Hola Mi nombre es Vadim Madison, lidero el desarrollo de la Plataforma del Sistema Avito. Sobre cómo en la compañía estamos cambiando de una arquitectura monolítica a una arquitectura de microservicio, se ha dicho más de una vez. Es hora de compartir cómo transformamos nuestra infraestructura para aprovechar al máximo los microservicios y no perdernos en ellos. Cómo PaaS nos ayuda aquí, cómo simplificamos la implementación y redujimos la creación de un microservicio a un solo clic. No todo lo que escribo a continuación está totalmente implementado en Avito, parte es cómo desarrollamos nuestra plataforma.
(Y al final de este artículo hablaré sobre la oportunidad de llegar a un seminario de tres días de un experto en arquitectura de microservicios Chris Richardson).

Como llegamos a los microservicios
Avito es uno de los mayores clasificados del mundo, publica más de 15 millones de nuevos anuncios por día. Nuestro backend acepta más de 20 mil solicitudes por segundo. Ahora tenemos varios cientos de microservicios.
Hemos estado construyendo arquitectura de microservicios durante varios años. Cómo exactamente: nuestros colegas hablaron en detalle en nuestra sección en RIT ++ 2017. En CodeFest 2017 (ver video ), Sergey Orlov y Mikhail Prokopchuk explicaron en detalle por qué necesitábamos la transición a microservicios y qué papel desempeñó Kubernetes aquí. Bueno, ahora estamos haciendo todo lo posible para minimizar los costos de escala inherentes a dicha arquitectura.
Inicialmente, no creamos un ecosistema que nos ayudara de manera integral en el desarrollo y lanzamiento de microservicios. Simplemente recopilaron soluciones sensatas de código abierto, las lanzaron en casa y sugirieron al desarrollador que las manejara. Como resultado, fue a una docena de lugares (tableros, servicios internos), después de lo cual se hizo más fuerte en el deseo de cortar el código de la manera antigua, en un monolito. El color verde en los diagramas a continuación indica lo que el desarrollador hace de una forma u otra con sus propias manos, el color amarillo indica automatización.
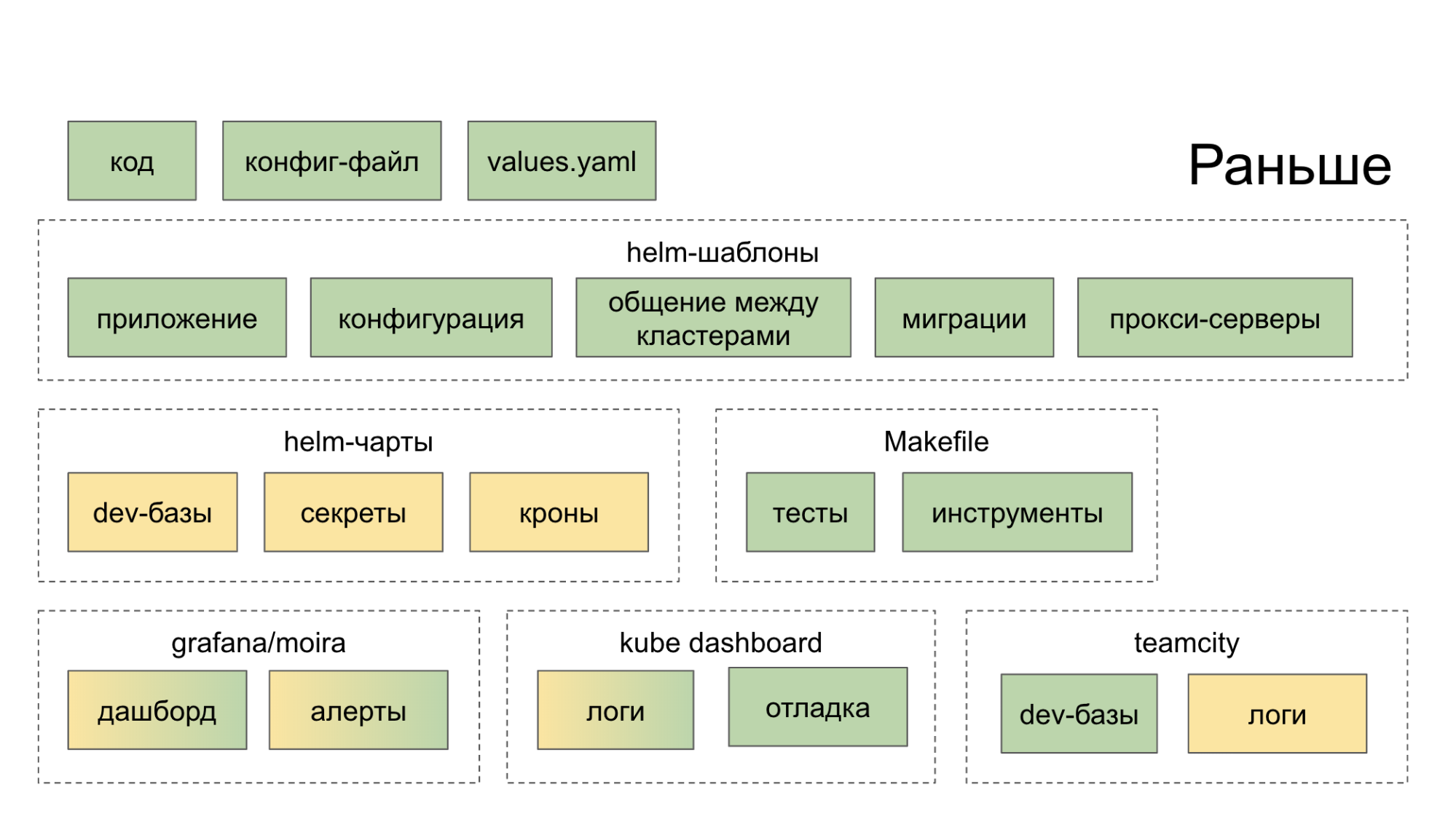
Ahora en la utilidad PaaS CLI, un equipo crea un nuevo servicio, y dos más agregan una nueva base de datos e implementan en Stage.
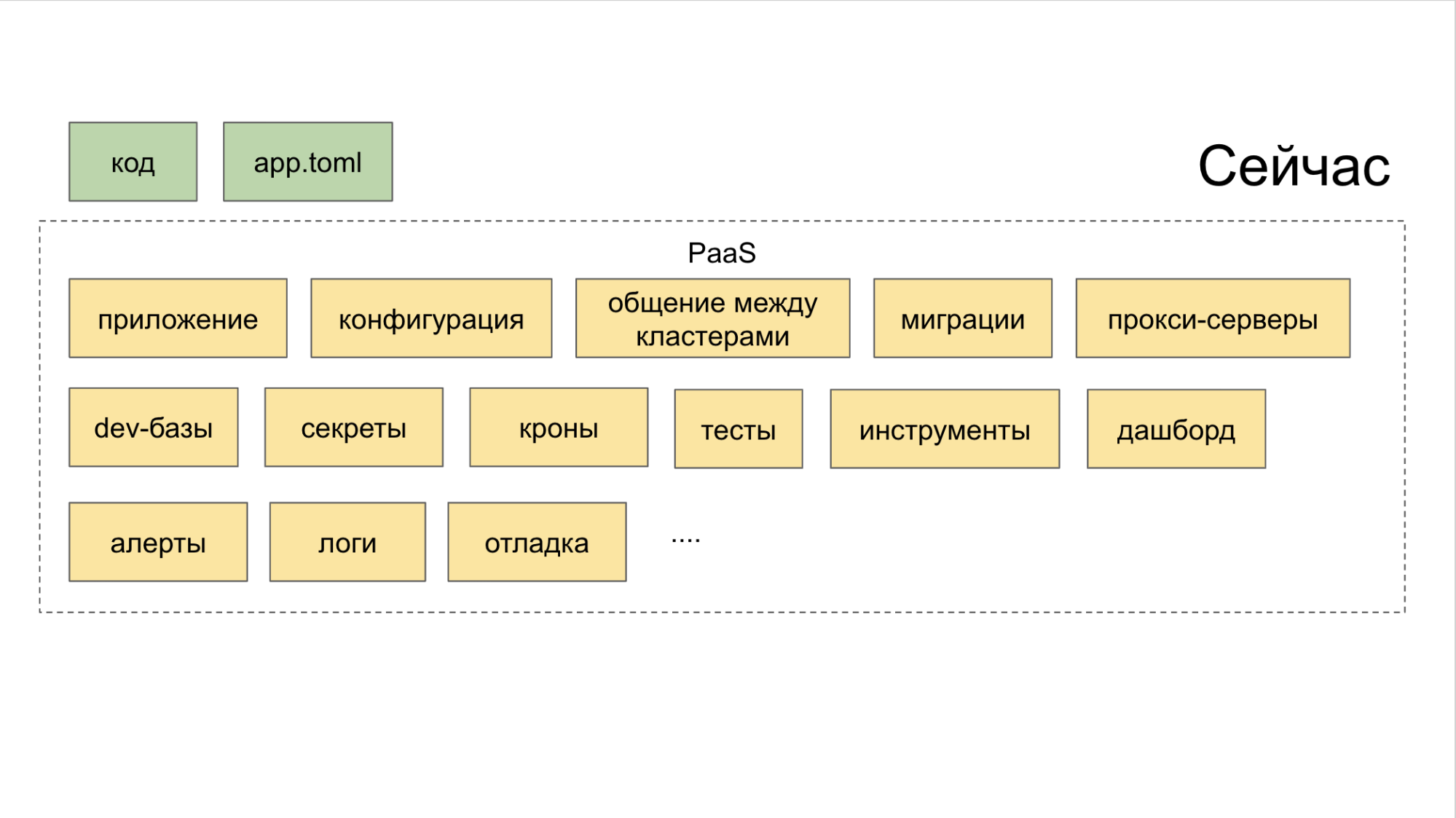
Cómo superar la era de la "fragmentación de microservicios"
Con una arquitectura monolítica, en aras de la coherencia de los cambios en el producto, los desarrolladores se vieron obligados a descubrir qué estaba pasando con sus vecinos. Cuando se trabaja en la nueva arquitectura, los contextos de servicio ya no dependen unos de otros.
Además, para que la arquitectura de microservicios sea efectiva, es necesario establecer muchos procesos, a saber:
• tala de árboles;
• seguimiento de consultas (Jaeger);
• agregación de errores (Centinela);
• estados, mensajes, eventos de Kubernetes (procesamiento de flujo de eventos);
• límite de carrera / disyuntor (puede usar Hystrix);
• control de la conectividad del servicio (usamos Netramesh);
• monitoreo (Grafana);
• asamblea (TeamCity);
• comunicación y notificación (Slack, correo electrónico);
• seguimiento de tareas; (Jira)
• compilación de documentación.
Para que, a medida que el sistema escala, no pierda su integridad y siga siendo efectivo, repensamos la organización del trabajo de microservicios en Avito.
Cómo manejamos los microservicios
Llevar a cabo una "política de partido" unificada entre los muchos microservicios que Avito ayuda a:
- división de infraestructura en capas;
- Concepto de plataforma como servicio (PaaS);
- Monitoreo de todo lo que sucede con microservicios.
Las capas de abstracción de infraestructura incluyen tres capas. Vayamos de arriba a abajo.
A. Superior - malla de servicio. Al principio probamos Istio, pero resultó que usa demasiados recursos, lo que es demasiado costoso para nuestros volúmenes. Por lo tanto, el ingeniero senior en el equipo de arquitectura Alexander Lukyanchenko desarrolló su propia solución: Netramesh (disponible en código abierto), que ahora usamos en producción y que consume varias veces menos recursos que Istio (pero no hace todo lo que Istio puede presumir).
B. Medio - Kubernetes. En él implementamos y operamos microservicios.
C. Inferior - metal desnudo. No usamos nubes y cosas como OpenStack, sino que nos sentamos completamente en metal desnudo.
Todas las capas están combinadas por PaaS. Y esta plataforma, a su vez, consta de tres partes.
I. Generadores controlados a través de la utilidad CLI. Es ella quien ayuda al desarrollador a crear un microservicio de la manera correcta y con un mínimo de esfuerzo.
II Colector combinado con control de todas las herramientas a través de un tablero común.
III. Repositorio . Interfiere con los planificadores que establecen automáticamente desencadenantes para acciones significativas. Gracias a este sistema, no se pierde una sola tarea solo porque alguien olvidó poner una tarea en Jira. Utilizamos una herramienta interna llamada Atlas para esto.

La implementación de microservicios en Avito también se lleva a cabo de acuerdo con un único esquema, que simplifica el control sobre ellos en cada etapa de desarrollo y lanzamiento.
Cómo funciona la tubería de desarrollo de microservicios estándar
En términos generales, la cadena de creación de microservicios es la siguiente:
CLI-push → Integración continua → Horneado → Implementación → Pruebas artificiales → Pruebas Canarias → Pruebas de compresión → Producción → Servicio.
Lo atravesamos exactamente en esta secuencia.
CLI-push
• Crear un microservicio .
Luchamos durante mucho tiempo para enseñar a cada desarrollador cómo hacer microservicios. Incluyendo escribió en Confluence instrucciones detalladas. Pero los esquemas cambiaron y se complementaron. En pocas palabras: un cuello de botella se formó al comienzo del viaje: tomó mucho más tiempo iniciar los microservicios de lo aceptable, y aún así, al crearlos, a menudo surgían problemas.
Al final, creamos una sencilla utilidad CLI que automatiza los pasos básicos al crear un microservicio. De hecho, reemplaza el primer git push. Esto es lo que ella hace.
- Crea un servicio de acuerdo con la plantilla, paso a paso, en el modo "asistente". Tenemos plantillas para los principales lenguajes de programación en el backend de Avito: PHP, Golang y Python.
- En un comando, implementa el entorno para el desarrollo local en una máquina específica - Minikube se eleva, los gráficos Helm se generan automáticamente y se ejecutan en kubernetes locales.
- Conecta la base de datos deseada. El desarrollador no necesita conocer la IP, el inicio de sesión y la contraseña para acceder a la base de datos que necesita, al menos localmente, al menos en Stage, al menos en producción. Además, la base de datos se implementa inmediatamente en una configuración tolerante a fallas y con equilibrio.
- Se realiza un montaje en vivo. Digamos que un desarrollador arregló algo en un microservicio a través de su IDE. La utilidad ve los cambios en el sistema de archivos y, en función de ellos, vuelve a ensamblar la aplicación (para Golang) y se reinicia. Para PHP, simplemente reenviamos el directorio dentro del cubo y allí la recarga en vivo se obtiene "automáticamente".
- Genera autotests. En forma de discos, pero bastante adecuados para su uso.
• Implementar microservicios .
Era un poco triste implementar un microservicio antes. Obligatorio requerido:
I. Dockerfile.
II Config.
III. Un gráfico de Helm, que es voluminoso e incluye:
- los propios gráficos;
- plantillas;
- valores específicos teniendo en cuenta diferentes entornos.
Nos libramos del dolor de rehacer los manifiestos de Kubernetes, y ahora se generan automáticamente. Pero lo más importante, simplificaron la implementación hasta el límite. De ahora en adelante, tenemos un Dockerfile, y el desarrollador escribe toda la configuración en un solo archivo corto app.toml.
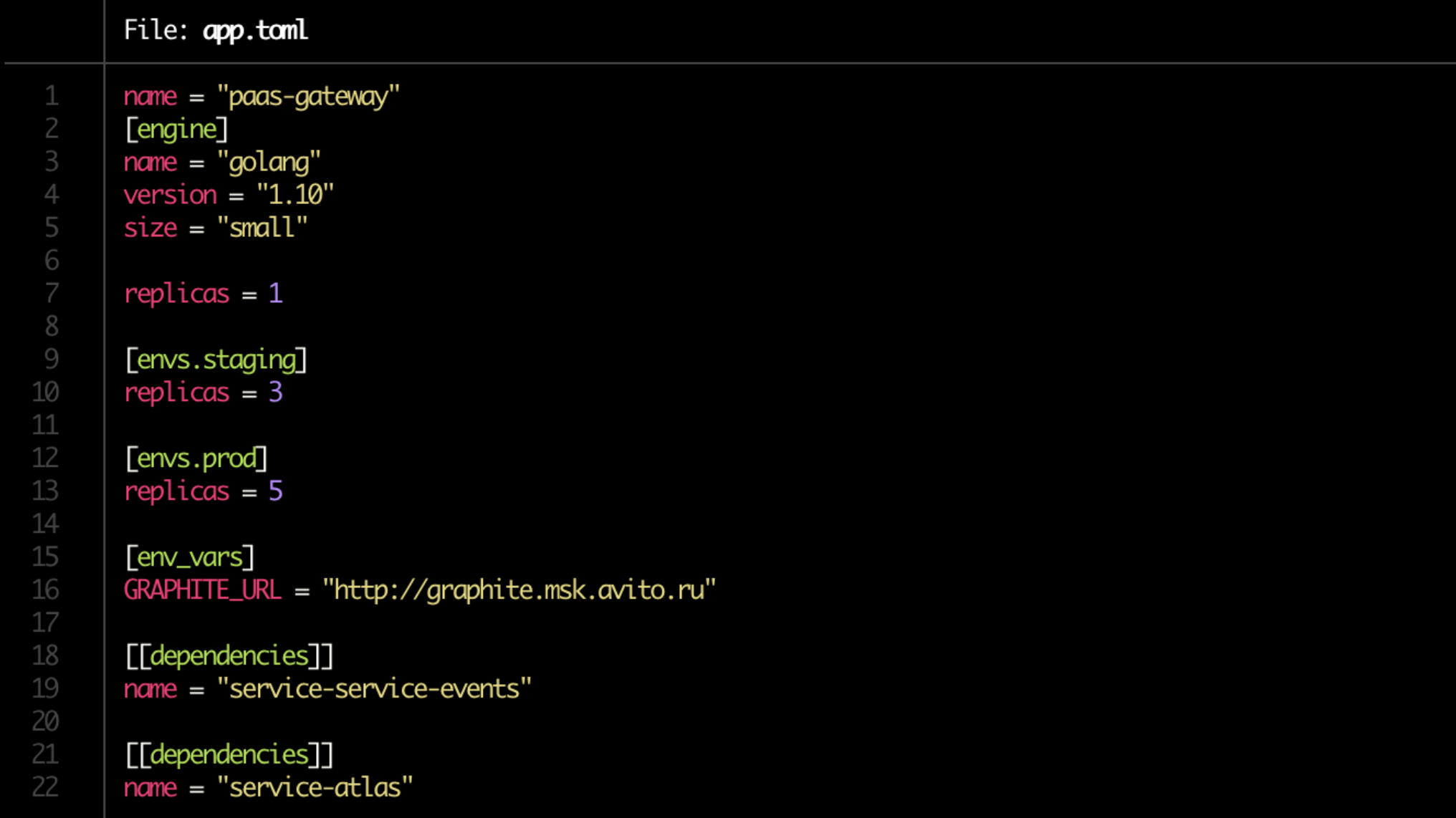
Sí, y en la aplicación .toml en sí es ahora asuntos por un minuto. Anotamos dónde y cuántas copias del servicio generar (en el servidor de desarrollo, en la preparación, en la producción), indican sus dependencias. Tenga en cuenta el tamaño de línea = "pequeño" en el bloque [motor]. Este es el límite que se asignará al servicio a través de Kubernetes.
Además, sobre la base de la configuración, todos los gráficos Helm necesarios se generan automáticamente y se crean conexiones a las bases de datos.
• Validación básica. Dichos controles también están automatizados.
Necesito rastrear:
- ¿Hay un Dockerfile?
- ¿hay app.toml;
- si hay documentación;
- si las dependencias están en orden;
- son las reglas de alertas establecidas.
Hasta el último punto: el propietario del servicio mismo indica qué métricas del producto monitorear.
• Preparación de documentación.
Sigue siendo un lugar problemático. Parece ser el más obvio, pero al mismo tiempo un récord "a menudo olvidado" y, por lo tanto, un eslabón vulnerable en la cadena.
Es necesario que la documentación esté bajo cada microservicio. Los siguientes bloques están incluidos en él.
I. Breve descripción del servicio . Solo unas pocas oraciones sobre lo que hace y para qué se necesita.
II Enlace al diagrama de arquitectura . Es importante que si lo mira rápidamente, sea fácil de entender, por ejemplo, si usa Redis para el almacenamiento en caché o como el almacén de datos principal en modo persistente. En Avito, hasta ahora, este es un enlace a Confluence.
III. Runbook Una breve guía para lanzar el servicio y las complejidades de manejarlo.
IV. Preguntas frecuentes , donde sería bueno anticipar los problemas que pueden encontrar sus colegas al trabajar con el servicio.
V. Descripción de puntos finales para la API . Si de repente no indicó su destino, es casi seguro que le pagarán colegas cuyos microservicios están relacionados con los suyos. Ahora usamos Swagger para esto y nuestra solución se llama breve.
VI. Etiquetas O marcadores que muestran a qué producto, funcionalidad, unidad estructural de la compañía a la que pertenece el servicio. Ayudan a comprender rápidamente, por ejemplo, si no está viendo la funcionalidad que sus colegas implementaron hace una semana para la misma unidad de negocios.
VII. El propietario o propietarios del servicio . En la mayoría de los casos, ellos, o ellos, pueden determinarse automáticamente usando PaaS, pero para el seguro requerimos que el desarrollador los especifique manualmente.
Finalmente, es una buena práctica revisar la documentación, similar a la revisión de código.
Integración continua
- Preparación de repositorios.
- Crear una tubería en TeamCity.
- Establecer derechos.
- Búsqueda de propietarios de servicios. Existe un esquema híbrido: marcado manual y automatización mínima de PaaS. Un esquema completamente automático no puede transferir servicios en apoyo a otro equipo de desarrollo o, por ejemplo, si un desarrollador de servicios se cierra.
- Registro de servicio en Atlas (ver arriba). Con todos sus propietarios y dependencias.
- Verifica las migraciones. Verificamos si hay alguno potencialmente peligroso entre ellos. Por ejemplo, en uno de ellos, aparece una tabla alternativa o algo más que puede alterar la compatibilidad del esquema de datos entre diferentes versiones del servicio. Luego, la migración no se realiza, sino que se suscribe: PaaS debe indicar al propietario del servicio cuando sea seguro usarlo.
Hornear
La siguiente etapa es el paquete de servicios antes de la implementación.
- Compila la aplicación. Según los clásicos, en la imagen de Docker.
- Generación de gráficos de Helm para el servicio en sí y los recursos relacionados. Incluido para bases de datos y caché. Se crean automáticamente de acuerdo con la configuración app.toml que se generó en la etapa CLI-push.
- Creación de tickets para que los administradores abran puertos (cuando sea necesario).
- Prueba de unidad y cálculo de cobertura de código . Si la cobertura del código está por debajo de un valor umbral dado, lo más probable es que el servicio falle aún más: se implementará. Si está al borde de lo permisible, se asignará un coeficiente de "pesimismo" al servicio: luego, en ausencia de una mejora del indicador con el tiempo, el desarrollador recibirá una notificación de que no hay progreso por parte de las pruebas (y algo debe hacerse con esto).
- Consideración de las limitaciones de memoria y CPU . Principalmente escribimos microservicios en Golang y los ejecutamos en Kubernetes. A partir de aquí, hay una sutileza asociada con la peculiaridad del lenguaje Golang: de manera predeterminada, todos los núcleos de la máquina se usan al inicio, si no configura explícitamente la variable GOMAXPROCS y cuando se inician varios de estos servicios en la misma máquina, comienzan a competir por los recursos, interfiriendo entre sí. Los gráficos a continuación muestran cómo cambia el tiempo de ejecución si ejecuta la aplicación sin competencia y en la carrera por los recursos. (La fuente de los gráficos está aquí ).

Plazo de ejecución, menos es mejor. Máximo: 643 ms; Mínimo: 42 ms. Se puede hacer clic en la foto.
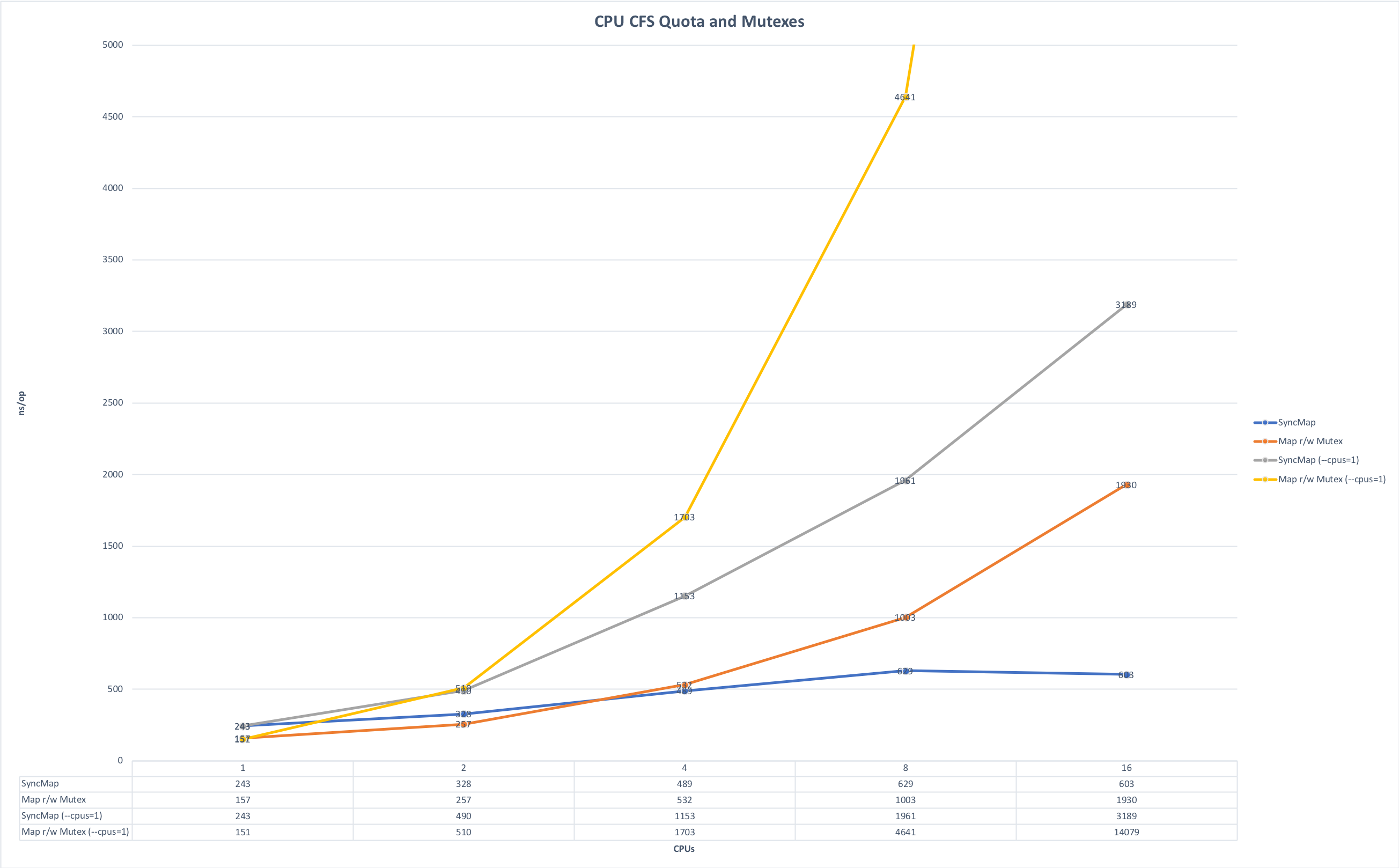
Tiempo para la cirugía, menos es mejor. Máximo: 14091 ns, Mínimo: 151 ns. Se puede hacer clic en la foto.
En la etapa de preparación del ensamblaje, puede establecer esta variable explícitamente o puede usar la biblioteca automaxprocs de los chicos de Uber.
Implementar
• Verificación de convenciones. Antes de comenzar a entregar ensamblados de servicios a los entornos previstos, debe verificar lo siguiente:
- Puntos finales API.
- Cumplimiento del esquema de puntos finales de respuestas API.
- Formato de registro.
- Configuración de encabezados para solicitudes de servicio (netramesh está haciendo esto ahora)
- Configuración del token del propietario al enviar mensajes al bus (bus de eventos). Esto es necesario para rastrear la conectividad de los servicios a través del bus. Puede enviar datos idempotentes al bus que no aumentan la conectividad de los servicios (lo cual es bueno), así como datos comerciales que mejoran la conectividad de los servicios (¡lo cual es muy malo!). Y en el momento en que esta conectividad se convierte en un problema, comprender quién escribe y lee el bus ayuda a dividir correctamente los servicios.
Si bien no hay muchas convenciones en Avito, su grupo se está expandiendo. Mientras más acuerdos de este tipo tengan la forma de un comando comprensible y conveniente, más fácil será mantener la coherencia entre los microservicios.
Pruebas sintéticas
• Prueba de circuito cerrado. Para él, ahora estamos utilizando el código abierto Hoverfly.io . Primero, registra la carga real en el servicio, luego, solo en un bucle cerrado, emula.
• Prueba de carga. Intentamos llevar todos los servicios a un rendimiento óptimo. Y todas las versiones de cada servicio deben someterse a pruebas de resistencia, para que podamos entender el rendimiento actual del servicio y la diferencia con versiones anteriores del mismo servicio. Si después de una actualización del servicio, su rendimiento se ha reducido una vez y media, esta es una señal clara para sus propietarios: debe profundizar en el código y solucionar la situación.
Nos basamos en los datos recopilados, por ejemplo, para implementar correctamente el escalado automático y, al final, generalmente entendemos cuán escalable es el servicio.
Durante las pruebas de resistencia, verificamos si el consumo de recursos cumple con los límites establecidos. Y nos centramos principalmente en los extremos.
a) Nos fijamos en la carga total.
- Demasiado pequeño: lo más probable es que algo no funcione si la carga cae repentinamente varias veces.
- Demasiado grande: se requiere optimización.
b) Nos fijamos en el límite por RPS.
Aquí nos fijamos en la diferencia entre la versión actual y la anterior y el número total. Por ejemplo, si un servicio produce 100 rps, entonces está mal escrito o es su especificidad, pero en cualquier caso, esta es una ocasión para mirar muy de cerca el servicio.
Si RPS, por el contrario, es demasiado, entonces quizás algún tipo de error y algunos de los puntos finales dejaron de realizar la carga útil, pero return true; activa algún tipo de return true;
Pruebas canarias
Después de que se pasan las pruebas sintéticas, ejecutamos el microservicio en un pequeño número de usuarios. Comenzamos con cuidado, con una pequeña fracción de la audiencia estimada del servicio, menos del 0.1%. En esta etapa, es muy importante que se establezcan las métricas técnicas y de producto correctas en el monitoreo para que muestren el problema en el servicio lo más rápido posible. El tiempo mínimo para una prueba canaria es de 5 minutos, el principal es de 2 horas. Para servicios complejos, configuramos la hora en modo manual.
Analizamos:
- métricas específicas del idioma, en particular los trabajadores php-fpm;
- errores en Centinela;
- estados de las respuestas;
- tiempo de respuesta (tiempo de respuesta), preciso y promedio;
- latencia;
- excepciones, procesadas y sin procesar;
- métricas alimentarias.
Prueba de compresión
La prueba de compresión también se llama prueba de extrusión. El nombre de la técnica se introdujo en Netflix. Su esencia es que al principio llenamos una instancia con tráfico real al estado de falla y, por lo tanto, establecemos su límite. Luego, agregue otra instancia y cargue esta pareja, nuevamente al máximo; vemos su techo y delta con el primer "apretón". Y entonces conectamos una instancia por paso y calculamos el patrón de cambios.
Los datos de prueba a través de "extrusión" también se agrupan en la base de datos de métricas generales, donde enriquecemos los resultados de la carga artificial con ellos o incluso los reemplazamos con "sintéticos".
Producción
• Escalado. Al extender el servicio a producción, hacemos un seguimiento de cómo se escala. En este caso, monitorear solo los indicadores de la CPU, en nuestra experiencia, es ineficiente. El escalado automático con la evaluación comparativa RPS en su forma pura funciona, pero solo para ciertos servicios, por ejemplo, la transmisión en línea. Por lo tanto, estamos analizando principalmente las métricas de productos específicos de la aplicación.
Como resultado, al escalar, analizamos:
- Indicadores de CPU y RAM,
- el número de solicitudes en la cola,
- tiempo de respuesta
- pronóstico basado en datos históricos.
Al escalar un servicio, también es importante controlar sus dependencias para que no resulte que somos el primer servicio en la cadena de escalado, y aquellos a los que se refiere están bajo carga. Para establecer una carga aceptable para todo el conjunto de servicios, observamos los datos históricos del servicio dependiente "más cercano" (basado en una combinación de CPU y RAM y métricas específicas de la aplicación) y los comparamos con los datos históricos del servicio de inicialización, y así sucesivamente a lo largo de toda la "cadena de dependencia" ", De arriba a abajo.
Servicio
Una vez que se pone en funcionamiento el microservicio, podemos colgar los activadores en él.
Aquí hay situaciones típicas en las que se dispara el fuego.
- Migraciones potencialmente peligrosas detectadas.
- Se han lanzado actualizaciones de seguridad.
- El servicio en sí no se ha actualizado durante mucho tiempo.
- La carga en el servicio ha disminuido significativamente o cualquiera de sus métricas de producto está más allá del rango normal.
- El servicio ha dejado de cumplir con los requisitos de la nueva plataforma.
Algunos de los desencadenantes son responsables de la estabilidad del trabajo, algunos en función del servicio del sistema; por ejemplo, algunos servicios no se han implementado durante mucho tiempo y su imagen básica ha dejado de pasar los controles de seguridad.
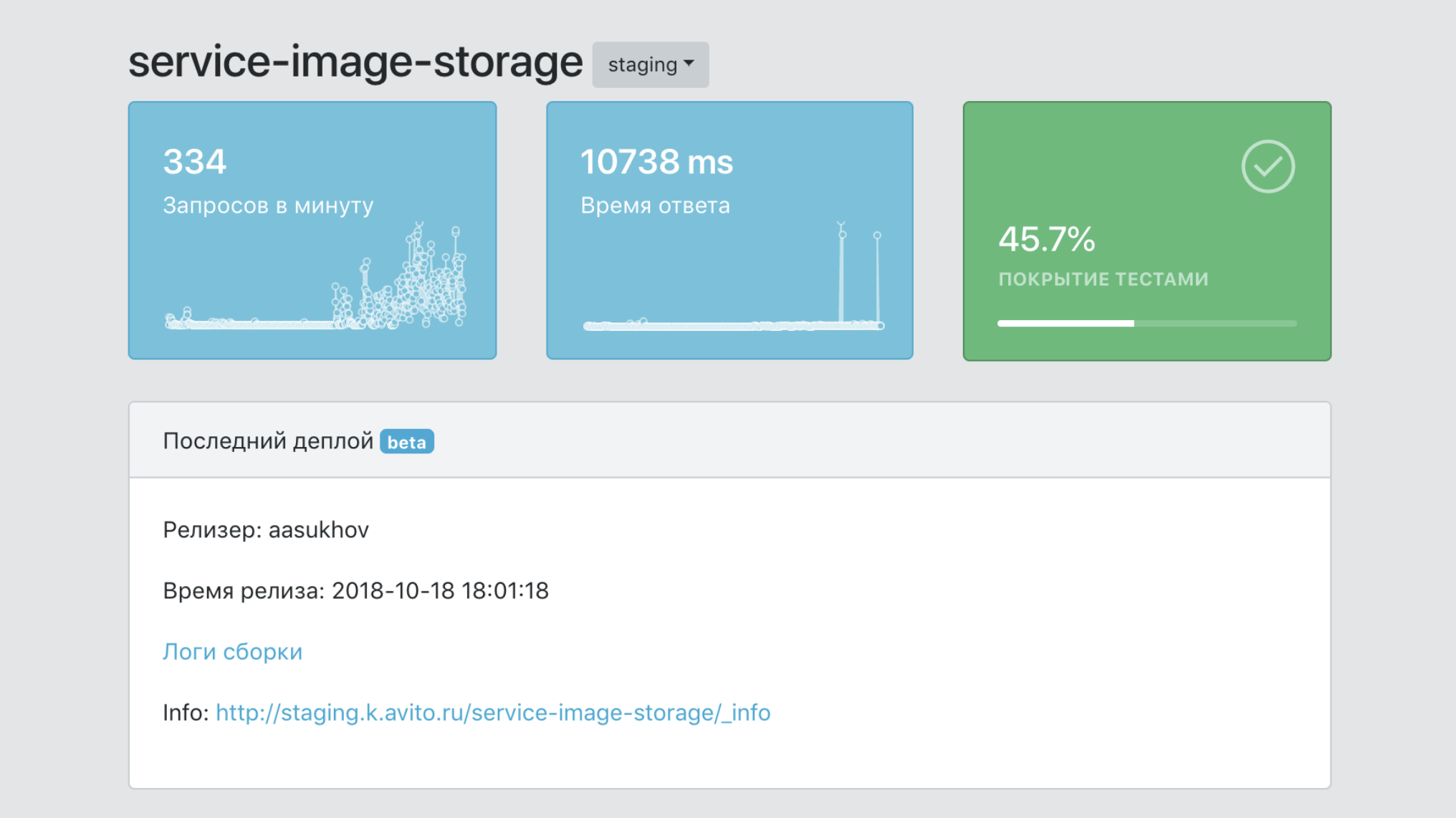
Tablero de instrumentos
En resumen, el tablero es el panel de control de todo nuestro PaaS.
- Un único punto de información sobre un servicio, con datos sobre su cobertura con pruebas, el número de sus imágenes, el número de copias de producción, versiones, etc.
- Una herramienta para filtrar datos por servicios y etiquetas (marcadores de pertenencia a unidades de negocio, funcionalidad del producto, etc.)
- Medios de integración con herramientas de infraestructura para rastreo, registro, monitoreo.
- Un único punto de documentación de servicio.
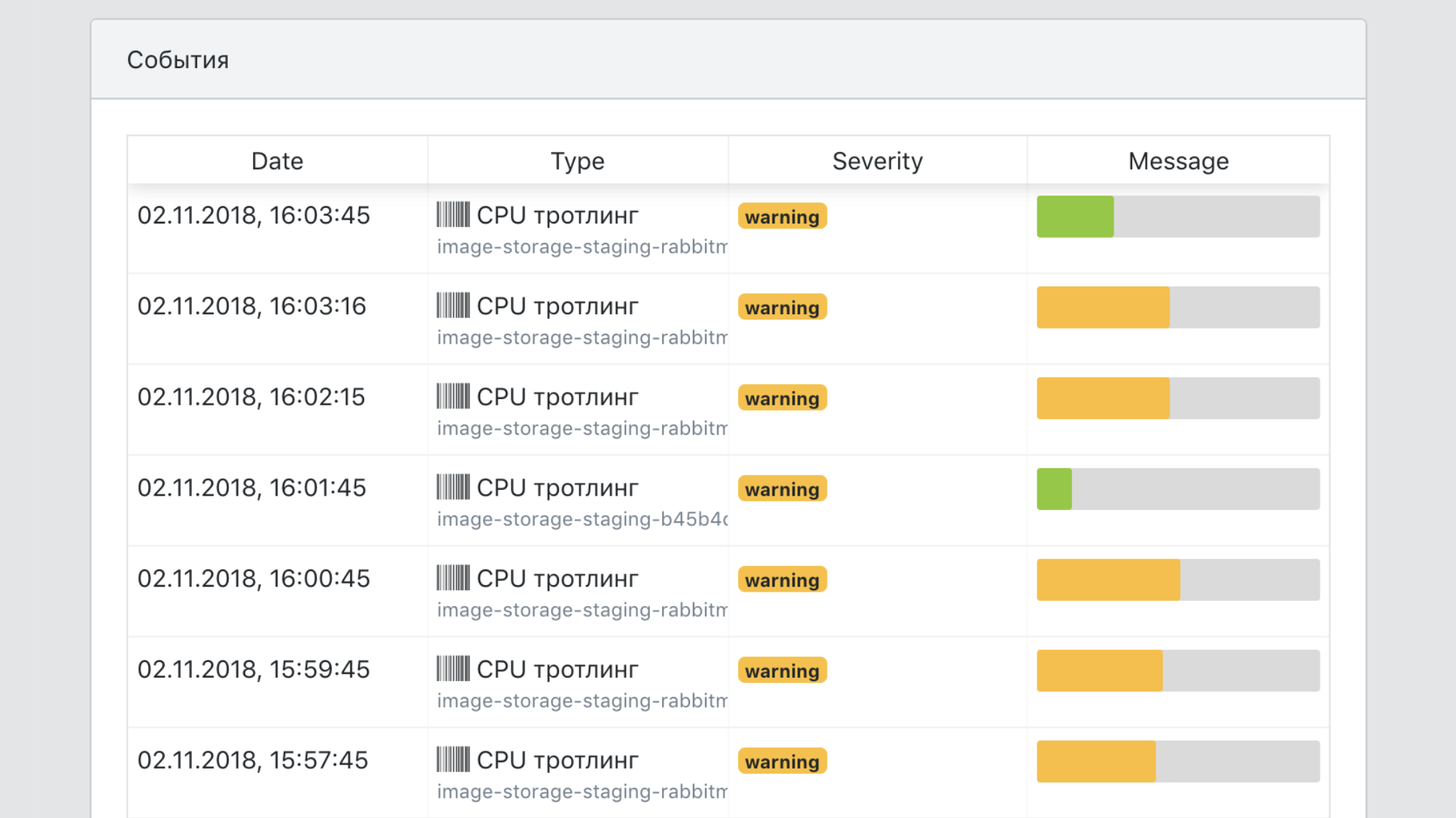
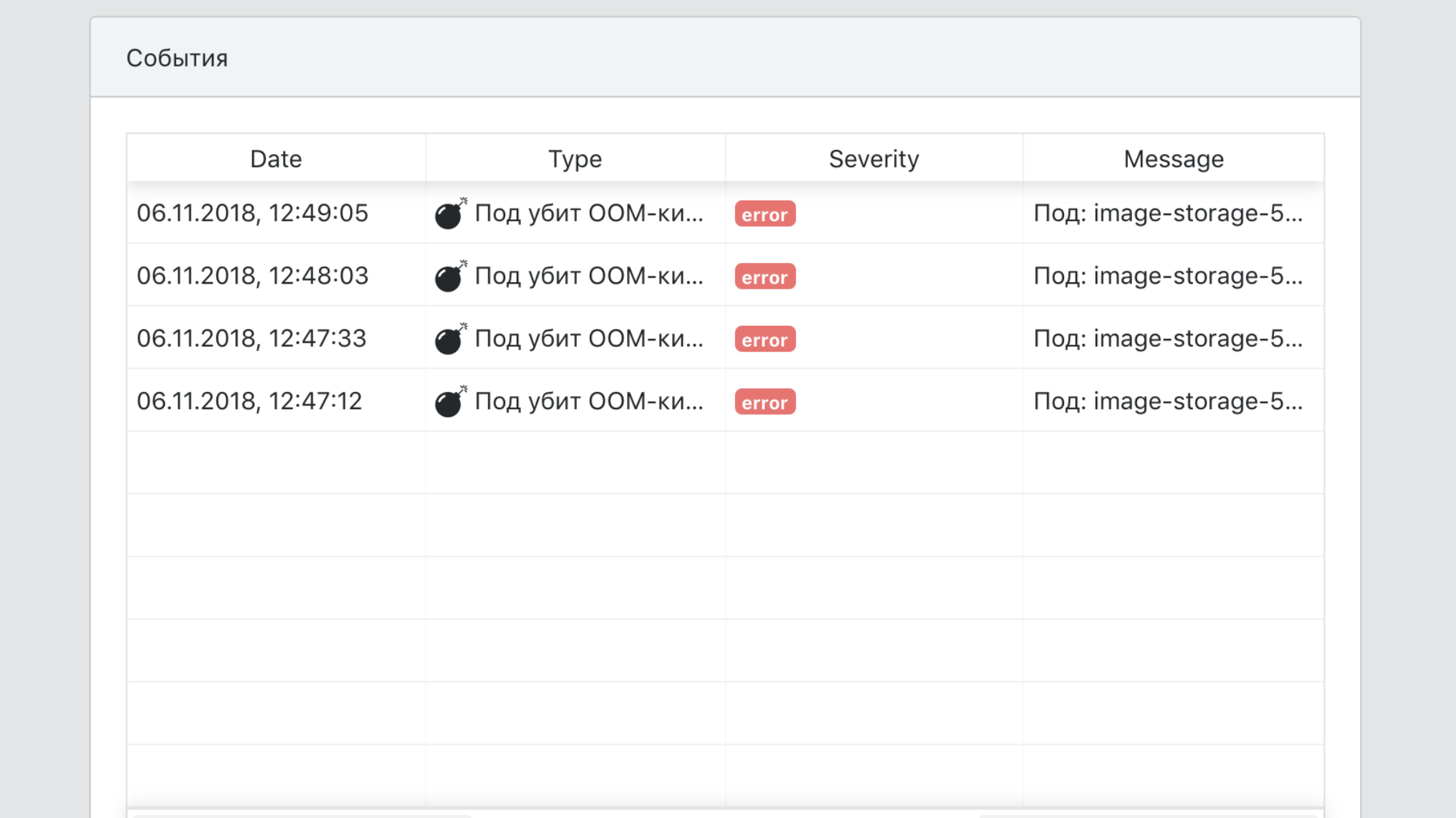
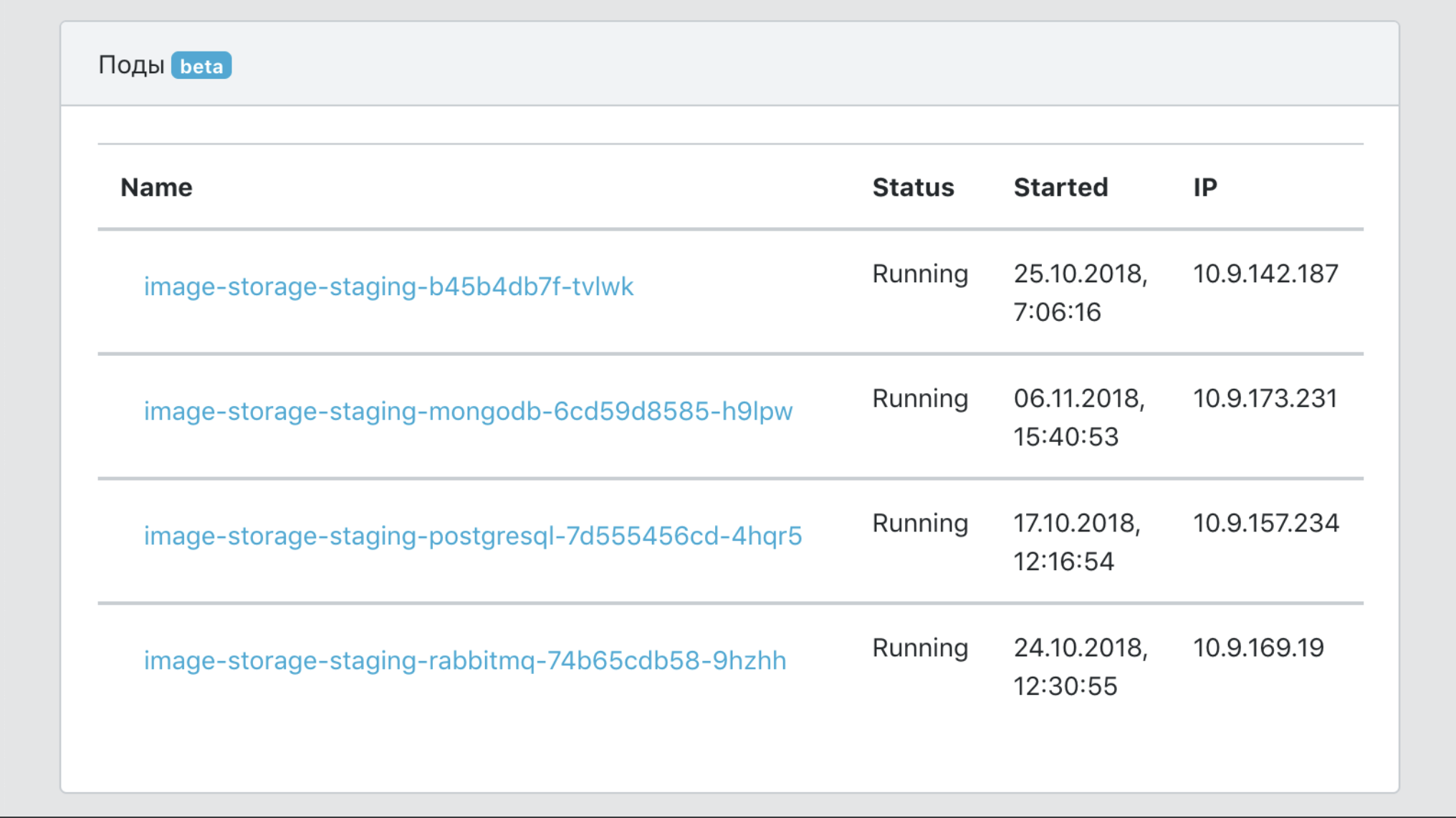
- Un único punto de vista de todos los eventos de servicio.
Total
Antes de la introducción de PaaS, un nuevo desarrollador podría pasar varias semanas clasificando todas las herramientas necesarias para lanzar un microservicio en producción: Kubernetes, Helm, nuestras características internas de TeamCity, configurando la conexión a bases de datos y cachés en una forma tolerante a fallas, etc. Ahora toma un par de horas leer el inicio rápido y hacer el servicio en sí.
Hice un informe sobre este tema para HighLoad ++ 2018, puede ver el video y la presentación .
Bonus track para aquellos que han leído hasta el final
Nosotros en Avito organizaremos una capacitación interna de tres días para desarrolladores de Chris Richardson , un experto en arquitectura de microservicios. Queremos darle la oportunidad de participar en él a uno de los lectores de esta publicación. Aquí hay un programa de entrenamiento.
La capacitación se realizará del 5 al 7 de agosto en Moscú. Estos son días hábiles que estarán completamente ocupados. El almuerzo y la capacitación serán en nuestra oficina, y el participante elegido pagará el viaje y el alojamiento.
Puede solicitar la participación en este formulario de Google . De usted: la respuesta a la pregunta de por qué exactamente necesita asistir a la capacitación e información sobre cómo contactarlo. Responda en inglés, porque Chris elegirá al participante que llegue a la capacitación.
Anunciaremos el nombre del participante del entrenamiento como una actualización de esta publicación en las redes sociales de Avito para desarrolladores (AvitoTech en Facebook , Vkontakte , Twitter ) a más tardar el 19 de julio.
UPD, 19/07: Recibimos docenas de solicitudes. Chris los examinó y eligió un participante: junto con nuestros colegas, Andrei Igumnov irá a estudiar. Felicidades