HighLoad ++ ha existido
durante mucho tiempo, y hablamos sobre trabajar con PostgreSQL regularmente. Pero los desarrolladores todavía tienen los mismos problemas de mes a mes, de año a año. Cuando en pequeñas empresas sin un DBA en el estado hay errores al trabajar con bases de datos, esto no es sorprendente. Las grandes empresas también necesitan bases de datos, e incluso con procesos depurados, aún se producen errores y las bases de datos caen. No importa el tamaño de la empresa: aún se producen errores, las bases de datos se bloquean periódicamente.

Por supuesto, esto nunca te sucederá, pero verificar la lista de verificación no es difícil, y puede ser muy decente para salvar los nervios futuros. Debajo del gato, enumeraremos los principales errores típicos que cometen los desarrolladores al trabajar con PostgreSQL, veremos por qué no necesitamos hacer esto y descubriremos cómo.
Sobre el orador: Alexey Lesovsky comenzó como administrador del sistema Linux. De las tareas de virtualización y sistemas de monitoreo, poco a poco llegó a PostgreSQL. Ahora PostgreSQL DBA en
Data Egret , una empresa de consultoría que trabaja con muchos proyectos diferentes y ve muchos ejemplos de problemas recurrentes. Este es un
enlace a la presentación del informe en HighLoad ++ 2018.
¿De dónde vienen los problemas?
Para calentar, algunas historias sobre cómo ocurren los errores.
Historia 1. Características
Uno de los problemas es qué características usa la compañía cuando trabaja con PostgreSQL. Todo comienza simple: PostgreSQL, conjuntos de datos, consultas simples con JOIN. Tomamos los datos, hacemos SELECCIONAR: todo es simple.
Luego comenzamos a usar la funcionalidad adicional de PostgreSQL, agregamos nuevas funciones, extensiones. La característica se está haciendo más grande. Conectamos replicación de transmisión, fragmentación. Aparecen varias utilidades y kits de cuerpo: pgbouncer, pgpool, patroni. Algo asi.

Cada palabra clave es una razón para que aparezca un error.
Historia 2. Almacenamiento de datos
La forma en que almacenamos datos también es una fuente de errores.
Cuando apareció el proyecto por primera vez, había bastantes datos y tablas en él. Las consultas simples son suficientes para recibir y registrar datos. Pero luego hay más y más mesas. Los datos se seleccionan de diferentes lugares, aparecen las UNIONES. Las consultas son complicadas e incluyen construcciones CTE, SUBQUERÍA, listas IN, LATERAL. Cometer un error y escribir una consulta de curva se vuelve mucho más fácil.
Y esto es solo la punta del iceberg: en algún lado puede haber otras 400 tablas, particiones, de las que también se leen ocasionalmente datos.
Historia 3. Ciclo de vida
La historia de cómo se sigue el producto. Los datos siempre deben almacenarse en algún lugar, por lo que siempre hay una base de datos. ¿Cómo se desarrolla una base de datos cuando se desarrolla un producto?
Por un lado, hay
desarrolladores que están ocupados con lenguajes de programación. Escriben sus aplicaciones y desarrollan habilidades en el campo del desarrollo de software, sin prestar atención a los servicios. A menudo no les interesa cómo funcionan Kafka o PostgreSQL: desarrollan nuevas funciones en su aplicación y no les importa el resto.
 Administradores, por
Administradores, por otro lado. Plantean nuevas instancias de Amazon en Bare-metal y están ocupados con la automatización: configuran implementaciones para que el diseño funcione bien y configuran para que los servicios interactúen bien entre sí.

Hay una situación en la que no hay tiempo o deseo de ajuste fino de componentes, y la base de datos también. Las bases de datos funcionan con configuraciones predeterminadas, y luego se olvidan por completo de ellas: "funciona, no lo toques".
Como resultado, los rastrillos se encuentran dispersos en varios lugares, que de vez en cuando vuelan a la frente de los desarrolladores. En este artículo, intentaremos recopilar todos estos rastrillos en un cobertizo para que los conozca y no los pise cuando trabaje con PostgreSQL.
Planificación y seguimiento.
Primero, imagine que tenemos un nuevo proyecto: siempre es un desarrollo activo, prueba de hipótesis e implementación de nuevas características. En el momento en que la aplicación acaba de aparecer y se está desarrollando, tiene poco tráfico, usuarios y clientes, y todos generan pequeñas cantidades de datos. La base de datos tiene consultas simples que se procesan rápidamente. No es necesario arrastrar grandes cantidades de datos, no hay problemas.
Pero hay más usuarios, llega el tráfico: aparecen nuevos datos, las bases de datos crecen y las consultas antiguas dejan de funcionar. Es necesario completar índices, reescribir y optimizar consultas. Hay problemas de rendimiento. Todo esto genera alertas a las 4 a.m., estrés para los administradores y descontento de la administración.
Que esta mal
En mi experiencia, la mayoría de las veces no hay suficientes discos.
El primer ejemplo . Abrimos el cronograma para monitorear la utilización del disco y vemos que el
espacio libre en el disco se está agotando .
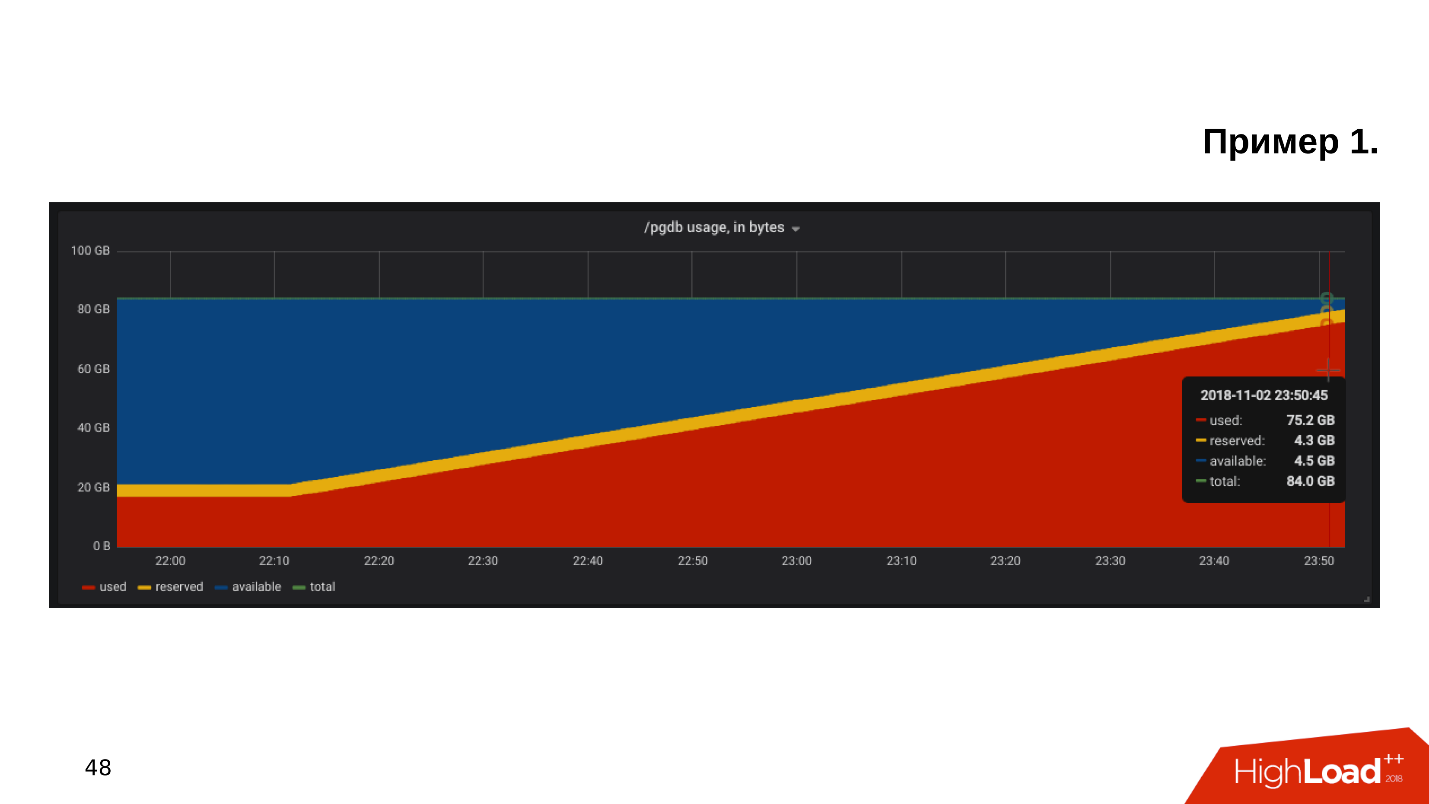
Observamos cuánto espacio y qué se come; resulta que hay un directorio pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
Los administradores de bases de datos generalmente saben qué es este directorio y no lo tocan, existe y existe. Pero el desarrollador, especialmente si observa la puesta en escena, se rasca la cabeza y piensa:
- Algún tipo de registros ... ¡Eliminemos pg_xlog!Elimina el directorio, la base de datos deja de funcionar . Inmediatamente debe buscar en Google cómo aumentar la base de datos después de eliminar los registros de transacciones.
 Segundo ejemplo
Segundo ejemplo Nuevamente, abrimos el monitoreo y vemos que no hay suficiente espacio. Esta vez el lugar está ocupado por algún tipo de base.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
Estamos buscando qué base de datos ocupa más espacio, qué tablas e índices.

Resulta que esta es una tabla con registros históricos. Nunca necesitamos registros históricos. Están escritos por si acaso, y si no fuera por el problema con el lugar, nadie los miraría hasta la segunda venida:
- Vamos a limpiar todo lo que mm ... más viejo que octubre!Haga una solicitud de actualización, ejecútela, funcionará y eliminará algunas de las líneas.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
La consulta se ejecuta durante 10 minutos, pero la tabla todavía ocupa la misma cantidad de espacio.
PostgreSQL elimina filas de la tabla: todo es correcto, pero no devuelve el lugar al sistema operativo. Este comportamiento de PostgreSQL es desconocido para la mayoría de los desarrolladores y puede ser muy sorprendente.
El tercer ejemplo . Por ejemplo, ORM hizo una solicitud interesante. Por lo general, todos culpan a ORM por hacer consultas "malas" que leen algunas tablas.
Supongamos que hay varias operaciones JOIN que leen tablas en paralelo en varios subprocesos. PostgreSQL puede paralelizar operaciones de datos y puede leer tablas en múltiples hilos. Pero, dado que tenemos varios servidores de aplicaciones, esta consulta lee todas las tablas varios miles de veces por segundo. Resulta que el servidor de la base de datos está sobrecargado, los discos no pueden hacer frente y todo esto conduce a un error
502 Bad Gateway desde el backend: la base de datos no está disponible.
Pero eso no es todo. Puede recordar otras características de PostgerSQL.
- Frenos de los procesos en segundo plano de DBMS : PostgreSQL tiene todo tipo de puntos de control, aspiradoras y replicación.
- Gastos generales de virtualización . Cuando la base de datos se ejecuta en una máquina virtual, en la misma pieza de hierro también hay máquinas virtuales a un lado, y pueden entrar en conflicto por los recursos.
- El almacenamiento es del fabricante chino NoName , cuyo rendimiento depende de la luna en Capricornio o la posición de Saturno, y no hay forma de averiguar por qué funciona de esta manera. La base está sufriendo.
- La configuración por defecto . Este es mi tema favorito: el cliente dice que su base de datos se está ralentizando, mira, y tiene una configuración predeterminada. El hecho es que la configuración predeterminada de PostgreSQL está diseñada para ejecutarse en la tetera más débil . La base se inicia, funciona, pero cuando ya funciona en hardware de nivel medio, entonces esta configuración no es suficiente, debe ajustarse.
Muy a menudo, PostgreSQL carece de espacio en disco o de rendimiento de disco. Afortunadamente, con procesadores, memoria y una red, por regla general, todo está más o menos en orden.
Como ser ¡Necesita monitoreo y planificación! Parece obvio, pero por alguna razón, en la mayoría de los casos, nadie planifica una base, y el monitoreo no cubre todo lo que se necesita monitorear durante la operación de PostgreSQL. Hay un conjunto de reglas claras, con las cuales todo funcionará bien, y no "al azar".
Planificacion
Hospede la base de datos en un SSD sin dudarlo . Los SSD se han vuelto confiables, estables y productivos. Los modelos de SSD empresariales han existido durante años.
Planifique siempre un esquema de datos . No escriba en la base de datos que duda de lo que se necesita, lo que garantiza que no será necesario. Un ejemplo simple es una tabla ligeramente modificada de uno de nuestros clientes.

Esta es una tabla de registro en la que hay una columna de datos de tipo json. Relativamente hablando, puedes escribir cualquier cosa en esta columna. Del último registro de esta tabla se puede ver que los registros ocupan 8 MB. PostgreSQL no tiene problemas para almacenar registros de esta longitud. PostgreSQL tiene muy buen almacenamiento que mastica dichos registros.
Pero el problema es que cuando los servidores de aplicaciones leen datos de esta tabla, obstruirán fácilmente todo el ancho de banda de la red, y otras solicitudes se verán afectadas. Este es el problema de planificar un esquema de datos.
Utilice la partición para cualquier pista de una historia que deba almacenarse durante más de dos años . El particionamiento a veces parece complicado: debe molestarse con los desencadenantes, con funciones que crearán particiones. En las nuevas versiones de PostgreSQL, la situación es mejor y ahora configurar la partición es mucho más simple: una vez hecho, funciona.
En el ejemplo considerado de eliminación de datos en 10 minutos,
DELETE se puede reemplazar con
DROP TABLE ; tal operación en circunstancias similares tomará solo unos pocos milisegundos.
Cuando los datos se ordenan por partición, la partición se elimina literalmente en unos pocos milisegundos y el sistema operativo se hace cargo de inmediato. Administrar datos históricos es más fácil, más fácil y más seguro.
Monitoreo
El monitoreo es un gran tema separado, pero desde el punto de vista de la base de datos hay recomendaciones que pueden encajar en una sección del artículo.
De manera predeterminada, muchos sistemas de monitoreo proporcionan monitoreo de procesadores, memoria, red, espacio en disco, pero, por regla general,
no se eliminan los dispositivos de disco . La información sobre qué tan cargados están los discos, qué ancho de banda está actualmente en los discos y el valor de latencia siempre debe agregarse a la supervisión. Esto lo ayudará a evaluar rápidamente cómo se cargan las unidades.
Hay muchas opciones de monitoreo de PostgreSQL, hay para todos los gustos. Aquí hay algunos puntos que deben estar presentes.
- Clientes conectados . Es necesario controlar con qué estados trabajan, encontrar rápidamente a los clientes "dañinos" que dañan la base de datos y apagarlos.
- Errores Es necesario monitorear los errores para monitorear qué tan bien funciona la base de datos: sin errores, excelente, han aparecido errores, una razón para mirar los registros y comenzar a comprender qué está yendo mal.
- Solicitudes (declaraciones) . Monitoreamos las características cuantitativas y cualitativas de las solicitudes para evaluar aproximadamente si tenemos solicitudes lentas, largas o que requieren muchos recursos.
Para obtener más información, consulte el informe
"Conceptos básicos de monitoreo de PostgreSQL" con HighLoad ++ Siberia y la página de
Monitoreo en el Wiki de PostgreSQL.
Cuando planificamos todo y "nos cubrimos" con el monitoreo, aún podemos encontrar algunos problemas.
Escalamiento
Por lo general, el desarrollador ve la línea de la base de datos en la configuración. No está particularmente interesado en cómo está organizado internamente: cómo funciona el punto de control, la replicación y el planificador. El desarrollador ya tiene algo que hacer: en todo hay muchas cosas interesantes que quiere probar.
"Dame la dirección de la base, luego yo mismo". © Desarrollador anónimo.
La ignorancia del tema conlleva consecuencias bastante interesantes cuando el desarrollador comienza a escribir consultas que funcionan en esta base de datos. Las fantasías al escribir consultas a veces dan efectos sorprendentes.
Hay dos tipos de transacciones.
Las transacciones OLTP son rápidas, cortas y livianas que toman fracciones de milisegundos. Funcionan muy rápido, y hay muchos de ellos.
OLAP - consultas analíticas - lentas, largas, pesadas, leen grandes conjuntos de tablas y leen estadísticas.
En los últimos 2-3 años, la abreviatura
HTAP a menudo suena: Transacción híbrida / Procesamiento analítico o Procesamiento
híbrido transaccional-analítico . Si no tiene tiempo para pensar en el escalado y la diversidad de las solicitudes OLAP y OLTP, puede decir: "¡Tenemos HTAP!" Pero la experiencia y el dolor de los errores muestran que, después de todo, los diferentes tipos de solicitudes deben vivir por separado, ya que las solicitudes OLAP largas bloquean las solicitudes OLTP ligeras.
Entonces llegamos a la pregunta de cómo escalar PostgreSQL para distribuir la carga, y todos quedaron satisfechos.
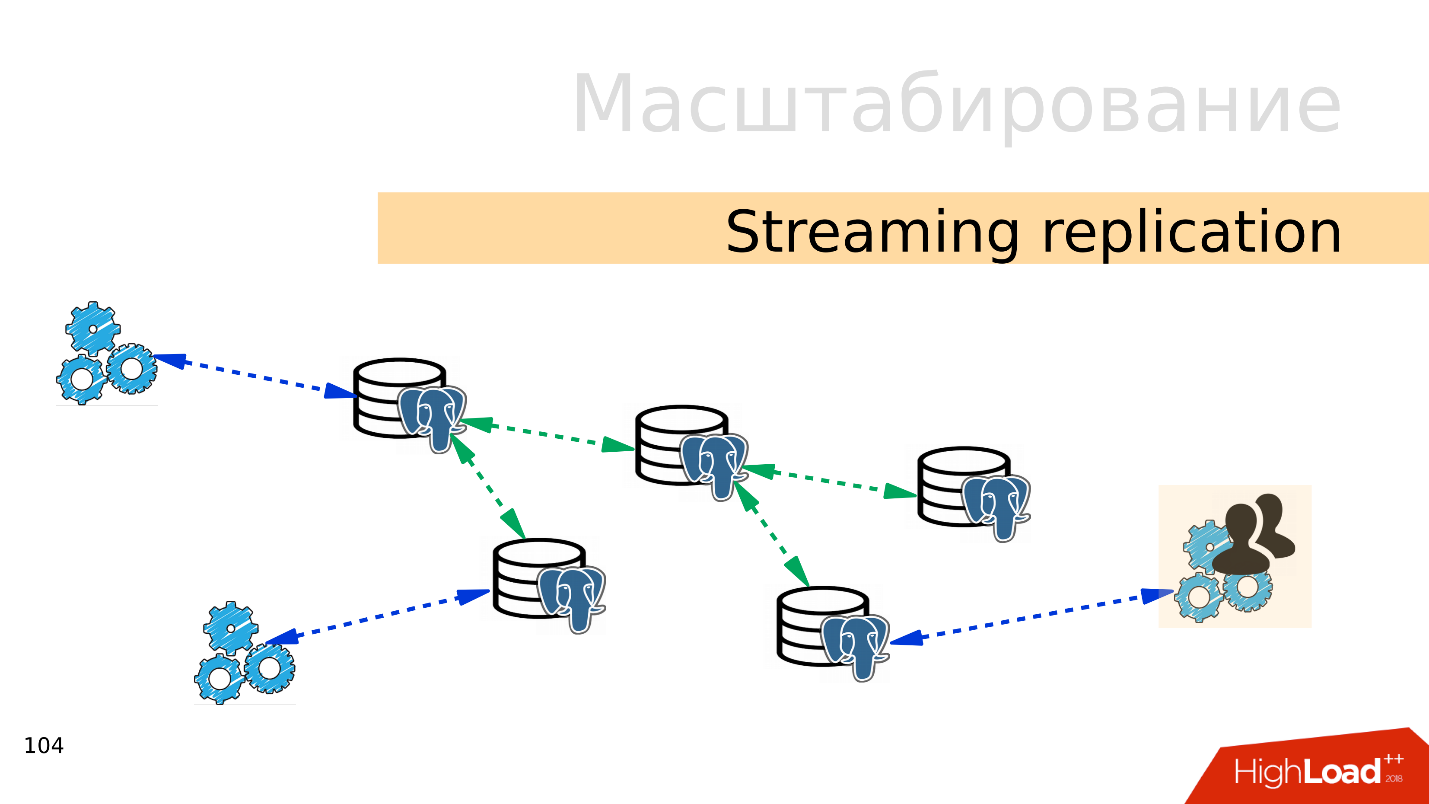
Streaming de replicación . La opción más fácil es
la replicación de transmisión . Cuando la aplicación funciona con la base de datos, conectamos varias réplicas a esta base de datos y distribuimos la carga. La grabación todavía va a la base maestra y la lectura a las réplicas. Este método le permite escalar muy ampliamente.
Además, puede conectar más réplicas a réplicas individuales y obtener
replicación en cascada . Grupos de usuarios o aplicaciones separados que, por ejemplo, leen análisis, se pueden mover a una réplica separada.
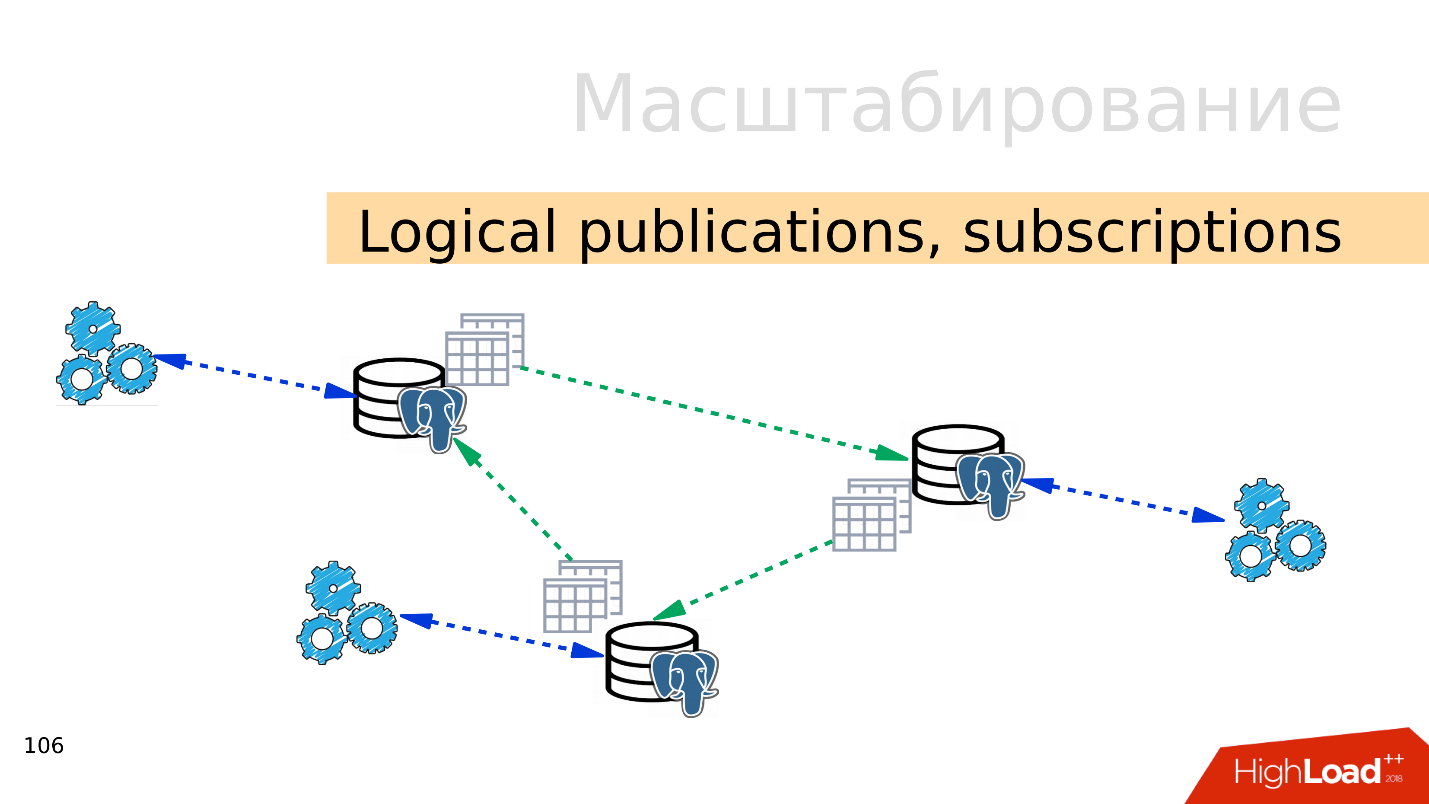
 Publicaciones lógicas, suscripciones
Publicaciones lógicas, suscripciones : el mecanismo de suscripciones y publicaciones lógicas implica la presencia de varios servidores PostgreSQL independientes con bases de datos y conjuntos de tablas independientes. Estos conjuntos de tablas se pueden conectar a bases de datos vecinas, serán visibles para las aplicaciones que pueden usarlas normalmente. Es decir, todos los cambios que se producen en el origen se replican en la base de destino y son visibles allí. Funciona muy bien con PostgreSQL 10.
 Tablas foráneas, Particionamiento declarativo - Particionamiento declarativo y tablas externas
Tablas foráneas, Particionamiento declarativo - Particionamiento declarativo y tablas externas . Puede tomar varios PostgreSQL y crear varios conjuntos de tablas allí que almacenarán los rangos de datos deseados. Estos pueden ser datos de un año específico o datos recopilados en cualquier rango.
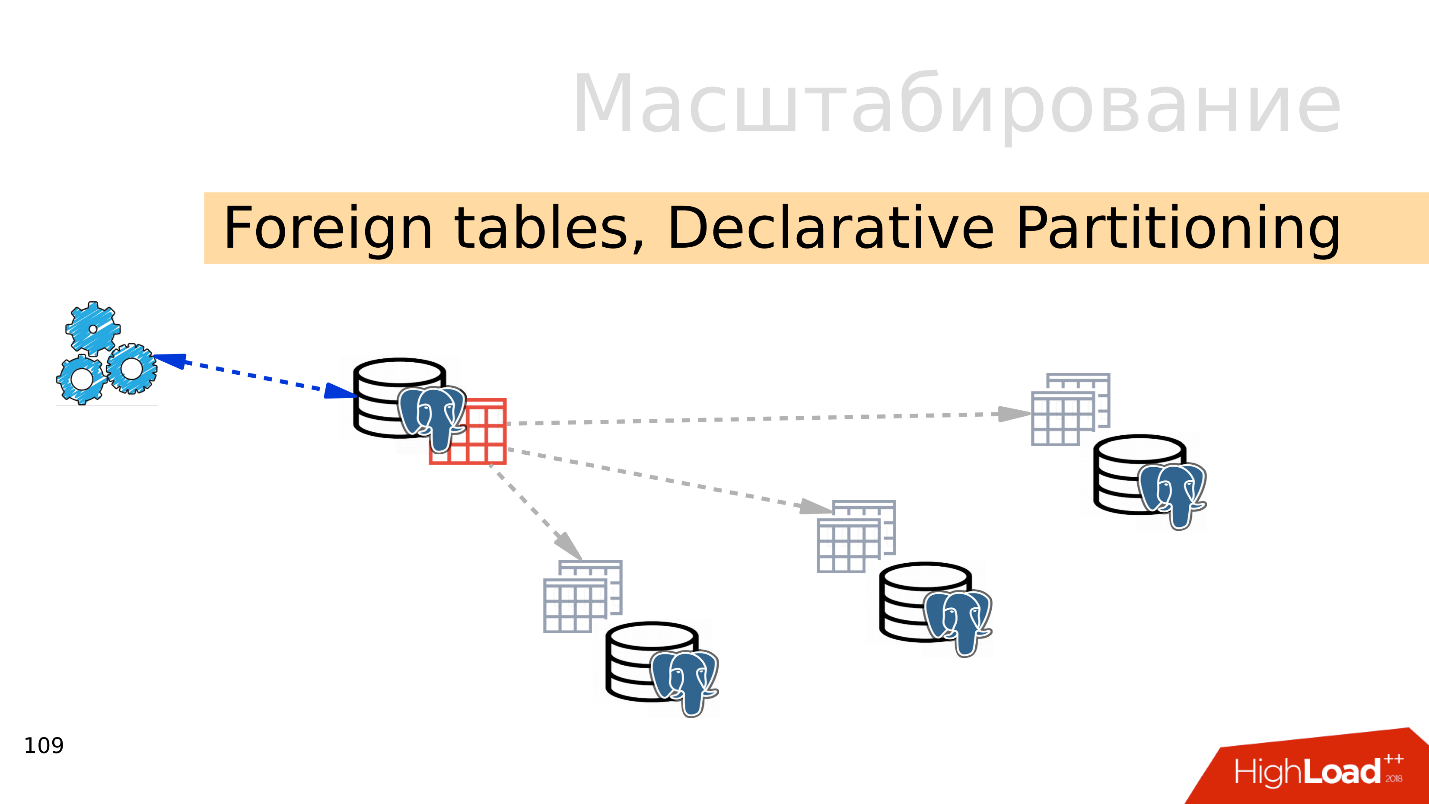
Usando el mecanismo de tablas externas, puede combinar todas estas bases de datos en forma de una tabla particionada en un PostgreSQL separado. Es posible que una aplicación ya funcione con esta tabla particionada, pero de hecho leerá datos de particiones remotas. Cuando los volúmenes de datos son más que las capacidades de un servidor, esto es fragmentación.

Todo esto se puede combinar en configuraciones de expansión, para obtener diferentes topologías de replicación PostgreSQL, pero cómo funciona todo y cómo administrarlo es el tema de un informe separado.
Por donde empezar
La opción más fácil es
con la replicación . El primer paso es repartir la carga de lectura y escritura. Es decir, escriba al maestro y lea las réplicas. Entonces escalamos la carga y llevamos a cabo la lectura del asistente. Además, no te olvides de los analistas. Las consultas analíticas funcionan durante mucho tiempo, necesitan una réplica separada con configuraciones separadas para que las consultas analíticas largas no puedan interferir con el resto.
El siguiente paso es
equilibrar . Todavía tenemos la misma línea en la configuración en la que opera el desarrollador. Necesita un lugar donde escriba y lea. Hay varias opciones aquí.
Lo ideal es implementar el equilibrio
a nivel de la aplicación , cuando la aplicación en sí misma sabe dónde leer los datos y sabe cómo elegir una réplica. Suponga que el saldo de una cuenta siempre se necesita actualizado y debe leerse desde el maestro, y la imagen del producto o la información al respecto se pueden leer con cierto retraso y desde una réplica.
- DNS Round Robin , en mi opinión, no es una implementación muy conveniente, porque a veces funciona durante mucho tiempo y no proporciona el tiempo necesario al cambiar las funciones de asistente entre servidores en casos de conmutación por error.
- Una opción más interesante es usar Keepalived y HAProxy . Las direcciones virtuales para el maestro y el conjunto de réplicas se lanzan entre los servidores HAProxy, y HAProxy ya está equilibrando el tráfico.
- Patroni, DCS junto con algo como ZooKeeper, etcd, Consul, la opción más interesante, en mi opinión. Es decir, el descubrimiento de servicios es responsable de la información sobre quién es el maestro ahora y quién es la réplica. Patroni administra un clúster de PostgreSQL, realiza la conmutación: si la topología ha cambiado, esta información aparecerá en el descubrimiento de servicios y las aplicaciones pueden encontrar rápidamente la topología actual.
Y hay matices con la replicación, el más común de los cuales es el
retraso de la
replicación . Puede hacerlo como GitLab, y cuando se acumula el retraso, simplemente suelte la base. Pero tenemos un monitoreo integral: lo miramos y vemos transacciones largas.
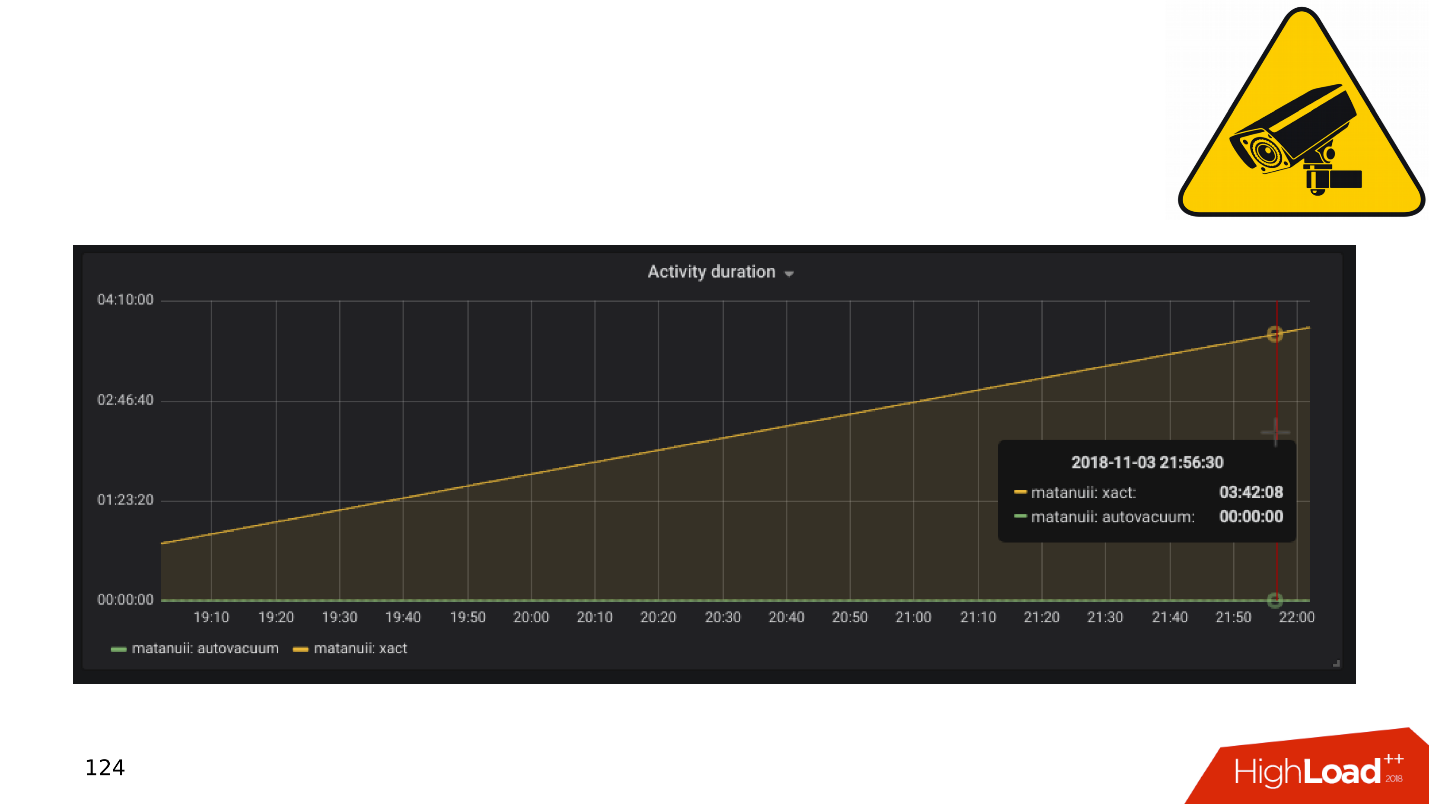
Aplicaciones y transacciones DBMS
En general, las transacciones lentas e inactivas resultan en:
- disminución de la productividad , no a un espasmódico agudo, sino suave;
- bloqueos y puntos muertos , porque las transacciones largas mantienen bloqueos en las filas y evitan que otras transacciones funcionen;
- 50 * errores HTTP en el backend , errores de interfaz o en otro lugar.
Veamos una pequeña teoría sobre cómo surgen estos problemas y por qué el mecanismo de transacciones largas e inactivas es perjudicial.
PostgreSQL tiene MVCC, relativamente hablando, un motor de base de datos. Permite a los clientes trabajar de manera competitiva con los datos sin interferir entre sí: los lectores no interfieren con los lectores, y los escritores no interfieren con los escritores. Por supuesto, hay algunas excepciones, pero en este caso no son importantes.
Resulta que en la base de datos para una fila puede haber varias versiones para diferentes transacciones. Los clientes se conectan, la base de datos les proporciona instantáneas de datos, y dentro de estas instantáneas pueden existir diferentes versiones de la misma línea. En consecuencia, en el ciclo de vida de la base de datos, las transacciones se cambian, se reemplazan entre sí y aparecen versiones de filas que nadie necesita.
Por lo tanto, existe la
necesidad de un recolector de basura: aspiradora automática . Existen transacciones largas y evitan que la aspiradora automática limpie versiones innecesarias de filas. Estos datos basura comienzan a vagar de la memoria al disco, del disco a la memoria. Para almacenar esta basura, se desperdician recursos de CPU y memoria.
Cuanto más larga sea la transacción, más basura y menor rendimiento.
Desde el punto de vista de "¿Quién tiene la culpa?", La aplicación tiene la culpa de la aparición de largas transacciones. Si la base de datos existirá por sí sola, no se tomarán transacciones largas de no hacer nada de ninguna parte. En la práctica, existen las siguientes opciones para la aparición de transacciones inactivas.
"Vayamos a una fuente externa" . La aplicación abre una transacción, hace algo en la base de datos, luego decide recurrir a una fuente externa, por ejemplo, Memcached o Redis, con la esperanza de que luego regrese a la base de datos, continúe trabajando y cierre la transacción. Pero si se produce un error en la fuente externa, la aplicación se bloquea y la transacción permanece cerrada hasta que alguien lo note y lo mate.
Sin manejo de errores . Por otro lado, puede haber un problema al manejar los errores. Cuando, nuevamente, la aplicación abrió una transacción, resolvió un problema en la base de datos, regresó a la ejecución del código, realizó algunas funciones y cálculos, para continuar trabajando en la transacción y cerrarla. Cuando en estos cálculos, la operación de la aplicación se interrumpió con un error, el código regresó al comienzo del ciclo y la transacción nuevamente permaneció sin cerrar.
El factor humano . Por ejemplo, un administrador, desarrollador, analista, trabaja en algún pgAdmin o en DBeaver: abre una transacción y hace algo en ella. Luego la persona se distrajo, cambió a otra tarea, luego a la tercera, se olvidó de la transacción, se fue para el fin de semana y la transacción continúa suspendida. El rendimiento base sufre.
Veamos qué hacer en estos casos.
- Tenemos monitoreo; en consecuencia, necesitamos alertas en el monitoreo . Cualquier transacción que se cuelgue durante más de una hora y no haga nada es una ocasión para ver de dónde vino y comprender qué está mal.
- El siguiente paso es disparar tales transacciones a través de la tarea en la corona (pg_terminate_backend (pid)) o configurar en la configuración de PostgreSQL. Se necesitan umbrales de 10-30 minutos, después de lo cual las transacciones se completan automáticamente.
- Refactorización de aplicaciones . Por supuesto, debe averiguar de dónde provienen las transacciones inactivas, por qué ocurren y eliminar dichos lugares.
Evite transacciones largas a toda costa, ya que afectan en gran medida el rendimiento de la base de datos.
Todo se vuelve aún más interesante cuando aparecen tareas pendientes, por ejemplo, debe calcular cuidadosamente las unidades. Y llegamos al tema de la construcción de bicicletas.
Construcción de bicicletas
Tema dolorido. Las empresas del lado de la aplicación deben realizar un procesamiento en segundo plano de los eventos. Por ejemplo, para calcular los agregados: mínimo, máximo, valor promedio, enviar notificaciones a los usuarios, emitir facturas a los clientes, configurar una cuenta de usuario después del registro o registrarse en los servicios vecinos, hacer el procesamiento retrasado.
La esencia de tales tareas es la misma: se posponen para más adelante. Las tablas aparecen en la base de datos que solo ejecutan las colas.

Aquí está el identificador de la tarea, el momento en que se creó la tarea, cuando se actualizó, el controlador que la tomó, el número de intentos de completar. Si tiene una tabla que incluso se parece remotamente a esta, entonces tiene
colas autoescritas .
Todo esto funciona bien hasta que aparecen transacciones largas. Después de eso, las
tablas que funcionan con colas aumentan de tamaño . Se agregan nuevos trabajos todo el tiempo, se eliminan los antiguos, se realizan actualizaciones: se obtiene una tabla con grabación intensiva. Debe limpiarse regularmente de versiones obsoletas de cadenas para que el rendimiento no se vea afectado.
El tiempo de procesamiento está aumentando : una transacción larga mantiene bloqueado las versiones obsoletas de las filas o evita que la aspiradora lo limpie. Cuando la tabla crece en tamaño, el tiempo de procesamiento también aumenta, ya que debe leer muchas páginas con basura. El tiempo aumenta y la
cola en algún momento deja de funcionar .
A continuación se muestra un ejemplo de la parte superior de uno de nuestros clientes, que tenía una cola. Todas las solicitudes solo están relacionadas con la cola.

Preste atención al tiempo de ejecución de estas solicitudes, todas menos una funcionan por más de veinte segundos.
Para resolver estos problemas,
Skytools PgQ , un gestor de colas para PostgreSQL, se inventó hace mucho tiempo. No reinvente su bicicleta: tome PgQ, configúrelo una vez y olvídese de las líneas.
Es cierto, él también tiene características. Skytools PgQ tiene
poca documentación . Después de leer la página oficial, uno tiene la sensación de que no entendió nada. El sentimiento crece cuando intentas hacer algo. Todo funciona, pero
no está claro cómo funciona . Algún tipo de magia Jedi. Pero se puede encontrar mucha información en
las listas de correo . Este no es un formato muy conveniente, pero hay muchas cosas interesantes allí, y tendrá que leer estas hojas.
A pesar de las desventajas, Skytools PgQ funciona según el principio de "configurar y olvidar". , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
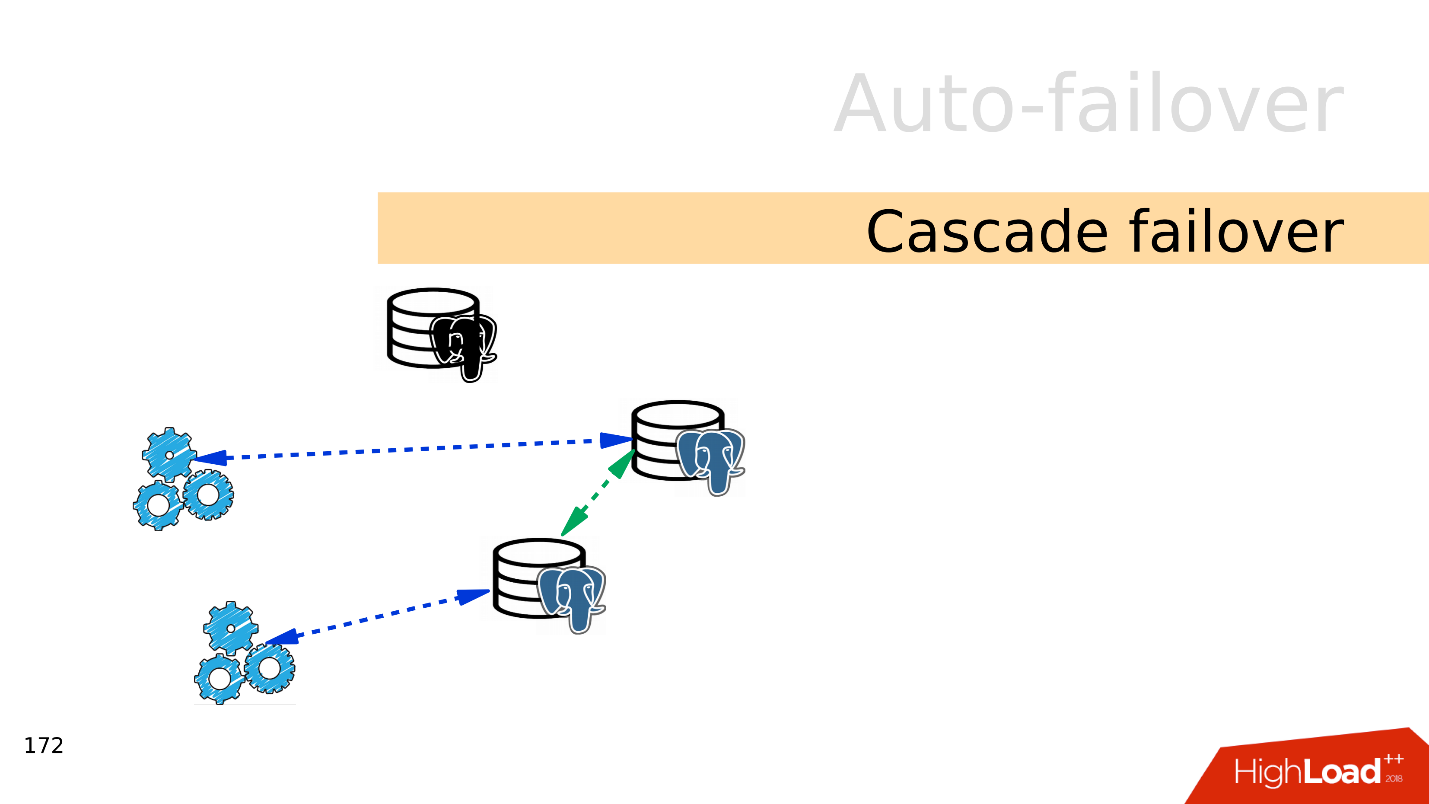
, . , .
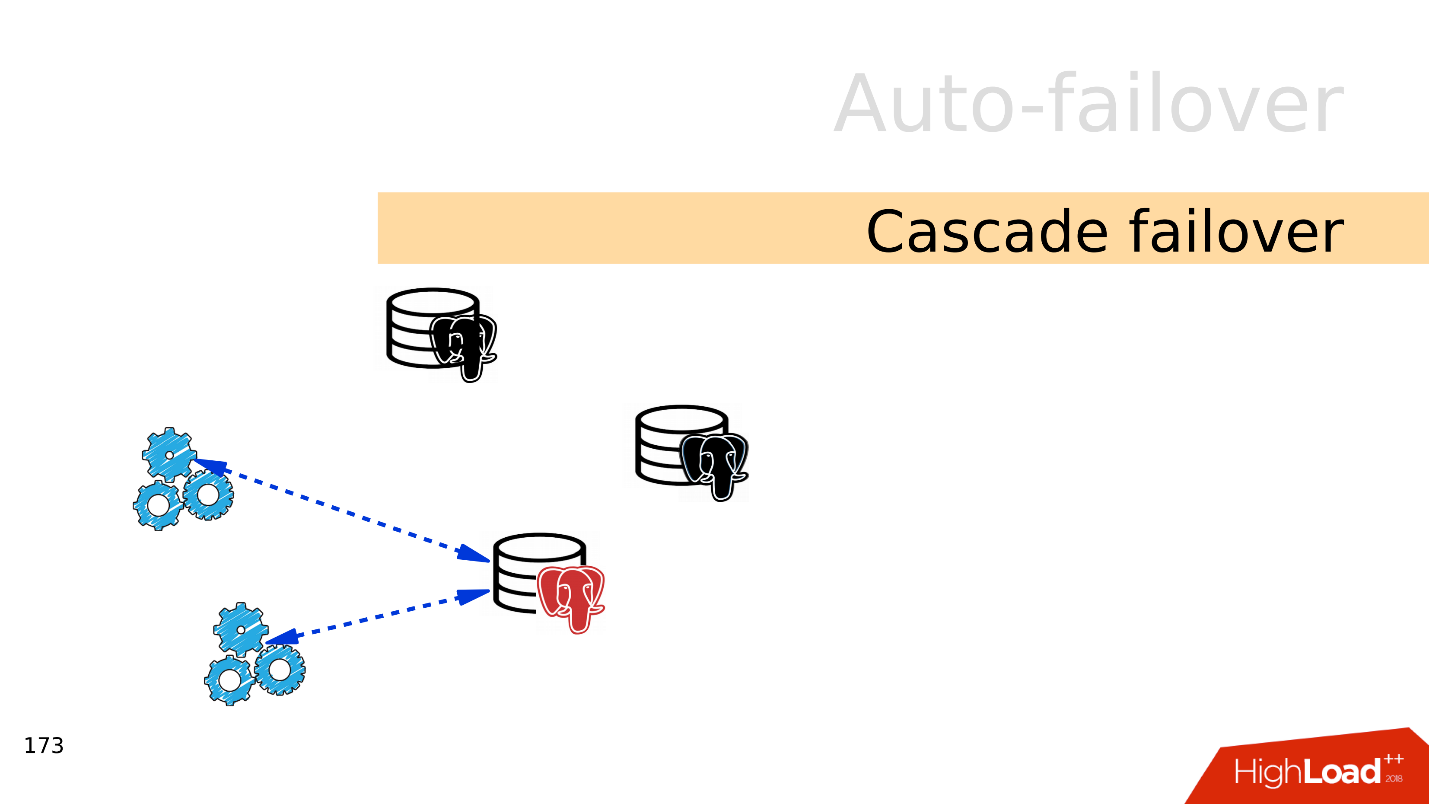
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
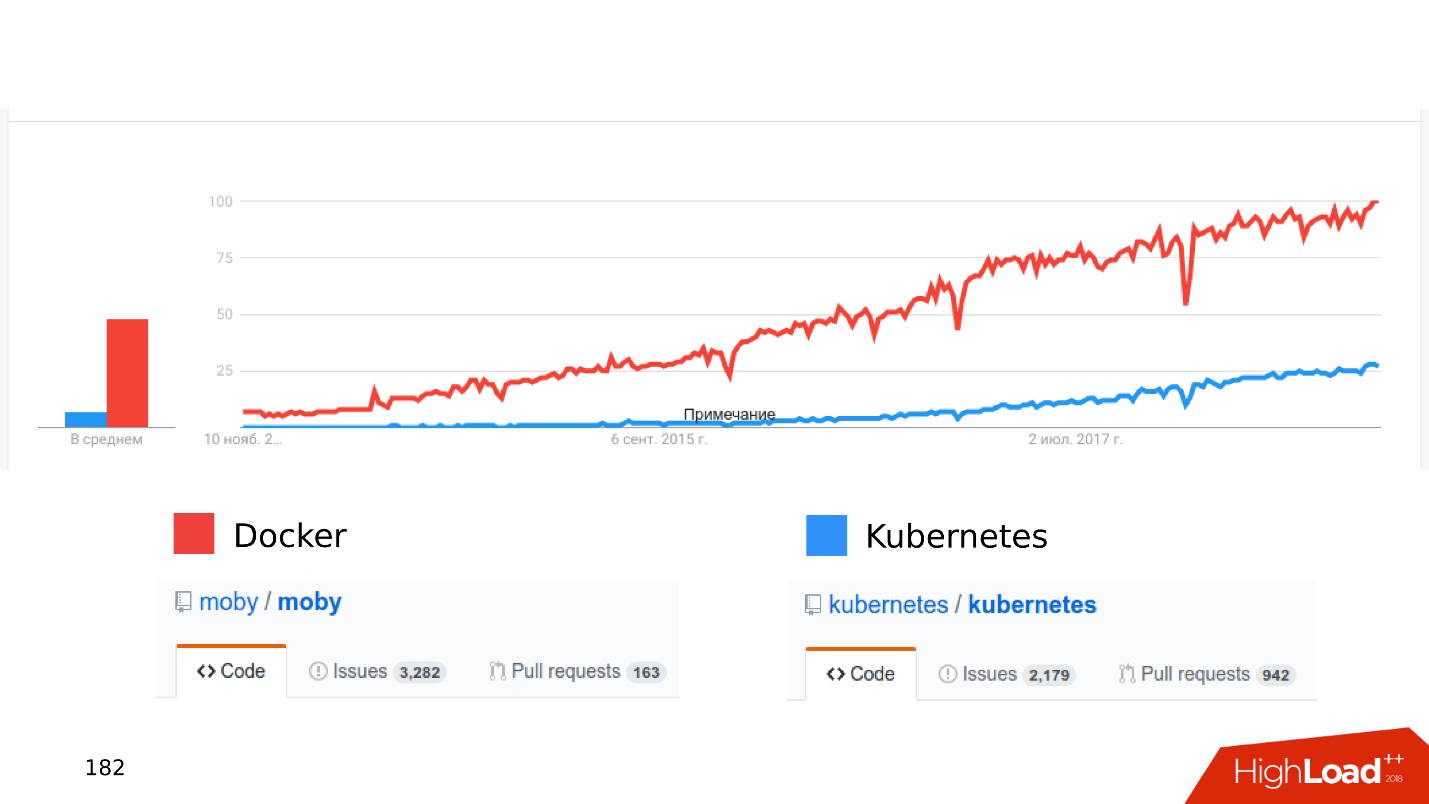
, .
« Kubernetes...» .
— stateful , - . Donde . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
Resumen
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !