El curso completo en ruso se puede encontrar en
este enlace .
El curso de inglés original está disponible en
este enlace .
 Nuevas conferencias están programadas cada 2-3 días.
Nuevas conferencias están programadas cada 2-3 días.Entrevista con Sebastian
- Entonces, estamos nuevamente con Sebastian en la tercera parte de este curso. Sebastian, sé que has desarrollado mucho usando redes neuronales convolucionales. ¿Puede contarnos un poco más sobre estas redes y cuáles son? Estoy seguro de que los estudiantes de nuestro curso escucharán con no menos interés, porque en esta parte tendrán que desarrollar ellos mismos la red neuronal convolucional.
- Genial! Entonces, las redes neuronales convolucionales son una excelente manera de estructurar en la red, construyendo la llamada invariancia (asignación de características inmutables). Por ejemplo, tome la idea del reconocimiento de patrones en el escenario o la fotografía, desea comprender si Sebastian está representado en él o no. No importa en qué parte de la fotografía estoy ubicado, dónde está ubicada mi cabeza, en el centro de la fotografía o en la esquina. Reconocimiento de mi cabeza, mi cara debería aparecer independientemente de dónde se encuentren en la imagen. Esto es invariancia, variabilidad de ubicación, que se realiza mediante redes neuronales convolucionales.
- Muy interesante! ¿Puede decirnos las tareas principales en las que se utilizan las redes neuronales convolucionales?
- Las redes neuronales convolucionales se usan bastante estrechamente cuando se trabaja con audio y video, incluidas imágenes médicas. También se utilizan en tecnologías del lenguaje, donde los especialistas utilizan el aprendizaje profundo para comprender y reproducir construcciones del lenguaje. De hecho, hay muchas aplicaciones para esta tecnología, ¡incluso diría que son infinitas! Su tecnología se puede utilizar en finanzas y en cualquier otra área.
"Utilicé redes neuronales convolucionales para analizar imágenes de satélite".
- Genial! La tarea estándar!
- ¿Qué opinas, podemos considerar las redes neuronales convolucionales como algo la última y más avanzada herramienta en el desarrollo del aprendizaje profundo?
- Ja! Ya he aprendido a nunca decir nunca. ¡Siempre habrá algo nuevo y sorprendente!
"¿Entonces todavía tenemos trabajo que hacer?" :)
- Habrá suficiente trabajo!
- excelente! En este curso, solo enseñamos a los futuros pioneros del aprendizaje automático. ¿Tiene algún deseo para nuestros estudiantes antes de que comiencen a construir su primera red neuronal convolucional?
- Aquí hay un hecho interesante para ti. Las redes neuronales convolucionales se inventaron en 1989, ¡y esto es hace mucho tiempo! La mayoría de ustedes ni siquiera nacieron en ese momento, lo que significa que no es el genio del algoritmo lo que importa, sino los datos con los que opera este algoritmo. Vivimos en un mundo donde hay muchos datos para analizar y buscar patrones. Tenemos la capacidad de emular las funciones de la mente humana utilizando esta gran cantidad de datos. Cuando trabaje en redes neuronales convolucionales, intente concentrarse en encontrar los datos correctos y aplicarlos; vea lo que sucede y, a veces, puede ser una verdadera magia, como fue el caso en nuestro caso cuando resolvíamos el problema de detectar el cáncer de piel.
- Genial! Bueno, ¡finalmente vamos a la magia!
Introduccion
En la última lección, aprendimos cómo desarrollar redes neuronales profundas que pueden clasificar imágenes de elementos de vestimenta del conjunto de datos Fashion MNIST.

Los resultados que obtuvimos al trabajar en la red neuronal fueron impresionantes: 88% de precisión de clasificación. ¡Y esto está en unas pocas líneas de código (sin tener en cuenta el código para construir gráficos e imágenes)!
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
NUM_EXAMPLES = 60000 train_dataset = train_dataset.repeat().shuffle(NUM_EXAMPLES).batch(32) test_dataset = test_dataset.batch(32)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/32))
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/32)) print(': ', test_accuracy)
: 0.8782
También experimentamos con el efecto del número de neuronas en capas ocultas y el número de iteraciones de entrenamiento sobre la precisión del modelo. Pero, ¿cómo hacemos que este modelo sea aún mejor y más preciso? Una forma de lograr esto es usar redes neuronales convolucionales, abreviado SNA. SNA muestra una mayor precisión en la resolución de los problemas de clasificación de imágenes que las redes neuronales estándar totalmente conectadas que encontramos en las clases anteriores. Es por esta razón que el SNA se hizo tan popular y fue gracias a ellos que se hizo posible un avance tecnológico en el campo de la visión artificial.
En esta lección, aprenderemos lo fácil que es desarrollar un clasificador SNA desde cero utilizando TensorFlow y Keras. Utilizaremos el mismo conjunto de datos Fashion MNIST que utilizamos en la lección anterior. Al final de esta lección, comparamos la precisión de la clasificación de los elementos de vestimenta de la red neuronal anterior con la red neuronal convolucional de esta lección.
Antes de sumergirse en el desarrollo, vale la pena profundizar un poco más en el principio de funcionamiento de las redes neuronales convolucionales.
Dos conceptos básicos en redes neuronales convolucionales:
- convolución
- operación de submuestreo (agrupación, agrupación máxima)
Echemos un vistazo más de cerca a ellos.
Convolución
En esta parte de nuestra lección, aprenderemos una técnica llamada convolución. Veamos como funciona.
Tome una imagen en tonos de gris y, por ejemplo, imagine que sus dimensiones son de 6 px de altura y 6 px de ancho.

Nuestra computadora interpreta la imagen como una matriz bidimensional de píxeles. Como nuestra imagen está en tonos de gris, el valor de cada píxel estará en el rango de 0 a 255. 0 - negro, 255 - blanco.
En la imagen a continuación vemos una representación de la imagen de 6px x 6px y los valores de píxeles correspondientes:
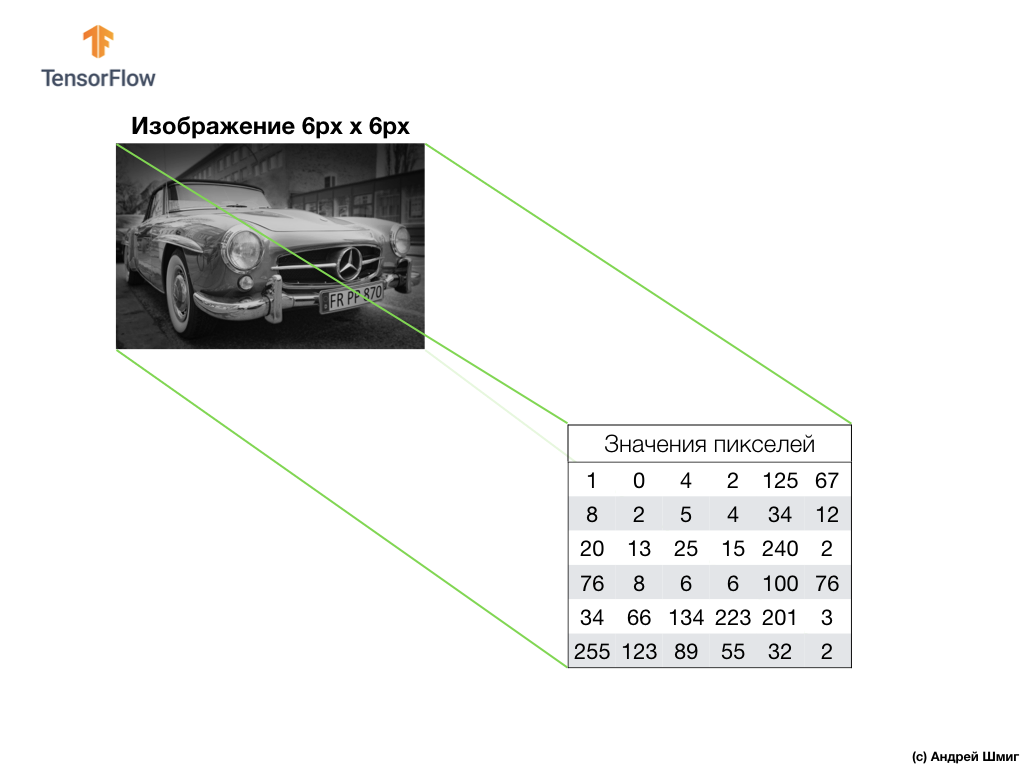
Como ya sabe, antes de trabajar con imágenes, debe normalizar los valores de píxeles: lleve los valores a un intervalo de 0 a 1. Sin embargo, en este ejemplo, para mayor comodidad, guardaremos los valores de píxeles de la imagen y no los normalizaremos.
La esencia de la convolución es crear otro conjunto de valores, que se llama núcleo o filtro. Se puede ver un ejemplo en la imagen a continuación: una matriz de 3 x 3:

Entonces podemos escanear nuestra imagen usando el núcleo. Las dimensiones de nuestra imagen son 6x6px, y los núcleos son 3x3px. La capa convolucional se aplica al núcleo y a cada sección de la imagen de entrada.
Imaginemos que queremos una convolución sobre un píxel con un valor de 25 (3 filas, 3 columnas) y lo primero que hay que hacer es centrar el núcleo sobre este píxel:

En la imagen, la ubicación del núcleo se resalta en amarillo. Ahora veremos solo los valores de píxeles que están en nuestro rectángulo amarillo, cuyos tamaños corresponden a los tamaños de nuestro núcleo de convolución.
Ahora tomamos los valores de píxel de la imagen y el núcleo, multiplicamos cada píxel de la imagen con el píxel correspondiente del núcleo y agregamos todos los valores del producto, y asignamos el valor de píxel resultante a la nueva imagen.

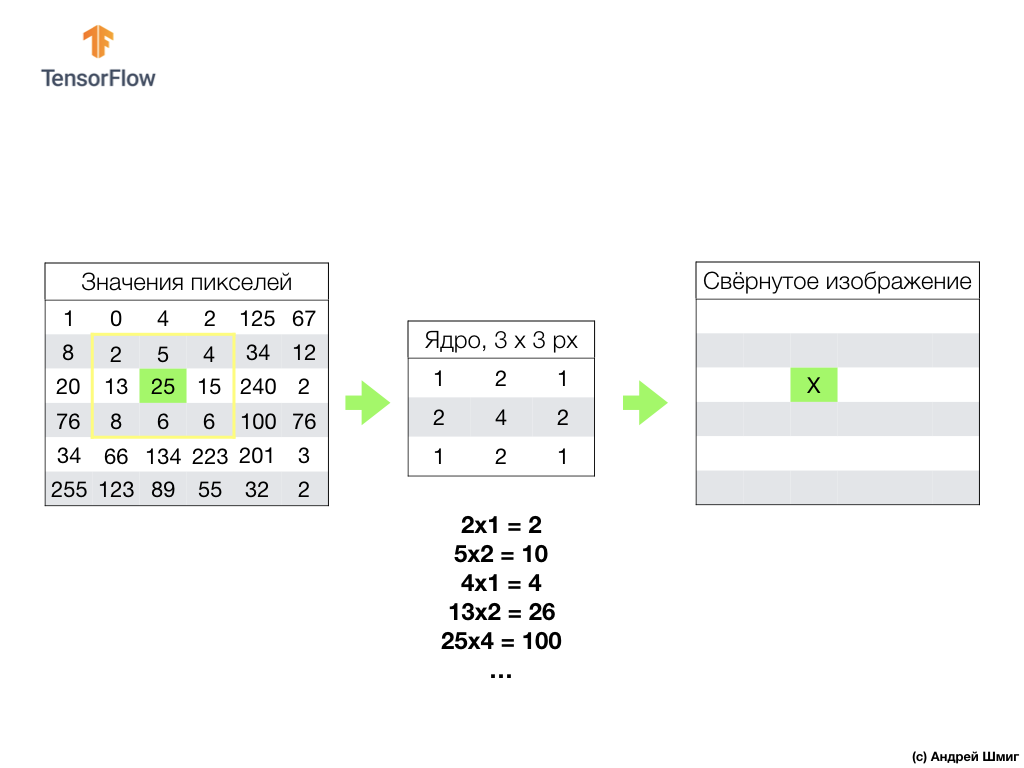

Realizamos una operación similar con todos los píxeles en nuestra imagen. Pero, ¿qué debería pasar con los píxeles en los bordes?
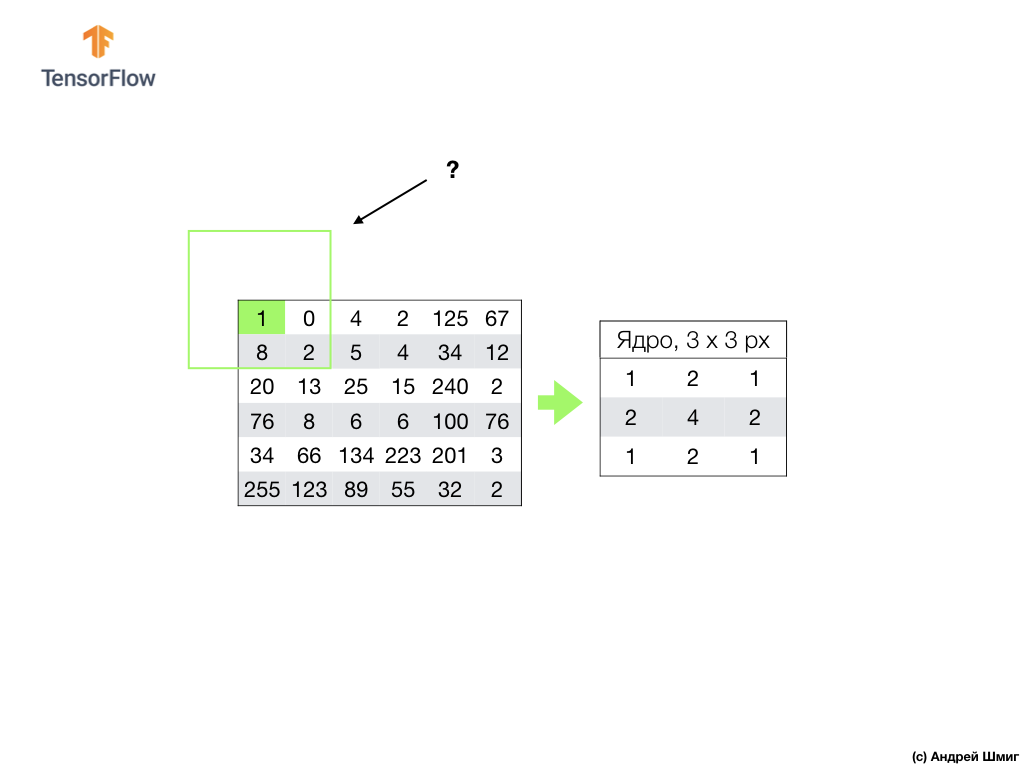
Hay varias soluciones En primer lugar, simplemente podemos ignorar estos píxeles, pero en este caso perderemos información sobre la imagen, lo que puede resultar significativo, y la imagen minimizada será más pequeña que la original. En segundo lugar, podemos simplemente "matar" con valores cero aquellos píxeles cuyos valores centrales están más allá del alcance de la imagen. El proceso se llama alineación.

Ahora que hemos realizado la alineación con valores de píxel cero, podemos calcular el valor del píxel final en la imagen minimizada como antes.
Una convolución es el proceso de aplicar un núcleo (filtro) a cada parte de la imagen de entrada, por analogía con una capa totalmente conectada (capa densa), veremos que la convolución es la misma capa en Keras.
Ahora veamos el segundo concepto de redes neuronales convolucionales: la operación de submuestreo (agrupación, agrupación máxima).
Operación de submuestreo (agrupación, agrupación máxima)
Ahora consideraremos el segundo concepto fundamental que subyace a las redes neuronales convolucionales: la operación de submuestreo (agrupación, agrupación máxima). En palabras simples, una operación de submuestreo es el proceso de comprimir (reducir) una imagen agregando los valores de los bloques de píxeles. Veamos cómo funciona esto en un ejemplo concreto.

Para realizar la operación de submuestreo, debemos decidir sobre dos componentes de este proceso: el tamaño de la muestra (el tamaño de la cuadrícula rectangular) y el tamaño del paso. En este ejemplo, utilizaremos una cuadrícula rectangular de 3x3 y el paso 3. El paso determina el número de píxeles por los cuales la cuadrícula rectangular debe desplazarse al realizar la operación de submuestreo.
Una vez que hayamos decidido el tamaño de la cuadrícula y el tamaño del paso, debemos encontrar el valor máximo de píxeles que cae en la cuadrícula seleccionada. En el ejemplo anterior, los valores 1, 0, 4, 8, 2, 5, 20, 13, 25. entran en la cuadrícula El valor máximo es 25. Este valor se "transfiere" a la nueva imagen. La cuadrícula se desplaza 3 píxeles hacia la derecha y se repite el proceso de seleccionar el valor máximo y transferirlo a una nueva imagen.

Como resultado, se obtendrá una imagen más pequeña en comparación con la imagen de entrada original. En nuestro ejemplo, se obtuvo una imagen que es la mitad del tamaño de nuestra imagen original. El tamaño de la imagen final variará dependiendo de la elección del tamaño de la cuadrícula rectangular y el tamaño del paso.
¡Veamos cómo funcionará esto en Python!
Resumen
Nos familiarizamos con conceptos tales como la convolución y la operación de agrupación máxima.
La convolución es el proceso de aplicar un filtro ("núcleo") a una imagen. La operación de submuestreo por valor máximo es el proceso de reducir el tamaño de una imagen combinando un grupo de píxeles en un solo valor máximo de este grupo.
Como veremos en la parte práctica, la capa convolucional se puede agregar a la red neuronal usando la capa
Conv2D en Keras. Esta capa es similar a la capa Densa y contiene pesos y compensaciones que se someten a optimización (selección).
Conv2D capa
Conv2D también contiene filtros ("núcleos"), cuyos valores también están optimizados. Entonces, en la capa
Conv2D , los valores dentro de la matriz de filtro son las variables que se someten a optimización.
Algunos términos que logramos encontrar:
- SNS - redes neuronales convolucionales. Una red neuronal que contiene al menos una capa convolucional. Un SNA típico contiene otras capas, como capas de muestra y capas completamente conectadas.
- La convolución es el proceso de aplicar un filtro ("núcleo") a una imagen.
- Un filtro (núcleo) es una matriz de menor tamaño que los datos de entrada, destinada a convertir datos de entrada en bloques.
- La alineación es el proceso de agregar, a menudo valores cero, a los bordes de una imagen.
- La operación de submuestreo es el proceso de reducir el tamaño de una imagen a través del muestreo. Existen varios tipos de capas de submuestreo, por ejemplo, una capa de submuestreo promediada (muestreo de un valor promedio), sin embargo, una submuestreo por el valor máximo se usa con mayor frecuencia.
- El submuestreo por el valor máximo es el proceso de submuestreo, durante el cual muchos valores se convierten en un valor único, el máximo entre el muestreo.
- Paso : el número de píxeles de desplazamiento por el filtro (núcleo) en la imagen.
- Muestreo (disminución de resolución) : proceso de reducción del tamaño de la imagen.
CoLab: clasificación de elementos de indumentaria Fashion MNIST utilizando una red neuronal convolucional
¡Nos rodearon alrededor de un dedo! Tiene sentido realizar esta parte práctica solo después de que
se haya completado la
parte anterior : todo el código, excepto un bloque, sigue siendo el mismo. La estructura de nuestra red neuronal está cambiando, y estas son cuatro líneas adicionales para capas neuronales convolucionales y capas de submuestra en el valor máximo (agrupación máxima).
model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, (3,3), padding='same', activation=tf.nn.relu, input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D((2, 2), strides=2), tf.keras.layers.Conv2D(64, (3,3), padding='same', activation=tf.nn.relu), tf.keras.layers.MaxPooling2D((2, 2), strides=2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
Todas las explicaciones detalladas de cómo trabajar, prometen darnos en la siguiente parte: 4 partes.
Oh si La precisión del modelo en la etapa de entrenamiento llegó a ser igual al 97% (el modelo "reentrenado" en
epochs=10 ), y cuando se ejecutó el conjunto de datos para las pruebas mostró exactamente el 91%. Un aumento notable en la precisión en relación con la arquitectura anterior, donde utilizamos solo capas completamente conectadas: 88%.
Resumen
En esta parte de la lección, estudiamos un nuevo tipo de red neuronal: la red neuronal convolucional. Nos familiarizamos con términos como "convolución" y "operación de agrupación máxima", desarrollamos y capacitamos una red neuronal convolucional desde cero. Como resultado, vimos que nuestra red neuronal convolucional produce más precisión que la red neuronal que desarrollamos en la última lección.
PD Nota del autor de la traducción.
El curso se llama "Introducción al aprendizaje profundo utilizando TensorFlow", por lo que no nos quejamos de la falta de explicaciones detalladas del principio de las redes neuronales convolucionales (capas): los próximos dos artículos serán sobre el principio de la red neuronal convolucional y su estructura interna. (los artículos no se relacionan con el curso, pero fueron recomendados por los participantes de StackOverflow para comprender mejor lo que está sucediendo).
... y un llamado a la acción estándar: regístrese, ponga un plus y comparta :)
YouTubeTelegramaVKontakte