Las aplicaciones web ahora se usan ampliamente, y HTTP es la mayor parte de todos los protocolos de transporte. Al estudiar los matices del desarrollo de aplicaciones web, la mayoría de ellos prestan muy poca atención al sistema operativo donde estas aplicaciones realmente se ejecutan. La separación del desarrollo (Dev) y la operación (Ops) solo empeoró las cosas. Pero con la difusión de la cultura DevOps, los desarrolladores comienzan a asumir la responsabilidad de lanzar sus aplicaciones en la nube, por lo que es muy útil que se familiaricen a fondo con el sistema operativo. Esto es especialmente útil si está intentando implementar un sistema para miles o decenas de miles de conexiones concurrentes.
Las limitaciones en los servicios web son muy similares a las limitaciones en otras aplicaciones. Ya se trate de equilibradores de carga o servidores de bases de datos, todas estas aplicaciones tienen problemas similares en un entorno de alto rendimiento. Comprender estas limitaciones fundamentales y cómo superarlas en general lo ayudará a evaluar el rendimiento y la escalabilidad de sus aplicaciones web.
Estoy escribiendo esta serie de artículos en respuesta a preguntas de desarrolladores jóvenes que desean convertirse en arquitectos de sistemas bien informados. Es imposible comprender claramente los métodos para optimizar las aplicaciones de Linux sin profundizar en los conceptos básicos de cómo funcionan a nivel del sistema operativo. Aunque hay muchos tipos de aplicaciones, en esta serie quiero explorar las aplicaciones de red, no las de escritorio, como un navegador o un editor de texto. Este material está destinado a desarrolladores y arquitectos que desean comprender cómo funcionan los programas Linux o Unix y cómo estructurarlos para un alto rendimiento.
Linux es un sistema operativo de
servidor , y con mayor frecuencia sus aplicaciones se ejecutan en este sistema operativo en particular. Aunque digo "Linux", la mayoría de las veces puede asumir con seguridad que todos los sistemas operativos similares a Unix en general están destinados. Sin embargo, no he probado el código que lo acompaña en otros sistemas. Entonces, si está interesado en FreeBSD u OpenBSD, el resultado puede variar. Cuando intento algo específico de Linux, lo señalo.
Aunque puede utilizar este conocimiento para crear una aplicación desde cero, y estará perfectamente optimizada, es mejor no hacerlo. Si escribe un nuevo servidor web en C o C ++ para la aplicación empresarial de su organización, este puede ser su último día en el trabajo. Sin embargo, el conocimiento de la estructura de estas aplicaciones ayudará en la selección de los programas existentes. Puede comparar sistemas basados en procesos con sistemas basados en hilos y eventos. Comprenderá y apreciará por qué Nginx funciona mejor que Apache httpd, por qué una aplicación Python basada en Tornado puede servir a más usuarios que una aplicación Python basada en Django.
ZeroHTTPd: herramienta de aprendizaje
ZeroHTTPd es un servidor web que escribí desde cero en C como herramienta de capacitación. No tiene dependencias externas, incluido el acceso a Redis. Ejecutamos nuestras propias rutinas de Redis. Ver abajo para más detalles.
Aunque podríamos discutir la teoría durante mucho tiempo, no hay nada mejor que escribir código, ejecutarlo y comparar todas las arquitecturas de servidores. Este es el método más obvio. Por lo tanto, escribiremos un servidor web simple ZeroHTTPd usando cada modelo: basado en procesos, hilos y eventos. Revisemos cada uno de estos servidores y veamos cómo funcionan en comparación entre sí. ZeroHTTPd se implementa en un solo archivo C. El servidor basado en eventos incluye
uthash , una excelente implementación de tabla hash que se envía en un solo archivo de encabezado. En otros casos, no hay dependencias, para no complicar el proyecto.
Hay muchos comentarios en el código para ayudar a resolverlo. Al ser un servidor web simple en unas pocas líneas de código, ZeroHTTPd también es un marco de desarrollo web mínimo. Tiene una funcionalidad limitada, pero es capaz de producir archivos estáticos y páginas "dinámicas" muy simples. Debo decir que ZeroHTTPd es muy adecuado para aprender a crear aplicaciones Linux de alto rendimiento. En general, la mayoría de los servicios web esperan solicitudes, las verifican y las procesan. Esto es exactamente lo que hará ZeroHTTPd. Esta es una herramienta de aprendizaje, no una herramienta de producción. No es bueno para manejar errores y es improbable que se jacte de las mejores prácticas de seguridad (oh sí, usé
strcpy ) o los trucos absurdos de C. Pero espero que haga bien su trabajo.
 Página de inicio de ZeroHTTPd. Puede producir diferentes tipos de archivos, incluidas imágenes
Página de inicio de ZeroHTTPd. Puede producir diferentes tipos de archivos, incluidas imágenesSolicitud de libro de visitas
Las aplicaciones web modernas generalmente no se limitan a archivos estáticos. Tienen interacciones complejas con varias bases de datos, cachés, etc. Por lo tanto, crearemos una aplicación web simple llamada "Libro de visitas", donde los visitantes dejan entradas bajo sus nombres. El libro de visitas guarda las entradas dejadas anteriormente. También hay un contador de visitantes en la parte inferior de la página.
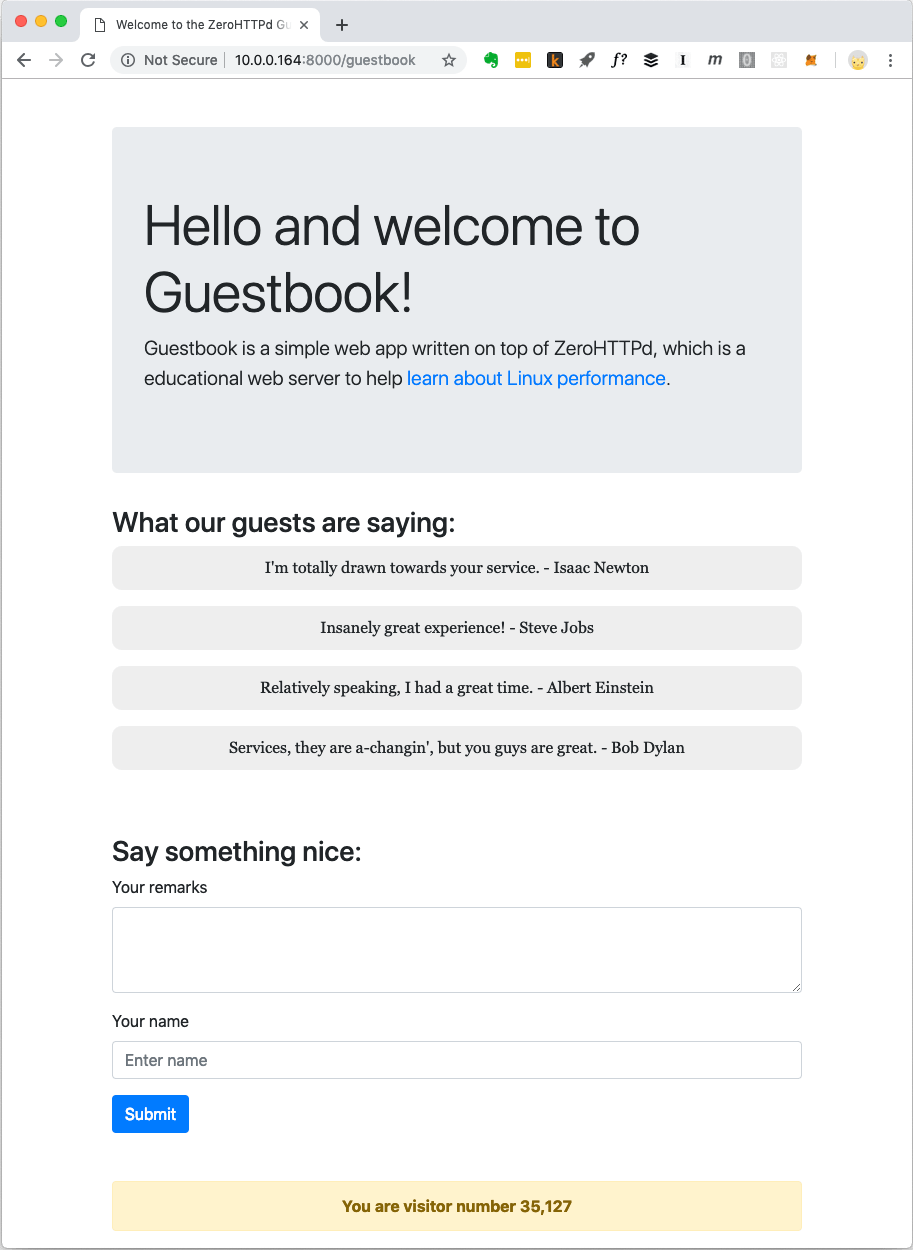 Libro de visitas Aplicación web ZeroHTTPd
Libro de visitas Aplicación web ZeroHTTPdEl contador de visitantes y las entradas del libro de visitas se almacenan en Redis. Para la comunicación con Redis, se implementan procedimientos propios; son independientes de una biblioteca externa. No soy un gran admirador del código interno cuando hay soluciones disponibles públicamente y bien probadas. Pero el objetivo de ZeroHTTPd es estudiar el rendimiento de Linux y el acceso a servicios externos, mientras que atender las solicitudes HTTP afecta seriamente el rendimiento. Debemos controlar completamente las comunicaciones con Redis en cada una de nuestras arquitecturas de servidor. En una arquitectura, usamos llamadas de bloqueo, en otras usamos procedimientos basados en eventos. El uso de una biblioteca de cliente Redis externa no otorgará dicho control. Además, nuestro pequeño cliente Redis realiza solo unas pocas funciones (obtener, configurar y aumentar una clave; obtener y agregar a una matriz). Además, el protocolo Redis es excepcionalmente elegante y simple. Ni siquiera necesita que se le enseñe especialmente. El hecho de que el protocolo realice todo el trabajo en aproximadamente cien líneas de código indica qué tan bien pensado está.
La siguiente figura muestra la aplicación cuando el cliente (navegador) solicita
/guestbookURL .
 El mecanismo de la aplicación del libro de visitas.
El mecanismo de la aplicación del libro de visitas.Cuando necesita emitir una página de libro de visitas, hay una llamada al sistema de archivos para leer la plantilla en la memoria y tres llamadas de red a Redis. El archivo de plantilla contiene la mayor parte del contenido HTML de la página en la captura de pantalla anterior. También hay marcadores de posición especiales para la parte dinámica del contenido: registros y contador de visitantes. Los obtenemos de Redis, los insertamos en la página y le damos al cliente contenido completamente formado. Se puede evitar una tercera llamada a Redis porque Redis devuelve un nuevo valor clave cuando se incrementa. Sin embargo, para nuestro servidor con una arquitectura asincrónica basada en eventos, muchas llamadas de red son una buena prueba para fines de capacitación. Por lo tanto, descartamos el valor de retorno de Redis sobre el número de visitantes y lo solicitamos en una llamada separada.
Arquitecturas del servidor ZeroHTTPd
Estamos creando siete versiones de ZeroHTTPd con la misma funcionalidad pero diferentes arquitecturas:
- Iterativo
- Servidor fork (un proceso secundario por solicitud)
- Servidor previo a la bifurcación (procesos previos a la bifurcación)
- Servidor con hilos (un hilo por solicitud)
- Servidor con subprocesamiento previo
- Arquitectura basada en
poll()
- Arquitectura epoll
Medimos el rendimiento de cada arquitectura cargando el servidor con solicitudes HTTP. Pero al comparar arquitecturas con un alto grado de paralelismo, aumenta el número de solicitudes. Probamos tres veces y consideramos el promedio.
Metodología de prueba
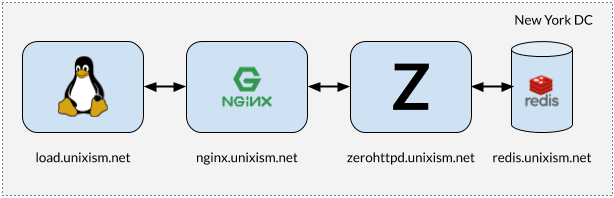 Instalación para pruebas de tensión ZeroHTTPd
Instalación para pruebas de tensión ZeroHTTPdEs importante que al realizar pruebas todos los componentes no funcionen en la misma máquina. En este caso, el sistema operativo conlleva una sobrecarga de planificación adicional, ya que los componentes compiten por la CPU. La medición de la sobrecarga del sistema operativo de cada una de las arquitecturas de servidor seleccionadas es uno de los objetivos más importantes de este ejercicio. Agregar más variables será perjudicial para el proceso. Por lo tanto, la configuración en la figura anterior funciona mejor.
Qué hace cada uno de estos servidores
- load.unixism.net: aquí ejecutamos
ab , la utilidad Apache Benchmark. Genera la carga necesaria para probar nuestras arquitecturas de servidor.
- nginx.unixism.net: a veces queremos ejecutar más de una instancia de un programa de servidor. Para esto, el servidor Nginx con la configuración adecuada funciona como un equilibrador de carga proveniente de ab para los procesos de nuestro servidor.
- zerohttpd.unixism.net: aquí ejecutamos nuestros programas de servidor en siete arquitecturas diferentes, una a la vez.
- redis.unixism.net: el demonio Redis se está ejecutando en este servidor, donde las entradas se almacenan en el libro de visitas y en el mostrador de visitantes.
Todos los servidores se ejecutan en un solo núcleo de procesador. La idea es evaluar el rendimiento máximo de cada arquitectura. Dado que todos los programas de servidor se prueban en el mismo hardware, este es el nivel básico para compararlos. Mi configuración de prueba consiste en servidores virtuales alquilados de Digital Ocean.
¿Qué estamos midiendo?
Puedes medir diferentes indicadores. Evaluamos el rendimiento de cada arquitectura en esta configuración, cargando servidores con solicitudes en diferentes niveles de concurrencia: la carga crece de 20 a 15,000 usuarios concurrentes.
Resultados de la prueba
El siguiente diagrama muestra el rendimiento de los servidores en diferentes arquitecturas en diferentes niveles de concurrencia. El eje y es el número de solicitudes por segundo, el eje x es conexiones paralelas.
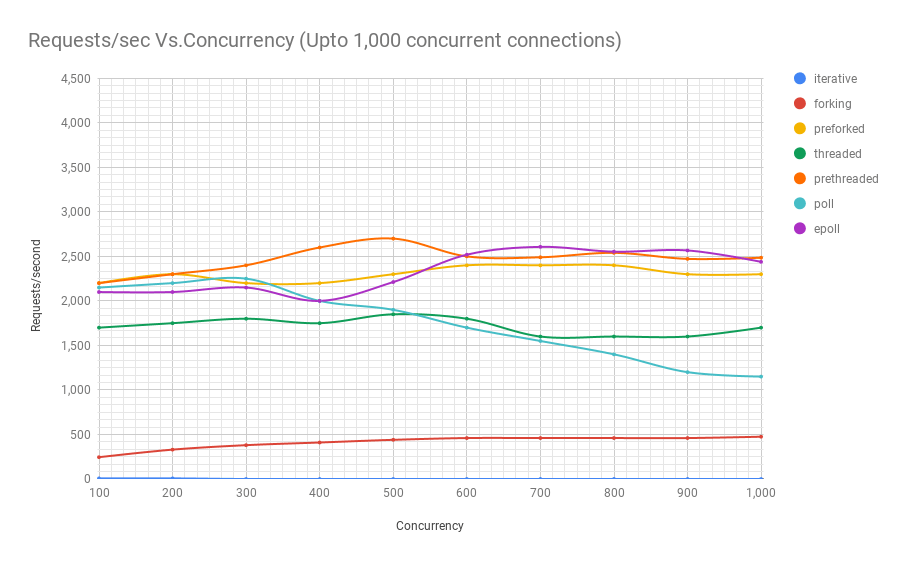
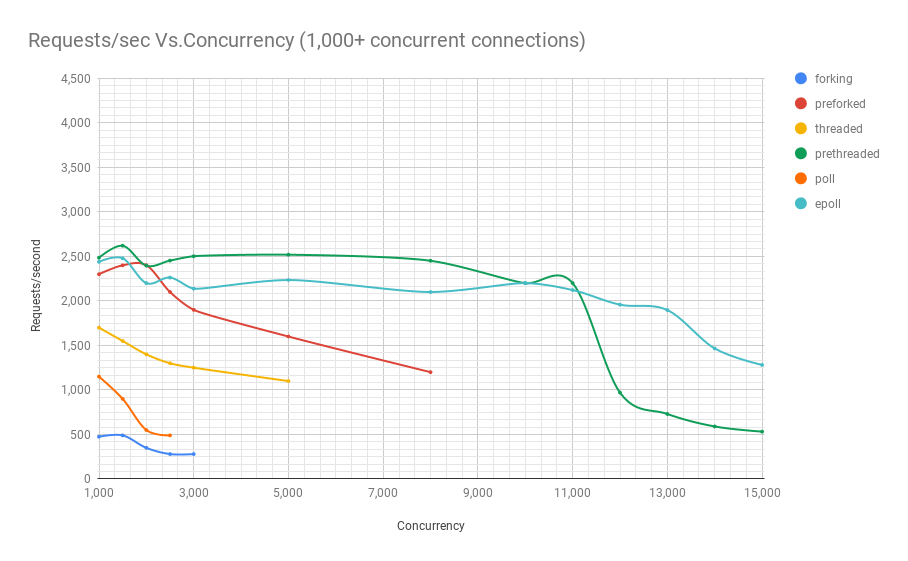
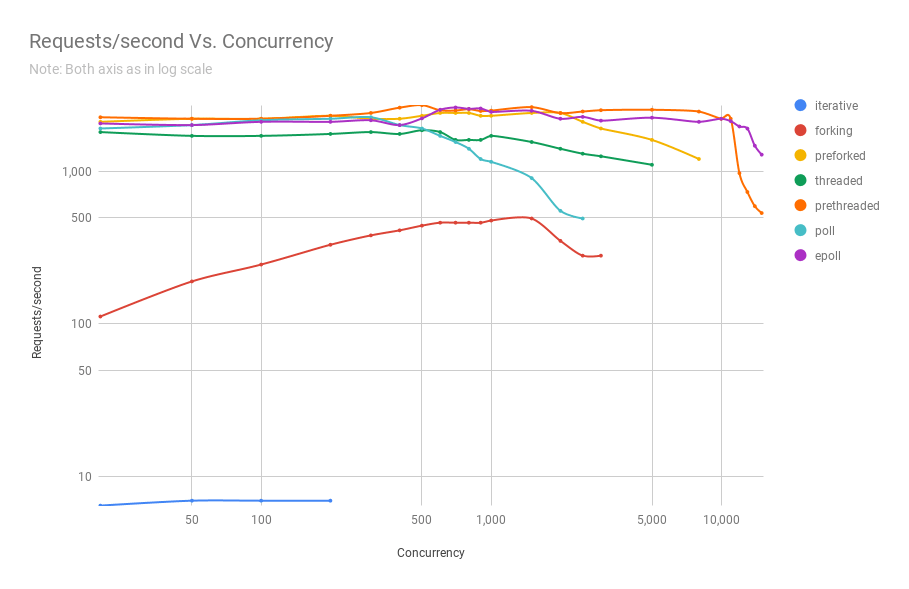
A continuación se muestra una tabla con los resultados.
Se puede ver en el gráfico y la tabla que por encima de 8000 solicitudes simultáneas, solo nos quedan dos jugadores: pre-fork y epoll. A medida que aumenta la carga, el servidor basado en encuestas funciona peor que la transmisión. La arquitectura de subprocesamiento previo compite con epoll: esto es evidencia de qué tan bien el kernel de Linux planifica una gran cantidad de subprocesos.
Código fuente ZeroHTTPd
El código fuente de ZeroHTTPd está
aquí . Cada arquitectura tiene un directorio separado.
ZeroHTTPd
│
├── 01_iterativo
│ ├── main.c
├── 02_forking
│ ├── main.c
├── 03_preforking
│ ├── main.c
├── 04_hilo
│ ├── main.c
├── 05_prethreading
│ ├── main.c
├── 06_poll
│ ├── main.c
├── 07_epoll
│ └── main.c
├── Makefile
├── público
│ ├── index.html
│ └── tux.png
└── plantillas
└── libro de visitas
└── index.html Además de siete directorios para todas las arquitecturas, hay dos más en el directorio de nivel superior: público y plantillas. El primero contiene el archivo index.html y la imagen de la primera captura de pantalla. Se pueden colocar otros archivos y carpetas allí, y ZeroHTTPd debería emitir estos archivos estáticos sin problemas. Si la ruta en el navegador coincide con la ruta en la carpeta pública, ZeroHTTPd busca el archivo index.html en este directorio. El contenido del libro de visitas se genera dinámicamente. Tiene solo la página principal y su contenido se basa en el archivo 'templates / guestbook / index.html'. ZeroHTTPd agrega fácilmente páginas dinámicas para expansión. La idea es que los usuarios puedan agregar plantillas a este directorio y extender ZeroHTTPd según sea necesario.
Para compilar los siete servidores, ejecute
make all desde el directorio de nivel superior, y todas las compilaciones aparecerán en este directorio. Los ejecutables buscan los directorios público y de plantillas en el directorio desde donde se ejecutan.
API de Linux
Para comprender la información en esta serie de artículos, no es necesario estar bien versado en la API de Linux. Sin embargo, recomiendo leer más sobre este tema, hay muchos recursos de referencia en la Web. Aunque cubriremos varias categorías de API de Linux, nuestro enfoque se centrará principalmente en procesos, subprocesos, eventos y la pila de red. Además de libros y artículos sobre la API de Linux, también recomiendo leer el maná para las llamadas al sistema y las funciones de biblioteca utilizadas.
Rendimiento y escalabilidad
Una nota sobre rendimiento y escalabilidad. Teóricamente, no hay conexión entre ellos. Es posible que tenga un servicio web que funcione muy bien, con un tiempo de respuesta de unos pocos milisegundos, pero no se escala en absoluto. Del mismo modo, puede haber una aplicación web que se ejecute mal y que tarde unos segundos en responder, pero se escala a decenas para manejar decenas de miles de usuarios concurrentes. Sin embargo, la combinación de alto rendimiento y escalabilidad es una combinación muy poderosa. Las aplicaciones de alto rendimiento generalmente usan recursos de manera económica y, por lo tanto, sirven de manera efectiva a más usuarios concurrentes en el servidor, lo que reduce los costos.
CPU y tareas de E / S
Finalmente, siempre hay dos tipos posibles de tareas en informática: para E / S y CPU. Recibir solicitudes a través de Internet (E / S de red), mantenimiento de archivos (E / S de red y disco), comunicación con la base de datos (E / S de red y disco) son todas las acciones de E / S. Algunas consultas de la base de datos pueden cargar un poco la CPU (clasificación, cálculo del promedio de un millón de resultados, etc.). La mayoría de las aplicaciones web están limitadas por la E / S máxima posible, y el procesador rara vez se usa a plena capacidad. Cuando vea que algunas CPU usan muchas CPU, esto probablemente sea un signo de una arquitectura de aplicación deficiente. Esto puede significar que los recursos de la CPU se gastan en el control de procesos y el cambio de contexto, y esto no es del todo útil. Si está haciendo algo como el procesamiento de imágenes, la conversión de audio o el aprendizaje automático, la aplicación requiere potentes recursos de CPU. Pero para la mayoría de las aplicaciones esto no es así.
Más sobre arquitecturas de servidor
- Parte I. Arquitectura iterativa
- Parte II Servidores de horquillas
- Parte III Servidores pre-fork
- Parte IV Servidores con hilos
- Parte V. Servidores con pre-creación de hilos
- Parte VI Arquitectura basada en encuestas
- Parte VII Arquitectura epoll