Por lo general, el rendimiento se entiende como el número de operaciones para un determinado intervalo de tiempo, y cuantas más, mejor. Pero tal definición, y el enfoque en su conjunto, tienen poca aplicabilidad al front-end, porque cada usuario tendrá su propio "front-end". De eso es de lo que quiero hablar, de lo que está sucediendo "allí", con el usuario, del otro lado, en realidad, y no en su MacBook superior.
Además de esto, trataré de considerar brevemente las reglas generales para optimizar el código y algunos errores a los que vale la pena prestarles atención. También le contaré acerca de una
herramienta que ayuda no solo en la creación de perfiles, sino que también incluye una serie de métricas básicas sobre el rendimiento de su aplicación (y espero que lea esta publicación hasta el final).
En primer lugar, determinaremos qué es el rendimiento de front-end y luego pasaremos a cómo medirlo. Entonces, como dije, no mediremos algunas operaciones por segundo, necesitamos datos reales que puedan responder a la pregunta de qué sucede exactamente con nuestro proyecto en cada etapa de su trabajo. Para hacer esto, necesitamos el siguiente conjunto de métricas:
- velocidad de descarga;
- tiempo de primer renderizado e interactividad (Time To Interactive);
- velocidad de reacción a las acciones del usuario;
- FPS para desplazamiento y animaciones;
- inicialización de la aplicación;
- si tiene un SPA, entonces necesita medir el tiempo dedicado a cambiar entre rutas;
- consumo de memoria y tráfico;
- y ... suficiente por ahora.
Todas estas son métricas básicas, sin las cuales es imposible entender qué está sucediendo exactamente en el front-end. Y no solo en la parte frontal, sino en realidad, con el usuario final. Pero para comenzar a recopilar estas métricas, primero debe aprender a medirlas, así que recordemos qué métodos existen para el análisis de rendimiento.
Lo primero para comenzar es, por supuesto, la API de rendimiento. A saber,
performance.timing , a través del cual puede averiguar cuánto tiempo le llevó a un usuario abrir su proyecto. Pero la API de rendimiento cubre solo una parte de la métrica, el resto deberá ser medido por nosotros mismos, y para esto tenemos las siguientes herramientas:
En ese momento, me di cuenta de que necesita ver una herramienta que combine las ventajas de lo anterior y, si es posible, no tenga inconvenientes. Entonces estaba
PerfKeeper .
Perfkeeper
- Control total sobre el principio y el final.
- Puedes enviar al servidor.
- Se muestra en la consola.
- Admite DevTools -> Rendimiento -> Tiempo de usuario.
- Hay una agrupación.
- Hay una codificación de colores (así como unidades de medida, es decir, puede medir no solo el tiempo).
- Soporta extensiones.
Ahora no pintaré la API aquí, no escribí
documentación para esto, y el artículo no trata sobre eso, pero continuaré sobre cómo recopilar métricas.
Velocidad de descarga de la página
Como ya dije, puede encontrar la velocidad de descarga desde
performance.timing , que le permitirá descubrir el ciclo completo desde el inicio de la carga de la página (tiempo para resolver DNS, instalar HTTP Handshake, procesar la solicitud) hasta la carga de la página completa (DomReady y OnLoad):
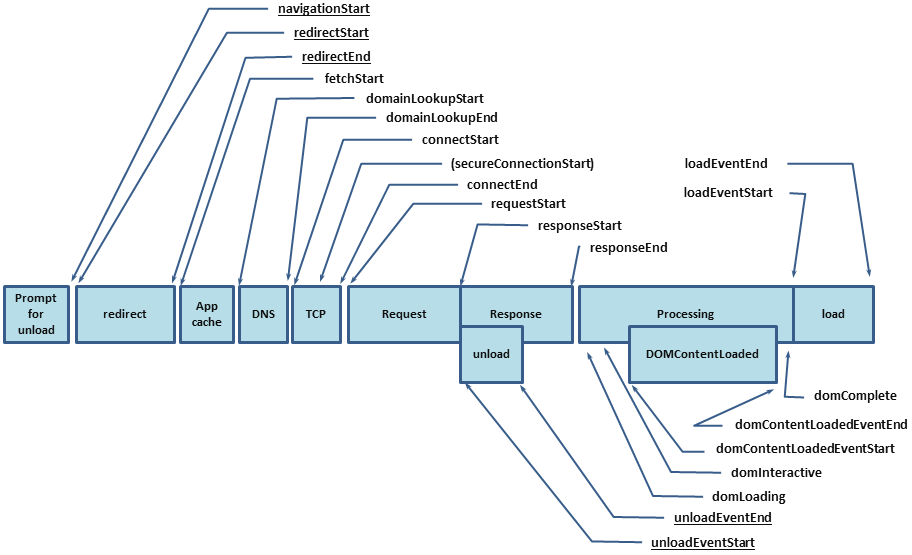
Como resultado, debe obtener el siguiente conjunto de métricas:
Un ejemplo de la extensión de navegación para @ perf-tools / keeper .Pero esto no es suficiente, solo obtuvimos los valores básicos y aún no sabemos qué es exactamente lo que tomó tanto tiempo. Y para averiguarlo, también debe completar las métricas HTML.
Como ya dije, mostraré ejemplos usando
PerfKeeper , por lo que lo primero que debe hacer es en línea en
<hed/> PerfKeeper (2.5 Kb) y más:

Como resultado, verá tanta belleza en la consola:
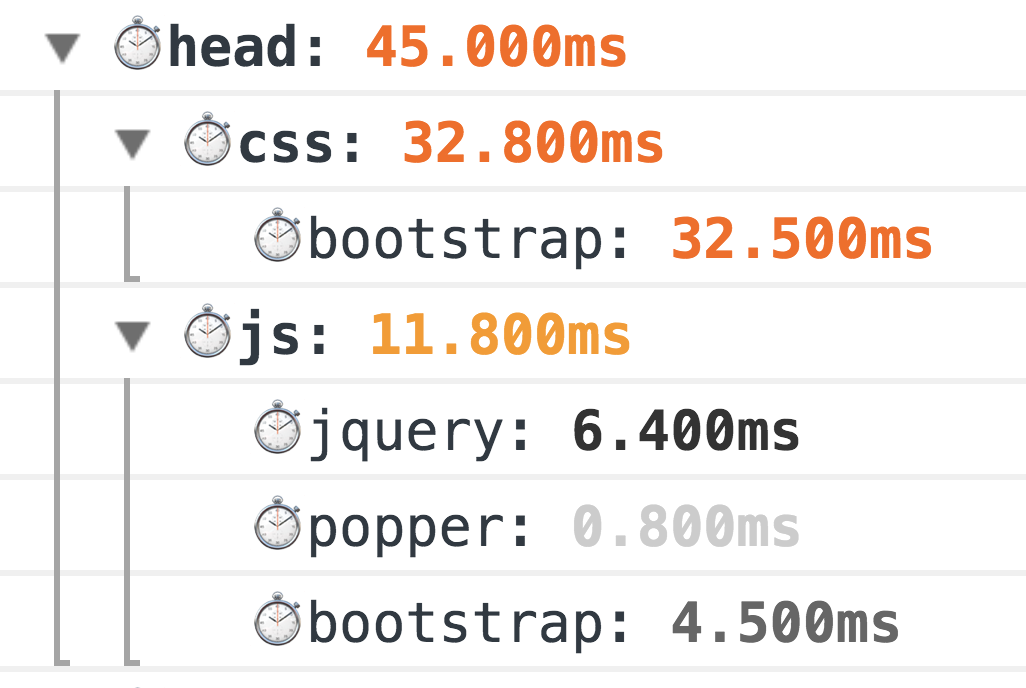
Este es un método clásico de medición del abuelo, 100% funciona. Pero el mundo no se detiene, y para mediciones más precisas ahora tenemos la
API de temporización de recursos (y si los recursos están en un dominio separado de
Timing-Allow-Origin para ayudarlo).
Y aquí vale la pena hablar de los errores clásicos durante la carga inicial de la página, a saber:
- falta de GZip y HTTP / 2 (sí, esto todavía es común);
- uso irrazonable de fuentes (a veces una fuente está conectada solo por un encabezado o incluso un número de teléfono en el pie de página 0_o);
- Los paquetes CSS / JS son demasiado genéricos.
Formas de optimizar la carga de la página:
- use Brotli (o incluso SDCH) en lugar de GZip, habilite HTTP / 2;
- Recopile solo el CSS necesario (crítico) y no se olvide de CSSO ;
- minimice el tamaño del paquete JS separando el paquete CORE mínimo y cargue el resto bajo demanda, es decir asincrónicamente
- cargar JS y CSS en modo sin bloqueo, creando dinámicamente
/> <sript src="..."/> , idealmente cargue JS después del contenido principal; - use SVG en lugar de PNG, y si se combina con JS, eliminará el XML redundante (por ejemplo, como font-awesome );
- use carga diferida para imágenes e iframes (además de esto, el soporte nativo aparecerá en el futuro cercano).
Primer tiempo de renderizado e interactividad (TTI)
La siguiente etapa después de la carga es el momento en que el usuario vio el resultado y la interfaz entró en modo interactivo. Para esto necesitamos
Performance Paint Timing y
PerformanceObserver .
El primero es simple, llamamos
performance.getEntriesByType('paint') y obtenemos dos métricas:
- first-paint: la primera representación;
- first-contentful-paint - y el primer render completo.
 Un ejemplo de la extensión de pintura para @ perf-tools / keeper .
Un ejemplo de la extensión de pintura para @ perf-tools / keeper .Pero con la próxima métrica, Time To Interactive, es un poco más interesante. No hay una forma exacta de determinar cuándo su aplicación se volvió interactiva, es decir accesible para el usuario, pero esto puede entenderse indirectamente por la ausencia de
tareas largas :
 Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper .
Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper .Además de estas métricas básicas, también se necesita la métrica de preparación de su aplicación, es decir, en algún lugar de su código debería ser así:
Import { system } from '@perf-tools/keeper'; export function applicationBoot(el, data) { const app = new Application(el, data);
Tasa de respuesta a las acciones del usuario.
Hay un campo enorme para las métricas y son muy individuales, por lo que hablaré sobre dos básicas que son adecuadas para cualquier proyecto, a saber:
primer evento : la hora del primer evento, por ejemplo, el primer clic (dividiendo dónde pinchó el usuario), esta métrica es especialmente relevante para todo tipo de resultados de búsqueda, una lista de productos, noticias, etc. Con él, puede controlar cómo el tiempo de reacción y el flujo de usuario de sus acciones (cambios en: diseño / nuevas características / optimizaciones, etc.) cambian
 Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper .latencia
Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper .latencia : retraso al procesar algunos eventos, por ejemplo:
click ,
input ,
submit ,
scroll , etc.
Para medir el retraso, simplemente cuelgue el controlador de eventos en la
window con
capture = true y use
requestAnimationFrame calcular la diferencia, este será el retraso:
window.addEventListener(eventType, ({target}) => { const start = now(); requestAnimationFrame(() => { const latency = now() - start; if (latency >= minLatency) {
 Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper trabajando cuando se calcula un número de Fibonacci con un clic.
Un ejemplo de la extensión de rendimiento para @ perf-tools / keeper trabajando cuando se calcula un número de Fibonacci con un clic.FPS al desplazarse y animar
Esta es la métrica más interesante, generalmente se mide a través de
requestAnimationFrame , y si necesita hacer una medición FPS constante, entonces el clásico
FPSMeter lo hará (aunque es demasiado optimista). Pero no funciona en absoluto si necesita medir la suavidad del desplazamiento de la página, porque Necesita un calentamiento. Y luego me encontré con una forma muy
interesante .
Ingeniosamente, de hecho, simplemente creamos un div transparente (1x1px), le agregamos
transition: left 300ms linear 300 ms
transition: left 300ms linear y lo ejecutamos de una esquina a otra, y mientras se anima, a través de
requestAnimationFrame verificamos su izquierda real, y si la nueva longitud difiere de la anterior, luego aumente el número de cuadros renderizados (de lo contrario, tenemos una reducción de FPS).
Y eso no es todo, si usa FF, entonces simplemente hay
mozPaintCount , que es responsable de la cantidad de cuadros procesados, es decir recordamos "HACER", y en el
transitionend calculamos la diferencia.
Total, sin ningún calentamiento, sabemos con certeza si el navegador redibujó el marco o no.
Pronto prometen una API normal:
http://wicg.imtqy.com/frame-timing/Un ejemplo de la extensión fps para @ perf-tools / keeper .Optimización de desplazamiento:
- lo más simple es no hacer nada en el desplazamiento, o retrasar la ejecución a través de
requestAnimationFrame , o incluso requestIdleCallback ; - utilice con mucho cuidado
pointer-events: none , activarlo y desactivarlo puede tener el efecto contrario, por lo que es mejor realizar un experimento A / B utilizando pointer-events y sin él; - no se olvide de las listas virtualizadas, casi todos los motores de View ahora tienen dichos componentes, pero nuevamente, tenga cuidado, los elementos de dicha lista deben ser lo más simples posible, o use "dummies" que serán reemplazados por elementos reales después de completar el desplazamiento. Si escribe una lista virtualizada usted mismo, no use HTML interno y no se olvide del reciclaje DOM (esto es cuando no crea elementos DOM para cada estornudo, sino que los reutiliza).
Inicialización de la aplicación
Solo hay una regla: detalles para que pueda responder exactamente qué tiempo ha consumido exactamente desde la inicialización de la aplicación hasta el lanzamiento final. Como resultado, debe obtener al menos las siguientes métricas:
- cuánto tiempo llevó resolver cada adicción;
- tiempo para recibir y preparar datos para la aplicación;
- Aplicación de renderizado con detalles por bloques.
Es decir en la salida, debe obtener esas métricas mediante las cuales puede realizar un seguimiento exacto de la fase en la que se realiza su reducción.
Ejemplo de trabajoConsola 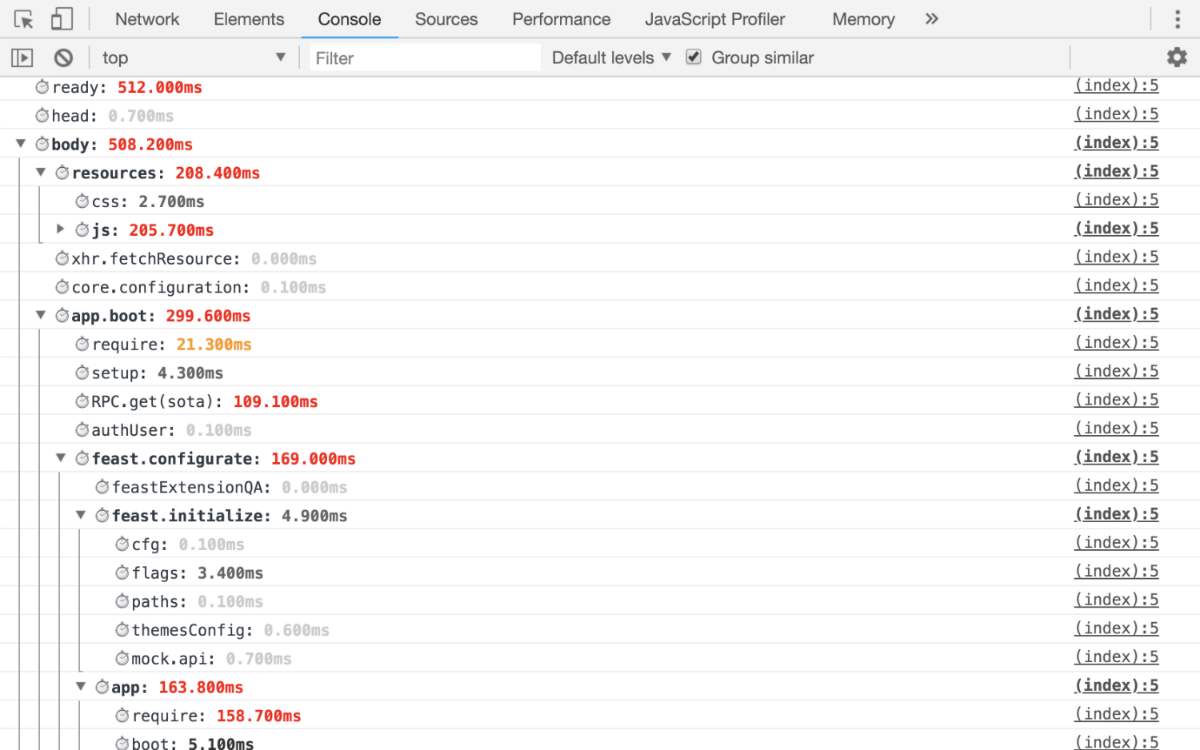 Tiempo de usuario
Tiempo de usuario 
Si tiene SPA, debe medir el tiempo de enrutamiento
En primer lugar, debe haber una métrica general para evaluar el rendimiento (tiempo de tránsito en la ruta) en su conjunto, pero también es necesario tener una métrica para cada ruta (por ejemplo, tenemos una "Lista de hilos", "Lectura de un hilo", "Búsqueda", etc. d.), la métrica en sí misma debe dividirse en métricas:
- Recepción de datos (con un desglose de cuáles)
- Procesamiento
- Actualización
- Renderizar
- Aplicación total
- Bloques (por ejemplo, con nosotros, será: "Columna izquierda" (también conocida como "Lista de carpetas"), "Barra de búsqueda inteligente", "Lista de letras" y similares)
Sin todo esto, es imposible entender dónde comienzan los problemas, por lo que tenemos muchos módulos listos para usar (por ejemplo, el mismo módulo para XHR tiene
startTime y
endTime , que se registran automáticamente).
Pero estas métricas no son suficientes para evaluar adecuadamente lo que está sucediendo. Son demasiado generales porque estamos hablando de SPA, entonces definitivamente tiene algún tipo de caché de tiempo de ejecución (para no volver al servidor si ya ha estado allí), por lo que nuestras métricas se dividen en enrutamiento con y sin caché. Aún así, específicamente en nuestro caso, dividimos la métrica por el número de entidades que contiene. En otras palabras, no puede agregar la vista "Hilo" con 1, 5, 10 o más de 100 letras en una métrica, por lo que si tiene alguna lista mostrada, debe seleccionar puntos de interrupción y separar aún más la métrica.
Memoria y consumo de tráfico
Comencemos con la memoria . Y aquí estamos esperando una gran decepción. Por el momento solo hay memoria no estandarizada (solo Chrome) performance, que da números ridículamente bajos. Pero aún deben medirse y observar cómo la aplicación "fluye" con el tiempo:
Un ejemplo de la extensión de memoria para @ perf-tools / keeperTráfico Para contar el tráfico, necesitará
Timing-Allow-Origin (si los recursos se encuentran en un dominio separado) y la
API de sincronización de recursos , esto ayudará no solo a calcular el tráfico, sino también a detallarlo:
- qué protocolo se utiliza (HTTP / 1, HTTP / 2, etc.);
- tipos de recursos cargados;
- cuánto tiempo llevó descargarlos;
- tamaño, además, puede comprender si el recurso se carga en la red o se toma del caché.
Un ejemplo de la extensión de recursos para @ perf-tools / keeper .¿Qué da cuenta del tráfico?
- Lo más importante es que le permite ver la imagen real, y no como es habitual con CSS + JS y más allá de eso, cómo esta "imagen" cambia con el tiempo.
- Luego puede analizar qué se carga exactamente, dividir los recursos en grupos, etc.
- Qué tan bien funciona el almacenamiento en caché para usted.
- ¿Hay alguna anomalía, por ejemplo, después de 15 minutos de operación, por ejemplo, el código entró en recursión y carga algunos recursos sin cesar, monitorear el tráfico ayudará en esto?
Bueno, un informe de actualización de mi colega
Igor Druzhinin sobre este tema:
Evaluar la calidad de la aplicación - monitorear el consumo de tráficoAnalítica
Configuramos las métricas, ¿y luego qué? Y luego necesitan ser enviados a alguna parte. Y aquí, ya sea que recoja algo de
grafito de usted o, para empezar, puede usar
Google Analytics o similar para la agregación de datos para beneficio personal.
Y no olvide, no es suficiente obtener un gráfico, para todas las métricas importantes debe haber percentiles que le permitan comprender, por ejemplo, qué porcentaje de la audiencia está cargando el proyecto para <1s, <2s, <3s, <5s, 5s +, etc.
Escribir un código de alto rendimiento
Al principio quería escribir algo significativo aquí, dicen que use WebWorker, no olvide
requestIdleCallback o algo exótico, por ejemplo, a través de Runtime Cache a través de las pestañas del navegador con SharedWorker o ServiceWorker (que no es solo sobre el almacenamiento en caché, si es que). Pero todo esto es muy abstracto y muchos temas son imposibles, así que solo escribe lo siguiente:
- Inicialmente cubra su código con métricas que medirán su rendimiento.
- No creas los puntos de referencia con jsperf. La gran mayoría de ellos están mal escritos y simplemente fuera de contexto. El mejor punto de referencia es la métrica real del proyecto, según la cual verá el efecto de sus acciones.
- Recuerde sobre la percepción de productividad, o más bien la Ley Weber-Fechner. Es decir, si comenzó la optimización, no despliegue los cambios hasta que mejore al menos en un 20%, de lo contrario, los usuarios simplemente no lo notarán. La ley también funciona en la dirección opuesta.
- Los asiduos del miedo, especialmente los generados. No solo pueden colgar el navegador, sino también obtener XSS, por lo que en nuestro correo está prohibido analizar HTML usándolos, solo a través de un bypass DOM.
- No necesita usar matrices para ingresar un valor en uno u otro grupo, para esto hay un
object o Set (por ejemplo, successSteps.includes(currentStep) necesario en successSteps.hasOwnProperty(currentStep) ), O (1) es todo. - La expresión "La optimización prematura es la raíz de todos los males" no se trata de escribir lo que quieras. Si sabes la mejor manera, escribe de manera óptima.
Escribiré un par de párrafos sobre el código y su optimización.DOM Muy a menudo escucho "El problema en el DOM"; esto, por supuesto, es cierto, pero dado que casi todos ahora tienen una abstracción al respecto. Es ella quien se convierte en el cuello de botella, o más bien su código, que es responsable de la formación de la vista y la lógica empresarial.
Pero si hablamos del DOM, por ejemplo, en lugar de eliminar un fragmento del DOM, es mejor ocultarlo o quitarlo. Si aún necesita eliminar, realice esta operación en
requestIdleCallback (si es posible), o divida el proceso de destrucción en dos fases: síncrona y asíncrona.
Haré una reserva de inmediato, use este enfoque con prudencia, de lo contrario puede dispararle a la rodilla.
También utilizamos otra técnica interesante en las listas, por ejemplo, la "Lista de hilos". La esencia de la técnica es que, en lugar de una "Lista" global y actualizar sus datos, generamos una "Lista de subprocesos" para cada "Carpeta". Como resultado, cuando el usuario navega entre las "Carpetas", una lista se elimina del DOM (no se elimina) y la otra se actualiza parcial o totalmente. Y no todo, como es el caso de la "Lista Única".
Todo esto da una respuesta instantánea a las acciones del usuario.
Matemáticas Eliminamos fácilmente todas las matemáticas en Worker o WebAssembly, esto ha estado funcionando durante mucho tiempo.
Transpilers . Oh, muchos ni siquiera piensan que el código que escriben pasa por el transpilador. Sí, ellos saben de él, pero eso es todo. Pero en qué se convierte ya no les importa. De hecho, en DevTools ven el resultado del mapa fuente.
Por lo tanto, estudie las herramientas que usa, por ejemplo, la misma babel en el
patio de recreo tiene la oportunidad de ver en qué genera el código dependiendo de los ajustes preestablecidos seleccionados, solo mire el mismo
yeild ,
await o no.
Las sutilezas de la lengua . Incluso menos personas saben sobre el monomorfismo del código, o cursi por qué el enlace es lento y ... ¡finalmente usas
handleEvent !
Datos y prekreshing . Menos solicitudes, más almacenamiento en caché. Además, muy a menudo usamos la técnica de "previsión", esto es cuando en el fondo cargamos datos. Por ejemplo, después de representar la "Lista de hilos", comenzamos a cargar N hilos no leídos en la "Carpeta" actual, de modo que cuando hace clic en ellos, el usuario cambia inmediatamente a "Leer" en lugar de otro "cargador". Utilizamos una técnica similar no solo para datos, sino también para JS. Por ejemplo, "Escribir una carta" es un gran paquete (debido al editor), y no todas las personas escriben cartas a la vez, por lo que lo cargamos en segundo plano, después de que se inicializa la aplicación.
Louders No sé por qué, pero no vi artículos que enseñen cómo no hacer un cargador, sino que hice una presentación del "futuro" React, en el que se dedicó mucho tiempo a este problema en el marco de Suspenso. Pero, después de todo, la aplicación ideal es sin cargadores, hemos estado tratando durante mucho tiempo en el Correo para mostrarla solo en situaciones de emergencia.
En general, tenemos una política de este tipo, no hay datos, no hay vista, no hay nada para dibujar una semi-interfaz, primero cargamos los datos y solo luego "dibujamos". Es por eso que usamos la "previsión" de dónde irá el usuario y cargamos estos datos para que el usuario no vea el cargador. Además, nuestra capa de datos, que es persistente, ayuda mucho en esta tarea. Si solicitó "Thread" en algún lugar de un lugar, la próxima vez que solicite desde otro o el mismo lugar, no habrá ninguna solicitud, tomaremos datos de Runtime Cache (más precisamente, un enlace a los datos). Y así, en todo, las colecciones de hilos también son solo enlaces a datos.
Pero si aún decide hacer un cargador, no olvide las reglas básicas que harán que su cargador sea menos molesto:
- no es necesario mostrar el cargador de inmediato, al momento de enviar la solicitud, debe haber un retraso de al menos 300-500 ms antes del espectáculo;
- Después de recibir los datos, no necesita eliminar bruscamente el cargador, aquí nuevamente debería haber un retraso.
Estas reglas simples son necesarias para que el cargador aparezca solo en solicitudes pesadas y no "parpadee" al finalizar. Pero lo más importante, el mejor cargador es un cargador que no apareció.
Gracias por su atención, eso es todo, medir, analizar y usar
PerfKeeper (
ejemplo en vivo ), así como
mi github y
twitter , en caso de preguntas.