Como sabe, el código se lee con mucha más frecuencia de lo que se escribe. Para que al menos alguien que no sea el autor pueda leerlo, y hay guías de estilo. Para R, esto puede ser, por ejemplo, el manual de Hadley.
Una guía de estilo no es solo un acuerdo tácito entre desarrolladores: muchas de las reglas tienen un curioso trasfondo. Por qué la flecha
<- mejor que el signo igual
= , por qué a los veteranos de R no les gusta el guión bajo, cómo se relaciona la longitud de línea recomendada con la tarjeta perforada y mucho más, más.
Descargo de responsabilidad: Guías de estilo RA diferencia de Python, R no tiene un solo estándar. En consecuencia, no hay una guía única. Además de la
guía Hadley (o su versión extendida de
tidyverse ), hay otras, como
Google o
Bioconductor .
Sin embargo, la guía Hadley puede considerarse la más extendida (como la
verificación de RStudio
incorporada , por ejemplo), lo que se ve facilitado en gran medida por la popularidad de las bibliotecas creadas por el propio Hadley (dplyr, ggplot, tidyr y otras de la colección tidyverse).
1. Operador de asignación: <- vs =
Todas las guías disponibles recomiendan utilizar el operador no estándar
<- , pero no el signo igual
= , que es común para otros idiomas modernos. Ni siquiera se mencionan otros tres operadores (
<<- ,
-> ,
->> ) (como el que existía en versiones anteriores
:= ). Parecería, ¿por qué necesitamos esta flecha no estándar?
La historia nos revela las cartas: en R, la flecha vino de S, que a su vez la heredó de la APL. En APL, nos permitió distinguir la asignación de la igualdad. En R, el operador de igualdad es estándar, por lo que la diferencia es diferente. Si la flecha era inicialmente un operador de asignación, entonces el signo igual asignó valores
solo a parámetros
con nombre. En 2001, el signo igual se convirtió en el operador de asignación, pero nunca se convirtió en sinónimo de la flecha.
¿Qué nos permite considerar
= reemplazo completo de la flecha? En primer lugar,
= cómo funciona el operador de asignación solo en el nivel superior. Por ejemplo, dentro de la función, todo funcionará como antes:
mean(x = 1:5)
Aquí
= solo establece el parámetro de la función, mientras que
<- también asigna el valor a la variable x. Podemos lograr el mismo efecto colocando la operación de asignación entre paréntesis
(no, esto todavía no es Lisp) :
mean ((x = 1:5))
... o entre llaves:
mean ({x = 1:5})
Además, la flecha tiene prioridad sobre el signo igual:
x <- y <- 1
La última expresión falló porque es equivalente a
(x <- y) = 4 , y el analizador la interpreta como
`<-<-`(x, y = 4, value = 4)
En otras palabras, estamos tratando de realizar una operación incorrecta: primero asigne x a y luego intente asignar x e y a 4. La expresión se procesará sin errores solo si cambia la prioridad de las operaciones con paréntesis:
x <- (y = 4) .
2. Espaciado
La guía recomienda poner espacios entre operadores (excepto, por supuesto, corchetes,:, :: y :: :), así como antes del corchete de apertura. Obviamente, esto es parte de los estándares de codificación GNU. Sin embargo, esta cláusula está estrechamente relacionada con el uso de
<- como operador de asignación. Por ejemplo
x <-1
Que es esto X es menor que -1? O establecer x a 1?
Sin embargo, el espacio extra no es mejor que el que falta, por ejemplo:
x <- 0 ifelse(x <-1, T, F)
En el primer caso, no hay espacio entre
< y
- , lo que crea un operador de asignación.
3. Nombres de funciones y variables.
Las guías de estilo no están de acuerdo con la cuestión de los nombres: la guía Hadley recomienda guiones bajos para todos los nombres; Guía de Google: separación por puntos para variables y estilo camel con la primera minúscula para funciones; Bioconductor recomienda lowerCamel para funciones y variables. No hay unidad en la comunidad R en este tema, y se pueden encontrar todos los estilos posibles:
lowerCamel period.separation lower_case_with_underscores allowercase UpperCamel
No hay un estilo uniforme incluso para los nombres base R (por ejemplo, los nombres de fila y row.names son funciones diferentes). Si no tiene en cuenta el permitido ilegible (solo a los usuarios de Matlab les puede encantar), hay tres estilos más populares: lowerCamel, minúsculas con _ y minúsculas con separación de puntos.
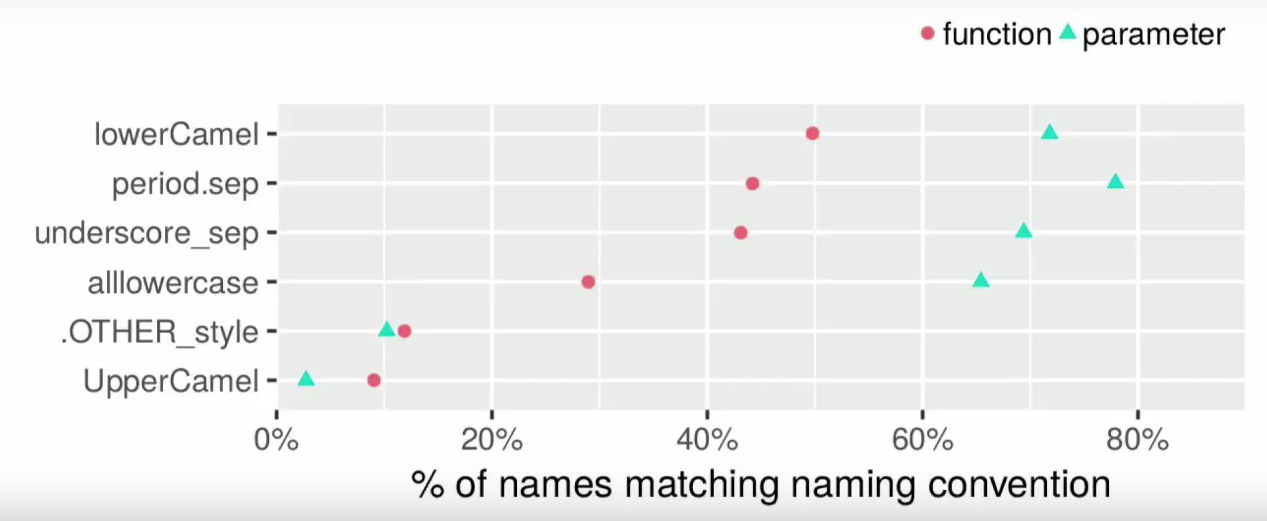
La popularidad de diferentes estilos para los nombres y parámetros de funciones (un nombre puede corresponder a diferentes estilos). Fuente:
rendimiento de Rasmus Bååth en useR! 2017.
La separación punto a punto recuerda ominosamente el uso de métodos en la programación orientada a objetos, pero es históricamente común. Es tan común que este estilo particular puede considerarse verdaderamente R'vsky. Por ejemplo, la mayoría de las funciones básicas lo usan específicamente (y todos se reunieron con data.table y as.factor).
Pero la separación _ es uno de los estilos menos populares (y aquí Hadley va en contra de la mayoría). Para muchos usuarios de R, los guiones bajos serán molestos: en la popular extensión Emacs Speaks Statistics, se reemplaza por defecto con el operador de asignación
<- . Y la configuración predeterminada, por supuesto,
casi nadie cambia.
Sin embargo, la influencia de Emacs ESS sigue siendo una explicación de la categoría de "menea la cola del perro". Hay una razón más antigua: en versiones anteriores de R, el guión bajo era sinónimo de la flecha
<- . Por ejemplo, en 2000 podría
cumplir con esto:
Aquí, en lugar de crear la variable
c_mean R asignó el valor 3 primero a la variable media, y luego a la variable c. En la R moderna, tales metamorfosis, por supuesto, no ocurrirán.
Debido a la impopularidad, las funciones _ de este estilo casi no se encuentran entre las básicas:
Finalmente, el estilo lowerCamel es poco legible cuando se usan nombres largos:
Por lo tanto, en términos de nombres, las recomendaciones de la guía no pueden considerarse inequívocas; después de todo, esto es una cuestión de gustos (siempre y cuando haya consistencia en esto).
4. llaves
Según la guía, una nueva línea debe seguir a la llave de apertura, y la de cierre debe estar en una línea separada (a menos que la siga). Es decir algo como esto:
if (x >= 0) { log(x) } else { message("Not applicable!") }
Todo aquí no es muy interesante: este es el estilo de sangría estándar de K&R, que se remonta al lenguaje C y el famoso libro de Kernigan y Ritchie "The C Programming Language" (o K&R por los nombres de los autores).
Los orígenes de este estilo también son bastante obvios: le permite guardar líneas y mantener la legibilidad. Para las primeras computadoras, el espacio vertical era demasiado lujoso. Por ejemplo, C se desarrolló en PDP-11, en cuyo terminal solo había 24 líneas. Y al imprimir un libro de K&R, ¡este estilo ahorró papel!
5. cadena de 80 caracteres
La longitud de línea recomendada según la guía es de 80 caracteres. El número mágico 80 se encuentra no solo en R, sino también en una gran cantidad de otros lenguajes (Java, Perl, PHP, etc., etc.). Y no solo idiomas: incluso la línea de comandos de Windows consta de 80 caracteres.
Por primera vez en programación, este número apareció en 1928 en lugar de con la tarjeta perforada estándar de IBM, donde había exactamente 80 columnas para datos. Una pregunta mucho más interesante es ¿por qué se eligió tal estándar? Después de todo, se utilizaron previamente tarjetas perforadas de diferente longitud (para 24 o 45 columnas).

La respuesta más popular relaciona la longitud de una tarjeta perforada con la longitud de línea de las máquinas de escribir. Las primeras máquinas fueron diseñadas para el papel estándar estadounidense de 8½ x 11 pulgadas, y se les permitió imprimir de 72 a 90 caracteres, dependiendo del tamaño de los márgenes. Por lo tanto, la versión de 80 caracteres por línea parece bastante plausible, aunque no es cierto en el último recurso. Es posible que 80 caracteres sea solo el término medio en términos de ergonomía.
6. Sangría de línea: espacios frente a pestañas
El estilo recomendado por la guía es dos espacios, no una pestaña. El rechazo de la tabulación es bastante comprensible: la longitud de la TAB varía en diferentes editores de texto (puede ser de 2 a 8 espacios). Al rechazarlos, obtenemos dos ventajas a la vez: en primer lugar, el código se verá exactamente igual a como lo escribimos; en segundo lugar, no habrá violación accidental de la longitud de cadena recomendada. En este caso, por supuesto, aumentamos el tamaño del archivo (¿quién quiere ocuparse de tales microoptimizaciones en 2k19?)
Los espacios de disputa vs pestañas tienen una larga historia, y pueden equipararse con los religiosos (como Win vs Linux, Android vs iOS y similares). Sin embargo, ya sabemos quién lo ganó: según el
estudio de Stack Overflow, los desarrolladores que usan espacios ganan más que aquellos que usan pestañas. Un argumento más poderoso que las reglas de una guía de estilo, ¿verdad?
En lugar de una conclusión: las reglas de las guías de estilo pueden parecer extrañas e ilógicas. De hecho, ¿por qué la flecha
<- si hay un operador estándar
= ? Pero si profundizas más, entonces detrás de cada regla hay una lógica, a menudo ya olvidada.