Hola, estoy desarrollando aplicaciones para el DBMS de
Tarantool . Esta es una plataforma desarrollada por Mail.ru Group que combina un DBMS de alto rendimiento y un servidor de aplicaciones en el idioma Lua. La alta velocidad de las soluciones basadas en Tarantool se logra, en particular, al admitir el modo DBMS en memoria y la capacidad de ejecutar la lógica de la aplicación empresarial en un solo espacio de direcciones con datos. Esto asegura la persistencia de los datos mediante transacciones ACID (se mantiene un registro WAL en el disco). Tarantool tiene soporte de replicación y fragmentación incorporado. A partir de la versión 2.1, se admiten consultas SQL. Tarantool es de código abierto y tiene licencia bajo el BSD simplificado. También hay una versión comercial de Enterprise.
 Siente el poder! (... también conocido como disfrutar de la actuación)
Siente el poder! (... también conocido como disfrutar de la actuación)Todo lo anterior hace de Tarantool una plataforma atractiva para crear aplicaciones de bases de datos altamente cargadas. En tales aplicaciones, la replicación de datos a menudo se hace necesaria.
Como se mencionó anteriormente, Tarantool tiene replicación de datos incorporada. El principio de su trabajo es la ejecución secuencial en réplicas de todas las transacciones contenidas en el registro del asistente (WAL). Típicamente, dicha replicación (la llamaremos de
bajo nivel a continuación) se usa para proporcionar tolerancia a fallas de la aplicación y / o para distribuir la carga de lectura entre los nodos del clúster.
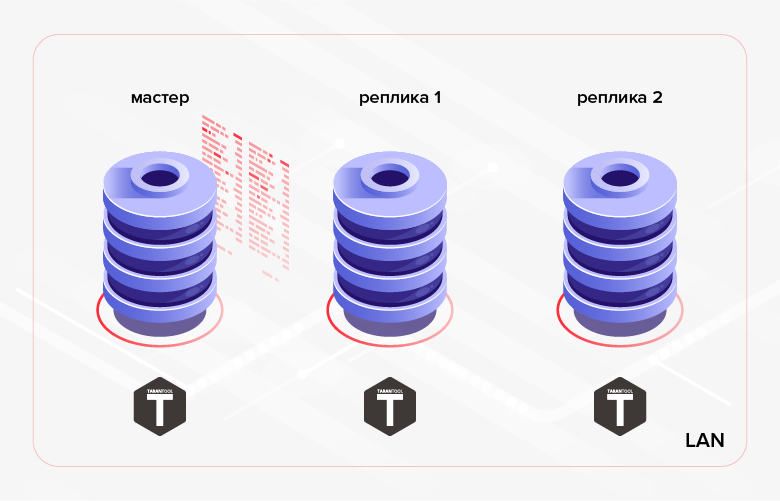 Fig. 1. Replicación dentro del clúster
Fig. 1. Replicación dentro del clústerUn ejemplo de un escenario alternativo es la transferencia de datos creados en una base de datos a otra base de datos para su procesamiento / monitoreo. En el último caso, una solución más conveniente puede ser utilizar
la replicación de
alto nivel : la replicación de datos en el nivel de lógica de negocios de la aplicación. Es decir No utilizamos una solución lista para usar integrada en el DBMS, pero por nuestra cuenta implementamos la replicación dentro de la aplicación que estamos desarrollando. Este enfoque tiene ventajas y desventajas. Enumeramos los pros.
1. Ahorre tráfico:
- no puede transferir todos los datos, sino solo una parte de ellos (por ejemplo, puede transferir solo algunas tablas, algunas de sus columnas o registros que cumplan un determinado criterio);
- A diferencia de la replicación de bajo nivel, que se realiza de forma continua en modo asíncrono (implementado en la versión actual de Tarantool - 1.10) o síncrono (para implementarse en versiones futuras de Tarantool), la replicación de alto nivel puede realizarse por sesiones (es decir, la aplicación primero realiza la sincronización de datos - sesión de intercambio datos, entonces hay una pausa en la replicación, después de lo cual ocurre la próxima sesión de intercambio, etc.);
- Si el registro ha cambiado varias veces, puede transferir solo su última versión (a diferencia de la replicación de bajo nivel, en la que todos los cambios realizados en el asistente se reproducirán secuencialmente en las réplicas).
2. No hay dificultades con la implementación del intercambio a través de HTTP, que le permite sincronizar bases de datos remotas.
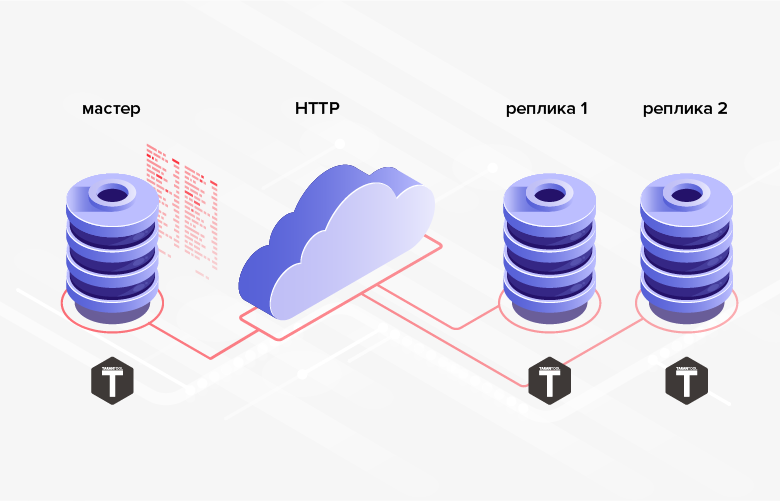 Fig. 2. replicación HTTP
Fig. 2. replicación HTTP3. Las estructuras de la base de datos entre las cuales se transmiten los datos no tienen que ser las mismas (además, en el caso general, incluso es posible utilizar diferentes DBMS, lenguajes de programación, plataformas, etc.).
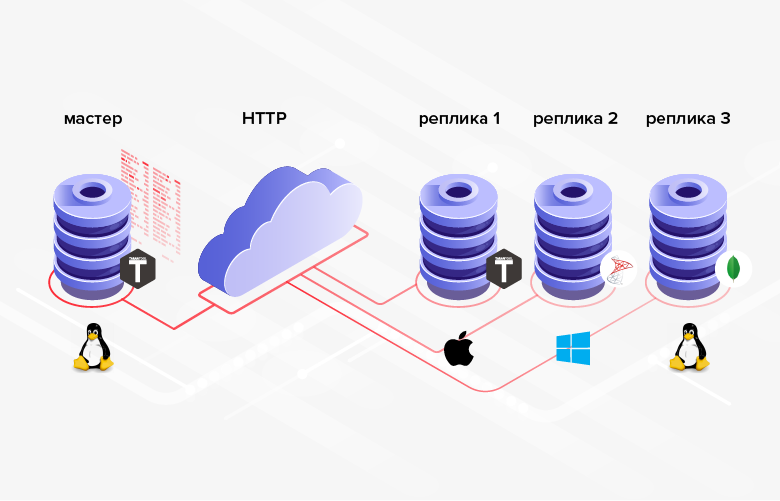 Fig. 3. Replicación en sistemas heterogéneos.
Fig. 3. Replicación en sistemas heterogéneos.La desventaja es que, en promedio, la programación es más complicada / más costosa que la configuración, y en lugar de configurar la funcionalidad incorporada, tendrá que implementar la suya.
Si en su situación las ventajas anteriores desempeñan un papel decisivo (o son una condición necesaria), entonces tiene sentido utilizar la replicación de alto nivel. Consideremos varias formas de implementar la replicación de datos de alto nivel en el DBMS de Tarantool.
Minimización del tráfico
Por lo tanto, uno de los beneficios de la replicación de alto nivel es el ahorro de tráfico. Para que esta ventaja se manifieste completamente, es necesario minimizar la cantidad de datos transmitidos durante cada sesión de intercambio. Por supuesto, uno no debe olvidar que al final de la sesión el receptor de datos debe estar sincronizado con la fuente (al menos para la parte de los datos que está involucrada en la replicación).
¿Cómo minimizar la cantidad de datos transferidos durante la replicación de alto nivel? La solución "en la frente" puede ser la selección de datos por fecha y hora. Para hacer esto, puede usar el campo de fecha y hora que ya se encuentra en la tabla (si corresponde). Por ejemplo, un documento "orden" puede tener un campo "tiempo requerido para la ejecución de la orden" -
delivery_time . El problema con esta solución es que los valores en este campo no tienen que estar en la secuencia correspondiente a la creación de órdenes. Por lo tanto, no podemos recordar el valor máximo del campo
delivery_time transmitido durante la sesión de intercambio anterior, y en la siguiente sesión de intercambio, seleccione todos los registros con un valor más alto del campo
delivery_time . En el intervalo entre sesiones de intercambio, se podrían agregar registros con un valor menor del campo
delivery_time . Además, el pedido podría sufrir cambios que, sin embargo, no afectaron el campo
delivery_time . En ambos casos, los cambios no se transmitirán desde la fuente al receptor. Para resolver estos problemas, necesitaremos transmitir datos "superpuestos". Es decir durante cada sesión de intercambio, transferiremos todos los datos con un valor de campo
delivery_time que exceda algún punto en el pasado (por ejemplo, N horas desde el momento actual). Sin embargo, es obvio que para sistemas grandes este enfoque es muy redundante y puede reducir los ahorros de tráfico que buscamos. Además, la tabla transmitida puede no tener un campo de fecha y hora.
Otra solución, más compleja en términos de implementación, es acusar recibo de los datos. En este caso, en cada sesión de intercambio, se transmiten todos los datos, cuyo recibo no ha sido confirmado por el destinatario. Para la implementación, debe agregar una columna booleana a la tabla de origen (por ejemplo,
is_transferred ). Si el receptor confirma la recepción del registro, el campo correspondiente se establece en
true , después de lo cual el registro ya no participa en los intercambios. Esta opción de implementación tiene las siguientes desventajas. En primer lugar, para cada registro transferido, es necesario generar y enviar una confirmación. En términos generales, esto puede ser comparable a duplicar la cantidad de datos transferidos y a duplicar el número de viajes de ida y vuelta. En segundo lugar, no hay posibilidad de enviar el mismo registro a varios receptores (el primer receptor confirmará el recibo por sí mismo y por todos los demás).
El método, sin las desventajas anteriores, es agregar columnas a la tabla que se transmitirá para rastrear los cambios en sus filas. Dicha columna puede ser del tipo de fecha y hora y la aplicación debe establecerla / actualizarla para la hora actual cada vez que agrega / cambia registros (atómicamente con agregar / cambiar). Como ejemplo, llamemos a la columna
update_time . Habiendo guardado el valor máximo del campo de esta columna para los registros transferidos, podemos comenzar la próxima sesión de intercambio desde este valor (seleccione registros con el valor del campo
update_time exceda el valor guardado previamente). El problema con este último enfoque es que los cambios de datos pueden ocurrir en modo por lotes. Como resultado, los valores de campo en la columna
update_time no ser únicos. Por lo tanto, esta columna no se puede utilizar para la salida de datos por lotes (página). Para la salida de datos página por página, será necesario inventar mecanismos adicionales que probablemente tengan una eficiencia muy baja (por ejemplo, recuperar de la base de datos todos los registros con
update_time encima del valor especificado y emitir un cierto número de registros, comenzando en un cierto desplazamiento desde el inicio de la muestra).
Puede aumentar la eficiencia de la transferencia de datos mejorando ligeramente el enfoque anterior. Para hacer esto, usaremos un tipo entero (entero largo) como los valores de los campos de columna para el seguimiento de los cambios.
row_ver columna
row_ver . El valor del campo de esta columna aún debe establecerse / actualizarse cada vez que se crea / modifica un registro. Pero en este caso, el campo se asignará no a la fecha y hora actual, sino al valor de algún contador aumentado en uno. Como resultado, la columna
row_ver contendrá valores únicos y puede usarse no solo para generar datos “delta” (datos agregados / modificados después del final de la sesión de intercambio anterior), sino también para una paginación simple y eficiente.
El último método propuesto para minimizar la cantidad de datos transferidos como parte de la replicación de alto nivel me parece el más óptimo y universal. Detengámonos en ello con más detalle.
Transferencia de datos usando el contador de versiones de fila
Implementación de servidor / maestro
En MS SQL Server, para implementar este enfoque, hay un tipo de columna especial:
rowversion . Cada base de datos tiene un contador, que aumenta en uno cada vez que agrega / cambia un registro en una tabla que tiene una columna de tipo
rowversion . El valor de este contador se asigna automáticamente al campo de esta columna en el registro agregado / modificado. Tarantool DBMS no tiene un mecanismo incorporado similar. Sin embargo, en Tarantool, no es difícil implementarlo manualmente. Considera cómo se hace esto.
Primero, una pequeña terminología: las tablas en Tarantool se llaman espacio, y los registros se llaman tuplas. En Tarantool, puedes crear secuencias. Las secuencias no son más que generadores nombrados de valores ordenados de enteros. Es decir Esto es justo lo que necesitamos para nuestros propósitos. A continuación crearemos tal secuencia.
Antes de realizar cualquier operación de base de datos en Tarantool, debe ejecutar el siguiente comando:
box.cfg{}
Como resultado, Tarantool comenzará a escribir instantáneas y un registro de transacciones en el directorio actual.
Crea una secuencia
row_version :
box.schema.sequence.create('row_version', { if_not_exists = true })
La opción
if_not_exists permite ejecutar el script de creación varias veces: si el objeto existe, Tarantool no intentará recrearlo. Esta opción se usará en todos los comandos DDL posteriores.
Creemos un espacio para un ejemplo.
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' }, { name = 'row_ver', type = 'unsigned' } }, if_not_exists = true })
Aquí establecemos el nombre del espacio (
goods ), los nombres de los campos y sus tipos.
Los campos de incremento automático de Tarantool también se crean usando secuencias. Cree una clave primaria de incremento automático para el campo
id :
box.schema.sequence.create('goods_id', { if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
Tarantool admite varios tipos de índices. Muy a menudo, se utilizan índices de los tipos TREE y HASH, que se basan en las estructuras correspondientes al nombre. TREE es el tipo de índice más versátil. Le permite recuperar datos de manera ordenada. Pero para la elección de la igualdad, HASH es más adecuado. En consecuencia, es aconsejable usar HASH para la clave primaria (lo cual hicimos).
Para usar la columna
row_ver para transmitir datos modificados, debe vincular los valores de secuencia
row_ver a los campos de esta columna. Pero a diferencia de la clave principal, el valor del campo en la columna
row_ver debería aumentar en uno, no solo al agregar nuevos registros, sino también al cambiar los existentes. Para hacer esto, puedes usar disparadores. Tarantool tiene dos tipos de disparadores para espacios:
before_replace y
on_replace . Los activadores se activan cada vez que se modifican los datos en el espacio (para cada tupla afectada por los cambios, se activa la función de activador). A diferencia de
on_replace , los disparadores
before_replace permiten modificar los datos de la tupla para la que se ejecuta el disparador. En consecuencia, el último tipo de desencadenantes nos conviene.
box.space.goods:before_replace(function(old, new) return box.tuple.new({new[1], new[2], new[3], box.sequence.row_version:next()}) end)
Este activador reemplaza el valor del campo
row_ver de la tupla almacenada con el siguiente
row_version secuencia
row_version .
Para poder extraer datos del espacio de
goods en la columna
row_ver , cree un índice:
box.space.goods:create_index('row_ver', { parts = { 'row_ver' }, unique = true, type = 'TREE', if_not_exists = true })
El tipo de índice es un árbol (
TREE ), porque necesitamos recuperar los datos en orden ascendente de valores en la columna
row_ver .
Agregue algunos datos al espacio:
box.space.goods:insert{nil, 'pen', 123} box.space.goods:insert{nil, 'pencil', 321} box.space.goods:insert{nil, 'brush', 100} box.space.goods:insert{nil, 'watercolour', 456} box.space.goods:insert{nil, 'album', 101} box.space.goods:insert{nil, 'notebook', 800} box.space.goods:insert{nil, 'rubber', 531} box.space.goods:insert{nil, 'ruler', 135}
Porque el primer campo es un contador de incremento automático, pasamos nulo en su lugar. Tarantool sustituirá automáticamente el siguiente valor. Del mismo modo, puede pasar nil como el valor de los campos en la columna
row_ver , o no especificar el valor en absoluto, porque Esta columna toma la última posición en el espacio.
Verifique el resultado del inserto:
tarantool> box.space.goods:select()
Como puede ver, el primer y el último campo se completaron automáticamente. Ahora será fácil escribir una función para paginar la descarga de las
goods :
local page_size = 5 local function get_goods(row_ver) local index = box.space.goods.index.row_ver local goods = {} local counter = 0 for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do local obj = tuple:tomap({ names_only = true }) table.insert(goods, obj) counter = counter + 1 if counter >= page_size then break end end return goods end
La función toma como parámetro el valor
row_ver del último registro recibido (0 para la primera llamada) y devuelve el siguiente lote de datos modificados (si hay uno, de lo contrario, una matriz vacía).
La recuperación de datos en Tarantool se realiza a través de índices. La función
get_goods usa el
row_ver índice
row_ver para recuperar los datos modificados. El tipo de iterador es GT (mayor que, más que). Esto significa que el iterador recorrerá secuencialmente los valores del índice comenzando desde el siguiente valor después de la clave pasada.
El iterador devuelve las tuplas. Para poder transferir datos posteriormente a través de HTTP, es necesario convertir las tuplas en una estructura conveniente para la serialización posterior. En el ejemplo, la función estándar de
tomap se utiliza para esto. En lugar de usar
tomap puede escribir su propia función. Por ejemplo, podríamos querer cambiar el
name campo de
name , no pasar el campo de
code y agregar el campo de
comment :
local function unflatten_goods(tuple) local obj = {} obj.id = tuple.id obj.goods_name = tuple.name obj.comment = 'some comment' obj.row_ver = tuple.row_ver return obj end
El tamaño de página de los datos de salida (el número de registros en una porción) está determinado por la variable
page_size . En el ejemplo, el valor de tamaño de página es 5. En un programa real, el tamaño de página suele ser más importante. Depende del tamaño promedio de la tupla espacial. El tamaño de página óptimo se puede seleccionar empíricamente midiendo el tiempo de transferencia de datos. Cuanto más grande es la página, menor es el número de viajes de ida y vuelta entre los lados emisores y receptores. Por lo tanto, puede reducir el tiempo total para cargar los cambios. Sin embargo, si el tamaño de la página es demasiado grande, el servidor tardará demasiado en serializar la selección. Como resultado, puede haber demoras en el procesamiento de otras solicitudes que llegaron al servidor. El parámetro
page_size se puede cargar desde el archivo de configuración. Para cada espacio transmitido, puede establecer su propio valor. Sin embargo, para la mayoría de los espacios, el valor predeterminado (por ejemplo, 100) puede ser adecuado.
get_goods función
get_goods en el módulo. Cree un archivo repl.lua que contenga la descripción de la variable
page_size y la función
get_goods . Al final del archivo, agregue la función de exportación:
return { get_goods = get_goods }
Para cargar el módulo, ejecute:
tarantool> repl = require('repl')
get_goods función
get_goods :
tarantool> repl.get_goods(0)
Tome el valor del campo
row_ver de la última fila y vuelva a llamar a la función:
tarantool> repl.get_goods(5)
Y de nuevo:
tarantool> repl.get_goods(8)
Como puede ver, con este uso, la función página por página devuelve todos los registros del espacio de
goods . La última página es seguida por una selección vacía.
Haremos cambios en el espacio:
box.space.goods:update(4, {{'=', 6, 'copybook'}}) box.space.goods:insert{nil, 'clip', 234} box.space.goods:insert{nil, 'folder', 432}
Cambiamos el valor del campo de
name para un registro y agregamos dos nuevos registros.
Repita la última llamada a la función:
tarantool> repl.get_goods(8)
La función devolvió los registros modificados y agregados. Por lo tanto, la función
get_goods permite obtener datos que han cambiado desde su última llamada, que es la base del método de replicación en consideración.
Dejamos el resultado de los resultados a través de HTTP en forma de JSON más allá del alcance de este artículo. Puede leer sobre esto aquí:
https://habr.com/ru/company/mailru/blog/272141/Implementación de la parte cliente / esclavo
Considere cómo se ve la implementación del lado receptor. Cree un espacio en el lado receptor para almacenar los datos descargados:
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' } }, if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
La estructura del espacio se asemeja a la estructura del espacio en la fuente. Pero como no vamos a transferir los datos recibidos a otra parte, la columna
row_ver está
row_ver en el espacio del destinatario. En el campo
id se escribirán los identificadores de la fuente. Por lo tanto, en el lado del receptor, no es necesario que se incremente automáticamente.
Además, necesitamos un espacio para guardar los valores de
row_ver :
box.schema.space.create('row_ver', { format = { { name = 'space_name', type = 'string' }, { name = 'value', type = 'string' } }, if_not_exists = true }) box.space.row_ver:create_index('primary', { parts = { 'space_name' }, unique = true, type = 'HASH', if_not_exists = true })
Para cada espacio cargado (campo
space_name )
space_name aquí el último valor cargado
row_ver (
value campo). La clave primaria es la columna
space_name .
Creemos una función para cargar datos de espacio de
goods través de HTTP. Para hacer esto, necesitamos una biblioteca que implemente un cliente HTTP. La siguiente línea carga la biblioteca y crea instancias del cliente HTTP:
local http_client = require('http.client').new()
También necesitamos una biblioteca para la deserialización de json:
local json = require('json')
Esto es suficiente para crear una función de carga de datos:
local function load_data(url, row_ver) local url = ('%s?rowVer=%s'):format(url, tostring(row_ver)) local body = nil local data = http_client:request('GET', url, body, { keepalive_idle = 1, keepalive_interval = 1 }) return json.decode(data.body) end
La función realiza una solicitud HTTP en url, le pasa
row_ver como parámetro y devuelve el resultado deserializado de la solicitud.
La función de guardar los datos recibidos es la siguiente:
local function save_goods(goods) local n = #goods box.atomic(function() for i = 1, n do local obj = goods[i] box.space.goods:put( obj.id, obj.name, obj.code) end end) end
El ciclo de almacenamiento de datos en el espacio de
goods se coloca en una transacción (la función
box.atomic se utiliza para esto) para reducir el número de operaciones de disco.
Finalmente, la función de sincronización de los
goods espaciales locales con la fuente se puede implementar de la siguiente manera:
local function sync_goods() local tuple = box.space.row_ver:get('goods') local row_ver = tuple and tuple.value or 0
Primero, leemos el valor
row_ver previamente guardado para el espacio de
goods . Si está ausente (la primera sesión de intercambio), tomamos cero como
row_ver . A continuación, en el ciclo, paginamos los datos modificados desde la fuente a la url especificada. En cada iteración, guardamos los datos recibidos en el espacio local correspondiente y actualizamos el valor
row_ver (en el
row_ver row_ver y en la variable
row_ver ): tomamos el valor
row_ver de la última fila de los datos cargados.
Para protegerse contra bucles accidentales (en caso de un error en el programa), el
while se puede reemplazar por:
for _ = 1, max_req do ...
Como resultado de la función
sync_goods , los
goods en el receptor contendrán las últimas versiones de todos los registros de espacio de
goods en la fuente.
Obviamente, la eliminación de datos no se puede transmitir de esta manera. Si existe tal necesidad, puede usar la marca de borrado. Agregue el campo booleano
is_deleted espacio de
goods y use la eliminación lógica en lugar de eliminar físicamente el registro; establezca el valor del campo
is_deleted en
true . A veces, en lugar del campo booleano
is_deleted ,
is_deleted más conveniente usar el campo
deleted , que almacena la fecha y hora de la eliminación lógica del registro. Después de realizar una eliminación lógica, el registro marcado para eliminación se transferirá desde la fuente al receptor (de acuerdo con la lógica discutida anteriormente).
La secuencia
row_ver se puede usar para transferir datos desde otros espacios: no es necesario crear una secuencia separada para cada espacio transmitido.
Examinamos una forma efectiva de replicación de datos de alto nivel en aplicaciones que utilizan el DBMS Tarantool.
Conclusiones
- Tarantool DBMS es un producto atractivo y prometedor para crear aplicaciones altamente cargadas.
- La replicación de alto nivel proporciona un enfoque más flexible para la transferencia de datos en comparación con la replicación de bajo nivel.
- El método de replicación de alto nivel discutido en el artículo permite minimizar la cantidad de datos transferidos al transferir solo aquellos registros que han cambiado desde la última sesión de intercambio.