
Los ingenieros de DevOps y SRE probablemente hayan oído hablar de Prometheus más de una vez.
Prometheus se creó en SoundCloud en 2012 y desde entonces se ha convertido en el estándar para sistemas de monitoreo . Tiene un código fuente completamente abierto, proporciona docenas de exportadores diferentes con los que puede configurar el monitoreo de toda la infraestructura en minutos .
Prometheus tiene un valor obvio y ya está siendo utilizado por innovadores de la industria como DigitalOcean o Docker como parte de un sistema de monitoreo completo.
¿Qué es Prometeo?
¿Por qué es necesario?
¿Cómo es diferente de otros sistemas?
Si no sabe nada acerca de Prometheus o quiere comprenderlo mejor, su ecosistema y todas las interacciones, este artículo es solo para usted .
Dividimos esta guía en 3 partes, como lo hicimos con InfluxDB .
- Primero viene una descripción completa de Prometheus , su ecosistema y los aspectos clave de la tecnología de ritmo rápido.
- Luego, se proporcionan explicaciones de los términos técnicos de Prometheus . Si no sabe qué métricas, etiquetas, instancias o exportadores son, aquí está.
- Finalmente, describimos varios escenarios del mundo real para usar Prometheus . Aquí te inspirarás con ejemplos de empresas exitosas.
Parte I. ¿Qué es Prometeo?
Prometeo es una base de datos de series de tiempo. Si no sabe qué es una base de datos de series de tiempo, lea la primera parte del manual InfluxDB .
Pero Prometheus no es solo una base de datos de series de tiempo.
Puede adjuntarle un ecosistema completo de herramientas para expandir la funcionalidad.
Prometheus monitorea una amplia variedad de sistemas : servidores, bases de datos, máquinas virtuales individuales y casi cualquier cosa.
Para hacer esto, Prometeo raspa periódicamente sus objetivos .
¿Qué es el raspado?
Prometheus recupera métricas a través de llamadas HTTP a puntos finales específicos especificados en la configuración de Prometheus.
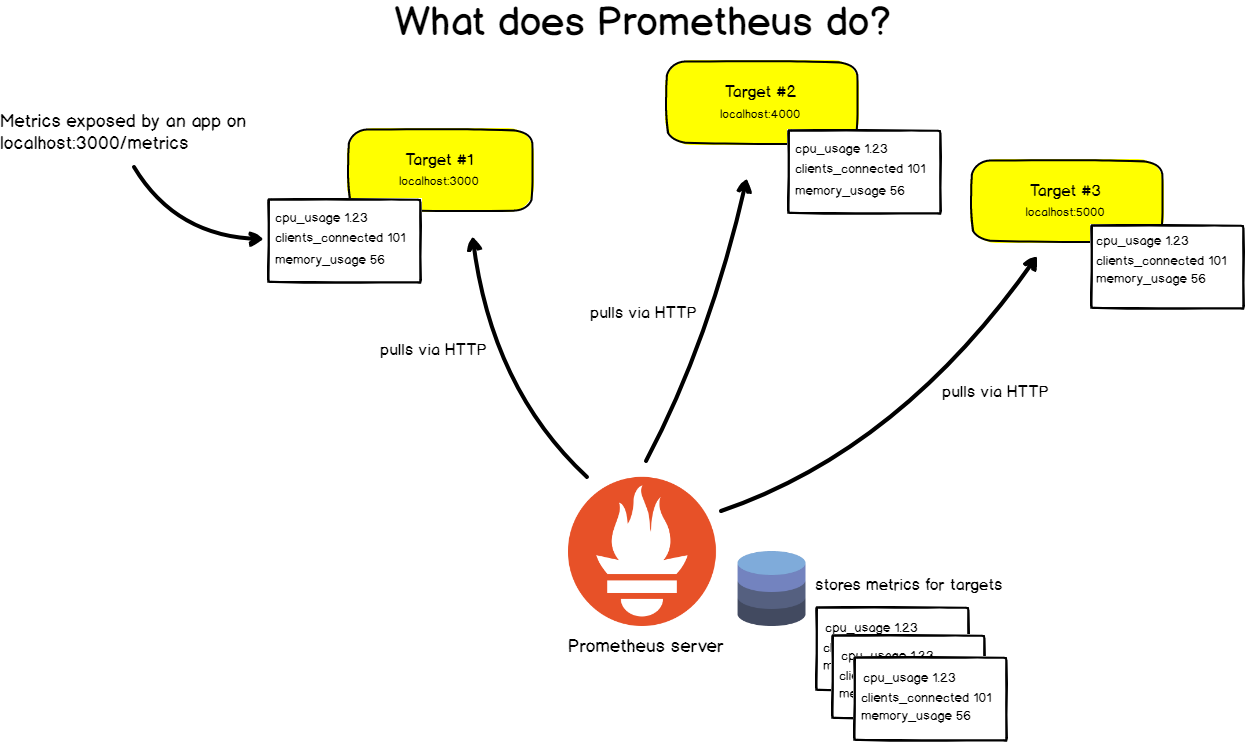
Tomemos, por ejemplo, la aplicación web ubicada en http: // localhost: 3000 . La aplicación transmite métricas en formato de texto a alguna URL. Digamos http: // localhost: 3000 / metrics .
En esta dirección, Prometheus recupera datos del objetivo a intervalos específicos.
1. ¿Cómo funciona Prometeo?
Como dijimos, Prometeo consta de una amplia variedad de componentes.
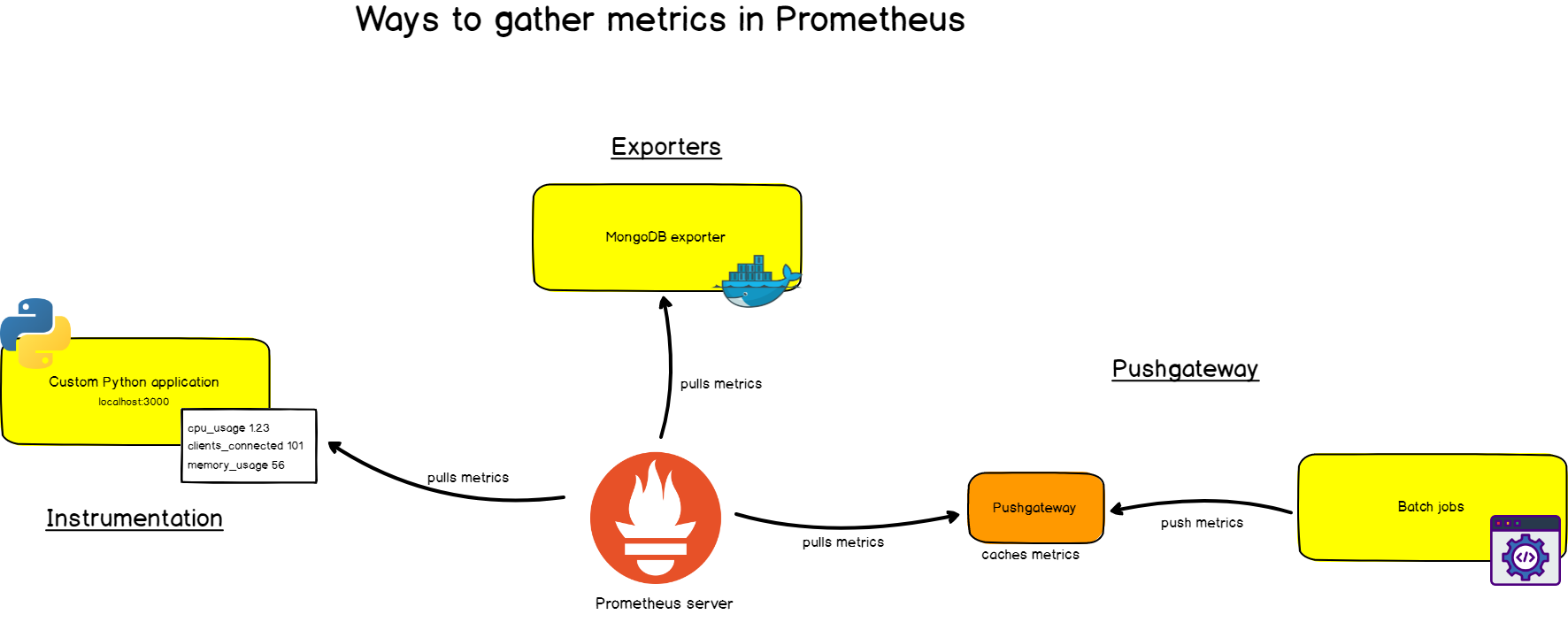
Primero, lo necesita para extraer métricas de sus sistemas. Hay diferentes formas:
- La instrumentación de la aplicación, es decir, su aplicación proporcionará métricas compatibles con Prometheus en la URL especificada. Prometheus lo identificará como el objetivo y lo desechará en el intervalo especificado.
- Uso de exportadores confeccionados . Prometheus tiene una colección de exportadores para tecnologías existentes. Por ejemplo, exportadores preparados para monitorear máquinas Linux ( Node Exporter ), para bases de datos comunes ( SQL Exporter o MongoDB Exporter ) e incluso para equilibradores de carga HTTP (por ejemplo, HAProxy Exporter ).
- Usando Pushgateway . A veces, las aplicaciones o tareas no proporcionan métricas directamente. Es posible que no estén diseñados para esto (por ejemplo, trabajos por lotes) o usted mismo decidió no proporcionar métricas directamente a través de la aplicación.
Como ya entendió, Prometheus recopila datos por sí mismo (excepto en los casos excepcionales en los que usamos Pushgateway).
¿Qué significa esto?
¿Por qué se necesita esto?
2. Colección vs. enviando
Prometheus tiene una diferencia notable con respecto a otras bases de datos de series de tiempo: escanea activamente los objetivos para obtener métricas de ellos .
InfluxDB, por ejemplo, funciona de manera diferente: usted mismo le envía datos directamente.
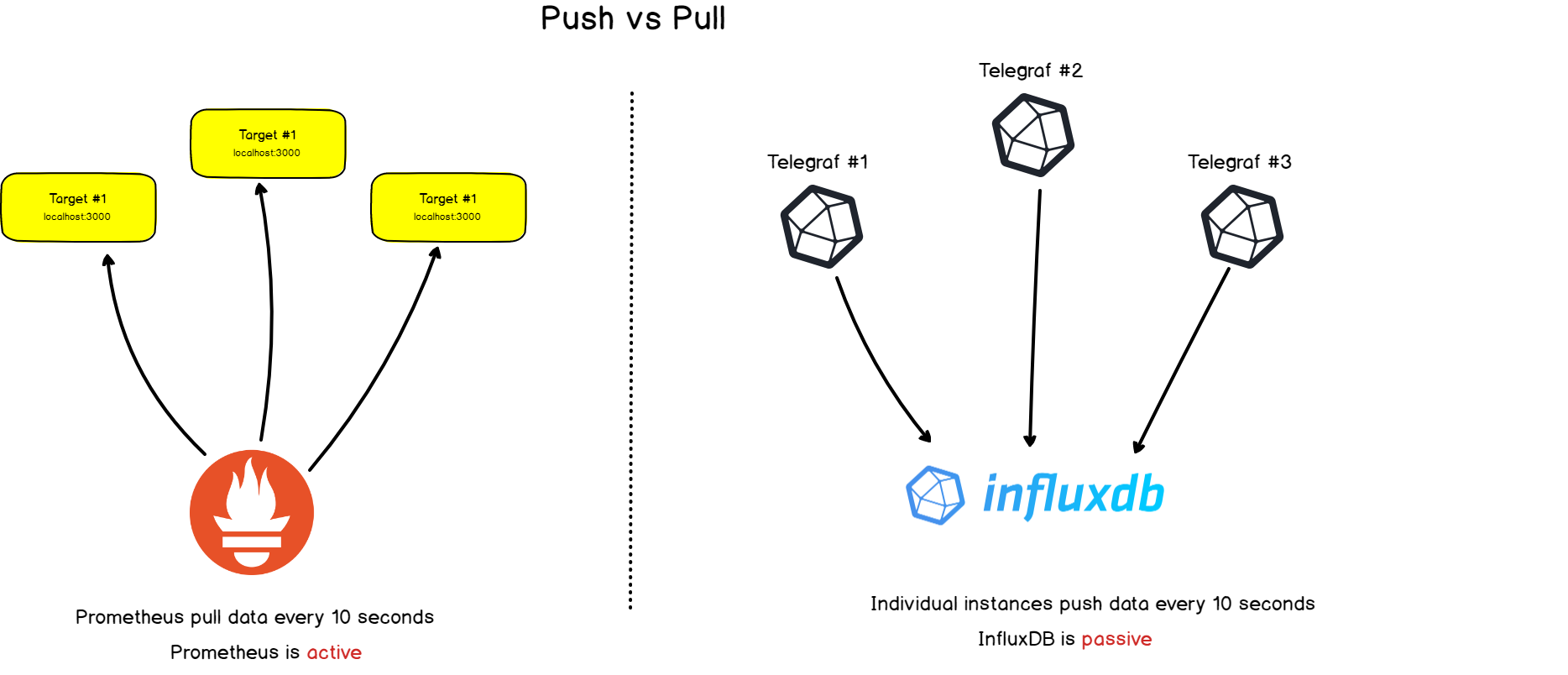
Ambos enfoques tienen sus pros y sus contras. Con base en la documentación disponible, hemos compilado una lista de razones por las cuales los creadores de Prometheus eligieron esta arquitectura:
- Control centralizado . Si Prometheus envía solicitudes a los objetivos, realizamos toda la configuración en el lado de Prometheus, no en los sistemas individuales.
Prometeo decide dónde y con qué frecuencia raspar.
Si los objetos mismos envían datos, existe el riesgo de que haya demasiados datos y el servidor se bloqueará. Cuando el sistema recopila datos, puede controlar la frecuencia de recopilación y crear varias configuraciones de raspado para seleccionar una frecuencia diferente para diferentes objetos .
- Prometheus almacena métricas agregadas .
Esta es una adición a la primera parte donde discutimos el papel de Prometeo.
Prometheus no está basado en eventos y es muy diferente de otras bases de datos de series temporales. No intercepta eventos individuales con referencia al tiempo (por ejemplo, interrupciones del servicio), sino que recopila métricas agregadas previamente sobre sus servicios .
Específicamente, el servicio web no envía un mensaje de error 404 y un mensaje con la causa del error. Se envía un mensaje de que el servicio recibió un mensaje de error 404 en los últimos cinco minutos.
Esta es la principal diferencia entre las bases de datos de series temporales que recopilan métricas agregadas y las que recopilan métricas sin procesar.
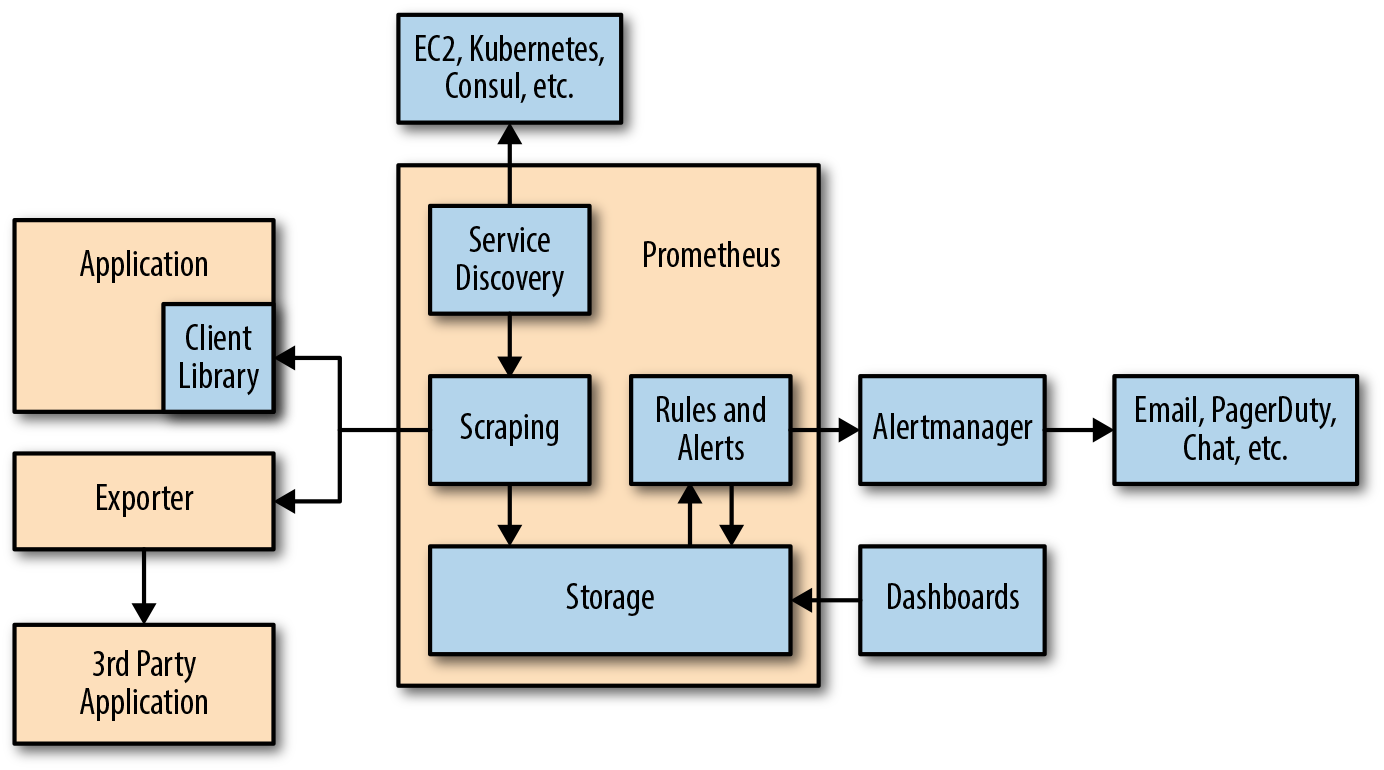
3. Desarrollo del ecosistema Prometeo
Básicamente, Prometheus es una base de datos de series de tiempo.
Pero cuando trabaja con tales bases de datos, a menudo necesita visualizar los datos, analizarlos y configurar alertas para ellos.
Prometheus admite las siguientes herramientas que amplían su funcionalidad:
- Alertmanager . Prometheus envía alertas a Alertmanager según las reglas personalizadas definidas en los archivos de configuración. A partir de ahí, se pueden exportar a diferentes puntos finales (por ejemplo, Pagerduty o Slack).
- Visualización de datos . Al igual que Grafana, puede visualizar series temporales directamente en la interfaz de usuario web de Prometheus. Puede filtrar los datos y crear revisiones específicas de lo que está sucediendo en diferentes objetivos.
- Servicio de descubrimiento . Prometheus detecta dinámicamente objetivos y raspa automáticamente nuevos objetivos a pedido. Esto es especialmente conveniente si trabaja con contenedores que cambian dinámicamente las direcciones según la demanda.

Parte II Conceptos de Prometeo
Como en el manual de InfluxDB, explicaremos en detalle los términos técnicos relacionados con Prometheus.
1. Modelo de datos de valor clave
Antes de pasar a las herramientas de Prometheus, es importante comprender completamente este modelo de datos.
Prometeo trabaja con pares clave-valor . La clave describe lo que estamos midiendo y el valor almacena el valor real como un número.
Recuerde: Prometheus no está diseñado para almacenar información en bruto, como texto sin formato. Almacena métricas agregadas durante un período de tiempo.
La clave en este caso se llama métrica . Esto es, por ejemplo, la velocidad del procesador o el uso de memoria.
Pero, ¿y si necesita más detalles sobre la métrica?
Por ejemplo, ¿el procesador tiene 4 núcleos y necesitamos 4 métricas separadas?
Y aquí los atajos vienen al rescate. Los accesos directos proporcionan más información sobre las métricas al agregar campos adicionales. Por ejemplo, usted describe no solo la velocidad del procesador, sino también la velocidad de un núcleo sobre una IP específica.
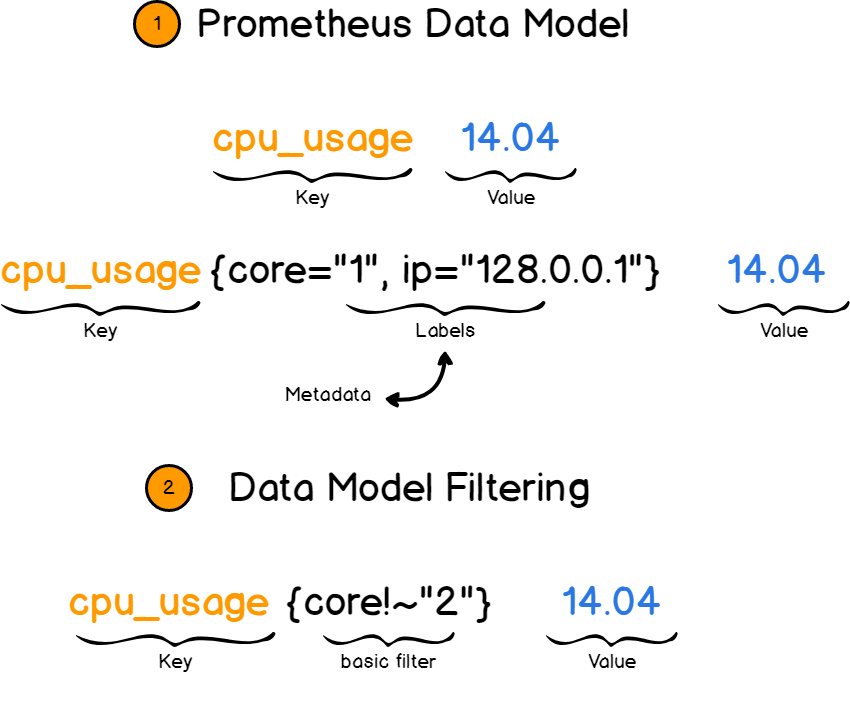
Luego puede filtrar las métricas por etiquetas y ver solo la información que necesita.
2. Tipos de métricas
Al monitorear con Prometheus, las métricas se pueden describir de cuatro maneras. Es mejor leerlo hasta el final, porque hay dificultades aquí.
Contador
Este es probablemente el tipo de métrica más simple. El contador, como su nombre lo indica, cuenta los elementos por un período de tiempo .
Si desea contar, por ejemplo, errores HTTP en servidores o visitar un sitio web, use un contador .
Y lógicamente, por supuesto, el contador solo puede aumentar o poner a cero el número , por lo tanto, no es adecuado para valores que pueden disminuir o para valores negativos.
Con su ayuda, es especialmente conveniente considerar el número de ocurrencias de un determinado evento durante un período de tiempo, es decir, la tasa de cambio de la métrica a lo largo del tiempo.
¿Y si necesita medir, por ejemplo, la memoria utilizada durante un período determinado?
Este valor puede disminuir. ¿Cómo contarlo con Prometeo?
Medidores
¡Conoce los medidores!
Los medidores manejan valores que pueden disminuir con el tiempo . Se pueden comparar con los termómetros: si observa el termómetro, veremos la temperatura actual.
Pero si los medidores pueden aumentar y disminuir y tomar valores positivos y negativos, ¿entonces resulta que son mejores que los contadores?
¿Entonces los contadores son inútiles?
Al principio, eso pensé. Como pueden hacer todo, usémoslos en todas partes. ¿Es lógico?
Pero no
Los medidores son ideales para medir el valor métrico actual, que puede disminuir con el tiempo.
Aquí es donde se encuentran los escollos: el medidor no muestra el desarrollo de la métrica durante un período de tiempo. Usando medidores, puede perderse los cambios métricos irregulares con el tiempo .
Por qué Esto es lo que dice / u / justinDavidow :
“El medidor muestra el valor promedio del contador delta para una unidad durante un período de tiempo.
El contador tiene en cuenta cada unidad utilizada (si es un procesador, luego operaciones, ciclos o tics), y luego puede elegir qué indicadores para qué período necesita.
Si está utilizando un medidor, la frecuencia de muestreo debe ser precisa. Si la frecuencia difiere al menos unos pocos microsegundos, el valor no será confiable. "Esto es aún más notable bajo una carga pesada, donde el tiempo entre mediciones aumenta exponencialmente, porque el planificador del sistema no tiene tiempo para prestar atención a la aplicación de monitoreo".
Si el sistema envía métricas cada 5 segundos y Prometheus raspa el objetivo cada 15, algunas métricas pueden perderse en el proceso. Si realiza cálculos adicionales con estas métricas, la precisión de los resultados será aún menor.
En el mostrador, cada valor se agrega. Cuando Prometeo lo recoge, se da cuenta de que el valor se envió en un intervalo determinado.
Ahora no te confundas.
Gráfico de barras
Un histograma es un tipo de métrica más complejo. Proporciona información adicional. Por ejemplo, la suma de las medidas y su número.
Los valores se recopilan en un área con un límite superior personalizado. Por lo tanto, un histograma puede:
- Calcule los valores promedio , es decir, la suma de los valores divididos por el número de valores.
- Calcule medidas relativas de valores , y esto es muy conveniente si necesita averiguar cuántos valores en un área determinada corresponden a los criterios especificados. Esto es especialmente útil si necesita rastrear proporciones o establecer indicadores de calidad.
En el mundo real, me gustaría recibir una alerta si el 20% de mis servidores tienen una respuesta de más de 300 ms o una respuesta del servidor de más de 300 ms más del 20% del tiempo.
Si se trata de proporciones, necesita histogramas .
Resumen
Los paneles son histogramas avanzados . También muestran la suma y el número de mediciones, y también cuantiles para el período móvil .
Los cuantiles, en todo caso, están dividiendo la densidad de probabilidad en segmentos de igual probabilidad.
Entonces: ¿gráficos de barras o resúmenes?
Todo depende de la intención .
Los histogramas combinan valores durante un período de tiempo, proporcionando la cantidad y la cantidad por la cual puede realizar un seguimiento del desarrollo de una métrica en particular.
Los resúmenes, por otro lado, muestran cuantiles durante un período de movimiento (es decir, desarrollo continuo en el tiempo).
Esto es especialmente conveniente si necesita conocer un valor que represente el 95% de los valores registrados durante un período.
3. Tareas e instancias
Dados los avances recientes en arquitecturas distribuidas y la popularidad de las soluciones basadas en la nube, es poco probable que use un solo servidor que se ejecute solo.
Los servidores se replican y distribuyen por todo el mundo.
Para ilustrar esto, echemos un vistazo a la arquitectura clásica de dos servidores HAProxy que redistribuyen la carga en nueve servidores web de fondo ( No, no, no hay pilas de Stackoverflow ) .
En este ejemplo de la vida real, rastrearemos la cantidad de errores HTTP devueltos por los servidores web .
En Prometheus, un servidor web se llama instancia . La tarea será el hecho de que mida la cantidad de errores HTTP en todas las instancias.
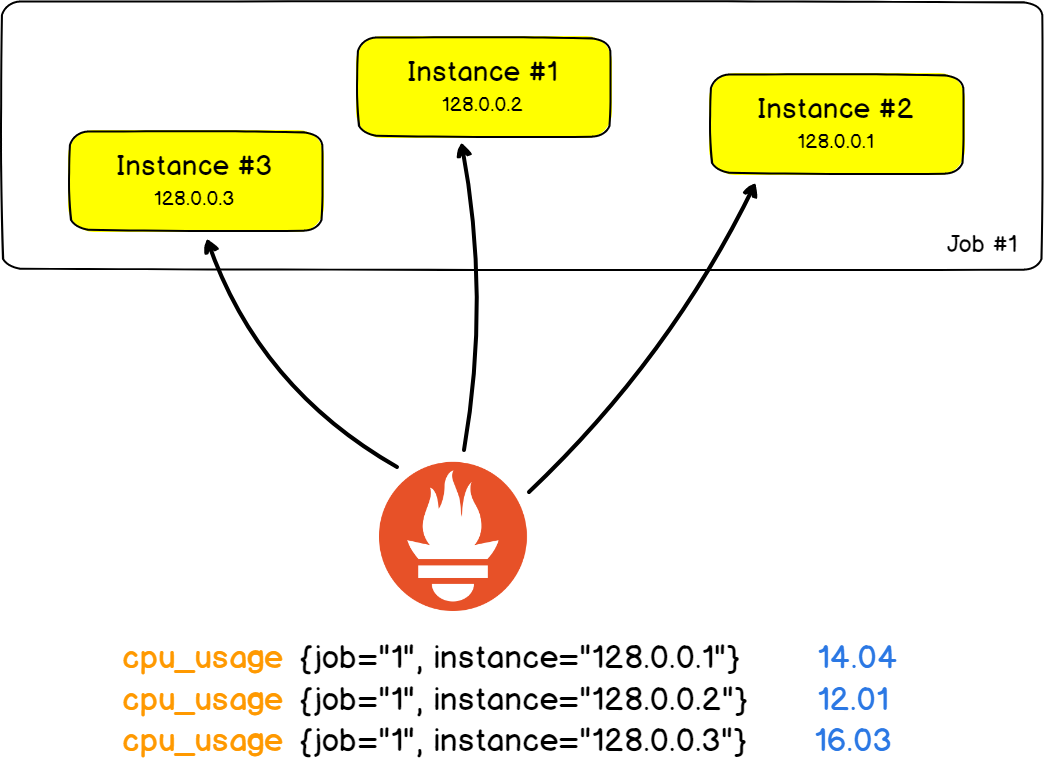
Lo bueno es que las tareas y las instancias son campos en las etiquetas, y puede filtrar los resultados por una instancia o tarea específica.
¿Es conveniente?
4. PromQL
Si usa bases de datos basadas en InfluxDB, probablemente ya esté familiarizado con InfluxQL . O use SQL en TimescaleDB .
Prometheus también tiene su propio lenguaje para consultar y recuperar datos de los servidores: PromQL .
Como ya sabemos, los datos se presentan en forma de pares clave-valor. PromQL usa la misma sintaxis y devuelve resultados como vectores.
¿Qué tipo de vectores?
Hay dos tipos de vectores en Prometheus y PromQL:
- Vectores instantáneos que representan todas las métricas por la última marca de tiempo.
- Vectores con un rango de tiempo : si necesita observar el desarrollo de una métrica a lo largo del tiempo, puede especificar un rango de tiempo en una solicitud a Prometheus. Como resultado, obtendrá un vector que combina todos los valores registrados para el período seleccionado.
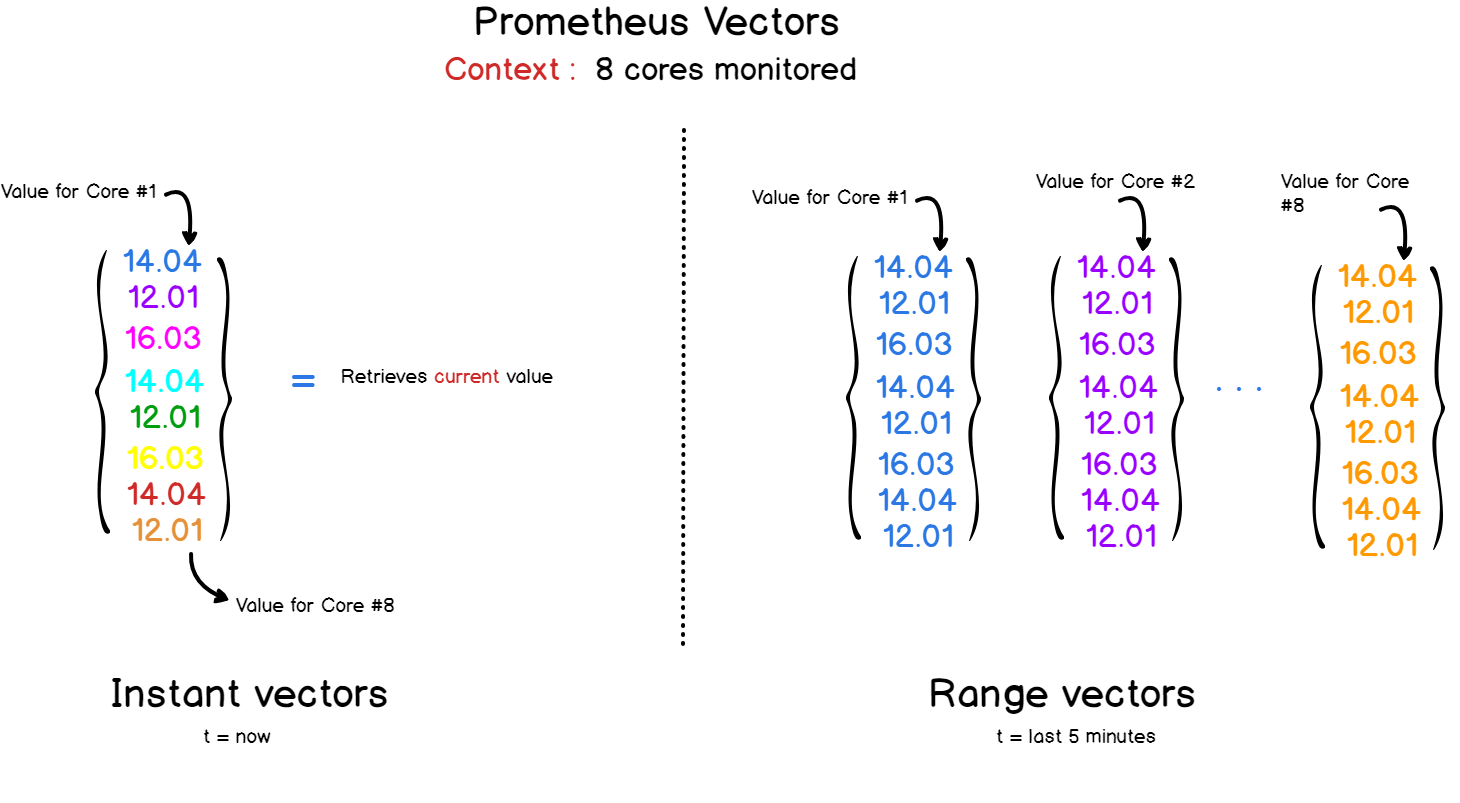
PromQL API proporciona un conjunto de funciones para operaciones con datos en consultas.
Puede ordenar los valores, aplicarles funciones matemáticas (por ejemplo, calcular derivados o exponentes) e incluso hacer predicciones (por ejemplo, utilizando el modelo Holt-Winters).
5. Instrumentación
La instrumentación es otra parte importante de Prometeo. Instrumenta las aplicaciones antes de extraer datos de ellas.
En Prometheus, la instrumentación significa agregar bibliotecas de clientes a la aplicación para proporcionar métricas de Prometheus.
La instrumentación está disponible para los lenguajes de programación más comunes: por ejemplo, Python, Java, Ruby, Go e incluso Node o C # .
En esencia, crea objetos de memoria (por ejemplo, medidores o contadores) que aumentarán o disminuirán dinámicamente el valor.
Luego, elige dónde proporcionar las métricas. Prometheus los recogerá desde allí y los guardará en su base de datos de series temporales.
6. Exportadores
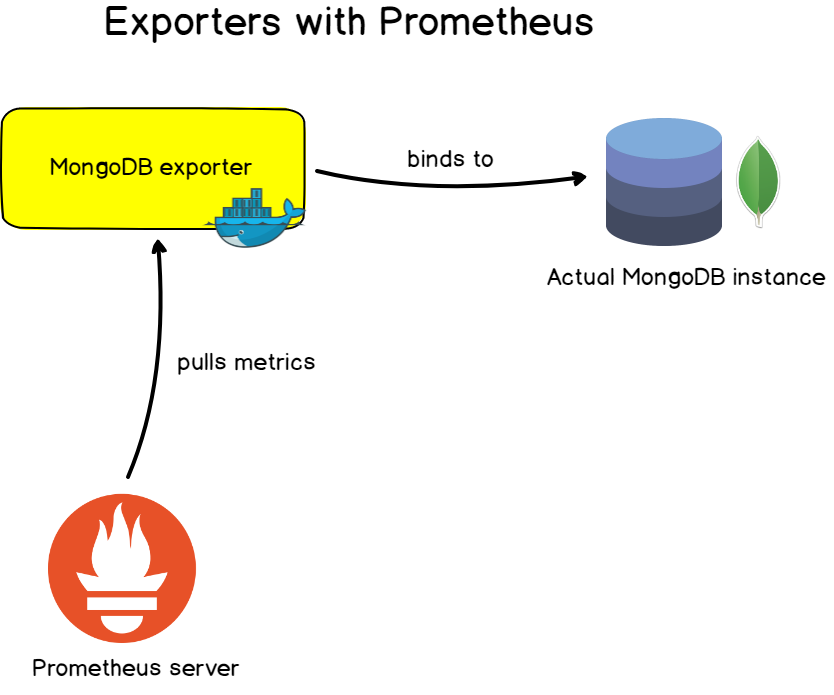
En las aplicaciones que escribió, es muy conveniente personalizar las métricas proporcionadas y cambiarlas con el tiempo utilizando la instrumentación.
Para aplicaciones, servidores y bases de datos conocidos, Prometheus ofrece exportadores con los que puede monitorear los objetivos .
Estos exportadores generalmente se representan como imágenes Docker y son fáciles de personalizar. Proporcionan un conjunto de métricas listas para usar y, a menudo, paneles de control listos para usar con los que puede configurar el monitoreo en minutos.
Ejemplos de exportadores:
- Exportadores de bases de datos : para bases de datos MongoDB, servidores SQL y MySQL.
- Exportadores HTTP : para servidores HAProxy, Apache o NGINX.
- Exportadores de Unix : el rendimiento del sistema se puede monitorear utilizando los exportadores de nodos integrados, que proporcionan todas las métricas del sistema sin configuración adicional.
Algunas palabras sobre compatibilidad mutua
La mayoría de las bases de datos de series temporales admiten la interoperabilidad de sus sistemas.
Prometheus no es el único sistema de monitoreo con sus requisitos métricos. Por ejemplo, InfluxDB (a través de Telegraf), CollectD , StatsD y Nagios también tienen sus propios estándares.
Por lo tanto, para la interacción de diferentes sistemas, se crean exportadores. Incluso si Telegraf no envía las métricas en el formato que acepta Prometheus, Telegraf puede enviar estas métricas al exportador InfluxDB, desde donde Prometheus las recogerá.
7. Alertas
Al trabajar con bases de datos de series temporales, necesita comentarios de los datos, y los administradores de alertas son responsables de esto.
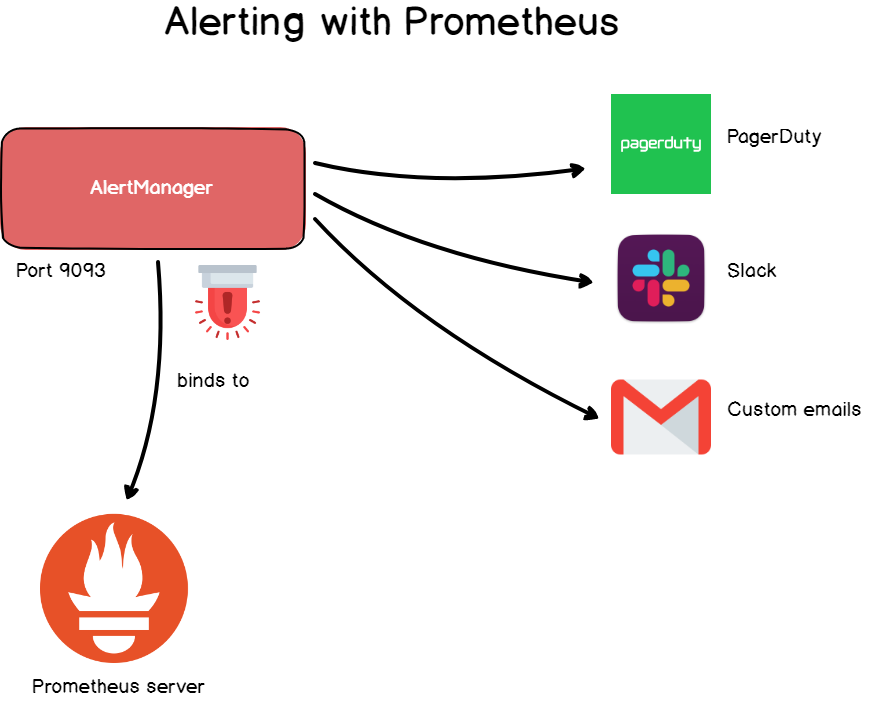
En Grafana, las alertas son comunes, pero también están disponibles en Prometheus a través del administrador de alertas.
Alert Manager es una herramienta separada que se une a Prometheus y lanza sirenas personalizadas .
Las alertas se definen en el archivo de configuración y definen un conjunto de reglas para las métricas. Si se cumple con la regla en la serie de tiempo, se activa una alerta y se envía a los destinatarios especificados.
Al igual que en Grafana, puede especificar la dirección de correo electrónico, Slack webhook, PagerDuty y objetos HTTP personalizados como destinatario.
Parte III Ejemplos de Prometeo

Y, por supuesto, cada guía debe tener ejemplos prácticos . Como me gusta decir, la tecnología no es un fin en sí misma y debe cumplir una tarea específica.
Hablaremos de esto.
1. DevOps
Con todos estos exportadores para diferentes sistemas, bases de datos y servidores, es obvio que Prometheus está destinado principalmente a la industria DevOps .
Sabemos que hay muchos proveedores competidores y soluciones personalizadas en esta área.
Prometheus es perfecto para DevOps.
Casi no requiere esfuerzo configurar y ejecutar instancias, y puede activar y configurar fácilmente cualquier herramienta auxiliar.
Al detectar objetivos , por ejemplo, a través de un exportador de archivos , esta es una gran solución para pilas donde los contenedores y las arquitecturas distribuidas se usan ampliamente.
En un entorno donde las instancias se crean y eliminan constantemente, ninguna pila de DevOps puede funcionar sin el descubrimiento del servicio .
2. salud
Hoy, las soluciones de monitoreo son necesarias no solo en TI. También se utilizan en grandes industrias que proporcionan arquitecturas sanitarias flexibles y escalables.
La demanda está creciendo y las arquitecturas de TI deben cumplirla. Si no tiene una herramienta confiable para monitorear toda la infraestructura, corre el riesgo de serias interrupciones en el servicio . Ya en el sector de la salud, ese peligro definitivamente debe minimizarse.
Este ejemplo se discutió en opensource.com en el siguiente artículo .
3. Servicios financieros
InfoQ, Prometheus .
(Jamie Christian) (Alan Strader) , Prometheus Northern Trust. , .
X. ?

.
Prometheus, , , .
, .
Prometheus, .
Luego instale las herramientas necesarias, cree su primer tablero de instrumentos, ¡y listo!
Si necesita inspiración, lea mi artículo sobre cómo monitorear una máquina Linux con Prometheus y Grafana . Hay instrucciones para configurar herramientas y el primer tablero de instrumentos.
Espero que hayas aprendido algo nuevo.
Si tienes un tema para mi próximo artículo, compártelo.
¡Quédate feliz!