Las imágenes JPEG se encuentran en todas partes en nuestra vida digital, pero detrás de esta cobertura de conciencia se encuentran algoritmos que eliminan detalles que no son percibidos por el ojo humano. El resultado es la más alta calidad visual con el tamaño de archivo más pequeño, pero ¿cómo funciona exactamente? ¡Veamos lo que nuestros ojos no ven exactamente!

Es fácil dar por sentado la posibilidad de enviar una foto a un amigo y no preocuparse por el dispositivo, el navegador o el sistema operativo que utiliza; sin embargo, este no siempre ha sido el caso. A principios de la década de 1980, las computadoras sabían cómo almacenar y mostrar imágenes digitales, pero había muchas ideas competitivas sobre la mejor manera de hacerlo. Era imposible simplemente enviar una imagen de una computadora a otra y esperar que todo funcionara.
Para resolver este problema, en 1986 se formó un comité de expertos de todo el mundo bajo el nombre de "Joint Photographic Experts Group (JPEG)", basado en la colaboración de la Organización Internacional de Normalización (ISO) y la Comisión Electrotécnica Internacional (IEC) ) - dos organizaciones internacionales de normalización, cuya sede se encuentra en Ginebra (Suiza).
Un grupo de personas llamado JPEG creó el estándar de compresión de imagen digital JPEG en 1992. Cualquiera que usara Internet probablemente encontraría imágenes codificadas en JPEG. Esta es la forma más común de codificar, enviar y almacenar imágenes. Desde páginas web hasta correo electrónico y redes sociales, JPEG se usa miles de millones de veces al día, casi cada vez que vemos una imagen en línea o la enviamos. Sin JPEG, la web sería menos vibrante, más lenta y probablemente habría menos imágenes de gatos.
Este artículo trata sobre cómo decodificar una imagen JPEG. En otras palabras, sobre lo que se requiere para convertir los datos comprimidos almacenados en una computadora en una imagen que aparece en la pantalla. Vale la pena saber sobre esto, no solo porque es importante para comprender la tecnología que usamos diariamente, sino también porque al revelar los niveles de compresión, entendemos mejor la percepción y la visión, así como los detalles a los que nuestros ojos son más sensibles.
Además, jugar con imágenes de esta manera es muy interesante.
Mirando dentro de un JPEG
En una computadora, todo se almacena como una secuencia de números binarios. Por lo general, estos bits, ceros y unos, se agrupan en ocho, formando bytes. Cuando abre una imagen JPEG en una computadora, algo (navegador, sistema operativo, algo más) debe decodificar los bytes, restaurando la imagen original en forma de una lista de colores que se pueden mostrar.
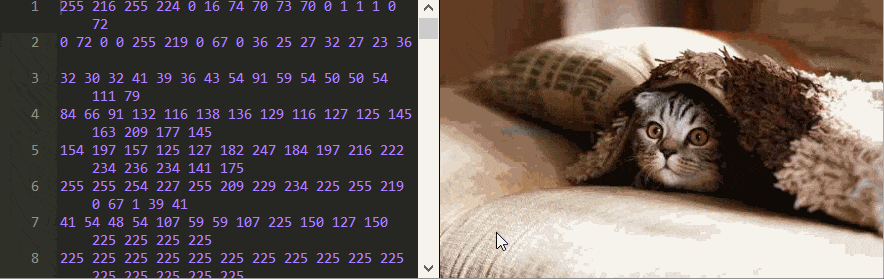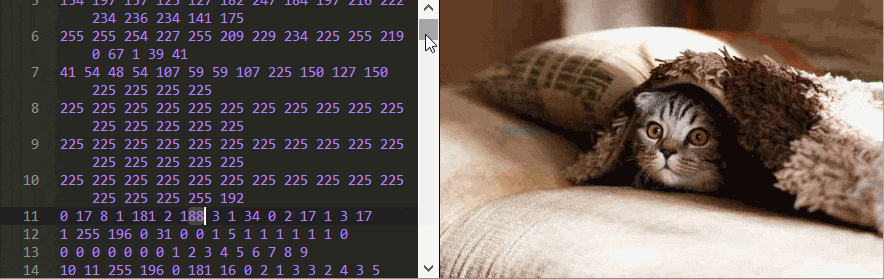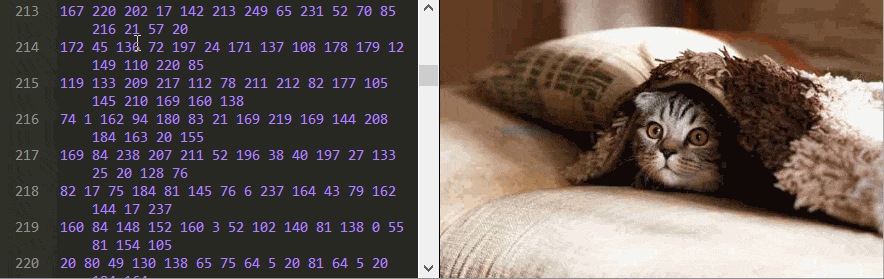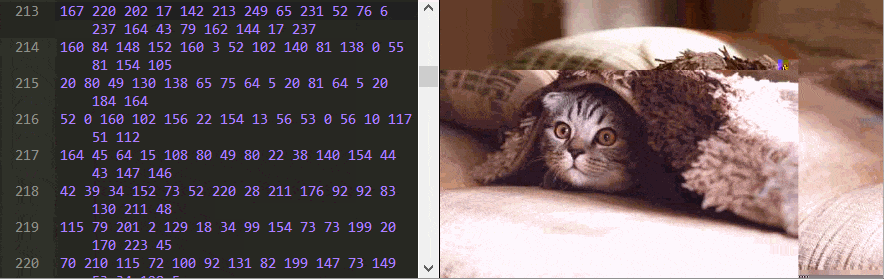
Si descargas esta linda
foto de gato y la abres en un editor de texto, verás un montón de personajes incoherentes.
 Aquí uso Notepad ++ para examinar el contenido de un archivo, ya que los editores de texto normales, como el Bloc de notas de Windows, corromperán el binario después de guardarlo y ya no satisfarán el formato JPEG.
Aquí uso Notepad ++ para examinar el contenido de un archivo, ya que los editores de texto normales, como el Bloc de notas de Windows, corromperán el binario después de guardarlo y ya no satisfarán el formato JPEG.Cuando abre una imagen en un editor de texto, confunde la computadora, ¡así como confunde su cerebro cuando se frota los ojos y comienza a ver manchas de color!
Estos puntos que ves se conocen como
fosfenos y no son el resultado de la exposición a un estímulo de luz o alucinaciones generadas por la mente. Ocurren porque su cerebro cree que cualquier señal eléctrica en los nervios ópticos transmite información sobre la luz. El cerebro necesita hacer tales suposiciones, porque es imposible saber si la señal es sonido, visión o cualquier otra cosa. Todos los nervios del cuerpo transmiten exactamente los mismos impulsos eléctricos. Al presionar los ojos, envía señales que no son visuales, pero activan los receptores del ojo que su cerebro interpreta, en este caso, incorrectamente, como algo visual. ¡Eres literalmente capaz de ver la presión!
Es divertido pensar en cómo las computadoras se ven como un cerebro, pero también es una analogía útil que ilustra cuán fuertemente la importancia de los datos, transmitidos a través del cuerpo por los nervios o almacenados en una computadora, depende de su interpretación. Todos los datos binarios consisten en ceros y unos, componentes básicos que pueden transmitir información de cualquier tipo. Su computadora a menudo adivina cómo interpretarlos usando sugerencias, como extensiones de archivo. Y ahora lo estamos obligando a interpretarlos como texto, ya que esto es lo que espera el editor de texto.
Para entender cómo decodificar JPEG, necesitamos ver las señales originales en sí mismas: datos binarios. ¡Esto se puede hacer usando el editor hexadecimal, o directamente en la
página web del artículo original ! Hay una imagen, junto a la cual en el cuadro de texto están todos sus bytes (excepto el encabezado), presentados en forma decimal. Puede cambiarlos, y el script recodificará y producirá una nueva imagen sobre la marcha.

Puedes aprender mucho solo jugando con este editor. Por ejemplo, ¿puede decir en qué orden se almacenan los píxeles?
En este ejemplo, es extraño que cambiar algunos números no afecte la imagen en absoluto, pero, por ejemplo, si reemplaza el número 17 con 0 en la primera línea, ¡la foto quedará completamente mal!

Otros cambios, por ejemplo, el reemplazo de 7 en la línea 1988 con el número 254 cambia el color, pero solo de los píxeles posteriores.

Quizás lo más extraño es que algunos números cambian no solo el color, sino también la forma de la imagen. Cambie 70 en la línea 12 a 2 y mire la fila superior de la imagen para ver a qué me refiero.

Y no importa qué imagen JPEG use, siempre encontrará estas secuencias de ajedrez crípticas cuando edite bytes.
Cuando se juega con el editor, es difícil entender cómo se recrea la foto a partir de estos bytes, ya que la compresión JPEG consta de tres tecnologías diferentes que se aplican secuencialmente en todos los niveles. Estudiaremos cada uno de ellos por separado para revelar el comportamiento misterioso que observamos.
Tres niveles de compresión JPEG:- Submuestreo de color .
- Transformación discreta del coseno y discretización .
- Longitudes de series de codificación , Delta y Huffman
Para que pueda imaginar la escala de compresión, tenga en cuenta que la imagen de arriba representa 79.819 números, es decir, aproximadamente 79 Kb. Si lo almacenamos sin compresión, para cada píxel se requerirían tres números, para el componente rojo, verde y azul. Eso sería 917,700 números, o aprox. 917 Kb. Como resultado de la compresión JPEG, el archivo resultante ha disminuido en más de 10 veces.
De hecho, esta imagen se puede comprimir con mucha más fuerza. A continuación se muestran dos imágenes una al lado de la otra: la foto de la derecha se redujo a 16 Kb, ¡57 veces más pequeña que la versión sin comprimir!

Si observa de cerca, verá que estas imágenes no son idénticas. Ambas son imágenes con compresión JPEG, pero la correcta es mucho más pequeña en volumen. También se ve un poco peor (mira los cuadrados de los colores de fondo). Por lo tanto, JPEG también se llama compresión con pérdida; Durante la compresión, la imagen cambia y pierde algunos detalles.
1. Disminución de color
Aquí hay una imagen que usa solo el primer nivel de compresión.
 (Versión interactiva - en el artículo original ). Eliminar un número destruye todos los colores. Sin embargo, si elimina exactamente seis números, esto prácticamente no afecta la imagen.
(Versión interactiva - en el artículo original ). Eliminar un número destruye todos los colores. Sin embargo, si elimina exactamente seis números, esto prácticamente no afecta la imagen.Ahora los números son un poco más fáciles de descifrar. Esta es una lista casi simple de colores en los que cada byte cambia exactamente un píxel, pero al mismo tiempo ya tiene la mitad del tamaño de una imagen sin comprimir (que ocuparía unos 300 Kb en un tamaño tan reducido). Adivina por qué?
Puede ver que estos números no denotan los componentes rojo, verde y azul estándar, porque si reemplazamos todos los números con ceros, obtenemos una imagen verde (y no blanca).

Esto se debe a que estos bytes indican Y (brillo),

Cb (azul relativo),

y fotos de Cr (enrojecimiento relativo).

¿Por qué no usar RGB? De hecho, así es como funcionan las pantallas más modernas. Su monitor puede mostrar cualquier color, incluido rojo, verde y azul con diferentes intensidades para cada píxel. El blanco se obtiene al encender los tres con brillo completo, y el negro al apagarlos.
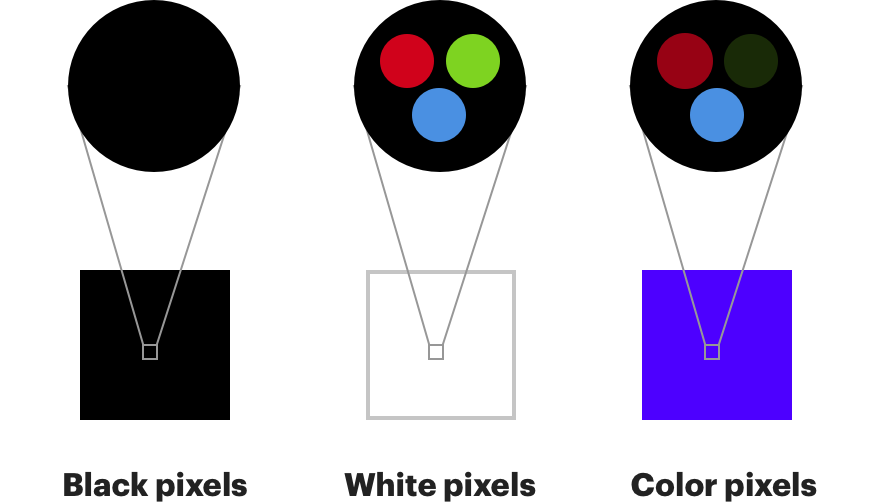
También es muy similar al trabajo del ojo humano. Los receptores de color de nuestros ojos se denominan "
conos " y se dividen en tres tipos, cada uno de los cuales es más sensible al rojo, verde o azul [los conos tipo S son sensibles al azul violeta (S del inglés Short - shortwave espectro), tipo M - en verde-amarillo (M del inglés. Medio - onda media), y tipo L - en las partes amarillo-rojo (L del inglés. Largo - onda larga) del espectro. La presencia de estos tres tipos de conos (y varillas sensibles en la parte verde esmeralda del espectro) le da a la persona una visión del color. / aprox. transl.].
Las varillas , otro tipo de fotorreceptores en nuestros ojos, solo pueden capturar cambios en el brillo, pero son mucho más sensibles. A nuestros ojos hay alrededor de 120 millones de barras y solo 6 millones de conos.
Por lo tanto, nuestros ojos notan cambios en el brillo mucho mejor que los cambios en el color. Si separa el color del brillo, puede eliminar un poco de color y nadie notará nada. La disminución de color es el proceso de representar los componentes de color de una imagen a una resolución más baja que los componentes de brillo. En el ejemplo anterior, cada píxel tiene exactamente un componente Y, y cada grupo individual de cuatro píxeles tiene exactamente un componente Cb y un Cr. Por lo tanto, la imagen contiene cuatro veces menos información de color que la original.
El espacio de color YCbCr se usa no solo en JPEG. Fue inventado originalmente en 1938 para programas de televisión. No todos tienen un televisor en color, por lo que la separación de color y brillo permitió que todos recibieran la misma señal, y los televisores sin color solo usaron el componente de brillo.
Por lo tanto, eliminar un número del editor destruye completamente todos los colores. Los componentes se almacenan como YYYY Cb Cr (de hecho, no necesariamente en ese orden; el orden de almacenamiento se especifica en el encabezado del archivo). Eliminar el primer número conducirá al hecho de que el primer valor de Cb se percibirá como Y, Cr como Cb, y en su conjunto resultará un efecto dominó, cambiando todos los colores de la imagen.
La especificación JPEG no lo obliga a usar YCbCr. Pero en la mayoría de los archivos se usa porque proporciona imágenes de mejor calidad después de la disminución de resolución en comparación con RGB. Pero no tienes que creer mi palabra. Vea usted mismo en la tabla a continuación cómo se verá la disminución de resolución de cada componente individual en RGB y en YCbCr.

(Versión interactiva - en el artículo
original ).
Eliminar el azul no es tan notable como el rojo o el verde. Esto se debe a los seis millones de conos en los ojos, aproximadamente el 64% son sensibles al rojo, el 32% al verde y el 2% al azul.
El submuestreo del componente Y (abajo a la izquierda) se ve mejor. Se nota incluso un ligero cambio.
La conversión de una imagen de RGB a YCbCr no reduce el tamaño del archivo, pero facilita la búsqueda de detalles menos notables que se pueden eliminar. La compresión con pérdida se produce en la segunda etapa. Se basa en la idea de representar datos en una forma más compresible.
2. Transformación discreta del coseno y discretización
Este nivel de compresión en su mayor parte determina la esencia de JPEG. Después de convertir los colores a YCbCr, los componentes se comprimen por separado, por lo que podemos concentrarnos en el componente Y solo más tarde, y así es como se ven los bytes del componente Y después de aplicar este nivel.
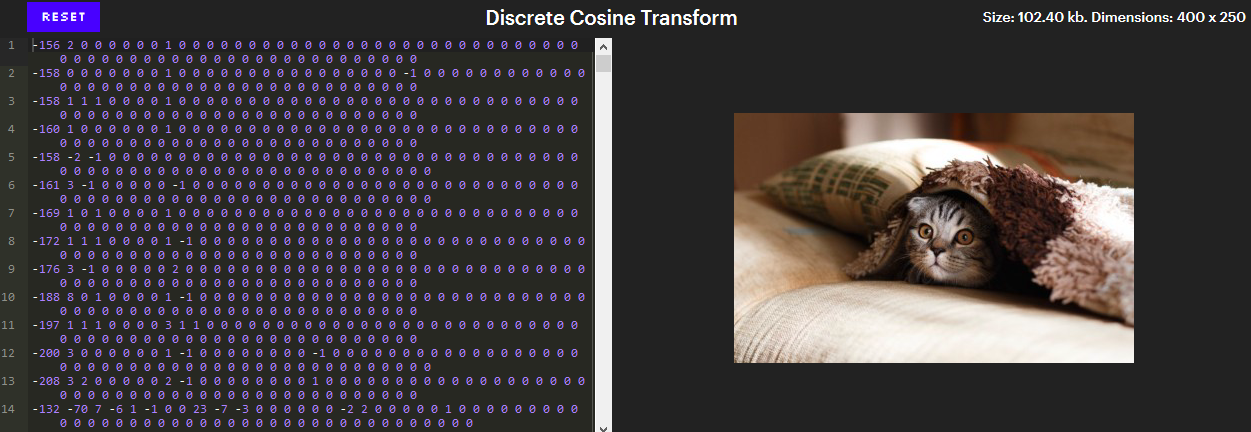 (Versión interactiva - en el artículo original ).
(Versión interactiva - en el artículo original ). En la versión interactiva, al hacer clic en un píxel se desplaza el editor a la línea que lo indica. Intente eliminar números del final o agregue algunos ceros a un número específico.
A primera vista, parece una muy mala compresión. Hay 100.000 píxeles en la imagen, y se requieren 102.400 números para indicar su brillo (componentes Y), ¡esto es peor que no comprimir nada en absoluto!
Sin embargo, tenga en cuenta que la mayoría de estos números son cero. Además, todos estos ceros al final de las líneas se pueden eliminar sin cambiar la imagen. ¡Quedan unos 26,000 números, y esto es casi 4 veces menos!
En este nivel está el secreto de los patrones de ajedrez. A diferencia de otros efectos que vimos, la apariencia de estos patrones no es un problema técnico. Son los bloques de construcción de toda la imagen. Cada línea del editor contiene exactamente 64 números, coeficientes de transformación de coseno discreto (DCT) correspondientes a intensidades de 64 patrones únicos.
Estos patrones se forman sobre la base del gráfico coseno. Aquí hay algunos de ellos:
 8 de 64 cuotas
8 de 64 cuotasA continuación se muestra una imagen que muestra los 64 patrones.
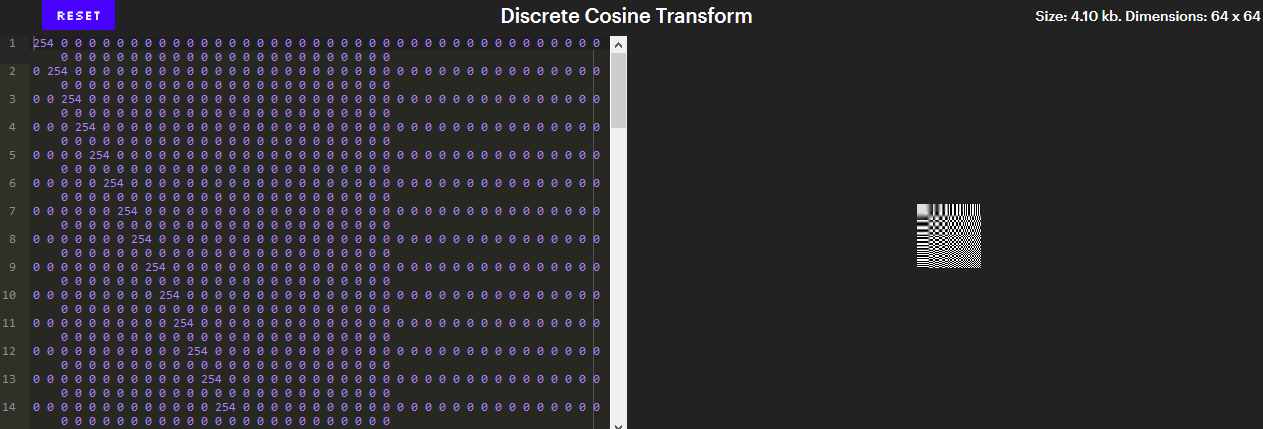 (Versión interactiva - en el artículo original ).
(Versión interactiva - en el artículo original ).Estos patrones son de particular importancia ya que forman la base de imágenes de 8x8. Si no está familiarizado con el álgebra lineal, esto significa que se puede obtener cualquier imagen de 8x8 a partir de estos 64 patrones. DCT es el proceso de dividir imágenes en bloques de 8x8 y convertir cada bloque en una combinación de estos 64 coeficientes.
El hecho de que cualquier imagen pueda estar compuesta de 64 patrones específicos parece mágico. Sin embargo, esto es lo mismo que decir que cualquier lugar en la Tierra puede describirse con dos números: latitud y longitud [indicando hemisferios / aprox. transl.]. A menudo consideramos la superficie de la Tierra en dos dimensiones, por lo que solo necesitamos dos números. Una imagen de 8x8 tiene 64 dimensiones, por lo que necesitamos 64 números.
Todavía no está claro cómo esto nos ayuda en el sentido de la compresión. Si necesitamos 64 números para representar una imagen de 8x8, ¿por qué sería mejor que simplemente almacenar 64 componentes de luminancia? Hacemos esto por la misma razón por la que convertimos tres números RGB en tres números YCbCr: esto nos permite eliminar detalles invisibles.
Es difícil ver exactamente qué detalles se eliminan en esta etapa, porque JPEG aplica DCT a bloques de 8x8. Sin embargo, nadie nos prohíbe aplicarlo a toda la imagen. Así es como se ve DCT en el componente Y cuando se aplica a toda la imagen:
Desde el final, puede eliminar más de 60,000 números prácticamente sin cambios notables en la foto.

Sin embargo, tenga en cuenta que si restablecemos los primeros cinco números, la diferencia será obvia.

Los números al principio indican cambios de baja frecuencia en la imagen, y nuestros ojos los perciben mejor. Los números cerca del final indican cambios en las frecuencias altas que son más difíciles de notar. Para "ver lo que no es visible con el ojo", podemos aislar estas partes de alta frecuencia poniendo a cero los primeros 5000 números.

Vemos todas las áreas de la imagen en las que se produce el mayor cambio de píxel a píxel. Se destacan los ojos del gato, su bigote, la manta de felpa y las sombras en la esquina inferior izquierda. Puede ir más allá borrando los primeros 10,000 números:

20,000:

40,000:

60,000:

Estas partes de alta frecuencia son jpeg y se eliminan durante la fase de compresión. La conversión de colores a coeficientes DCT no tiene pérdidas. Las pérdidas se generan en el paso de discretización, donde se eliminan los valores de alta frecuencia o cerca de cero. Cuando baja la calidad de guardar JPEG, el programa aumenta el umbral para la cantidad de valores eliminados, lo que reduce el tamaño del archivo, pero hace que la imagen esté más pixelada. Por lo tanto, la imagen en la primera sección, que era 57 veces más pequeña, se veía así. Cada bloque de 8x8 parecía tener un número mucho menor de coeficientes DCT en comparación con una versión mejor.
Puede hacer un efecto genial como la transmisión gradual de imágenes. Puede mostrar una imagen borrosa, que se vuelve más detallada a medida que se descargan más y más coeficientes.
Aquí, solo por diversión, qué sucede cuando se usan solo 24,000 números:

O solo 5000:

Muy borrosa, pero como si fuera reconocible!
3. Codificación de longitudes de series, delta y Huffman
Hasta ahora, todas las etapas de compresión han ido con pérdidas. La última etapa, por el contrario, pasa sin pérdida. No elimina información, pero reduce significativamente el tamaño del archivo.
¿Cómo se puede comprimir algo sin descartar información? Imagina cómo describiríamos un simple rectángulo negro de 700 x 437.
JPEG utiliza 5000 números para esto, pero se puede lograr un resultado mucho mejor. ¿Te imaginas un esquema de codificación que describa una imagen con el menor número de bytes posible?
El esquema mínimo que se me ocurre utiliza cuatro: tres para indicar el color y el cuarto: cuántos píxeles tienen ese color. La idea de representar valores repetidos de una manera tan comprimida se denomina codificación de longitud de serie. No tiene pérdidas, ya que podemos restaurar los datos codificados en su forma original.
El tamaño de un archivo JPEG con un rectángulo negro es mucho mayor que 4 bytes; recuerde que en el nivel DCT, la compresión se aplica a bloques de 8x8 píxeles. Por lo tanto, al menos necesitamos un coeficiente DCT por cada 64 píxeles. Necesitamos uno porque en lugar de almacenar un solo coeficiente DCT seguido de 63 ceros, codificar las longitudes de la serie nos permite almacenar un número e indicar que "todos los demás son ceros".
La codificación delta es una técnica en la que cada byte contiene una diferencia de algún valor, en lugar de un valor absoluto. Por lo tanto, la edición de ciertos bytes cambia el color de todos los demás píxeles. Por ejemplo, en lugar de almacenar
12 13 14 14 14 13 13 14
Podríamos comenzar con 12 y luego simplemente indicar cuánto necesitamos sumar o restar para obtener el siguiente número. Y esta secuencia en la codificación delta toma la forma:12 1 1 0 0 -1 0 1 Losdatos convertidos no se obtienen menos que el original, pero ya es más fácil comprimirlos. El uso de la codificación delta antes de codificar longitudes de serie puede ayudar mucho, mientras se mantiene la compresión sin pérdidas.La codificación delta es una de las pocas técnicas utilizadas fuera de los bloques de 8x8. De los 64 coeficientes DCT, uno es simplemente una función de onda constante (color sólido). Representa el brillo promedio de cada bloque para los componentes de luminancia, o el azul promedio para los componentes de Cb, y así sucesivamente. El primer valor de cada bloque DCT se denomina valor DC, y cada valor DC sufre una codificación delta con respecto a los anteriores. Por lo tanto, un cambio en el brillo del primer bloque afectará a todos los bloques.El último misterio permanece: ¿cómo el cambio singular estropea por completo toda la imagen? Hasta ahora, los niveles de compresión no tenían tales propiedades. La respuesta se encuentra en el encabezado JPEG. Los primeros 500 bytes contienen metadatos sobre la imagen: ancho, alto, etc., y hasta ahora no hemos trabajado con ellos.Sin un encabezado, es casi imposible (bueno, o muy difícil) decodificar JPEG. Parecerá que estoy tratando de describirte la imagen y comenzar a inventar palabras para transmitir mi impresión. La descripción probablemente será muy concisa, porque puedo inventar palabras con exactamente el significado que quiero transmitir, pero para todos los demás no tendrán sentido.Suena estúpido, pero eso es exactamente lo que sucede. Cada imagen JPEG está comprimida con códigos específicos. Un diccionario de códigos se almacena en el encabezado. Esta técnica se llama código Huffman y el diccionario se llama tabla Huffman. En el encabezado, la tabla está marcada con dos bytes: 255 y luego 196. Cada componente de color puede tener su propia tabla.Los cambios en las tablas afectarán radicalmente cualquier imagen. Un buen ejemplo es cambiar 1 en 12 en la línea 15. Esto se debe a que las tablas indican cómo leer bits individuales. Hasta ahora, solo hemos trabajado con números binarios en forma decimal. Pero esto nos oculta el hecho de que si desea almacenar el número 1 en un byte, entonces se verá como 00000001, ya que cada byte debe tener exactamente ocho bits, incluso si solo se necesita uno de ellos.Esto es potencialmente una gran pérdida de espacio si tienes muchos números pequeños. El código Huffman es una técnica que nos permite relajar este requisito, según el cual cada número debe ocupar ocho bits. Esto significa que si ve dos bytes:234 115
Esto se debe a que las tablas indican cómo leer bits individuales. Hasta ahora, solo hemos trabajado con números binarios en forma decimal. Pero esto nos oculta el hecho de que si desea almacenar el número 1 en un byte, entonces se verá como 00000001, ya que cada byte debe tener exactamente ocho bits, incluso si solo se necesita uno de ellos.Esto es potencialmente una gran pérdida de espacio si tienes muchos números pequeños. El código Huffman es una técnica que nos permite relajar este requisito, según el cual cada número debe ocupar ocho bits. Esto significa que si ve dos bytes:234 115, , . , :
11101010 01110011
, , . , , (111010), 58 , (10011), 19, (0011), 3.
. , . ,
.
Uno de los trucos interesantes que puede hacer si sabe esto es separar el encabezado del JPEG y almacenarlo por separado. De hecho, resulta que solo tú puedes leer el archivo. Facebook está haciendo esto para reducir aún más el tamaño del archivo.Lo que más puede hacer es modificar un poco la tabla de Huffman. Para otros, se verá como una imagen dañada. Y solo tú conocerás la versión mágica de su corrección.Para resumir: entonces, ¿qué se necesita para la decodificación JPEG? Es necesario:- Extraiga la (s) tabla (s) Huffman del encabezado y decodifique los bits.
- Extraiga coeficientes de transformación de coseno discretos para cada componente de color y brillo para cada bloque de 8x8 realizando transformaciones inversas de codificación de longitudes y deltas de series.
- , 88.
- , ( ).
- YCbCr RGB.
- !
! , – , JPEG . , , . , , JPEG, , . , - , , ( , ).
, , , .