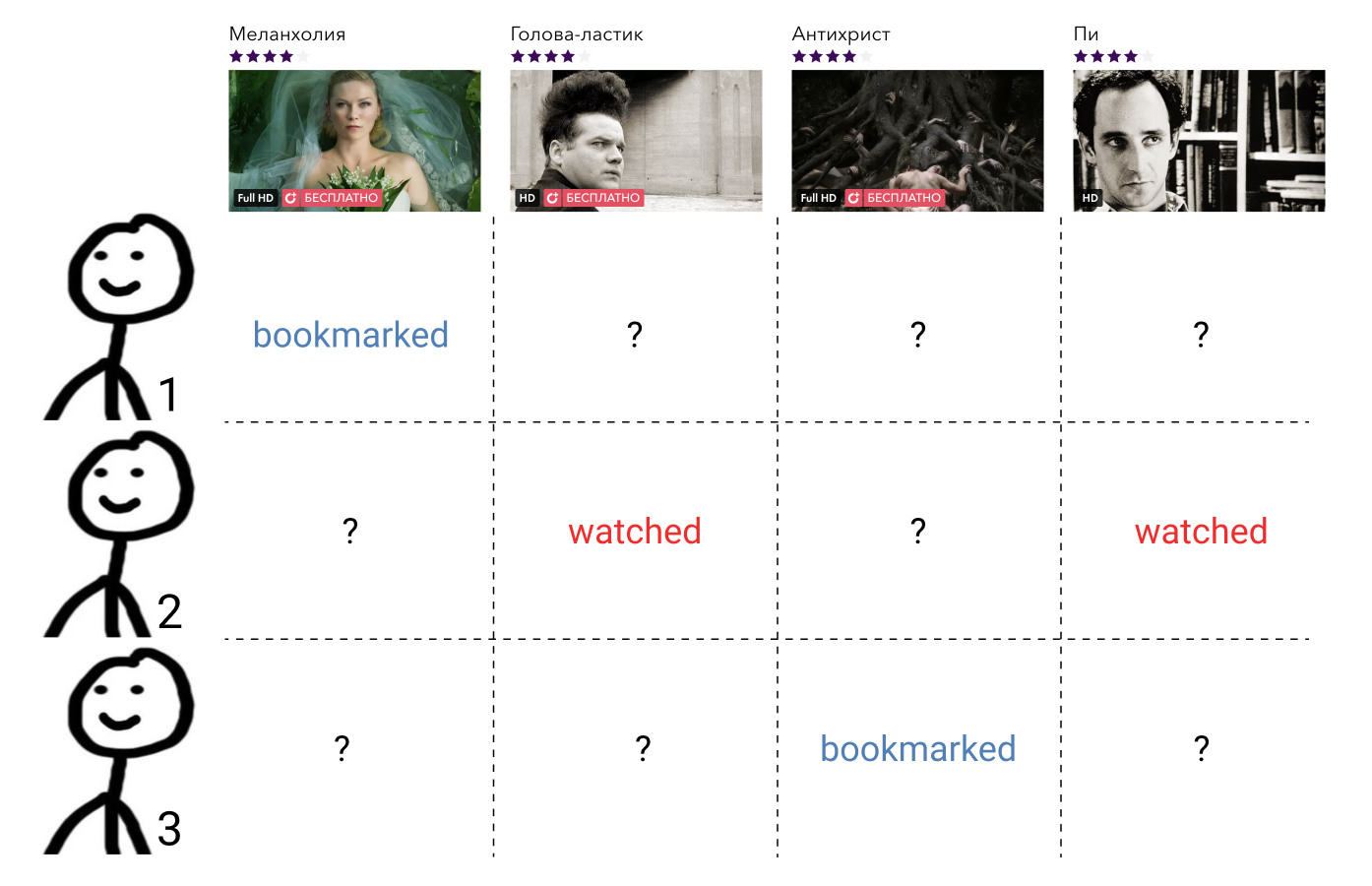
Estos métodos, por regla general, son fáciles de entender e implementar, rápidos, pero no muestran el mejor resultado.
Modelos de contenido: métodos de aprendizaje automático arbitrarios para resolver problemas de clasificación o regresión, parametrizados por un determinado conjunto de parámetros . En la entrada, aceptan los atributos del usuario y los atributos del elemento, y la salida es el grado de relevancia del elemento dado para este usuario. Dichos modelos no se enseñan sobre las interacciones de todos los usuarios y todos los elementos, como los métodos de filtrado colaborativo, sino solo en los precedentes individuales.

Tales modelos, como regla, son mucho más precisos que los métodos de filtrado colaborativo, pero son mucho más lentos en velocidad. Imagine que tenemos una función de alguna forma general que acepta signos de usuarios y elementos como entrada, entonces debe llamarse para cada par . En el caso de mil usuarios y diez mil elementos, esto es un millón de llamadas.
Los modelos híbridos combinan las fortalezas de ambos enfoques, ofreciendo recomendaciones de calidad en un tiempo razonable.
El enfoque híbrido más popular hoy en día es una arquitectura de dos niveles, donde el modelo de filtrado colaborativo selecciona un pequeño número (100 - 1000) de candidatos de todos los elementos posibles, que luego se clasifican por un modelo de contenido mucho más potente. A veces puede haber varias etapas de selección de candidatos y se utiliza un modelo cada vez más complejo en cada nuevo nivel.

Tal arquitectura tiene muchas ventajas:
- Las partes colaborativas y de contenido no están interconectadas y se pueden entrenar por separado con diferentes frecuencias;
- La calidad siempre es mejor que la de un modelo colaborativo por separado;
- La velocidad es mucho más alta que la del modelo de contenido por separado;
- "Gratis" obtenemos vectores de un modelo colaborativo, que luego puede usarse para resolver problemas relacionados.
Si hablamos de tecnologías específicas, entonces hay muchas combinaciones posibles.
Como parte de colaboración, puede tomar suscripciones de usuarios, contenido popular, contenido popular entre los amigos del usuario, puede aplicar factorización de matriz o tensor, entrenar DSSM o cualquier otro método con predicción bastante rápida.
Como modelo de contenido, cualquier enfoque puede usarse en general, desde la regresión lineal hasta las cuadrículas profundas.
En Okko, actualmente nos estamos centrando en una combinación de factorización matricial con pérdida de WARP y aumento de gradiente sobre los árboles, que ahora analizaré en detalle.
Etapa uno: selección de candidatos
Creo que no miento si digo que los algoritmos de factorización matricial son, con mucho, los métodos más populares de filtrado colaborativo. La esencia del método está clara en el nombre: estamos tratando de presentar la matriz de interacciones del usuario ya mencionada con el contenido del producto de dos matrices de rango inferior, una de las cuales será una "matriz de usuario" y la otra una "matriz de elementos". Con esta descomposición, podemos restaurar la matriz original junto con todos los valores faltantes.

En este caso, por supuesto, somos libres de elegir un criterio para la similitud de las matrices disponibles y restauradas. El criterio más simple es la desviación estándar.
Dejar - fila de matriz de usuario correspondiente al usuario y - columna de la matriz de elementos correspondiente al elemento . Luego, al multiplicar matrices, su producto significará la magnitud de la interacción prevista entre el usuario dado y el elemento. Ahora calculando la desviación estándar entre esta cantidad y el valor conocido a priori de la interacción para todos los pares de usuarios y elementos que interactúan , obtenemos una función de pérdida que se puede minimizar.
Como regla general, todavía se le agrega regularización.
Tal problema no es convexo y complejo NP. Sin embargo, es fácil notar que al arreglar una de las matrices, el problema se convierte en una regresión lineal con respecto a la segunda matriz, lo que significa que podemos buscar una solución de forma iterativa, congelando alternativamente la matriz del usuario o la matriz de elementos. Este enfoque se llama Alternating Least Squares (ALS).

La principal ventaja de ALS es la velocidad y la capacidad de paralelizar fácilmente. Por esto, es muy querido en Yandex.Zen y Vkontakte, donde los usuarios y los elementos suman decenas de millones.
Sin embargo, si estamos hablando de la cantidad de datos que cabe en una máquina, ALS no resiste las críticas. Su principal problema es que optimiza la función de pérdida incorrecta. Recuerde la formulación de la tarea de construir un sistema de recomendación. Queremos obtener la relación de orden en el conjunto y, en su lugar, optimizar la desviación estándar.
Es fácil dar un ejemplo de una matriz para la cual la desviación estándar será mínima, pero el orden de los elementos se destruye irremediablemente.
Veamos qué podemos hacer al respecto. En la cabeza del usuario, todos los elementos con los que interactuó están ordenados en algún orden. Por ejemplo, él sabe con certeza que Interstellar es mejor que Gravity, Gravity y Alien son películas igualmente buenas, y todas son un poco peores que Terminator. Al mismo tiempo, también experimenta una cierta actitud hacia las películas que el usuario aún no ha visto, y lo mismo para todos. Puede creer que tales películas son a priori peores que las películas que vio. O puede considerar que, por ejemplo, Prometeo es una mala película, y cualquier película que aún no haya visto será mejor que él.
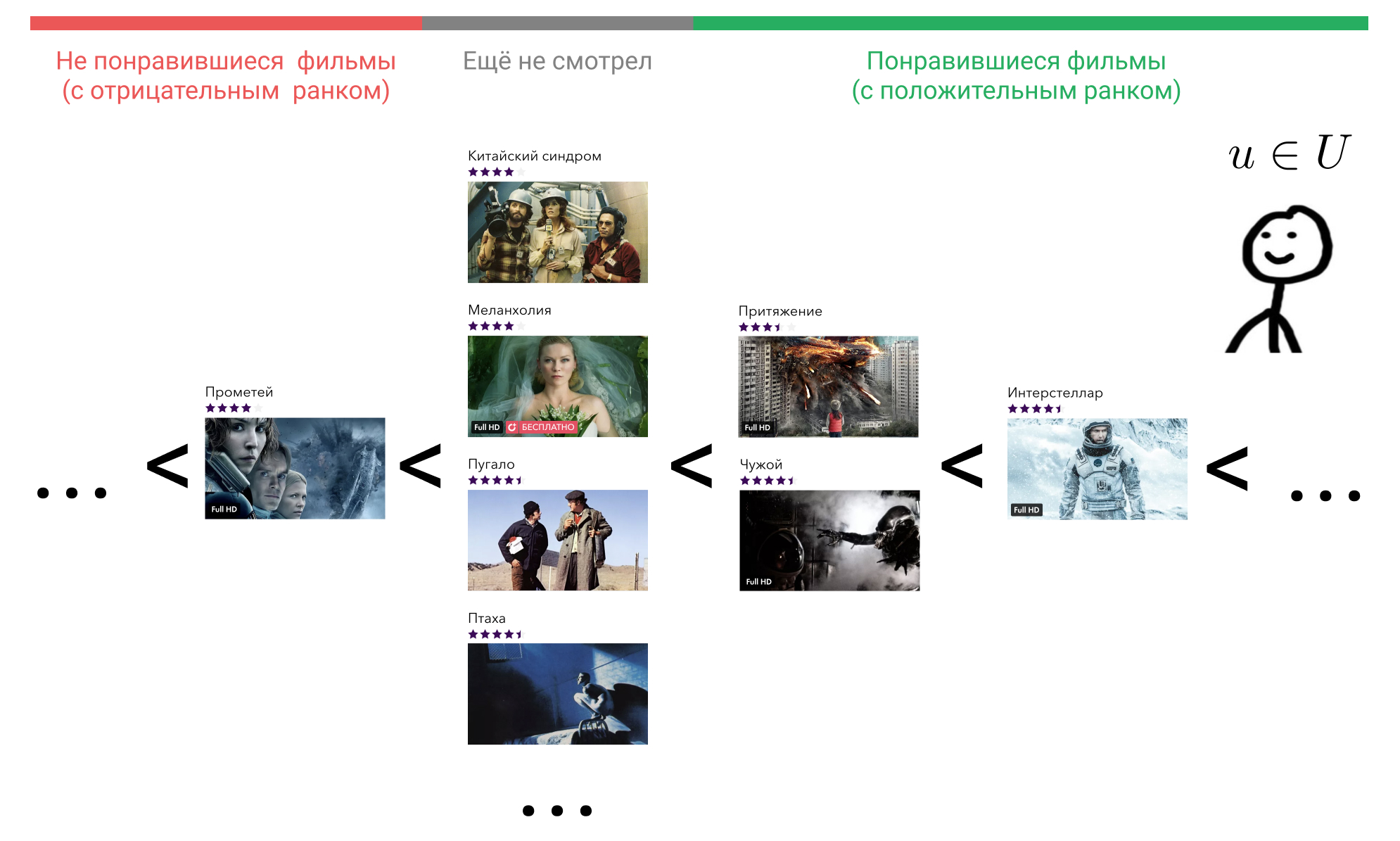
Imagine que, de acuerdo con algunos signos de comportamiento del usuario en el servicio, podemos restaurar este orden al mostrar el elemento con el que interactuó, en un entero utilizando la función . Muchas de las películas con las que el usuario interactuado, denotar como . Estamos de acuerdo que si el usuario no ha interactuado con la película eso es . Por lo tanto, si el usuario considera que la película es mala, entonces y si es bueno, entonces .

Ahora podemos ingresar al rango .
aquí denota la función del indicador y es igual a la unidad si verdadero y cero de lo contrario.
Paremos por un minuto y pensemos qué significa tal rango.
Arreglamos al usuario , este es un usuario específico, en cuál, no estamos interesados. En consecuencia, su vector será arreglado
Tome ahora cualquier película que haya visto, por ejemplo, interestelar. En la fórmula, esto . A continuación, encontramos una película que el usuario considera peor que Interstellar. Podemos elegir entre "Atracción", "Extraterrestre", "Prometeo" o cualquier película que aún no haya visto.

Tome la "atracción". En la fórmula, esto . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
donde — .
, , , .
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
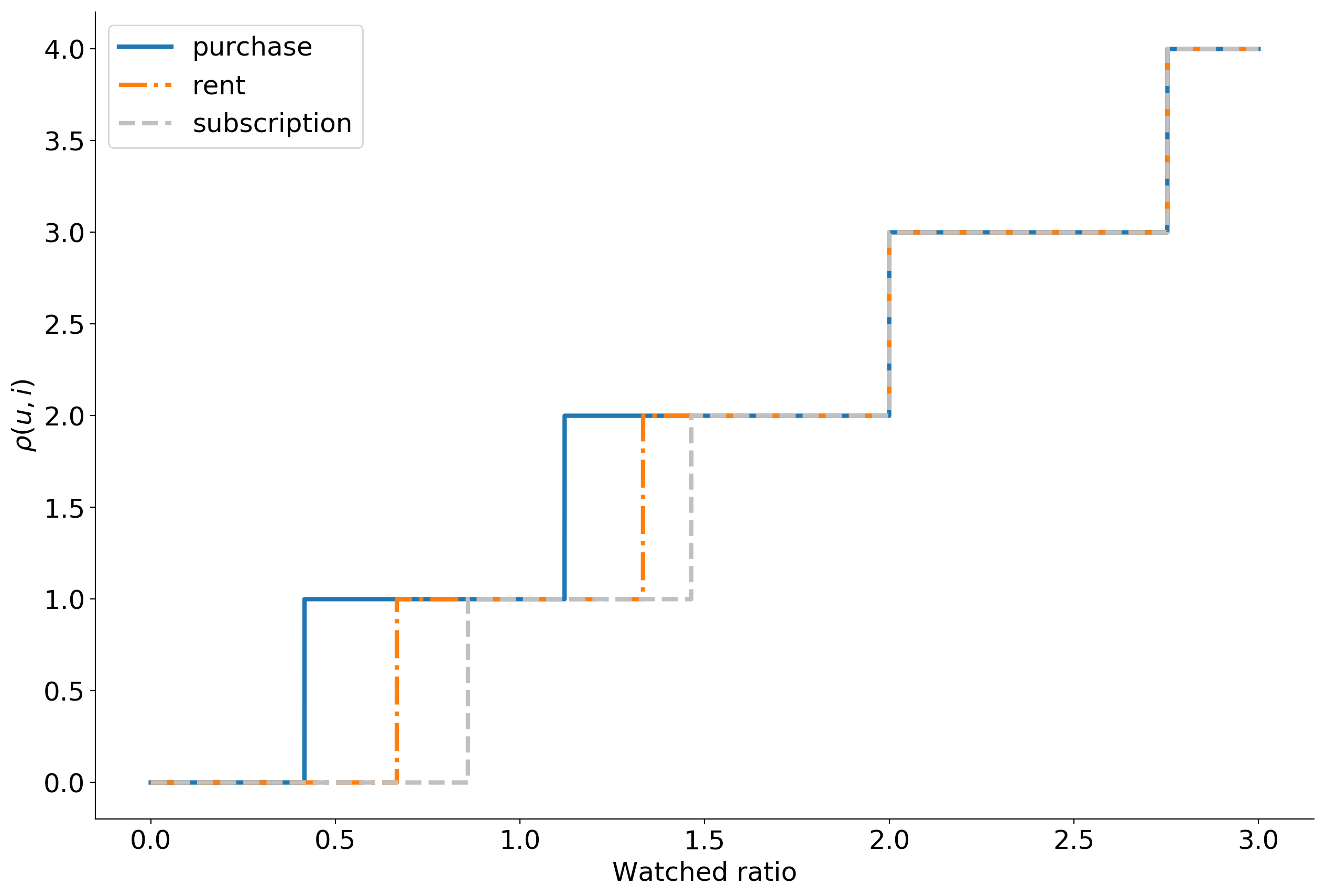
, , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
Estos problemas son evitados por los modelos de contenido. Son potentes, expresivos y puedes colocar cualquier señal en ellos, pero son extremadamente lentos. La solución es ejecutar el modelo de contenido no en todos los elementos, sino en los candidatos obtenidos de la descomposición de la matriz. Puede haber tantos candidatos como logre procesar, pero preferiblemente al menos el doble de lo que muestra a los usuarios. En nuestro caso, para las 100 películas recomendadas, la mejor solución era usar 400 candidatos.

Los atributos que enviamos al modelo de contenido se pueden dividir en tres grupos: atributos de usuario, atributos de elementos y signos de interacción. En total, se obtienen unos 50 signos.
Como signos de usuarios, utilizamos estadísticas agregadas de su comportamiento en el servicio, por ejemplo:
- Porcentaje de vistas de suscripción
- distribución de dispositivos desde los cuales el usuario inicia sesión en la aplicación,
- tiempo de vida en el servicio,
- etc.
Para las películas, utilizamos casi toda la metainformación disponible: género, año de lanzamiento, país, actor, director, límite de edad, etc. Las métricas comerciales agregadas también ayudan: porcentaje de visitas a la tarjeta, número de visitas, adiciones a favoritos, distribución mediante métodos de visualización, dispositivos, etc.
Los signos de interacción incluyen la velocidad desde la etapa de selección de candidatos y estadísticas agregadas para todas las interacciones anteriores de usuarios y películas con la participación de los mismos actores, directores y guionistas de la película en cuestión.
La pregunta más común que surge cuando se trata de clasificar candidatos con un modelo de segundo nivel es cómo entrenar este modelo. Solo en el caso de la factorización matricial, necesitábamos dos conjuntos, separados por tiempo: entrenamiento y prueba. En el caso de un sistema de dos etapas, necesitaremos tres de ellas: dos de capacitación y una de prueba.
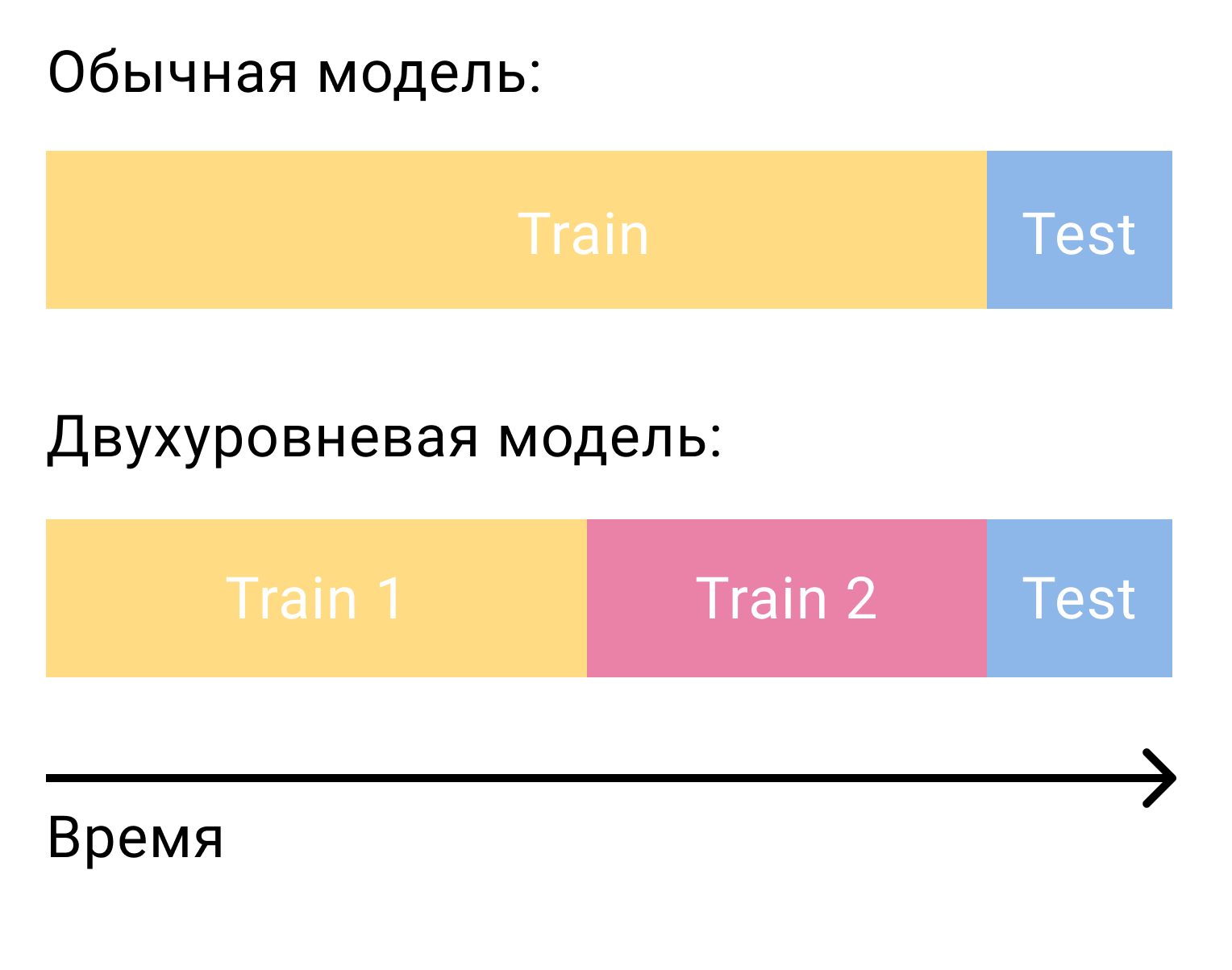
En el primer conjunto de entrenamiento, entrenaremos el modelo de primer nivel y crearemos candidatos. De los candidatos es importante excluir aquellos elementos con los que el usuario interactuó en este conjunto. Luego veremos con qué candidatos interactuó el usuario en el segundo conjunto de capacitación. Los llamamos positivos y los candidatos restantes negativos. Este será nuestro conjunto de capacitación para el modelo de contenido.
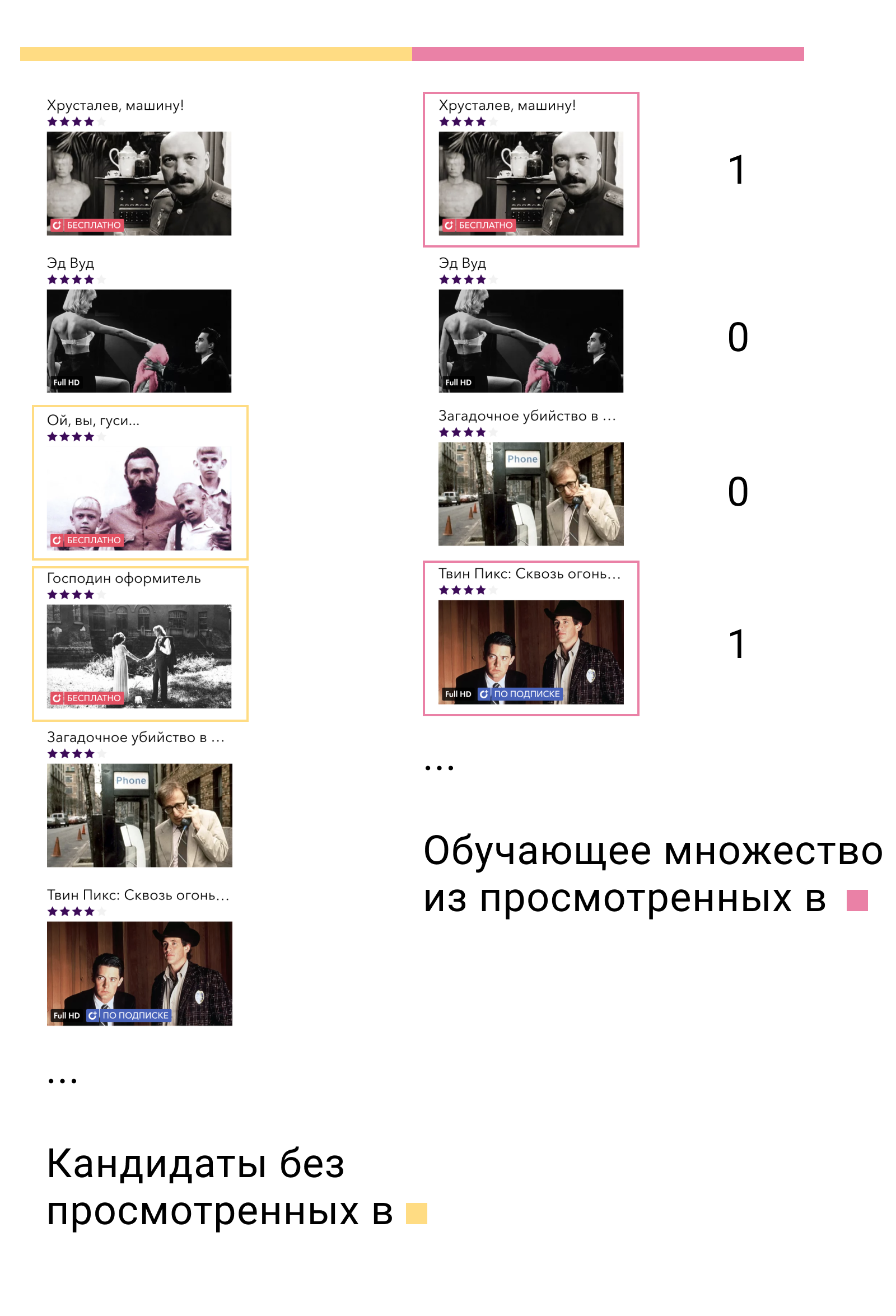
Por que funciona En primer lugar, entrenamos el modelo exactamente en los datos en los que se utilizará: la salida del modelo de primer nivel. En segundo lugar, entre todos los posibles ejemplos negativos, tomamos los más complejos, aquellos que el modelo de primer nivel llama relevantes para el usuario, pero no lo son.
Que sigue La solución más simple y obvia es resolver el problema de clasificación binaria y luego ordenar los elementos en orden descendente de probabilidad para que sea un ejemplo positivo. Pero podemos recordar nuevamente el enunciado del problema de la construcción de un sistema de recomendación, entender que la clasificación binaria no es el problema que estamos resolviendo y volver al problema de clasificación.
En XGBoost y LightGBM, la función de pérdida primaria para clasificar tareas es LambdaMART. Si no entra en detalles, la intuición detrás de esto es bastante simple. Si - salida del modelo, por ejemplo , entonces la probabilidad de que el elemento tendrá un rango más alto que el elemento será igual
La función de pérdida se puede escribir de la siguiente manera.
Aquí está la verdadera probabilidad de clasificación. Lo definiremos como 1 si , 0 si y 0.5 en el caso .
Un modelo de dos niveles proporciona un aumento del 50% en las métricas en comparación con un modelo de un solo nivel. La función de pérdida de clasificación agrega otro 10%.
Bonus: películas relacionadas
Recuerde, en las ventajas de nuestro enfoque, ¿mencioné los vectores "libres" de la factorización matricial que se pueden usar para resolver problemas relacionados? Entonces, una de estas tareas, la búsqueda de películas similares, decidimos.
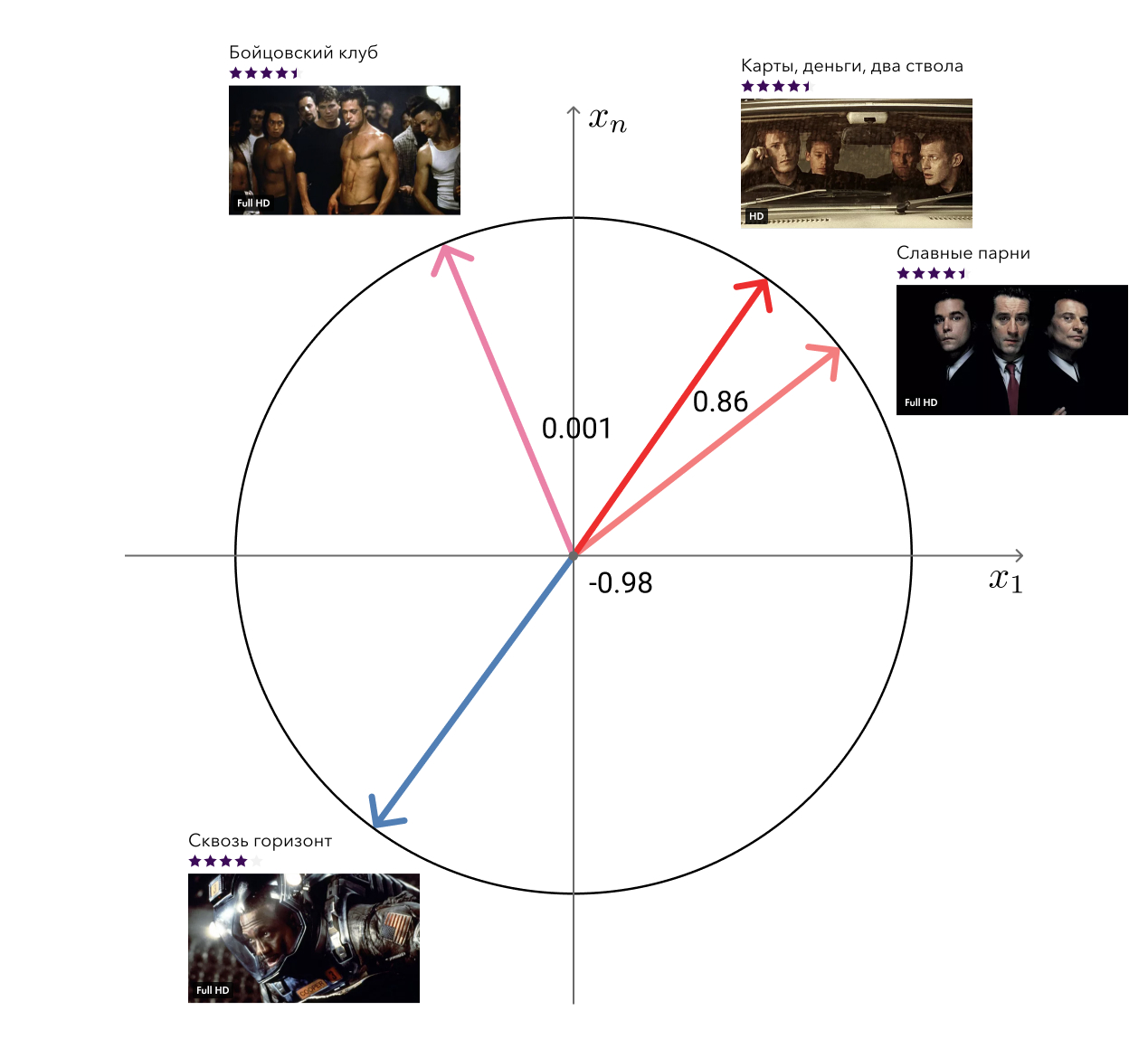
La solución a la desgracia es simple: para cada película, tomamos su vector y buscamos los más cercanos en la distancia del coseno. Se ve bastante adecuado a la vista. El siguiente nivel es agregar metainformación y usar algoritmos gráficos.

Implementación técnica
Además de la parte algorítmica, quiero hablar un poco sobre la implementación. Rekko consta de tres componentes: lynch, rekko-task y rekko-service.
Lynch se ejecuta en una máquina potente, se despierta periódicamente, prepara datos para el microservicio y los coloca en S3.
Las tareas de Rekko y los microservicios de servicio de rekko se encuentran en el entorno del producto Okko, junto con todos los demás microservicios y bases de datos. El primero de ellos monitorea constantemente los cambios en S3, si los hay, los descarga y los coloca en las bases de los supermercados. El segundo microservicio utiliza estos resultados calculados para responder en tiempo real a las solicitudes de los usuarios y calcular sus recomendaciones.

Los microservicios se escriben en Python usando falcon, gunicorn y gevent y no representan nada interesante excepto la lógica de negocios. Al igual que todos los demás microservicios del entorno del producto Okko, el equilibrador los cierra.
Lynch es mucho más interesante.
¿Qué se debe hacer para calcular la siguiente porción de recomendaciones para los usuarios? Al menos:
- Descargue nuevos datos que han aparecido desde el último recuento;
- Procesarlos;
- Factorizar la matriz del tren;
- Construir candidatos
- Reorganizar candidatos;
- Aplicar reglas comerciales
- Descargar.
Parece que no suena aterrador, puedes poner cada parte en una función separada y simplemente llamarlas por turno:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
Bueno, todo hizo un gran trabajo, ¿estamos en desacuerdo? En realidad no Pero, ¿qué pasa si toda la hoja cae en algún lugar? Bueno, por ejemplo, debido a la falta de memoria. Tendremos que reiniciar todo nuevamente, incluso si ya hemos pasado un par de horas entrenando al modelo y formando candidatos.
Bueno, entonces guardemos todos los resultados intermedios en archivos, y después de la caída, verifiquemos cuáles ya existen, restaure el estado y comience los cálculos desde el momento correcto. De hecho, esta idea es incluso peor que la anterior. Un programa puede ser interrumpido en medio de la escritura en un archivo, y aunque existe, estará en un estado incorrecto. En el mejor de los casos, todo el cálculo caerá; en el peor, terminará con el resultado incorrecto.
Ok, vamos a escribir en el archivo atómico. Y sacamos cada función en una entidad separada e indicamos las dependencias entre ellas. El resultado es una cadena de cálculos, cada uno de los cuales se puede realizar o no.

Ya no está mal. Pero en realidad, todos los cálculos necesarios difícilmente serán descritos por una lista. El aprendizaje de la factorización matricial requerirá no solo datos de transacciones, sino también calificaciones de los usuarios, la creación de candidatos requerirá una lista de películas recordadas para excluirlas, el cálculo de películas similares requerirá una factorización matricial capacitada y metainformación del catálogo, y así sucesivamente. Nuestras tareas ya no se crean en una lista simplemente conectada, sino en un gráfico dirigido sin ciclos (Gráfico Acíclico Dirigido, DAG).

DAG es una organización informática extremadamente popular. Hay dos marcos principales para construir un DAG: Airflow y Luigi . En Okko nos decidimos por lo último. Luigi se desarrolla en Spotify, se está desarrollando activamente, está completamente escrito en python, es fácilmente extensible y le permite organizar los cálculos de manera muy flexible.
Una tarea en Luigi está definida por una clase que hereda de luigi.Task e implementa tres métodos requeridos: requires , output y run . Así es como se ve una tarea típica:
Luigi se asegurará de que las tareas se completen en el orden correcto sin exceder el consumo de recursos disponibles. Si las tareas se pueden realizar en paralelo, las ejecutará en paralelo, maximizando la utilización de la CPU y minimizando el tiempo de ejecución general. Si alguna tarea falla, la reiniciará varias veces y, en caso de falla, nos informará. En este caso, se realizarán todas las tareas que se pueden realizar. Esto significa, por ejemplo, que un error en la tarea de clasificar a los candidatos no impide contar y subir una lista de películas similares.
Actualmente Lynch consta de 47 tareas únicas, produciendo alrededor de 100 de sus copias. Algunos de ellos están ocupados con el trabajo directo, algunos cuentan las métricas y las envían a nuestra herramienta Splunk BI. Lynch también nos envía periódicamente estadísticas e informes básicos sobre su trabajo por telegrama. También escribe sobre errores, pero en PM.
Monitoreo, división y resultados.

La primera regla de Data Science: no le cuentes a nadie sobre los salarios en Data Science. La segunda regla de la ciencia de datos: lo que no se puede medir no se puede mejorar.
Intentamos hacer un seguimiento de todo. En primer lugar, esto, por supuesto, clasifica las métricas en datos históricos. Ayudan incluso en la etapa de investigación a elegir el mejor modelo entre varios y elegir hiperparámetros para él.
Para los modelos que trabajan en producción, también consideramos las métricas, pero ya día a día. Dichas métricas son bastante volátiles, pero pueden decirlo si el modelo se degrada repentinamente por alguna razón. Cuando se lanza un nuevo modelo en el producto, puede dejarlo inactivo durante una semana y asegurarse de que las métricas no cedan. Después de eso, puede habilitarlo para algunos usuarios, ejecutar la prueba A / B y monitorear las métricas comerciales.

Además, consideramos la distribución de recomendaciones por género, país, año, tipo, etc. Esto nos permite comprender la naturaleza actual de las preferencias del usuario, compararla con datos de visualización reales y detectar errores en las reglas comerciales.

También es importante realizar un seguimiento de las distribuciones de todos los rasgos utilizados. Un cambio brusco en ellos puede ser causado por un error en la fuente de datos y conducir a resultados impredecibles.
Pero, por supuesto, lo más importante que requiere mucha atención son las métricas comerciales. Como parte del sistema de recomendaciones, las principales métricas comerciales para nosotros son:
- Ingresos de modelos de consumo transaccional y de suscripción (ingresos de TVOD / SVOD);
- Ingresos promedio por visitante (ingresos promedio por visitante, ARPV);
- El cheque promedio (precio promedio por compra, APPP);
- Promedio de compras por usuario (APPU);
- Conversión a compra (CR a compra);
- Conversión para ver por suscripción (CR para mirar);
- Conversión durante el período de prueba (CR a prueba).
Al mismo tiempo, observamos por separado las métricas de las secciones "Recomendaciones" y "Similares" y las métricas de todo el servicio en su conjunto para tener en cuenta el efecto de redistribución y considerar la situación desde diferentes ángulos.
Esto puede parecer un tablero de instrumentos que compara varios modelos:

Como dije al principio, comparamos no solo los modelos entre sí, sino también un grupo de usuarios con recomendaciones contra un grupo de usuarios sin recomendaciones. Esto nos permite evaluar el efecto neto de la implementación de Rekko y comprender dónde estamos en este momento y qué margen de mejora aún queda. Según esta prueba A / B, actualmente tenemos:
- ARPV + 3.5%
- ARPV con margen + 5%
- APPU + 4.3%
- CR a prueba + 2.6%
- CR para ver + 2.5%
- APPP -1%
Las películas en un cine en línea se pueden dividir en dos grupos: elementos nuevos y contenido antiguo. Ya sabemos cómo vender buenas noticias. El objetivo principal de las recomendaciones personales es obtener contenido antiguo relevante para los usuarios del catálogo. Esto lleva a un aumento en el número de compras y subsidencia del cheque promedio, ya que dicho contenido es naturalmente más barato. Pero dicho contenido también tiene un alto margen, lo que compensa el hundimiento del cheque y da un aumento en los ingresos.
El contenido de suscripción más relevante ha llevado a una mayor conversión durante el período de prueba y a la visualización por suscripción.
Rekko Challenge
Del 18 de febrero al 18 de abril de 2019, junto con la plataforma Boosters, realizamos el Rekko Challenge, donde invitamos a los participantes a crear un sistema de recomendación basado en datos de productos anónimos.

Se espera que los participantes que construyeron un sistema de dos niveles similar al nuestro estén en la cima. Los ganadores que tomaron el primer y tercer lugar lograron agregar al conjunto RNN. Y el participante del octavo lugar logró escalar usando solo modelos de filtrado colaborativos.
Evgeni Smirnov, quien obtuvo el segundo lugar en la competencia, escribió un artículo en el que habló sobre su decisión.
Por el momento, la competencia está disponible en forma de sandbox, por lo que todos los que estén interesados en los sistemas de recomendación pueden probarlo y adquirir experiencia útil.
Conclusión
Con este artículo, quería mostrarle que los sistemas de recomendación en producción no son nada difíciles, sino divertidos y rentables. Lo principal es pensar en los objetivos, no en los medios para alcanzarlos y medir constantemente todo.
En futuros artículos, le diremos aún más sobre la cocina interior de Okko, así que no olvide suscribirse y darle me gusta.