
Introduccion
Es hora de hablar de excepciones o, más bien, de situaciones excepcionales. Antes de comenzar, veamos la definición. ¿Qué es una situación excepcional?
Esta es una situación que hace que la ejecución del código actual o posterior sea incorrecta. Me refiero diferente de cómo fue diseñado o previsto. Tal situación compromete la integridad de una aplicación o su parte, por ejemplo, un objeto. Lleva la aplicación a un estado extraordinario o excepcional.
Pero, ¿por qué necesitamos definir esta terminología? Porque nos mantendrá en algunos límites. Si no seguimos la terminología, podemos alejarnos demasiado de un concepto diseñado que puede dar lugar a muchas situaciones ambiguas. Veamos algunos ejemplos prácticos:
struct Number { public static Number Parse(string source) { // ... if(!parsed) { throw new ParsingException(); } // ... } public static bool TryParse(string source, out Number result) { // .. return parsed; } }
Este ejemplo parece un poco extraño, y es por una razón. Hice este código ligeramente artificial para mostrar la importancia de los problemas que aparecen en él. Primero, veamos el método Parse . ¿Por qué debería lanzar una excepción?
- Porque el parámetro que acepta es una cadena, pero su salida es un número, que es un tipo de valor. Este número no puede indicar la validez de los cálculos: simplemente existe. En otras palabras, el método no tiene medios en su interfaz para comunicar un problema potencial.
- Por otro lado, el método espera una cadena correcta que contenga algún número y no caracteres redundantes. Si no contiene, hay un problema en los requisitos previos del método: el código que llama a nuestro método ha pasado datos incorrectos.
Por lo tanto, la situación cuando este método obtiene una cadena con datos incorrectos es excepcional porque el método no puede devolver un valor correcto ni nada. Por lo tanto, la única forma es lanzar una excepción.
La segunda variante del método puede señalar algunos problemas con los datos de entrada: el valor de retorno aquí es boolean que indica la ejecución exitosa del método. Este método no necesita usar excepciones para señalar problemas: todos están cubiertos por el valor de retorno false .
Resumen
El manejo de excepciones puede parecer tan fácil como ABC: solo necesitamos colocar bloques try-catch y esperar los eventos correspondientes. Sin embargo, esta simplicidad se hizo posible debido al tremendo trabajo de los equipos CLR y CoreCLR que unificaron todos los errores que provienen de todas las direcciones y fuentes en el CLR. Para entender de qué vamos a hablar a continuación, veamos un diagrama:
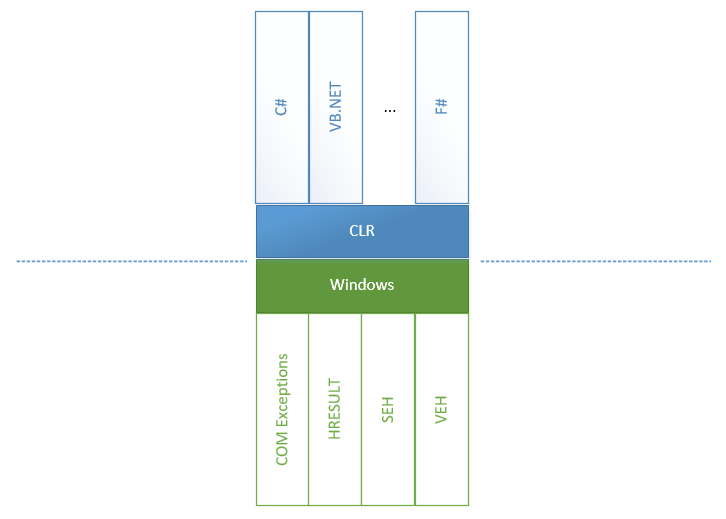
Podemos ver que dentro de .NET Framework hay dos mundos: todo lo que pertenece a CLR y todo lo que no, incluidos todos los posibles errores que aparecen en Windows y otras partes del mundo inseguro.
- El manejo estructurado de excepciones (SEH) es una forma estándar en que Windows maneja las excepciones. Cuando se llaman métodos
unsafe y se lanzan excepciones, existe la conversión insegura <-> CLR de excepciones en ambas direcciones: de inseguro a CLR y hacia atrás. Esto se debe a que CLR puede llamar a un método inseguro que a su vez puede llamar a un método CLR. - El manejo de excepciones vectorizadas (VEH) es una raíz de SEH y le permite colocar sus manejadores en lugares donde puedan producirse excepciones. En particular, se usaba para colocar
FirstChanceException . - Las excepciones COM + aparecen cuando la fuente de un problema es un componente COM. En este caso, una capa entre COM y un método .NET debe convertir un error COM en una excepción .NET.
- Y, por supuesto, envoltorios para HRESULT. Se introducen para convertir un modelo WinAPI (un código de error está contenido en un valor de retorno, mientras que los valores de retorno se obtienen utilizando parámetros de método) en un modelo de excepciones porque es una excepción que es estándar para .NET.
Por otro lado, hay idiomas por encima de CLI, cada uno de los cuales tiene más o menos funciones para manejar excepciones. Por ejemplo, recientemente VB.NET o F # tenían una funcionalidad de manejo de excepciones más rica expresada en varios filtros que no existían en C #.
Códigos de retorno vs. excepción
Por separado, debo mencionar un modelo de manejo de errores de aplicación utilizando códigos de retorno. La idea de simplemente devolver un error es clara y clara. Además, si tratamos las excepciones como un operador goto , el uso de códigos de retorno se vuelve más razonable: en este caso, el usuario de un método ve la posibilidad de errores y puede entender qué errores pueden ocurrir. Sin embargo, no adivinemos qué es mejor y para qué, sino que discutamos el problema de elección utilizando una teoría bien razonada.
Supongamos que todos los métodos tienen interfaces para tratar los errores. Entonces todos los métodos se verían así:
public bool TryParseInteger(string source, out int result); public DialogBoxResult OpenDialogBox(...); public WebServiceResult IWebService.GetClientsList(...); public class DialogBoxResult : ResultBase { ... } public class WebServiceResult : ResultBase { ... }
Y su uso se vería así:
public ShowClientsResult ShowClients(string group) { if(!TryParseInteger(group, out var clientsGroupId)) return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed }; var webResult = _service.GetClientsList(clientsGroupId); if(!webResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult }; } var dialogResult = _dialogsService.OpenDialogBox(webResult.Result); if(!dialogResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult }; } return ShowClientsResult.Success(); }
Puede pensar que este código está sobrecargado con el manejo de errores. Sin embargo, me gustaría que reconsiderara su posición: todo aquí es una emulación de un mecanismo que arroja y maneja excepciones.
¿Cómo puede un método informar un problema? Puede hacerlo utilizando una interfaz para informar errores. Por ejemplo, en el método TryParseInteger , dicha interfaz está representada por un valor de retorno: si todo está bien, el método devolverá true . Si no está bien, devolverá false . Sin embargo, aquí hay una desventaja: el valor real se devuelve a través del parámetro out int result . La desventaja es que, por un lado, el valor de retorno es lógicamente y, por percepción, tiene más esencia de "valor de retorno" que la de nuestro parámetro. Por otro lado, no siempre nos importan los errores. el análisis proviene de un servicio que generó esta cadena, no necesitamos verificar si hay errores: la cadena siempre será correcta y buena para el análisis. Sin embargo, supongamos que tomamos otra implementación del método:
public int ParseInt(string source);
Entonces, hay una pregunta: si una cadena tiene errores, ¿qué debe hacer el método? ¿Debería devolver cero? Esto no será correcto: no hay cero en la cadena. En este caso, tenemos un conflicto de intereses: la primera variante tiene demasiado código, mientras que la segunda variante no tiene medios para informar errores. Sin embargo, en realidad es fácil decidir cuándo usar códigos de retorno y cuándo usar excepciones.
Si obtener un error es una norma, elija un código de retorno. Por ejemplo, es normal cuando un algoritmo de análisis de texto encuentra errores en un texto, pero si otro algoritmo que funciona con una cadena analizada obtiene un error de un analizador, puede ser crítico o, en otras palabras, excepcional.
Intenta atrapar finalmente en breve
Un bloque try cubre una sección donde un programador espera obtener una situación crítica que es tratada como una norma por código externo. En otras palabras, si algún código considera que su estado interno es inconsistente en función de algunas reglas y genera una excepción, un sistema externo, que tiene una visión más amplia de la misma situación, puede detectar esta excepción utilizando un bloque catch y normalizar la ejecución del código de la aplicación . Por lo tanto, legaliza las excepciones en esta sección del código al capturarlas . Creo que es una idea importante que justifica la prohibición de capturar todas try-catch(Exception ex){ ...} si acaso .
No significa que la captura de excepciones contradiga alguna ideología. Le digo que debe detectar solo los errores que espera de una sección particular de código. Por ejemplo, no puede esperar todo tipo de excepciones heredadas de ArgumentException o no puede obtener NullReferenceException , porque a menudo significa que un problema está más en su código que en uno llamado. Pero es apropiado esperar que no podrá abrir un archivo deseado. Incluso si está 200% seguro de que podrá hacerlo, no se olvide de verificar.
El bloque finally también es bien conocido. Es adecuado para todos los casos cubiertos por bloques try-catch . Excepto por varias situaciones especiales raras, este bloque siempre funcionará. ¿Por qué se introdujo tal garantía de rendimiento? Para limpiar aquellos recursos y grupos de objetos que fueron asignados o capturados en el bloque try y de los cuales este bloque es responsable.
Este bloque a menudo se usa sin el bloque catch cuando no nos importa qué error rompió un algoritmo, pero necesitamos limpiar todos los recursos asignados para este algoritmo. Veamos un ejemplo simple: un algoritmo de copia de archivos necesita dos archivos abiertos y un rango de memoria para un búfer de efectivo. Imagine que asignamos memoria y abrimos un archivo, pero no pudimos abrir otro. Para envolver todo en una "transacción" atómicamente, colocamos las tres operaciones en un solo bloque de try (como una variante de implementación) con recursos limpiados finally . Puede parecer un ejemplo simplificado, pero lo más importante es mostrar la esencia.
Lo que realmente le falta a C # es un bloque de fault que se activa cada vez que ocurre un error. Es como finally con esteroides. Si tuviéramos esto, podríamos, por ejemplo, crear un único punto de entrada para registrar situaciones excepcionales:
try { //... } fault exception { _logger.Warn(exception); }
Otra cosa que debería tocar en esta introducción son los filtros de excepción. No es una característica nueva en la plataforma .NET, pero los desarrolladores de C # pueden ser nuevos: el filtrado de excepciones apareció solo en v. 6.0. Los filtros deberían normalizar una situación cuando hay un único tipo de excepción que combina varios tipos de errores. Debería ayudarnos cuando queremos abordar un escenario particular, pero primero tenemos que detectar todo el grupo de errores y luego filtrarlos. Por supuesto, me refiero al código del siguiente tipo:
try { //... } catch (ParserException exception) { switch(exception.ErrorCode) { case ErrorCode.MissingModifier: // ... break; case ErrorCode.MissingBracket: // ... break; default: throw; } }
Bueno, ahora podemos reescribir este código correctamente:
try { //... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier) { // ... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket) { // ... }
La mejora aquí no está en la falta de construcción del switch . Creo que esta nueva construcción es mejor en varias cosas:
- usando
when para filtrar capturamos exactamente lo que queremos y es correcto en términos de ideología; - el código se vuelve más legible en esta nueva forma. Mirando a través del código, nuestro cerebro puede identificar bloques para manejar errores más fácilmente, ya que inicialmente busca
catch y no switch-case ; - el último pero no menos importante: una comparación preliminar ANTES de ingresar al bloque de captura. Significa que si hacemos conjeturas erróneas sobre situaciones potenciales, esta construcción funcionará más rápido que el
switch en el caso de lanzar una excepción nuevamente.
Muchas fuentes dicen que la característica peculiar de este código es que el filtrado ocurre antes de desenrollar la pila. Puede ver esto en situaciones en las que no hay otras llamadas excepto las habituales entre el lugar donde se produce una excepción y el lugar donde se produce la verificación del filtrado.
static void Main() { try { Foo(); } catch (Exception ex) when (Check(ex)) { ; } } static void Foo() { Boo(); } static void Boo() { throw new Exception("1"); } static bool Check(Exception ex) { return ex.Message == "1"; }
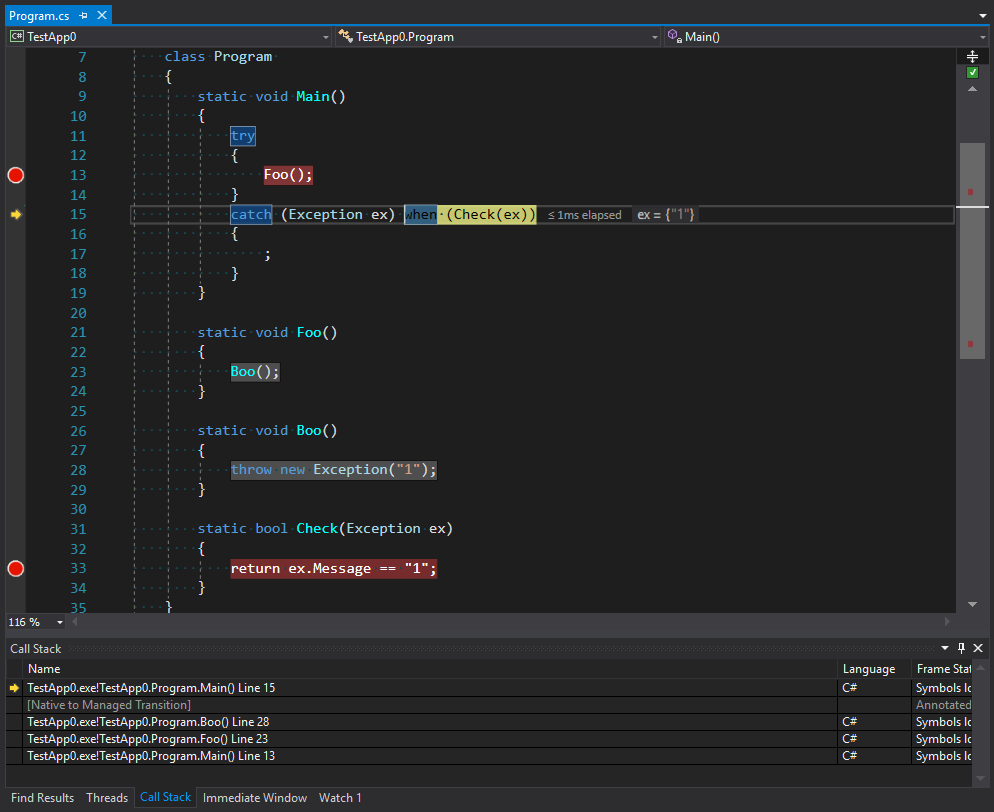
Puede ver en la imagen que el seguimiento de la pila contiene no solo la primera llamada de Main como el punto para capturar una excepción, sino toda la pila antes del punto de lanzar una excepción más la segunda entrada en Main través de un código no administrado. Podemos suponer que este código es exactamente el código para lanzar excepciones que se encuentra en la etapa de filtrado y elección de un controlador final. Sin embargo, no todas las llamadas se pueden manejar sin desenrollar la pila . Creo que la uniformidad excesiva de la plataforma genera demasiada confianza en ella. Por ejemplo, cuando un dominio llama a un método desde otro dominio, es absolutamente transparente en términos de código. Sin embargo, la forma en que los métodos llaman al trabajo es una historia absolutamente diferente. Vamos a hablar de ellos en la siguiente parte.
Serialización
Comencemos mirando los resultados de ejecutar el siguiente código (agregué la transferencia de una llamada a través del límite entre dos dominios de aplicación).
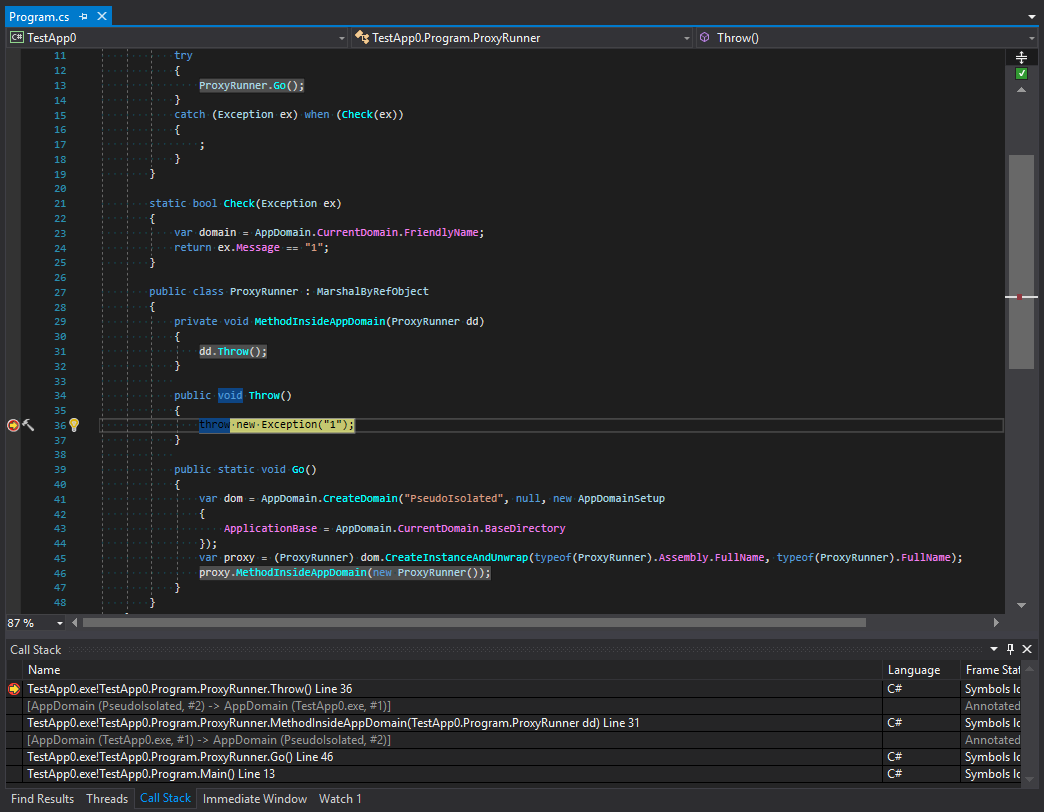
class Program { static void Main() { try { ProxyRunner.Go(); } catch (Exception ex) when (Check(ex)) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { throw new Exception("1"); } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } } }
Podemos ver que el despliegue de la pila ocurre antes de comenzar a filtrar. Veamos capturas de pantalla. El primero se toma antes de la generación de una excepción:
El segundo es después:
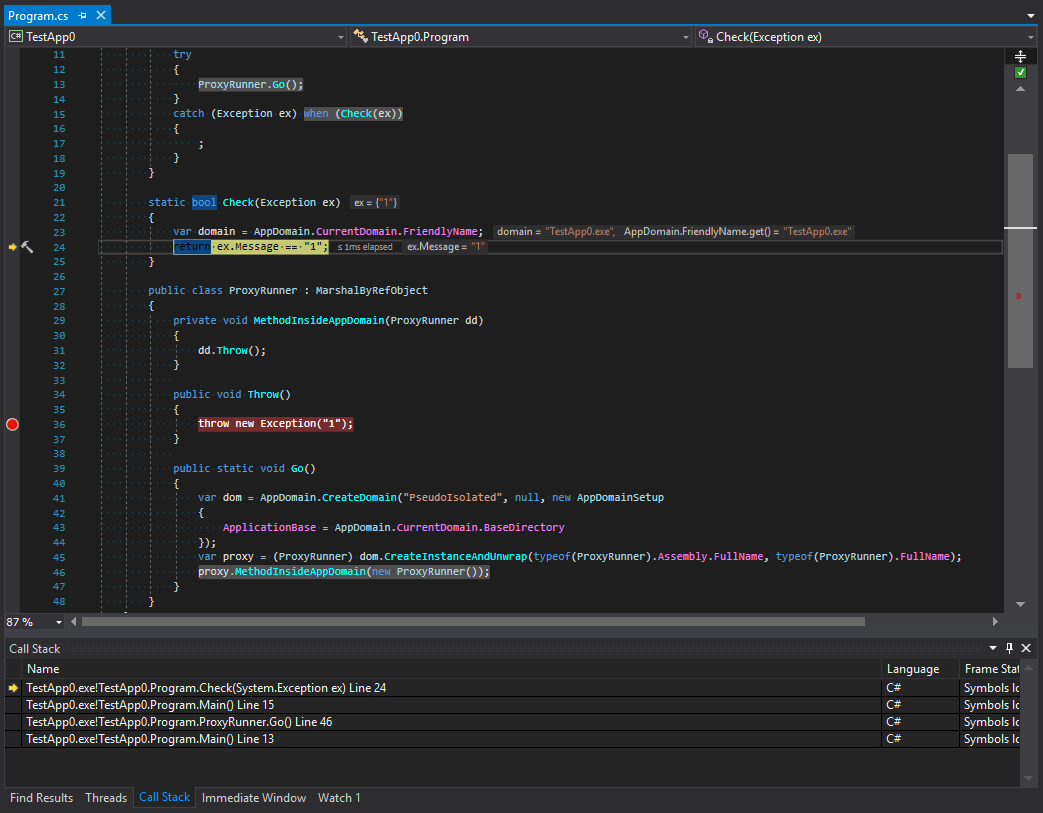
Estudiemos el seguimiento de llamadas antes y después de filtrar las excepciones. Que pasa aqui Podemos ver que los desarrolladores de plataformas hicieron algo que a primera vista parece la protección de un subdominio. El seguimiento se corta después del último método en la cadena de llamadas y luego está la transferencia a otro dominio. Pero creo que esto se ve extraño. Para entender por qué sucede esto, recordemos la regla principal para los tipos que organizan la interacción entre dominios. Estos tipos deberían heredar MarshalByRefObject y ser serializables. Sin embargo, a pesar de la rigurosidad de los tipos de excepción de C #, puede ser de cualquier naturaleza. Que significa Esto significa que pueden ocurrir situaciones en las que una excepción dentro de un subdominio puede ser atrapada en un dominio principal. Además, si un objeto de datos que puede entrar en una situación excepcional tiene algunos métodos que son peligrosos en términos de seguridad, puede llamarse en un dominio principal. Para evitar esto, la excepción se serializa primero y luego cruza el límite entre los dominios de aplicación y aparece nuevamente con una nueva pila. Veamos esta teoría:
[StructLayout(LayoutKind.Explicit)] class Cast { [FieldOffset(0)] public Exception Exception; [FieldOffset(0)] public object obj; } static void Main() { try { ProxyRunner.Go(); Console.ReadKey(); } catch (RuntimeWrappedException ex) when (ex.WrappedException is Program) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { var x = new Cast {obj = new Program()}; throw x.Exception; } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } }
Para el código C # podría arrojar una excepción de cualquier tipo (no quiero torturarte con MSIL) Realicé un truco en este ejemplo lanzando un tipo a uno no comparable, por lo que podríamos lanzar una excepción de cualquier tipo, pero el traductor pensaría que usamos el tipo de Exception . Creamos una instancia del tipo de Program , que no es serializable con seguridad, y lanzamos una excepción usando este tipo como carga de trabajo. La buena noticia es que obtienes un contenedor para excepciones que no son de excepción de RuntimeWrappedException que almacenará una instancia de nuestro objeto de tipo Program dentro y podremos detectar esta excepción. Sin embargo, hay malas noticias que respaldan nuestra idea: llamar a proxy.MethodInsideAppDomain(); generará SerializationException :
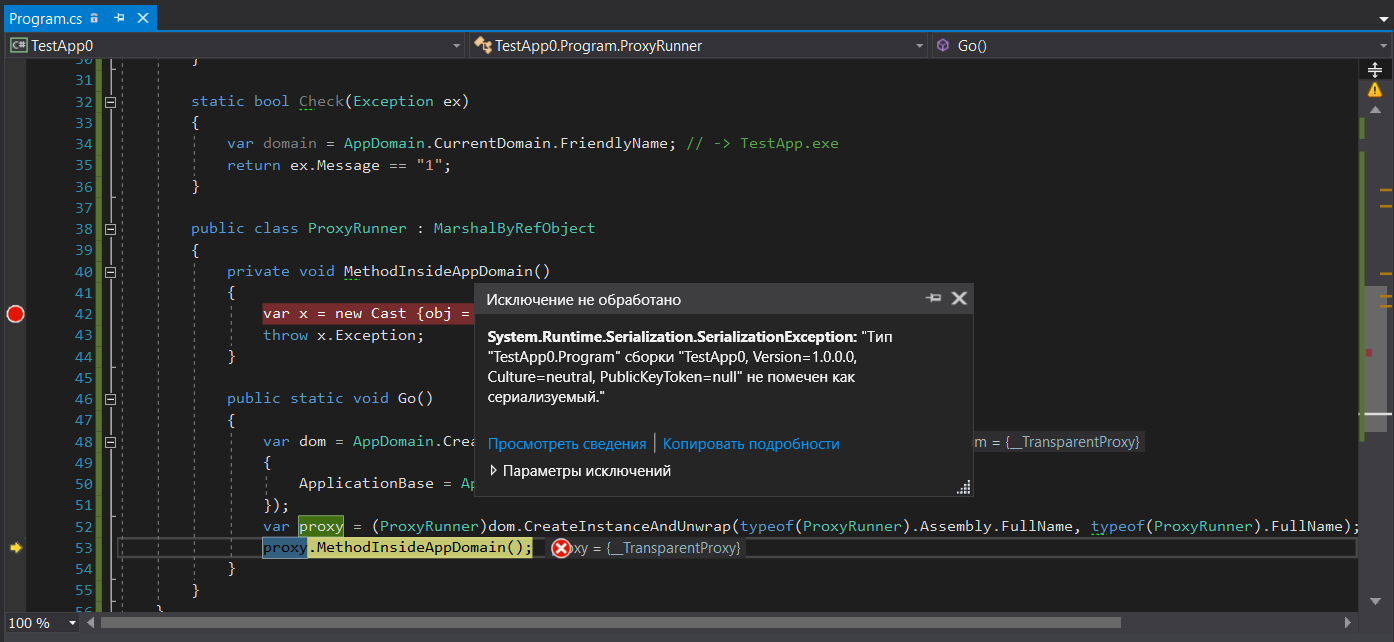
Por lo tanto, no puede transferir dicha excepción entre dominios ya que no es posible serializarla. Esto, a su vez, significa que el uso de filtros de excepción para envolver llamadas de métodos en otros dominios de todos modos conducirá al desenrollamiento de la pila a pesar de que la serialización parece ser innecesaria con la configuración FullTrust de un subdominio.
Deberíamos prestar atención adicional a la razón por la cual la serialización entre dominios es tan necesaria. En nuestro ejemplo artificial, creamos un subdominio que no tiene ninguna configuración. Significa que funciona en modo FullTrust. CLR confía plenamente en su contenido y no ejecuta ninguna comprobación adicional. Sin embargo, cuando inserte al menos una configuración de seguridad, la confianza completa desaparecerá y CLR comenzará a controlar todo lo que sucede dentro de un subdominio. Entonces, cuando tiene un dominio totalmente confiable, no necesita una serialización. Admita, no necesitamos protegernos. Pero la serialización existe no solo para protección. Cada dominio carga todos los ensamblajes necesarios por segunda vez y crea sus copias. Por lo tanto, crea copias de todos los tipos y todas las VMT. Por supuesto, al pasar un objeto de dominio a dominio obtendrá el mismo objeto. Pero sus VMT no serán suyos y este objeto no se puede convertir a otro tipo. En otras palabras, si creamos una instancia de un tipo Boo y la obtenemos en otro dominio, la conversión de (Boo)boo no funcionará. En este caso, la serialización y la deserialización resolverán el problema ya que el objeto existirá en dos dominios simultáneamente. Existirá con todos sus datos donde se creó y existirá en el dominio de uso como un objeto proxy, asegurando que se invoquen los métodos de un objeto original.
Al transferir un objeto serializado entre dominios, obtiene una copia completa del objeto de un dominio en otro mientras mantiene cierta delimitación en la memoria. Sin embargo, esta delimitación es ficticia. Se usa solo para aquellos tipos que no están en Shared AppDomain . Por lo tanto, si arroja algo no serializable como una excepción, pero desde Shared AppDomain , no obtendrá un error de serialización (podemos intentar lanzar Action lugar de Program ). Sin embargo, el despliegue de la pila ocurrirá de todos modos en este caso: ya que ambas variantes deberían funcionar de manera estándar. Para que nadie se confunda.
 Este capítulo fue traducido del ruso conjuntamente por el autor y por traductores profesionales . Puede ayudarnos con la traducción del ruso o el inglés a cualquier otro idioma, principalmente al chino o al alemán.
Este capítulo fue traducido del ruso conjuntamente por el autor y por traductores profesionales . Puede ayudarnos con la traducción del ruso o el inglés a cualquier otro idioma, principalmente al chino o al alemán.
Además, si quieres agradecernos, la mejor manera de hacerlo es darnos una estrella en Github o bifurcar el repositorio  github / sidristij / dotnetbook .
github / sidristij / dotnetbook .