Los sistemas de moderación automática se implementan en servicios web y aplicaciones donde es necesario procesar una gran cantidad de mensajes de usuario. Dichos sistemas pueden reducir los costos de la moderación manual, acelerarla y procesar todos los mensajes de los usuarios en tiempo real. En el artículo, hablaremos sobre la construcción de un sistema de moderación automática para procesar inglés usando algoritmos de aprendizaje automático. Discutiremos todo el trabajo de la tubería desde las tareas de investigación y la elección de los algoritmos de ML hasta la implementación. Veamos dónde buscar conjuntos de datos listos para usar y cómo recopilar datos para la tarea usted mismo.
Preparado con Ira Stepanyuk ( id_step ), científico de datos en Poteha LabsDescripción de la tarea
Trabajamos con chats activos multiusuario, donde pueden aparecer mensajes cortos de docenas de usuarios en un chat cada minuto. La tarea es resaltar mensajes tóxicos y mensajes con comentarios obscenos en los diálogos de dichos chats. Desde el punto de vista del aprendizaje automático, esta es una tarea de clasificación binaria, donde cada mensaje debe asignarse a una de las clases.
Para resolver este problema, antes que nada, era necesario comprender qué son los mensajes tóxicos y qué los hace tóxicos. Para hacer esto, observamos una gran cantidad de mensajes de usuario típicos en Internet. Aquí hay algunos ejemplos que ya hemos dividido en mensajes tóxicos y normales.
Se puede ver que los mensajes tóxicos a menudo contienen palabras obscenas, pero aún así esto no es un requisito previo. El mensaje puede no contener palabras inapropiadas, pero puede ser ofensivo para alguien (ejemplo (1)). Además, a veces los mensajes tóxicos y normales contienen las mismas palabras que se usan en diferentes contextos, ofensivos o no (ejemplo (2)). Tales mensajes también deben ser capaces de distinguir.
Habiendo estudiado varios mensajes, para nuestro sistema de moderación llamamos
tóxico a aquellos mensajes que contienen declaraciones con expresiones obscenas, insultantes u odio hacia alguien.
Datos
Datos abiertos
Uno de los conjuntos de datos de moderación más famosos es el conjunto de datos del Kaggle
Toxic Comment Classification Challenge . Parte del marcado en el conjunto de datos es incorrecto: por ejemplo, los mensajes con palabras obscenas se pueden marcar como normales. Debido a esto, no puedes simplemente competir en Kernel y obtener un algoritmo de clasificación que funcione bien. Debe trabajar más con los datos, ver qué ejemplos no son suficientes y agregar datos adicionales con dichos ejemplos.
Además de los concursos, hay varias publicaciones científicas con enlaces a conjuntos de datos adecuados (
ejemplo ), pero no todos pueden usarse en proyectos comerciales. La mayoría de estos conjuntos de datos contienen mensajes de la red social Twitter, donde puedes encontrar muchos tweets tóxicos. Además, los datos se recopilan de Twitter, ya que ciertos hashtags se pueden usar para buscar y marcar mensajes de usuario tóxicos.
Datos manuales
Después de recopilar el conjunto de datos de fuentes abiertas y entrenarlo en el modelo básico, quedó claro que los datos abiertos no son suficientes: la calidad del modelo no es satisfactoria. Además de los datos abiertos para resolver el problema, teníamos a nuestra disposición una selección no asignada de mensajes de un mensajero del juego con una gran cantidad de mensajes tóxicos.

Para usar estos datos para su tarea, tuvieron que ser etiquetados de alguna manera. En ese momento, ya había un clasificador de línea base entrenado, que decidimos usar para el marcado semiautomático. Después de ejecutar todos los mensajes a través del modelo, obtuvimos las probabilidades de toxicidad de cada mensaje y los ordenamos en orden descendente. Al comienzo de esta lista se recopilaron mensajes con palabras obscenas y ofensivas. Al final, por el contrario, hay mensajes de usuario normales. Por lo tanto, la mayoría de los datos (con valores de probabilidad muy grandes y muy pequeños) no se pudieron marcar, sino que se asignaron inmediatamente a una determinada clase. Queda por marcar los mensajes que se ubicaron en el medio de la lista, lo que se hizo manualmente.
Aumento de datos
A menudo, en los conjuntos de datos puede ver mensajes cambiados en los que el clasificador está equivocado, y la persona entiende correctamente su significado.
Esto se debe a que los usuarios se ajustan y aprenden a engañar a los sistemas de moderación para que los algoritmos cometan errores en los mensajes tóxicos, y el significado permanece claro para la persona. Lo que los usuarios están haciendo ahora:
- errores tipográficos generan: eres un estúpido imbécil, fóllate ,
- reemplace los caracteres alfabéticos con números similares en la descripción: n1gga, b0ll0cks ,
- inserte espacios adicionales: idiota ,
- eliminar espacios entre palabras: dieyoustupid .
Para entrenar un clasificador que sea resistente a tales sustituciones, debe hacer lo que hacen los usuarios: generar los mismos cambios en los mensajes y agregarlos al conjunto de entrenamiento a los datos principales.
En general, esta lucha es inevitable: los usuarios siempre tratarán de encontrar vulnerabilidades y ataques, y los moderadores implementarán nuevos algoritmos.
Descripción de subtareas
Nos enfrentamos a subtareas para analizar mensajes en dos modos diferentes:
- modo en línea: análisis de mensajes en tiempo real, con máxima velocidad de respuesta;
- modo fuera de línea: análisis de registros de mensajes y asignación de diálogos tóxicos.
En el modo en línea, procesamos cada mensaje de usuario y lo ejecutamos a través del modelo. Si el mensaje es tóxico, ocúltelo en la interfaz de chat y, si es normal, muéstrelo. En este modo, todos los mensajes deben procesarse muy rápidamente: el modelo debe dar una respuesta tan rápida como para no interrumpir la estructura del diálogo entre usuarios.
En el modo fuera de línea, no hay límites de tiempo para el trabajo y, por lo tanto, quería implementar el modelo con la más alta calidad.
Modo en línea. Búsqueda de diccionario
Independientemente del modelo que se elija a continuación, debemos buscar y filtrar mensajes con palabras obscenas. Para resolver este subproblema, es más fácil compilar un diccionario de palabras y expresiones no válidas que no se pueden omitir, y buscar esas palabras en cada mensaje. La búsqueda debe ser rápida, por lo que el algoritmo de búsqueda de subcadenas ingenuo para ese tiempo no encaja. Un algoritmo adecuado para encontrar un conjunto de palabras en una cadena es
el algoritmo Aho-Korasik . Debido a este enfoque, es posible identificar rápidamente algunos ejemplos tóxicos y bloquear mensajes antes de que se transmitan al algoritmo principal. El uso del algoritmo ML le permitirá "comprender el significado" de los mensajes y mejorar la calidad de la clasificación.
Modo en línea. Modelo básico de aprendizaje automático
Para el modelo base, decidimos utilizar un enfoque estándar para la clasificación de texto: TF-IDF + algoritmo de clasificación clásico. De nuevo por razones de velocidad y rendimiento.
TF-IDF es una medida estadística que le permite determinar las palabras más importantes para el texto en el cuerpo utilizando dos parámetros: la frecuencia de las palabras en cada documento y el número de documentos que contienen una palabra específica (en más detalle
aquí ). Habiendo calculado para cada palabra en el mensaje TF-IDF, obtenemos una representación vectorial de este mensaje.
TF-IDF se puede calcular para palabras en el texto, así como para palabras y caracteres de n-gramas. Dicha extensión funcionará mejor, ya que podrá manejar frases y palabras frecuentes que no estaban en la muestra de capacitación (fuera del vocabulario).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
Ejemplo de uso de TF-IDF en n-gramos de palabras y caracteresDespués de convertir los mensajes en vectores, puede usar cualquier método clásico para la clasificación:
regresión logística, SVM ,
bosque aleatorio, impulso .
Decidimos utilizar la regresión logística en nuestra tarea, ya que este modelo aumenta la velocidad en comparación con otros clasificadores clásicos de ML y predice las probabilidades de clase, lo que le permite seleccionar de manera flexible un umbral de clasificación en la producción.
El algoritmo obtenido usando TF-IDF y la regresión logística funciona rápidamente y define bien los mensajes con palabras y expresiones obscenas, pero no siempre comprende el significado. Por ejemplo, a menudo los mensajes con las palabras '
negro ' y '
feminismo ' cayeron en la clase tóxica. Quería solucionar este problema y aprender a comprender mejor el significado de los mensajes utilizando la próxima versión del clasificador.
Modo fuera de línea
Para comprender mejor el significado de los mensajes, puede usar algoritmos de redes neuronales:
- Incrustaciones (Word2Vec, FastText)
- Redes neuronales (CNN, RNN, LSTM)
- Nuevos modelos pre-entrenados (ELMo, ULMFiT, BERT)
Analizaremos algunos de estos algoritmos y cómo se pueden usar con más detalle.
Word2Vec y FastText
Los modelos de incrustación le permiten obtener representaciones vectoriales de palabras de textos. Hay
dos tipos de Word2Vec : Skip-gram y CBOW (Continuous Bag of Words). En Skip-gram, el contexto es predicho por la palabra, pero en CBOW, viceversa: el contexto predice la palabra.
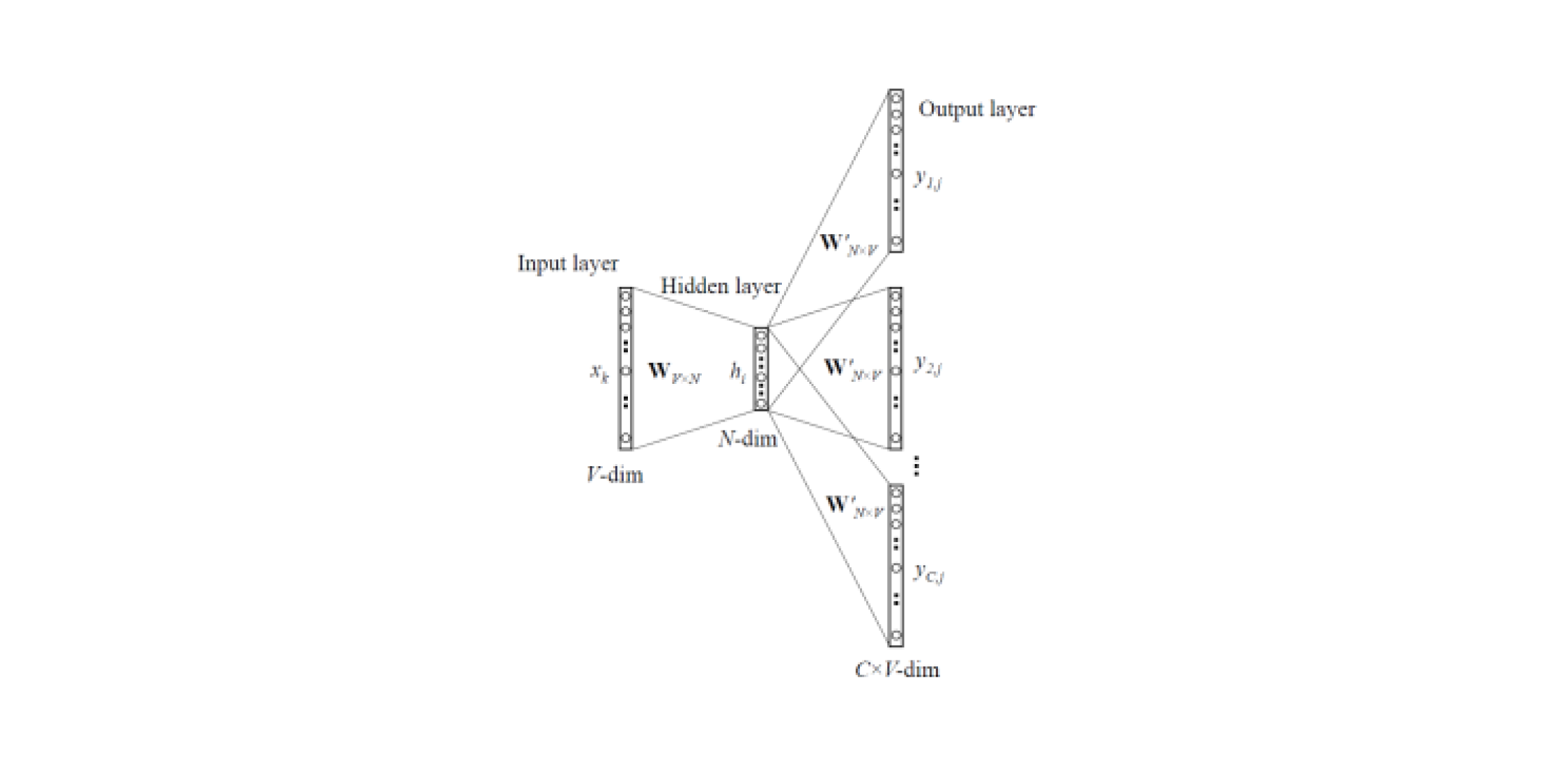
Dichos modelos están entrenados en grandes cuerpos de textos y le permiten obtener representaciones vectoriales de palabras de una capa oculta de una red neuronal entrenada. La desventaja de esta arquitectura es que el modelo aprende de un conjunto limitado de palabras contenidas en el corpus. Esto significa que para todas las palabras que no estaban en el cuerpo de textos en la etapa de entrenamiento, no habrá incrustaciones. Y esta situación a menudo ocurre cuando se usan modelos pre-entrenados para sus tareas: para algunas de las palabras no habrá incrustaciones, en consecuencia se perderá una gran cantidad de información útil.
Para resolver el problema con palabras que no están en el diccionario (OOV, fuera del vocabulario) hay un modelo de incrustación mejorado:
FastText . En lugar de usar palabras simples para entrenar la red neuronal, FastText divide las palabras en n-gramas (subpalabras) y aprende de ellas. Para obtener una representación vectorial de una palabra, debe obtener representaciones vectoriales del n-gramo de esta palabra y agregarlas.
Por lo tanto, los modelos Word2Vec y FastText pre-entrenados se pueden usar para obtener vectores de características de los mensajes. Las características obtenidas se pueden clasificar utilizando clasificadores clásicos de ML o una red neuronal completamente conectada.
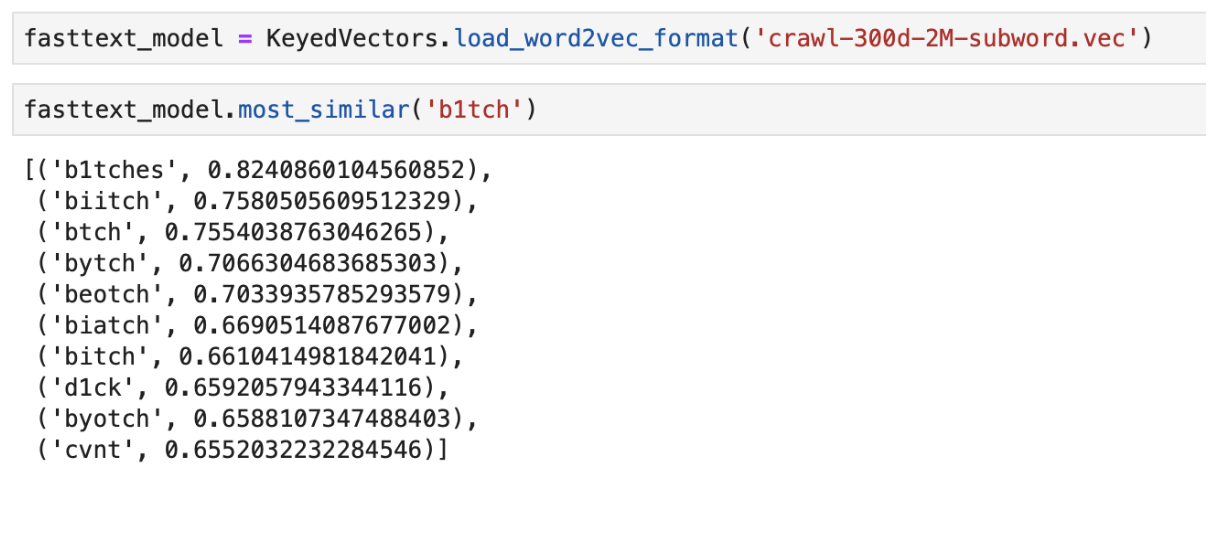 Un ejemplo de la salida de las palabras "más cercano" en significado usando FastText pre- entrenado
Un ejemplo de la salida de las palabras "más cercano" en significado usando FastText pre- entrenadoClasificador CNN
Para el procesamiento y clasificación de textos de algoritmos de redes neuronales, las redes recurrentes (LSTM, GRU) se usan con mayor frecuencia, ya que funcionan bien con secuencias. Las redes convolucionales (CNN) se usan con mayor frecuencia para el procesamiento de imágenes, pero también se
pueden usar en la tarea de clasificación de texto. Considere cómo se puede hacer esto.
Cada mensaje es una matriz en la que en cada línea del token (palabra) se escribe su representación vectorial. La convolución se aplica a dicha matriz de cierta manera: el filtro de convolución "se desliza" sobre filas enteras de la matriz (vectores de palabras), pero captura varias palabras a la vez (generalmente 2-5 palabras), procesando así las palabras en el contexto de palabras vecinas. Los detalles de cómo sucede esto se pueden ver en la
imagen .
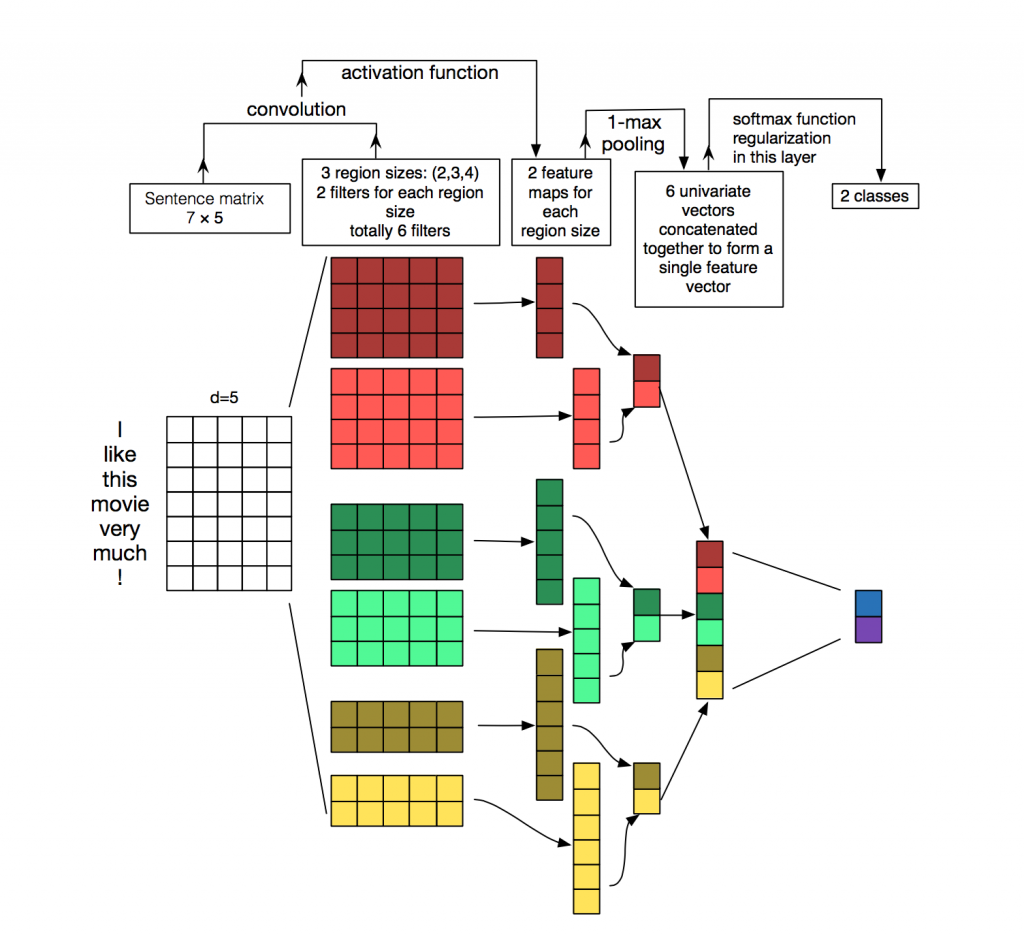
¿Por qué usar redes convolucionales para el procesamiento de textos cuando puede usar recurrentes? El hecho es que las convoluciones funcionan mucho más rápido. Utilizándolos para la clasificación de mensajes, puede ahorrar mucho tiempo en la capacitación.
ELMo
ELMo (incrustaciones de modelos de lenguaje) es un modelo de incrustación basado en un modelo de idioma que se
introdujo recientemente . El nuevo modelo de incrustación es diferente de los modelos Word2Vec y FastText. Los vectores de palabras ELMo tienen ciertas ventajas:
- La presentación de cada palabra depende del contexto completo en el que se usa.
- La representación se basa en símbolos, lo que permite la formación de representaciones confiables para palabras OOV (fuera del vocabulario).
ELMo se puede utilizar para diversas tareas en PNL. Por ejemplo, para nuestra tarea, los vectores de mensajes recibidos usando ELMo se pueden enviar al clasificador clásico de ML o usar una red convolucional o totalmente conectada.
Las incrustaciones pre-entrenadas ELMo son bastante simples de usar para su tarea, un ejemplo de uso se puede encontrar
aquí .
Características de implementación
API de matraz
El prototipo de API fue escrito en Flask, ya que es fácil de usar.
Dos imágenes de Docker
Para la implementación, utilizamos dos imágenes de acoplador: la base, donde se instalaron todas las dependencias, y la principal para iniciar la aplicación. Esto ahorra mucho tiempo de montaje, ya que la primera imagen rara vez se reconstruye, y esto ahorra tiempo durante la implementación. Se dedica mucho tiempo a construir y descargar bibliotecas de aprendizaje automático, lo que no es necesario con cada confirmación.
Prueba
La peculiaridad de la implementación de un número bastante grande de algoritmos de aprendizaje automático es que incluso con altas métricas en el conjunto de datos de validación, la calidad real del algoritmo en producción puede ser baja. Por lo tanto, para probar el funcionamiento del algoritmo, todo el equipo usó el bot en Slack. Esto es muy conveniente, porque cualquier miembro del equipo puede verificar qué respuesta dan los algoritmos para un mensaje en particular. Este método de prueba le permite ver de inmediato cómo funcionarán los algoritmos en los datos en vivo.
Una buena alternativa es lanzar la solución en sitios públicos como Yandex Toloka y AWS Mechanical Turk.
Conclusión
Examinamos varios enfoques para resolver el problema de la moderación automática de mensajes y describimos las características de nuestra implementación.
Las principales observaciones obtenidas durante el trabajo:
- La búsqueda de diccionario y el algoritmo de aprendizaje automático basados en TF-IDF y la regresión logística permitieron clasificar los mensajes rápidamente, pero no siempre correctamente.
- Los algoritmos de red neuronal y los modelos de incrustaciones pre-entrenados hacen frente mejor a esta tarea y pueden determinar la toxicidad dentro del significado del mensaje.
Por supuesto, publicamos la
demostración abierta
Poteha Toxic Comment Detection en el bot de
Facebook . ¡Ayúdanos a mejorar el bot!
Estaré encantado de responder preguntas en los comentarios.