Hola a todos! Recientemente descubrí el lenguaje Rust. Compartió sus primeras impresiones en un artículo anterior . Ahora decidí profundizar un poco más, para esto necesitas algo más serio que la lista. Mi elección recayó en el árbol Merkle. En este artículo quiero:
- hablar sobre esta estructura de datos
- mira lo que Rust ya tiene
- ofrece tu implementación
- comparar rendimiento
Árbol de merkle
Esta es una estructura de datos relativamente simple, y ya hay mucha información al respecto en Internet, pero creo que mi artículo estará incompleto sin una descripción del árbol.
Cual es el problema
El árbol Merkle se inventó en 1979, pero ganó popularidad gracias a la cadena de bloques. La cadena de bloques en la red es muy grande (para bitcoin es más de 200 GB), y no todos los nodos pueden bombearla. Por ejemplo, teléfonos o cajas registradoras. Sin embargo, necesitan saber sobre el hecho de incluir esta o aquella transacción en el bloque. Para esto, se inventó el protocolo SPV - Verificación de pago simplificada .
¿Cómo funciona un árbol?
Este es un árbol binario cuyas hojas son hashes de cualquier objeto. Para construir el siguiente nivel, los hash de las hojas vecinas se toman en pares, se concatenan y se calcula el hash del resultado de la concatenación, que se ilustra en la imagen del encabezado. Por lo tanto, la raíz del árbol es un hash de todas las hojas. Si elimina o agrega un elemento, la raíz cambiará.
¿Cómo funciona un árbol?
Al tener un árbol Merkle, puede generar evidencia de la inclusión de una transacción en un bloque como una ruta desde un hash de transacción a la raíz. Por ejemplo, estamos interesados en la transacción Tx2, para ello la prueba será (Hash3, Hash01). Este mecanismo también se usa en SPV. El cliente solo descarga el encabezado del bloque con su hash. Al tener una transacción de interés, solicita pruebas de un nodo que contiene toda la cadena. Luego realiza una comprobación, para Tx2 será:
hash(Hash01, hash(Hash2, Hash3)) = Root Hash
El resultado se compara con la raíz del encabezado del bloque. Este enfoque hace que sea imposible falsificar evidencia, porque en este caso el resultado de la prueba no converge con el contenido del encabezado.
Qué implementaciones ya existen
Rust es un lenguaje joven, pero muchas realizaciones del árbol Merkle ya están escritas en él. A juzgar por Github, en este momento 56, esto es más que en C y C ++ combinados. Aunque Go los pone de pie con 80 implementaciones.
Para mi comparación, elegí esta implementación por el número de estrellas en el repositorio.
Este árbol está construido de la manera más obvia, es decir, es un gráfico de objetos. Como ya señalé, este enfoque no es completamente amigable con Rust. Por ejemplo, no es posible hacer una comunicación bidireccional de niños a padres.
La construcción de evidencia ocurre a través de una búsqueda en profundidad. Si se encuentra una hoja con el hash correcto, entonces el camino será el resultado.
¿Qué se puede mejorar?
No fue interesante para mí hacer una implementación simple (n + 1), así que pensé en la optimización. El código para mi vector-merkle-tree está en Github .
Almacenamiento de datos
Lo primero que viene a la mente es cambiar el árbol a una matriz. Esta solución será mucho mejor en términos de localidad de datos: más aciertos de caché y mejor precarga. Caminar alrededor de objetos dispersos de la memoria lleva más tiempo. Un hecho conveniente es que todos los hashes tienen la misma longitud, porque calculado por un algoritmo El árbol de Merkle en la matriz se verá así:

Prueba
Cuando inicializa el árbol, puede crear un HashMap con todos los índices de hoja. Por lo tanto, cuando no hay hoja, no es necesario rodear todo el árbol, y si la hay, puede ir inmediatamente hacia ella y elevarse hasta la raíz, construyendo una prueba. En mi implementación, hice HashMap opcional.
Concatenación y Hash
Parece que aquí se puede mejorar? Después de todo, todo está claro: toma dos hashes, pégalos y calcula un nuevo hash. Pero el hecho es que esta función no es conmutativa, es decir hash (H0, H1) ≠ hash (H1, H0). Debido a esto, al construir la prueba, debe recordar de qué lado está el nodo vecino. Esto hace que el algoritmo sea más difícil de implementar y agrega la necesidad de almacenar datos redundantes. Todo es muy fácil de arreglar, solo ordena los dos nodos antes del hash. Por ejemplo, cité Tx2, teniendo en cuenta la conmutatividad, la verificación se verá así:
hash(hash(Hash2, Hash3), Hash01) = Root Hash
Cuando no tiene que preocuparse por el orden, el algoritmo de verificación parece una simple convolución de una matriz:
pub fn validate(&self, proof: &Vec<&[u8]>) -> bool { proof[2..].iter() .fold( get_pair_hash(proof[0], proof[1], self.algo), |a, b| get_pair_hash(a.as_ref(), b, self.algo) ).as_ref() == self.get_root() }
El elemento cero es el hash del objeto deseado, el primero es su vecino.
Vamos!
La historia estaría incompleta sin una comparación de rendimiento, lo que me llevó varias veces más que la implementación del árbol en sí. Para estos fines, utilicé el marco de criterios . Las fuentes de las pruebas en sí están aquí . Todas las pruebas se realizan a través de la interfaz TreeWrapper , que se implementó para ambos temas:
pub trait TreeWrapper<V> { fn create(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn find(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn validate(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); }
Ambos árboles funcionan con la misma criptografía en anillo . Aquí no voy a comparar diferentes bibliotecas. Tomé lo más común.
Como objetos hash, se utilizan cadenas generadas aleatoriamente. Los árboles se comparan en matrices de varias longitudes: (500, 1000, 1500, 2000, 2500 3000). 2500 - 3000 es el número aproximado de transacciones en el bloque bitcoin en este momento.
En todos los gráficos, el eje X indica el número de elementos de la matriz (o el número de transacciones en el bloque), y el eje Y representa el tiempo promedio para completar la operación en microsegundos. Es decir, cuanto más peor.
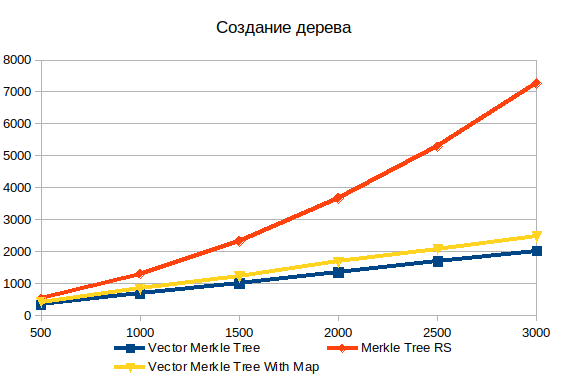
Fabricación de árboles
El almacenamiento de todos los datos del árbol en una matriz excede en gran medida el gráfico de rendimiento de los objetos. Para una matriz con 500 elementos, 1.5 veces, y para 3000 elementos ya 3.6 veces. La naturaleza no lineal de la dependencia de la complejidad del volumen de datos de entrada en la implementación estándar es claramente visible.
Además, en comparación, agregué dos variantes del árbol de vectores: con y sin HashMap . Llenar una estructura de datos adicional agrega aproximadamente el 20%, pero le permite buscar objetos mucho más rápido al generar evidencia.
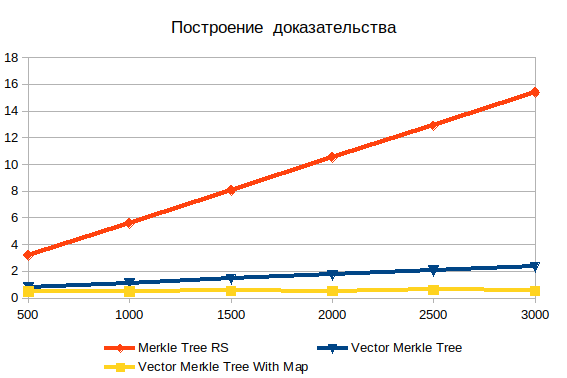
Construyendo evidencia
Aquí puede ver la ineficiencia evidente de la búsqueda en profundidad. Con un aumento en la entrada, solo empeora. Es importante comprender que los objetos que está buscando son hojas, por lo que no puede haber complejidad de log (n) . Si los datos se procesan previamente, el tiempo de operación es prácticamente independiente del número de elementos. Sin hashing, la complejidad crece linealmente y consiste en la búsqueda de fuerza bruta.
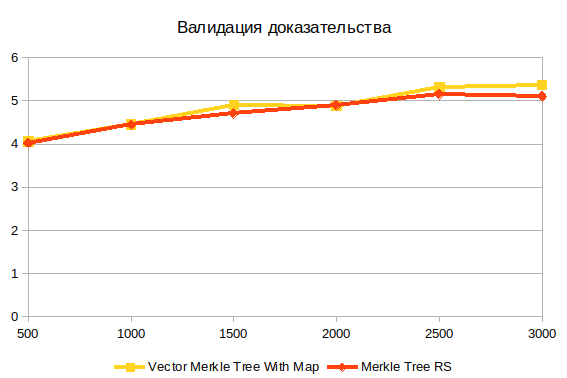
Validación de evidencia
Esta es la última operación. No depende de la estructura del árbol, porque trabaja con el resultado de construir evidencia. Creo que la principal dificultad aquí es el cálculo hash.
Resumen
- La forma en que se almacenan los datos afecta en gran medida el rendimiento. Cuando todo en una matriz es mucho más rápido. Y serializar tal estructura será muy simple. La cantidad total de código también se reduce.
- La concatenación de nodos con ordenación simplifica enormemente el código, pero no lo hace más rápido.
Un poco sobre el óxido
- Me gustó el marco de criterios . Da resultados claros con valores promedio y desviaciones equipadas con gráficos. Capaz de comparar diferentes implementaciones del mismo código.
- La falta de herencia no interfiere en gran medida con la vida.
- Las macros son un mecanismo poderoso. Los usé en mis pruebas de árbol para la parametrización. Creo que si se usan mal, puede hacer tal cosa que usted mismo no será feliz más tarde.
- En algunos lugares, el compilador aburrido con sus comprobaciones de memoria. Mi suposición inicial de que comenzar a escribir en Rust tan simplemente no funcionó fue correcta.
Referencias