
Si alguno de sus proyectos usa los datos almacenados en la base de datos de Azhurov, es muy posible que tenga la oportunidad de usar la búsqueda de datos mediante la búsqueda de Azure. Puede buscar no solo por bases de datos (Azure Cosmos DB, Azure SQL Database, SQL Server alojada en una máquina virtual de Azure), sino también por Blob (Azure Blob Storage, Azure Table Storage).
La búsqueda tiene una tarifa gratuita, que le permite crear hasta tres índices con un tamaño total de hasta 50 Mb. La tarifa gratuita no tiene capacidades de equilibrio de carga, pero es bastante adecuada para su uso.
Tratar con la búsqueda me pareció bastante simple (aunque no siempre es obvio). Hay 3 tipos de objetos: fuente de datos, índice e indexador. El objeto principal, tal vez, es el índice. Es él quien es responsable de cómo buscar y qué buscar exactamente. Datasource es una conexión de datos, y el indexador es un trabajo que actualiza los datos del índice.
La interfaz de usuario del portal le permite importar datos y crear los tres objetos. La oportunidad pasará y agregará capacidades cognitivas a la búsqueda. Si la base de datos SQL está en la suscripción, puede seleccionarla al crear la fuente de datos. Aunque la contraseña por alguna razón, todavía tiene que ingresar. Si desea usar Cosmos DB, deberá ingresar la cadena de conexión manualmente. No olvide indicar en la línea y en la base de datos, agregando al final de la línea Base de datos = YOUR_BASE_NAME
Después de elegir una fuente de datos, se le pedirá que use capacidades de búsqueda cognitiva. El conjunto de habilidades predeterminadas aún es bastante pequeño: puede definir el idioma, extraer nombres, nombres de organizaciones, lugares y frases clave. También hay una oportunidad interesante para determinar la naturaleza del texto para las emociones positivas o negativas mediante la detección de sentimientos. Esta habilidad debería ser conveniente para usar con reseñas de productos en tiendas en línea. Es posible crear su propia habilidad usando la descripción de la API.
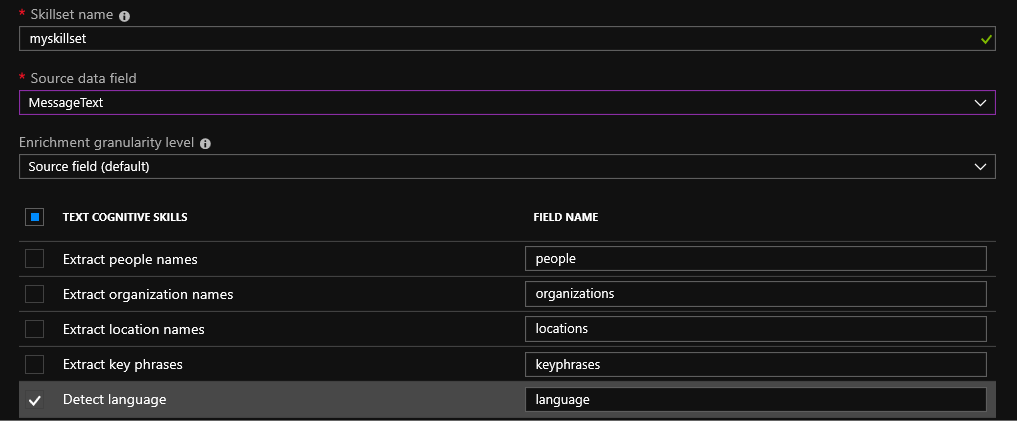
Para los archivos cargados en blob, es posible el reconocimiento óptico de caracteres (OCR). Es posible el reconocimiento de textos escritos a mano (hasta ahora solo en inglés) e impresos. Usando servicios cognitivos, es posible identificar varios objetos en la foto. Por ejemplo, lugares famosos o celebridades.
El siguiente paso es crear un índice. La única opción para el modo de búsqueda de este día es "analysisInfixMatching"
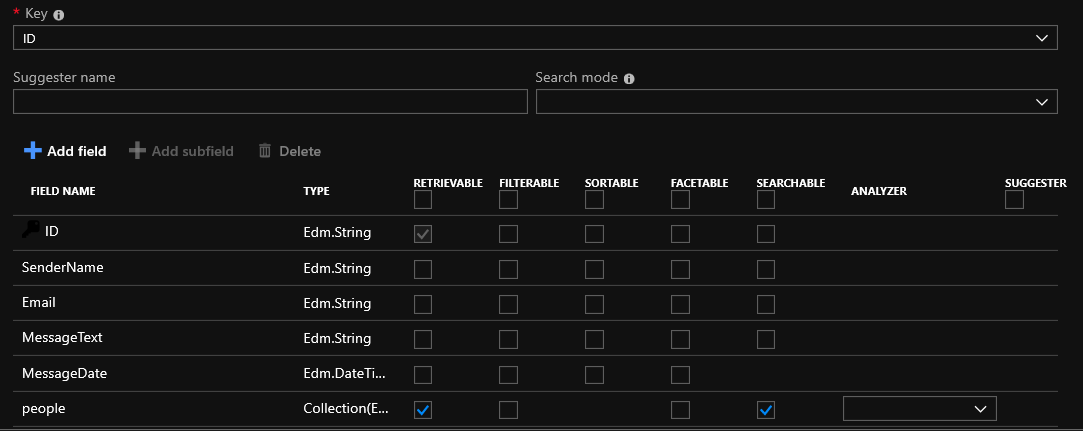
En este punto, puede marcar las casillas junto a los campos en su tabla o agregar algún campo nuevo al índice. Por si acaso, explicaré las posibilidades de los campos:
Recuperable : el campo estará presente en los resultados de búsqueda
Filtrable : el valor del campo se puede filtrar
Seleccionable : puede ordenar el resultado por este campo
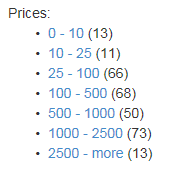
Facetable : un tipo de agrupación de acuerdo con ciertas características. Por ejemplo, utilizando la siguiente expresión facet = listPrice, valores: 10 | 25 | 100 | 500 | 1000 | 2500, puede obtener el siguiente desglose de los resultados en grupos
Se puede buscar: este campo buscará
El campo Analizador sugiere elegir un analizador para varios idiomas. Se utilizan 2 versiones: Lucene y Microsoft . Para comprender cuál es la diferencia, debe comprender cuál es la diferencia entre los dos términos siguientes:
La tartamudez es el proceso de encontrar la base de una palabra para una palabra fuente dada. Tallo (inglés) - tallo, tallo, origen. Stemming usa algoritmos. A menudo trunca las palabras eliminando sufijos y terminaciones, obteniendo la base de la palabra.
La lematización es el proceso de reducir una forma de palabra a lema, su forma normal (vocabulario). El lema es la forma canónica, básica de la palabra. La lematización utiliza una búsqueda en el diccionario que contiene varias formas de palabras.
El analizador Lucene utiliza stemming. El analizador de Microsoft usa lematización.
Por defecto, si no se selecciona nada, se usa Lucene. Pero si está buscando datos en un idioma en particular, sin duda es mejor usar un analizador para este idioma.
Suggester : le permite dar pistas con documentos que contienen el texto ingresado utilizando las letras iniciales de la búsqueda.
Si está usando el probador en Azure Search en la aplicación cliente, tendrá 2 opciones para usarlo: el propio contador o el autocompletado . En resumen, el mensaje sugiere completamente la fila completa del campo de la tabla, y el autocompletado solo ofrece completar una palabra o expresión de un par de palabras. El mejor artículo sobre las diferencias entre las indicaciones y los modos de autocompletar se describe en el siguiente artículo: Autocompletar en Azure Buscar ahora en vista previa pública Este artículo tiene gifs muy visuales.
En la etapa de creación del indexador, debe especificar una columna de marca de agua alta . Este es un campo que cambia cada vez que se cambia un registro. Por lo general, esto es algo así como un campo con la fecha del último cambio o un campo _ts en Cosmos DB. Durante la indexación, si se cambia el valor del campo, el índice también cambiará.
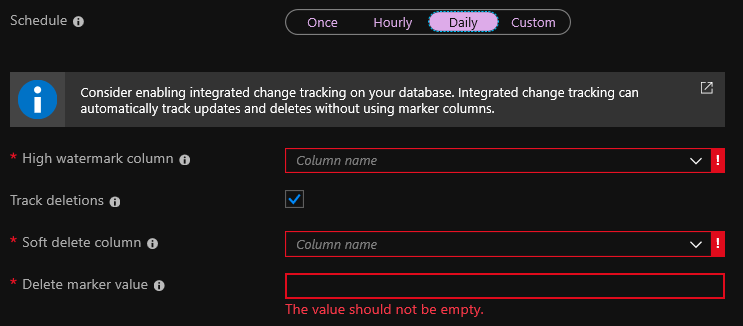
El seguimiento de eliminaciones es una opción para eliminar entradas del índice automáticamente. Pero para esto, debe tener una eliminación suave configurada en su base de datos. Si usa la eliminación suave, cuando elimina un registro, no se elimina, sino que simplemente se marca como eliminado. La opción estándar es agregar el campo isDeleted a la base de datos y establecerlo en verdadero si se elimina el registro.
Alternativamente, cada vez que elimine una entrada de la base de datos, puede enviar una solicitud de eliminación de la búsqueda a la API de Azure Search. En este caso, se puede omitir la casilla de verificación Eliminaciones de Trak. Pero realmente no me gusta esta opción, porque si la solicitud de eliminación no funciona, el registro permanecerá en el índice. En cuanto a mí, no hay suficientes oportunidades para reconstruir el índice una vez en un cierto período de tiempo por completo.
A pesar de todas las ventajas del portal, después de crearlo puede agregar algunos campos nuevos al índice, pero no puede cambiar los existentes. ¿Qué hacer si necesitas cambiar algo? Puedes recrear el índice. Elimine el existente y cree uno nuevo que contenga los cambios necesarios. Usar el portal para hacer esto es una tarea bastante triste. Yo uso la API para estos fines. Usando una aplicación como Postman, puede obtener el índice JSON y usarlo para escribir una solicitud de creación de índice. Solo es necesario realizar pequeños cambios (por ejemplo, elimine los campos del sistema "@ odata.context" y "@ odata.etag").
Para trabajar con la API, debe tomar la clave del portal, que debe agregarse al encabezado de cada solicitud de API. La clave se toma aquí:
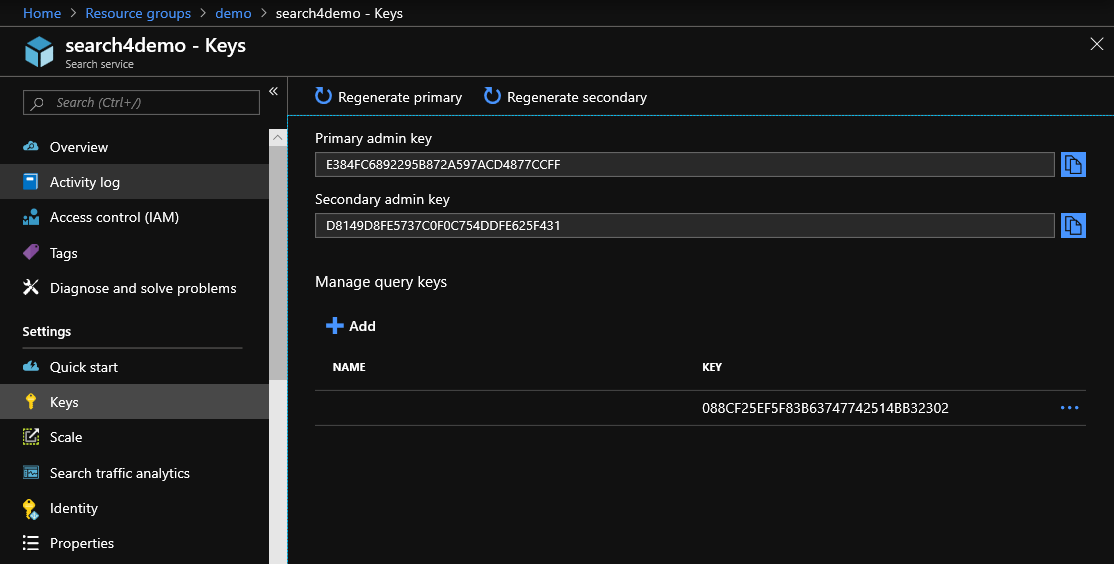
Una consulta para obtener datos de índice es:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
api-key: [admin key] debe agregarse al encabezado api-key: [admin key]
Es posible crear un índice utilizando una de las siguientes dos consultas:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
o
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
En cuerpo, debe especificar JSON con el contenido del índice. La última versión en este momento es 2019-05-06, y antes de que se usara durante mucho tiempo 2017-11-11
Trabajando a través de la API, puede usar algunas funciones de búsqueda que no están disponibles en el portal.
Para dar prioridad a algunos campos en la búsqueda, puede usar perfiles de puntuación .
El siguiente JSON agregado a la solicitud le da al campo "título" una doble ventaja sobre el campo "información":
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
Además de la capacidad de dar prioridad a algunos campos usando pesos, es posible usar algunas funciones predefinidas: frescura, magnitud, distancia y etiqueta.
La frescura se usa solo con los campos de fecha y hora y le permite mostrar los últimos registros en la búsqueda. La magnitud se usa con los campos int y double. Bueno, y en consecuencia, esta función es buena para usar con campos que almacenan precios, la cantidad de descargas y otra información numérica. La distancia se usa solo con campos como Edm.GeographyPoint y se eleva en una búsqueda por distancia desde una ubicación específica. Si la etiqueta se especifica como el tipo de función, los documentos que contienen etiquetas que aparecen en la cadena de búsqueda aparecerán en la búsqueda.
Una de las opciones más populares es recoger los últimos documentos en una búsqueda como esta:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Se mostrarán los documentos cuyo campo documentDate contiene la fecha de los últimos siete días ("P7D").
Después de haber creado un perfil de puntuación, puede especificar su nombre en las solicitudes. Solo en este caso se generarán los campos necesarios en la búsqueda.
Lea más en la documentación oficial: Agregue perfiles de puntuación a un índice de Azure Search
Política de detección de cambio de datos
La API proporciona un poco más de funciones para la fuente de datos. Como puede leer arriba, al crear un origen de datos, puede especificar un campo para determinar si los datos han cambiado. En forma de JSON, se ve así:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } soft delete policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Si utiliza SQL Server y su base de datos admite el seguimiento de cambios, los registros eliminados se pueden eliminar del índice automáticamente. No es necesario especificar highWaterMarkColumnName en este caso. Es suficiente especificar SqlIntegratedChangeTrackingPolicy en lugar de HighWaterMarkChangeDetectionPolicy
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
Es muy conveniente. Pero hay matices que no permiten disfrutar esta característica por completo.
Primero, SqlIntegratedChangeTrackingPolicy no se puede usar con vistas. En segundo lugar, la tabla no debe tener claves primarias compuestas. No hace falta decir que la versión de SQL Server debe ser más o menos nueva. Y finalmente, el seguimiento de cambios debe estar habilitado para la base de datos y las tablas utilizadas por la búsqueda. Para la base de datos, se activa así:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
Y para la mesa como esta:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Pero eso no es todo. Se recomienda encarecidamente que habilite el aislamiento de instantáneas para la base.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
Además de bailar con una pandereta cuando instalo Change Traçking para la base de datos, la desventaja es la incapacidad de usar vistas. Por lo tanto, todavía tengo que usar HighWaterMarkChangeDetectionPolicy
Búsqueda de datos
De forma predeterminada, la búsqueda de Azure usa una sintaxis de consulta simple . Puede que no parezca sorprendente, pero es bastante simple:
wifi + lujo busca las palabras wifi y lujo al mismo tiempo
"hotel de lujo" está buscando la frase
wifi | lujo busca la palabra wifi o la palabra lujo
wifi –luxury busca textos con la palabra wifi pero sin la palabra lujo
lux busca palabras que empiecen con lux
Es posible combinar reglas de búsqueda usando paréntesis. Por ejemplo, la regla motel + (wifi | lujo) busca la palabra motel y la palabra wifi o la palabra lujo
Es bueno que Azure Search pueda usar la sintaxis de Lucene . Para usarlo, es necesario agregar queryType = full a la consulta de búsqueda
La diferencia entre la sintaxis clásica de Azure y Lucene es solo en ausencia de rango.
Por lo tanto, en Azure Search no puede: mod_date:[20020101 TO 20030101]
Pero en Azure Search, puede usar $ filter con sintaxis ODATA . Aquí hay un filtro de ejemplo:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Los filtros también se pueden usar con sintaxis de consulta simple.
En Lucene, la lógica "o" se implementa utilizando OR o ||
Ambos valores se pueden encontrar especificando la declaración "y" con: AND , && o +
Para "no" puede utilizar uno de los siguientes: ¡ NO! o -
La instrucción "no" tiene una característica común tanto para la sintaxis simple como para Lucene. Su comportamiento depende del modo de búsqueda, que se puede establecer tanto en searchMode = all como en searchMode = any (este valor se usa de manera predeterminada). En cualquier modo, al buscar wifi -luxury encontrará documentos con la palabra wifi o documentos sin la palabra lujo. En el modo todo, por la misma solicitud, encontrará muelles con la palabra wifi y simultáneamente sin la palabra lujo.
Veamos algunas características interesantes de Lucene.
La búsqueda difusa le permite buscar palabras que difieren de la búsqueda en una o más letras. Es decir, ayuda a lidiar con los errores tipográficos. Por ejemplo, una búsqueda de "azul ~" o "azul ~ 1" le devolverá "azul" y "azul" e incluso "pegamento". Pero al mismo tiempo, una búsqueda de "analista comercial ~" significará comercial o analista
La proximidad le permite buscar palabras cercanas. Por ejemplo, "hotel aeropuerto" ~ 5 encontrará las palabras "hotel" y "aeropuerto" que se encuentran en el texto a no más de 5 palabras entre sí.
El refuerzo de términos le permite establecer la prioridad de una palabra en la búsqueda. Ejemplo: "rock ^ 2 electronic" busca las palabras rock y electronic, pero las entradas con la palabra rock en la búsqueda se mostrarán arriba.
Expresiones regulares : uso de expresiones regulares. Todo aquí está de acuerdo con la documentación oficial de expresiones regulares de Lucene. Puedes encontrarla en el siguiente enlace . Al buscar, las expresiones regulares deben colocarse entre barras diagonales "/". Por ejemplo, así: / [mh] otel /
Si su cadena de búsqueda contiene caracteres especiales, se deben escapar con una barra diagonal inversa. Caracteres de ejemplo para escapar: + - && ||! () {} [] ^ "~ * ?: \ /
La búsqueda se puede hacer usando una solicitud GET. El ejemplo oficial es este:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Pero puede usar una solicitud POST con body. De nuevo, un ejemplo oficial:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Si está utilizando una solicitud GET o POST con el tipo de datos application / x-www-form-urlencoded, entonces necesita codificar caracteres inseguros y reservados.
Los símbolos /?: @ = & están reservados
Los caracteres `` <> #% {} | \ ^ ~ [] no son seguros.
Por ejemplo, el símbolo # se convertirá en% 23 y el símbolo? se convierte en% 3F
Un par de enlaces para desarrolladores.
Si .NET es desarrollador, puede utilizar el paquete Microsoft.Azure.Search NuGet . Además, hay ejemplos en NodeJS y Java .
Puede encontrar un ejemplo de una aplicación simple en .NET Core aquí. Ejemplo de búsqueda de ASP.NET Core Azure