Sensación de muerte, soledad, al mismo tiempo, una sed loca por la vida ... Se podría pensar que decidimos dar una conferencia sobre expresionismo y sumergirnos en el trabajo de Munch. Pero no Usted pasa por todas estas etapas en el momento en que ve que su deuda técnica pronto empujará a su empresa al abismo de la crisis.

Durante 8 años, el equipo de TI de Dodo Pizza ha crecido de 2 desarrolladores que atienden a un país a 80 personas que atienden a 12 países. Hace tres años, me uní a Dodo Pizza como Chief Agile Officer y comencé a ayudar a los equipos a crear procesos e implementar prácticas de ingeniería. A menudo, estas implementaciones eran demasiado lentas. Además, se descubrió que cuando varios equipos trabajan en el mismo producto, es difícil lograr que mantengan un código de alta calidad.
Proseguimos el desarrollo de las funciones comerciales, posponiendo la perfección técnica del código para más adelante. Entonces estábamos atrapados. Una enorme deuda técnica nos atrapó, pero no la aplastó, pero solo, con un chasquido de dedos, arrojó a nuestra compañía al abismo de la crisis. En 2018, el equipo de marketing lanzó una campaña publicitaria masiva, no pudimos soportar la carga y caímos. Vergüenza, vergüenza y vergüenza. Pero durante la crisis, nos dimos cuenta de que podemos trabajar muchas veces de manera más eficiente. La crisis nos obligó a implementar rápidamente las prácticas de ingeniería más famosas y revolucionar los procesos.
Antecedentes
Dodo Pizza es una empresa cyborg que vende pizza . Nuestro negocio se basa en la plataforma Dodo IS, que gestiona todos los procesos comerciales: recepción de pedidos, fabricación de pizzas, gestión de inventario, gestión de personas (gestión) y mucho, mucho más. En solo 8 años, hemos crecido de 2 desarrolladores que sirven a una pizzería a más de 80 desarrolladores que sirven a 498 pizzerías en 12 países.
Hace tres años, Dodo IS era un monolito que contenía 1 millón de líneas de código. Hubo una pequeña cobertura con las pruebas unitarias, no hubo pruebas API / UI en absoluto. La calidad del código en sí fue decepcionante. Todos sabían sobre esto, o al menos lo adivinaron. En sueños de un futuro mejor, dividimos el monolito en una docena de servicios y reescribimos las partes más desagradables del sistema. Incluso dibujamos un diagrama de la arquitectura "futura", pero, francamente, no hicimos nada para acercarnos a ella.
Mientras más crecía el equipo, más sufríamos por la falta de un proceso claro y prácticas de ingeniería. Los lanzamientos se hicieron cada vez más, porque los seis equipos de desarrollo realizaron cambios simultáneamente en diferentes ramas. Cuando los equipos fusionaron sus cambios en una rama, a veces perdimos hasta 4 horas tratando de resolver conflictos de fusión. No hubo pruebas de regresión automática, y con cada lanzamiento dedicamos más y más tiempo a la regresión manual.
Mierda pasa
En 2018, el equipo de marketing lanzó nuestra primera campaña publicitaria de televisión federal con un presupuesto de 100 millones de rublos. Fue un gran evento para Dodo Pizza. El equipo de TI también estaba bien preparado para la campaña. Hemos automatizado y simplificado nuestra implementación: ahora con un solo botón en TeamCity podríamos implementar un monolito en 12 países. Mediante pruebas de rendimiento, realizamos un análisis de vulnerabilidad. Hicimos nuestro mejor esfuerzo, pero la jodimos de todos modos.
La campaña publicitaria fue increíble. Recibimos de 100 a 300 pedidos por minuto. Esa fue una buena noticia. La mala noticia: Dodo IS no pudo soportar tal carga y murió. Alcanzamos el límite de escala vertical y ya no pudimos procesar pedidos. El sistema se reinicia cada 3 horas. Cada minuto de tiempo de inactividad nos costó decenas de miles de rublos, sin contar la pérdida de respeto de los clientes enojados.
Cuando llegué a Dodo Pizza hace tres años, inmediatamente comencé a implementar prácticas de ingeniería. La mayoría de los equipos adoptaron programación de pares, pruebas de unidades y DDD con bastante rapidez. Pero no todo fue tan simple. Tuve que superar la resistencia de los desarrolladores, los productos y el equipo de soporte.
A diferencia de las ideas de las prácticas de ingeniería, al principio no todos apoyaban la idea de los equipos de características. Los desarrolladores están acostumbrados a pensar que un equipo centrado en un componente escribe el mejor código. No estaba claro cómo combinar el rápido desarrollo de las funciones comerciales con la refactorización masiva desde hace mucho tiempo de un sistema complejo. Además, este flujo interminable de errores constantemente requería atención ... Lanzamos el producto no más de una vez a la semana, y cada lanzamiento tomó mucho tiempo, requirió una gran cantidad de regresión manual y soporte para las pruebas de IU. Traté de arreglarlo, pero el cambio del proceso fue demasiado lento y fragmentado.
La historia de la caída y el ascenso.
Estado inicial: arquitectura monolítica
En la búsqueda de la velocidad de desarrollo de las funciones comerciales, no siempre pensamos bien en las soluciones técnicas. Afectado por la falta de experiencia. Teníamos una aplicación monolítica con una única base de datos que contenía todos los datos de todos los componentes en un solo lugar. Rastreador, contabilidad, sitio web, API para páginas de destino: todos los componentes del sistema funcionaban con una base de datos, lo que era un cuello de botella.
Historia verdadera
La arquitectura monolítica es buena para comenzar, porque es simple. Pero no puede soportar una carga alta, siendo el único punto de falla. Una vez que todos nuestros restaurantes en Rusia dejaron de aceptar pedidos debido a una publicación de blog. ¿Cómo pudo pasar esto?
Nuestro CEO, Fedor, publicó una publicación en su blog. Esta publicación ganó popularidad rápidamente. El sitio del blog de Fedor tiene un contador que muestra el número de pizzerías en nuestra red y el ingreso total de todas las pizzerías. Cada vez que alguien lee el blog de Fedor, el servidor web envía una solicitud a la base de datos maestra para calcular los ingresos. Estas solicitudes sobrecargaron tanto la base de datos que dejó de atender las solicitudes de la caja del restaurante. Rápidamente solucionamos el problema, pero esta fue una de las muchas señales de que nuestra arquitectura no podía satisfacer las necesidades del negocio y debería ser rediseñada. Sin embargo, continuamos ignorando estos signos.
Choque temprano en 2017
14 de febrero. Para los amantes de las felicitaciones, el 14 de febrero, hacemos una pizza especial: Pepperoni en forma de corazón. Siempre recordaré el 14 de febrero de 2017, porque en este día, cuando todas las pizzerías estaban trabajando a plena carga, Dodo IS comenzó a caer. Cada pizzería tiene 4-5 tabletas para la gestión de la producción: para qué orden el fabricante de pizza rueda la masa, pone los ingredientes, hornea o la envía para su entrega. En ese momento, el número de pizzerías llegó a más de 150, cada tableta se actualizó varias veces por minuto. Todas estas consultas crearon una carga tan grande en la base de datos que dejó de resistir y comenzó a fallar. Dodo IS murió durante el pico de ventas. Pero había una temporada de vacaciones ocupada por delante: 23 de febrero, 8 de marzo, 1 y 9 de mayo. Durante estas vacaciones, esperábamos un crecimiento aún mayor en los pedidos.
El día que mueras . Conociendo nuestros planes de crecimiento y el límite de carga que podemos soportar, descubrimos cuánto tiempo podemos seguir con vida. La fecha estimada de Armagedón se esperaba en unos seis meses: en agosto - septiembre de 2017. ¿Cómo es vivir, sabiendo la fecha de su muerte?
Detener el desarrollo de funciones por un año. Junto con el CEO Fedor, tuvimos que tomar una decisión difícil. Quizás una de las decisiones más difíciles en la historia de la empresa. Durante el año siguiente, creamos una sola característica comercial. El resto del tiempo los equipos pagaron la deuda técnica. Esta deuda nos costó caro: más de 100 millones de rublos solo para los salarios de los desarrolladores.
Algunas mejoras después de un año.
A lo largo del año, hemos crecido notablemente:
- Automatizamos y aceleramos el proceso de implementación a 4-5 horas.
- Finalmente, comenzamos a ver el monolito: el rastreador y las placas de TV se trasladaron a un servicio separado con su propia base de datos
- Comenzamos a separar la caja de efectivo de entrega, el segundo componente que creó una gran carga
- Reescribió el sistema de autenticación de usuarios y dispositivos
Parece que podríamos estar orgullosos de nosotros mismos. Pero delante de nosotros había una gran decepción.
Fracaso durante la campaña publicitaria federal. Segunda crisis de confianza
La deuda técnica es fácil de acumular, pero muy difícil de pagar. Es poco probable que pueda comprender de antemano cuánto le costará.
A pesar del hecho de que luchamos con un retraso técnico durante todo un año, no estábamos listos para una campaña de marketing masivo y volvimos a equivocarnos frente a nuestro negocio. La confianza que ganamos gota a gota desapareció.
Bajo la carga de la Campaña Federal de Marketing, volvemos a acostarnos. El sistema se bloqueó nuevamente y se reinició cada 3 horas. Nuestro negocio estaba perdiendo decenas de millones de rublos.

Gracias a la crisis, aprendimos que en condiciones extremas podemos trabajar muchas veces de manera más eficiente. Somos liberados 20 veces al día. Todos trabajaron como un solo equipo, enfocándose en un objetivo. Durante las dos semanas de crisis, hicimos lo que temíamos incluso comenzar a hacer antes, creyendo que tomaría meses de trabajo. Recepción asíncrona de pedidos, inhabilitación de pedidos, pruebas de estrés, registros limpios: esto es solo una pequeña parte de lo que hemos hecho. Queríamos continuar trabajando con la misma eficiencia, pero sin horas extras y sin estrés.
Lecciones aprendidas
Después de la retrospectiva, reorganizamos completamente nuestros procesos. Tomamos LeSS como base y lo complementamos con prácticas de ingeniería. En los próximos meses, hicimos un gran avance en la introducción de prácticas de ingeniería. Basado en LeSS, hemos implementado y seguimos utilizando:
- Producto atrasado
- Comandos completamente cruzados funcionales y de componentes cruzados
- Programación en pareja y mafia
- Integración continua verdadera (CI): integración de código con 12 equipos en una rama
- Trabajo simplificado con ramas (desarrollo basado en troncales)
- Lanzamientos frecuentes: despliegue continuo para microservicios, lanzamiento diario para monolitos
- Rechazo de un equipo de control de calidad separado, los expertos en control de calidad son parte del equipo de desarrollo
6 prácticas que elegimos después de la crisis:
1. El poder del enfoque. Antes de la crisis, cada equipo trabajaba con su propia deuda y se especializaba en su campo. Durante la crisis, los equipos no tenían tareas específicas; tenían un gran objetivo difícil. Por ejemplo, una aplicación móvil y una API deben procesar 300 pedidos por minuto, pase lo que pase. El equipo toma la meta e independientemente piensa cómo lograrla. El equipo mismo formula las hipótesis y las prueba rápidamente en el producto. Los equipos no quieren ser simples programadores, quieren resolver problemas.
El poder del enfoque se manifiesta en tareas complejas. Por ejemplo, durante la crisis, creamos pruebas de estrés, a pesar de que no teníamos experiencia. También hicimos la lógica para recibir el pedido de forma asincrónica. Lo pensamos durante mucho tiempo y hablamos, y nos pareció que esta es una tarea muy difícil, que puede llevar mucho tiempo. Pero resultó que el equipo es bastante capaz de hacer esto en 2 semanas, si no está distraído y se centra completamente en el problema.
2. Hackatones internos. Realizamos el Hackathon 500 Errores. Todos los equipos juntos borraron los registros y eliminaron las causas de 500 errores en el sitio y en la API. El objetivo era mantener limpios los registros. Cuando los registros están limpios, los nuevos errores son claramente visibles, puede establecer fácilmente umbrales para alertas.
Otro ejemplo de un hackathon son los errores. Anteriormente, teníamos una acumulación completa de errores, algunos de ellos colgados por muchos años. Nunca parecieron terminar. Y cada día aparecían nuevos. Combinamos el trabajo en errores y los elementos habituales de la cartera de pedidos.
Política de #Zerobugspolicy.- Si el error ha estado en la cartera durante más de 3 meses, simplemente elimínelo. Había permanecido allí por siglos, y nadie murió.
- Evalúe el dolor que los errores restantes causan a los clientes. Deje solo los errores que dificultan la vida de un gran grupo de usuarios.
- Organice un hackathon interno para errores. Lo hicimos en unos pocos sprints. Cada sprint, cada equipo tomó varios errores y los corrigió. Después de 2-3 sprints, tuvimos una acumulación limpia. Ahora puede ingresar #zerobugspolicy.
- #zerobugspolicy. Si el error entra en la cartera de pedidos, definitivamente se solucionará. Cualquier error en el backlog tiene una prioridad más alta que cualquier otro elemento del backlog. Pero para entrar en la cartera de pedidos, el error debe ser grave. O hace un daño irreparable o afecta a un gran número de usuarios.
3. De los equipos del proyecto a un equipo estable. Hubo una historia divertida con los equipos del proyecto. Durante la crisis, formamos equipos expertos de personas que estaban más calificadas para la tarea. Después de que terminó la crisis, los equipos decidieron continuar esta práctica. A pesar de que no me gustó esta idea, lo intentamos. En solo 2 semanas (un sprint), en la próxima retrospectiva, los equipos abandonaron esta práctica (esta decisión me hizo feliz). Si un equipo carece de algunas habilidades, puede aprender gradualmente. Pero el espíritu de equipo, el apoyo y la asistencia mutua tardan mucho tiempo en completarse, lleva meses. Los equipos de proyectos a corto plazo están constantemente en la etapa de formación y tormenta. Puede tolerar esto durante varias semanas, pero no podrá trabajar de esta manera todo el tiempo.
4. Sin regresión manual. Fijamos una meta para deshacernos de las regresiones manuales. Nos llevó 1,5 años alcanzarlo. Pero tener un objetivo ambicioso a largo plazo te hace pensar en los pasos que conducen al objetivo.
Lo hicimos en 3 pasos.- Automatización de ruta crítica.
En junio de 2017, formamos un equipo de control de calidad. La tarea del equipo era automatizar la regresión de la funcionalidad más crítica de Dodo IS: recibir y producir pedidos. Durante los próximos 6 meses, un nuevo equipo de control de calidad de 4 personas cubrió todas las funciones críticas del sistema con pruebas automáticas. Los desarrolladores del equipo de funciones ayudaron activamente al equipo de control de calidad. Juntos escribimos un lenguaje de dominio (DSL) hermoso y comprensible, que incluso los clientes entendieron. Paralelamente a las pruebas de extremo a extremo, los desarrolladores ponderaron el código con pruebas unitarias. Algunos componentes nuevos se han rediseñado con TDD. Después de eso, disolvimos el equipo de control de calidad. Los ex miembros del equipo de control de calidad se unieron a los equipos que trabajan en funciones comerciales para transferir la experiencia de desarrollar y apoyar las pruebas automáticas a los equipos. - Modo de sombra.
Al tener pruebas automáticas, durante 5 lanzamientos hicimos una regresión manual en modo sombra. Los equipos solo confiaron en las pruebas automáticas, pero cuando el equipo decidió que estaba listo para el lanzamiento, lanzamos una regresión manual para verificar si nuestras pruebas automáticas habían fallado. Rastreamos cuántos errores fueron detectados manualmente y no detectados por las pruebas automáticas. Después de 5 lanzamientos, analizamos los datos y decidimos que podemos confiar en nuestras pruebas automáticas. No se perdieron errores importantes. - Denegación de regresión manual.
Cuando tuvimos suficientes pruebas para comenzar a confiar en ellas, abandonamos por completo las pruebas manuales. Cuantas más pruebas escribimos, más confiamos en ellas. Pero esto solo sucedió 1.5 años después de que comenzamos a automatizar las pruebas de regresión.
5. Las pruebas de estrés son parte de la regresión. Durante la crisis, escribimos pruebas de estrés. Esta fue una experiencia completamente nueva para nosotros. Sin embargo, en solo 2 semanas, pudimos crear algo usando las herramientas de Visual Studio. Los usamos, incluso para generar carga artificial en el servidor, con el fin de encontrar límites de rendimiento. Por ejemplo, si la carga orgánica en el producto es de 100 pedidos / min, agregamos otros 50 pedidos / min utilizando nuestras pruebas para ver si el sistema puede manejar el aumento de carga.
Al año siguiente, reescribimos las pruebas de estrés con un equipo experimentado de PerformanceLab. Hoy en día, estas pruebas se ejecutan semanalmente y proporcionan comentarios rápidos a los equipos de desarrollo.
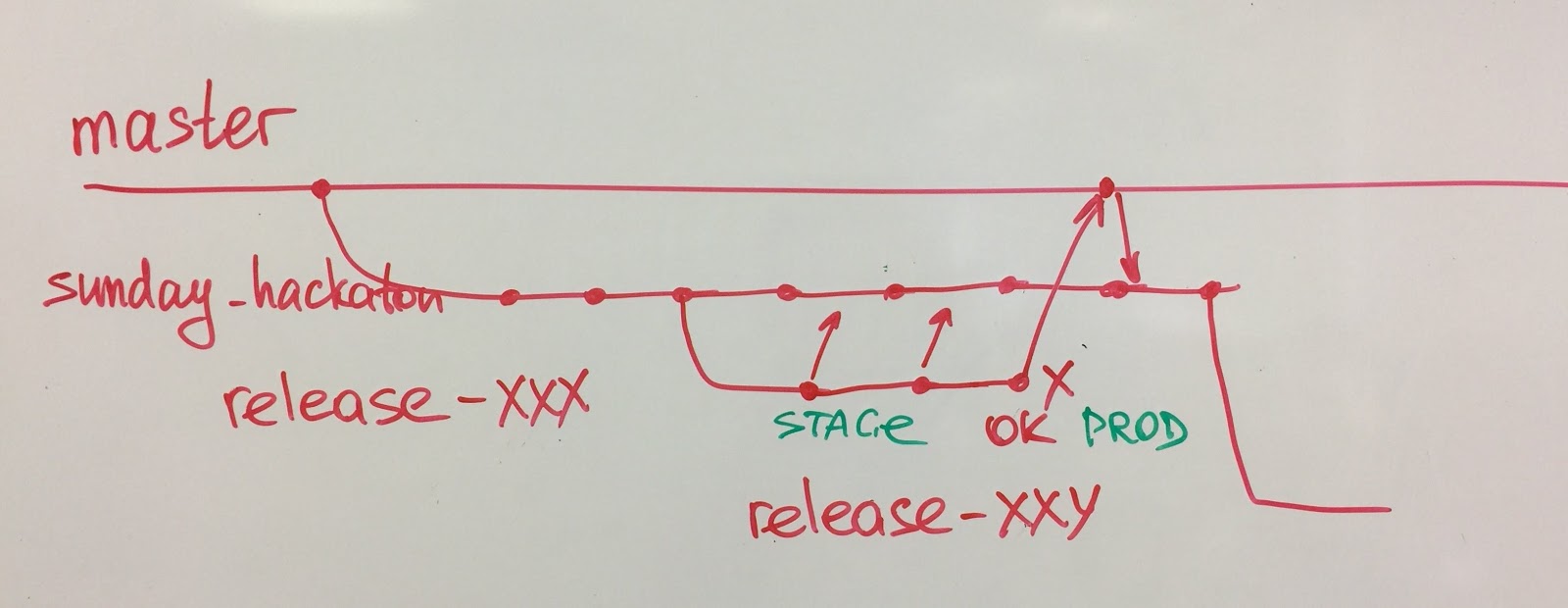 6. Prácticas de ingeniería.
6. Prácticas de ingeniería. Todos nuestros equipos usan programación en pares. Considero que la programación en pareja es una de las prácticas más simples pero más poderosas. Si no sabe con qué práctica de ingeniería comenzar, le recomiendo la programación de pares.
Resultados
El resultado principal para nosotros fue una sacudida. Nos despertamos y comenzamos a actuar. La crisis nos ayudó a ver nuestro máximo potencial. Vimos que podemos trabajar muchas veces de manera más eficiente y alcanzar rápidamente nuestros objetivos. Pero para esto es necesario cambiar la forma habitual de trabajar. Ya no tenemos miedo de los experimentos audaces.
Como resultado de estos experimentos durante el año pasado, hemos mejorado significativamente la calidad y la estabilidad del Dodo IS. Si durante las vacaciones de primavera de 2018 nuestras pizzerías no pudieron funcionar debido a Dodo IS, entonces, en 2019, con un aumento de 300 a 498 pizzerías, Dodo IS funciona perfectamente. Sobrevivimos con calma el pico de ventas en el nuevo año, durante la segunda campaña de marketing y las vacaciones de primavera.
Por primera vez en mucho tiempo, confiamos en la calidad del sistema y podemos permitirnos dormir profundamente por la noche. Este es el resultado del uso continuo de métodos de ingeniería y un enfoque en la excelencia técnica.
Resultados comerciales
Las prácticas de ingeniería no son necesarias por sí mismas si no benefician a su negocio. Como resultado de centrarnos en la excelencia técnica, mejoramos la calidad del código y desarrollamos funciones comerciales con una velocidad predecible. Los lanzamientos se han convertido en un evento común para nosotros.
Resultados para equipos
Hoy utilizamos una amplia gama de métodos de ingeniería:
- Comandos completamente cruzados funcionales y de componentes cruzados
- Programación par / mafia
- Integración continua: integración continua de 12 comandos en una rama
- Experto en la materia como equipo
- No hay un equipo de control de calidad separado, los expertos en control de calidad son parte de los equipos de desarrollo
- Sustitución de regresión manual con autotest
- Política sin errores (#Zerobugspolicy)
- Detenga la línea como conductor para acelerar la implementación
Que hemos aprendido
Me gustaría que la crisis no suceda. Como desarrollador, me sentí personalmente responsable de acumular demasiadas deudas técnicas y de no poder prever las consecuencias.
- Las prácticas de ingeniería protegen a las empresas de las crisis.
- No acumule deuda técnica. Puede llegar demasiado tarde y costar demasiado.
- Los cambios evolutivos tardan varias veces más que los revolucionarios.
- Una crisis no siempre es algo malo. Utiliza la crisis para revolucionar los procesos
- Sin embargo, se requiere un largo entrenamiento evolutivo por adelantado.
- No aplique a ciegas todos los métodos que desee. Algunos métodos están esperando en las alas, y cuando llegue, los equipos los usarán sin resistencia. Espera el momento adecuado
- Con el tiempo, los propios equipos comienzan a tomar decisiones importantes y a implementarlas. Bríndeles un entorno propicio para probar, déjelos fallar y aprenda de los errores
La deuda técnica nos ha llevado a una terrible crisis. Estoy muy contento de que nuestro equipo haya encontrado la fuerza para usar este punto muerto como punto de crecimiento. En nuestra propia piel, nos dimos cuenta de que el tiempo de crisis puede y debe usarse para cambios masivos en la organización y el proceso. Así que nunca te rindas, porque incluso en las situaciones más difíciles hay espacio para una hazaña.
Agradecimientos
Me gustaría dar las gracias a todas las personas que me ayudaron en mi viaje desde la crisis hasta la transformación de LeSS. Constantemente siento tu apoyo.Muchas gracias a nuestro CEO Fedor Ovchinnikov por su confianza. Eres un verdadero líder en una empresa con una cultura verdadera y flexible.Muchas gracias a Dmitry Pavlov, nuestro Product Owner, mi viejo amigo y co-entrenador.Gracias a Alexander Andronov y Andrey Morevsky por su apoyo.Muchas gracias a Dasha Bayanova, nuestro primer Scrum-master a tiempo completo, que siempre me ayuda y apoya con toda nuestra iniciativa. Su ayuda es difícil de sobreestimar.Un agradecimiento especial a Joanna Rothman, quien me ayudó a escribir este informe en cualquier condición: de vacaciones, recuperándose de una enfermedad. Joanna, fue un placer trabajar contigo. Su consejo, atención al detalle y trabajo duro me ayudaron mucho.