Hasta la fecha, el servicio Bitrix24 no tiene cientos de gigabits de tráfico, no hay una gran flota de servidores (aunque, por supuesto, hay muchos existentes). Pero para muchos clientes, es la herramienta principal para trabajar en la empresa, es una aplicación crítica para el negocio real. Por lo tanto, cayendo, bueno, de ninguna manera. Pero, ¿qué pasa si la caída sucedió, pero el servicio "se rebeló" tan rápido que nadie notó nada? ¿Y cómo logra implementar la conmutación por error sin perder la calidad del trabajo y la cantidad de clientes? Alexander Demidov, director de servicios en la nube de Bitrix24, contó a nuestro blog sobre cómo ha evolucionado el sistema de respaldo durante los 7 años de existencia del producto.

“En forma de SaaS, lanzamos Bitrix24 hace 7 años. La principal dificultad, probablemente, fue la siguiente: antes de lanzarse en público en forma de SaaS, este producto existía simplemente en el formato de una solución en caja. Los clientes nos lo compraron, lo colocaron en sus servidores, configuraron un portal corporativo, una solución común para la comunicación de los empleados, el almacenamiento de archivos, la gestión de tareas, CRM, eso es todo. Y para 2012, decidimos que queríamos lanzarlo como SaaS, administrándolo nosotros mismos, brindando tolerancia a fallas y confiabilidad. Adquirimos experiencia en el proceso, porque hasta entonces simplemente no lo teníamos: solo éramos fabricantes de software, no proveedores de servicios.
Al lanzar el servicio, entendimos que lo más importante es garantizar la tolerancia a fallas, la confiabilidad y la disponibilidad constante del servicio, porque si tiene un sitio regular simple, una tienda, por ejemplo, y se cayó de usted y yace una hora, solo usted mismo sufre, pierde pedidos , pierde clientes, pero para su propio cliente, para él esto no es muy crítico. Estaba molesto, por supuesto, pero fue y compró en otro sitio. Y si esta es una aplicación con la que todo el trabajo dentro de la empresa, las comunicaciones y las soluciones están vinculadas, lo más importante es ganarse la confianza de los usuarios, es decir, no decepcionarlos y no caer. Porque todo el trabajo puede levantarse si algo en el interior no funciona.
Bitrix.24 como SaaS
El primer prototipo que armamos un año antes del lanzamiento público, en 2011. Reunidos en aproximadamente una semana, mirados, retorcidos, incluso estaba trabajando. Es decir, fue posible ingresar al formulario, ingresar el nombre del portal allí, se estaba desplegando un nuevo portal, se estaba creando una base de usuarios. Lo analizamos, evaluamos el producto en principio, lo apagamos y lo finalizamos un año después. Debido a que teníamos una gran tarea: no queríamos crear dos bases de código diferentes, no queríamos admitir un producto en caja separado, soluciones en la nube por separado; queríamos hacer todo esto dentro del mismo código.

Una aplicación web típica en ese momento es un servidor en el que se está ejecutando algún código php, la base mysql, los archivos se están descargando, los documentos, las imágenes se colocan en la carga de papá, bueno, todo funciona. Por desgracia, es imposible ejecutar un servicio web críticamente sostenible en esto. La caché distribuida no es compatible allí, la replicación de la base de datos no es compatible.
Formulamos los requisitos: esta capacidad para ubicarse en diferentes ubicaciones, para admitir la replicación, idealmente para ubicarse en diferentes centros de datos distribuidos geográficamente. Separe la lógica del producto y, de hecho, el almacenamiento de datos. Ser capaz de escalar dinámicamente de acuerdo con la carga, generalmente hacer la estática. A partir de estas consideraciones, de hecho, había requisitos para el producto, que acabamos de desarrollar durante el año. Durante este tiempo, en una plataforma que resultó estar unificada, para soluciones en caja, para nuestro propio servicio, brindamos soporte para las cosas que necesitábamos. Soporte para la replicación de mysql a nivel del producto en sí: es decir, el desarrollador que escribe el código no piensa en cómo se distribuirán sus solicitudes, usa nuestra API y podemos distribuir correctamente las solicitudes de escritura y lectura entre maestros y esclavos.
Hicimos soporte a nivel de producto para varias tiendas de objetos en la nube: almacenamiento de google, amazon s3, - plus, soporte para open stack swift. Por lo tanto, fue conveniente tanto para nosotros como un servicio como para los desarrolladores que trabajan con una solución en caja: si solo usan nuestra API para el trabajo, no piensan dónde se guardará el archivo, ya sea localmente en el sistema de archivos o en el almacenamiento de archivos de objetos .
Como resultado, decidimos inmediatamente que reservaríamos al nivel de un centro de datos completo. En 2012, lanzamos completamente en Amazon AWS, porque ya teníamos experiencia con esta plataforma: nuestro propio sitio web estaba alojado allí. Nos atrajo el hecho de que en cada región de Amazon hay varias zonas de acceso; de hecho, en su terminología, varios centros de datos que son más o menos independientes entre sí y nos permiten reservar a nivel de un centro de datos completo: si falla repentinamente, las bases de datos master-master se replican, los servidores de aplicaciones web se reservan y la estática se mueve al almacenamiento de objetos s3. La carga está equilibrada, en ese momento el elba amazónica, pero un poco más tarde llegamos a nuestros propios equilibradores, porque necesitábamos una lógica más compleja.
Lo que querían, lo consiguieron ...
Todas las cosas básicas que queríamos proporcionar, la tolerancia a fallas de los servidores, aplicaciones web, bases de datos, todo funcionó bien. El escenario más simple: si algunas de las aplicaciones web fallan, entonces todo es simple: se desactivan de la balanza.

El equilibrador de la máquina (entonces era un elfo amazónico) que bloqueó la máquina como no saludable, apagó la distribución de carga en ellos. El escalado automático de la Amazonía funcionó: cuando la carga creció, se agregaron autos nuevos al grupo de escalado automático, la carga se distribuyó a los autos nuevos, todo estaba bien. Con nuestros equilibradores, la lógica es más o menos la misma: si algo le sucede al servidor de aplicaciones, eliminamos las solicitudes, eliminamos estas máquinas, iniciamos nuevas y seguimos trabajando. El esquema para todos estos años ha cambiado un poco, pero continúa funcionando: es simple, comprensible y no hay dificultades con esto.
Trabajamos en todo el mundo, la carga máxima de clientes es completamente diferente y, en el buen sentido, deberíamos poder realizar ciertos trabajos de mantenimiento con cualquier componente de nuestro sistema en cualquier momento, de forma invisible para los clientes. Por lo tanto, tenemos la oportunidad de cerrar la base de datos del trabajo, redistribuyendo la carga en el segundo centro de datos.
¿Cómo funciona todo? - Cambiamos el tráfico a un centro de datos en funcionamiento: si se trata de un accidente en un centro de datos, entonces completamente, si es nuestro trabajo planificado con cualquier base, entonces formamos parte del tráfico que sirve a estos clientes, cambiamos a un segundo centro de datos, se detiene replicación Si necesita máquinas nuevas para aplicaciones web, a medida que aumenta la carga en el segundo centro de datos, se inician automáticamente. Terminamos el trabajo, se restaura la replicación y devolvemos toda la carga. Si necesitamos reflejar algún trabajo en el segundo DC, por ejemplo, instalar actualizaciones del sistema o cambiar la configuración en la segunda base de datos, entonces, en general, repetimos lo mismo, al revés. Y si esto es un accidente, entonces hacemos todo trivialmente: en el sistema de monitoreo usamos el mecanismo de manejo de eventos. Si varias comprobaciones funcionan para nosotros y el estado se vuelve crítico, entonces se inicia este controlador, un controlador que puede ejecutar esta o aquella lógica. Para cada base de datos, hemos registrado qué servidor tiene conmutación por error y dónde debe cambiar el tráfico si no está disponible. Nosotros, como se ha desarrollado históricamente, utilizamos de una forma u otra nagios o cualquiera de sus tenedores. En principio, existen mecanismos similares en casi cualquier sistema de monitoreo, todavía no estamos usando algo más complicado, pero quizás algún día lo hagamos. Ahora el monitoreo se activa por inaccesibilidad y tiene la capacidad de cambiar algo.
¿Hemos reservado todo?
Tenemos muchos clientes de los EE. UU., Muchos clientes de Europa, muchos clientes que están más cerca del Este: Japón, Singapur, etc. Por supuesto, una gran proporción de clientes en Rusia. Es decir, el trabajo está lejos de estar en una región. Los usuarios desean una respuesta rápida, hay requisitos para observar varias leyes locales, y dentro de cada región que reservamos para dos centros de datos, además hay algunos servicios adicionales que, nuevamente, son convenientes para colocar dentro de una región, para los clientes que están en esta región de trabajo. Los controladores REST, los servidores de autorización, son menos críticos para el cliente en general, puede cambiar entre ellos con un pequeño retraso aceptable, pero no desea inventar bicicletas, cómo monitorearlas y qué hacer con ellas. Por lo tanto, al máximo intentamos utilizar las soluciones existentes y no desarrollar cierta competencia en productos adicionales. Y en algún lugar, utilizamos trivialmente el cambio en el nivel dns, y determinamos la vivacidad del servicio con el mismo dns. Amazon tiene un servicio de Route 53, pero no solo es dns en el que puede grabar todo, es mucho más flexible y conveniente. A través de él, puede crear servicios geo-distribuidos con geolocalizaciones, cuando lo usa para determinar de dónde vino el cliente y darles ciertos registros; con él puede construir arquitecturas de conmutación por error. Las mismas comprobaciones de estado se configuran en la ruta 53, especifica puntos finales que se supervisan, establece métricas y especifica qué protocolos determinan la vida útil del servicio: tcp, http, https; establecer la frecuencia de las verificaciones que determinan si el servicio está en vivo o no. Y en el dns mismo, prescribe qué será primario, qué será secundario, dónde cambiar si se activa la verificación de estado dentro de la ruta 53. Todo esto se puede hacer con otras herramientas, pero lo que es más conveniente: lo configuramos una vez y luego no pensamos en cómo hacemos cheques, cómo cambiamos: todo funciona por sí solo.
El primer "pero" : ¿cómo y cómo reservar la ruta 53? ¿Ocurre si algo le sucede a él? Afortunadamente, nunca hemos pisado este rastrillo, pero nuevamente, frente a mí, tendré una historia de por qué pensamos que todavía tenemos que reservar. Aquí ponemos la paja de antemano. Varias veces al día hacemos una descarga completa de todas las zonas que tenemos en la ruta 53. La API de Amazon les permite enviarlos de manera segura a JSON, y hemos creado varios servidores redundantes donde los convertimos, los cargamos en forma de configuraciones y, en términos generales, tenemos una configuración de respaldo. En cuyo caso podemos implementarlo rápidamente de forma manual, no perderemos los datos de configuración de dns.
El segundo "pero" : ¿qué no está reservado en esta imagen? El equilibrador mismo! Hemos hecho que la distribución de clientes por región sea muy simple. Tenemos dominios bitrix24.ru, bitrix24.com, .de, ahora hay 13 dominios diferentes que funcionan en zonas muy diferentes. Hemos llegado a lo siguiente: cada región tiene sus propios equilibradores. Es más conveniente distribuir por región, dependiendo de dónde esté la carga máxima en la red. Si se trata de una falla a nivel de cualquier equilibrador, simplemente se retira del servicio y se elimina de dns. Si se produce algún tipo de problema con un grupo de equilibradores, entonces se reservan en otros sitios, y el cambio entre ellos se realiza utilizando la misma ruta53, porque debido a un ttl corto, el cambio se produce durante un máximo de 2, 3, 5 minutos.
El tercer "pero" : ¿qué aún no se ha reservado? S3, a la derecha. Nosotros, colocando los archivos que los usuarios almacenan en s3, creíamos sinceramente que era una perforación blindada y que no había necesidad de reservar nada allí. Pero la historia muestra lo que sucede de manera diferente. En general, Amazon describe S3 como un servicio fundamental, porque Amazon mismo usa S3 para almacenar imágenes de máquinas, configuraciones, imágenes AMI, instantáneas ... Y si s3 falla, como sucedió en estos 7 años, cuánto bitrix24 hemos estado usando, es seguido por un ventilador saca un montón de todo: inaccesibilidad para iniciar máquinas virtuales, mal funcionamiento de la API, etc.
Y S3 puede caer, sucedió una vez. Por lo tanto, llegamos al siguiente esquema: hace unos años no había ningún almacenamiento público de objetos graves en Rusia, y estábamos considerando la opción de hacer algo por nuestra cuenta ... Afortunadamente, no comenzamos a hacer esto, porque investigaríamos ese examen que no hicimos. poseer, y probablemente lo habría hecho. Ahora Mail.ru tiene almacenes compatibles con s3, Yandex lo tiene y varios proveedores aún lo tienen. Como resultado, llegamos a la conclusión de que queremos tener, en primer lugar, una copia de seguridad y, en segundo lugar, la capacidad de trabajar con copias locales. Para una región rusa en particular, utilizamos el servicio Mail.ru Hotbox, que es api compatible con s3. No necesitábamos modificaciones serias en el código dentro de la aplicación, e hicimos el siguiente mecanismo: en s3 hay disparadores que funcionan en la creación / eliminación de objetos, Amazon tiene un servicio como Lambda: esta es la ejecución de código sin servidor, que se ejecutará solo cuando se activan ciertos desencadenantes.
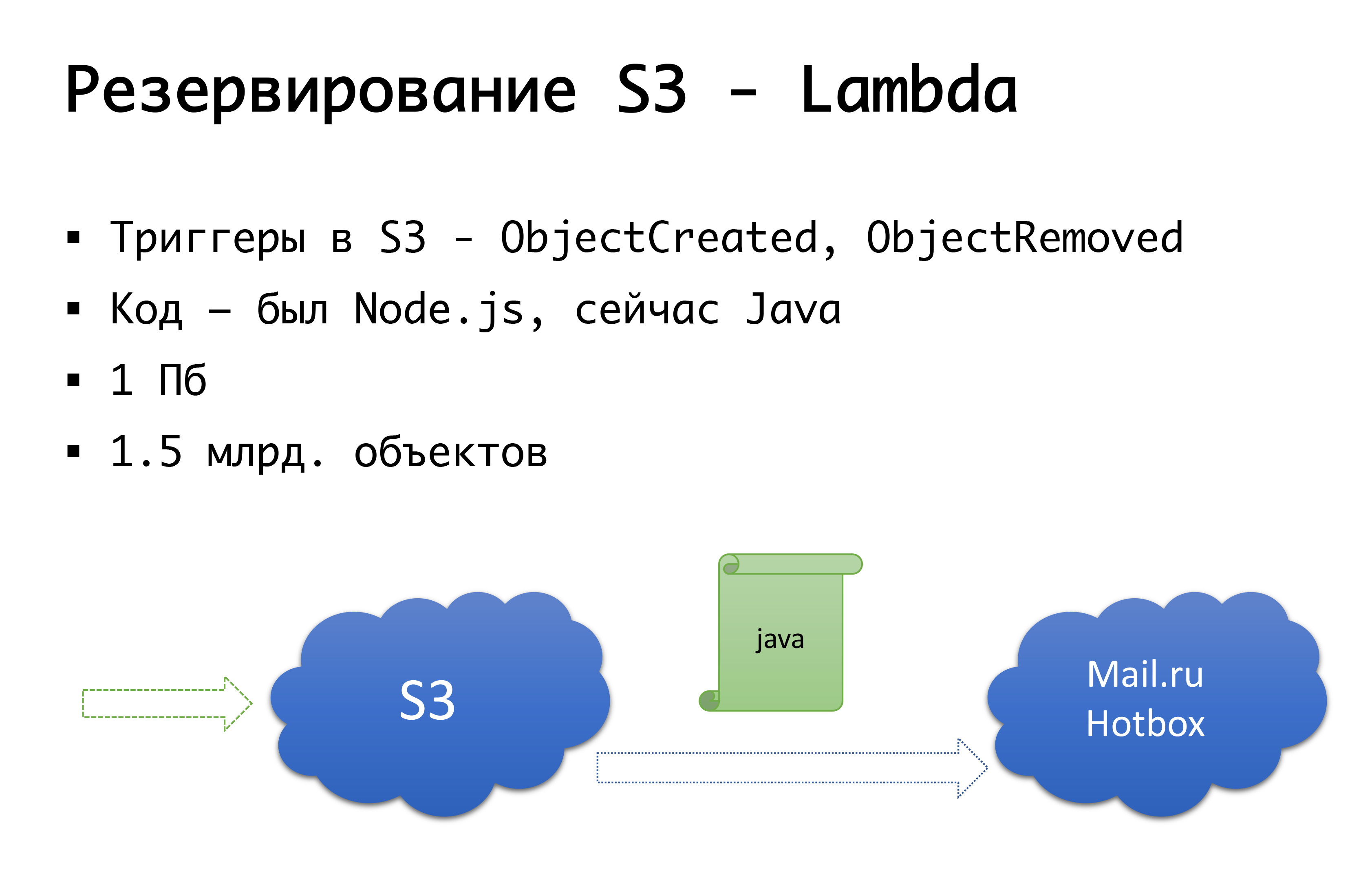
Lo hicimos de manera muy simple: si nuestro disparador se dispara, ejecutamos el código que copiará el objeto al repositorio Mail.ru. Para comenzar a trabajar completamente con copias locales de datos, también necesitamos sincronización inversa, de modo que los clientes ubicados en el segmento ruso puedan trabajar con almacenamiento más cercano a ellos. El correo está a punto de completar los desencadenantes en su repositorio: será posible realizar una sincronización inversa ya a nivel de infraestructura, pero por ahora lo estamos haciendo a nivel de nuestro propio código. Si vemos que el cliente ha colocado algún tipo de archivo, entonces a nuestro nivel de código colocamos el evento en la cola, lo procesamos y hacemos la replicación inversa. ¿Por qué es malo? Si tenemos algún tipo de trabajo con nuestros objetos fuera de nuestro producto, es decir, por algún medio externo, no lo tendremos en cuenta. Por lo tanto, esperamos hasta el final cuando aparecen los desencadenantes en el nivel de almacenamiento, de modo que no importa desde dónde ejecutamos el código, el objeto que nos llegó se copia de la otra manera.
A nivel de código, para cada cliente, ambos repositorios están registrados: uno se considera el principal, el otro es una copia de seguridad. Si todo está bien, trabajamos con el almacenamiento que está más cerca de nosotros: es decir, nuestros clientes que están en Amazon, trabajan con S3, y aquellos que trabajan en Rusia, trabajan con Hotbox. Si la casilla de verificación funciona, la conmutación por error debería conectarse con nosotros y cambiaremos los clientes a otro almacenamiento. Podemos establecer este indicador de forma independiente por región y podemos cambiarlos de un lado a otro. En la práctica, aún no lo hemos usado, pero hemos imaginado este mecanismo y creemos que algún día necesitaremos y usaremos este mismo interruptor. Una vez que ya ha sucedido.
Ah, y tu Amazon escapó ...
Este abril es el aniversario del inicio de las cerraduras de Telegram en Rusia. El proveedor más afectado que vino debajo de esto es Amazon. Y, desafortunadamente, las compañías rusas que trabajaron en todo el mundo sufrieron más.
Si la empresa es global y Rusia es un segmento muy pequeño, 3-5%, bueno, de una forma u otra, puede donarlos.
Si se trata de una empresa puramente rusa, estoy seguro de que necesita ubicarse localmente, bueno, es solo que los propios usuarios serán convenientes, cómodos, habrá menos riesgos.
¿Y si esta es una empresa que trabaja a nivel mundial, y tiene aproximadamente partes iguales de clientes de Rusia y de algún lugar del mundo? La conectividad de los segmentos es importante, y de todos modos deben trabajar entre ellos.
A finales de marzo de 2018, Roskomnadzor envió una carta a los operadores más grandes indicando que planean bloquear varios millones de ip de Amazon para bloquear ... el mensajero Zello. Gracias a estos mismos proveedores, filtraron con éxito la carta a todos, y se entendió que la conectividad con Amazon podría desmoronarse. Era viernes, nos encontramos con los colegas de los servidores.ru en pánico, con las palabras: "Amigos, necesitamos varios servidores que no estarán en Rusia, no en Amazon, sino, por ejemplo, en algún lugar de Amsterdam". para poder, al menos de alguna manera, poner nuestra propia VPN y proxy para algunos puntos finales en los que no podemos influir en absoluto, por ejemplo, los endponts del mismo s3, no podemos intentar aumentar un nuevo servicio y obtener otra ip, Todavía necesitas llegar allí. En unos pocos días, configuramos estos servidores, los elevamos y, en general, nos preparamos para el inicio de los bloqueos. Es curioso que el ILV, mirando la exageración y el pánico elevado, dijo: "No, no bloquearemos nada ahora". (Pero esto es exactamente hasta el momento en que comenzaron a bloquear los telegramas). Habiendo configurado las opciones de derivación y dándonos cuenta de que no entraron en la cerradura, nosotros, sin embargo, no desmantelamos todo el asunto. Entonces, por si acaso.

Y en 2019, todavía vivimos en condiciones de cerraduras. Miré anoche: alrededor de un millón de ip siguen bloqueados. Es cierto, Amazon casi completamente desbloqueado, en el pico alcanzó 20 millones de direcciones ... En general, la realidad es que la conectividad, buena conectividad, puede no serlo. De repente Puede que no sea por razones técnicas: incendios, excavadoras, todo eso. O, como hemos visto, no del todo técnico. Por lo tanto, alguien grande y grande, con su propio AS-kami, probablemente pueda dirigirlo de otras maneras: conexión directa y otras cosas ya están en el nivel l2. Pero en una versión simple, al igual que nosotros o incluso más pequeña, puede, por si acaso, tener redundancia a nivel de servidores criados en otros lugares, configurados por adelantado vpn, proxy, con la capacidad de cambiar rápidamente las configuraciones en aquellos segmentos que tiene conectividad crítica . Esto nos fue útil más de una vez, cuando se iniciaron los bloqueos de Amazon, dejamos pasar el tráfico S3 en el peor de los casos, pero gradualmente todo salió mal.
¿Y cómo reservar ... todo el proveedor?
Ahora no tenemos escenario en caso de falla de toda la Amazonía. Tenemos un escenario similar para Rusia. Nosotros en Rusia fuimos alojados por un proveedor, de quien elegimos tener varios sitios. Y hace un año nos encontramos con un problema: a pesar de que estos son dos centros de datos, es posible que ya haya problemas a nivel de la configuración de red del proveedor que afectarán a ambos centros de datos de todos modos. Y podemos obtener inaccesibilidad en ambos sitios. Por supuesto, eso es lo que pasó. Eventualmente redefinimos la arquitectura interior. No ha cambiado mucho, pero para Rusia ahora tenemos dos sitios, que no son un proveedor, sino dos diferentes. Si uno de ellos falla, podemos cambiar a otro.
Hipotéticamente, estamos considerando que Amazon reserve al nivel de otro proveedor; tal vez Google, tal vez alguien más ... Pero hasta ahora hemos observado en la práctica que si Amazon se bloquea al mismo nivel de zona de disponibilidad, los bloqueos a nivel de toda una región son bastante raros. Por lo tanto, teóricamente tenemos la idea de que, tal vez, haremos una reserva "Amazon no es Amazon", pero en la práctica esto aún no existe.
Algunas palabras sobre automatización
¿Siempre necesitas automatización? Es apropiado recordar el efecto Dunning-Krueger. En el eje x, nuestro conocimiento y experiencia, que estamos ganando, y en el eje y, confianza en nuestras acciones. Al principio no sabemos nada y no estamos del todo seguros. Entonces sabemos un poco y nos volvemos más seguros: este es el llamado "pico de la estupidez", está bien ilustrado por la imagen "demencia y coraje". Además, ya hemos aprendido un poco y estamos listos para la batalla. Luego pisamos un rastrillo mega serio, caemos en un valle de desesperación cuando parecemos saber algo, pero en realidad no sabemos mucho. Luego, a medida que adquieres experiencia, nos volvemos más seguros.
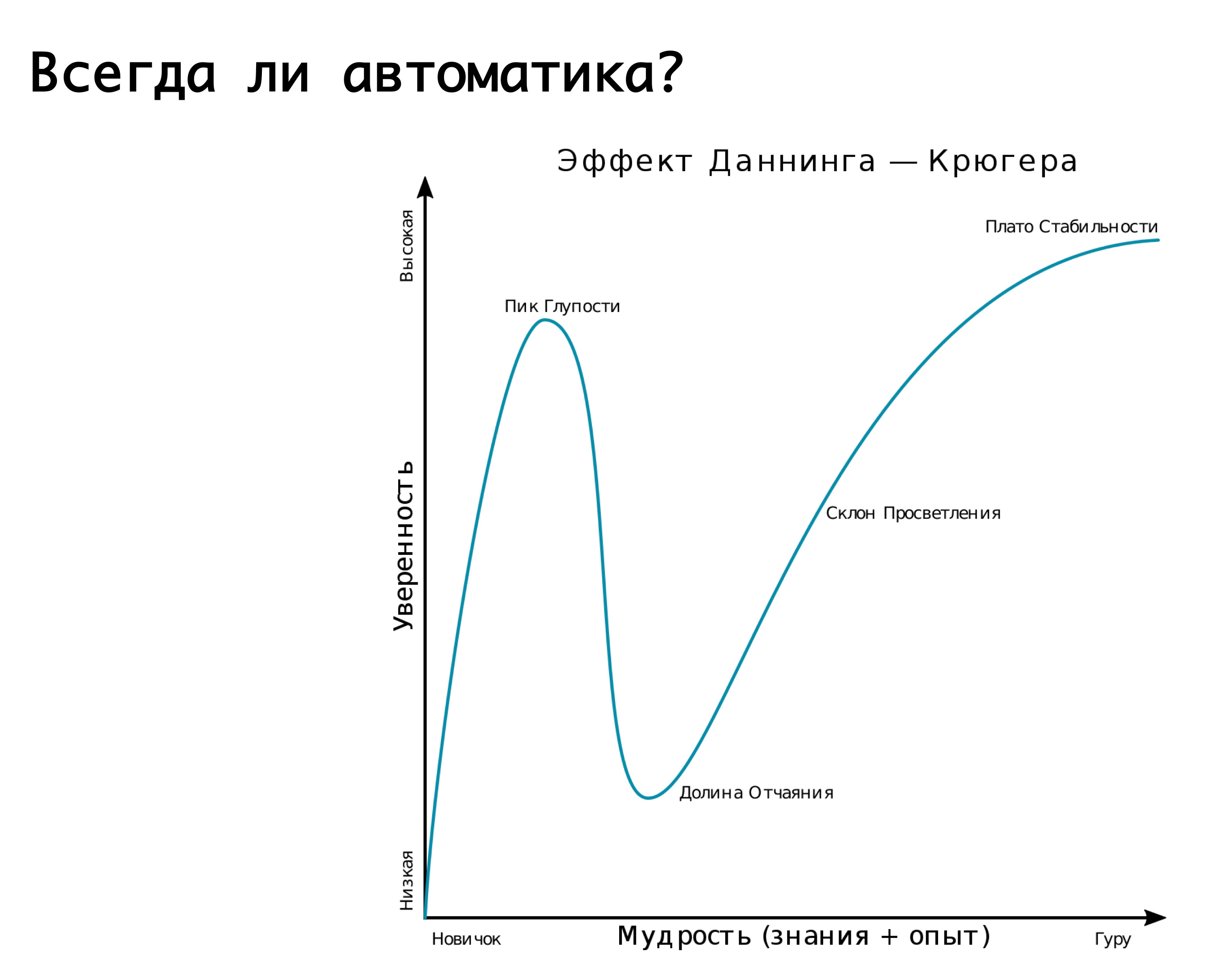
Este gráfico describe muy bien nuestra lógica acerca de varios cambios automáticos a uno u otro accidente. — , . , , , . -: false positive, - , , -, . , - — . , . , . Pero! , , , , , , …
Conclusión
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
Un compromiso razonable entre el perfeccionismo y las fuerzas reales, el tiempo, el dinero que puede gastar en el esquema que eventualmente tendrá.Este texto es una versión complementada y ampliada del informe de Alexander Demidov en la conferencia Uptime día 4 .