Hola a todos Mi equipo en Tinkoff está construyendo sistemas de recomendación. Si está satisfecho con su reembolso mensual, entonces este es nuestro negocio. También creamos un sistema de recomendación de ofertas especiales de socios y participamos en colecciones individuales de Historias en la aplicación Tinkoff. Y nos encanta participar en concursos de aprendizaje automático para mantenernos en buena forma.
En Boosters.pro durante dos meses, del 18 de febrero al 18 de abril, se realizó un concurso para construir un sistema de recomendación sobre datos reales de uno de los cines en línea más grandes de Rusia, Okko . Los organizadores tenían como objetivo mejorar el sistema de recomendación existente. Por el momento, la competencia está disponible en modo sandbox , en el que puede probar sus enfoques y perfeccionar sus habilidades en la construcción de sistemas de recomendación.
Descripción de datos
El acceso al contenido en Okko se realiza a través de la aplicación en el televisor o teléfono inteligente, o mediante la interfaz web. El contenido se puede alquilar®, comprar (P) o ver por suscripción (S). El organizador de la competencia proporcionó datos sobre las vistas durante N días (N> 60), además, la información sobre las calificaciones y los marcadores agregados estaba disponible. Vale la pena tener en cuenta un detalle importante, si el usuario vio una película varias veces o varios episodios de la serie, solo se registrará en la tableta la fecha de la última transacción y el tiempo total empleado por unidad de contenido.
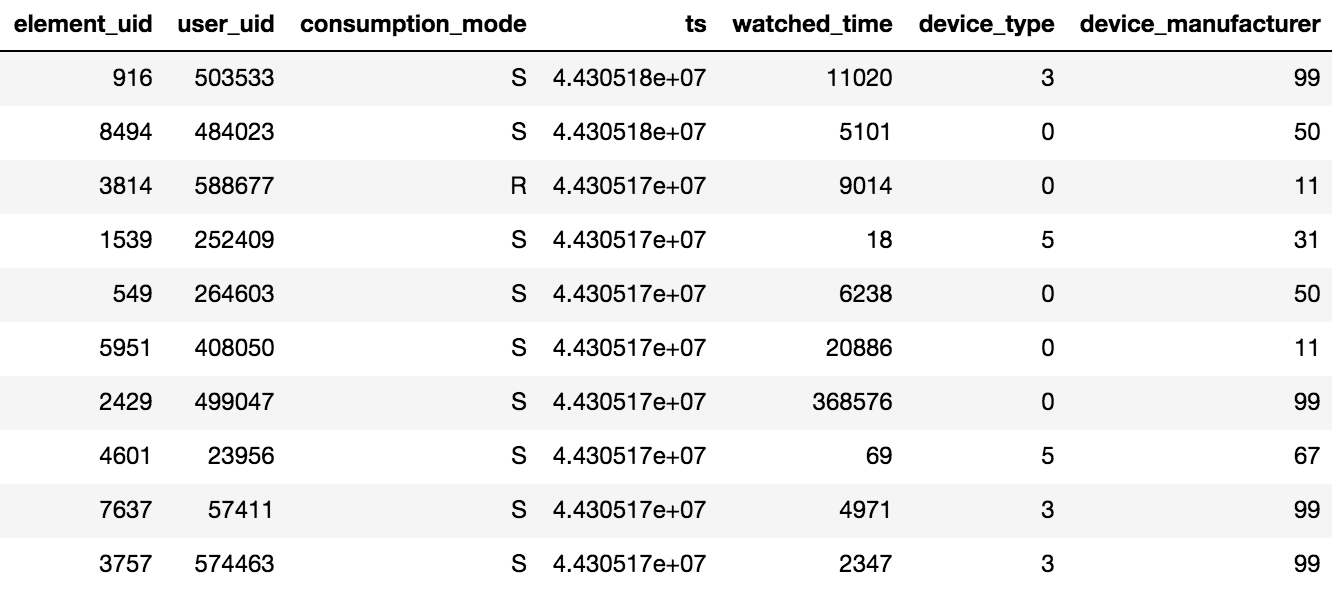
Se proporcionaron alrededor de 10 millones de transacciones, 450 mil calificaciones y 950 mil marcadores para 500 mil usuarios.
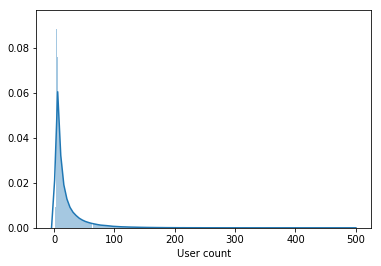
La muestra contiene no solo usuarios activos, sino también usuarios que han visto un par de películas durante todo el período.
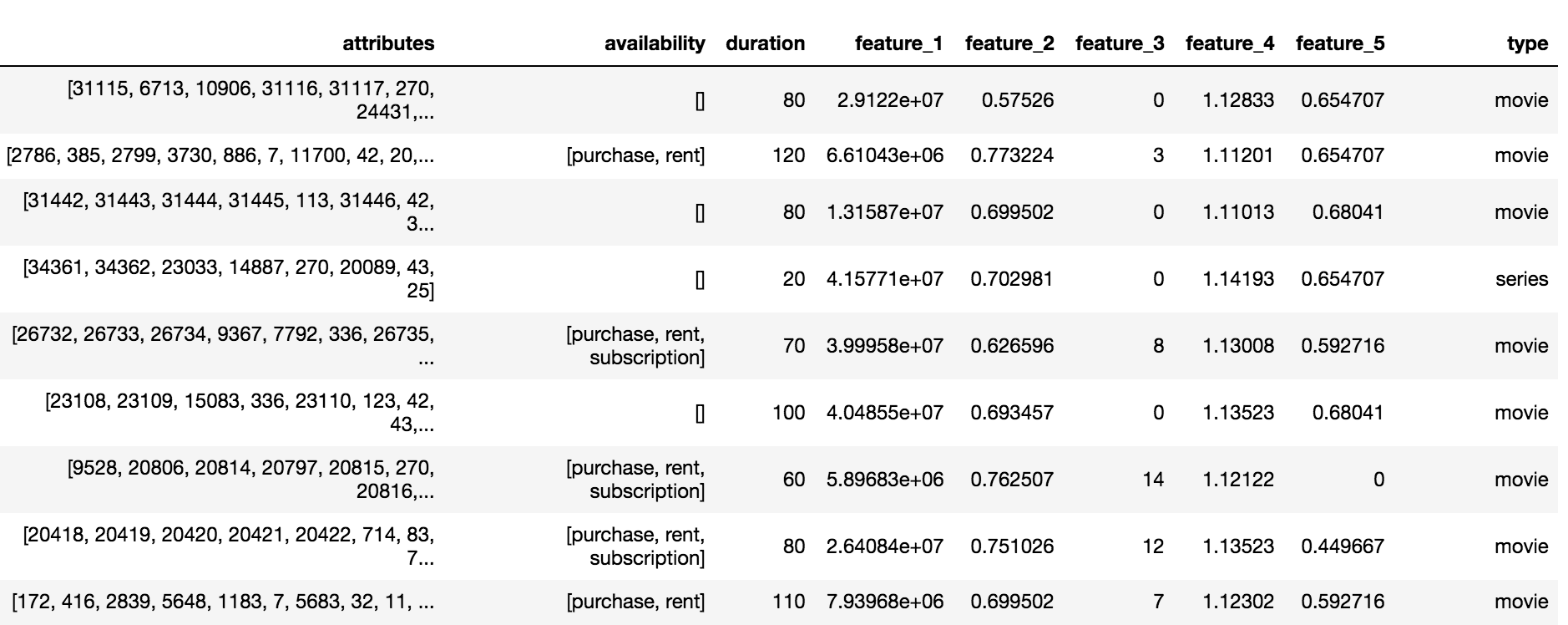
El catálogo de Okko contiene tres tipos de contenido: películas (películas), series (series) y películas en serie (película multiparte), un total de 10.200 objetos. Para cada objeto, estaba disponible un conjunto de atributos y atributos anónimos (característica_1, ..., característica_5), disponibilidad de suscripción, alquiler o compra y duración.
Variable objetivo y métrica
La tarea requería predecir una gran cantidad de contenido que el usuario consumiría en los próximos 60 días. Se cree que un usuario consumirá contenido si él:
- Cómpralo o alquilalo
- Mira más de la mitad de la película por suscripción
- Mire más de un tercio de la serie por suscripción
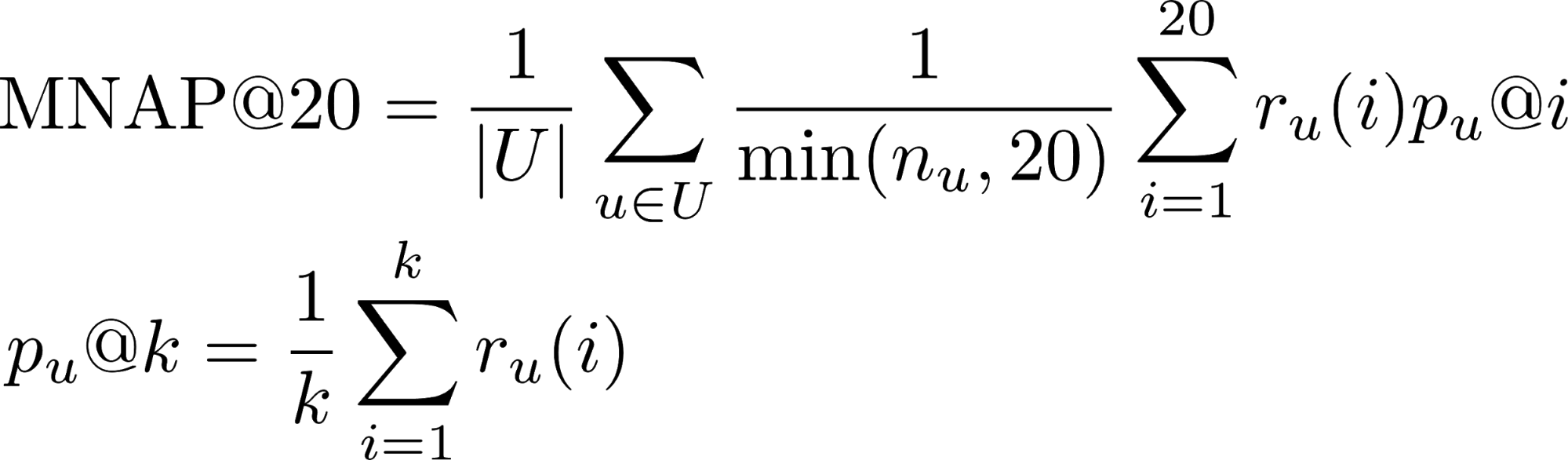
- r_u (i) : si el usuario u consumió el contenido predicho para él en el lugar i (1 o 0)
- n_u : la cantidad de elementos que el usuario consumió durante el período de prueba
- U : muchos usuarios de prueba
Puede obtener más información sobre las métricas para la tarea de clasificación en esta publicación .
La mayoría de los usuarios ven películas hasta el final, por lo que la proporción de la clase positiva en las transacciones es del 65%. La calidad del algoritmo se evaluó utilizando un subconjunto de 50 mil usuarios de la muestra presentada.
Calificación agregada
La decisión de la competencia comenzó con la agregación de todas las interacciones de los usuarios con el contenido en una sola escala de calificación. Se suponía que si el usuario compraba el contenido, esto significaba el máximo interés. La película es más corta que la serie, por lo tanto, para ver la serie en su conjunto, debe dar más puntos. Como resultado, la calificación agregada se formó de acuerdo con las siguientes reglas:
- Compartir película * 5
- Programa de TV Compartir * 10
- [Marcando la película] * 0.5
- [Marcando la serie] * 1.5
- [Compra / alquiler de contenido] * 15
- Calificación + 2
Modelo de primer nivel
Los organizadores proporcionaron una solución básica basada en el filtrado colaborativo con escalas Tf-IDF. Al agregar todo tipo de interacciones a la calificación agregada, aumentar el número de vecinos más cercanos de 20 a 150 y reemplazar Tf-IDF con pesos BM25 eliminó aproximadamente 0.03 en LB (Tabla de líderes).
Inspirado por la publicación del equipo que ocupó el tercer lugar en el RecSys Challenge 2018 , elegí el modelo LightFM con pérdida WARP como el segundo modelo base. LightFM con hiperparámetros seleccionados: learning_rate, no_components, item_alpha, user_alpha, max_sampled dio 0.033 en LB.

La validación del modelo se realizó a tiempo: el primer 80% de las interacciones cayeron en el tren, el 20% restante en la validación. Para una presentación sobre LB, se entrenó un modelo en todo el conjunto de datos con parámetros seleccionados para la validación.
Mezcla de modelos
En la etapa anterior, resultó construir dos líneas de base sólidas, además, sus recomendaciones se cruzaron en promedio para el 60 por ciento del contenido recomendado. Si hay dos modelos fuertes y al mismo tiempo débilmente correlacionados, entonces su combinación es un paso razonable.
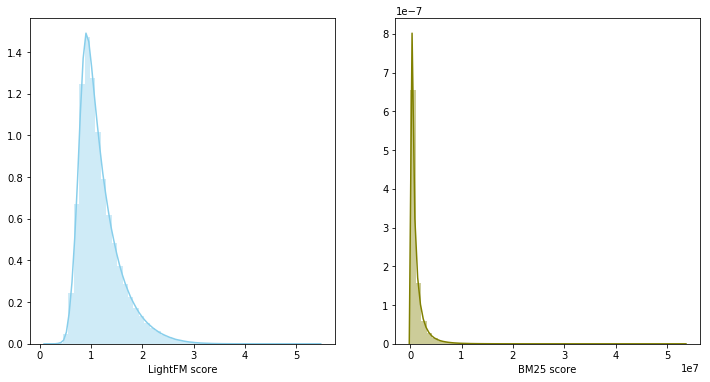
En este caso, los puntajes del modelo pertenecen a diferentes distribuciones y tienen diferentes escalas, por lo que se decidió utilizar la suma de los rangos para combinar los dos modelos. La combinación de modelos produjo 0.0347 en LB.

Modelo de segundo nivel
Los sistemas de recomendación a menudo usan un enfoque de dos niveles para construir modelos: primero, los candidatos principales se seleccionan mediante un modelo simple de primer nivel, luego el superior seleccionado se vuelve a clasificar por un modelo más complejo con la adición de una gran cantidad de características.

El conjunto de datos se dividió en el tiempo en las partes de capacitación y validación. Se recopiló una selección de recomendaciones para la parte de validación para cada usuario, que consiste en combinar las predicciones top200 de modelos de primer nivel con la excepción de las películas ya vistas. Además, se requería enseñar al modelo a reorganizar la parte superior resultante para cada usuario. El problema fue formulado en términos de clasificación binaria. Un par (usuario, contenido) pertenecía a la clase positiva solo si el usuario consumió el contenido durante el período de validación. Como modelo de segundo nivel, se utilizó el aumento de gradiente, es decir, el paquete LightGBM.
Signos
Los modelos de primer nivel para pares (usuario, contenido) evalúan la relevancia en forma de velocidad, clasificando en orden decreciente para obtener un rango. El modelo entrenado en los signos de rango y velocidad, junto con los signos del catálogo de contenido, noqueó 0.0359 en LB.
A partir de la forma de distribución de la primera de las características anónimas, se concluyó que es la fecha en que apareció la película en el catálogo, por lo tanto, el modelo fue fuertemente reentrenado para esta característica con el esquema de validación seleccionado. La eliminación de una característica de la muestra dio un aumento en LB a 0.0367
El modelo LightFM, además de predecir la relevancia del contenido para el usuario, devuelve dos vectores: sesgo del elemento y sesgo del usuario, que se correlacionan con el grado de popularidad del contenido y el número de películas vistas por el usuario, respectivamente. Agregar signos aumentó la velocidad en LB a 0.0388 .
Puede asignar un rango para un par (usuario, contenido) antes o después de eliminar películas ya vistas. Los cambios en el método a este último proporcionaron un aumento en LB a 0.0395 .
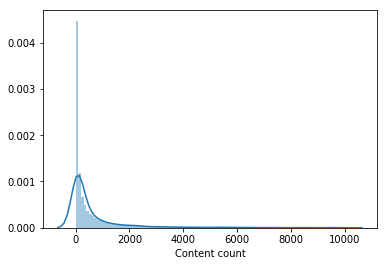
Casi nadie vio una parte significativa del catálogo de películas. El contenido que vieron menos de 100 usuarios se eliminó de la muestra para capacitar a un modelo de segundo nivel, lo que redujo el catálogo a la mitad. La eliminación de contenido impopular hizo que la selección de los modelos de primer nivel fuera más relevante y solo después de eso el vector de usuarios de LightFM mejoró la velocidad de validación y aumentó LB a 0.0429 .
Además, se agregó una señal: el usuario agregó el marcador al libro, pero no miró el período del tren, lo que aumentó la velocidad en LB a 0.0447 . Además, se agregaron signos sobre la fecha de la primera y última transacción, aumentaron la velocidad a 0.0457 en LB.

Consideraremos este modelo final. Los más significativos fueron los signos de los modelos de primer nivel y los signos anónimos del catálogo de contenido.
Las siguientes características no aumentaron al modelo final:
- cantidad de marcadores + parte del contenido visto de los marcadores - 0.0453 LB
- la cantidad de películas compradas 0.0451 LB
Pero cuando se mezclaron con el modelo final, noquearon 0.0465 en LB. Inspirados por el resultado de la mezcla, los siguientes modelos fueron entrenados por separado:
- con diferentes fracciones de la muestra de entrenamiento para el modelo de primer nivel. La división del 90% / 10% dio un aumento, en contraste con la división del 95% / 5% y 70% / 30%.
- con un método de agregación de calificación modificado.
- con la adición de películas impopulares al conjunto de entrenamiento para un modelo de segundo nivel. Para cada unidad de contenido, se compiló una compilación de 1000 usuarios.
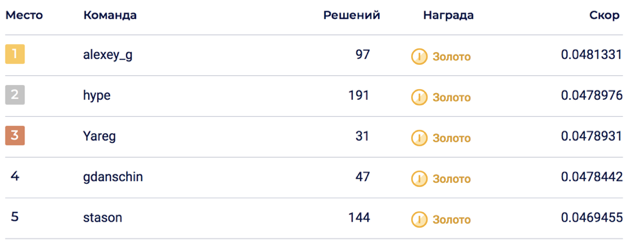
La combinación final de 6 modelos permitió alcanzar 0.0469678 en LB, que correspondía al quinto lugar.

En la parte privada, ocurrió una sacudida, que arrojó la solución al segundo lugar. Creo que la solución resultó ser sostenible gracias a la combinación de una gran cantidad de modelos.
No ingresado
En el proceso de resolver la competencia, se generaron muchos signos que parecían entrar definitivamente, pero lamentablemente. Señales y enfoques de mayor confianza:
- Atributos de contenido anónimo. No se sabía con certeza qué contenían, pero todos los participantes en el concurso creían que contenían información sobre actores, directores, compositores ... En mi decisión, traté de agregarlos en varios formatos: los más populares como caracteres binarios, trazaron la matriz de contenido atributos usando LightFM y BigARTM, y luego extraiga los vectores y agréguelos al modelo de segundo nivel.
- Vectores de contenido del modelo LigthFM en el modelo de segundo nivel.
- Atributos de los dispositivos desde los cuales el usuario vio el contenido.
- Bajar el peso del contenido popular para un modelo de segundo nivel.
- La proporción de películas / programas de televisión en relación con el número total de contenido visto.
- Clasificación de métricas de CatBoost.
Datos interesantes sobre la competencia.
- La solución Top1 resultó ser peor que el modelo de producto okko 0.048 vs 0.062. Debe tenerse en cuenta que el modelo del producto ya se lanzó al momento del muestreo.
- Aproximadamente una semana después del comienzo de la competencia, se modificó el conjunto de datos, para aquellos que participaron desde el principio agregaron 30 presentaciones, que se quemaron inesperadamente después de que los equipos se fusionaron.
- La validación no siempre se correlacionó con LB, lo que indicaba una posible sacudida.
Código de decisión
La solución está disponible en github en forma de dos computadoras portátiles jupyter: agregación de clasificación, modelos de capacitación del primer y segundo nivel.
Una solución de tercer lugar también está disponible en github .
La decisión de los organizadores.
En lugar de mil palabras, adjunto las principales características de los organizadores.
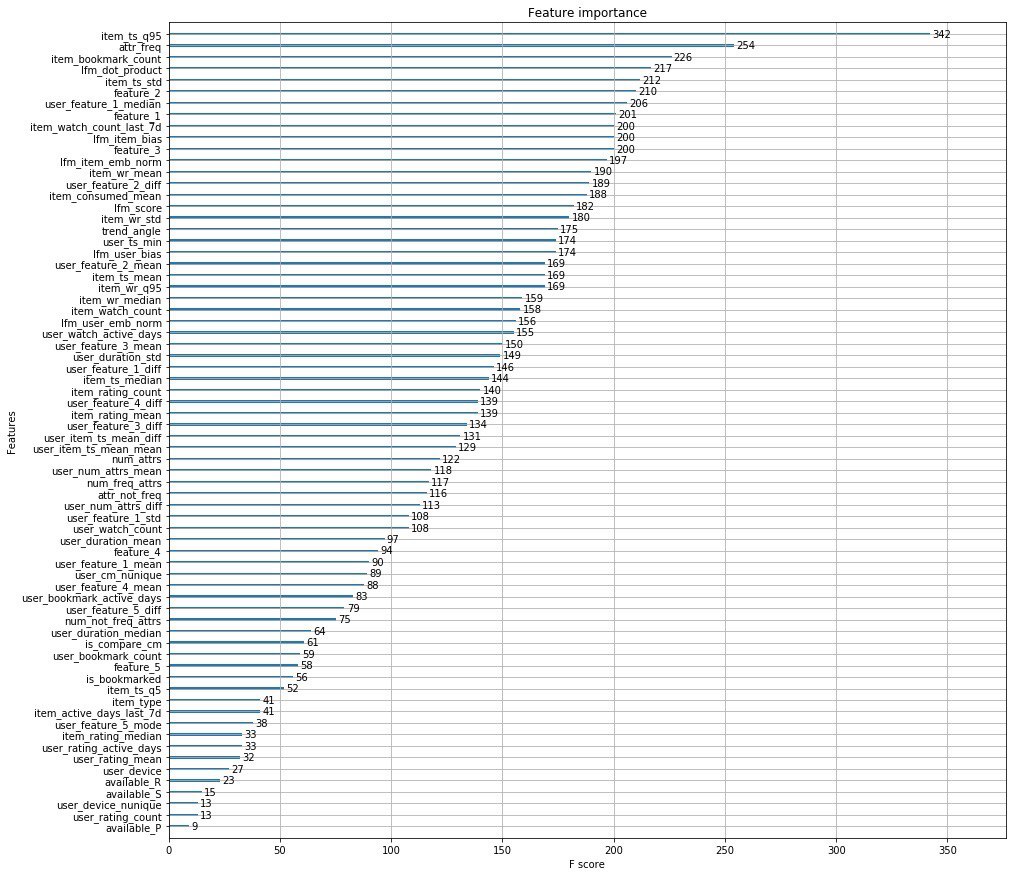
Además, los chicos de Okko publicaron un artículo en el que hablan sobre las etapas de desarrollo de su motor de recomendación.
PD: aquí puede ver el rendimiento en Data Fest 6 sobre esta solución al problema.