QlikView y su hermano menor QlikSense son maravillosas herramientas de BI bastante populares en nuestro país y en el extranjero. Muy a menudo, estos sistemas guardan resultados "intermedios" de su trabajo (datos que visualizan sus "paneles") en los llamados "archivos QVD". A menudo, los archivos QVD se utilizan como almacenamiento principal en procesos ETL de varias etapas creados sobre la base de Qlik. Y luego algunos (por ejemplo, yo - trato con la ingeniería de datos en la empresa) tienen una pregunta: ¿es posible y cómo usar estos datos sin QlikView / QlikSense? U otro, y ¿qué hay allí y es correcto que se haya contado?
QVD es un formato de archivo optimizado para QlikView / QlikSense (la lectura de la escritura de información de estas aplicaciones en archivos de este formato es mucho más rápida que en archivos de cualquier otro formato). La estructura de este archivo no está documentada y está cubierta por una "penumbra de propiedad", prácticamente no hay aplicaciones que puedan funcionar con dichos archivos (leer y aún más escribir). En esta serie de artículos compartiré mi experiencia y el conocimiento práctico adquirido: sé cómo funciona QVD, puedo leerlo y escribirlo de manera directa y rápida.
¿Quién estará interesado en esta información? En primer lugar, aquellos que trabajan con QlikView / QlikSense, así como aquellos que (como yo) quisieran usar los datos almacenados en archivos QVD. Y, por supuesto, para todos los curiosos.
Todo lo escrito en esta serie se basa en mi experiencia personal, que, por supuesto, no es una "documentación" o una "garantía" (que sus archivos serán exactamente los mismos que describí. O que serán para siempre ) Tampoco puedo garantizar que haya resuelto todos los casos, seguramente habrá archivos que contendrán algo que no describí (aunque solo sea porque no encontré tales opciones). Sin embargo, debo tener en cuenta que la información se verifica en un gran conjunto (varios cientos) de archivos creados por diferentes personas de diferentes sistemas que utilizan diferentes versiones de QlikView / QlikSense.
Y un poco sobre cómo lo hice: comencé con uno simple: un pequeño ejemplo en línea guardado en QVD. Además, el análisis del archivo binario, los esfuerzos del cerebro, las pruebas y los errores. Mirando hacia el futuro (hablaré sobre esto con más detalle en la conclusión de la serie), logré leer y escribir archivos QVD de tamaño mediano (cientos de gigabytes) de manera bastante eficiente. El punto de partida de mi viaje al mundo QVD fue este GitHub , muchas gracias al autor (trató de contactarlo, no responde).
¿Cuál era mi objetivo (además de la curiosidad y el deseo de verificar la exactitud de los datos con los que trabaja QlikView / QlikSense), necesitaba leer el contenido del archivo QVD, es decir recrear una tabla relacional basada en ella. Por el contrario, cargue los datos de la tabla relacional en QVD para que QlikView pueda cargarlos correctamente.
Cómo veo esta serie de artículos
- introducción, estructura de archivos, metadatos (este artículo)
- almacenamiento de información de columna
- almacenamiento de información de línea, logros, planes
Estructura de archivo
El script QlikView / QlikSense crea el archivo QVD en el proceso de carga de datos en la memoria de la aplicación (el resultado del comando STORE) y corresponde a una tabla QlikView / QlikSense (relacional). Consta de dos partes
- textual (metadatos) y
- binario (columnas y filas)
Los metadatos se presentan como XML (se proporcionará un ejemplo a continuación), la parte binaria comienza inmediatamente después del texto y consta de dos bloques
- valores únicos de todas las columnas (tabla fuente)
- filas (tabla de origen) que hacen referencia a valores de columna únicos
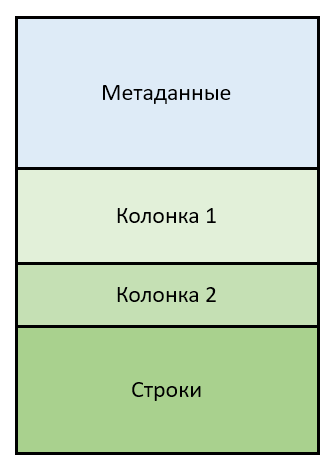
Por lo tanto, para una tabla de N columnas, el archivo contendrá bloques binarios N + 1. Todas las partes del archivo están "bien pegadas" y van una tras otra sin rellenos ni "vástagos".
El archivo QVD contiene muchos metadatos: "datos sobre datos". Es casi autosuficiente, juzga por ti mismo, aquí hay una breve lista de lo que está en los metadatos (los describiré con más detalle a continuación):
- versión del software que generó el archivo
- fecha y hora de creación del archivo
- QlikView / QlikSense file, el script que condujo a la creación del archivo
- código fuente del script que generó el archivo QVD
- nombre de la tabla
- información de columna (nombres, tipos, cantidades de valores únicos)
- recuento de filas
Los metadatos se almacenan en un archivo en forma de texto y se pueden ver en cualquier programa que pueda mostrar el archivo en forma de texto (bueno, casi cualquier ... en uno que no tenga miedo a los archivos grandes). Personalmente, miro la metainformación con más: es bastante conveniente.
En el resto de la presentación, usaré la tabla de prueba (uso la sintaxis QlikView, pero creo que será fácil de conjeturar):
SET NULLINTERPRET =<sym>; tab1: LOAD * INLINE [ ID, NAME 123.12,"Pete" 124,12/31/2018 -2,"Vasya" 1,"John" <sym>,"None" ];
Daré como ejemplo los metadatos de esta placa.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <QvdTableHeader> <QvBuildNo>7314</QvBuildNo> <CreatorDoc></CreatorDoc> <CreateUtcTime>2019-04-03 06:24:33</CreateUtcTime> <SourceCreateUtcTime></SourceCreateUtcTime> <SourceFileUtcTime></SourceFileUtcTime> <SourceFileSize>-1</SourceFileSize> <StaleUtcTime></StaleUtcTime> <TableName>tab1</TableName> <Fields> <QvdFieldHeader> <FieldName>ID</FieldName> <BitOffset>0</BitOffset> <BitWidth>3</BitWidth> <Bias>-2</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>4</NoOfSymbols> <Offset>0</Offset> <Length>40</Length> </QvdFieldHeader> <QvdFieldHeader> <FieldName>NAME</FieldName> <BitOffset>3</BitOffset> <BitWidth>5</BitWidth> <Bias>0</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>5</NoOfSymbols> <Offset>40</Offset> <Length>37</Length> </QvdFieldHeader> </Fields> <Compression></Compression> <RecordByteSize>1</RecordByteSize> <NoOfRecords>5</NoOfRecords> <Offset>77</Offset> <Length>5</Length> </QvdTableHeader>
Mi experiencia con QVD muestra que la estructura XML no cambia de un archivo a otro.
Comentaré los elementos de metadatos más importantes.
QvBuildNo
El número de compilación de la aplicación QlikView / QlikSense que generó el archivo QVD.
Creatordoc
Como regla, contiene el nombre del archivo QVW, cuyo script generó el archivo QVD. Este ejemplo está en blanco, posiblemente porque se usó la Edición Personal.
CreateUtcTime
Tiempo de creación del archivo QVD.
SourceCreateUtcTime, SourceFileUtcTime, SourceFileSize, StaleUtcTime
No vi los archivos en los que se rellenarían estos campos, para preguntarme: ¿quizás faltan algunas configuraciones?
Nombre de tabla
El nombre de la tabla en QlikView (consulte el ejemplo anterior).
Por cierto, las palabras "campo" y "columna" son sinónimos para mí, no se alarme si las uso a ambas (intentaré no hacerlo, pero aún así ...).
La información sobre cada campo se almacena en QVD acerca de
Nombre del campo
El nombre del campo (nuevamente en términos de QlikView, es decir, teniendo en cuenta "AS")
BitOffset, BitWidth, Bias
Por ahora, saltemos: esta es información para "decodificar cadenas", consideraremos en la tercera parte cuándo tratará con cadenas.
Tipo, nDec, UseThou, Fmt, Dec, Thou
Bien concebido (a juzgar por los nombres), pero absolutamente inútil desde el punto de vista de lograr la información de mi objetivo (para más detalles, vea la segunda parte, donde hablaremos sobre las columnas). ¿Por qué es inútil? - la etiqueta "Tipo" no se correlaciona con el tipo de datos almacenados en la parte binaria. Es imposible restaurar el tipo de columna (parece que podría ser más fácil, ¡hay una etiqueta Tipo!). En el 90% de los casos, el valor de esta etiqueta será la cadena DESCONOCIDA ...
En los metadatos sobre las columnas todavía hay tales datos (en los metadatos del ejemplo, aparentemente no se debe al pequeño tamaño)
<Comment></Comment> <Tags> <String>$numeric</String> <String>$integer</String> </Tags>
El comentario no necesita comentarios (por cierto, los archivos con los que trabajé están 100% vacíos ...).
Las etiquetas también son información inútil (desde el punto de vista de restaurar la estructura de la tabla). Pero a partir de él, puede adivinar aproximadamente qué tipo de información se almacena en la columna. Me referiré a escribir con más detalle en la segunda parte, cuando hablaré sobre columnas: esto es importante. Pero un poco más complicado de lo que me gustaría.
NoOfSymbols
El número de entradas en la parte binaria relacionadas con esta columna. Como vemos, en nuestro ejemplo es 5. Información que es muy importante para el descifrado.
Offset
El desplazamiento del bloque de datos de esta columna en bytes en relación con el comienzo de la parte binaria del archivo. También muy importante.
Longitud
La longitud del bloque de datos completo de esta columna en bytes. Tenga en cuenta que la representación binaria de un elemento de columna (celda de tabla) generalmente tiene una longitud variable (fila, por ejemplo), por lo que la longitud no se puede calcular, solo puede tomarla de esta etiqueta (sonrisa).
Compresión
Nunca completado (en los datos con los que trabajé). Quizás no estamos usando esta opción ...
RecordByteSize
El tamaño de la entrada de la fila en bytes. Todas las cadenas se representan en el bloque binario de cadenas como un índice de bits (más sobre esto en la tercera parte), un índice de bits consiste en filas de la misma longitud.
NoOfRecords
El número de filas (en el índice de bits y en la tabla de origen).
Offset
El desplazamiento del índice de bits (bloque con información de cadena) en bytes en relación con el comienzo de la parte binaria del archivo.
Longitud
La longitud del índice de bits en bytes.
En los metadatos sobre las cadenas todavía hay tales datos (nuevamente, un breve ejemplo no le permite ver todo, pero le permite comprender el complejo)
<Lineage> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>LinkTable: LOAD SOURCE_NAME & '_' & SOURCE_ID as SYSKEY, HID_PARTY;SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>STORE - \\xxx.ru\mfs\SPECIAL\Qlikview\QVData\LinkTable.qvd (qvd)</Discriminator> <Statement></Statement> </LineageInfo> </Lineage> <Comment></Comment>
No voy a entrar demasiado en el punto aquí, es bastante comprensible (los SELECT originales que generaron la tabla en QlikView), todavía no lo he descubierto todavía (a veces se duplican) ... (excepto uno - 100% sin comentarios (sonrisa)) .
Para resumir
- El archivo QVD es autónomo (es decir, se puede analizar de forma aislada de otros datos)
- El archivo QVD consta de partes de texto (metadatos) y binarias (columnas e índice de bits)
- los metadatos son XML con una semántica clara
Un lector curioso tiene derecho a preguntar aquí: "Hasta ahora no se ha escuchado nada nuevo, todo lo anterior se puede tomar y ver en el encabezado XML del archivo QVD ... Esto ya se ha escrito sobre esto muchas veces en Internet diferente, ¿cuál es la novedad?" Así es, la primera parte está dedicada casi por completo a los metadatos. Pero este no es el final.
A continuación, en la siguiente parte, examinaremos en detalle la estructura de la parte binaria del archivo QVD que contiene información sobre las columnas (valores únicos de todas las columnas de la tabla).