Hola colegas
Quizás el título de la publicación de hoy se vería mejor con un signo de interrogación, es difícil de decir. En cualquier caso, hoy queremos ofrecerle un breve recorrido que le presentará la biblioteca
Dask , diseñada para paralelizar tareas en Python. Esperamos volver a este tema más a fondo en el futuro.
 Foto tomada en
Foto tomada enDask es, sin exagerar, la herramienta de procesamiento de datos más revolucionaria que he encontrado. Si le gustan
Pandas y Numpy , pero a veces no puede hacer frente a los datos que no caben en la RAM, entonces Dask es exactamente lo que necesita. Dask admite el marco de datos de Pandas y las estructuras de datos de Numpy (matrices). Dask puede ejecutarse en la computadora local o escalarse, y luego ejecutarse en el clúster. En esencia, escribe el código solo una vez y luego elige si usarlo en la máquina local o implementarlo en un grupo de muchos nodos usando la sintaxis Python más común para todo esto. La característica en sí es excelente, pero decidí escribir este artículo solo para enfatizar: cada Data Scientist (al menos usando Python) debería usar Dask. Desde mi punto de vista, la magia de Dask es que al minimizar el código, puede paralelizarlo utilizando la potencia informática que ya está disponible, por ejemplo, en mi computadora portátil. Con el procesamiento paralelo de datos, el programa se ejecuta más rápido, debe esperar menos y, en consecuencia, queda más tiempo para el análisis. En particular, en este artículo hablaremos sobre el objeto
dask.delayed y cómo encaja en el flujo de tareas de ciencia de datos.
Introduciendo Dask
Como introducción a Dask, te daré un par de ejemplos solo para que te hagas una idea de su sintaxis completamente discreta y natural. La conclusión más importante que quiero sugerir en este caso es que el conocimiento que ya tiene será suficiente para trabajar; No tiene que aprender una nueva herramienta de Big Data como Hadoop o Spark.
Dask ofrece 3 colecciones paralelas en las que puede almacenar datos que exceden el tamaño de la RAM, a saber: marcos de datos, bolsas y matrices. En cada uno de estos tipos de colecciones, puede almacenar datos al segmentarlos entre la RAM y el disco duro, así como distribuir datos a través de múltiples nodos en un clúster.
Un Dask DataFrame consta de marcos de datos triturados, como los de Pandas, por lo que le permite utilizar un subconjunto de las características de la sintaxis de consulta de Pandas. A continuación se muestra un código de ejemplo que descarga todos los archivos csv para 2018, analiza un campo con una marca de tiempo e inicia una solicitud de Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Ejemplo de marco de datos de DaskEn Dask Bag, puede almacenar y procesar colecciones de objetos pitónicos que no caben en la memoria. Dask Bag es ideal para procesar registros y colecciones de documentos en formato json. En este ejemplo de código, todos los archivos json para 2018 se cargan en la estructura de datos de Dask Bag, cada registro json se analiza y los datos del usuario se filtran utilizando la función lambda:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
Ejemplo de bolsa DaskLa estructura de datos de Dask Arrays admite cortes de estilo Numpy. En el siguiente ejemplo, un conjunto de datos HDF5 se divide en bloques de dimensión (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Ejemplo de matriz de DaskProcesamiento Paralelo en Dask
Otro título igualmente preciso para esta sección sería "Muerte de un ciclo secuencial". De vez en cuando encuentro un patrón común: iterar sobre la lista de elementos y luego ejecutar el método Python con cada elemento, pero con diferentes argumentos de entrada. Los escenarios comunes de procesamiento de datos incluyen el cálculo de agregados de características para cada cliente o la agregación de eventos del registro para cada estudiante. En lugar de aplicar una función a cada argumento en un bucle secuencial, el objeto Dask Delayed le permite procesar muchos elementos en paralelo. Cuando se trabaja con Dask Delayed, todas las llamadas a funciones se ponen en cola, se colocan en el gráfico de ejecución, después de lo cual se planea procesarlas.
Siempre fui un poco vago para escribir mi propio motor de subprocesos o usar asyncio, así que ni siquiera te mostraré ejemplos similares para comparar. ¡Con Dask, no puede cambiar ni la sintaxis ni el estilo de programación! Solo necesita anotar o ajustar el método, que se ejecutará en paralelo con
@dask.delayed y llamar al método computacional después de que se ejecute el código de bucle.
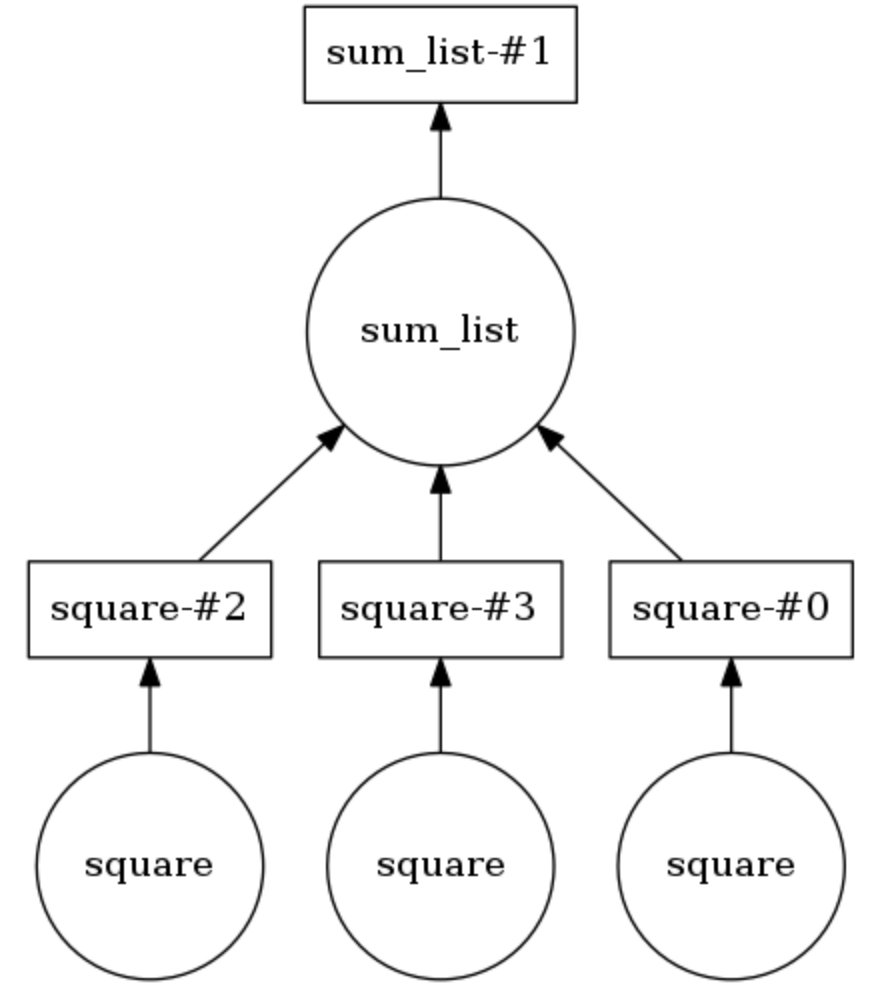
Ejemplo de gráfico de computación Dask
En el siguiente ejemplo, los dos métodos están anotados
@dask.delayed . Tres números se almacenan en una lista, deben cuadrarse y luego sumarse. Dask crea un gráfico computacional que proporciona una ejecución paralela del método de cuadratura, después de lo cual el resultado de esta operación se pasa al método
sum_list . El gráfico computacional se puede mostrar llamando
calling .visualize() .
Calling .compute() ejecuta el gráfico de cálculo. Como se desprende de la
conclusión , los elementos de la lista se procesan no en orden, sino en paralelo.
Se puede establecer el número de subprocesos (por ejemplo,
dask.set_options( pool=ThreadPool(10) ), y también se pueden intercambiar fácilmente para usar procesos en su computadora portátil o PC (por ejemplo,
dask.config.set( scheduler='processes' ) .
Entonces, demostré lo trivial que será agregar el procesamiento paralelo de tareas a un proyecto desde el campo de la Ciencia de Datos usando Dask. Poco antes de escribir este artículo, utilicé Dask para dividir los datos sobre las secuencias de clics de los usuarios (historial de visitas) en sesiones de 40 minutos, y luego agregué los atributos para cada usuario para la agrupación adicional. ¡Cuéntanos cómo usaste Dask!